
Augmentation Method for High Intra-Class Variation Data in Apple Detection


Abstract
:1. Introduction
- We created the MTOA, the first dataset considering multi-type occlusion of apple fruits, and made it available for free under the MIT license.
- We proposed a balance augmentation method to achieve a balanced number of annotation boxes of each apple occlusion class in different regions under different illuminations and solved the problem of severe differences in the number of samples between classes.
- We validated the effectiveness of the proposed algorithm using five popular lightweight object detection models.
2. Materials and Methods
2.1. Making the MTOA Dataset
2.2. Data Balance Algorithms
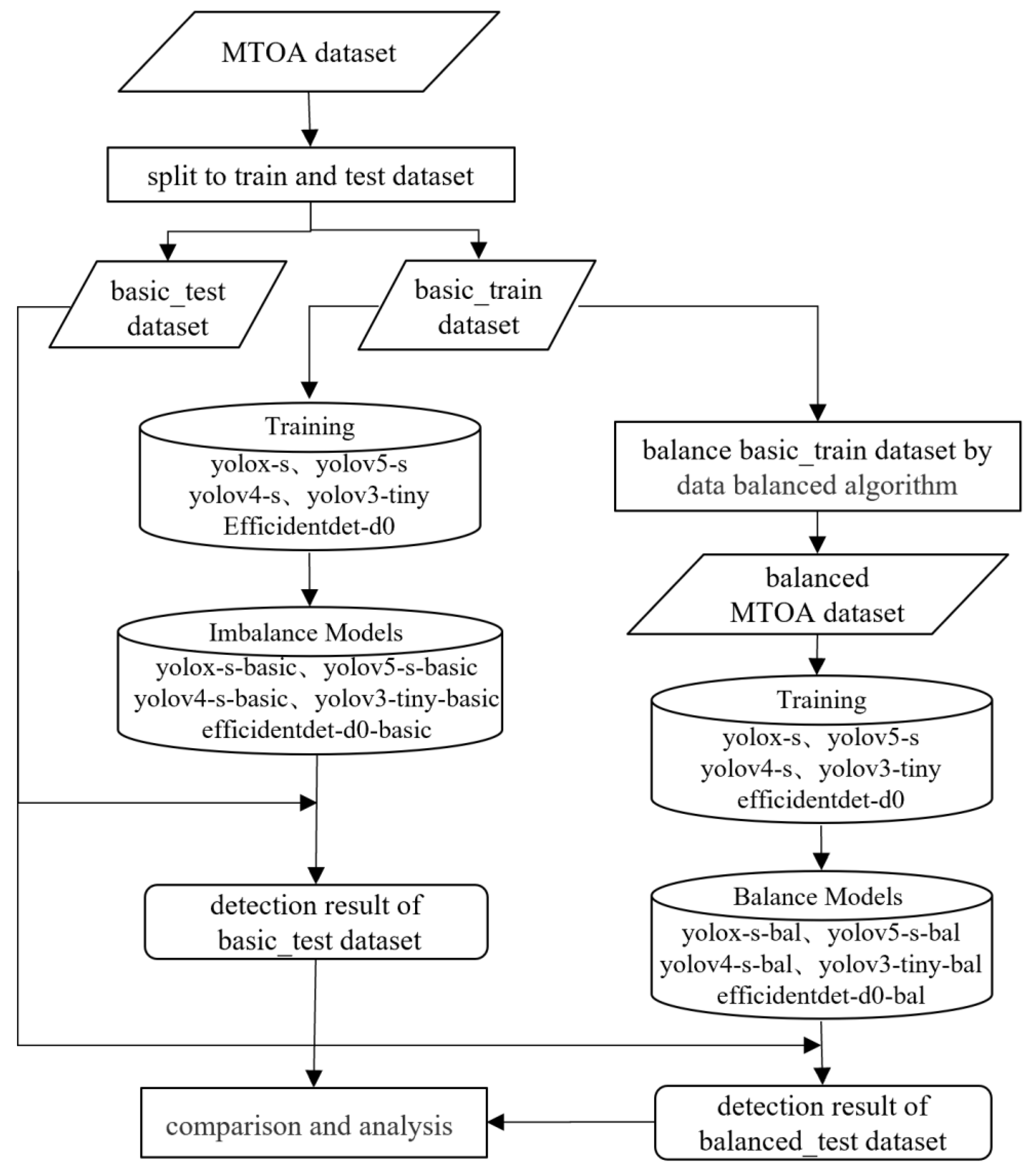
2.2.1. Algorithm Validation Process
- Splitting the MTOA dataset into a basic test and training dataset with a ratio of 3:7 and then training five lightweight models with the basic training dataset. The training of five lightweight models was carried out to form five corresponding basic models.
