
Infrared Target Detection Based on Joint Spatio-Temporal Filtering and L1 Norm Regularization


Abstract
:1. Introduction
- 1.
- A new anisotropic Gaussian kernel diffusion function, which makes full use of the local spatial feature information of the image, effectively suppresses the edge contour of the image background;
- 2.
- By combining the time-domain information and L1 norm regularization, the temporal-domain information of the image is used to globally constrain the low rank characteristics of the background, and the L1 norm is used to characterize the sparse characteristics of the target, which effectively suppresses the dynamic background and achieves good detection results;
- 3.
- The overlapping multiplier method is used to solve and reconstruct the image to better separate the background and target components.
2. Anisotropic Function Description
2.1. Preliminary Work
2.2. New Anisotropic Gaussian Kernel Diffusion Function
| Algorithm 1: Anisotropic Gaussian kernel diffusion function background modeling process. |
1. Input image; 2. Initializing Gaussian anisotropic kernel diffusion function parameters and in Formula (4) as follow . 3. Setting anisotropic filtering pixel gradient step in Formula (2) as follows
4. Combining Formulas (2) and (4) to calculate the pixel gradient of the pixel in 4 directions, and output the result as . 5. Using the result in step 4 and the constructed anisotropic filtering model Formula (5) as follows
6. Finish background modeling and output the Difference diagram as G. 7. end |
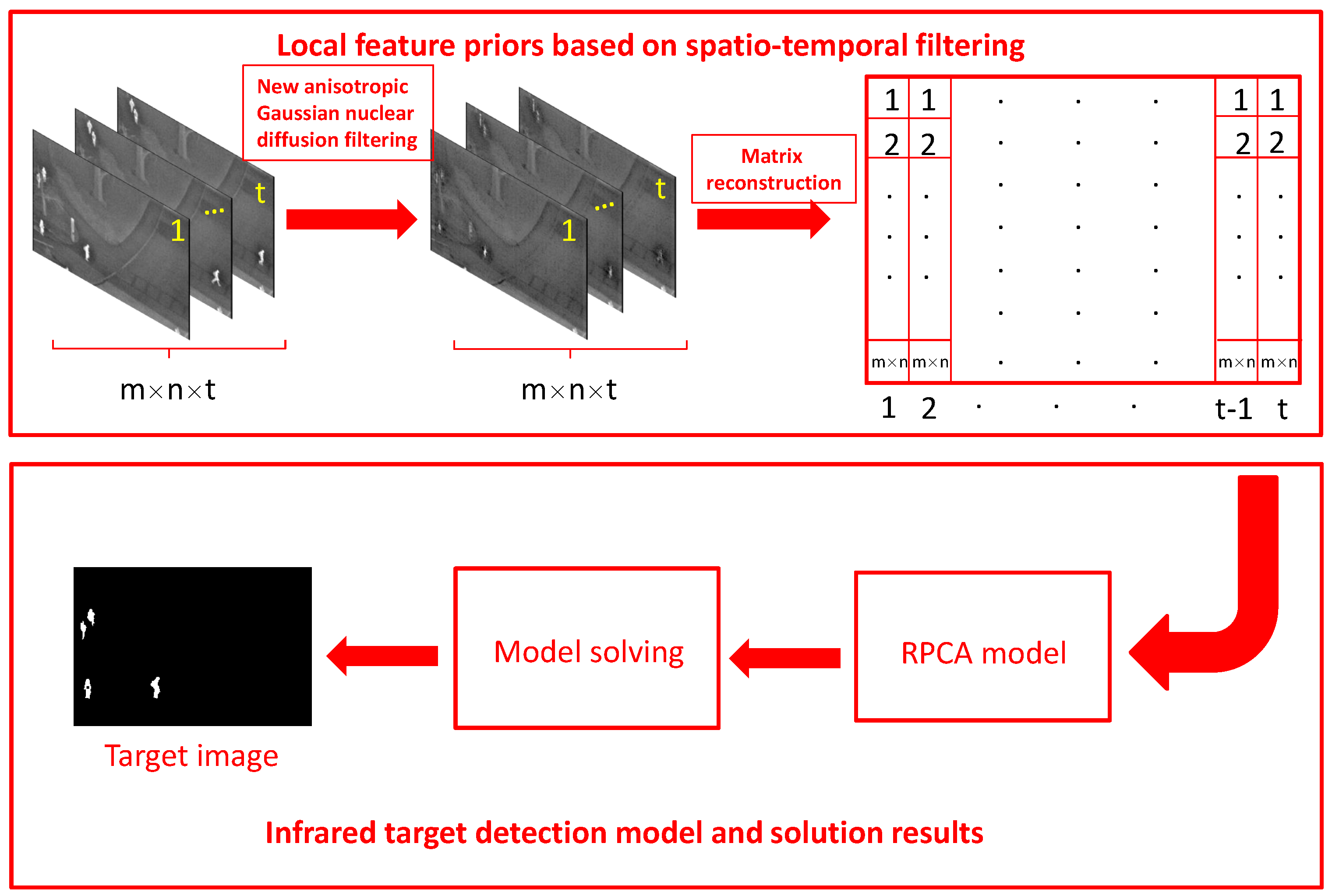
3. The Proposed Detection Model
