1. Introduction
Behavior recognition technologies are increasingly being employed in wearable-based fitness trackers as user interest in health grows. Because most wearable devices have an acceleration and gyro sensor, sensor signals can be used to recognize behavior. Simple actions such as walking, running, and running can be analyzed while wearing a watch. In line with this trend, various studies are being actively conducted to analyze and recognize behavior patterns using smart devices, such as mobile phones and wearable devices [
1,
2,
3,
4]. Some researchers have investigated the accuracy of behavior recognition based on the position of a wearable sensor. The most optimal sensor placement for actual behavior identification is the waist, ankle, or hip, despite most wearable devices being in the form of a watch worn on the wrist [
3,
4]. Stewart et al. used a logistic regression model to segment a 10 s windowed acceleration signal from the hip and wrist and found that the hip sensor achieved an accuracy of 91%, whereas the wrist sensor had an accuracy of 88.4% [
4].
The acceleration signal was used as an input signal to extract features and then used as an input for the deep learning model. Methods for extracting the characteristics of the accelerometer signal include applying the mean, median, zero-crossing, correlation, and signal vector magnitude. The extracted features are used as inputs for machine learning and deep learning models to recognize behavior patterns. In a study conducted by Anahita et al., the accelerometer and gyroscope data of 25 children were measured using a smart watch [
5]. Children wore smartwatches and conducted six different activities. Their running, walking, standing, sitting, lying, and stair climbing were measured at 10 Hz at 10 min intervals. The measured data were subjected to a preprocessing process suitable for each feature type, and features such as the mean, median, FFT-entropy, and signal vector magnitude were extracted and used as inputs for the deep learning model. Six activities were classified using two deep learning techniques: DNN and RNN. The RNN model showed an average F1 score of 80%.
Ahmadi et al. used machine learning techniques to recognize the behavioral patterns of adolescents and children with cerebral palsy into four classes: sedentary (SED), standing utilitarian movements (SUM), comfortable walking (CW), and brisk walking (BW) [
6]. They used the signal vector magnitude feature extracted from 10 s non-overlapping segmented signals, which were measured from 22 children and adolescents. Using the extracted features, four classes were classified using three machine learning techniques: random forest (RF), support vector machine (SVM), and binary decision tree (BDT). The results showed that the SVM and RF performed better than the BDT, with an average of 82.0% to 89% for the SVM, 82.6% to 88.8% for the RF, and 76.1% to 86.2% for the BDT. By class, SED was 94.1% to 97.9%, SUM was 74.0% to 96.6%, CW was 47.6% to 70.4%, and BW was 71.5% to 86.0%, which showed a good performance in the SED and SUM classifications, but a poor performance in the CW and BW classifications. Ignatov recognized the acceleration signal based on a user-independent CNN model and analyzed it using the UCI database, in which six types of behavioral data, including jogging, walking, and climbing stairs, were collected [
7]. Wang et al. recognized 19 behaviors using an auto-encoder composed of a deep belief network in unsupervised learning based on signals collected through wearable devices and showed a performance of 99.3% [
8].
Unlike in previous studies, there is a trend of applying deep learning models based on raw data without preprocessing [
9,
10]. It has been reported that a deep neural network model performs better by finding more information than a shallow neural model [
11]. Existing studies have used only accelerometer data or extracting features from the sensor data; however, the model can find more usable features than humans are unable to find. However, if a preprocessing is not applied, the model can be trained with better features because it learns by extracting features directly from the raw data [
12]. River et al. proposed an RNN-based human activity recognition model to classify six hand activities [
13]. They used inertial sensor data directly in the proposed model without preprocessing. Zhao et al. proposed a customized long short-term memory (LSTM) model by varying the window size in the data segmentation step [
14]. They used an accelerometer, a gyroscope, and magnetometer sensors as inputs without preprocessing. They found the optimized window size to obtain improved results; their final recognition accuracy was 93.6% using the UCI HAR database. Hassan et al. presented an end-to-end deep neural network (DNN) model for recognizing human actions from temporally sparse data signals generated by passive wearable sensors [
15]. Wan et al. proposed an HAR architecture based on a smartphone inertial accelerometer [
16]. The smartphone gathered the sensory data sequence while the participants went about their everyday activities and extracted the high-efficiency features from the original data through numerous three-axis accelerometers. To extract the relevant feature vectors, the data were preprocessed through denoising, normalization, and segmentation. They applied CNN, LSTM, BLSTM, MLP, and SVM models using the UCI and Pamap2 datasets and observed 93.21% accuracy with the CNN model using the UCI dataset.
In addition to the accelerometer signal, research on recognizing user behavior based on image signals is being actively conducted. In the case of images, studies are actively being applied to extract image features using a scale-invariant feature transform (SIFT) or speeded-up robust features, and to predict poses by recognizing silhouettes, depth information, and skeletons. Kale et al. proposed video-based human activity recognition for a smart surveillance system [
17]. The system extracted the features based on SIFT and applied a K-nearest neighbor (KNN) and an SVM to recognize four to nine activities including falling, fighting, walking, running, and sitting, among other general actions. The results show that an SVM achieves a 92.91% accuracy rate, whereas a KNN has an accuracy rate of 90.83%. Kim et al. proposed the activity recognition of elderly people using skeleton joint features from a depth video [
18]. They applied a hidden Markov model to distinguish between diverse human behaviors. The results of the experiments demonstrate that the elderly achieve a higher recognition rate, with a mean recognition rate of 84.33% for nine daily regular activities.
In recent years, the accuracy of behavior recognition has been significantly improved by applying deep learning and machine learning technologies. Khaire et al. applied a 5-CNN model using various vision cues, such as RGB images, depth images, and skeletal data as inputs. The performance of the 5-CNN model was 95% to 96% for classifying 27 activities, including bowling, boxing, tennis, and swinging [
19]. In addition, in self-supervised learning, a small number of data is augmented, and a study based on rotation data is being conducted. However, there is a problem in that it is difficult to recognize whether the image has been rotated, and thus whether lying or standing can be recognized as different poses. Amir et al. classified 60 classes using NTU RGB-D data as the input of the proposed 2-layer Part-Aware LSTM model [
20]. The class contains 40 daily actions (e.g., drinking, eating, and reading), nine health-related actions (e.g., sneezing, staggering, and falling), and 11 mutual actions (e.g., punching, kicking, and hugging). It was confirmed that the proposed model showed a cross-subject accuracy of 62.93% and a cross-view accuracy of 70.27%. Because of the complexity of human activity sequences, Shahroudy et al. suggested a multimodal multipart learning method that supports the sparse combination of multimodal part-based characteristics using depth and skeleton data [
21].
