
MSF-Net: Multi-Scale Feature Learning Network for Classification of Surface Defects of Multifarious Sizes


Abstract
:1. Introduction
- Artificial visual inspection, which has the disadvantages of low detection efficiency, high false detection rate and high missed detection rate, high labor intensity, and low speed.
- The non-contact detection method based on machine vision [2,3] usually adopts image processing algorithms or manual design feature extractors to combine the classifier. Liu T.I. [4] proposed a fuzzy logic expert system for roller bearing defect detection, the system combines frequency response and fuzzy reasoning and has achieved good results. Baygin et al. [5] used Otsu thresholding and Hough transform to extract features from the reference image for the problem of printed circuit board with defects and matched the image to be inspected with the reference image to accurately detect the missing holes on the circuit board. Zhang Lei et al. [6] proposed a fabric defect classification algorithm combining Local Binary Pattern (LBP) and Gray Level Co-occurrence Matrix (GLCM). The algorithm first uses the LBP algorithm to extract the local feature information of the image and then uses the GLCM to describe the overall texture information, and finally, the feature information of the two parts as a whole constructed as the input of the BP neural network, and a higher classification accuracy is obtained. Denis Sidorov et al. [7] proposed an automatic defect classification method based on the p-median clustering technique, the proposed method uses the p-median combinatorial optimization problem to complete the clustering problem, which can be sued in semiconductor and other manufacturing industries. In general, compared with artificial visual inspection methods, the above methods have the advantages of safety and reliability, high detection accuracy, and long-term operation in complex production environments, which effectively improves production efficiency and quality inspection efficiency. However, in a real and complex industrial environment, there are generally small differences between surface defects and background, low contrast, large differences in defect scales, and various types of defects. The design of image processing algorithm schemes and artificially designed feature extraction schemes typically requires rich expert experience and a large number of experiments, resulting in high cost and time consumption, and the effectiveness and generalization cannot be guaranteed, and it is difficult to obtain better detection results.
2. Related Work
2.1. AlexNet and VGGNet
2.2. GoogLeNet and ResNet
3. Methods
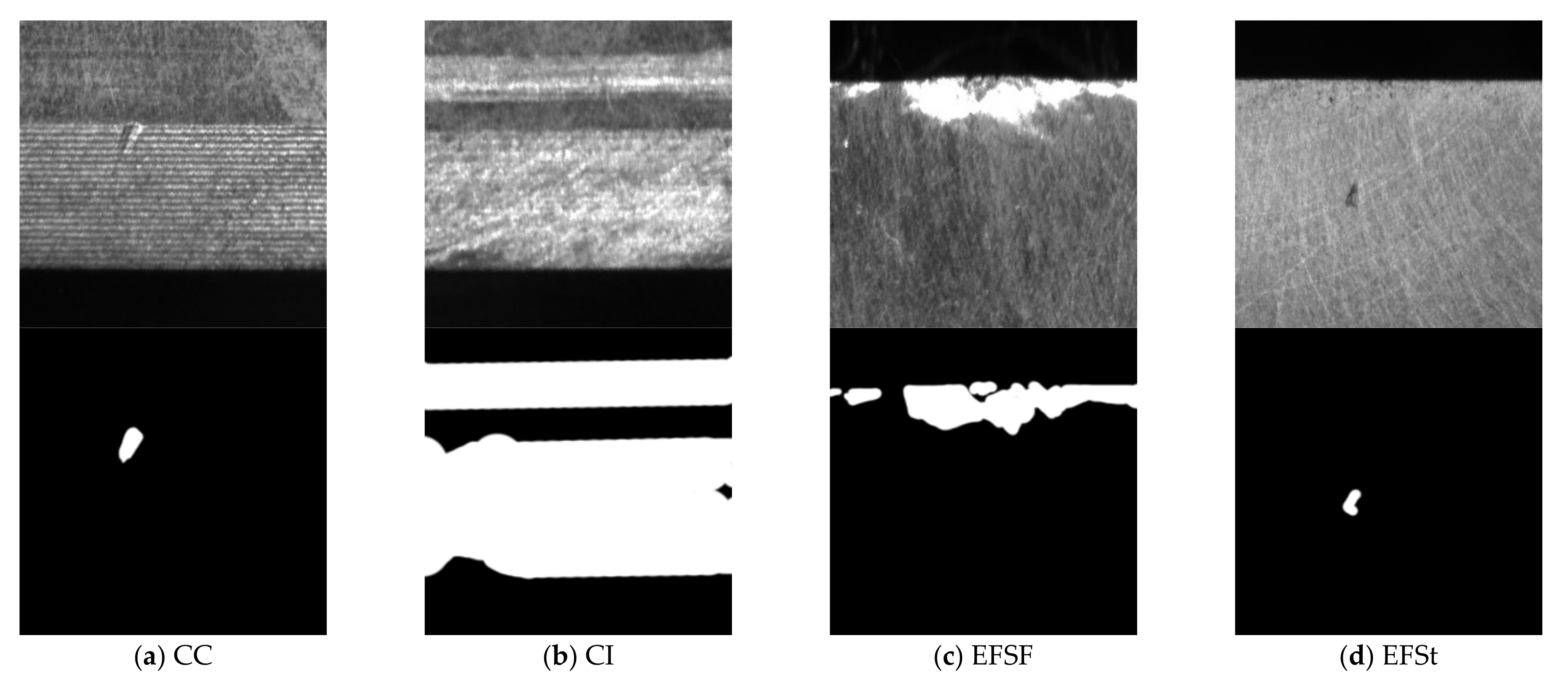
3.1. Data Set Preparation
