
Decentralized Personal Data Marketplaces: How Participation in a DAO Can Support the Production of Citizen-Generated Data


Abstract
:1. Introduction
- Are decentralized personal data marketplaces able to optimally support individuals’ personal data protection and portability?
- How can decentralized technologies foster a convergence between the protection of individuals’ personal data and the development of data aggregation solutions?
Contributions
- First, we provide a description of the implementation of a decentralized personal data marketplace, where
- Our PDS is implemented using a DFS for storing personal data;
- We use a DLT for providing data integrity, validation and indexing;
- Our smart contract-based authorization system executes distributed data access control;
- Our hypercube DHT enables a decentralized way of searching for data in DLTs.
In particular, we provide a detailed description of the protocols behind the authorization blockchain and the hypercube DHT. - Second, we provide the implementation of a use case for the architecture through the description of citizen-generated data creation based on direct participation. This consists of the development of a data aggregation solution through the use of a DAO, where members are citizens.
- Third, we evaluate the implementation’s performance by means of an experimental evaluation. More specifically, (i) we simulate a P2P network executing the hypercube DHT for decentralized search of data, (ii) we test the distributed data access control execution for the use case and (iii) we evaluate the smart contract implementation in terms of gas usage.
2. Background
2.1. Distributed Hash Table (DHT)
2.2. Decentralized File Storage (DFS)
2.3. Distributed Ledger Technology (DLT)
2.4. Smart Contract and Decentralized Autonomous Organization (DAO)
2.5. IOTA and Streams
2.6. Proxy Re-Encryption (PRE) and Cryptographic Threshold Schemes
3. Related Works
3.1. Decentralized Data Marketplace
3.2. Decentralized Access Control
3.3. Decentralized Data Search
3.4. Decentralized Personal Data Management
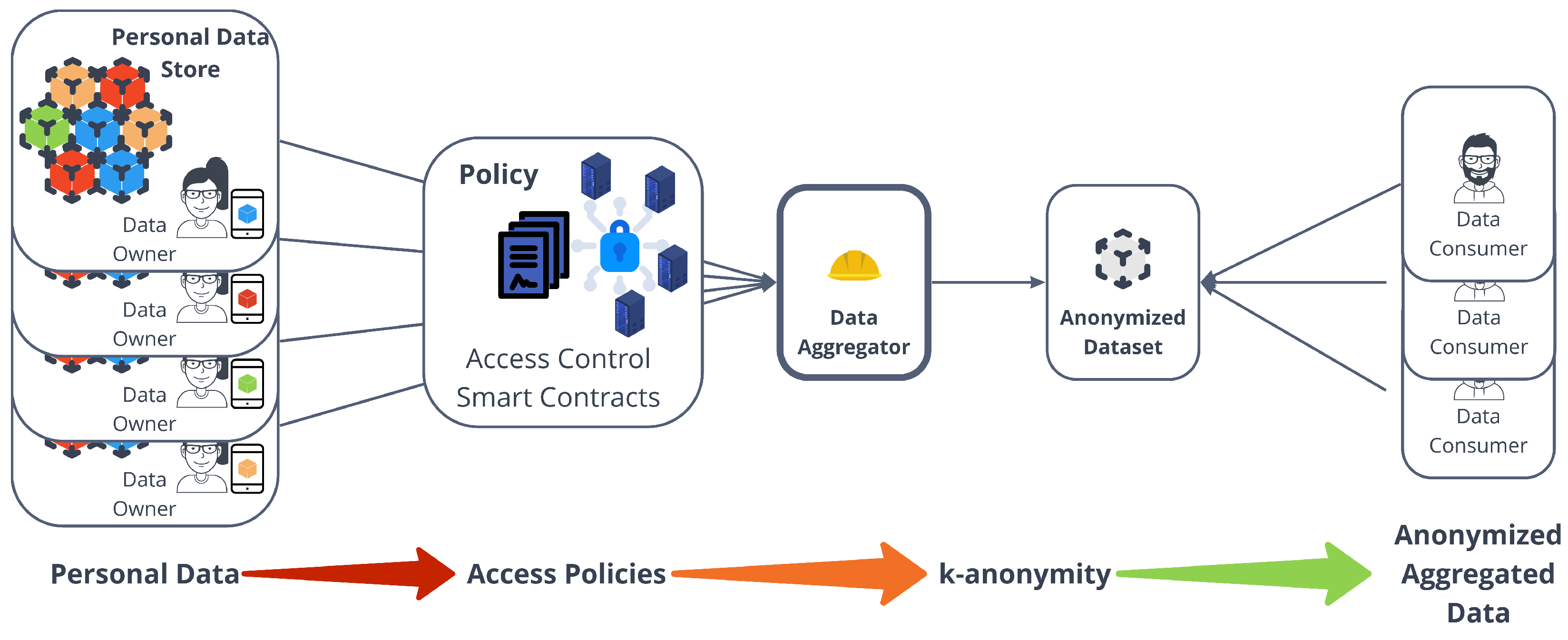
4. Decentralized Personal Data Marketplace Architecture
- A Decentralized File Storage (DFS) is used to store personal data in an encrypted form and to create immutable universal identifiers that directly represent the content of a piece of data. This kind of system is used to take advantage of the property of high data availability that is often taken for granted in centralized file storages.
- Smart contracts are used to provide decentralized access control mechanisms that can be leveraged by data consumers to access data retrieved from the DFS, following a policy indicated by the data owner (e.g., access through payment).
- A Distributed Ledger Technology (DLT) is used to enable the data indexing and validation. The ledger’s untamperability property makes sure that data integrity can be validated by storing data’s immutable universal identifiers, specifically in the form of hash pointers. Moreover, related pieces of data can be already linked and indexed in this layer.