Research on integrating multiple heterogeneous sensory information is being conducted. Some existing studies were conducted to recognize behavior by extracting and integrating various feature values, such as silhouette and depth information, from the video signal. Khaire et al. proposed a method integrating vision data such as RGB, silhouettes, and skeletons [
19]. Amir et al. proposed RGB and depth data to recognize human activities [
20]. In addition, research integrating various sensor data such as accelerometers, gyroscopes, and magnetic field signals to recognize behavior have been conducted [
22]. Wei et al. proposed a CNN-based deep learning model to integrate the video and inertial-sensing signal in order to detect human activities [
23]. In this research, continuous motion was expressed using a three-dimensional video volume and an input translated from a one-dimensional acceleration signal into a two-dimensional image form using a spectrogram. CNN was employed in the behavior recognition model, as well as two types of fusion models. Fusion was performed at the decision level in the first model following classification for each input, while fusion was performed at the feature extraction level in the second model. The fusion at the feature level was 94.1% accurate, and the fusion at the decision level was 95.6% accurate.
Recently, much research has been undertaken to examine performance according to the enhanced method of distinguishing the backdrop from the person in the image, data segmentation, feature extraction, and feature selection, in order to increase the accuracy of behavior identification. Kiran et al. proposed a deep learning model with five multi-layers based on CNN that optimizes computation time [
24]. Each deep learning model was used for database normalization, transfer-learning-based optimal feature extraction, fusion and classification, and the Shannon entropy theory, a statistical feature, was applied to feature selection. In this study, by applying various databases such as UCF sport, KTH, and UT interaction, it was verified through experiments whether there was an improvement in processing speed while maintaining accuracy. Khan et al. proposed a cascaded framework for action recognition from video sequences [
25]. They used frame enhancement by contrast stretching, luminance channel selection, and so on, to clearly distinguish between the background and the person. After classifying it using the removed background and saliency map, a morphological operation to classify the human form was derived. Then, various types of features such as HOG and SFTA were extracted from the image, fused, and then classified by applying a neural network. The proposed method showed 97.2% to 99.9% performance in various open databases, such as KTH, UIUC, Muhavi, and WVU. Helmi et al. suggested a light-weight feature selection method, called GBOBWO algorithm, for human activity categorization based on a gradient-based optimizer algorithm and a support vector machine-based classifier. They used accelerometer signals as inputs and extract features in a general way [