- Balancing the basic training dataset using the proposed method to form the balanced MTOA dataset.
- Training five lightweight models with the balanced MTOA dataset. Five lightweight models were trained to form five corresponding balanced models.
- Using basic test dataset to perform metrics on five basic and balanced models and analyze reasons for changes in model performance.
2.2.2. MTOA Dataset Statistical Analysis by Illumination
2.2.3. Rules for Building the Component Pool
- Rules for making base image elementsIn this study, images with no fruit in high illumination and matching the orchard background were selected as high-illumination base images. Images with no fruit in low illumination and matching the orchard background were selected as low-illumination base images. However, since there were fewer images in this study, some low-illumination images were blurred and supplemented as base images. These two types of base images were randomly scaled to 640 × 480 and 1280 × 720 to maintain consistency with the image size in basic training dataset. Finally, 1000 high-illumination base images and 1000 low-illumination base images were selected. Figure 4 shows various base images under high and low illuminations.
- Rules for the selection of occlusion elementsIn this study, fruit, branch, leaf, and composite occlusion elements were segmented from images from the basic training dataset. The fruit occlusion elements were mainly single intact fruits; the branch elements were divided into multiple branches and single branches; the leaf elements were divided into a single leaf and multiple leaves; and the composite elements were mainly the combination of branches, leaves, and fruits. Five hundred elements of each of the five classes were segmented to ensure the diversity of selected results. After that, fruit, branch, leaf, and composite occlusion elements under high illumination were grouped into one category. Meanwhile, the fruit, branch, leaf, and composite occlusion elements under low illumination were grouped into another category. Figure 5 shows the occlusion elements at high and low illuminations.
2.2.4. Data Synthesis Methods for Each Apple Occlusion Class
- N, B, and L class synthesis methodsN synthesis required the cyclic extraction of the required number of N from the basic training dataset for the corresponding region and illumination. B and L were formed by directly attaching branch and leaf occlusion elements to the surface of N randomly according to the edge entry rule. Figure 6 shows the synthesis of B and L.
- First, the numbers of B and L to be synthesized were calculated. Then, the N class was selected from the images of the basic training dataset for the corresponding region and illumination. The selected N was divided into six equal parts according to their width and height to form a grid with a size of 6 × 6. Since all occlusion elements were entered by the edges of N, the boundary of the grid was set in this study as an edge entry area, within which the starting points of branch and leaf needed to be selected.
- The branch and leaf elements were randomly extracted from the component pool and cropped at a scale of 0.5–1.0 to form a new occlusion element.
- The edge entry area contained 24 location points from which the starting point of the occlusion element was randomly selected. The endpoint of the occlusion element could not be in the same row or column as the random starting point because the area formed by the starting and endpoints of the occlusion element in the same row and column was a line, which cannot provide a rectangular area of the same size for the occlusion element. To highlight the occlusion elements, this study set the distance between the starting and endpoints of the occlusion element to be greater than three grid lengths to ensure that any area adjacent to the random starting point that was less than three grid lengths could not be used as the endpoint of the selection area. Other areas could be used as the endpoint of the selection area. Then, we randomly selected the endpoint of the occlusion elements from the endpoint of the selection area.
- After determining the random starting points and random endpoints of the occlusion element, the dimensions of the new occlusion element were transformed by scaling or cropping the rectangular area between the random start and endpoints. Then, the changed occlusion element was pasted in the random starting and ending areas to form B or L, and finally, the synthetic B or L image was saved.
- Class F synthesis methodWhen synthesizing class F, it was impossible to directly attach the fruit occlusion element to the N surface. This was because it was easy to identify the fruit occlusion element as N during the model training process if the N area was overshadowed. The synthesis process of F, shown in Figure 7, was accomplished by limiting the common area of the fruit occlusion element and N.