| Algorithm 2: Combined spatio-temporal filtering and L1 norm regularization model. |
input: image matrix D, parameters , c. 1. Initialize: , max_Iter = 500, . while not converged do 2. Fixed other parameters and update by . 3. Fixed other parameters and update by . 4. Fixed other parameters and update by . 5. Fixed other parameters and update by . 6. Check the convergence conditions: or Iter > max_Iter. 7. Update . end while Output: B, T. |
4. Results and Analysis
4.1. Experimental Scenes
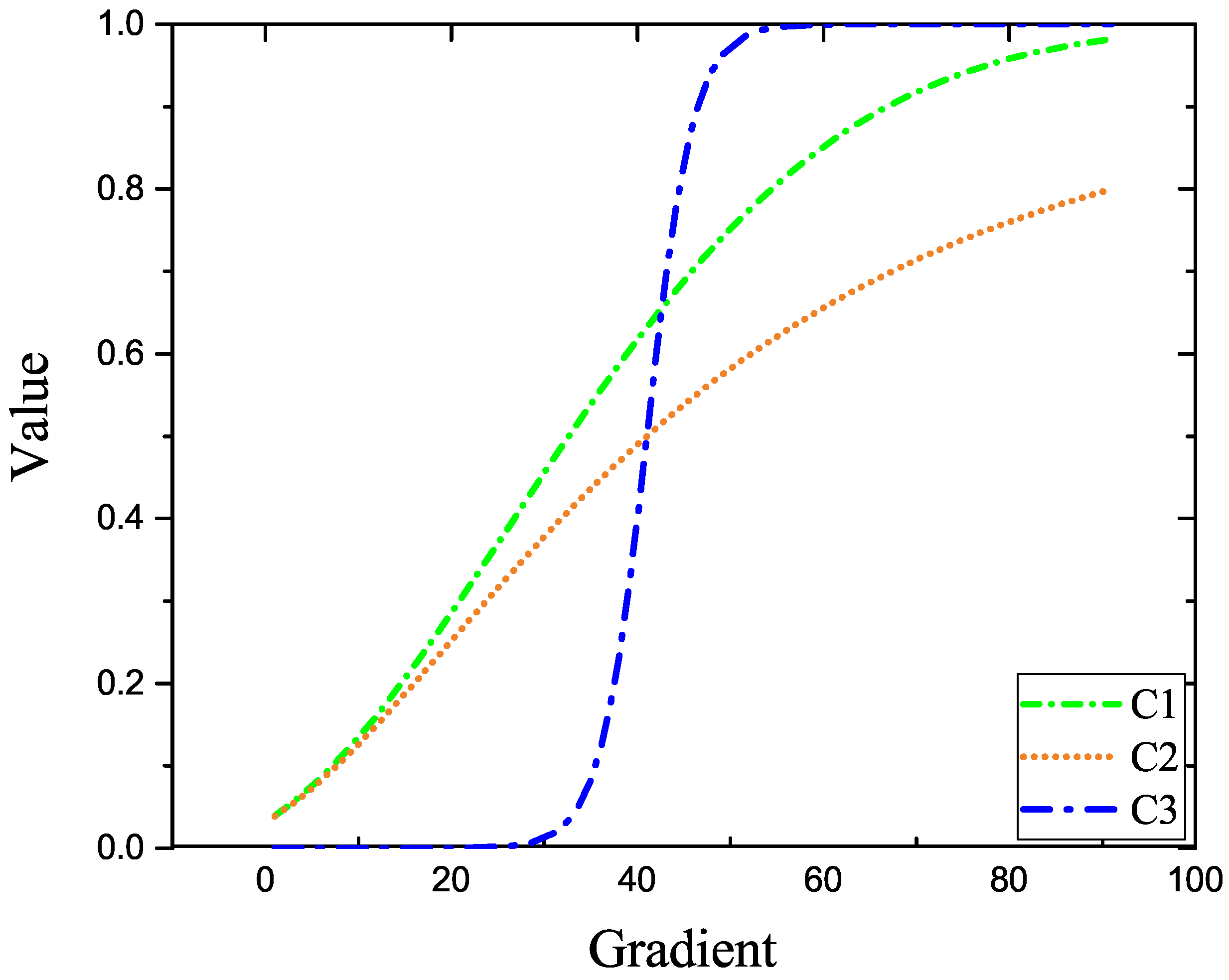
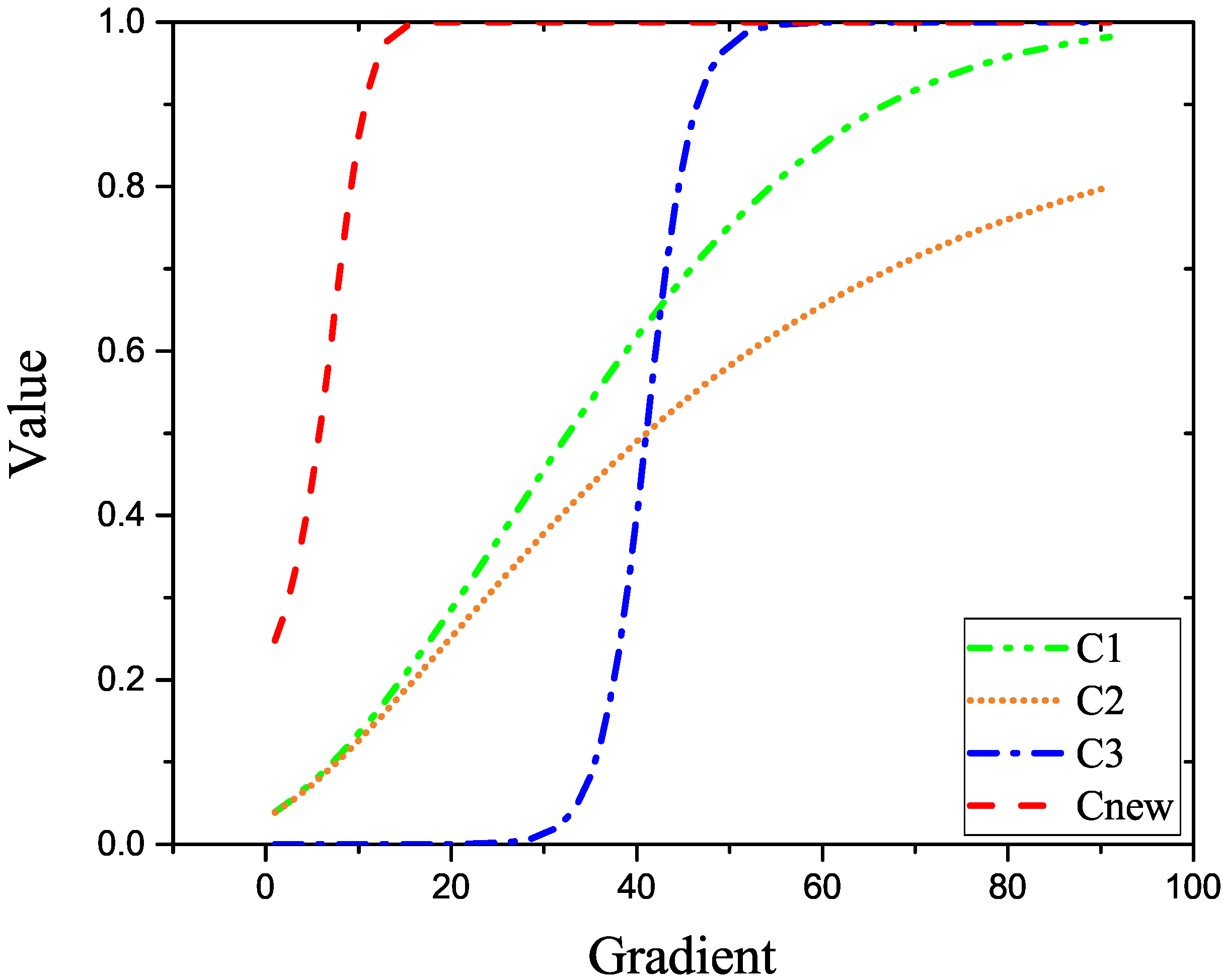
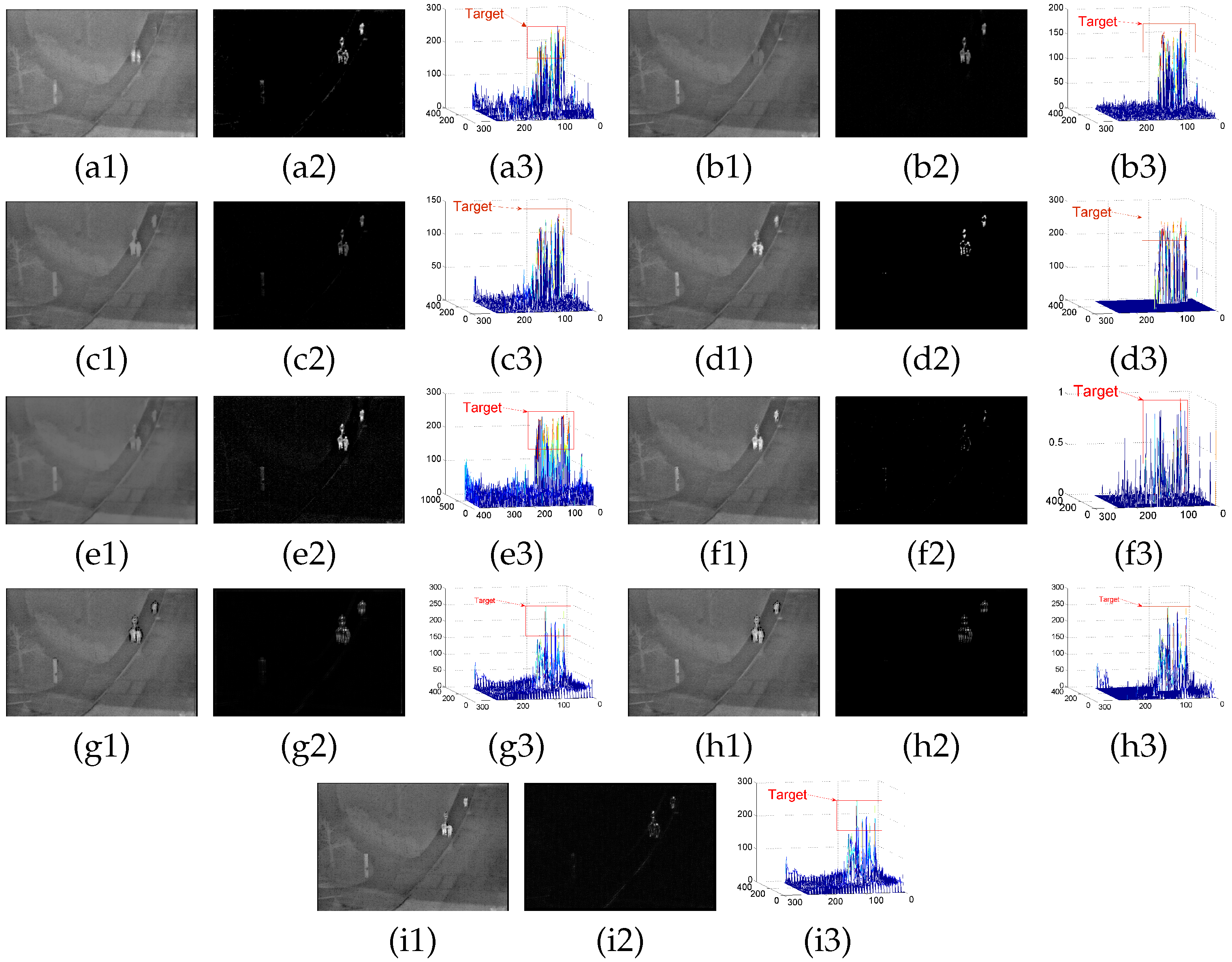
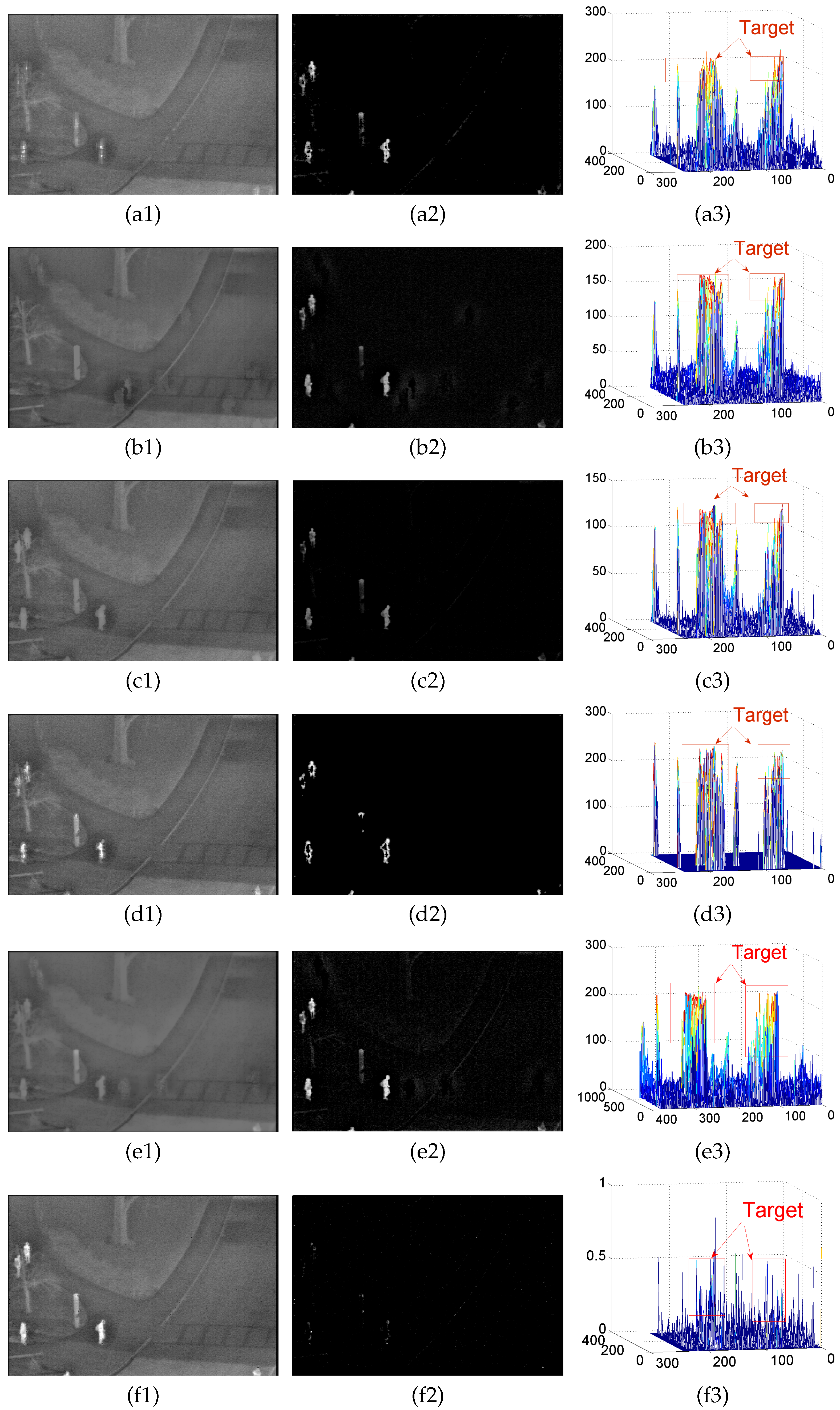
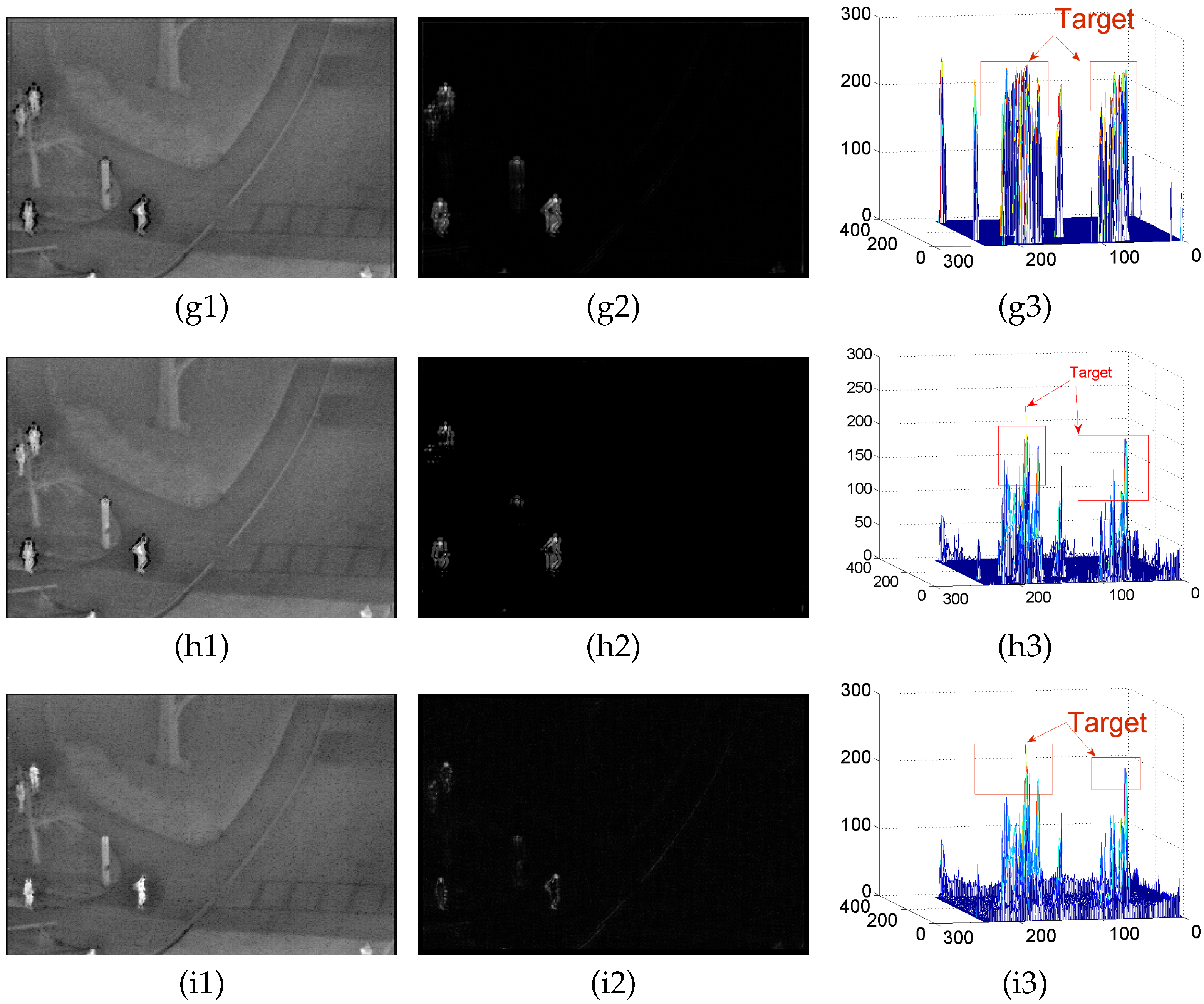
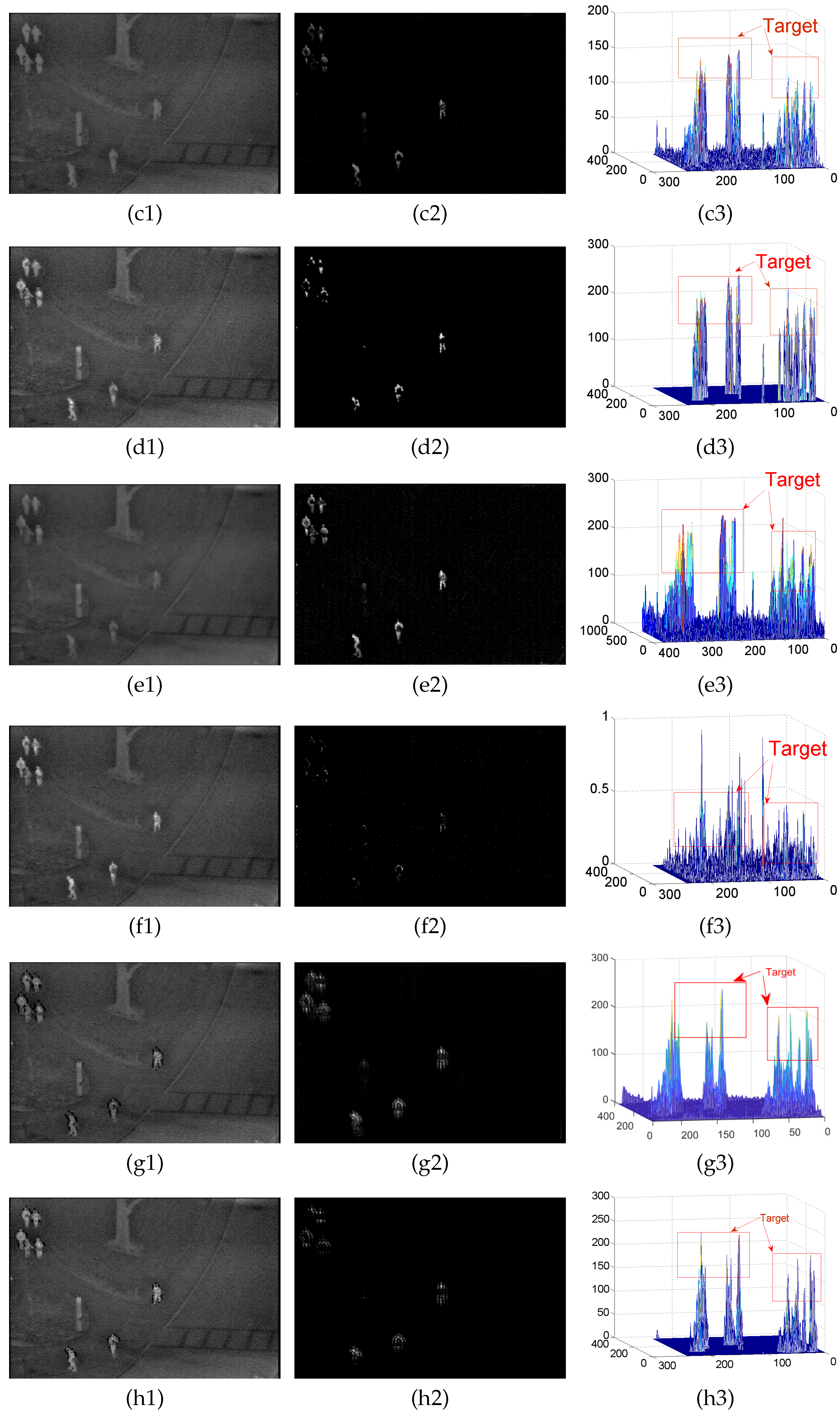
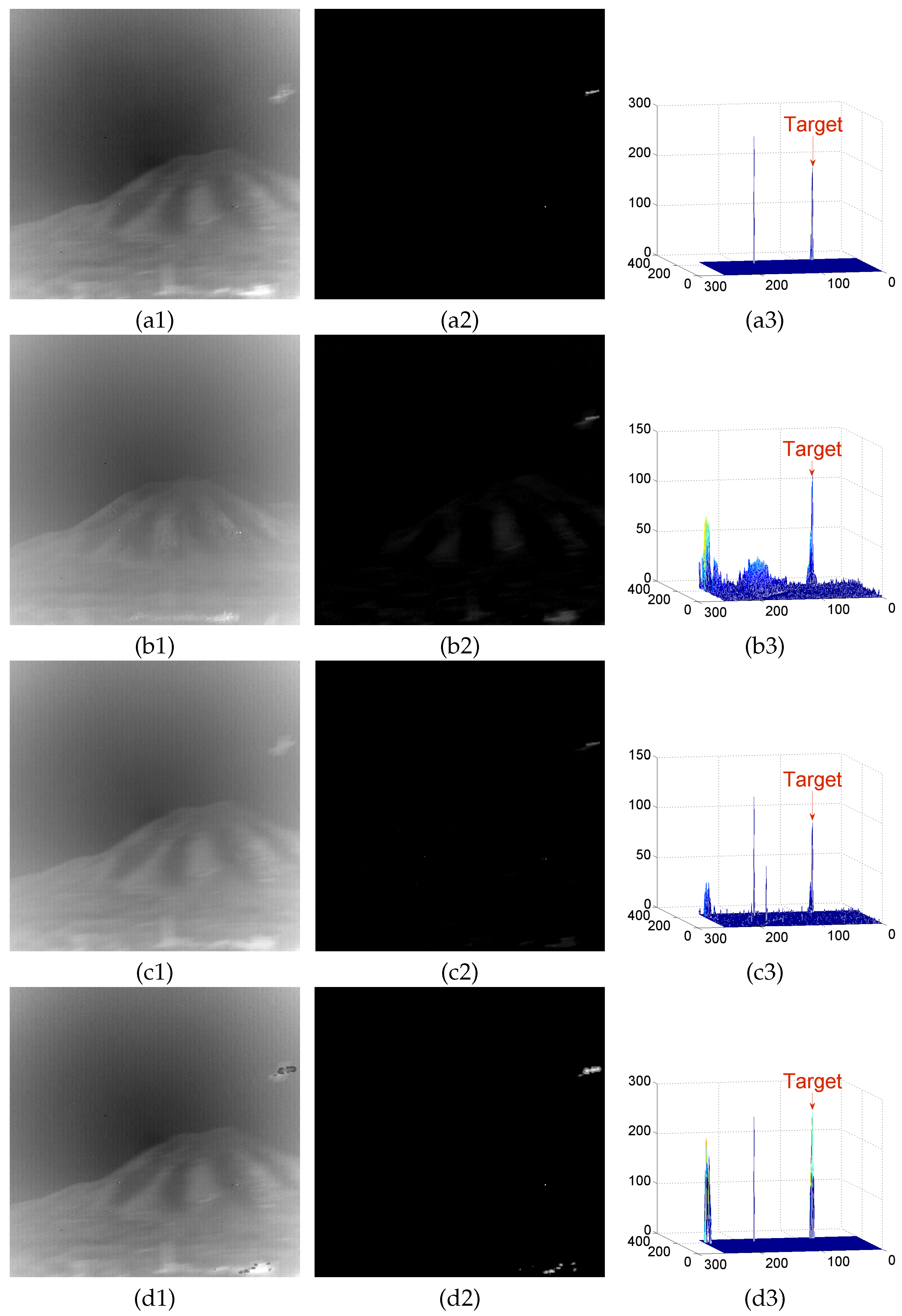
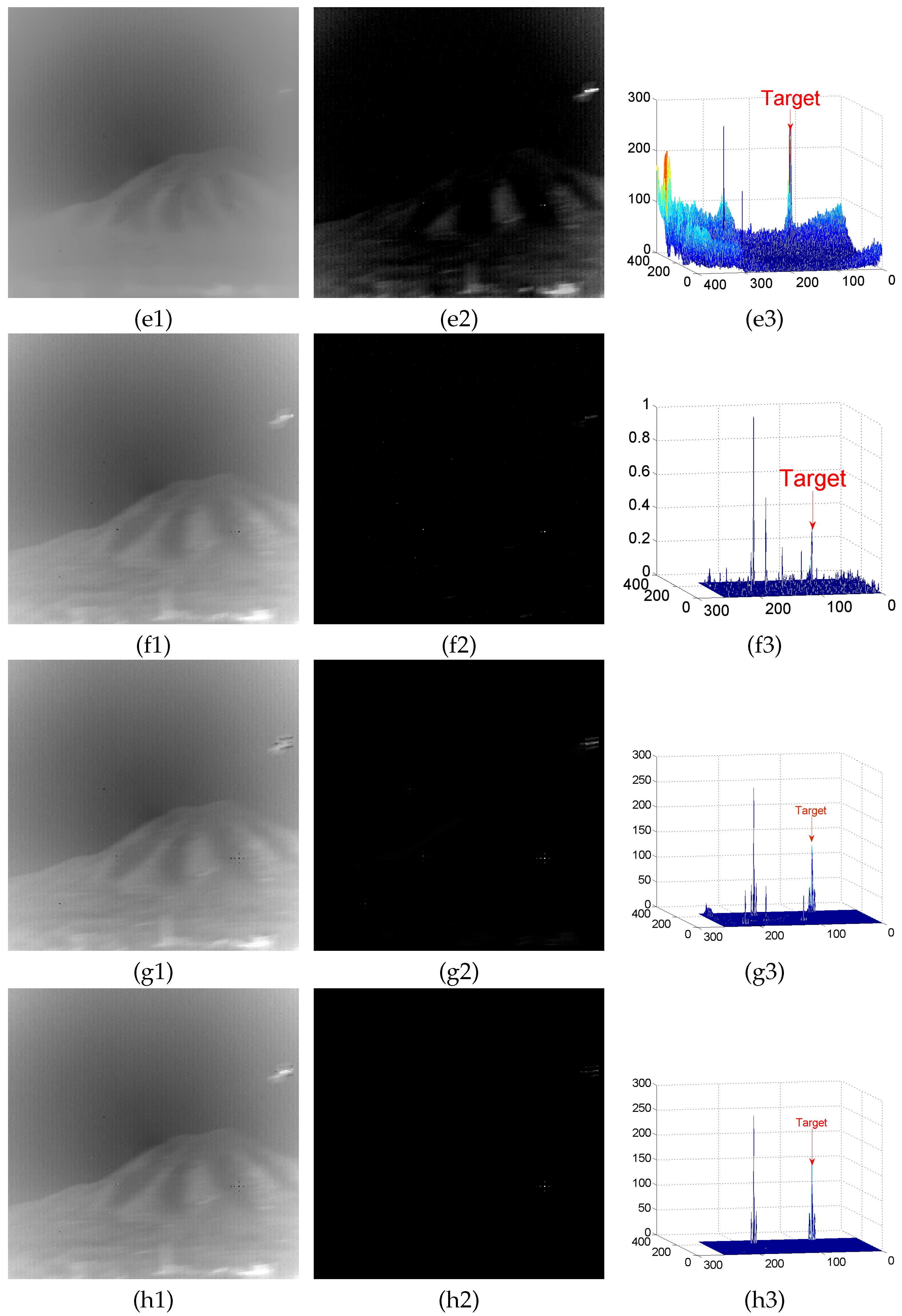
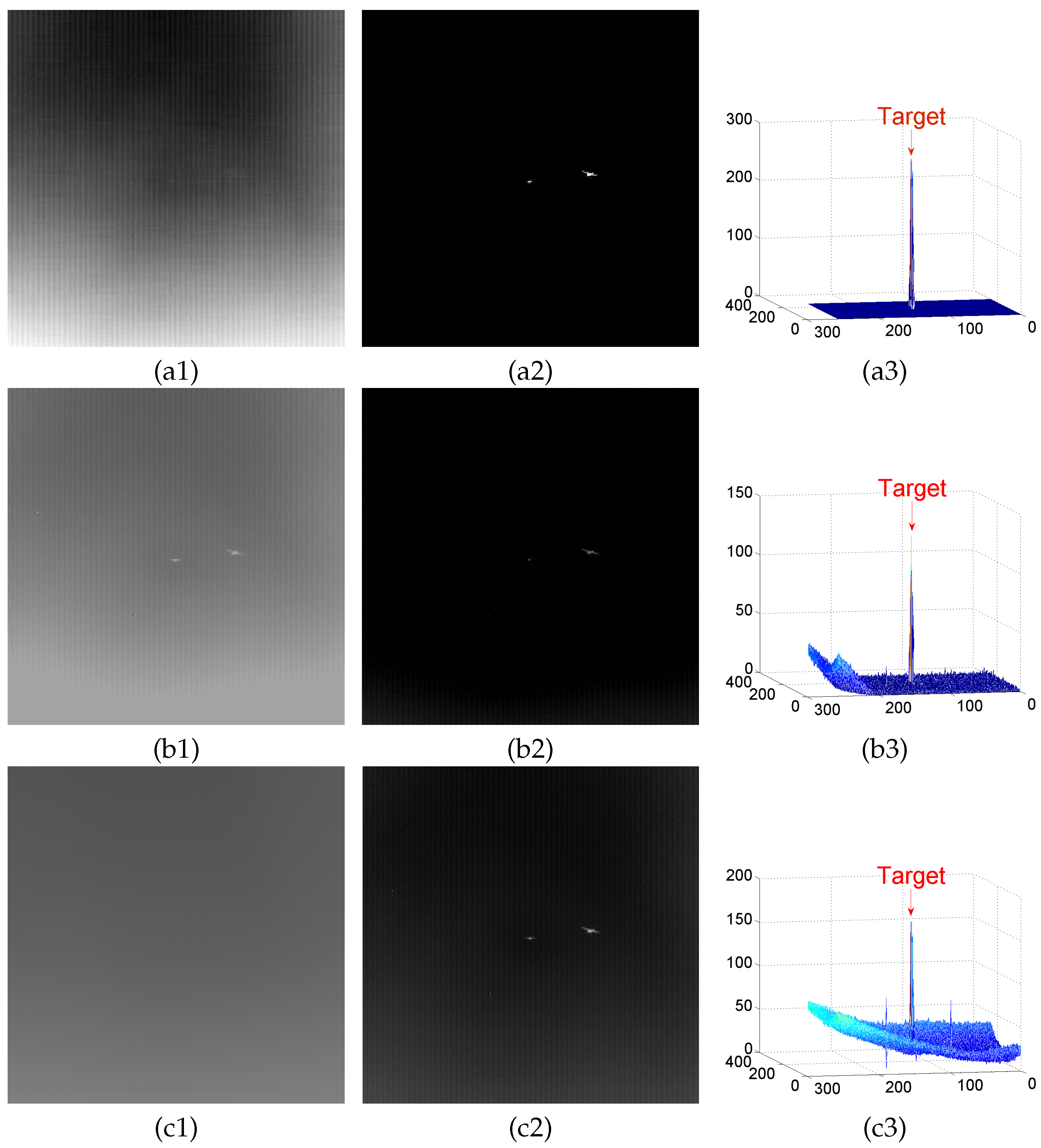
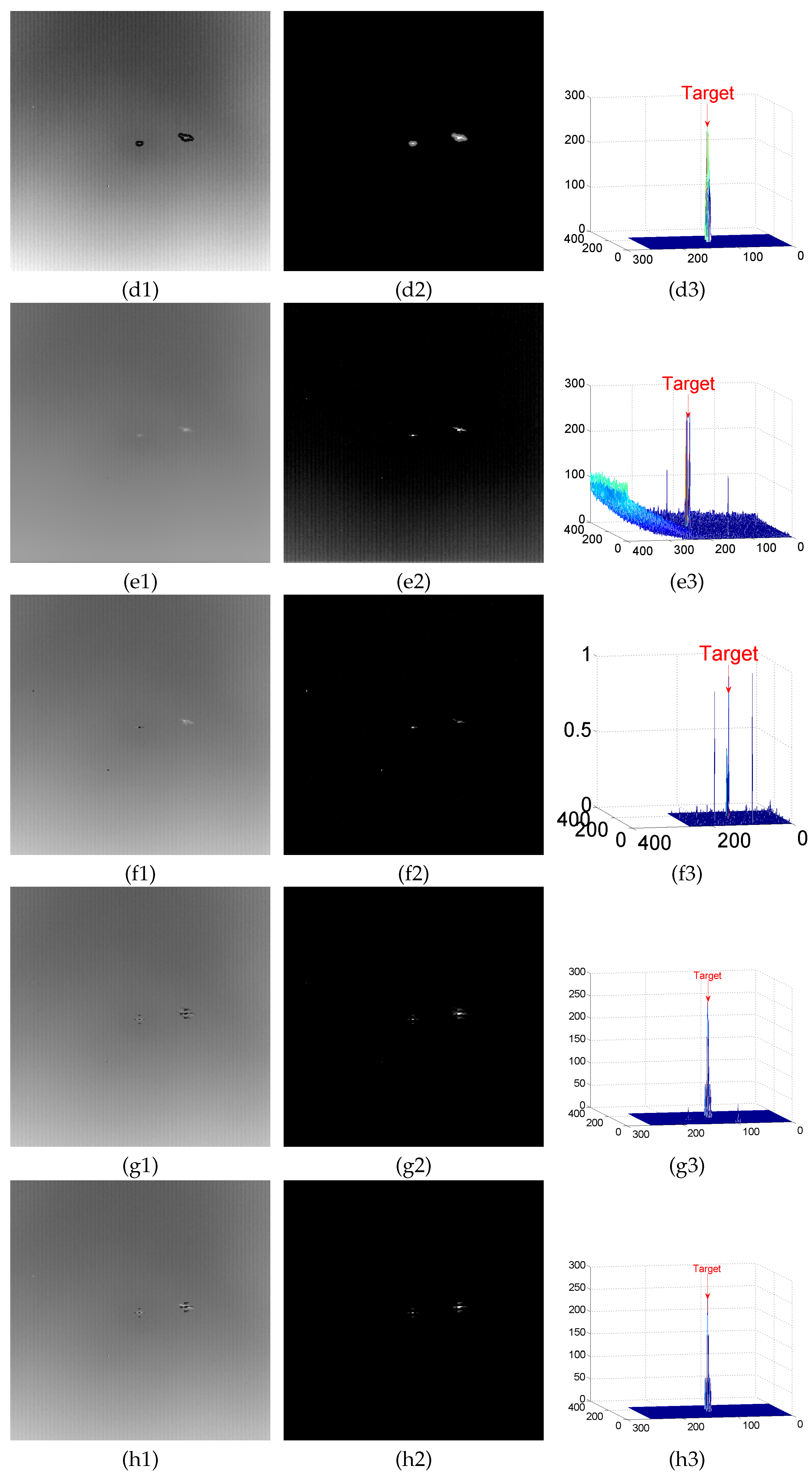
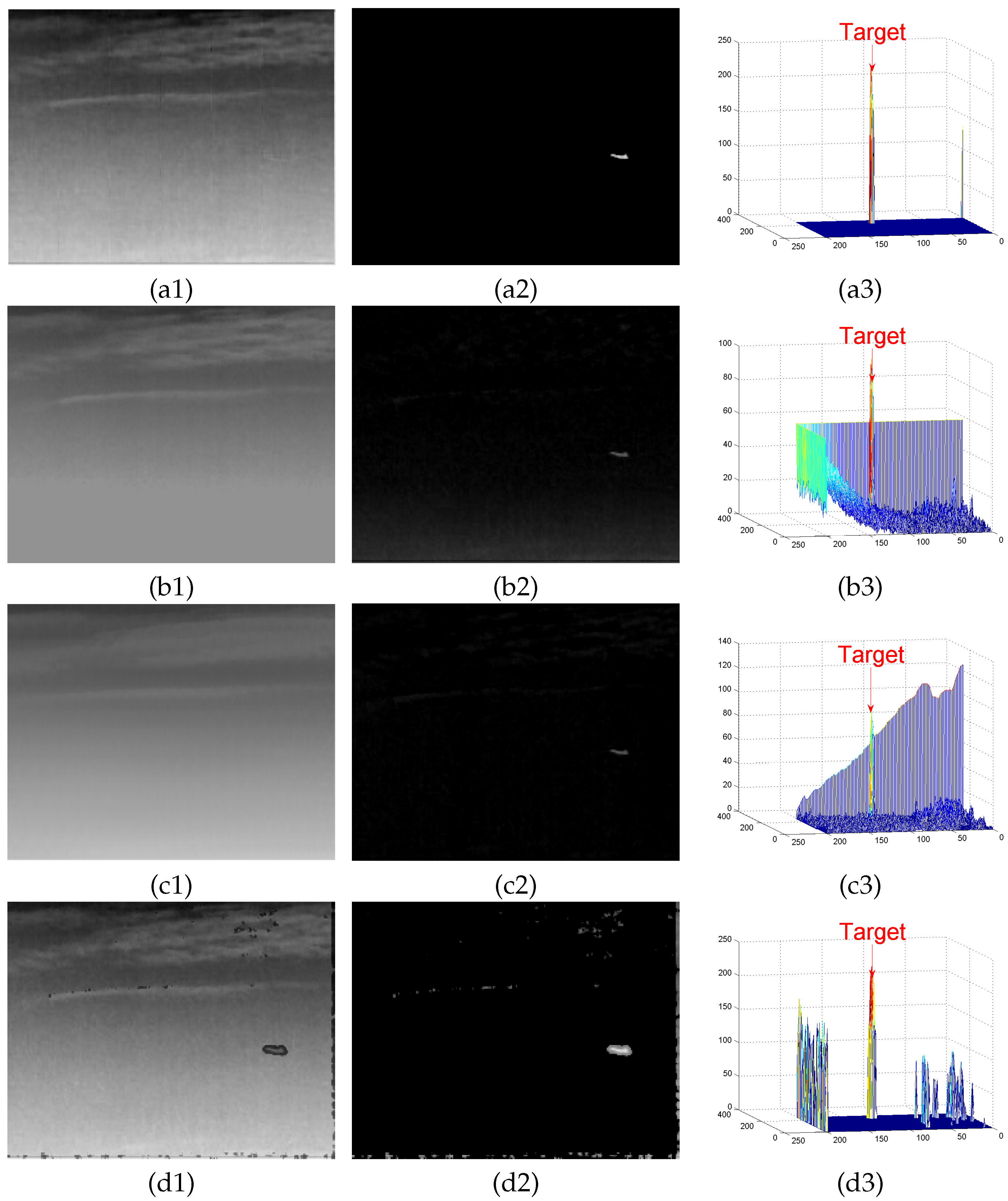
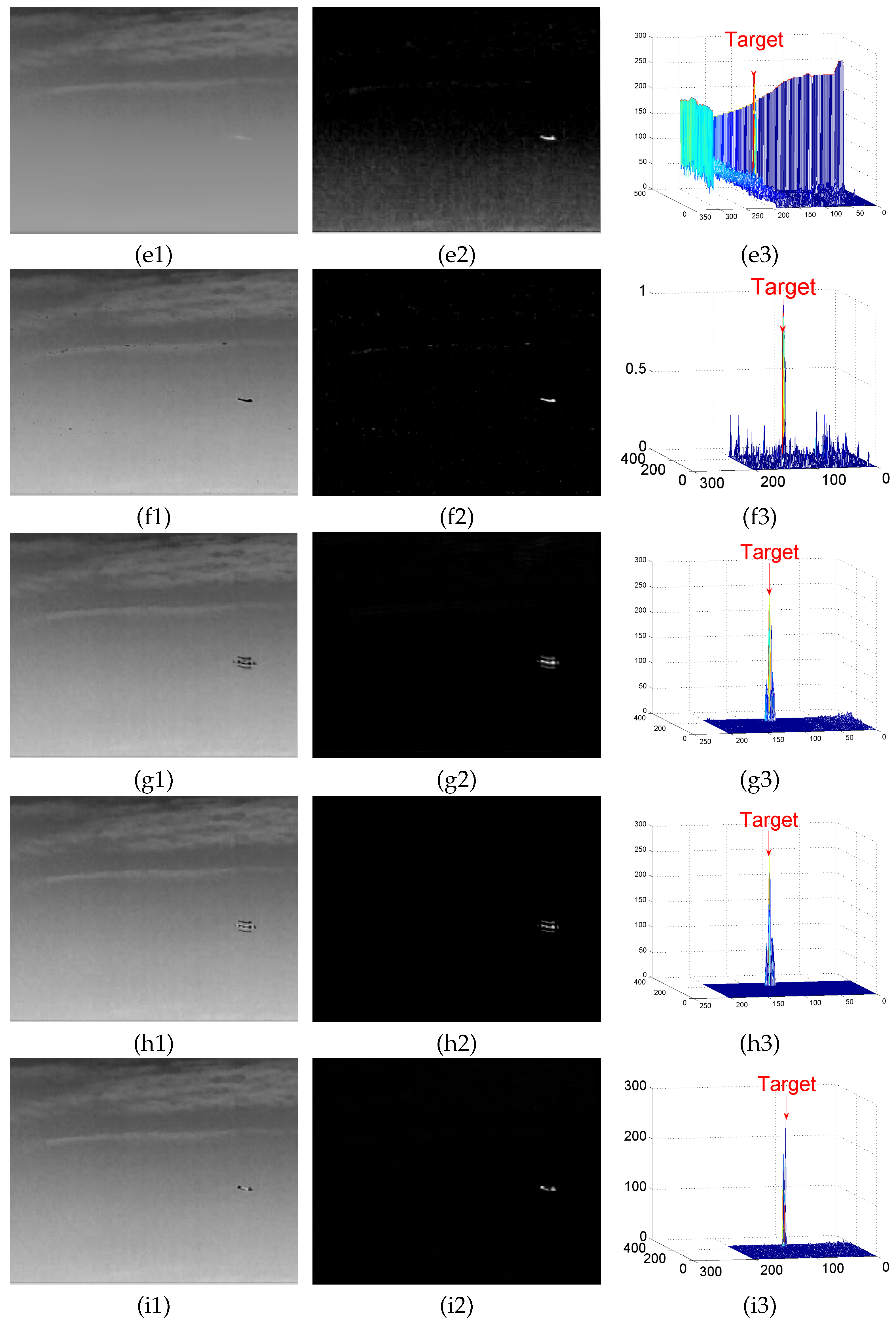
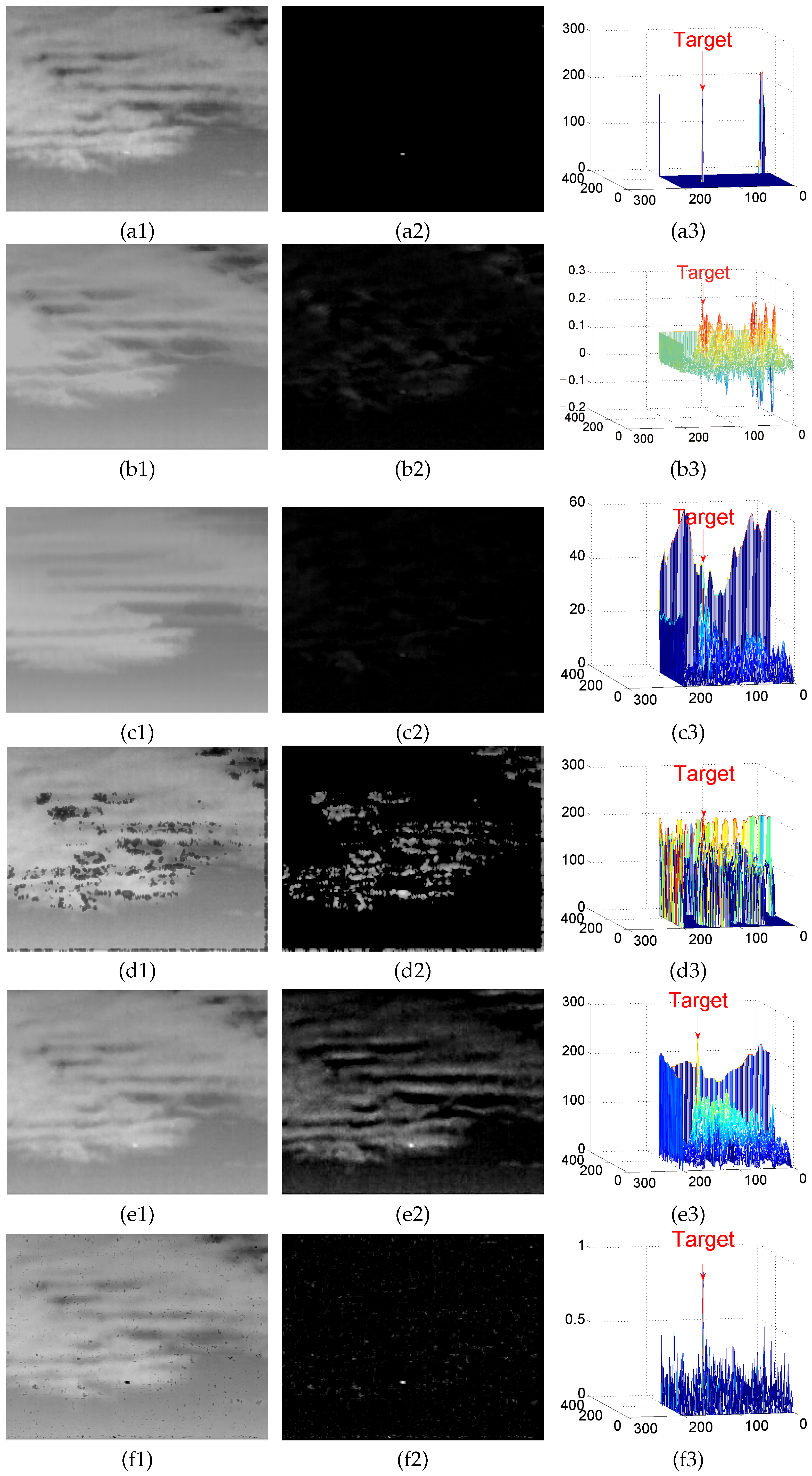
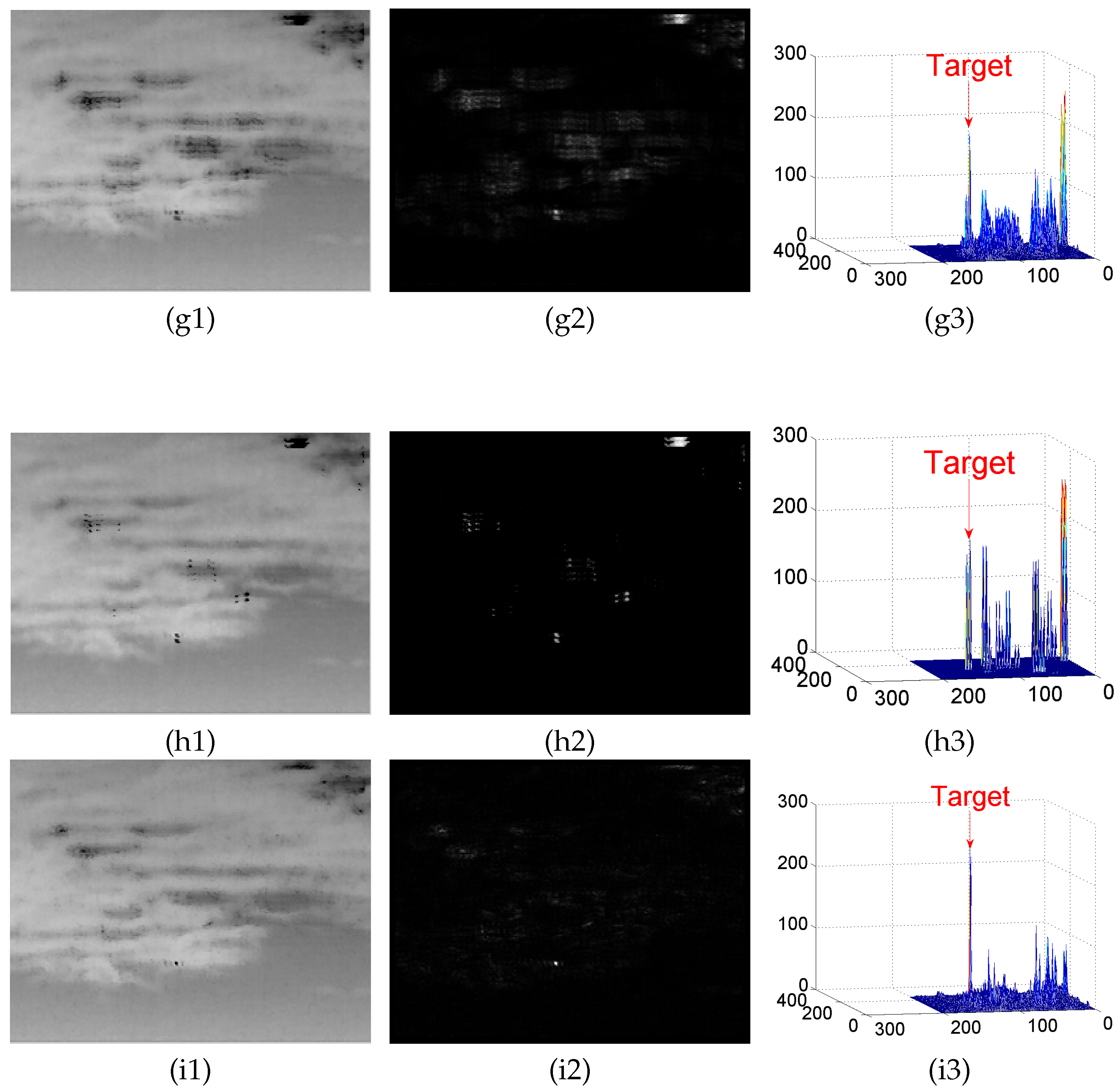
4.2. Background Modeling Results and Analysis
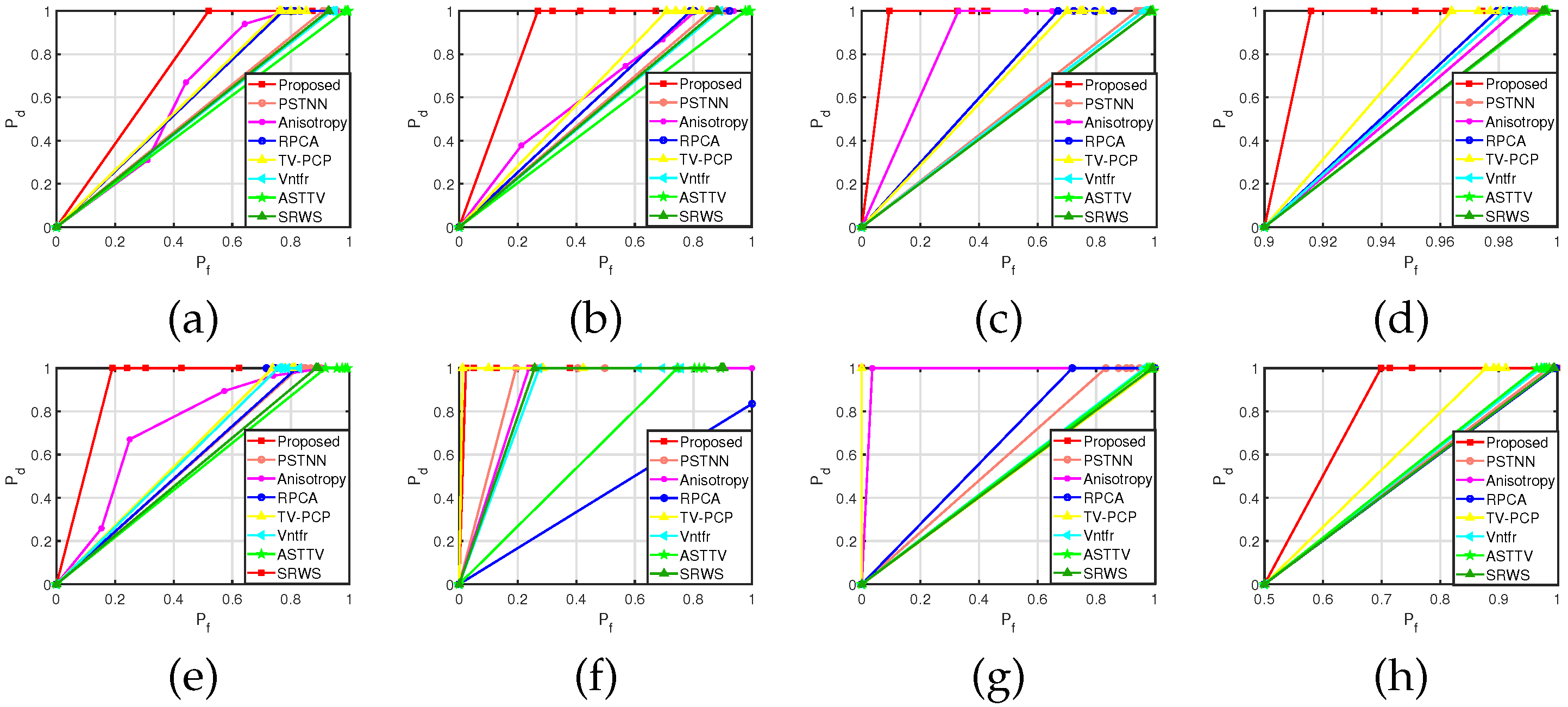
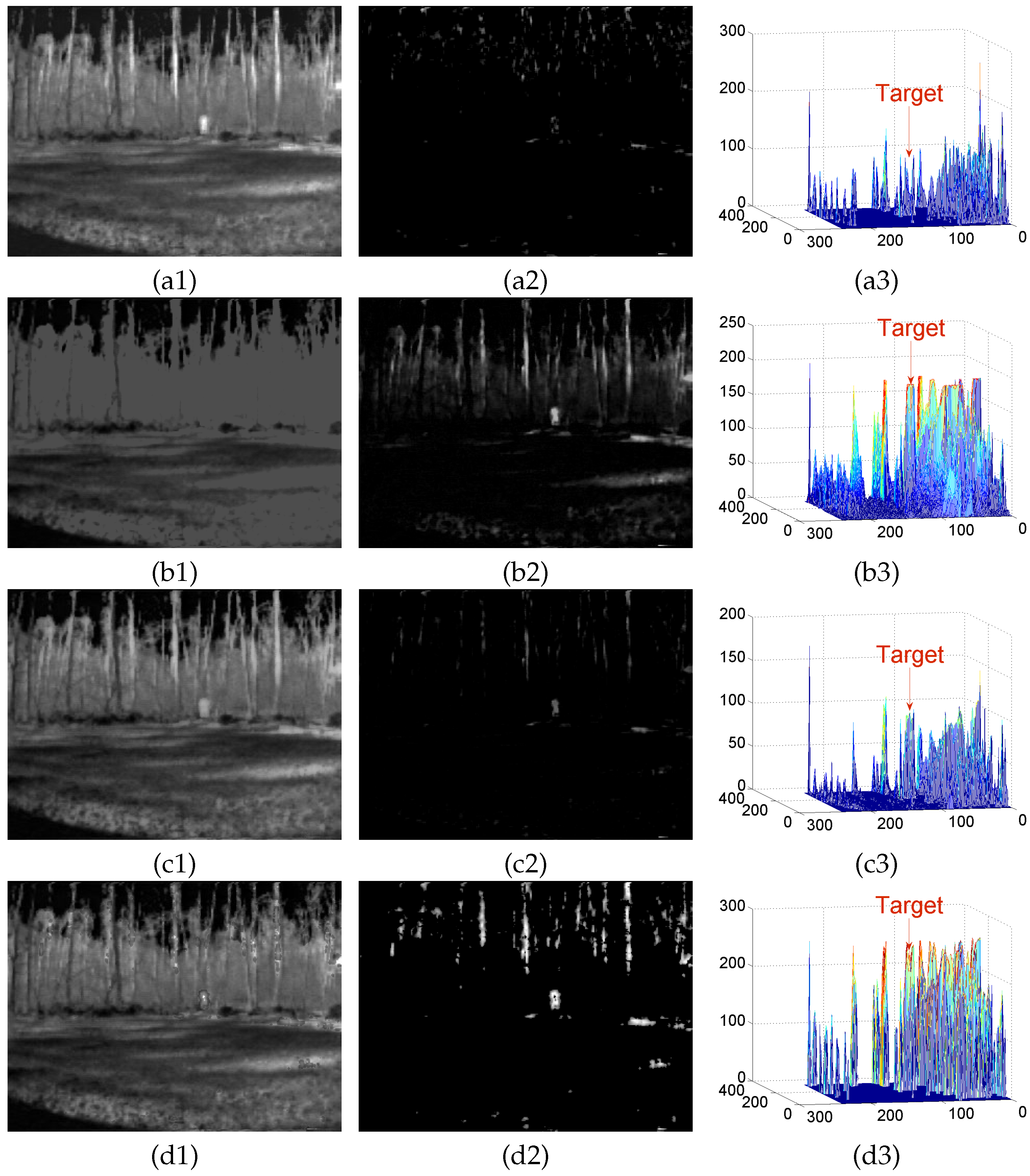
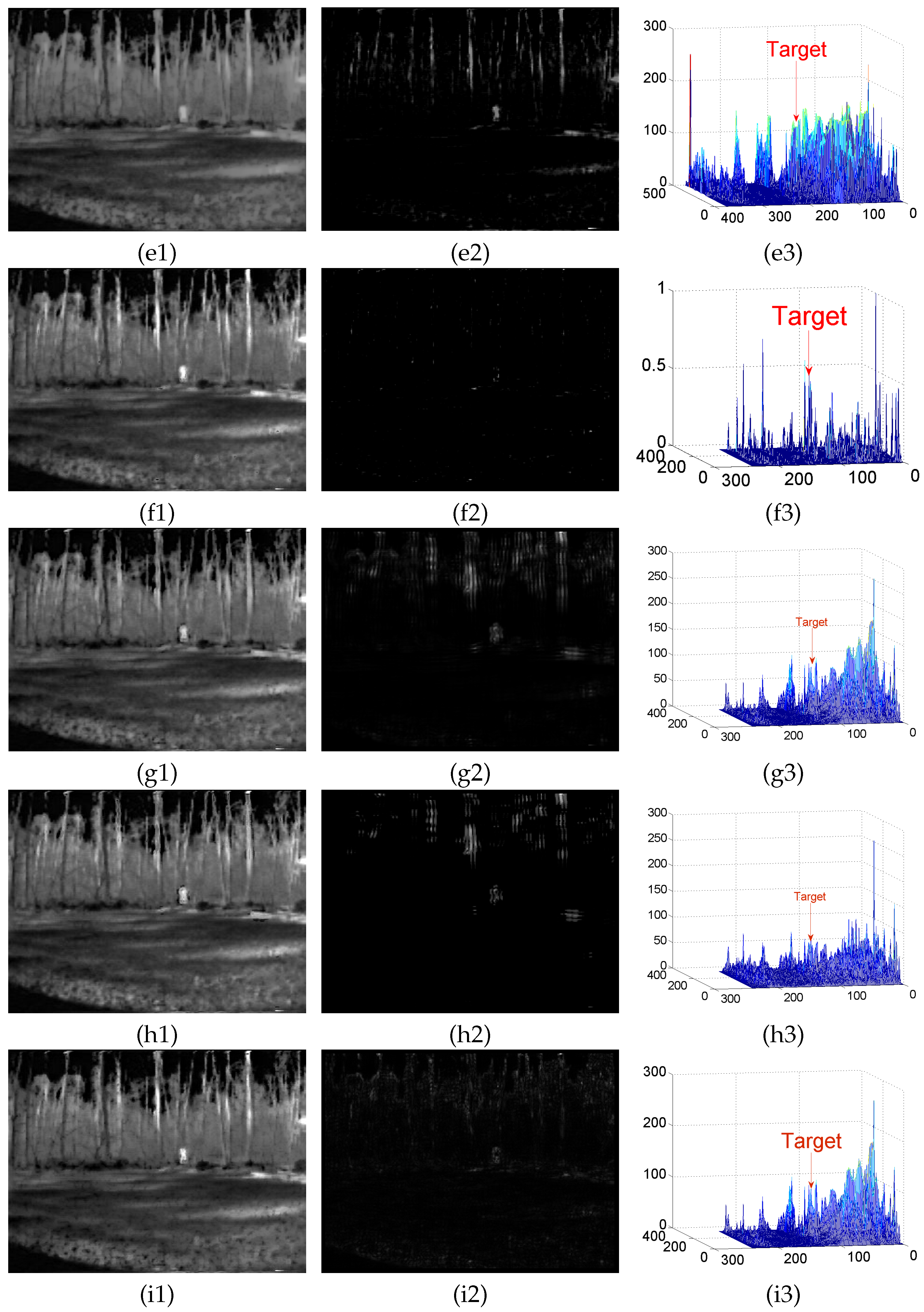
4.3. Detection Results
5. Conclusions and Future Direction
5.1. Conclusions
5.2. Future Direction
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VNTFR | Via Nonconvex Tensor Fibered Rank |
| PSTNN | Partial Sum of the Tensor Nuclear Norm |
| RPCA | Robust Principal Component Analysis |
| TV-PSMSV | Total Variation Partial Sum Minimization of Singular Values |
| STFM | Spatial-Temporal Features Measure |