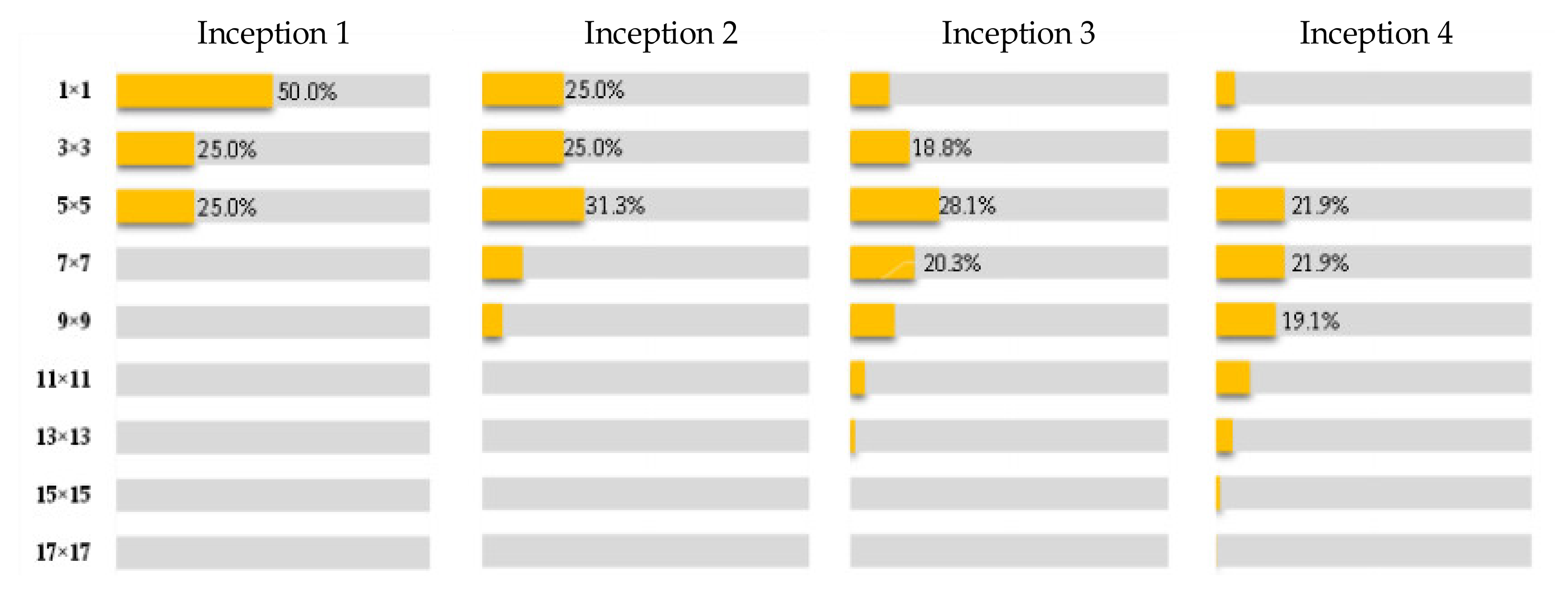
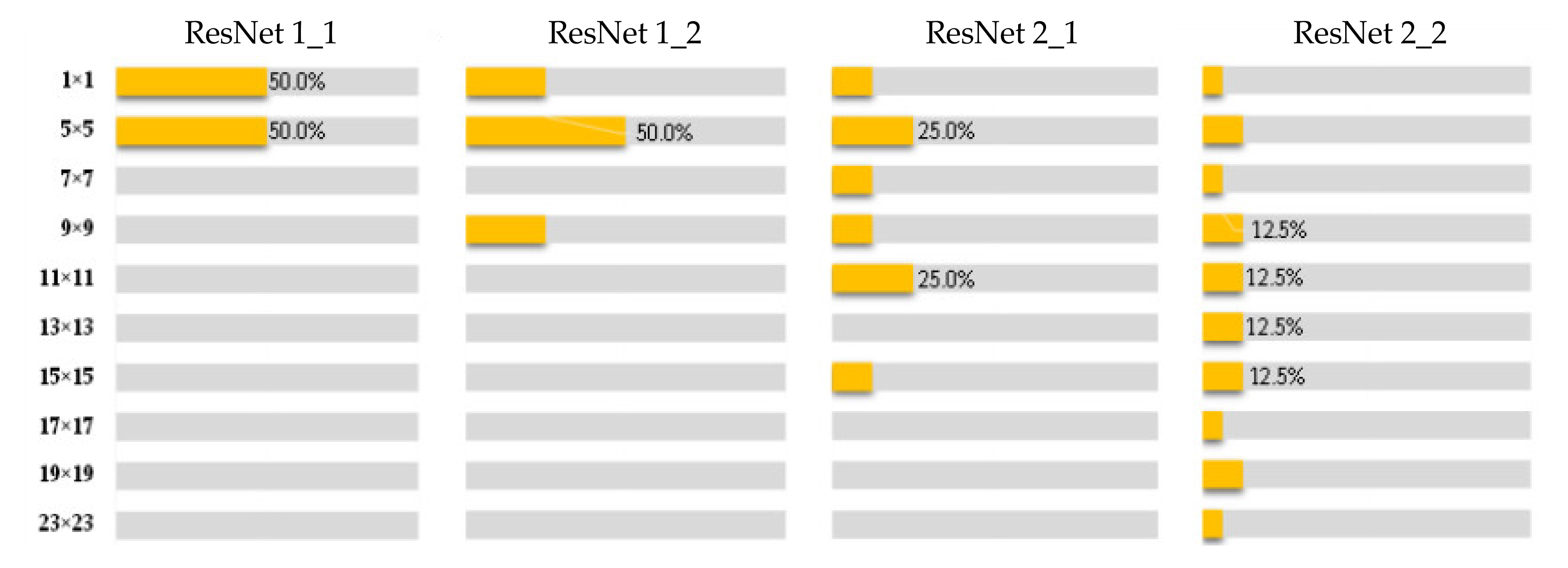
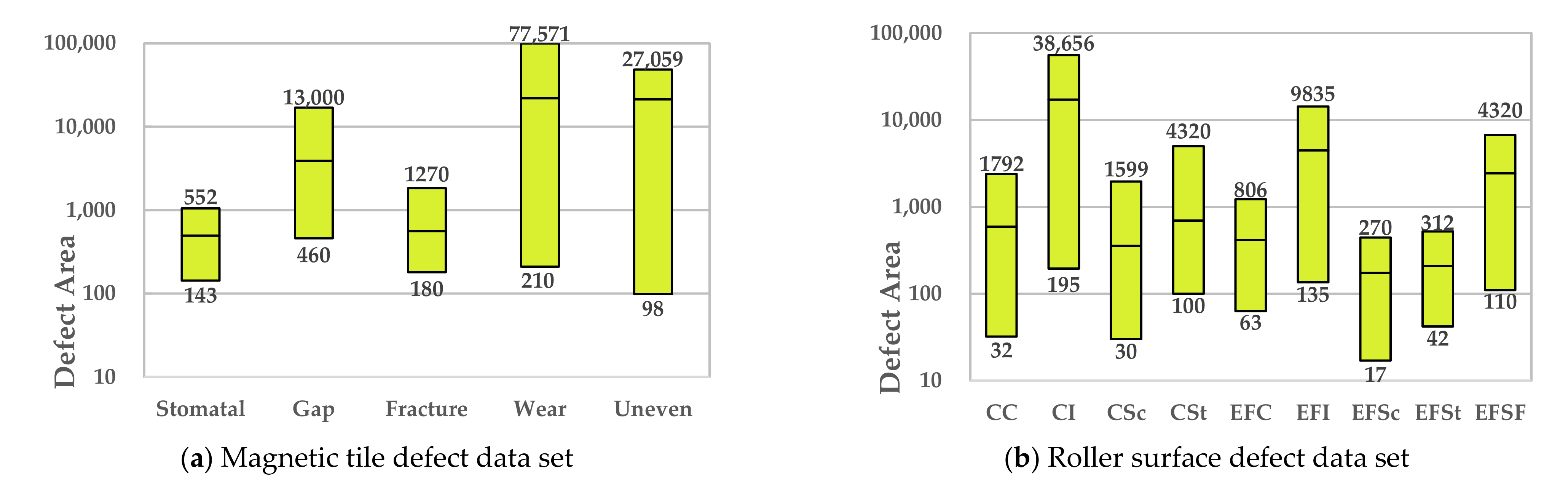
3.2. Sample Defect Size Analysis
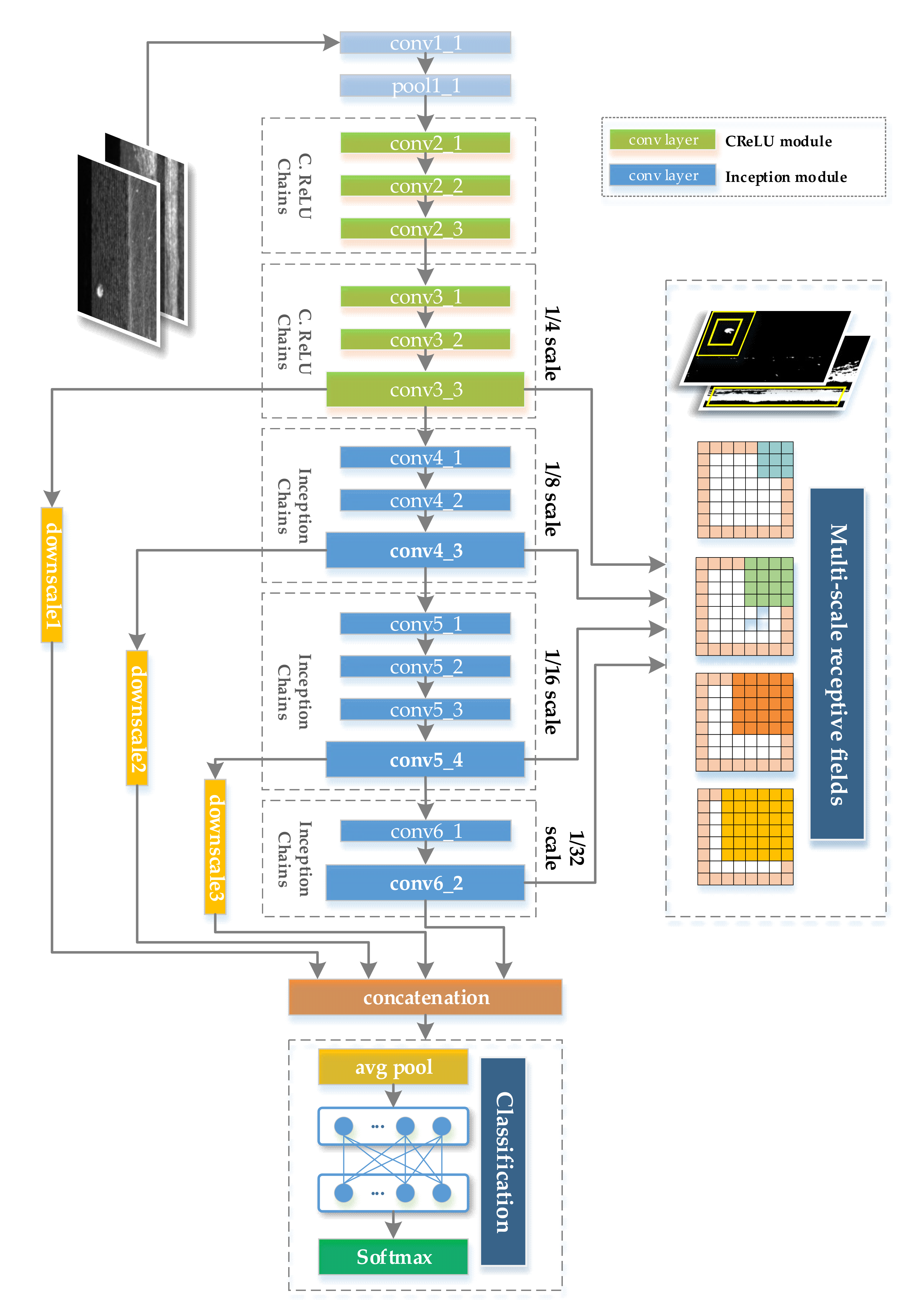
3.3. Multi-Scale Feature Learning Network Based on Dual Module Feature Extractor
- (1)
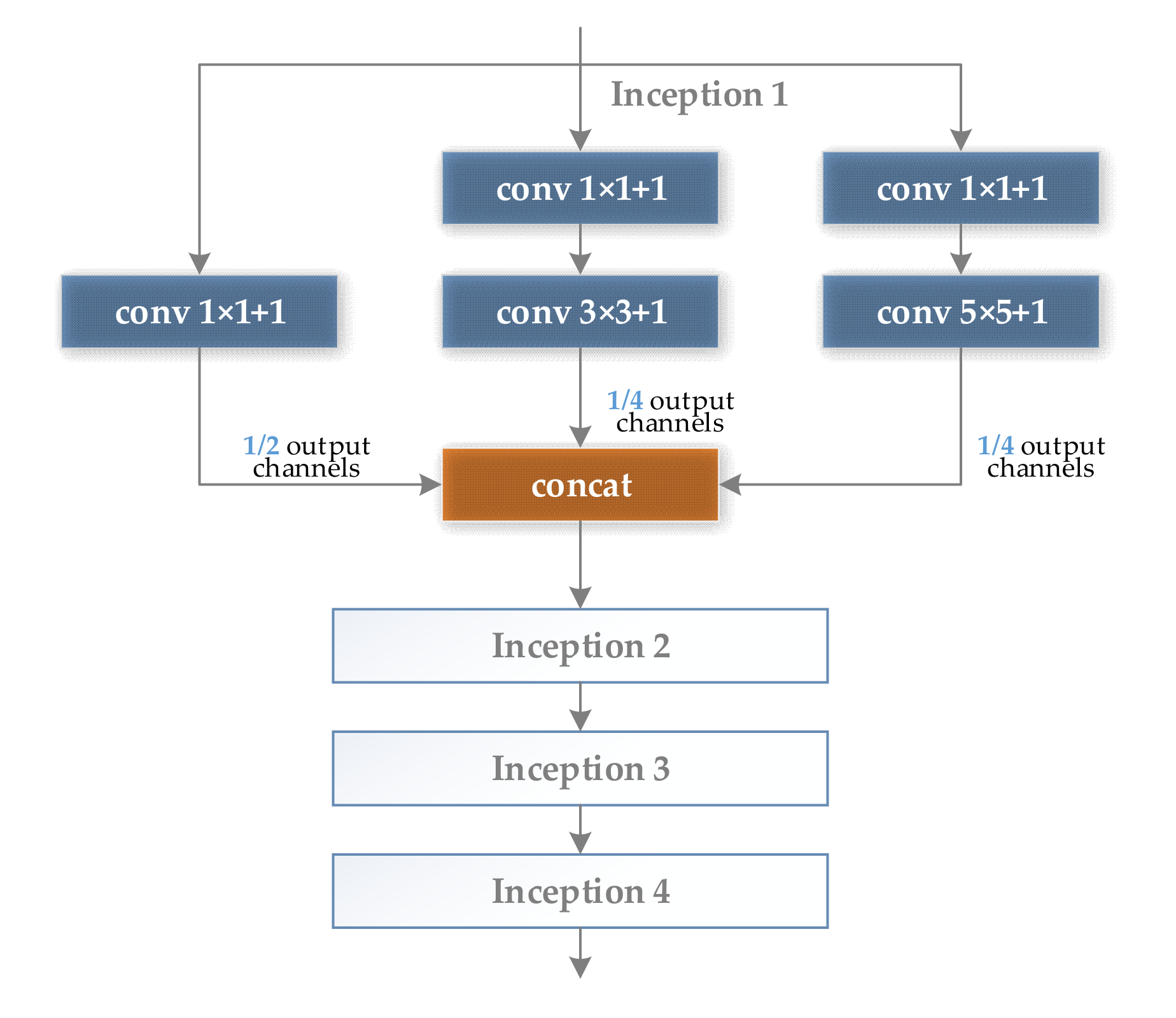
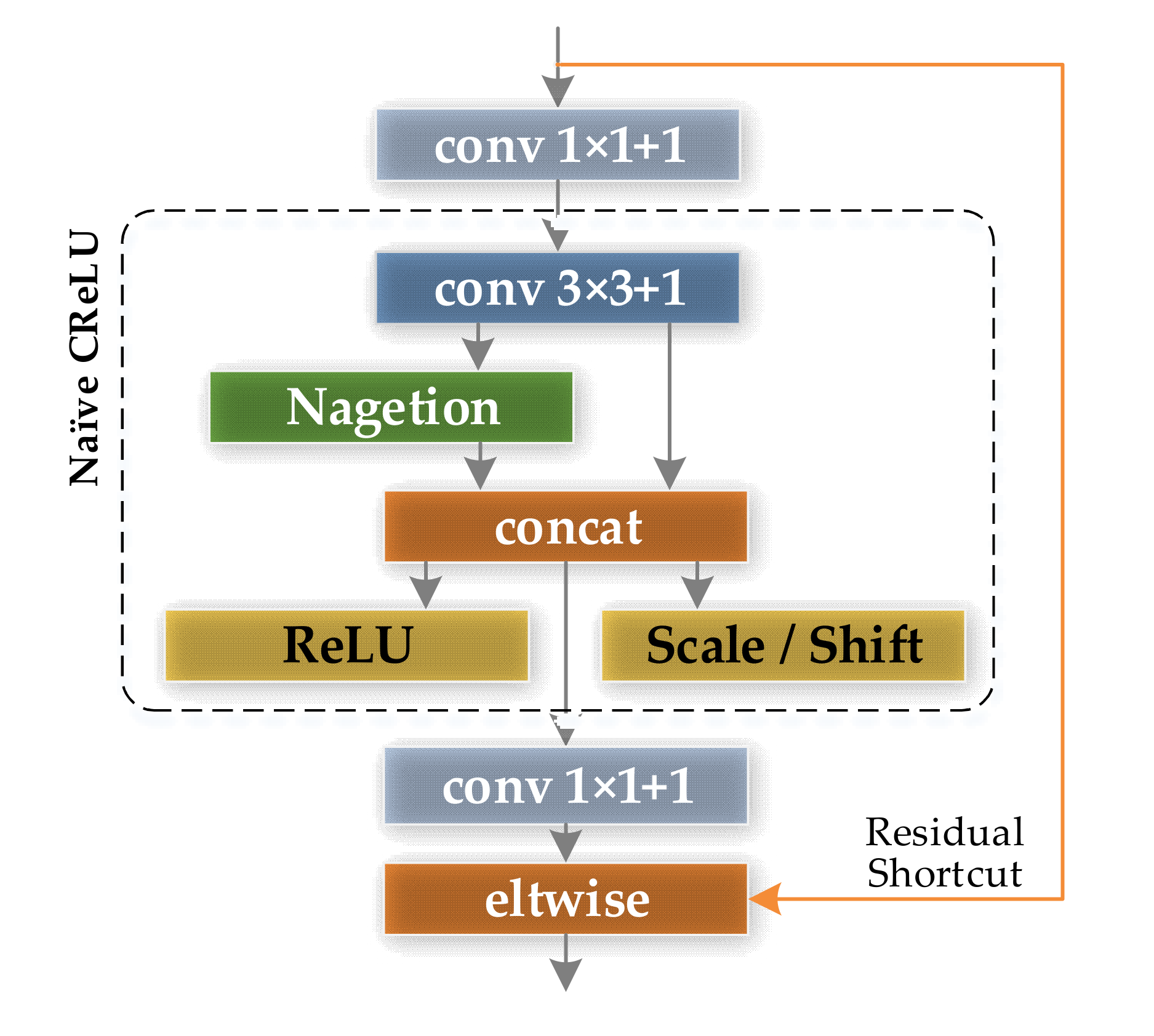
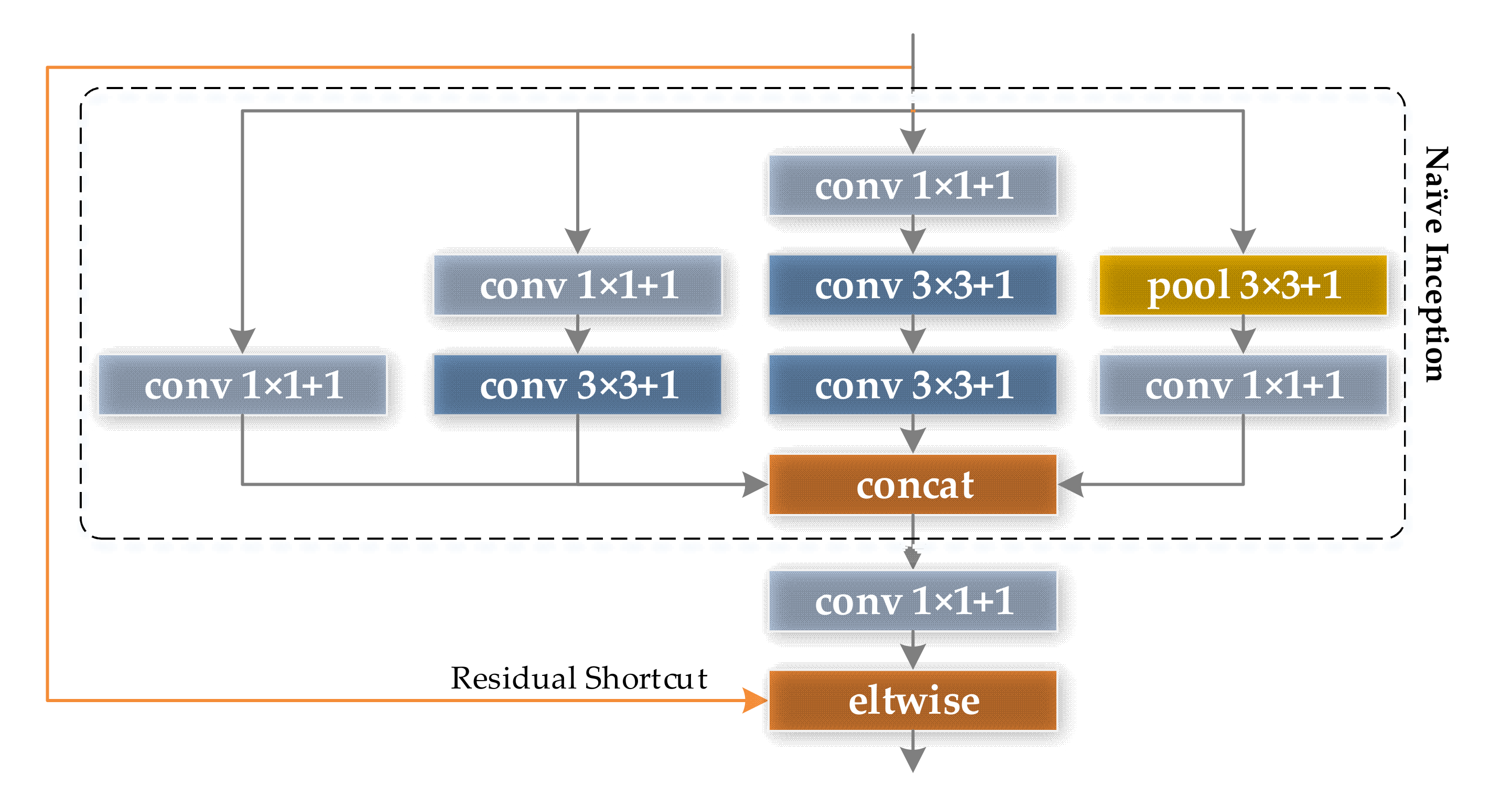
- Increase the diversity of the receptive field of a single convolution module in CNNsFrom the analysis of the receptive field of CNN in Section 2.1, it can be seen that single branch CNNs, such as AlexNet and VGGNet, have a relatively single receptive field scale. As the number of layers of the CNN deepens, the small-scale receptive field gradually disappears, which is not conducive to the feature expression of subtle defects in the classification task of surface defects.Therefore, this paper chooses the convolution module with branch structure as the basic unit of MSF-Net. Among the many representative modules with branch structures, the Inception module has favored domestic and foreign researchers in the field of target classification and detection, because of its lightweight design ideas and excellent characteristic expression ability and classification accuracy. In this paper, the Inception v3 [32] structure is used as the design prototype, as the feature extraction