- First, N was selected from the images of the basic training dataset for the corresponding region and illumination, which depended on the number of F to be synthesized. Then, we obtained the fruit occlusion element from the component pool according to illumination demand and adjusted its size to the same size as the selected N. Subsequently, we divided N into a 6 × 6 grid and created a 14 × 14 grid area with the center point of N as the origin. The 14 × 14 grid area was divided into four quadrants, with the upper left corner as the first quadrant.
- The location of the upper left corner of the fruit occlusion element was randomly selected in the first quadrant. To prevent the fruit occlusion element from completely obscuring N, the centroid of the occlusion element and origin were not allowed to overlap. This method limited the area of overlap between the fruit occlusion element and N to no more than 34%, because the fruit occlusion element would become N if it exceeded 34%, leading to confusing annotations.
- After determining the starting position of the upper left corner for the fruit occlusion element, the upper left corner of the fruit occlusion element and starting position were overlapped to complete the operation of pasting the fruit occlusion element on a 14 × 14 grid. Finally, area N on a 14 × 14 grid was intercepted, and the result of the interception was the synthesized F image.
- Fused occlusion-type compositing methodsThe fused occlusion apples mainly consisted of BL, BF, LF, and BLF. All four could be synthesized on the basis of B, L, and F by the attachment of a second or third occlusion element to form the final fused occlusion apple class. The results of BL, BF, LF, and BLF are shown in Figure 8, and the specific synthesis process is described in Method 1 of the Supplementary Material.
2.2.5. Making the Augmented MTOA Dataset
| Algorithm 1: Making the Augmented MTOA Dataset |
| Input: a. Synthetic occlusion apple images: b. Base images under high and low illumination: |
| Output: Balanced MTOA dataset: |
| id∈(Zhaoyuan,Qixia,Procieer), l∈(low,high), i∈(N,L,F,B,LF,BL,BF,BLF), j is num of class i with l light, k is img num with l light. |
2.3. Equipment and Model Training
2.3.1. Training Equipment
2.3.2. Model Selection and Training
2.4. Performance Metrics
3. Results
3.1. Results after the Balance of Each Occlusion Class
3.2. Training Results before and after Data Balance
- Yolox-s-bal improved significantly over the yolox-s-basic model in terms of precision, recall, and mAp, and it showed some improvement in Ap values between all occlusion classes. Moreover, yolov4-s-bal, yolov3-tiny-bal, and yolox-s-bal had the same performance, indicating that the balance method proposed in this study can improve the performance of the above four models in detecting apple occlusion targets in a comprehensive manner. Compared with the yolov5-s-basic model, the precision and APBLF values decreased by 0.001 and 0.042, respectively. However, the recall value improved significantly, the mAp value remained balanced, and the AP values of all classes except BLF improved, indicating that the proposed method in this study can maintain an accurate performance of yolov5-s-basic while improving the ability of the model to find a full range of occlusion targets.
- The highest values of each metric in the detection results were P (0.974) in yolox_s_bal; R (0.972) in yolox-s-bal; mAp (0.960) in yolov5-s-basic and yolov5-s-bal; APN (0.985) in yolov5-s-bal; and APB (0.982), APL (0.975), APF (0.963), APBL (0.965), APBF (0.959), APLF (0.956), and APBLF (0.994) in yolox-s-bal, showing that the highest metric values were among the models trained with the balanced MTOA dataset. This indicates that the proposed method can promote a great expression of the detection performance of the model for some categories.
- The proposed method improved most of the metrics of each model, but the APBLF metrics decreased after the training of yolov5-s-bal and efficientDet-d0-bal, indicating that the features of the BLF in the balanced MTOA dataset differed from those in the BLF classes of the basic training dataset. This affected the detection ability of the BLF in these two models.
4. Discussion
- First, four sub-classes of test datasets were tested based on the yolov5-s-basic and yolov5-s-bal models. Test results are shown in Table 6, and visualization test results are shown in Supplementary Material Figure S2. In the test results for ZY_H_TEST and QX_H_TEST, the APBLF improved by 0.018 and 0.071, respectively, but the APBLF decreased by 0.085 and 0.096 in the test results for ZY_L_TEST and PSR_H_TEST, respectively. Meanwhile, in the test results for PSR_H, all metrics decreased for different illuminations except APF, indicating that the yolov5-s-bal model had a loss in the detection performance of the BLF in PSR_H_TEST and ZY_L_TEST, which is also the main reason for the decrease in APBLF when testing the yolov5-s-bal model. In addition, the yolov5-s-basic model had the greatest variability in all test metrics for PSR_H_TEST. If we want to continue to improve the metrics, we need to provide data that are more similar to source data for model training. However, for PSR_H_TEST balance augmentation, the occlusion elements in ZY_H and ZY_L were used for synthesis, which improved the amount of training data but fell short of the goal of being more similar to the source data, resulting in a decrease in the APBLF and other metrics.
