
Compressed Video Quality Index Based on Saliency-Aware Artifact Detection


Abstract
:1. Introduction
- (1)
- Proposed a NR-VQA method based on PEA detection. The PEA detection module accurately identifies four typical types of PEAs (i.e., blurring, blocking, ringing and color bleeding). Based on the PEA detection module, the PEA intensities are obtained to analyze video quality.
- (2)
- Introduced visual saliency detection and patch segmentation for high VQA accuracy and reduced complexity. The visual saliency detection can make useful information of videos and maximize utilization of computing resources, as well as help to eliminate the impact of redundant visual information on subjective evaluation.
- (3)
- Achieved the superior performance of our method in terms of compressed videos. Compared with multiple typical VQA metrics, our index has the highest overall correlation coefficient with the subjective quality score. In addition, our algorithm can achieve reasonable performance in cross-database verification, which shows that our algorithm has good generalization and robustness.
2. PEA-Based Video Quality Index
2.1. Perceivable Encoding Artifacts
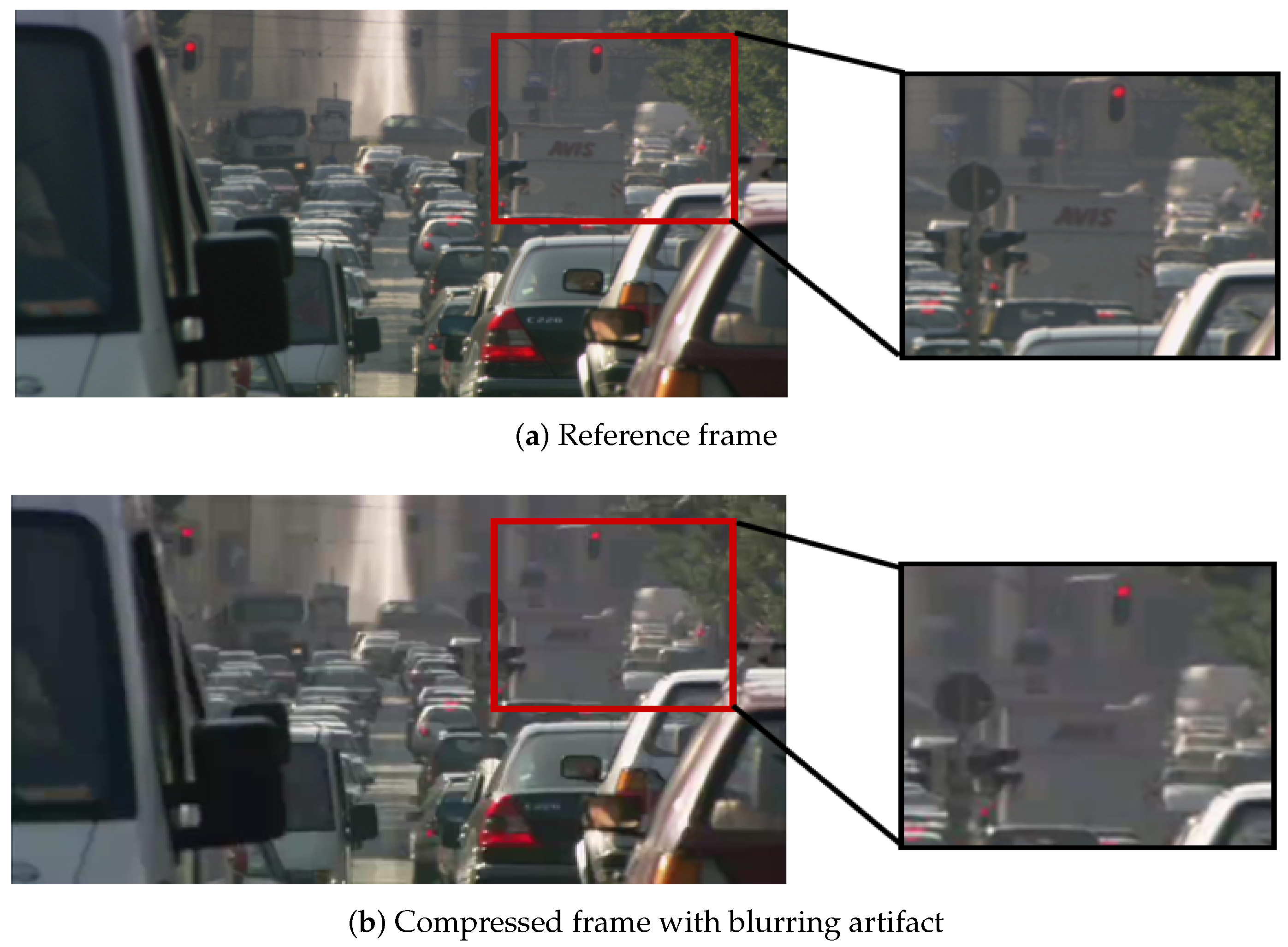
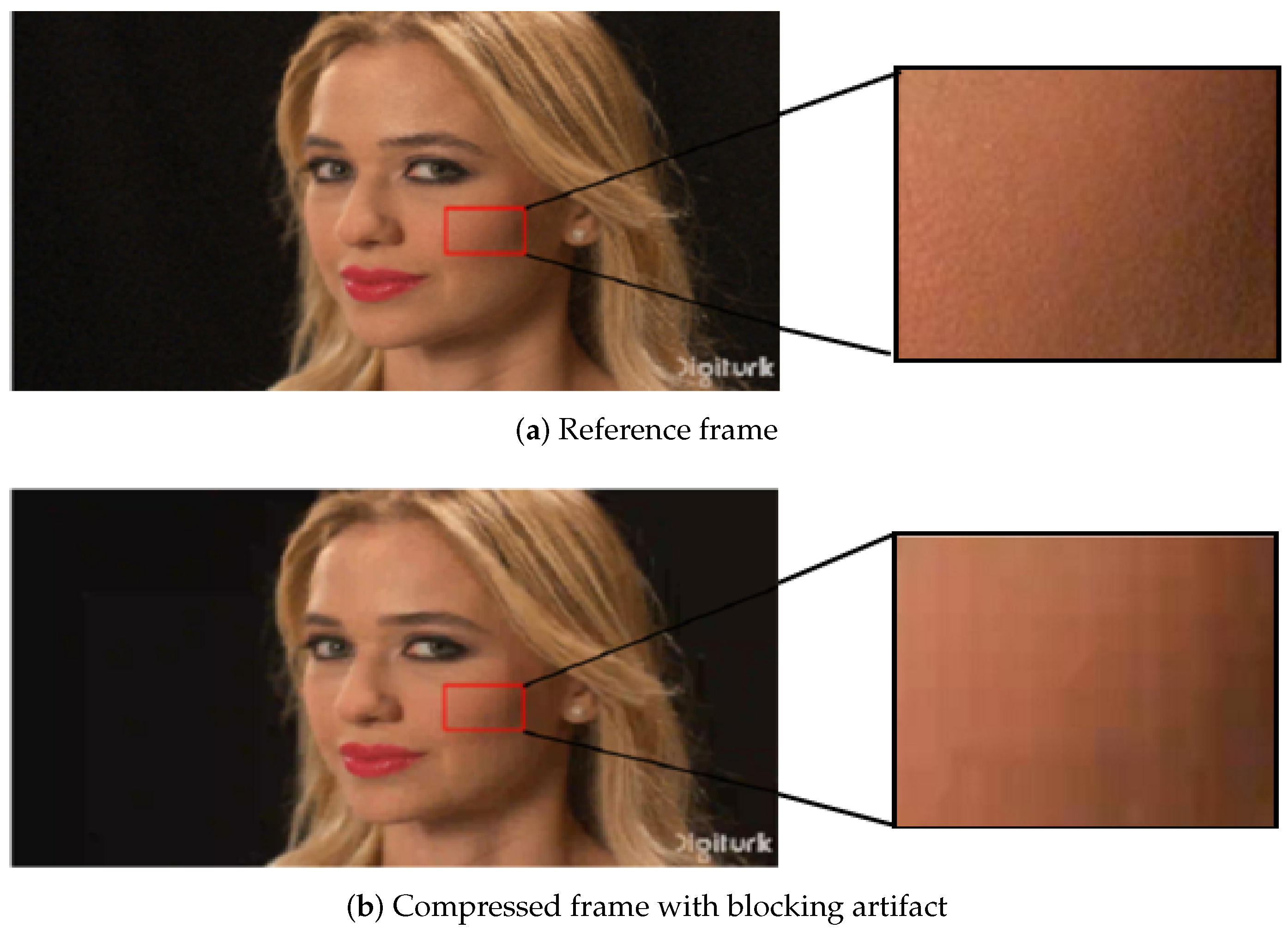
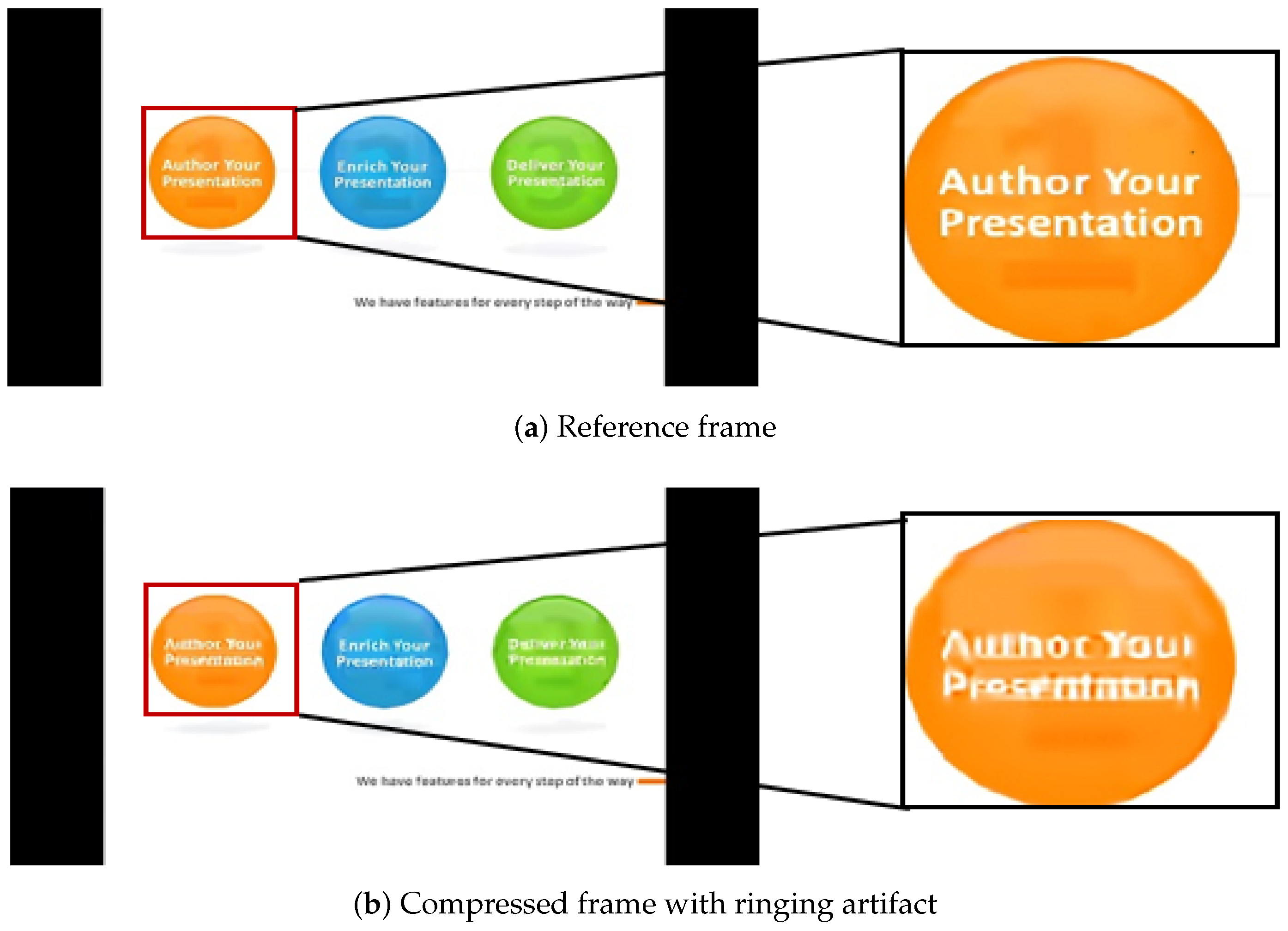
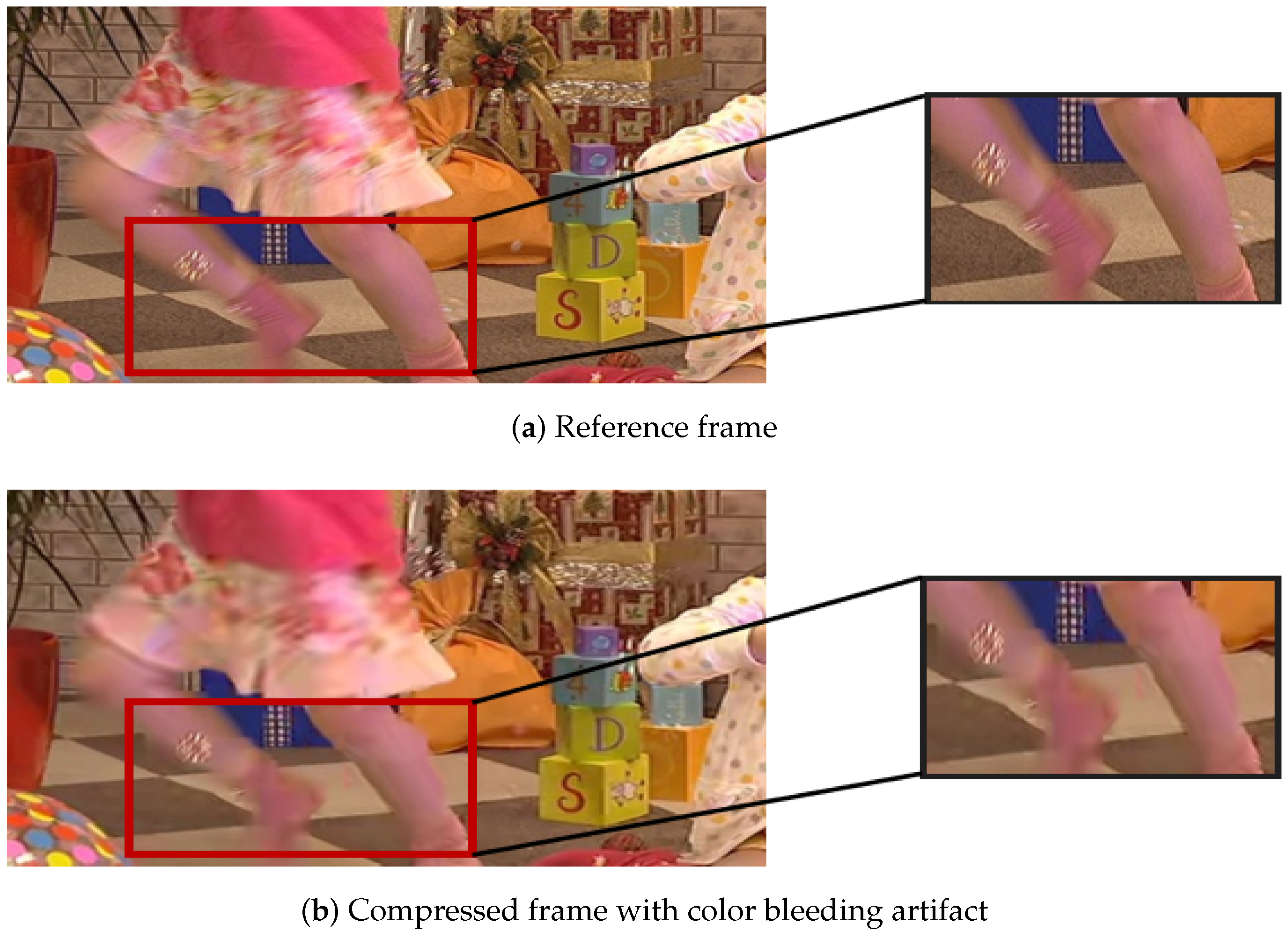
2.1.1. Four Typical PEAs
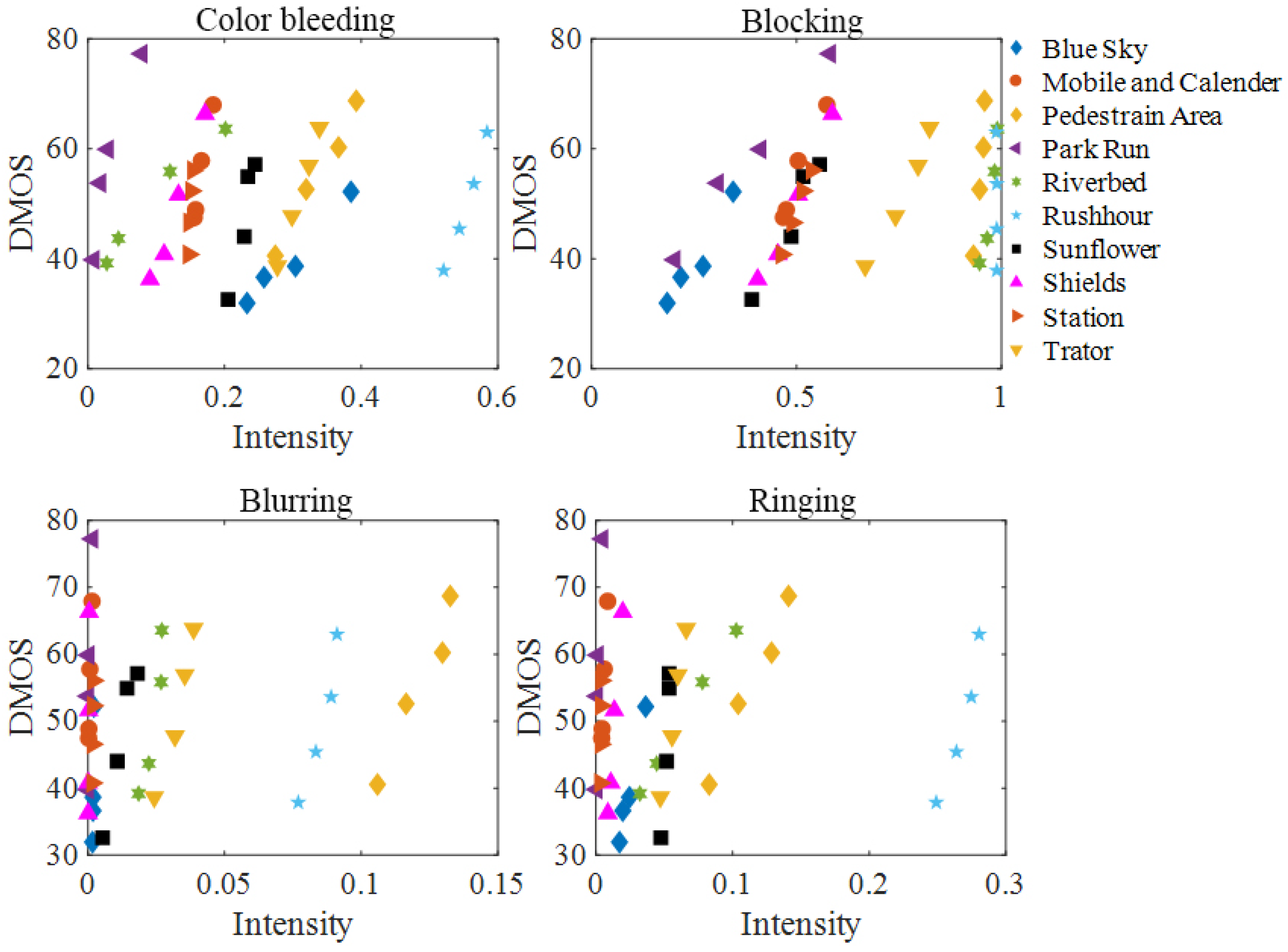
2.1.2. Correlation between PEAs and Visual Quality
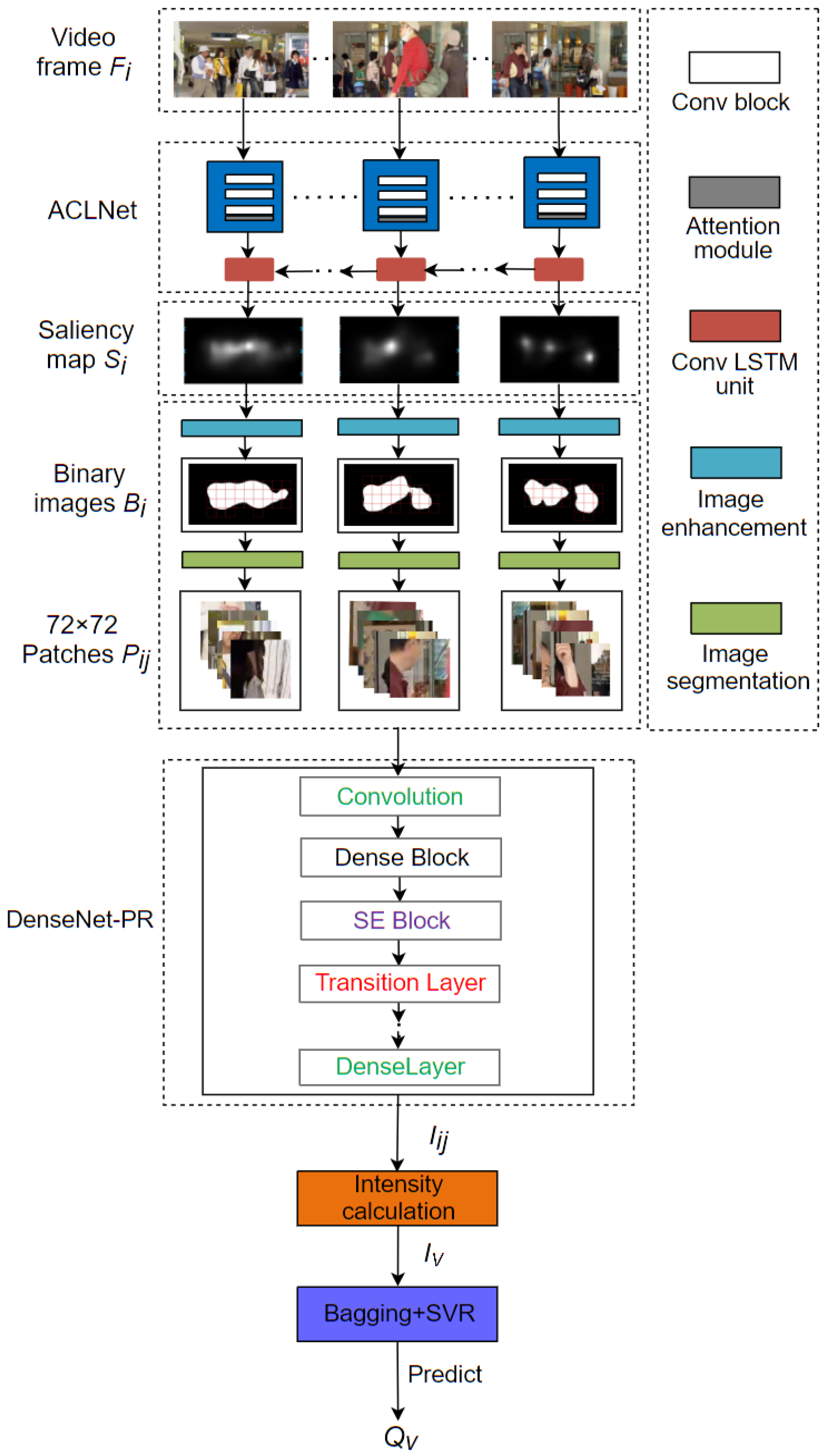
2.2. Video Saliency Detection with ACLNet
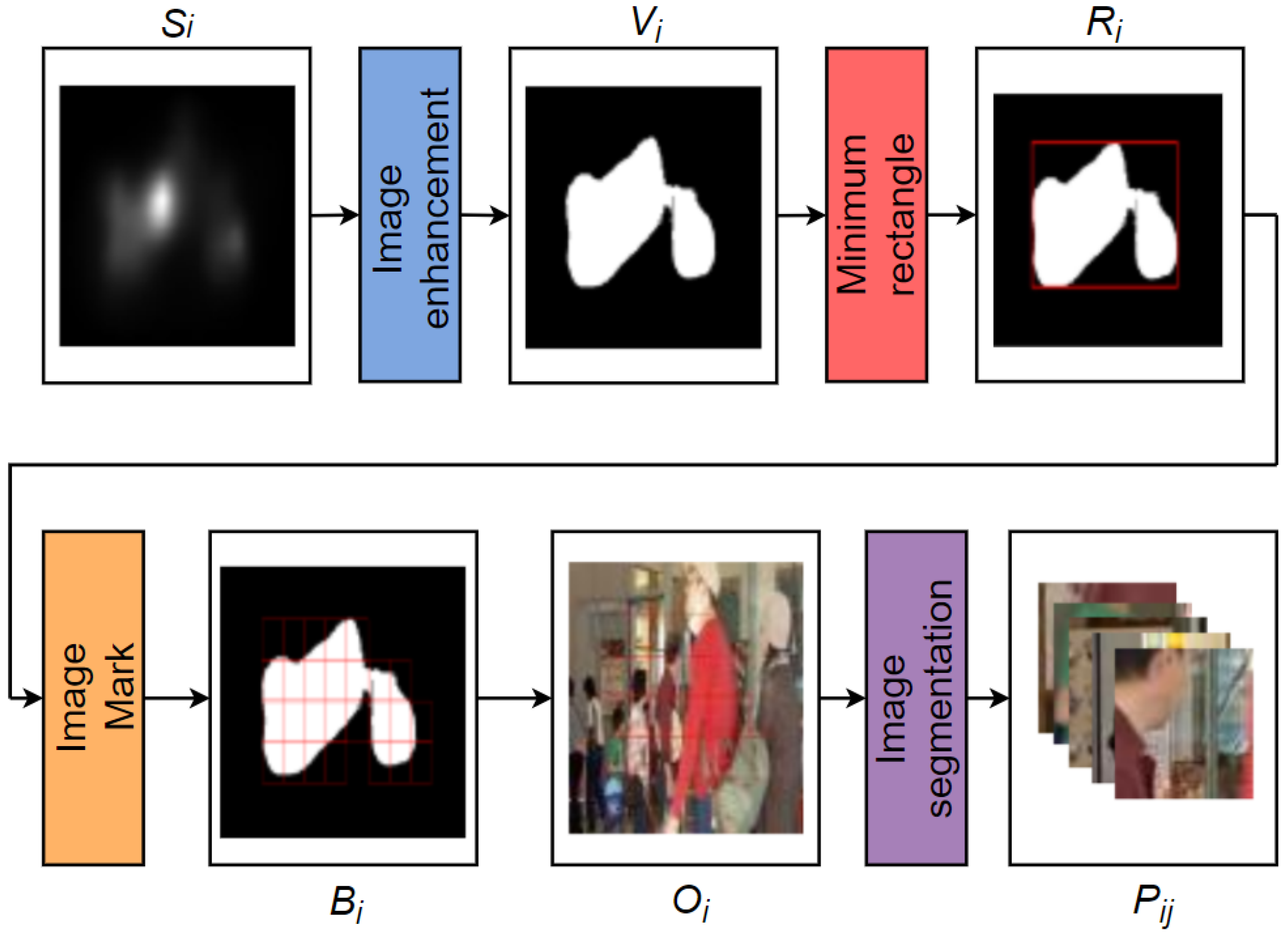
2.3. Image Patch Segmentation
2.4. PEA Detection
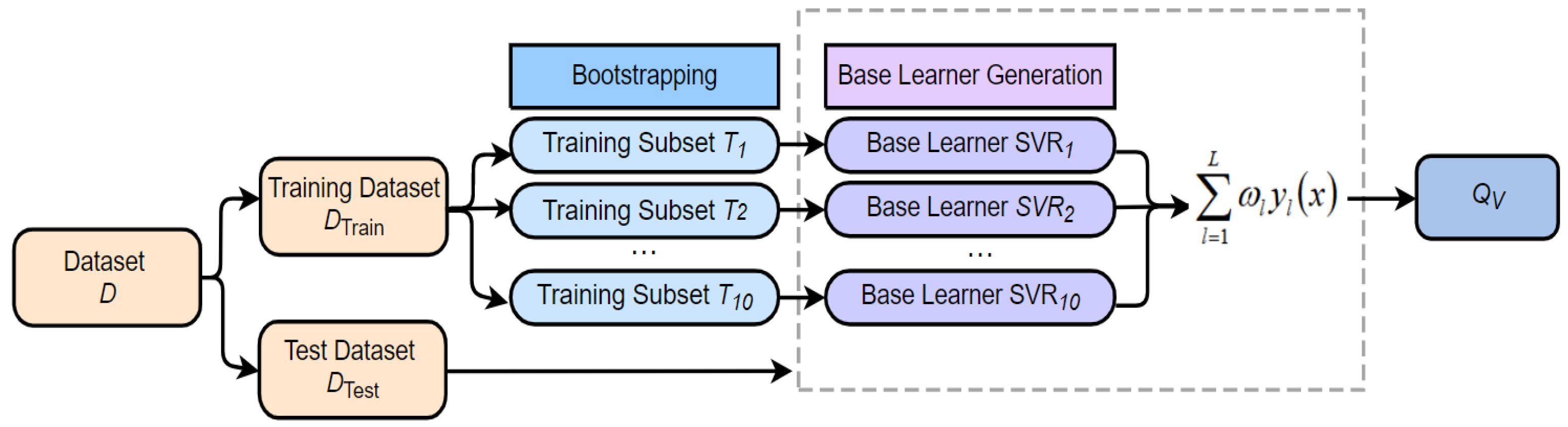
2.5. Video Quality Prediction
3. Experiments and Discussions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, L.; Yu, S.; Zhou, L.; Chen, W.; Zhao, T.; Wang, Z. PEA265: Perceptual assessment of video compression artifacts. IEEE Trans. Circuits Syst. Video Technol. 2020, 28, 3898–3910. [Google Scholar] [CrossRef] [Green Version]