| TV-PCP | Total Variation regulation and Principal Component Pursuit |
| SRWS | Self-Regularized Weighted Sparse |
| ASTTV | Asymmetric Spatial-Temporal Total Variation |
Appendix A. Experimental Results
Appendix A.1. Results of Background Modeling Experiments

















Appendix A.2. Test Results







References
- Fan, X.; Guo, H.; Xu, Z.; Li, B. Dim and Small Targets Detection in Sequence Images Based on spatio-temporal Motion Characteristics. Math. Probl. Eng. 2020, 2020, 7164859. [Google Scholar]
- Li, Q.; Nie, J.; Qu, S. A small target detection algorithm in infrared image by combining multi-response fusion and local contrast enhancement. Opt.-Int. J. Light Electron. Opt. 2021, 241, 166919. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C. Infrared small-target detection using multiscale gray difference weighted image entropy. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 60–72. [Google Scholar] [CrossRef]
- Xiong, B.; Huang, X.; Wang, M. Local Gradient Field Feature Contrast Measure for Infrared Small Target Detection. IEEE Geosci. Remote. Sens. Lett. 2020, 18, 553–557. [Google Scholar] [CrossRef]
- Fan, X.; Xu, Z.; Zhang, J.; Huang, Y.; Peng, Z.; Wei, Z.; Guo, H. Dim small target detection based on high-order cumulant of motion estimation. Infrared Phys. Technol. 2019, 99, 86–101. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Zhu, L.; Zhang, Z.; Chen, Z.; Li, X.; Wang, Y.; Tian, Y.; Wu, F. VisEvent: Reliable Object Tracking via Collaboration of Frame and Event Flows. arXiv 2021, arXiv:2108.05015. [Google Scholar]