- Four sub-classes of test datasets were tested based on the yolov4-s-basic and yolov4-s-bal models. The test results are shown in Table 7, and the visualization test results are shown in Supplementary Material Figure S3. The decreases in APBLF and P for ZY_L_TEST data were 0.036 and 0.001, respectively, with a large decrease in APBLF, which is due to the same reason as the decrease in APBLF for the yolov5-s-bal model test. Moreover, the detection metrics under all other sub-class test datasets showed substantial improvements, indicating that the combined detection performance of the yolov4-s-bal model improved significantly. Although the detection ability of BLF in ZY_L_TEST data was suppressed, the AP values in other sub-classes increased significantly, which was the main reason for the increase in APBLF when all test datasets passed the yolov4-s-bal test. The results of the yolov4-s-basic model for PSR_H_TEST, ZY_H_TEST, and PSR_H_TEST were all relatively low, which shows that there is more room to improve the performance of the model. All other metrics improved after training the model with a balanced MTOA dataset, indicating that the proposed method in this study is more effective in improving the performance of the model when there is more room for improvement.
5. Limitations and Future Research
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sambasivan, N.; Kapania, S.; Highfill, H.; Akrong, D.; Paritosh, P.; Aroyo, L.M. Everyone wants to do the model work, not the data work: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar] [CrossRef]
- Jun, J.; Kim, J.; Seol, J.; Kim, J.; Son, H.I. Towards an Efficient Tomato Harvesting Robot: 3D Perception, Manipulation, and End-Effector. IEEE Access 2021, 9, 17631–17640. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Jia, W.; Mou, S.; Wang, J.; Liu, X.; Zheng, Y.; Lian, J.; Zhao, D. Fruit recognition based on pulse coupled neural network and genetic Elman algorithm application in apple harvesting robot. Int. J. Adv. Robot. Syst. 2020, 17, 1–14. [Google Scholar] [CrossRef]
- Jia, W.; Zhang, Y.; Lian, J.; Zheng, Y.; Zhao, D.; Li, C. Apple harvesting robot under information technology: A review. Int. J. Adv. Robot. Syst. 2020, 17, 1–16. [Google Scholar] [CrossRef]
- Kootstra, G.; Wang, X.; Blok, P.M.; Hemming, J.; van Henten, E. Selective Harvesting Robotics: Current Research, Trends, and Future Directions. Curr. Robot. Rep. 2021, 2, 95–104. [Google Scholar] [CrossRef]
- Dandan, H.D.W. Recognition of apple targets before fruits thinning by robot based on R-FCN deep convolution neural network. Trans. Chin. Soc. Agric. Eng. 2019, 35, 8. [Google Scholar]
- Biffi, L.; Mitishita, E.; Liesenberg, V.; Santos, A.; Gonçalves, D.; Estrabis, N.; Silva, J.; Osco, L.P.; Ramos, A.; Centeno, J.; et al. ATSS Deep Learning-Based Approach to Detect Apple Fruits. Remote Sens. 2020, 13, 54. [Google Scholar] [CrossRef]
- Chu, P.; Li, Z.; Lammers, K.; Lu, R.; Liu, X. Deep learning-based apple detection using a suppression mask R-CNN. Pattern Recognit. Lett. 2021, 147, 206–211. [Google Scholar] [CrossRef]