- An hypercube-structured Distributed Hash Table (DHT) is used to provide a distributed mechanism for the search of data. This system is in charge of associating keywords to addresses or references stored in the DLT.
4.1. DFS-Based Personal Data Store
4.2. Smart Contract-Based Distributed Access Control
4.2.1. Access Mechanism
- Keypairs—each actor creates a set of asymmetric keypairs, e.g., the data owner creates (, ) while the data consumer creates (, ).
- Capsule—a capsule is created by the data owner for each piece of data stored in the DFS. Recall that the content key k is used for encrypting the piece of data. Then, the result of the encryption of k results in the capsule.
- Re-encryption key—The re-encryption key is created by the data owner for each data consumer through the public key .
- Kfrags—The data consumer divides the re-encryption key into n fragments following the -threshold scheme. The single re-encryption key fragments are unique for each authorization blockchain node. We call these key fragments “kfrags” for simplicity.
- Cfrags—Each authorization blockchain node receives the same capsule and a unique kfrag. The capsule cannot be “opened” because it is encrypted with the data owner’s public key. Only one kfrag (or a number less than t) cannot be used to completely re-encrypt the capsule in such a way that the data consumer can open the capsule. The authorization blockchain node only performs a re-encryption operation that takes as input the capsule and the unique kfrags, and it outputs a new capsule fragment, “cfrag”. The data consumer requires at least t cfrags to reconstruct the new capsule and to decrypt it with the private key .
4.3. DLT Indexing and Validation
Layer-2 Solution
4.4. Hypercube-Structured DHT
4.4.1. Keyword-Based Complex Queries
4.4.2. Multiple Keywords Search
- Pin Search—this procedure aims at obtaining all and only the objects associated exactly with a keyword set K, i.e., . Upon request, the responsible node returns to the requester all the announcement links of the corresponding objects that it keeps in its table associated with K.
- Superset Search—this procedure is similar to the previous one, but it also searches for objects that can be described by keyword sets that include K, i.e., . Since the possible outcomes of this search can be quite large, a limit l is set.
4.4.3. The Query Routing Mechanism
| Algorithm 1: Query Routing Mechanism |
 |
5. -DaO Use Case: Participatory Data Stewardship and Citizen-Generated Data Creation
5.1. Anonymizing Data by Aggregation
5.2. Step Zero: Search Data on the Decentralized Marketplace
5.3. Smart Contracts Implementing the Distributed Access Control
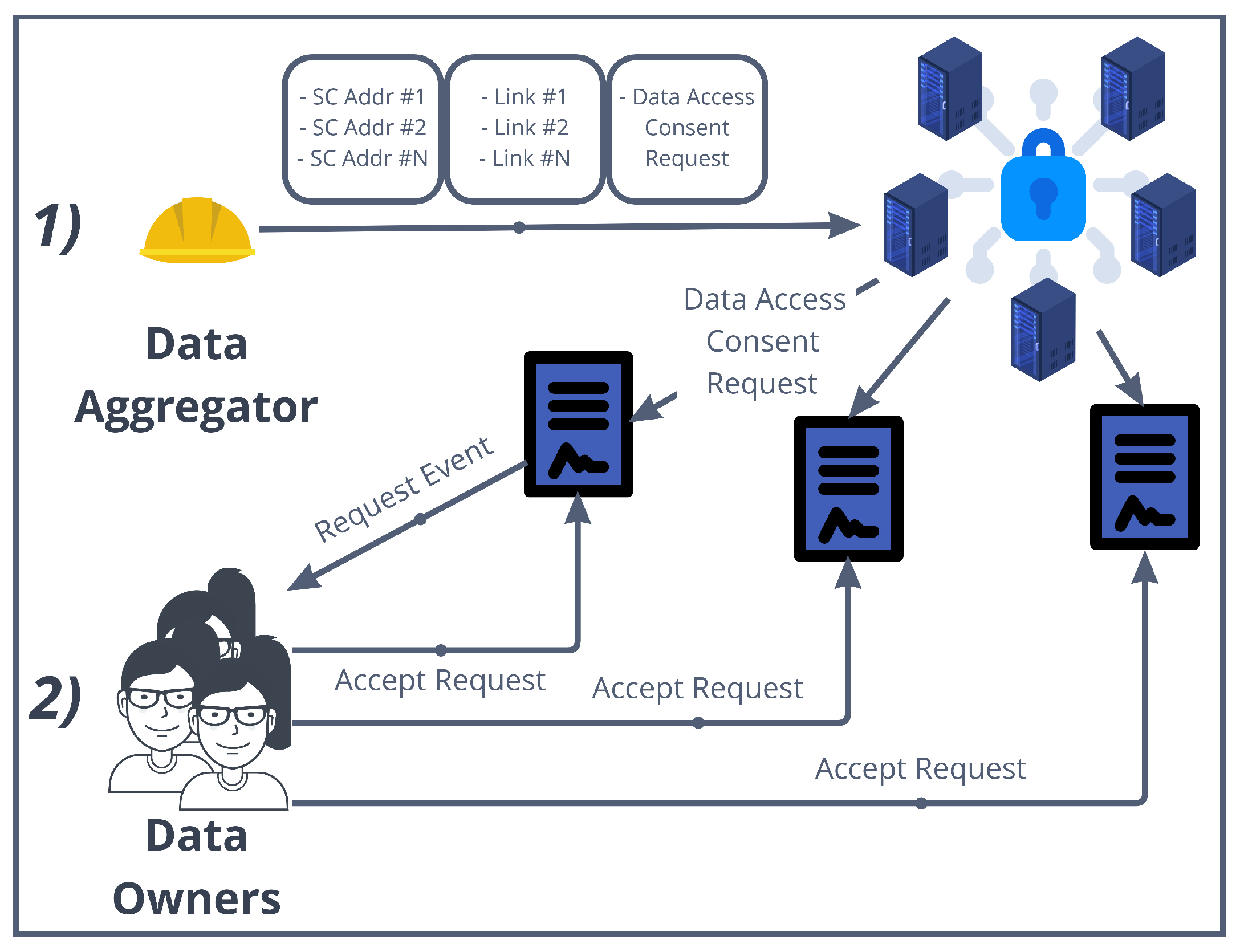
- Each data owner has previously deployed a DataOwnerContract in the authorization blockchain. The data aggregator too has previously deployed an AggregatorContract.