- International Telecommunication Union. Methodology for the Subjective Assessment of the Quality of Television Pictures; Recommendation ITU-R BT.500-13; International Telecommunication Union: Geneva, Switzerland, 2012. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Soundararajan, R.; Bovik, A.C. Video quality assessment by reduced reference spatiotemporal entropic differencing. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 684–694. [Google Scholar] [CrossRef]
- Bampis, C.G.; Gupta, P.; Soundararajan, R.; Bovik, A.C. SpEED-QA: Spatial efficient entropic differencing for image and video quality. IEEE Signal Process. Lett. 2017, 24, 1333–1337. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind prediction of natural video quality. IEEE Trans. Image Process. 2014, 23, 1352–1365. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Po, L.; Cheung, C.; Xu, X.; Feng, L.; Yuan, F.; Cheung, K. No-reference video quality assessment with 3D shearlet transform and convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1044–1057. [Google Scholar] [CrossRef]
- Wang, S.; Gu, K.; Zhang, X.; Lin, W.; Zhang, L.; Ma, S.; Gao, W. Subjective and Objective Quality Assessment of Compressed Screen Content Images. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 532–543. [Google Scholar] [CrossRef]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Xu, J.; Ye, P.; Liu, Y.; Doermann, D. No-reference video quality assessment via feature learning. In Proceedings of the IEEE Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 491–495. [Google Scholar]
- Mittal, A.; Saad, M.A.; Bovik, A.C. A completely blind video integrity oracle. IEEE Trans. Image Process. 2016, 25, 289–300. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, Y.; Shuai, Y. Blind video quality assessment based on spatio-temporal internal generative mechanism. In Proceedings of the IEEE Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 305–309. [Google Scholar]