- Gao, X.; Hui, L.I.; Zhang, Y.; Yan, M.; Zhang, Z.; Sun, X.; Sun, H.; Hongfeng, Y.U. Vehicle Detection in Remote Sensing Images of Dense Areas Based on Deformable Convolution Neural Network. J. Electron. Inf. Technol. 2018, 40, 2812–2819. [Google Scholar]
- Hu, G.; Yang, Z.; Han, J.; Huang, L.; Gong, J.; Xiong, N. Aircraft detection in remote sensing images based on saliency and convolution neural network. Eurasip J. Wirel. Commun. Netw. 2018, 2018, 26. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Wang, Z.M.; Yang, X.M.; Gu, X.F. Small Target Detection in a Single Infrared Image Based on RPCA. Acta Armamentarii 2016, 37, 1753. [Google Scholar]
- Wang, X.; Peng, Z.; Kong, D.; Zhang, P.; He, Y. Infrared dim target detection based on total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Wu, A.; Fan, X.; Chen, H.; Min, L.; Xu, Z. Infrared Dim and Small Target Detection Algorithm Combining Multiway Gradient Regularized Principal Component Decomposition Model. IEEE Access 2022, 10, 36057–36072. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Dai, Y.; Ni, K. Robust Infrared Small Target Detection via Jointly Sparse Constraint of l1/2-Metric and Dual-Graph Regularization. Remote Sens. 2020, 12, 1963. [Google Scholar] [CrossRef]
- Rawat, S.S.; Alghamdi, S.; Kumar, G.; Alotaibi, Y.; Khalaf, O.I.; Verma, L.P. Infrared Small Target Detection Based on Partial Sum Minimization and Total Variation. Mathematics 2022, 10, 671. [Google Scholar] [CrossRef]
- Mu, J.; Rao, J.; Chen, R.; Li, F. Low-Altitude Infrared Slow-Moving Small Target Detection via Spatial-Temporal Features Measure. Sensors 2022, 22, 5136. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted Infrared Patch-Tensor Model With Both Nonlocal and Local Priors for Single-Frame Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Peng, Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef] [Green Version]