26]. They selected appropriate features based on the GBOBWO method. They achieved 98% accuracy with the UCI-HAR and WISDM database.
In summary, the accuracy of video and sensor-based behavior identification varies greatly depending on how the properties of the constantly changing input signal are extracted, how segmentation is performed, how features are selected, and how the recognition model is used. As a result, there have been studies conducted to normalize data and extract step-by-step features through multiple CNN layers [
24], a study on a method of deriving features that can be distinguished from the background through preprocessing [
25], and a study on fusion of various feature values in the signal extraction and selection stage and extracting features of a light input signal that can be operated in a wearable environment [
26]. Another study on a method of deriving features that can be distinguished from the A study was also recently undertaken to integrate the picture signal and the acceleration signal and analyze it with a CNN in order to complement the constraints of the input data and thereby increase the accuracy of behavior recognition [
23].
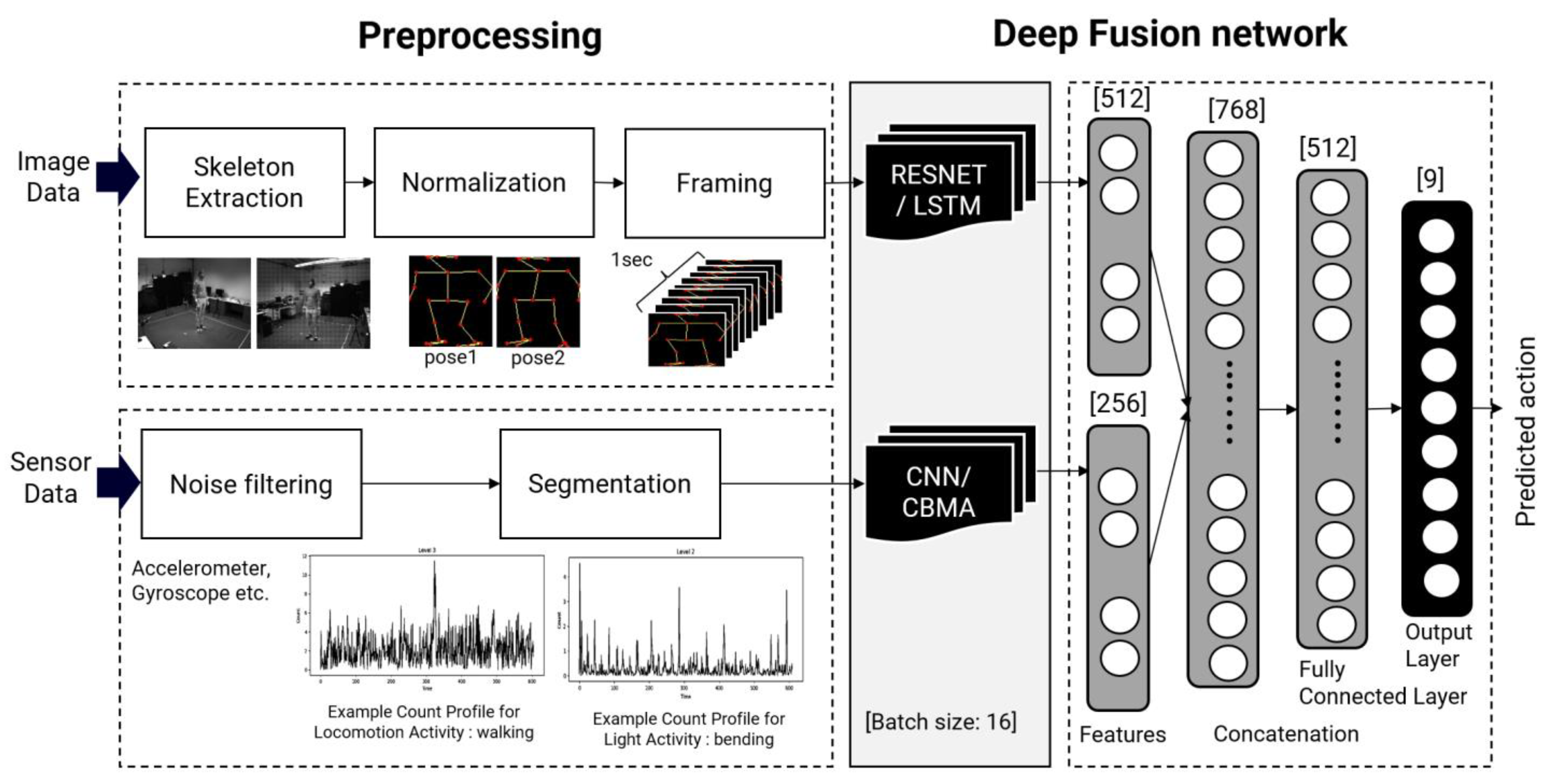
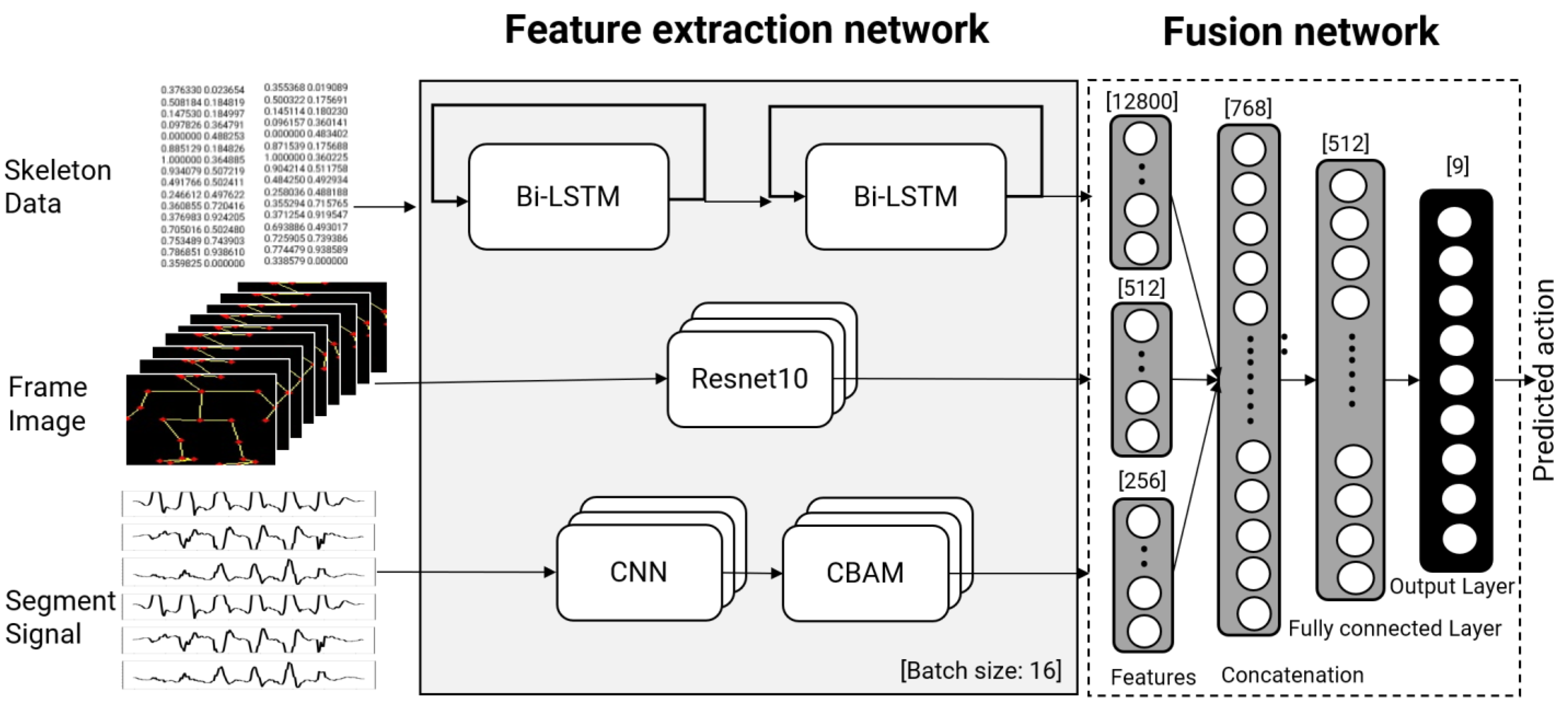
However, among existing studies, no study on generalized behavior recognition models that support various types of input signals or minimize the preprocessing of input signals, while also being robust to any noise that may occur in daily life, has been conducted. In addition, in previous studies, deep learning models other than CNN were not applied to fusion. Therefore, in this study, we propose a generalized deep learning model that is robust to noise not dependent on input signals by extracting features through a deep learning model for each heterogeneous input signal that can maintain performance while minimizing preprocessing of, and while integrating, the input signal. In this work, we propose a hybrid deep learning network that can recognize user behavior patterns using heterogeneous signals of image signals and accelerometer sensor signals. We also propose a fusion network that uses two sensors to maximize the identification rate for unfamiliar actions with a single signal and the development of a noise-resistant generalized recognition model. With the proposed model, an image signal and an accelerometer signal are inputted at the same time (for approximately 1 s) in the form of a time-series signal. A ResNet feature is produced for an image signal, and a CNN and CBAM model is used to create a feature for an accelerometer signal. The two signals are then concatenated to identify the activity.