- Reddy, D.S.V.; Channappayya, S.S. No-reference video quality assessment using natural spatiotemporal scene statistics. IEEE Trans. Image Process. 2020, 29, 5612–5624. [Google Scholar] [CrossRef]
- Abate, L.; Ramponi, G.; Stessen, J. Detection and measurement of the blocking artifact in decoded video frames. Signal Image Video Process. 2013, 7, 453–466. [Google Scholar] [CrossRef]
- Amor, M.B.; Larabi, M.C.; Kammoun, F.; Masmoudi, N. A no reference quality metric to measure the blocking artefacts for video sequences. J. Photogr. Sci. 2016, 64, 408–417. [Google Scholar]
- Xue, Y.; Erkin, B.; Wang, Y. A novel no-reference video quality metric for evaluating temporal jerkiness due to frame freezing. IEEE Trans. Multimedia 2014, 17, 134–139. [Google Scholar] [CrossRef]
- Zhu, K.; Li, C.; Asari, V.; Saupe, D. No-reference video quality assessment based on artifact measurement and statistical analysis. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 533–546. [Google Scholar] [CrossRef] [Green Version]
- Men, H.; Lin, H.; Saupe, D. Empirical evaluation of no-reference VQA methods on a natural video quality database. In Proceedings of the International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017; pp. 1–3. [Google Scholar]
- Vranje, M.; Bajinovci, V.; Grbi, R.; Vajak, D. No-reference artifacts measurements based video quality metric. Signal Process Image Commun. 2019, 78, 345–358. [Google Scholar] [CrossRef]
- Rohil, M.K.; Gupta, N.; Yadav, P. An improved model for no-reference image quality assessment and a no-reference video quality assessment model based on frame analysis. Signal Image Video Process. 2020, 14, 205–213. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Xie, J.; Chen, M.; Ling, H.; Borji, A. Revisiting video saliency prediction in the deep learning era. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 220–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kai, Z.; Zhao, T.; Rehman, A.; Zhou, W. Characterizing perceptual artifacts in compressed video streams. In Proceedings of the Human Vision and Electronic Imaging XIX, San Francisco, CA, USA, 3–6 February 2014; pp. 173–182. [Google Scholar]
- LIVE Video Quality Database. Available online: http://live.ece.utexas.edu/research/quality/live_video.html (accessed on 20 September 2021).
- Seshadrinathan, K.; Soundararajan, R.; Bovik, A.C.; Cormack, L. Study of subjective and objective quality assessment of video. IEEE Trans. Image Process. 2010, 19, 1427–1441. [Google Scholar] [CrossRef]
- Seshadrinathan, K.; Soundararajan, R.; Bovik, A.C.; Cormack, L. A Subjective Study to Evaluate Video Quality Assessment Algorithms. In Proceedings of the Human Vision and Electronic Imaging XV, San Jose, CA, USA, 18–21 January 2010. [Google Scholar]
- Li, L.; Lin, W.; Zhu, H. Learning structural regularity for evaluating blocking artifacts in JPEG images. IEEE Signal Process. Lett. 2014, 21, 918–922. [Google Scholar] [CrossRef]
- Ultra Video Group. Available online: http://ultravideo.cs.tut.fi/#main (accessed on 20 September 2021).