module in the middle and late stages of MSF-Net; and in the early stage of MSF-Net, in order to reduce the parameter quantity and calculation amount, this paper selects the CReLU module [33] as the prototype design feature extraction module. In this way, the Dual Module Feature (DMF) extractor is formed.
- (2)
- Increase the diversity of the receptive field of the feature map output by the last convolutional layer of CNNsIn order to improve the classification accuracy of multi-scale defect samples, it is necessary to ensure that the feature map output by the last convolutional layer before the fully connected layer has sufficient receptive field scales, especially the number of small-scale receptive fields. Therefore, inspired by HyperNet [34], the feature maps of several convolution modules with different scale receptive fields are combined to effectively increase the diversity of the receptive fields of the feature maps of the last convolution layer before the fully connected layer.
- (3)
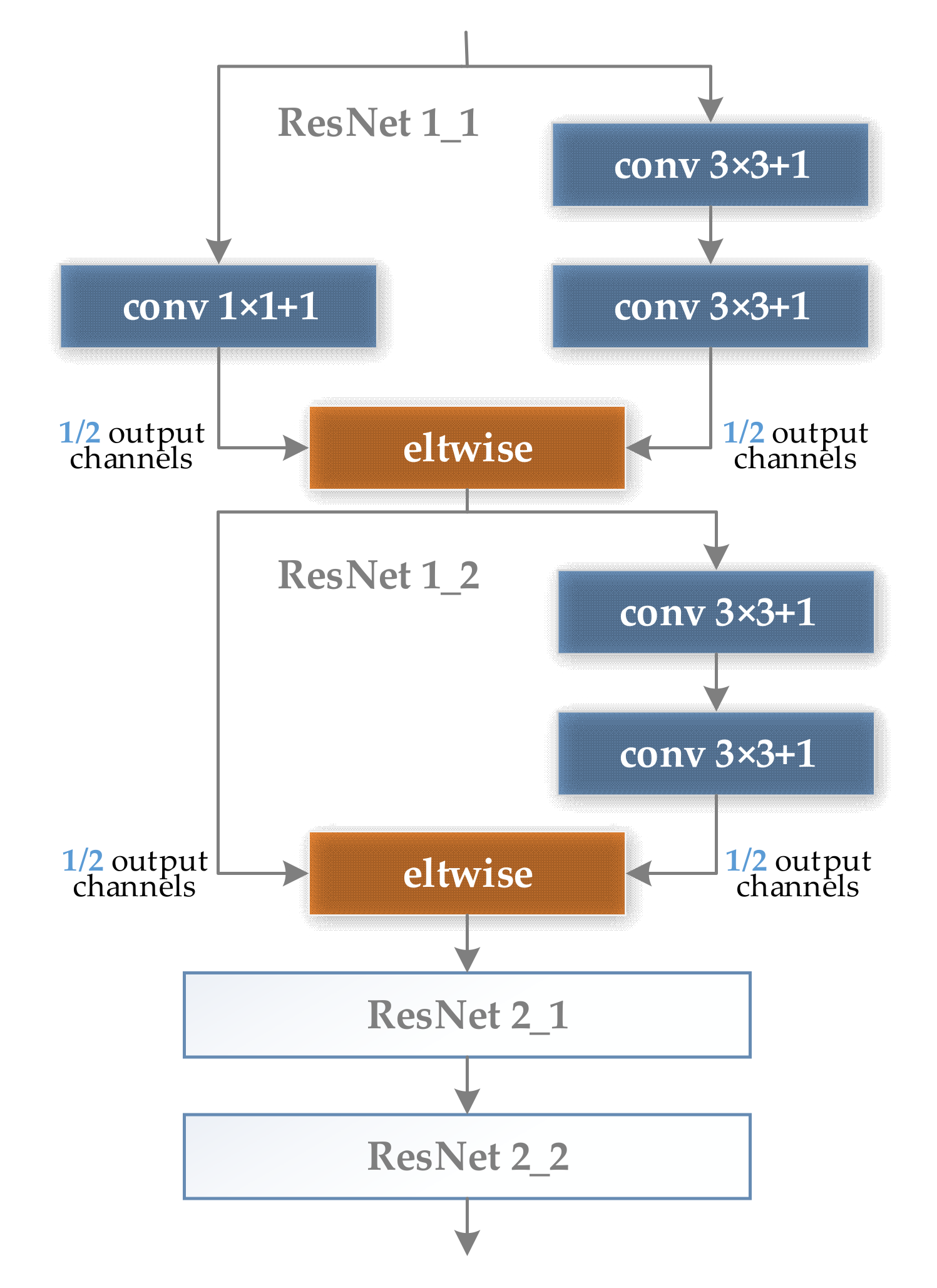
- Improve training efficiencyThe improvement of feature expression ability inevitably means the deepening of the number of layers of CNNs. Therefore, it is essential to improve training efficiency. MSF-Net improves training efficiency and avoids over-fitting by using residual shortcuts and batch normalization (BN) layers.