- In the “step zero”, the aggregator has obtained a list of DataOwnerContract addresses that point to IOTA stream channels through as many announcement links. Then, they produce a data access consent request in a string form for such data (the use of standardized models for the consent request, such as W3C recommended ontologies, is left as future work).
- The aggregator gives these three pieces of information as inputs to the requestAccessToData() method in the AggregatorContract(), together with a series of parameters needed for the k-DaO (shown in the next subsection). This method implements, in only one blockchain transaction, the request to access data for each DataOwnerContract found as input. In particular, the method requestAccess() is invoked for each DataOwnerContract, with the associated announcement link and request as input (Figure 6 shows id_ as parameter representing the link and an array of addresses users for representing the Ethereum accounts that will be granted access).
- A NewRequest event will reach each data owner. This one decides to consent to the access to data based on the data access consent request received through the event. If so, the data owner invokes the grantAccessRequest() method in the DataOwnerContract.
- Among the parameters set in requestAccessToData(), m was set as the minimum number of members needed to create the k-DaO and to start the data aggregation process. It is also the minimum number of participants required to provide “reasonable” anonymity.
- The aggregator uses the checkKgtM() method to check if the number k of data owners that granted the access to their data is greather than m. When this happens, the aggregator can create the k-DaO through the createkDaO() method that instantiates a new kDaO contract.
- The aggregator can now access all content keys for the decryption of all the data owners’ data through the authorization blockchain nodes, as described in Section 4.2.1.
5.4. Smart Contracts Implementing the k-DaO
- A kDaO contract is created for each aggregation process. The AggregationContract acts as a contract factory but implementing a proxy pattern (EIP-1167 Minimal Proxy [72]). Instead of deploying a new contract each time such as in the factory pattern, this implementation clones an already deployed contract functionalities by delegating all methods invocation to it.
- Some DAO parameters were already set up during the request data access process, such as the amount the aggregator stakes. When the kDaO contract is created, a transfer of an amount of ERC20 tokens [73], i.e., the kDaOToken, is performed automatically from the aggregator account to the kDaO contract. At the end of the aggregation process, the aggregator can redeem this stake if all operations have been successful.
- k-DaO members can call for a vote and then decide on a proposal. Any member can make a proposal using the submitProposal() method, and for that proposal, all members can submit a suggestion using submitSuggestion(). Then, all members vote on a suggestion regarding that proposal. For instance, a proposal could be to “Change anonymization technique”, and some suggestions could be “Differential privacy” or “k-anonymity”. Each proposal has their own debate period and any member can invoke vote() to vote for a suggestion within that time period. After the debate period, the method executeProposal() counts the votes, if minQuorum is reached, then it stores the result and possibly enacts a specific procedure.
- Indeed, any extension of the previous voting smart contract can be developed to allow for a decision taken to directly enact an operation to be executed on-chain. In this case, submitRefundProposal() specifically starts a vote to take the data aggregator’s staked amount and to redistribute it to all members. In this case, executeProposal() would subdivide the staked amount to all the members if the proposal is passed.
- The kDaOToken is central in the DAO, as it also allows members to vote. Indeed, a member vote weight is proportional to the amount of tokens locked until a date that comes after the debate period ends. This is performed in order to avoid malicious data owners unreasonably voting to redeem the aggregator stake. A TokenTimelockUpgreadable is used for each token lock. This is created using the proxy pattern as well.
5.5. Anonymized Aggregated Dataset
6. Performance Evaluation
6.1. Hypercube DHT Simulation
6.1.1. Tests Setup
6.1.2. Results
Pin Search
Superset Search
6.1.3. Discussion
6.2. Authorization Blockchain Performances
6.2.1. Test Setup
- Request Access—this operation is executed by the data aggregator and consists of only one method invocation, i.e., the requestAccessToData() method in the AggregatorContract; we recall that this method requests access to data for each DataConsumerContract given as input.
- Grant Access—this operation is executed by each data owner by invoking the grantAccessRequest() from their own DataConsumerContract(); this will store the aggregator public key in the smart contract ACL.
- Create KFrags—this operation includes three subsequent steps; first, the owner generates a new set of n kfrags using the data aggregator’s (as described in Section 4.2.1); then, the owner sends a kfrag each to the n authorization blockchain nodes; finally, the owner requests to the n nodes the creation of a cfrag using the kfrag just got (the capsule for the piece of data interested was sent in a pre-processing step, not accounted for the measuring).
- Get CFrags—the last operation is executed by the data aggregator to obtain access to the content key; the aggregator first sign a challenge-response message using the secret key associated to the ; then, the aggregator sends a Get CFrag request to k authorization blockchain nodes using the signed message; and each node validates the signature and check if is in the associated ACL in the DataConsumerContract, and if so, each node returns a cfrag to the data aggregator.