- Wu, J.; Liu, Y.; Dong, W.; Shi, G.; Lin, W. Quality Assessment for Video With Degradation Along Salient Trajectories. IEEE Trans. Multimedia 2019, 21, 2738–2749. [Google Scholar] [CrossRef]
- Duanmu, Z.; Zeng, K.; Ma, K.; Rehman, A.; Wang, Z. A Quality-of-Experience Index for Streaming Video. IEEE J. Sel. Top. Signal Process. 2017, 11, 154–166. [Google Scholar] [CrossRef]
- Hu, S.; Jin, L.; Wang, H.; Zhang, Y.; Kwong, S.; Kuo, C. Objective Video Quality Assessment Based on Perceptually Weighted Mean Squared Error. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1844–1855. [Google Scholar] [CrossRef]
- Yang, J.; Ji, C.; Jiang, B.; Lu, W.; Meng, Q. No reference quality assessment of stereo video based on saliency and sparsity. IEEE Trans. Broadcast. 2018, 64, 341–353. [Google Scholar] [CrossRef] [Green Version]
- Feng, W.; Li, X.; Gao, G.; Chen, X.; Liu, Q. Multi-Scale Global Contrast CNN for Salient Object Detection. Sensors 2020, 20, 2656. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vu, P.V.; Chandler, D.M. ViS3: An algorithm for video quality assessment via analysis of spatial and spatiotemporal slices. J. Electron. Imaging 2014, 23, 1–25. [Google Scholar] [CrossRef]
- Zhang, F.; Li, S.; Ma, L.; Wong, Y.; Ngan, K. IVP Subjective Quality Video Database. Available online: http://ivp.ee.cuhk.edu.hk/research/database/subjective (accessed on 20 September 2021).
- Bajčinovci, V.; Vranješ, M.; Babić, D.; Kovačević, B. Subjective and objective quality assessment of MPEG-2, H.264 and H.265 videos. In Proceedings of the International Symposium ELMAR, Zadar, Croatia, 18–20 September 2017; pp. 73–77. [Google Scholar]
- Sun, W.; Liao, Q.; Xue, J.; Zhou, F. SPSIM: A Superpixel-Based Similarity Index for Full-Reference Image Quality Assessment. IEEE Trans. Image Process. 2018, 27, 4232–4244. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a completely blind image quality analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Correlation | Blocking | Blurring | Ringing | Color Bleeding |
|---|---|---|---|---|
| PLCC | 0.5551 | 0.1921 | 0.1900 | 0.1902 |
| SRCC | 0.4208 | 0.1848 | 0.1340 | 0.1109 |
| Methods | LIVE | CSIQ | IVP | FERIT-RTRK | Overall |
|---|---|---|---|---|---|
| PSNR | 0.5735 | 0.8220 | 0.7998 | 0.7756 | 0.7383 |
| SSIM | 0.6072 | 0.8454 | 0.8197 | 0.6870 | 0.7406 |
| MS-SSIM | 0.6855 | 0.8782 | 0.8282 | 0.8724 | 0.8105 |
| STRRED | 0.8392 | 0.8772 | 0.5947 | 0.8425 | 0.7823 |
| SpEED-QA | 0.7933 | 0.8554 | 0.6822 | 0.6978 | 0.7586 |
| BRISQUE | 0.2154 | 0.5526 | 0.2956 | 0.7653 | 0.4335 |
| NIQE | 0.3311 | 0.5350 | 0.3955 | 0.5817 | 0.4505 |
| VIIDEO | 0.6829 | 0.7211 | 0.4358 | 0.3933 | 0.5651 |
| SAAM | 0.9023 | 0.9244 | 0.8717 | 0.9499 | 0.9091 |
| Methods | LIVE | CSIQ | IVP | FERIT-RTRK | Overall |
|---|---|---|---|---|---|
| PSNR | 0.4146 | 0.8028 | 0.8154 | 0.7685 | 0.6928 |
| SSIM | 0.5677 | 0.8440 | 0.8049 | 0.7236 | 0.7328 |
| MS-SSIM | 0.6773 | 0.9465 | 0.7917 | 0.8508 | 0.8107 |
| STRRED | 0.8358 | 0.9770 | 0.8595 | 0.8310 | 0.8761 |
| SpEED-QA | 0.7895 | 0.9639 | 0.8812 | 0.7945 | 0.8587 |
| BRISQUE | 0.2638 | 0.5655 | 0.1051 | 0.7574 | 0.3961 |
| NIQE | 0.1769 | 0.5012 | 0.2351 | 0.4855 | 0.3362 |
| VIIDEO | 0.6593 | 0.7153 | 0.1621 | 0.3177 | 0.4667 |
| SAAM | 0.8691 | 0.8810 | 0.8413 | 0.9429 | 0.8796 |
| Training Set | Testing Set | PLCC | SRCC |
|---|---|---|---|
| LIVE | CSIQ | 0.7107 | 0.7290 |
| FERIT-RTRK | CSIQ | 0.4437 | 0.5302 |
| Data Size | Time of PEAs Detection | PLCC | SRCC | |
|---|---|---|---|---|
| Without Saliency | 1.11 GB | 6.47 h | 0.9557 | 0.8929 |
| With Saliency | 0.37 GB | 0.50 h | 0.9244 | 0.8810 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, L.; Yang, J.; Wang, Z.; Zhou, L.; Chen, W.; Xu, Y. Compressed Video Quality Index Based on Saliency-Aware Artifact Detection. Sensors 2021, 21, 6429. https://doi.org/10.3390/s21196429
Lin L, Yang J, Wang Z, Zhou L, Chen W, Xu Y. Compressed Video Quality Index Based on Saliency-Aware Artifact Detection. Sensors. 2021; 21(19):6429. https://doi.org/10.3390/s21196429
Chicago/Turabian StyleLin, Liqun, Jing Yang, Zheng Wang, Liping Zhou, Weiling Chen, and Yiwen Xu. 2021. "Compressed Video Quality Index Based on Saliency-Aware Artifact Detection" Sensors 21, no. 19: 6429. https://doi.org/10.3390/s21196429