3.3.1. Dual Module Feature Extractor
Optimized CReLU Feature Extraction Modules
Optimized Inception V3 Module
3.3.2. Multi-Scale Feature Learning Network
- (1)
- At the input of the convolution modules conv3_1, conv4_1, conv5_1, and conv6_1, the convolution kernel with a size of 1 × 1 and a stride of 2 is used instead of the pooling layer to achieve the proportional reduction of the feature map size, so that the feature maps output by conv3, conv4, conv5, conv6 is 1/4, 1/8, 1/16, and 1/32 of the input image, respectively.
- (2)
- The output feature maps of the convolution modules conv3_3, conv4_3, and conv5_4 are down-sampled, and the average pooling layers with kernel sizes of 8 × 8, 4 × 4, and 2 × 2 are used, so that their respective output feature maps are consistent with the feature map output by conv6_2
- (3)
- The above four feature maps are combined and connected to form the final output feature map, the formula is as follows:
- (1)
- Avoiding expression bottlenecks in the early stage of feature extraction. That is, the information flow should avoid highly compressed convolution layers in the forward propagation process, and the width and height of the feature map should be gradually reduced in an orderly manner, especially for surface defect datasets with subtle defect features, it is not wise to compress the feature map too early. Therefore, the convolutional layer conv1_1 (size 3 × 3, stride 1) and pooling layer pool1_1 (size 3 × 3, stride 2) are concatenated to slow down the reduction speed of the feature map.
- (2)
- In the middle and late stages of feature extraction in CNNs, the width and depth of CNNs should be balanced as much as possible. That is, as the CNN deepens, the feature map gradually shrinks, and the output matrix dimension of each convolutional layer should gradually increase. Therefore, the number of modules, the feature map sizes, and the number of channels of the three module chains of conv 4, conv 5, and conv 6 are designed with full reference to Inception V1 [29] and Inception V3 [32] to improve the rationality of CNN’s evolution.
- (3)
- Average pooling layer is used to replace the fully connected layer, which can greatly reduce the number of parameters and save calculation costs. Specifically, MSF-Net uses an average pooling layer with a kernel size of 7 × 7 and a strider of 1 to replace the fully connected layer. It can be calculated from Table 4 that this adjustment can reduce 180,635,529 parameters.
- (4)
- The residual shortcut connections are used to effectively accelerate training and promote CNN’s convergence. Specially, almost every convolution module in MSF-Net, except conv1_1, uses a shortcut connection, which effectively avoids the problem of gradient disappearance and speeds up training.
4. Experimental Results and Analysis
4.1. Experimental Setup
4.2. CNNs for Comparison
- (1)
- Inception v3 and ResNet-50 are closer to MSF-Net in terms of the number of convolutional layers and parameters, as shown in Table 6, which makes the comparison of experimental results fairer.
- (2)
- MSF-Net is deeply influenced by GoogLeNet v3 in terms of the design of feature extraction modules, the number of modules, and the width and depth of CNN. Therefore, comparing MSF-Net with Inception v3 can more accurately assess the impact of CNN’s structure on classification performance.
- (3)
- Except conv1_1, all feature extraction modules of MSF-Net use residual shortcut connections.
4.3. Training Efficiency Evaluation of CNNs
- (1)