6.2.2. Results
Round of Operations
System Throughput
Threshold Number
6.2.3. Discussion
6.3. Smart Contract Gas Usage
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| ACL | Access Control List |
| CFrag | Capsule Fragment |
| CID | Content Identifier |
| DAG | Directed Acyclic Graph |
| DAO | Decentralized Autonomous Organization |
| DFS | Decentralized File Storage |
| DHT | Distributed Hash Table |
| DLT | Distributed Ledger Technology |
| GDPR | General Data Protection Regulation |
| IBFT | Istanbul Byzantine Fault-Tolerant |
| IPFS | InterPlanetary File System |
| KFrag | Key Fragment |
| P2P | Peer-to-Peer |
| PIMS | Personal Information Management System |
| PDS | Personal Data Store |
| PRE | Proxy Re-Encryption |
| SSI | Self-Sovereign Identity |
| TPRE | Threshold Proxy Re-Encryption |
| UML | Universal Modeling Language |
| W3C | World Wide Web Consortium |
References
- Cadwalladr, C.; Graham-Harrison, E. Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach. Guardian 2018, 17, 22. [Google Scholar]
- Patel, R. Participatory Data Stewardship; Technical Report; Ada Lovelace Institute: London, UK, 2021. [Google Scholar]
- Prandi, C.; Mirri, S.; Ferretti, S.; Salomoni, P. On the need of trustworthy sensing and crowdsourcing for urban accessibility in smart city. ACM Trans. Internet Technol. 2017, 18, 1–21. [Google Scholar] [CrossRef]
- Floridi, L. The fight for digital sovereignty: What it is, and why it matters, especially for the EU. Philos. Technol. 2020, 33, 369–378. [Google Scholar] [CrossRef] [PubMed]
- Ramachandran, G.S.; Radhakrishnan, R.; Krishnamachari, B. Towards a Decentralized Data Marketplace for Smart Cities. In Proceedings of the 2018 IEEE International Smart Cities Conference (ISC2), Kansas City, MO, USA, 16–19 September 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Zichichi, M.; Ferretti, S.; D’Angelo, G. A Framework based on Distributed Ledger Technologies for Data Management and Services in Intelligent Transportation Systems. IEEE Access 2020, 8, 100384–100402. [Google Scholar] [CrossRef]
- High-Level Expert Group on Business-to-Government Data Sharing. Towards a European Strategy on Business-to-Government Data Sharing for the Public Interest; Technical Report; European Commission: Brussels, Belgium, 2021. [Google Scholar]
- Janssen, H.; Singh, J. Personal Information Management Systems. Internet Policy Rev. 2022, 11, 1–6. [Google Scholar] [CrossRef]
- Zichichi, M.; Ferretti, S.; D’Angelo, G.; Rodríguez-Doncel, V. Data Governance through a Multi-DLT Architecture in View of the GDPR. Clust. Comput. 2022, 1–32. [Google Scholar] [CrossRef]
- Yan, Z.; Gan, G.; Riad, K. BC-PDS: Protecting privacy and self-sovereignty through BlockChains for OpenPDS. In Proceedings of the 2017 IEEE Symposium on Service-Oriented System Engineering (SOSE), San Francisco, CA, USA, 6–9 April 2017; pp. 138–144. [Google Scholar]
- Crabtree, A.; Lodge, T.; Colley, J.; Greenhalgh, C.; Glover, K.; Haddadi, H.; Amar, Y.; Mortier, R.; Li, Q.; Moore, J.; et al. Building accountability into the Internet of Things: The IoT Databox model. J. Reliab. Intell. Environ. 2018, 4, 39–55. [Google Scholar] [CrossRef] [Green Version]
- Sambra, A.V.; Mansour, E.; Hawke, S.; Zereba, M.; Greco, N.; Ghanem, A.; Zagidulin, D.; Aboulnaga, A.; Berners-Lee, T. Solid: A Platform for Decentralized Social Applications Based on Linked Data; Technical Report; MIT CSAIL & Qatar Computing Research Institute: Cambridge, MA, USA, 2016. [Google Scholar]
- European Commission. A European Strategy for Data; European Union: Brussels, Belgium, 2020. [Google Scholar]
- European Commission. European Data Governance (Data Governance Act); European Union: Brussels, Belgium, 2020. [Google Scholar]
- Council of European Union. Regulation (eu) 2016/679—Directive 95/46; European Union: Brussels, Belgium, 2016. [Google Scholar]
- Kondova, G.; Erbguth, J. Self-sovereign identity on public blockchains and the GDPR. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 342–345. [Google Scholar]
- Park, J.S.; Youn, T.Y.; Kim, H.B.; Rhee, K.H.; Shin, S.U. Smart contract-based review system for an IoT data marketplace. Sensors 2018, 18, 3577. [Google Scholar] [CrossRef] [Green Version]
- Özyilmaz, K.R.; Doğan, M.; Yurdakul, A. IDMoB: IoT Data Marketplace on Blockchain. In Proceedings of the Crypto Valley Conference on Blockchain Technology (CVCBT), Zug, Switzerland, 20–22 June 2018. [Google Scholar]
- Ramsundar, B.; Chen, R.; Vasudev, A.; Robbins, R.; Gorokh, A. Tokenized Data Markets. arXiv 2018, arXiv:1806.00139. [Google Scholar]
- Benet, J. Ipfs-content addressed, versioned, p2p file system. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Popov, S. The Tangle. 2016. Available online: https://assets.ctfassets.net/r1dr6vzfxhev/2t4uxvsIqk0EUau6g2sw0g/45eae33637ca92f85dd9f4a3a218e1ec/iota1_4_3.pdf (accessed on 24 May 2022).