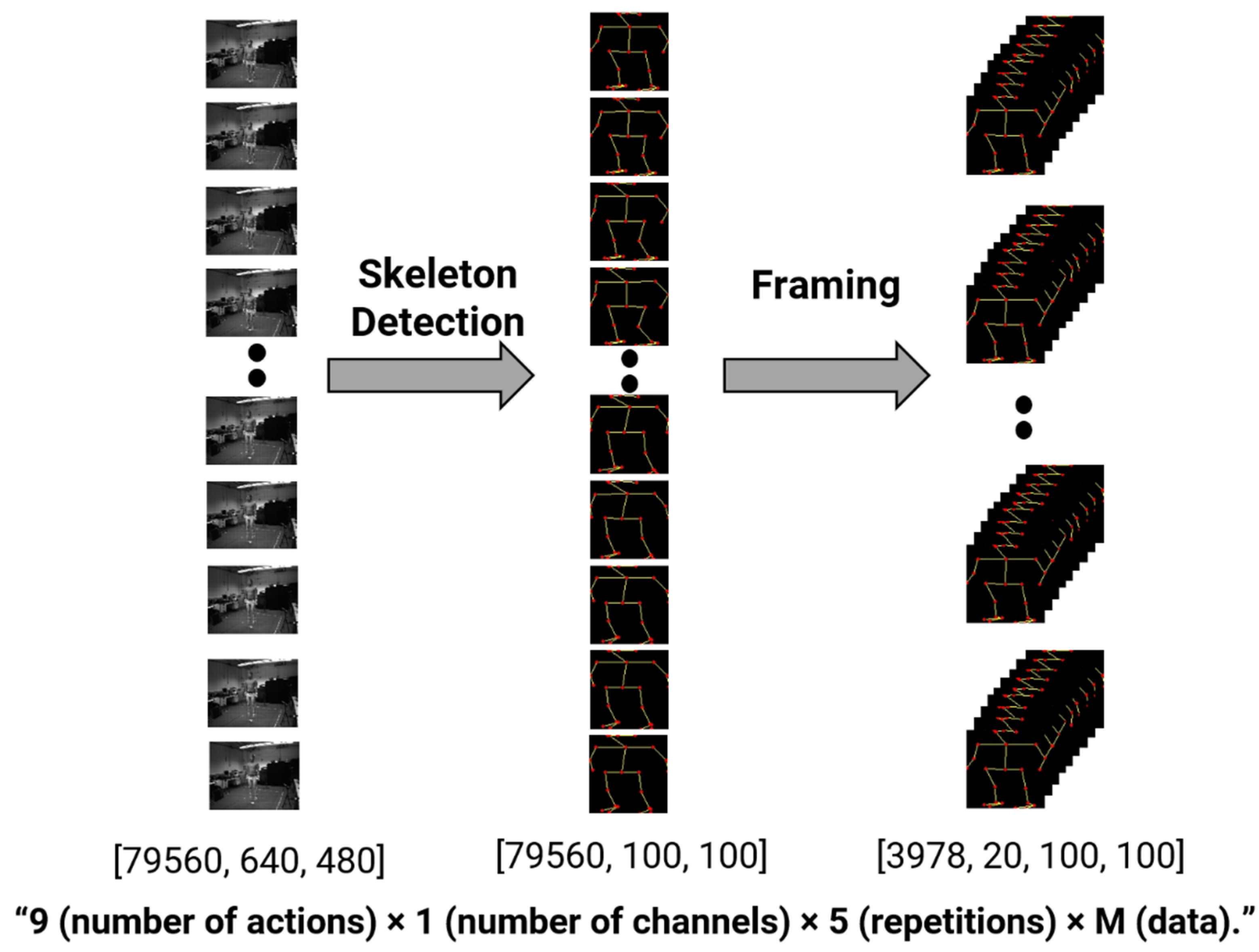
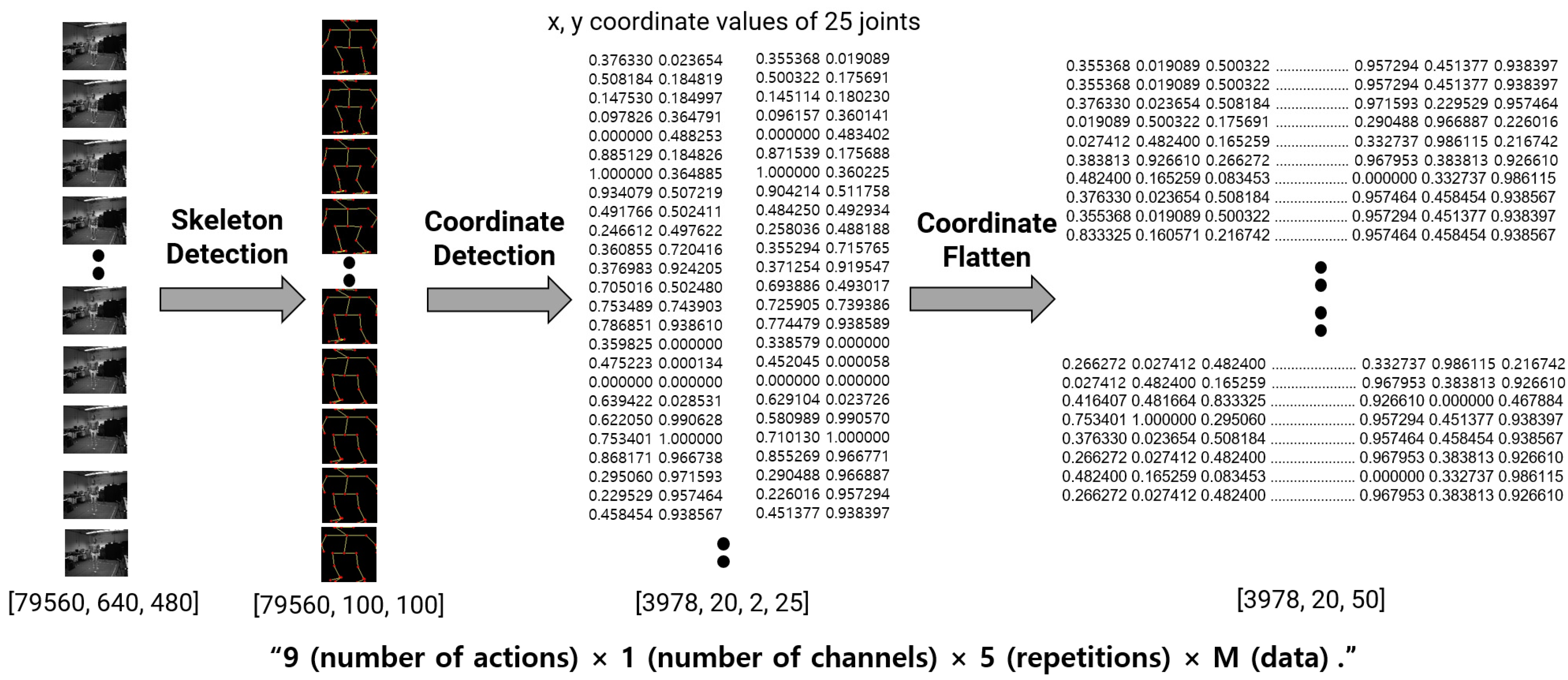
The technical contribution of this paper is as follows. First, we propose a generalized deep learning model that guarantees the recognition rate even when noise occurs in the acceleration signal or when distortion such as left and right reversal of the image occurs. The suggested model extracts features using a deep learning model that is appropriate for the type of input signal. ResNet is used to extract the features of the image signal, and CNN is used to extract the features of the multi-channel acceleration signal. LSTM and CBMA, which add attention to weights, are used to reflect temporal characteristics. Second, we use heterogeneous input data such as image and sensor data simultaneously to classify human activity, which can maintain performance while minimizing preprocessing of the input signal. Third, with respect to computational time, we offer an optimal input and a model for behavior recognition that takes into account the computational resources and processing time required based on the kind and size of input data. For activity recognition, normalized skeleton data can be enough to classify the actions while maintaining accuracy. The majority of present research has focused on increasing accuracy, although concerns such as training time and processing speed are crucial for practical usage in everyday life. The remainder of this chapter describes the materials, proposed methods, and experiment results in detail.