- Fu, L.; Majeed, Y.; Zhang, X.; Karkee, M.; Zhang, Q. Faster R–CNN–based apple detection in dense-foliage fruiting-wall trees using RGB and depth features for robotic harvesting. Biosyst. Eng. 2020, 197, 245–256. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Vilaplana, V.; Rosell-Polo, J.R.; Morros, J.-R.; Ruiz-Hidalgo, J.; Gregorio, E. KFuji RGB-DS database: Fuji apple multi-modal images for fruit detection with color, depth and range-corrected IR data. Data Brief 2019, 25, 104289. [Google Scholar] [CrossRef]
- Hani, N.; Roy, P.; Isler, V. MinneApple: A Benchmark Dataset for Apple Detection and Segmentation. IEEE Robot. Autom. Lett. 2020, 5, 852–858. [Google Scholar] [CrossRef]
- Janowski, A.; Kaźmierczak, R.; Kowalczyk, C.; Szulwic, J. Detecting Apples in the Wild: Potential for Harvest Quantity Estimation. Sustainability 2021, 13, 8054. [Google Scholar] [CrossRef]
- Ji, W.; Gao, X.; Xu, B.; Pan, Y.; Zhang, Z.; Zhao, D. Apple target recognition method in complex environment based on improved YOLOv4. J. Food Process Eng. 2021, 44, e13866. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Jiao, Y.; Luo, R.; Li, Q.; Deng, X.; Yin, X.; Ruan, C.; Jia, W. Detection and Localization of Overlapped Fruits Application in an Apple Harvesting Robot. Electronics 2020, 9, 1023. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Lv, J.; Wang, Y.; Xu, L.; Gu, Y.; Zou, L.; Yang, B.; Ma, Z. A method to obtain the near-large fruit from apple image in orchard for single-arm apple harvesting robot. Sci. Hortic. 2019, 257, 108758. [Google Scholar] [CrossRef]
- Mazzia, V.; Khaliq, A.; Salvetti, F.; Chiaberge, M. Real-Time Apple Detection System Using Embedded Systems with Hardware Accelerators: An Edge AI Application. IEEE Access 2020, 8, 9102–9114. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Wang, Y. Target Recognition and Trajectory Planning of Apple Harvesting Robot considering Color Multimedia Image Segmentation Algorithm. Adv. Multimed. 2021, 2021, 2817869. [Google Scholar] [CrossRef]
- Wu, L.; Ma, J.; Zhao, Y.; Liu, H. Apple Detection in Complex Scene Using the Improved YOLOv4 Model. Agronomy 2021, 11, 476. [Google Scholar] [CrossRef]
- Xuan, G.; Gao, C.; Shao, Y.; Zhang, M.; Wang, Y.; Zhong, J.; Li, Q.; Peng, H. Apple Detection in Natural Environment Using Deep Learning Algorithms. IEEE Access 2020, 8, 216772–216780. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, C.; Dai, J.; Xun, Y.; Bao, G. Tracking and recognition algorithm for a robot harvesting oscillating apples. Int. J. Agric. Biol. Eng. 2020, 13, 163–170. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Hu, J.; Yang, H.; Lyu, M.R.; King, I.; So, A.M.-C. Online Nonlinear AUC Maximization for Imbalanced Data Sets. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 882–895. [Google Scholar] [CrossRef]
- Mateusz, B.; Atsuto, M.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar]
- Yan, Y.; Liu, R.; Ding, Z.; Du, X.; Chen, J.; Zhang, Y. A Parameter-Free Cleaning Method for SMOTE in Imbalanced Classification. IEEE Access 2019, 7, 23537–23548. [Google Scholar] [CrossRef]