- Buterin, V. Ethereum White Paper. 2013. Available online: https://ethereum.org/en/whitepaper/ (accessed on 24 May 2022).
- Nunez, D. Umbral: A Threshold Proxy Re-Encryption Scheme; University of Malaga: Malaga, Spain, 2018. [Google Scholar]
- Joung, Y.J.; Yang, L.W.; Fang, C.T. Keyword search in dht-based peer-to-peer networks. IEEE J. Sel. Areas Commun. 2007, 25, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Kubach, M.; Sellung, R. On the market for self-sovereign identity: Structure and stakeholders. In Open Identity Summit 2021; Gesellschaft für Informatik: Bonn, Germany, 2021. [Google Scholar]
- Zichichi, M.; Contu, M.; Ferretti, S.; D’Angelo, G. LikeStarter: A Smart-contract based Social DAO for Crowdfunding. In Proceedings of the INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019. [Google Scholar]
- Ratnasamy, S.; Francis, P.; Handley, M.; Karp, R.; Shenker, S. A scalable content-addressable network. In Proceedings of the 2001 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, San Diego, CA, USA, 27–31 August 2001; pp. 161–172. [Google Scholar]
- Ferretti, S.; Ghini, V.; Panzieri, F.; Turrini, E. Seamless support of multimedia distributed applications through a cloud. In Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing, Miami, FL, USA, 5–10 July 2010; pp. 548–549. [Google Scholar]
- Becker, M.; Bodó, B. Trust in blockchain-based systems. Internet Policy Rev. 2021, 10, 1–10. [Google Scholar] [CrossRef]
- Pocher, N.; Zichichi, M. Towards CBDC-based Machine-to-Machine Payments in Consumer IoT. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing (SAC), Virtual, 25–29 April 2022; pp. 1–8. [Google Scholar]
- Bez, M.; Fornari, G.; Vardanega, T. The scalability challenge of ethereum: An initial quantitative analysis. In Proceedings of the 2019 IEEE International Conference on Service-Oriented System Engineering (SOSE), San Francisco, CA, USA, 4–9 April 2019; pp. 167–176. [Google Scholar]
- The Graph Protocol. 2020. Available online: https://thegraph.com/en/ (accessed on 24 May 2022).
- De Filippi, P.; Wray, C.; Sileno, G. Smart contracts. Internet Policy Rev. 2021, 10. [Google Scholar] [CrossRef]
- Ferretti, S.; D’Angelo, G. On the ethereum blockchain structure: A complex networks theory perspective. Concurr. Comput. Pract. Exp. 2020, 32, e5493. [Google Scholar] [CrossRef] [Green Version]
- Aiello, M.; Cambiaso, E.; Canonico, R.; Maccari, L.; Mellia, M.; Pescapè, A.; Vaccari, I. IPPO: A Privacy-Aware Architecture for Decentralized Data-sharing. arXiv 2020, arXiv:2001.06420. [Google Scholar]
- Yu, L.; Zichichi, M.; Markovich, R.; Najjar, A. Intelligent Human-input-based Blockchain Oracle (IHiBO). In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART), Online, 3–5 February 2022; pp. 1–12. [Google Scholar]
- D’Angelo, G.; Ferretti, S.; Marzolla, M. A blockchain-based flight data recorder for cloud accountability. In Proceedings of the 1st Workshop on Cryptocurrencies and Blockchains for Distributed Systems, Munich, Germany, 15 June 2018; pp. 93–98. [Google Scholar]
- Radix Knowledge Base. 2019. Available online: https://learn.radixdlt.com/ (accessed on 24 May 2022).
- Benčić, F.M.; Žarko, I.P. Distributed ledger technology: Blockchain compared to directed acyclic graph. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1569–1570. [Google Scholar]
- Brogan, J.; Baskaran, I.; Ramachandran, N. Authenticating Health Activity Data Using Distributed Ledger Technologies. Comput. Struct. Biotechnol. J. 2018, 16, 257–266. [Google Scholar] [CrossRef]
- IOTA Streams Specification. 2022. Available online: https://github.com/iotaledger/streams/blob/develop/specification/Streams_Specification_1_0A.pdf (accessed on 24 May 2022).