- Compared with ResNet-50 and Inception v3, MSF-Net’s parameters is reduced by more than 54%, which greatly reduces the computational cost, the most intuitive manifestation is that the number of epochs required for MSF-Net to achieve convergence is greatly reduced;
- (2)
- Compared with the Inception modules fully used by Inception v3, MSF-Net uses the optimized CReLU module in the early stage of feature extraction, the optimized CReLU module has outstanding performance in reducing computational costs, which effectively shortens the time consumption of forward back propagation and improves the training performance of MSF-Net.
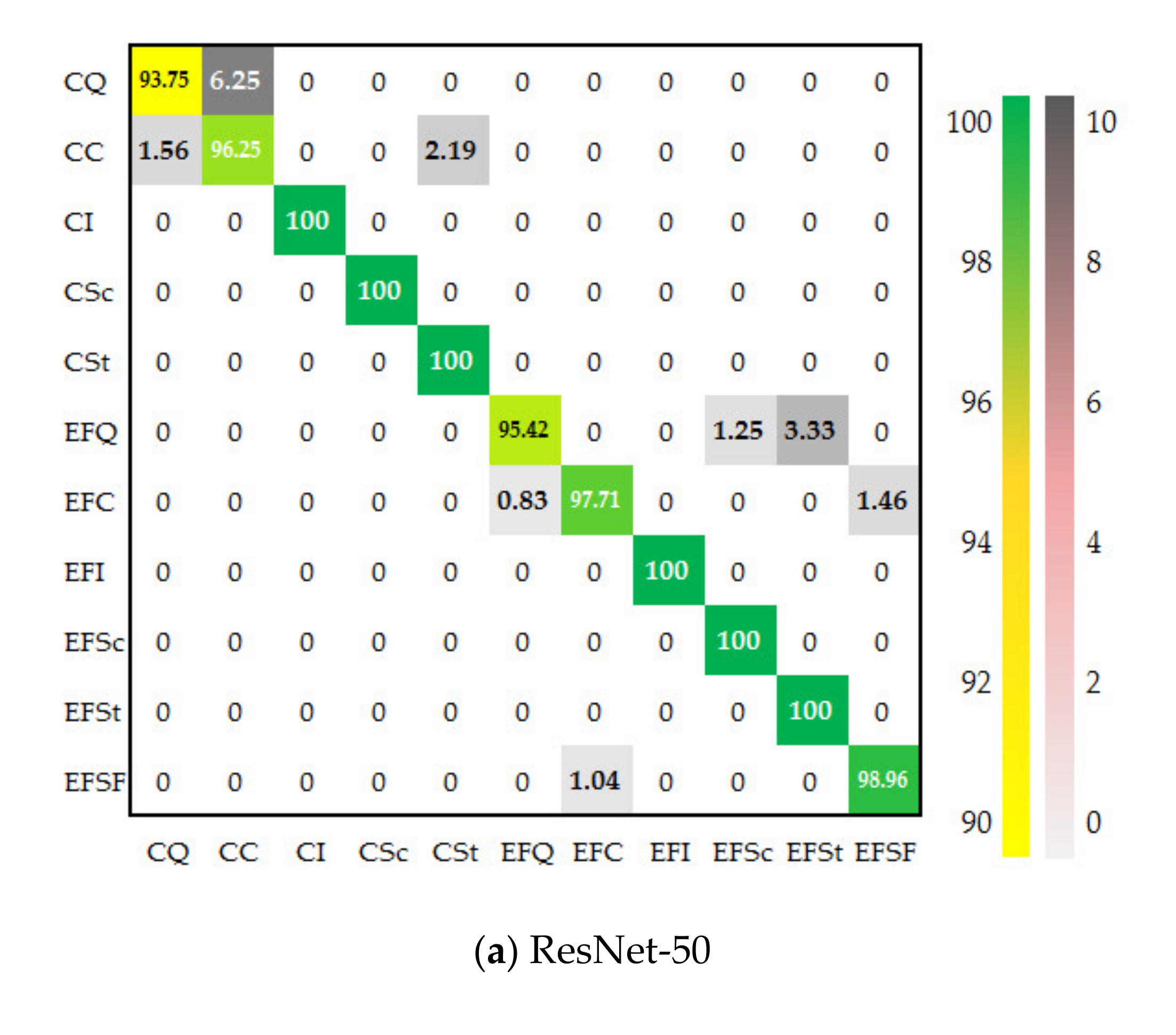
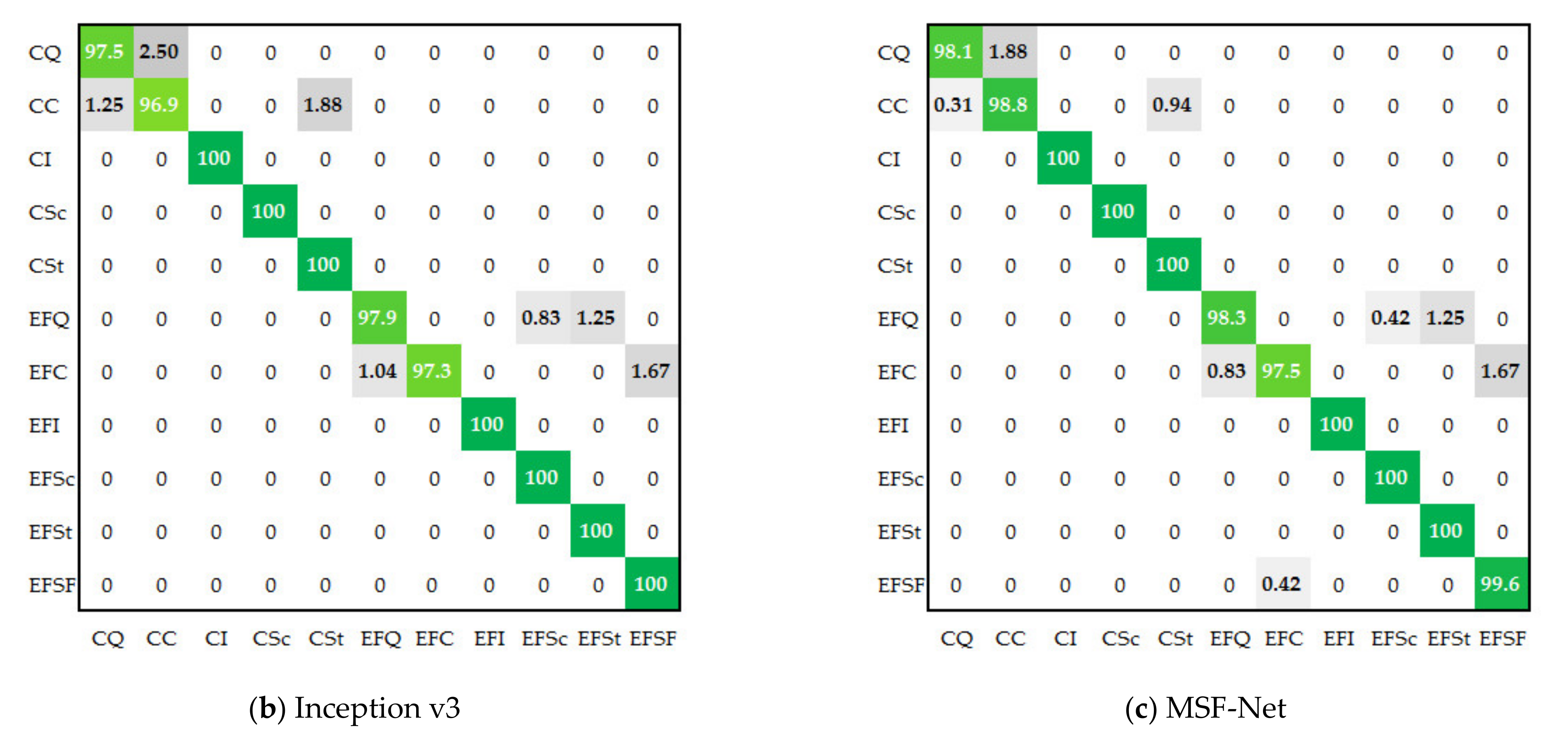
4.4. Classification Performance Evaluation on Two Multi-Scale Defect Data Sets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tao, X.; Hou, W.; Xu, D. A Survey of Surface Defect Detection Methods Based on Deep Learning. Acta Autom. Sin. 2020, 46, 1–18. [Google Scholar]
- Jing, J.; Liu, S.; Li, P.; Zhang, L. The fabric defect detection based on CIE L*a*b* color space using 2-D Gabor filter. J. Text. Inst. Proc. Abstr. 2016, 107, 1305–1313. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Sresakoolchai, J.; Thamba, A. Machine learning-aided identification of train weights from railway sleeper vibration. Insight Non-Destr. Test. Cond. Monit. 2021, 63, 151–159. [Google Scholar] [CrossRef]
- Liu, T.I.; Singonahalli, J.H.; Iyer, N.R. Detection of roller bearing defects using expert system and fuzzy logic. Mech. Syst. Signal Process. 1996, 10, 595–614. [Google Scholar] [CrossRef]
- Baygin, M.; Karakose, M.; Sarimaden, A.; Erhan, A.K.I.N. Machine vision based defect detection approach using image processing. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium, Malatya, Turkey, 16–17 September 2017; Institute of Electrical and Electronics Engineers: Malatya, Turkey, 2017; p. 8090292. [Google Scholar]
- Zhang, L.; Jing, J.; Zhang, H. Fabric defect classification based on LBP and GLCM. J. Fiber Bioeng. Inform. 2015, 8, 81–89. [Google Scholar] [CrossRef]
- Sidorov, D.; Wei, W.S.; Vasilyev, I.; Salerno, S. Automatic defects classification with p-median clustering technique. In Proceedings of the 2008 10th International Conference on Control, Automation, Robotics and Vision, Hanoi, Vietnam, 17–20 December 2008; pp. 775–780. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Huang, W.; Qiao, Y.; Yao, J. Text-Attentional Convolutional Neural Network for Scene Text Detection. IEEE Trans. Image Process. 2016, 25, 2529–2541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prasad, P.S.; Pathak, R.; Gunjan, V.K.; Rao, H.R. Deep learning based representation for face recognition. In ICCCE 2019; Springer: Singapore, 2020; pp. 419–424. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. CIRP Ann. Manuf. Technol. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Ren, R.; Hung, T.; Tan, K.C. A Generic Deep-Learning-Based Approach for Automated Surface Inspection. IEEE Trans. Cybern. 2017, 99, 1–12. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J.; Fricout, G. Steel defect classification with Max-Pooling Convolutional Neural Networks. In Proceedings of the International Joint Conference on Neural Networks, Brisbane, Australia, 10–15 June 2012; IEEE: New York, NY, USA, 2012; pp. 1–6. [Google Scholar]
- Guo, Z.; Zheng, H.; Xu, X.; Ju, J.; Zheng, Z.; You, C.; Gu, Y. Quality grading of jujubes using composite convolutional neural networks in combination with RGB color space segmentation and deep convolutional generative adversarial networks. J. Food Process. Eng. 2021, 44, e13620. [Google Scholar] [CrossRef]