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data 2021, 8, 6. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Levi, G.; Hassncer, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Sambasivam, G.; Opiyo, G.D. A predictive machine learning application in agriculture: Cassava disease detection and classification with imbalanced dataset using convolutional neural networks. Egypt. Inform. J. 2021, 22, 27–34. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IJCNN 2008: (IEEE World Congress on Computational Intelligence): IEEE International Joint Conference on the Neural Networks, Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Hasan, A.; Sohel, F.; Diepeveen, D.; Laga, H.; Jones, M. Weed recognition using deep learning techniques on class-imbalanced imagery. Crop Pasture Sci. 2022. [Google Scholar] [CrossRef]
- Koščević, K.; Subašić, M.; Lončarić, S. Guiding the Illumination Estimation Using the Attention Mechanism. In Proceedings of the 2020 2nd Asia Pacific Information Technology Conference, Bali, Indonesia, 17–19 January 2020. [Google Scholar]
- Koscevic, K.; Subasic, M.; Loncaric, S. Deep Learning-Based Illumination Estimation Using Light Source Classification. IEEE Access 2020, 8, 84239–84247. [Google Scholar] [CrossRef]
- Zhao, D.A.; Lv, J.; Wei, J.; Ying, Z.; Chen, Y. Design and control of an apple harvesting robot. Biosyst. Eng. 2011, 110, 112–122. [Google Scholar]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. Automatic Fire Detection and Notification System Based on Improved YOLOv4 for the Blind and Visually Impaired. Sensors 2022, 22, 3307. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Owner | Country | Location | Acquisition Date | Sensor | Platform | Development Stage | Size | No. of Image |
|---|---|---|---|---|---|---|---|---|---|
| SD_ZY_IMG | CAAS | China | ZhaoYuan | 25 October 2021 | Intel d455 | Handheld | filling-ripening | 1280 × 720 | 4870 |
| SD_QX_IMG | CAAS | China | Qixia | 10 October 2020 | Osmo Action1 | Handheld | filling-ripening | 640 × 480 | 2827 |
| WT_PSR_IMG | Fu3lab | America | Prosser | 2017/2018 | Kinect V2 | Tractor | filling-ripening | 640 × 480 | 1558 |
| Data Name | No. of Images | No. of Annotation Boxes | No. of N | No. of B | No. of L | No. of BL | No. of BF | No. of F | No. of LF | No. of BLF |
|---|---|---|---|---|---|---|---|---|---|---|
| ZY_H | 2738 | 36,803 | 9856 | 10,579 | 5597 | 6405 | 1936 | 1296 | 474 | 660 |
| ZY_L | 2132 | 25,165 | 9639 | 5671 | 4558 | 3133 | 728 | 901 | 252 | 283 |
| QX_H | 2681 | 8159 | 1273 | 3053 | 804 | 1442 | 934 | 268 | 116 | 269 |
| QX_L | 146 | 491 | 68 | 215 | 34 | 112 | 41 | 6 | 0 | 15 |
| PSR_H | 1558 | 10,774 | 2150 | 189 | 5295 | 942 | 54 | 540 | 1457 | 147 |
| PSR_L | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Model | Epochs | Image_Size | Original Augmentation Algorithm | New Augmentation Algorithm | Training Time (h) | Project Website |
|---|---|---|---|---|---|---|
| yolox-s | ≤300 | 640 × 640 | mosaic, mixup, flip, hsv | mosaic, mixup (≤60 epoch) flip, hsv (≥0 epoch) | 7.8/17.2 | https://github.com/MegEngine/YOLOX (accessed on 30 December 2021) |
| yolov5-s | ≤300 | 640 × 640 | mosaic, mixup, flip, copy_paste, multi-scale | flip, copy_paste, multi-scale | 4.4/10.4 | https://github.com/ultralytics/yolov5 (accessed on 30 November 2021) |