4. Discussion
In the case of deep-learning-based recognition, a robust deep learning model cannot be generated if there are insufficient data or if the activity to be recognized is deformed. For example, if the image is rotated, it is not possible to recognize whether the image has been rotated, and the possibility of determining a different posture increase. That is, even in the case of the same standing action, there is a problem in that a different pose can be recognized when lying down or standing. To solve this problem, a study was conducted to generate learning data by applying a self-supervised learning technique to augment a small amount of data [
19,
20].
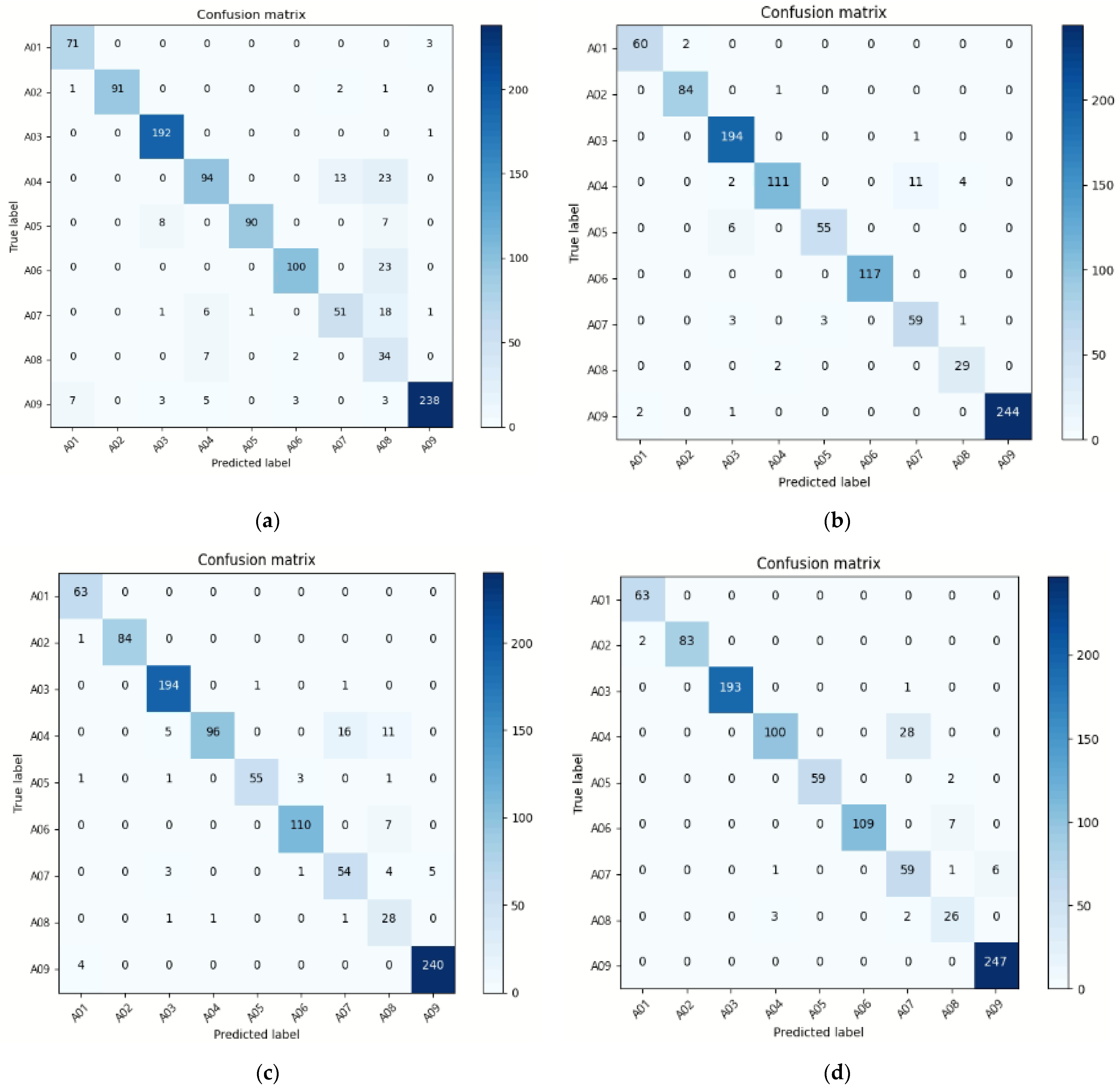
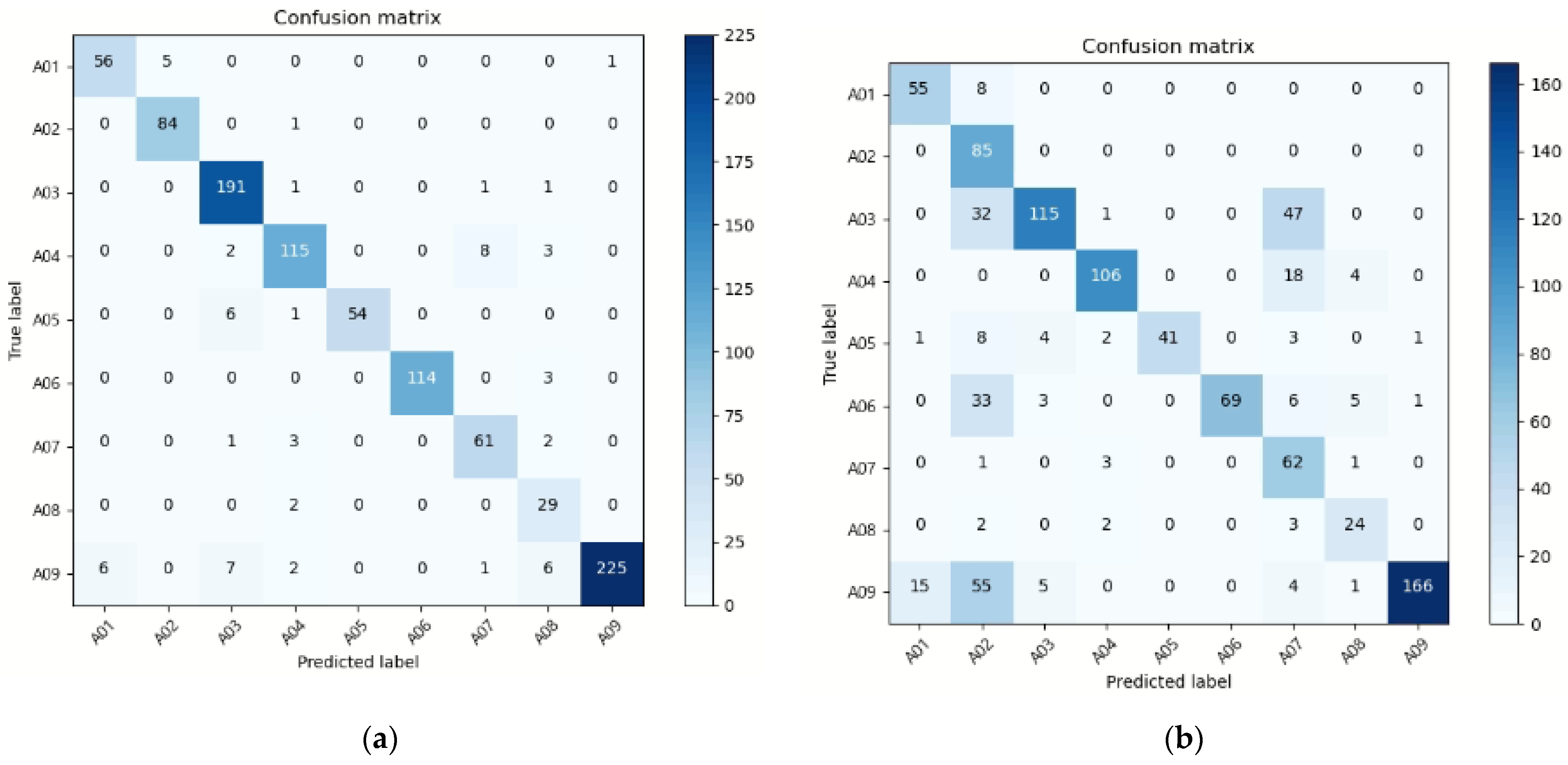
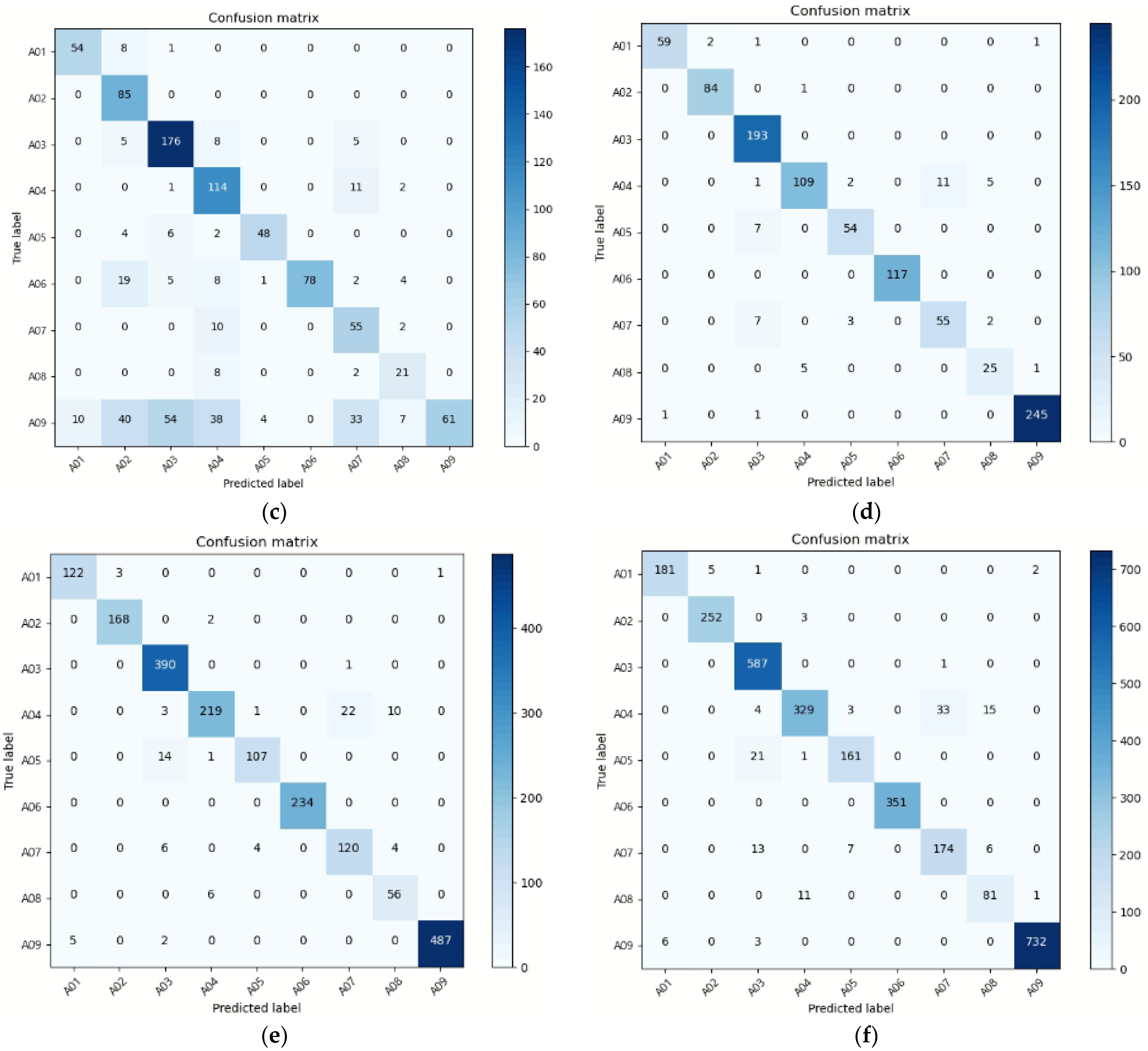
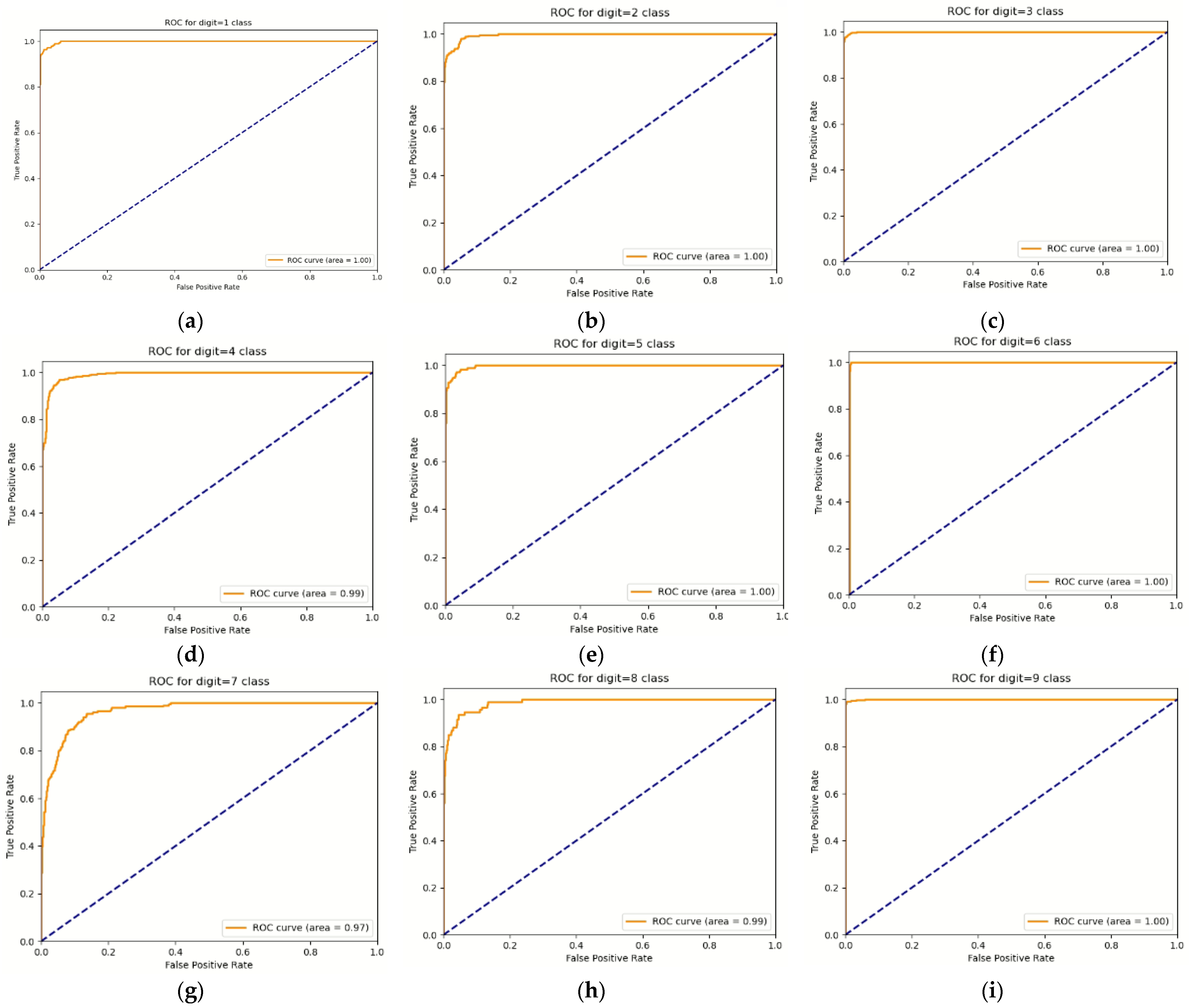
From this study, we observed that the proposed deep learning model preserves the recognition rate even when various poses are inputted for confirming experimentally the complementary behavior recognition of the accelerometer and image sensor. The overall performance was demonstrated by establishing a deep fusion network with heterogeneous inputs, and