- Guan, X.; Zhang, L.; Huang, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Tensor Rank Surrogate Joint Local Contrast Energy. Remote Sens. 2020, 12, 1520. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, H.; Liu, Y.; Peng, L.; Yang, C.; Peng, Z. Infrared Small Target Detection Based on Non-Convex Optimization with Lp-Norm Constraint. Remote Sens. 2019, 11, 559. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Yang, J.; Long, Y.; An, W. Infrared Small Target Detection via Spatial-Temporal Total Variation Regularization and Weighted Tensor Nuclear Norm. IEEE Access 2019, 7, 56667–56682. [Google Scholar] [CrossRef]
- Fang, H.; Chen, M.; Liu, X.; Yao, S. Infrared Small Target Detection with Total Variation and Reweighted Regularization. Math. Probl. Eng. 2020, 2020, 1529704. [Google Scholar] [CrossRef] [Green Version]
- Ling, Q.; Huang, S.; Wu, X.; Zhong, Y. Infrared small target detection based on kernel anisotropic diffusion. High Power Laser Part. Beams 2015, 27, 93–98. [Google Scholar]
- Zhou, H.X.; Zhao, Y.; Qin, H.L.; Yin, S.M.; Rong, S.H. Infrared Dim and Small Target Detection Algorithm Based on Multi-scale Anisotropic Diffusion Equation. Acta Photonica Sin. 2015, 44, 146–150. [Google Scholar]
- Chen, M. Fast convex optimization algorithms for exact recovery of a corrupted low-rank matrix. J. Mar. Biol. Assoc. UK 2009. Available online: https://people.eecs.berkeley.edu/~yima/matrix-rank/Files/rpca_algorithms.pdf (accessed on 27 June 2022).