- Ateniese, G.; Fu, K.; Green, M.; Hohenberger, S. Improved proxy re-encryption schemes with applications to secure distributed storage. ACM Trans. Inf. Syst. Secur. 2006, 9, 1–30. [Google Scholar] [CrossRef]
- de la Vega, F.; Soriano, J.; Jimenez, M.; Lizcano, D. A peer-to-peer architecture for distributed data monetization in fog computing scenarios. Wirel. Commun. Mob. Comput. 2018, 2018, 5758741. [Google Scholar] [CrossRef]
- Zhu, L.; Xiao, C.; Gong, X. Keyword Search in Decentralized Storage Systems. Electronics 2020, 9, 2041. [Google Scholar] [CrossRef]
- Onik, M.M.H.; Kim, C.S.; Lee, N.Y.; Yang, J. Privacy-aware blockchain for personal data sharing and tracking. Open Comput. Sci. 2019, 9, 80–91. [Google Scholar] [CrossRef]
- Zichichi, M.; Contu, M.; Ferretti, S.; Rodríguez-Doncel, V. Ensuring Personal Data Anonymity in Data Marketplaces through Sensing-as-a-Service and Distributed Ledger. In Proceedings of the 3rd Distributed Ledger Technology Workshop, Co-Located with ITASEC 2020, Ancona, Italy, 4 February 2020. [Google Scholar]
- Lopez, D.; Farooq, B. A multi-layered blockchain framework for smart mobility data-markets. Transp. Res. Part C Emerg. Technol. 2020, 111, 588–615. [Google Scholar] [CrossRef] [Green Version]
- Zyskind, G.; Nathan, O. Decentralizing privacy: Using blockchain to protect personal data. In Proceedings of the 2015 IEEE Security and Privacy Workshops, San Jose, CA, USA, 21–22 May 2015; pp. 180–184. [Google Scholar]
- Cruz, J.P.; Kaji, Y.; Yanai, N. RBAC-SC: Role-based access control using smart contract. IEEE Access 2018, 6, 12240–12251. [Google Scholar] [CrossRef]
- Maesa, D.D.F.; Mori, P.; Ricci, L. Blockchain based access control. In IFIP International Conference on Distributed Applications and Interoperable Systems; Springer: Cham, Switerland, 2017; pp. 206–220. [Google Scholar]
- Zhang, Y.; He, D.; Choo, K.K.R. BaDS: Blockchain-based architecture for data sharing with ABS and CP-ABE in IoT. Wirel. Commun. Mob. Comput. 2018, 2018, 2783658. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Zhang, Y. A blockchain-based framework for data sharing with fine-grained access control in decentralized storage systems. IEEE Access 2018, 6, 38437–38450. [Google Scholar] [CrossRef]
- Xu, H.; He, Q.; Li, X.; Jiang, B.; Qin, K. BDSS-FA: A Blockchain-Based Data Security Sharing Platform With Fine-Grained Access Control. IEEE Access 2020, 8, 87552–87561. [Google Scholar] [CrossRef]
- Jiang, P.; Guo, F.; Liang, K.; Lai, J.; Wen, Q. Searchain: Blockchain-based private keyword search in decentralized storage. Future Gener. Comput. Syst. 2020, 107, 781–792. [Google Scholar] [CrossRef]
- IPFS Community. Search Engine for the InterPlanetary File System. 2021. Available online: https://github.com/ipfs-search/ipfs-search (accessed on 24 May 2022).
- Khudhur, N.; Fujita, S. Siva-The IPFS Search Engine. In Proceedings of the 2019 Seventh International Symposium on Computing and Networking (CANDAR), Nagasaki, Japan, 25–28 November 2019; pp. 150–156. [Google Scholar]
- Serena, L.; Zichichi, M.; D’Angelo, G.; Ferretti, S. Simulation of Hybrid Edge Computing Architectures. In Proceedings of the 2021 IEEE/ACM 25th International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Valencia, Spain, 27–29 September 2021; pp. 1–8. [Google Scholar]
- Chaudhry, A.; Crowcroft, J.; Howard, H.; Madhavapeddy, A.; Mortier, R.; Haddadi, H.; McAuley, D. Personal data: Thinking inside the box. In Proceedings of the Fifth Decennial Aarhus Conference on Critical Alternatives, Aarhus, Denmark, 17–21 August 2015; pp. 29–32. [Google Scholar]
- Esteves, B.; Pandit, H.J.; Rodríguez-Doncel, V. ODRL Profile for Expressing Consent through Granular Access Control Policies in Solid. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy Workshops (EuroS PW), Vienna, Austria, 6–10 September 2021; pp. 298–306. [Google Scholar] [CrossRef]
- Davari, M.; Bertino, E. Access control model extensions to support data privacy protection based on GDPR. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4017–4024. [Google Scholar]
- European Union Agency for Cybersecurity. Data Pseudonymisation: Advanced Techniques & Use Cases; Technical Report; European Union Agency for Cybersecurity: Athens, Greece, 2021. [Google Scholar]
- Herranz, J.; Hofheinz, D.; Kiltz, E. KEM/DEM: Necessary and Sufficient Conditions for Secure Hybrid Encryption. IACR Cryptology ePrint Archive. 2006. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.64.9369&rep=rep1&type=pdf (accessed on 24 May 2022).
- Gudgeon, L.; Moreno-Sanchez, P.; Roos, S.; McCorry, P.; Gervais, A. SoK: Layer-two blockchain protocols. In International Conference on Financial Cryptography and Data Security; Springer: Cham, Switerland, 2020. [Google Scholar]
- Yu, L.; Zichichi, M.; Markovich, R.; Najjar, A. Enhancing Trust in Trust Services: Towards an Intelligent Human-input-based Blockchain Oracle (IHiBO). In Proceedings of the 55th Hawaii International Conference on System Sciences (HICSS), Maui, HI, USA, 4–7 January 2022; pp. 1–10. [Google Scholar]
- Corcho, O.; Jiménez, J.; Morote, C.; Simperl, E. Data.europa.eu and Citizen-Generated Data. 2022. Available online: https://data.europa.eu/sites/default/files/report/data.europa.eu_Report_Citizen-generateddataondata_europa_eu.pdf (accessed on 24 May 2022).
- Samarati, P.; Sweeney, L. Protecting Privacy when Disclosing Information: K-Anonymity and Its Enforcement through Generalization and Suppression; Technical Report; SRI International: Menlo Park, CA, USA, 1998. [Google Scholar]
- Campbell, M.J.; Dennison, P.E.; Butler, B.W.; Page, W.G. Using crowdsourced fitness tracker data to model the relationship between slope and travel rates. Appl. Geogr. 2019, 106, 93–107. [Google Scholar] [CrossRef]
- Mazzoni, M.; Corradi, A.; Di Nicola, V. Performance evaluation of permissioned blockchains for financial applications: The ConsenSys Quorum case study. Blockchain Res. Appl. 2022, 3, 100026. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy. In Encyclopedia of Cryptography and Security; Springer: New York, NY, USA, 2011; pp. 338–340. [Google Scholar]
- Article 29 Working Party. 2014. Available online: https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2014/wp216_en.pdf (accessed on 24 May 2022).