| yolov4-s | ≤300 | 640 × 640 | hsv, flip, mosaic | hsv, flip | 11.1/27.7 | https://github.com/WongKinYiu/PyTorch_YOLOv4 (accessed on 30 November 2021) |
| yolov3-tiny | ≤300 | 640 × 640 | flip, hsv, mosaic, mixup | flip, hsv | 4.8/11.6 | https://github.com/ultralytics/yolov3 (accessed on 30 November 2021) |
| efficientDet-d0 | ≤200 | 640 × 640 | -- | -- | 19.4/33.8 | https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch (accessed on 31 December 2021) |
| Results of Data Synthesis | Total Synthetic | No. of N | No. of B | No. of L | No. of BL | No. of BF | No. of F | No. of LF | No. of BLF |
|---|---|---|---|---|---|---|---|---|---|
| ZY_H_syn | 4,7829 | 723 | 0 | 4982 | 4174 | 8643 | 9283 | 10,105 | 9919 |
| ZY_L_syn | 59,467 | 940 | 4908 | 6021 | 7446 | 9851 | 9678 | 10,327 | 10,296 |
| QX_H_syn | 76,473 | 9306 | 7526 | 9775 | 9137 | 9645 | 10,311 | 10,463 | 10,310 |
| QX_L_syn | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| PSR_H_syn | 73,858 | 8429 | 10,390 | 5284 | 9637 | 10,525 | 10,039 | 9122 | 10,432 |
| PSR_L_syn | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Model Comparison | P | R | mAP0.5 | APN | APB | APL | APF | APBL | APBF | APLF | APBLF |
|---|---|---|---|---|---|---|---|---|---|---|---|
| yolox-s-basic | 0.894 | 0.845 | 0.892 | 0.904 | 0.898 | 0.897 | 0.892 | 0.886 | 0.888 | 0.884 | 0.885 |
| yolox-s-bal | 0.974 | 0.972 | 0.919 | 0.909 | 0.909 | 0.908 | 0.909 | 0.908 | 0.908 | 0.906 | 0.994 |
| diff | 0.080 | 0.127 | 0.027 | 0.005 | 0.011 | 0.011 | 0.017 | 0.022 | 0.020 | 0.022 | 0.109 |
| yolov5-s-basic | 0.947 | 0.914 | 0.960 | 0.984 | 0.979 | 0.97 | 0.960 | 0.957 | 0.948 | 0.955 | 0.934 |
| yolov5-s-bal | 0.946 | 0.936 | 0.960 | 0.985 | 0.982 | 0.975 | 0.963 | 0.965 | 0.959 | 0.956 | 0.898 |
| diff | −0.001 | 0.022 | 0 | 0.001 | 0.003 | 0.005 | 0.003 | 0.008 | 0.011 | 0.001 | −0.036 |
| yolov4-s-basic | 0.900 | 0.751 | 0.727 | 0.835 | 0.797 | 0.768 | 0.699 | 0.742 | 0.693 | 0.639 | 0.646 |
| yolov4-s-bal | 0.961 | 0.913 | 0.907 | 0.941 | 0.930 | 0.916 | 0.910 | 0.904 | 0.920 | 0.879 | 0.859 |
| diff | 0.061 | 0.162 | 0.180 | 0.106 | 0.133 | 0.148 | 0.211 | 0.162 | 0.227 | 0.240 | 0.213 |
| yolov3-tiny-basic | 0.856 | 0.791 | 0.883 | 0.959 | 0.936 | 0.941 | 0.856 | 0.889 | 0.842 | 0.877 | 0.768 |
| yolov3-tiny-bal | 0.910 | 0.842 | 0.918 | 0.97 | 0.95 | 0.956 | 0.897 | 0.912 | 0.895 | 0.917 | 0.835 |
| diff | 0.054 | 0.051 | 0.035 | 0.011 | 0.014 | 0.015 | 0.041 | 0.023 | 0.053 | 0.040 | 0.067 |
| efficientdet-d0-basic | 0.933 | 0.896 | 0.930 | 0.951 | 0.938 | 0.936 | 0.923 | 0.923 | 0.934 | 0.919 | 0.913 |
| efficientdet-d0-bal | 0.940 | 0.923 | 0.935 | 0.951 | 0.948 | 0.939 | 0.934 | 0.935 | 0.935 | 0.934 | 0.901 |
| diff | 0.007 | 0.027 | 0.005 | 0.000 | 0.01 | 0.003 | 0.011 | 0.012 | 0.001 | 0.015 | −0.012 |
| Model Comparison | Data | P | R | mAP0.5 | APN | APB | APL | APF | APBL | APBF | APLF | APBLF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| yolov5-s-basic | ZY_H_TEST | 0.943 | 0.935 | 0.960 | 0.983 | 0.975 | 0.964 | 0.944 | 0.971 | 0.940 | 0.977 | 0.926 |
| yolov5-s-bal | 0.970 | 0.950 | 0.970 | 0.986 | 0.983 | 0.970 | 0.968 | 0.979 | 0.957 | 0.970 | 0.944 | |