- Cai, J.; Candes, E.J.; Shen, Z. A Singular Value Thresholding Algorithm for Matrix Completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Cao, Z.; Kong, X.; Zhu, Q.; Cao, S.; Peng, Z. Infrared dim target detection via mode-k1k2 extension tensor tubal rank under complex ocean environment. ISPRS J. Photogramm. Remote Sens. 2021, 181, 167–190. [Google Scholar] [CrossRef]
- Kong, X.; Yang, C.; Cao, S.; Li, C.; Peng, Z. Infrared Small Target Detection via Nonconvex Tensor Fibered Rank Approximation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5000321. [Google Scholar] [CrossRef]
- Liu, T.; Yang, J.; Li, B.; Xiao, C.; Sun, Y.; Wang, Y.; An, W. Non-Convex Tensor Low-Rank Approximation for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5614718. [Google Scholar]
- Tz, A.; Zp, A.; Hao, W.A.; Yh, A.; Cl, B.; Cy, A. Infrared small target detection via self-regularized weighted sparse model–ScienceDirect. Neurocomputing 2021, 420, 124–148. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Target Size | Image Size | Number of Scene Frames | Target Motion Description |
|---|---|---|---|---|
| Scene A | 20 × 20 | 360 × 240 | 30 | Multiple pedestrian movements on campus |
| Scene B | 20 × 20 | 360 × 240 | 18 | Multiple pedestrian movements on campus |
| Scene C | 20 × 20 | 360 × 240 | 18 | Multiple pedestrian movements on campus |
| Scene D | 20 × 20 | 320 × 240 | 103 | Multiple pedestrian movements on campus |
| Scene E | 15 × 15 | 256 × 256 | 88 | Large aircraft moving in low altitude complex background |
| Scene F | 5 × 5, 3 × 3 | 256 × 256 | 599 | Large aircraft moving in low altitude complex background |