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, citizen science or volunteered geographic information? The current state of crowdsourced geographic information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Murray, P.; Nate Welch, J.M. EIP-1167: Minimal Proxy Contract. 2018. Available online: https://eips.ethereum.org/EIPS/eip-1167 (accessed on 24 May 2022).
- Fabian Vogelsteller, V.B. EIP-20: ERC-20 Token Standard. 2015. Available online: https://eips.ethereum.org/EIPS/eip-20 (accessed on 24 May 2022).
- Zichichi, M.; Ferretti, S.; D’Angelo, G. Are Distributed Ledger Technologies Ready for Intelligent Transportation Systems? In Proceedings of the 3rd Workshop on Cryptocurrencies and Blockchains for Distributed Systems (CryBlock 2020), London, UK, 25 September 2020; pp. 1–6. [Google Scholar]
- Zichichi, M.; Ferretti, S.; D’Angelo, G. On the Efficiency of Decentralized File Storage for Personal Information Management Systems. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–6. [Google Scholar]
- AnaNSi-Research. Hypercube. 2022. Available online: https://github.com/AnaNSi-research/hypfs (accessed on 24 May 2022).
- Zichichi, M. miker83z/umbral-rs. Software 2022. [CrossRef]
- Zichichi, M. miker83z/testingIPFS: IPFS and SIA User Client Application Tests. Software. 2021. [CrossRef]
- AnaNSi-Research. IOTA. 2022. Available online: https://github.com/AnaNSi-research/testingIOTA (accessed on 24 May 2022).
- Montresor, A.; Jelasity, M. PeerSim: A scalable P2P simulator. In Proceedings of the 2009 IEEE Ninth International Conference on Peer-to-Peer Computing, Seattle, WA, USA, 9–11 September 2009; pp. 99–100. [Google Scholar]
- D’Angelo, G.; Ferretti, S. LUNES: Agent-based simulation of P2P systems. In Proceedings of the 2011 International Conference on High Performance Computing & Simulation, Istanbul, Turkey, 4–8 July 2011; pp. 593–599. [Google Scholar]
- Giansante, C.; Zichichi, M. miker83z/Hypercube-DHT-Simulation. Software. 2022. [CrossRef]
- Blockchain Explorer. 2020. Available online: www.blockchain.com/explorer (accessed on 24 May 2022).
- Zichichi, M. miker83z/k-DaO. Software 2022. [CrossRef]
- Serena, L.; Zichichi, M.; D’Angelo, G.; Ferretti, S. Simulation of Dissemination Strategies on Temporal Networks. In Proceedings of the 2021 Annual Modeling and Simulation Conference (ANNSIM), Fairfax, VA, USA, 19–22 July 2021; pp. 1–12. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Zichichi, M.; Serena, L.; Ferretti, S.; D’Angelo, G. Towards Decentralized Complex Queries over Distributed Ledgers: A Data Marketplace Use-Case. In Proceedings of the 30th IEEE International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–6. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nodes Number | Average | Standard Deviation | Confidence Interval (95%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 100 | 1000 | 10,000 | 100 | 1000 | 10,000 | 100 | 1000 | 10,000 | |
| 128 | 3.64 | 3.2 | 3.5 | 1.33 | 1.32 | 1.12 | (3.2, 4.0) | (2.8, 3.5) | (3.1, 3.8) |
| 256 | 4.08 | 4.28 | 3.66 | 1.45 | 1.48 | 1.31 | (3.6, 4.4) | (3.8, 4.6) | (3.2, 4.0) |
| 512 | 4.62 | 4.8 | 4.72 | 1.57 | 1.70 | 1.24 | (4.1, 5.0) | (4.3, 5.2) | (4.3, 5.0) |
| 1024 | 5.02 | 4.96 | 4.9 | 1.68 | 1.67 | 1.69 | (4.5, 5.4) | (4.4, 5.4) | (4.4, 5.3) |
| 2048 | 5.48 | 6.04 | 5.48 | 1.76 | 1.85 | 1.69 | (4.9, 5.9) | (5.5, 6.5) | (5.0, 5.9) |
| 4096 | 6.02 | 6.18 | 5.96 | 1.55 | 1.61 | 1.62 | (5.5, 6.4) | (5.7, 6.6) | (5.5, 6.4) |
| 8192 | 6.78 | 7.08 | 6.28 | 1.63 | 1.60 | 1.64 | (6.3, 7.2) | (6.6, 7.5) | (5.8, 6.7) |
| Nodes Number | Average | Standard Deviation | Confidence Interval (95%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 100 | 1000 | 10,000 | 100 | 1000 | 10,000 | 100 | 1000 | 10,000 | |
| 128 | 18.28 | 4.54 | 3.52 | 8.44 | 1.54 | 1.19 | (15.9, 20.6) | (4.1, 4.9) | (3.1, 3.8) |
| 256 | 35.90 | 6.80 | 4.16 | 17.89 | 2.25 | 1.43 | (30.9, 40.8) | (6.1, 7.4) | (3.7, 4.5) |
| 512 | 51.18 | 12.16 | 4.46 | 37.85 | 3.29 | 1.31 | (40.6, 61.6) | (11.2, 13.0) | (4.1, 4.8) |