- Deitsch, S.; Christlein, V.; Berger, S.; Buerhop-Lutz, C.; Maier, A.; Gallwitz, F.; Riess, C. Automatic classification of defective photovoltaic module cells in electroluminescence images. Sol. Energy 2019, 185, 455–468. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Zheng, H.; Guo, Z.; Wu, X.; Zheng, Z. SDD-CNN: Small Data-Driven Convolution Neural Networks for Subtle Roller Defect Inspection. Appl. Sci. 2019, 9, 1364. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1125–1134. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: New York, NY, USA, 2016; pp. 565–571. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Pelt, D.M.; Sethian, J.A. A mixed-scale dense convolutional neural network for image analysis. Proc. Natl. Acad. Sci. USA 2018, 115, 254–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rundo, L.; Han, C.; Zhang, J.; Hataya, R.; Nagano, Y.; Militello, C.; Ferretti, C.; Nobile, M.S.; Tangherloni, A.; Gilardi, M.C.; et al. CNN-based prostate zonal segmentation on T2-weighted MR images: A cross-dataset study. In Neural Approaches to Dynamics of Signal Exchanges; Springer: Singapore, 2020; pp. 269–280. [Google Scholar]
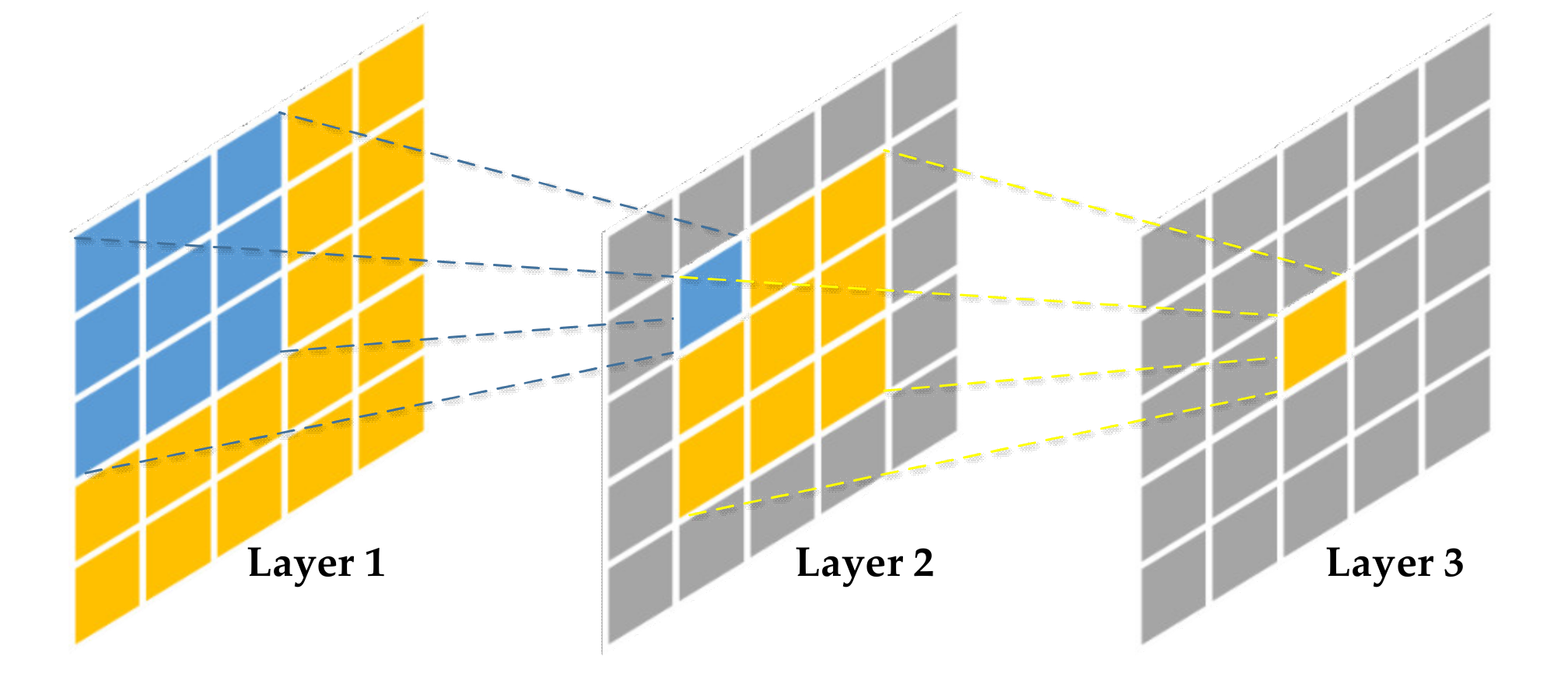
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 4898–4906. [Google Scholar]
- Tang, C.; Sheng, L.; Zhang, Z.; Hu, X. Improving Pedestrian Attribute Recognition with Weakly-Supervised Multi-Scale Attribute-Specific Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4997–5006. [Google Scholar]
- Kim, Y.; Kang, B.N.; Kim, D. San: Learning relationship between convolutional features for multi-scale object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 316–331. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, Y.; Qiu, C.; Guo, Y.; Wang, X.; Yuan, K. Surface Defect Saliency of Magnetic Tile. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 612–617. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 2818–2826. [Google Scholar]
- Shang, W.; Sohn, K.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2217–2225. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNNs | Feature Maps of the Last Convolution Layer | Receptive Field |
|---|---|---|
| AlexNet | pool5 | 195 × 195 |
| VGG-16 | pool5 | 212 × 212 |
| CNNs | Feature Map of the Last Convolutional Layer | Minimal Receptive Field | Maximum Receptive Field |
|---|---|---|---|
| GoogLeNet | pool5/7 × 7_s1 | 267 × 267 | 907 × 907 |
| ResNet-18 | pool5 | 203 × 203 | 627 × 627 |
| Category Name | EFQ * | EFC | EFI | EFSc | EFSt | EFSF |
|---|---|---|---|---|---|---|
| Number of samples | 1500 | 470 | 70 | 160 | 90 | 220 |
| Sample example |  |  |  |  |  |  |
| Category name | CQ | CC | CI | CSc | CSt | |
| Number of samples | 1000 | 350 | 155 | 30 | 105 | |
| Sample example |  |  |  |  |  |
| Layername | Type | Output Dimension | Depth | CReLU Output | Inception Output | Parameters | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| #1×1-3×3-1×1 | Pool Proj | #1×1 | #3×3 | #5×5 | #1×1 out | |||||
| conv1_1 | 3 × 3 CReLU | 224 × 224 × 32 | 1 | NA-16-NA | / | 480 | ||||
| pool1_1 | 3 × 3 Max pool. | 112 × 112 × 32 | 0 | / | / | |||||
| conv2_1 | 3 × 3 CReLU | 112 × 112 × 64 | 3 | 24-24-64 | / | 13,440 | ||||
| conv2_2 | 3 × 3 CReLU | 112 × 112 × 64 | 3 | 24-24-64 | 13,440 | |||||
| conv2_3 | 3 × 3 CReLU | 112 × 112 × 64 | 3 | 24-24-64 | 13,440 | |||||
| conv3_1 | 3 × 3 CReLU | 56 × 56 × 128 | 3 | 48-48-128 | / | 53,760 | ||||