| Scene G | 7 × 7 | 256 × 256 | 30 | Large aircraft moving in low altitude complex background |
| Scene H | 5 × 5 | 256 × 256 | 28 | Large aircraft moving in low altitude complex background |
| Method | Evaluation Indicators | SeqA | SeqB | SeqC | SeqD | SeqE | SeqF | SeqG | SeqH |
|---|---|---|---|---|---|---|---|---|---|
| PSTNN [17] | SSIM | 0.8929 | 0.9643 | 0.8007 | 0.9643 | 0.9707 | 0.7127 | 0.9479 | 0.9704 |
| BSF | 16.3978 | 44.5755 | 14.5276 | 44.5755 | 99.984 | 78.191 | 81.58 | 60.2096 | |
| IC | 1.7549 | 4.4669 | NaN | 4.4669 | 9.7552 | 10.77 | 46.7006 | NaN | |
| RPCA [10] | SSIM | 0.8992 | 0.743 | 0.8457 | 0.743 | 0.9807 | 0.9814 | 0.906 | 0.9035 |
| BSF | 22.7456 | 17.3042 | 18.9079 | 17.3042 | 51.09 | 53.682 | 26.6465 | 23.1095 | |
| IC | 1.7333 | 1.8644 | 52.0959 | 1.8644 | 12.037 | 7.9779 | 9.5817 | 39.1915 | |
| TV-PCP [11] | SSIM | 0.9418 | 0.9825 | 0.9118 | 0.9825 | 0.998 | 0.7412 | 0.9848 | 0.8935 |
| BSF | 31.1774 | 55.5603 | 26.0405 | 55.5603 | 157.32 | 18.67 | 57.7783 | 24.4123 | |
| IC | 1.2946 | 2.5605 | 51.9887 | 2.5605 | 12.429 | 3.3153 | 15.9996 | 465.7584 | |
| VNTFRA [27] | SSIM | 0.9733 | 0.9251 | 0.9599 | 0.9251 | 0.9784 | 0.8536 | 0.9281 | 0.6475 |
| BSF | 19.259 | 13.9744 | 17.4709 | 13.9744 | 45.428 | 43.729 | 19.4073 | 5.4145 | |
| IC | 3.9947 | 2.7721 | NaN | 2.7721 | 20.881 | 0.9476 | 8.0377 | 350.5143 | |
| ASTTV [28] | SSIM | 0.838 | 0.8154 | 0.8533 | 0.9684 | 0.928 | 0.927 | 0.9386 | 0.7944 |
| BSF | 12.026 | 11.953 | 13.809 | 22.861 | 13.07 | 13.54 | 11.482 | 5.8283 | |
| IC | 19.931 | 25.002 | 113.28 | 2.3377 | 17.1 | 11.07 | 13.4227 | 3.9597 | |
| SRWS [29] | SSIM | 0.9707 | 0.9832 | 0.9647 | 0.9965 | 0.999 | 0.996 | 0.991 | 0.9298 |