| diff | 0.027 | 0.015 | 0.010 | 0.003 | 0.008 | 0.006 | 0.024 | 0.008 | 0.017 | −0.007 | 0.018 | |
| yolov5-s-basic | ZY_L_TEST | 0.954 | 0.913 | 0.96 | 0.985 | 0.966 | 0.950 | 0.968 | 0.935 | 0.952 | 0.953 | 0.971 |
| yolov5-s-bal | 0.966 | 0.943 | 0.965 | 0.992 | 0.983 | 0.979 | 0.977 | 0.951 | 0.985 | 0.967 | 0.886 | |
| diff | 0.012 | 0.030 | 0.005 | 0.007 | 0.017 | 0.029 | 0.009 | 0.016 | 0.033 | 0.014 | −0.085 | |
| yolov5-s-basic | QX_H_TEST | 0.948 | 0.950 | 0.958 | 0.985 | 0.985 | 0.955 | 0.935 | 0.977 | 0.962 | 0.967 | 0.890 |
| yolov5-s-bal | 0.943 | 0.902 | 0.973 | 0.992 | 0.986 | 0.982 | 0.954 | 0.981 | 0.964 | 0.967 | 0.961 | |
| diff | −0.005 | −0.048 | 0.015 | 0.007 | 0.001 | 0.027 | 0.019 | 0.004 | 0.002 | 0.000 | 0.071 | |
| yolov5-s-basic | PSR_H_TEST | 0.923 | 0.936 | 0.960 | 0.989 | 0.985 | 0.983 | 0.964 | 0.947 | 0.905 | 0.963 | 0.942 |
| yolov5-s-bal | 0.957 | 0.886 | 0.934 | 0.979 | 0.951 | 0.982 | 0.964 | 0.936 | 0.859 | 0.957 | 0.846 | |
| diff | 0.034 | −0.050 | −0.026 | −0.010 | −0.034 | −0.001 | 0.000 | −0.011 | −0.046 | −0.006 | −0.096 |
| Model Comparison | Data | P | R | mAP0.5 | APN | APB | APL | APF | APBL | APBF | APLF | APBLF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| yolov4-s-basic | ZY_H_ TEST | 0.894 | 0.845 | 0.892 | 0.904 | 0.898 | 0.897 | 0.892 | 0.886 | 0.888 | 0.884 | 0.885 |
| yolov4-s-bal | 0.974 | 0.972 | 0.919 | 0.909 | 0.909 | 0.908 | 0.909 | 0.908 | 0.908 | 0.906 | 0.994 | |
| diff | 0.08 | 0.127 | 0.027 | 0.005 | 0.011 | 0.011 | 0.017 | 0.022 | 0.02 | 0.022 | 0.109 | |
| yolov4-s-basic | ZY_L_ TEST | 0.947 | 0.914 | 0.960 | 0.984 | 0.979 | 0.97 | 0.96 | 0.957 | 0.948 | 0.955 | 0.934 |
| yolov4-s-bal | 0.946 | 0.936 | 0.960 | 0.985 | 0.982 | 0.975 | 0.963 | 0.965 | 0.959 | 0.956 | 0.898 | |
| diff | −0.001 | 0.022 | 0.000 | 0.001 | 0.003 | 0.005 | 0.003 | 0.008 | 0.011 | 0.001 | −0.036 | |
| yolov4-s-basic | QX_H_ TEST | 0.900 | 0.751 | 0.727 | 0.835 | 0.797 | 0.768 | 0.699 | 0.742 | 0.693 | 0.639 | 0.646 |
| yolov4-s-bal | 0.961 | 0.913 | 0.907 | 0.941 | 0.93 | 0.916 | 0.910 | 0.904 | 0.92 | 0.879 | 0.859 | |
| diff | 0.061 | 0.162 | 0.180 | 0.106 | 0.133 | 0.148 | 0.211 | 0.162 | 0.227 | 0.240 | 0.213 | |
| yolov4-s-basic | PSR_H_TEST | 0.856 | 0.791 | 0.883 | 0.959 | 0.936 | 0.941 | 0.856 | 0.889 | 0.842 | 0.877 | 0.768 |
| yolov4-s-bal | 0.910 | 0.842 | 0.918 | 0.97 | 0.950 | 0.956 | 0.897 | 0.912 | 0.895 | 0.917 | 0.835 | |
| diff | 0.054 | 0.051 | 0.035 | 0.011 | 0.014 | 0.015 | 0.041 | 0.023 | 0.053 | 0.040 | 0.067 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Guo, W.; Lu, G.; Shi, Y. Augmentation Method for High Intra-Class Variation Data in Apple Detection. Sensors 2022, 22, 6325. https://doi.org/10.3390/s22176325
Li H, Guo W, Lu G, Shi Y. Augmentation Method for High Intra-Class Variation Data in Apple Detection. Sensors. 2022; 22(17):6325. https://doi.org/10.3390/s22176325
Chicago/Turabian StyleLi, Huibin, Wei Guo, Guowen Lu, and Yun Shi. 2022. "Augmentation Method for High Intra-Class Variation Data in Apple Detection" Sensors 22, no. 17: 6325. https://doi.org/10.3390/s22176325