| 1024 | 91.06 | 21.70 | 5.08 | 72.44 | 6.23 | 1.68 | (70, 111) | (19.9, 23.4) | (4.6, 5.5) |
| 2048 | 115.70 | 34.56 | 7.84 | 98.39 | 13.00 | 1.98 | (88, 142) | (30.9, 38.1) | (7.2, 8.3) |
| 4096 | 196.00 | 63.38 | 11.92 | 186.88 | 25.37 | 2.64 | (144, 247) | (56.3, 70.4) | (11.1, 12.6) |
| 8192 | 243.90 | 120.38 | 20.38 | 253.59 | 68.65 | 6.28 | (173, 314) | (101, 139) | (18.6, 22.1) |
| k | t | Create KFrags (ms) | Get CFrags (ms) | ||
|---|---|---|---|---|---|
| Average | Conf Int (95%) | Average | Conf Int (95%) | ||
| 10 | 1 | 75.6 | (72.11, 79.09) | 106.63 | (104.79, 108.47) |
| 2 | 86.58 | (82.07, 91.09) | 116.01 | (113.49, 118.54) | |
| 3 | 88.23 | (82.38, 94.09) | 120.17 | (117.04, 123.3) | |
| 4 | 100.48 | (94.42, 106.53) | 127.98 | (124.23, 131.73) | |
| 20 | 1 | 155.96 | (144.22, 167.69) | 128.38 | (122.94, 133.82) |
| 2 | 130.32 | (122.91, 137.73) | 135.27 | (130.74, 139.79) | |
| 3 | 144.0 | (136.01, 152.0) | 152.28 | (146.56, 157.99) | |
| 4 | 146.92 | (135.99, 157.85) | 163.61 | (154.72, 172.49) | |
| 30 | 1 | 113.11 | (107.89, 118.33) | 119.94 | (116.93, 122.95) |
| 2 | 146.23 | (140.54, 151.92) | 141.16 | (137.83, 144.49) | |
| 3 | 172.57 | (163.51, 181.62) | 167.19 | (160.77, 173.62) | |
| 4 | 162.65 | (154.41, 170.89) | 173.43 | (167.14, 179.73) | |
| 40 | 1 | 211.23 | (200.45, 222.01) | 158.86 | (152.58, 165.15) |
| 2 | 176.49 | (168.25, 184.73) | 166.48 | (160.42, 172.53) | |
| 3 | 206.08 | (196.19, 215.97) | 192.9 | (185.59, 200.22) | |
| 4 | 220.54 | (210.67, 230.4) | 209.77 | (202.55, 216.98) | |
| 50 | 1 | 122.28 | (117.61, 126.95) | 122.32 | (119.94, 124.7) |
| 2 | 189.77 | (179.35, 200.2) | 170.66 | (163.35, 177.96) | |
| 3 | 235.03 | (224.69, 245.36) | 215.84 | (207.61, 224.08) | |
| 4 | 267.82 | (257.65, 277.99) | 251.73 | (243.17, 260.3) | |
| 60 | 1 | 172.14 | (166.32, 177.95) | 148.48 | (144.76, 152.19) |
| 2 | 177.44 | (169.55, 185.34) | 172.77 | (166.75, 178.8) | |
| 3 | 225.4 | (216.35, 234.45) | 208.26 | (201.29, 215.22) | |
| 4 | 140.75 | (135.36, 146.15) | 159.98 | (155.94, 164.03) | |
| 70 | 1 | 158.52 | (152.33, 164.7) | 141.2 | (137.57, 144.83) |
| 2 | 179.65 | (173.0, 186.3) | 166.32 | (161.58, 171.05) | |
| 3 | 275.55 | (264.45, 286.65) | 250.54 | (241.68, 259.4) | |
| 4 | 230.97 | (221.41, 240.53) | 229.48 | (221.51, 237.45) | |
| 80 | 1 | 178.65 | (172.19, 185.1) | 153.97 | (149.92, 158.02) |
| 2 | 198.21 | (190.55, 205.88) | 178.61 | (173.34, 183.89) | |
| 3 | 204.39 | (196.89, 211.89) | 205.24 | (198.95, 211.53) | |
| 4 | 226.86 | (217.05, 236.66) | 231.71 | (223.5, 239.92) | |
| Smart Contract | Method | Gas Usage |
|---|---|---|
| DataOwnerContract | grantAccess() | 96,436 |
| requestAccess() | 142,648 | |
| grantAccessRequest() | 77,706 | |
| revokeAccess() | 30,126 | |
| AggregatorContract | requestAccessToData() | 698,854 |
| createkDaO() | 447,958 | |
| kDaO | submitProposal() | 133,501 |
| submitRefundProposal() | 362,489 | |
| submitSuggestion() | 114,523 | |
| vote() | 188,539 | |
| changeVote() | 153,587 | |
| executeRefundProposal() | 82,672 | |
| kDaOToken | transfer() | 52,311 |
| TokenTimelockProxy | lockTokens() | 246,525 |
| TokenTimelockUpgreadeable | release() | 45,808 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zichichi, M.; Ferretti, S.; Rodríguez-Doncel, V. Decentralized Personal Data Marketplaces: How Participation in a DAO Can Support the Production of Citizen-Generated Data. Sensors 2022, 22, 6260. https://doi.org/10.3390/s22166260
Zichichi M, Ferretti S, Rodríguez-Doncel V. Decentralized Personal Data Marketplaces: How Participation in a DAO Can Support the Production of Citizen-Generated Data. Sensors. 2022; 22(16):6260. https://doi.org/10.3390/s22166260
Chicago/Turabian StyleZichichi, Mirko, Stefano Ferretti, and Víctor Rodríguez-Doncel. 2022. "Decentralized Personal Data Marketplaces: How Participation in a DAO Can Support the Production of Citizen-Generated Data" Sensors 22, no. 16: 6260. https://doi.org/10.3390/s22166260