the fluctuation in the recognition rate for each behavior was also reduced. Boxing or punching movements, for instance, have a similar pattern of arm motions and arm bending, which are comparable to those of clapping and throwing a ball. As a result, when only an image signal was used, the accuracy was only approximately 50%; however, when both the image and the sensor signal were used, the accuracy was determined to be approximately 86%.
In addition, when noise or distortion occurs in image or sensor data, it was confirmed that the proposed system can recognize the behavior while maintaining accuracy in the absence of noise. The accuracy analysis indicated a 93.41% performance when the image with the input signal was inverted toward the left or right and the existing image was mixed and evaluated, and a 94.16% performance when the vertically inverted image and the existing image were mixed and tested. The system performed well when merging the left and right images, the upside-down image, and the current image, reaching an accuracy of 93.44%. White noise was also added to one channel value in the case of the acceleration signal, and the test confirmed that the performance was 93.23%. After testing the data with inversion and noise data, it has been determined that the suggested model is resilient, with a performance deterioration of approximately 1%.
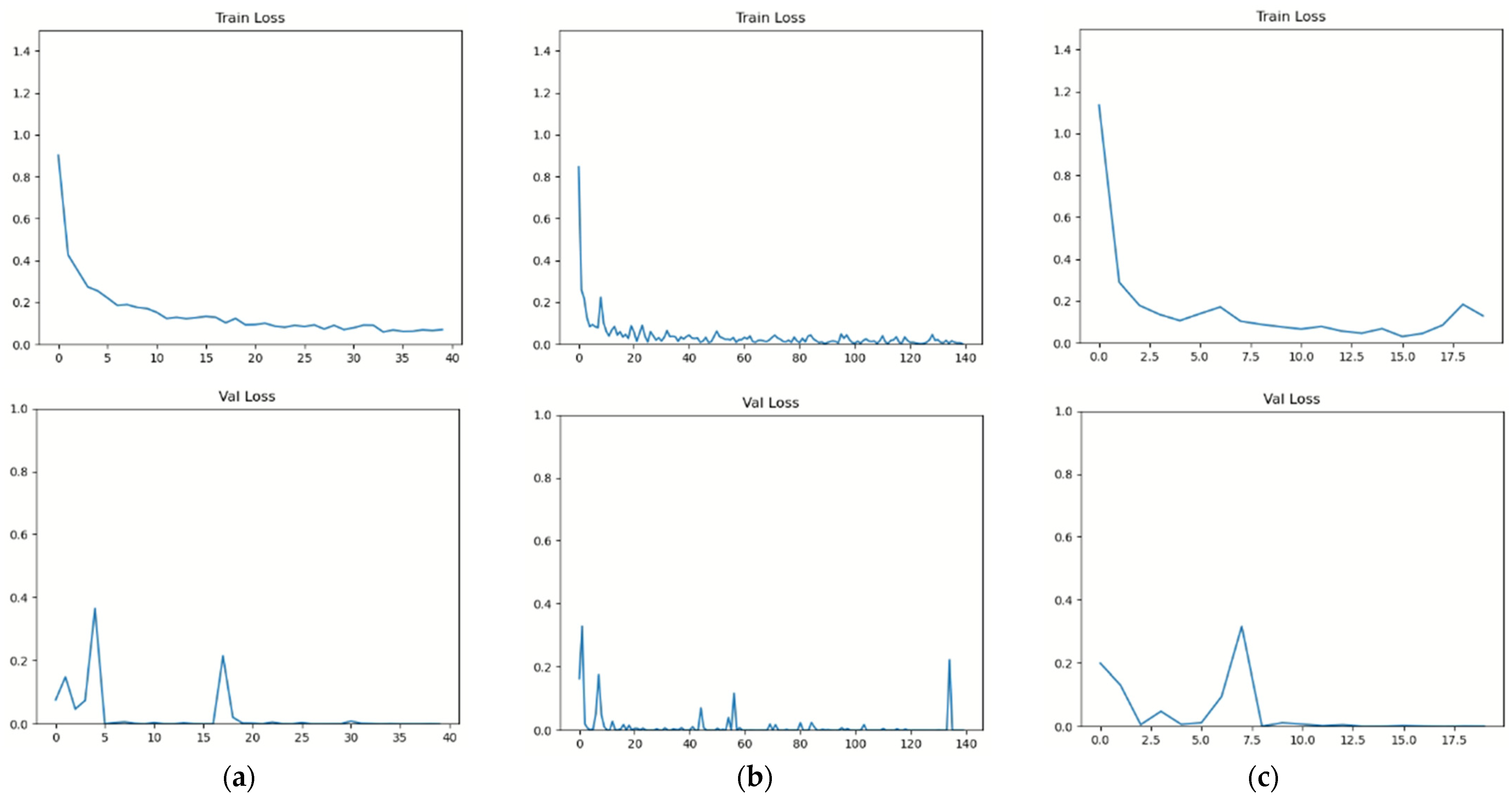
By comparing the performance with the training time, we confirmed that activity recognition above a certain level is possible if only skeleton data are needed for such recognition. In terms of a simple temporal efficiency, the model using sensor and coordinate information showed a good performance, after which the accelerometer and image model and the model using accelerometer, image, and coordinate information showed similar performance. Instead of using the complete image as the input for behavior recognition, the proposed method employs a skeleton image and its coordinate values. This reduces both learning time and learning accuracy. When all data were analyzed at the same time, it took approximately 300 s to learn the three proposed deep learning networks, but only approximately 10 s when the skeleton coordinate vector was utilized as an input. As a result, a performance improvement of approximately 30-fold in terms of time efficiency was confirmed.