| conv3_2 | 3 × 3 CReLU | 56 × 56 × 128 | 3 | 48-48-128 | 53,760 | |||||
| conv3_3 | 3 × 3 CReLU | 56 × 56 × 128 | 3 | 48-48-128 | 53,760 | |||||
| conv4_1 | Inception | 28 × 28 × 256 | 4 | / | 32 | 64 | 96-128 | 16-32-32 | 256 | 322,560 |
| conv4_2 | Inception | 28 × 28 × 256 | 4 | 32 | 64 | 96-128 | 16-32-32 | 256 | 322,560 | |
| conv4_3 | Inception | 28 × 28 × 256 | 4 | 32 | 64 | 96-128 | 16-32-32 | 256 | 322,560 | |
| conv5_1 | Inception | 14 × 14 × 512 | 4 | / | 64 | 128 | 128-192 | 32-96-96 | 512 | 1,040,384 |
| conv5_2 | Inception | 14 × 14 × 512 | 4 | 64 | 128 | 128-192 | 32-96-96 | 512 | 1,040,384 | |
| conv5_3 | Inception | 14 × 14 × 512 | 4 | 64 | 128 | 128-192 | 32-96-96 | 512 | 1,040,384 | |
| conv5_4 | Inception | 14 × 14 × 512 | 4 | 64 | 128 | 128-192 | 32-96-96 | 512 | 1,040,384 | |
| conv6_1 | Inception | 7 × 7 × 1024 | 4 | / | 128 | 256 | 160-320 | 32-128-128 | 1024 | 3,010,560 |
| conv6-2 | Inception | 7 × 7 × 1024 | 4 | 128 | 256 | 160-320 | 32-128-128 | 1024 | 3,010,560 | |
| concat | Concatenation | 7 × 7 × 1920 | 0 | / | / | / | ||||
| avg pool | 7 × 7 Avg pool. | 1 × 1 × 1920 | 0 | |||||||
| linear | Inner product | 1 × 1 × | 1 | 19,200 | ||||||
| Total | 47 | 11,371,616 | ||||||||
| CPU | Intel E3-1230 V2*2 (3.30 GHz) | RAM | 16 GB DDR3 | GPU | NVIDIA GTX-1080Ti |
| OS | Ubuntu 16.04 LTS | Software | Visual Studio Code with Python 2.7 | ||
| CNNs | Convolution Layers | Parameters |
|---|---|---|
| Inception v3 | 48 | 24,734,048 |
| ResNet-50 | 50 | ~25.5 × 106 |
| MSF-Net | 56 | 11,371,616 |
| CQ | CC | CI | CSc | CSt | Precision | micro-F1 | ||
|---|---|---|---|---|---|---|---|---|
| ResNet-50 | 93.75 | 96.25 | 100.00 | 100.00 | 100.00 | 98.46 ± 0.017 | 98.381 | |
| Inception v3 | 97.50 | 96.88 | 100.00 | 100.00 | 100.00 | 99.09 ± 0.008 | 99.055 | |
| MSF-Net | 98.13 | 98.75 | 100.00 | 100.00 | 100.00 | 99.29 ± 0.006 | 99.301 | |
| EFQ | EFC | EFI | EFSc | EFSt | EFSF | Recall | macro-F1 | |
| ResNet-50 | 95.42 | 97.71 | 100.00 | 100.00 | 100.00 | 98.96 | 98.44 ± 0.022 | 98.367 |
| Inception v3 | 97.92 | 97.29 | 100.00 | 100.00 | 100.00 | 99.79 | 99.06 ± 0.013 | 99.051 |
| MSF-Net | 98.33 | 97.50 | 100.00 | 100.00 | 100.00 | 99.58 | 99.29 ± 0.009 | 99.298 |
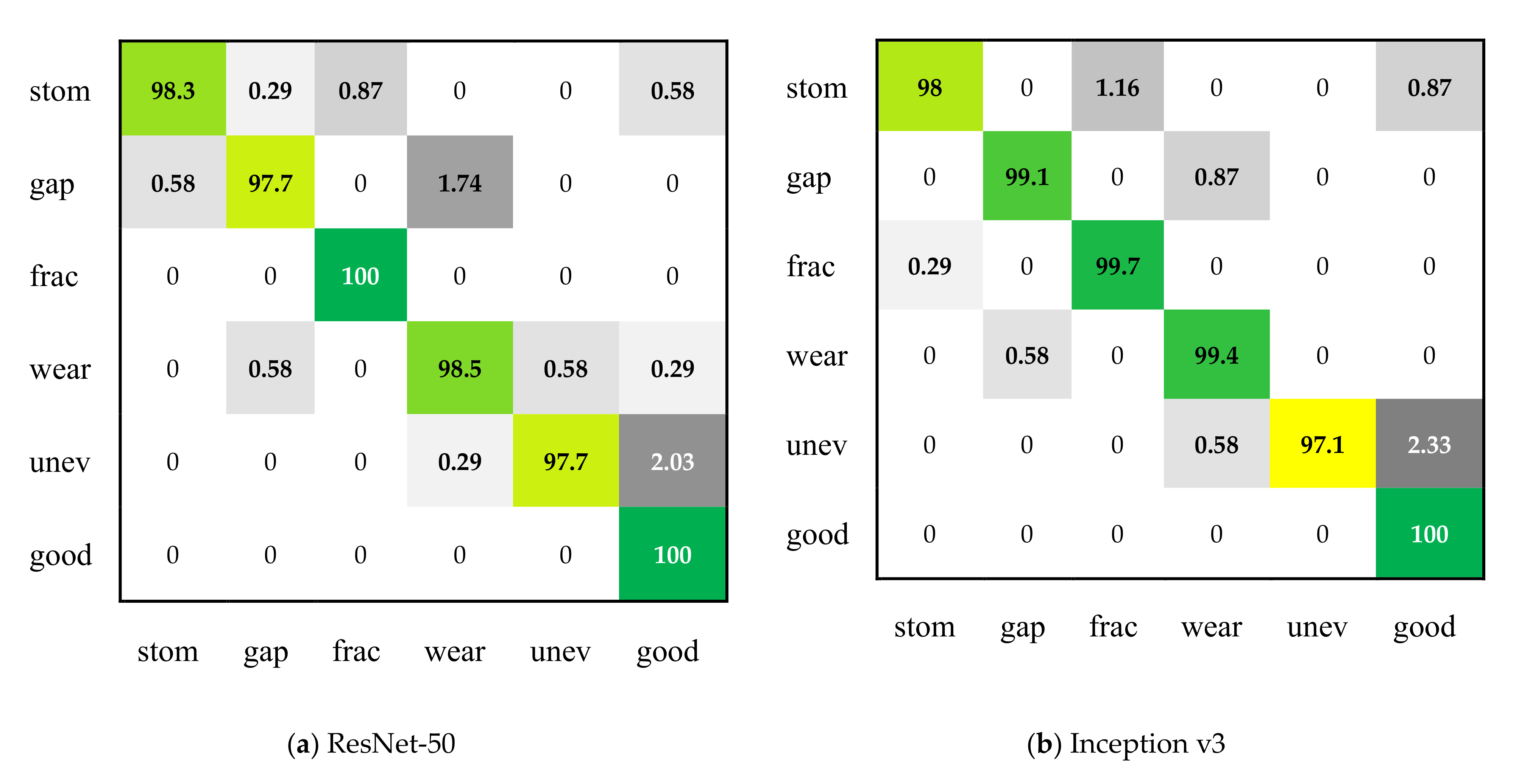
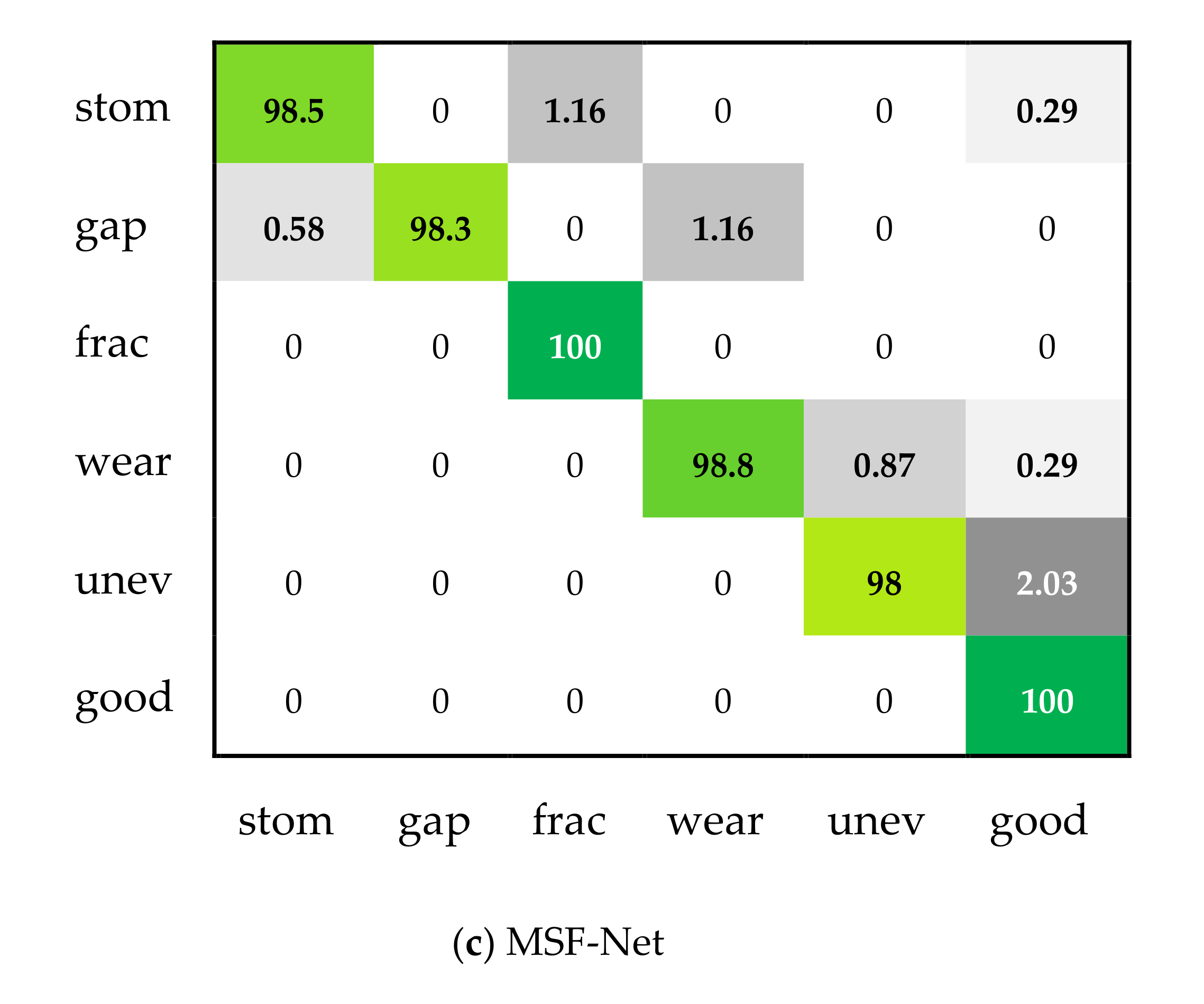
| Stomatal | Gap | Fracture | Precision | Micro-F1 | |
|---|---|---|---|---|---|
| ResNet-50 | 98.26% | 97.67% | 100.00% | 98.70 ± 0.008 | 98.70 |
| Inception v3 | 97.97% | 99.13% | 99.71% | 98.90 ± 0.010 | 98.90 |
| MSF-Net | 98.55% | 98.26% | 100.00% | 98.94 ± 0.007 | 98.94 |
| Wear | Uneven | Good | Recall | Macro-F1 | |
| ResNet-50 | 98.55% | 97.67% | 100.00% | 98.69 ± 0.009 | 98.69 |
| Inception v3 | 99.42% | 97.09% | 100.00% | 98.89 ± 0.010 | 98.89 |
| MSF-Net | 98.84% | 97.97% | 100.00% | 98.93 ± 0.008 | 98.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, P.; Guo, Z.; Liang, L.; Xu, X. MSF-Net: Multi-Scale Feature Learning Network for Classification of Surface Defects of Multifarious Sizes. Sensors 2021, 21, 5125. https://doi.org/10.3390/s21155125
Xu P, Guo Z, Liang L, Xu X. MSF-Net: Multi-Scale Feature Learning Network for Classification of Surface Defects of Multifarious Sizes. Sensors. 2021; 21(15):5125. https://doi.org/10.3390/s21155125
Chicago/Turabian StyleXu, Pengcheng, Zhongyuan Guo, Lei Liang, and Xiaohang Xu. 2021. "MSF-Net: Multi-Scale Feature Learning Network for Classification of Surface Defects of Multifarious Sizes" Sensors 21, no. 15: 5125. https://doi.org/10.3390/s21155125