| BSF | 40.144 | 53.383 | 36.94 | 118.64 | 184.2 | 113 | 73.5345 | 25.2542 | |
| IC | 3.8509 | 3.8715 | 52.096 | 3.6856 | 52.01 | 12.9 | 46.0748 | 218.8171 | |
| C2 [22] | SSIM | 0.9096 | 0.8929 | 0.8756 | 0.9594 | 0.9967 | 0.9933 | 0.9922 | 0.9155 |
| BSF | 22.9123 | 21.6956 | 20.2689 | 33.5829 | 122.63 | 86.64 | 79.1137 | 19.9491 | |
| IC | 1.9262 | 1.417 | 16.0295 | 2.5389 | 6.501 | 3.9545 | 3.7964 | 81.1303 | |
| C3 [23] | SSIM | 0.9239 | 0.9135 | 0.9339 | 0.9594 | 0.9971 | 0.995 | 0.995 | 0.9594 |
| BSF | 24.3321 | 23.942 | 26.7567 | 32.2585 | 132.31 | 99.797 | 98.9412 | 22.7394 | |
| IC | 1.477 | 1.4636 | NaN | 4.5367 | 11.957 | 7.5737 | 12.8887 | NaN | |
| Proposed | SSIM | 0.9827 | 0.9889 | 0.9685 | 0.9819 | 0.9989 | 0.9962 | 0.9965 | 0.9774 |
| BSF | 53.8529 | 68.4012 | 41.3969 | 57.6583 | 211.49 | 115.01 | 114.9036 | 45.1366 | |
| IC | 4.175 | 3.5205 | 10.4192 | 8.776 | 12.375 | 12.915 | 29.4573 | 70.1029 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, E.; Wu, A.; Li, J.; Chen, H.; Fan, X.; Huang, Q. Infrared Target Detection Based on Joint Spatio-Temporal Filtering and L1 Norm Regularization. Sensors 2022, 22, 6258. https://doi.org/10.3390/s22166258
Xu E, Wu A, Li J, Chen H, Fan X, Huang Q. Infrared Target Detection Based on Joint Spatio-Temporal Filtering and L1 Norm Regularization. Sensors. 2022; 22(16):6258. https://doi.org/10.3390/s22166258
Chicago/Turabian StyleXu, Enyong, Anqing Wu, Juliu Li, Huajin Chen, Xiangsuo Fan, and Qibai Huang. 2022. "Infrared Target Detection Based on Joint Spatio-Temporal Filtering and L1 Norm Regularization" Sensors 22, no. 16: 6258. https://doi.org/10.3390/s22166258