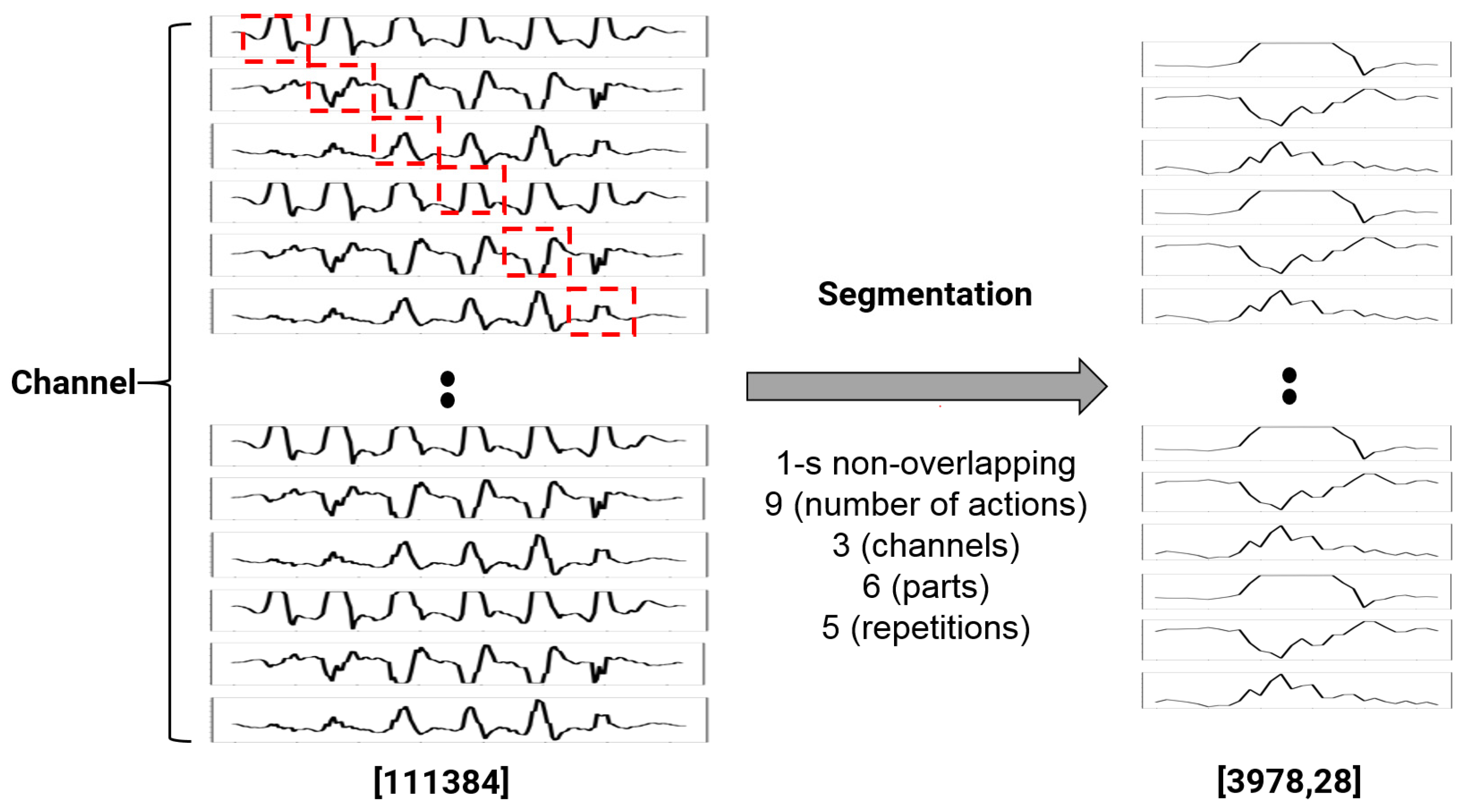
The limitations of the proposed study are as follows. The deep learning model proposed in this study applied ResNet for image data, CNN and CBAM for time series signals, and LSTM for skeleton vector data to apply a model suitable for input signals. This model is widely used in the deep learning field, and it seems that additional performance improvements can be expected. Especially, the existing skeleton vector produces poor results. Additional speed increases can be predicted if one employs a learning method that weighs coordinate changes based on a transformer or BERT model used for sequential data modeling instead of LSTM. In addition, to optimize performance and processing power, a skeleton, not an original image, was extracted and used as an input. However, considering that research on generalizing models based on limited input signals in recent studies is ongoing, further research on end-to-end models based on raw input signals is needed. Lastly, behavior recognition was performed using current 18 channel data extracted from six wearable devices and camera images in four directions. More research is needed to figure out how to simplify the input signal and put it to use in the actual world.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}