
INIM: Inertial Images Construction with Applications to Activity Recognition


Abstract
:1. Introduction
- Feature Based: features are extracted from the raw signals of the inertial sensors and used in classical machine learning algorithms.
- One Dimensional Deep Learning (1D-DL): the raw inertial sensor signals are plugged into one dimensional networks.
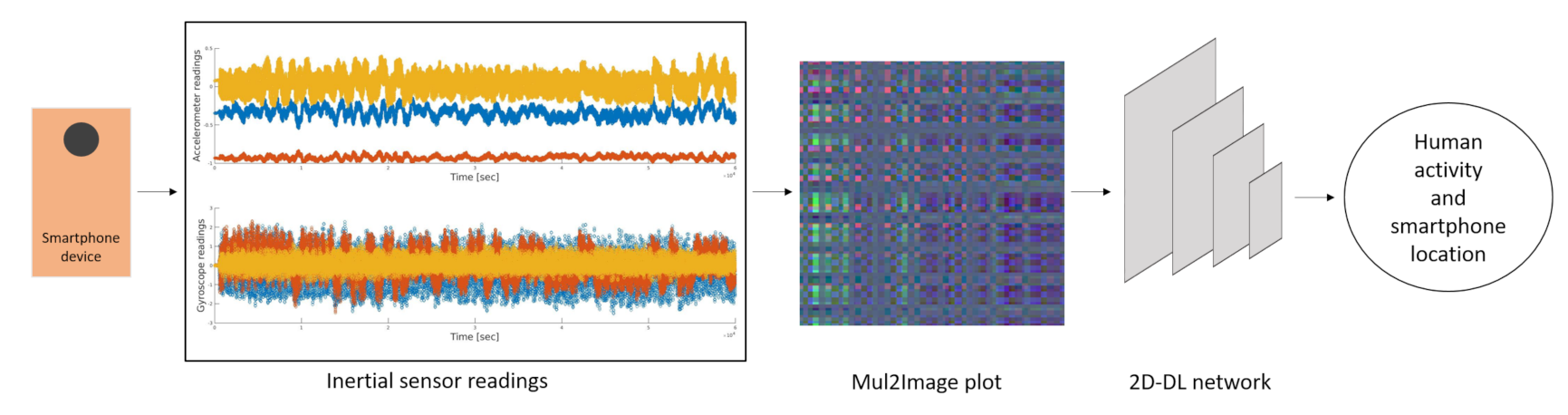
- Two Dimensional Deep Learning (2D-DL): the raw inertial sensors are transformed into two dimensional images and used as input for a network with the same dimensions.
- Encoding. A novel time series encoding approach based on accelerometers and gyroscopes readings. The three-axes accelerometers and three axes gyroscopes signals are encoded into a single RGB image.
- Transfer Learning. To initialize the backbone deep-learning architecture, transfer-learning is applied form a residual network trained on the ImageNet [30] dataset. The dataset contains one thousand different labels and commonly used in computer vision domain. That is, the proposed transfer learning is performed between the computer vision domain to the inertial sensor domain.
2. Related Work Formulation—Iss2Image
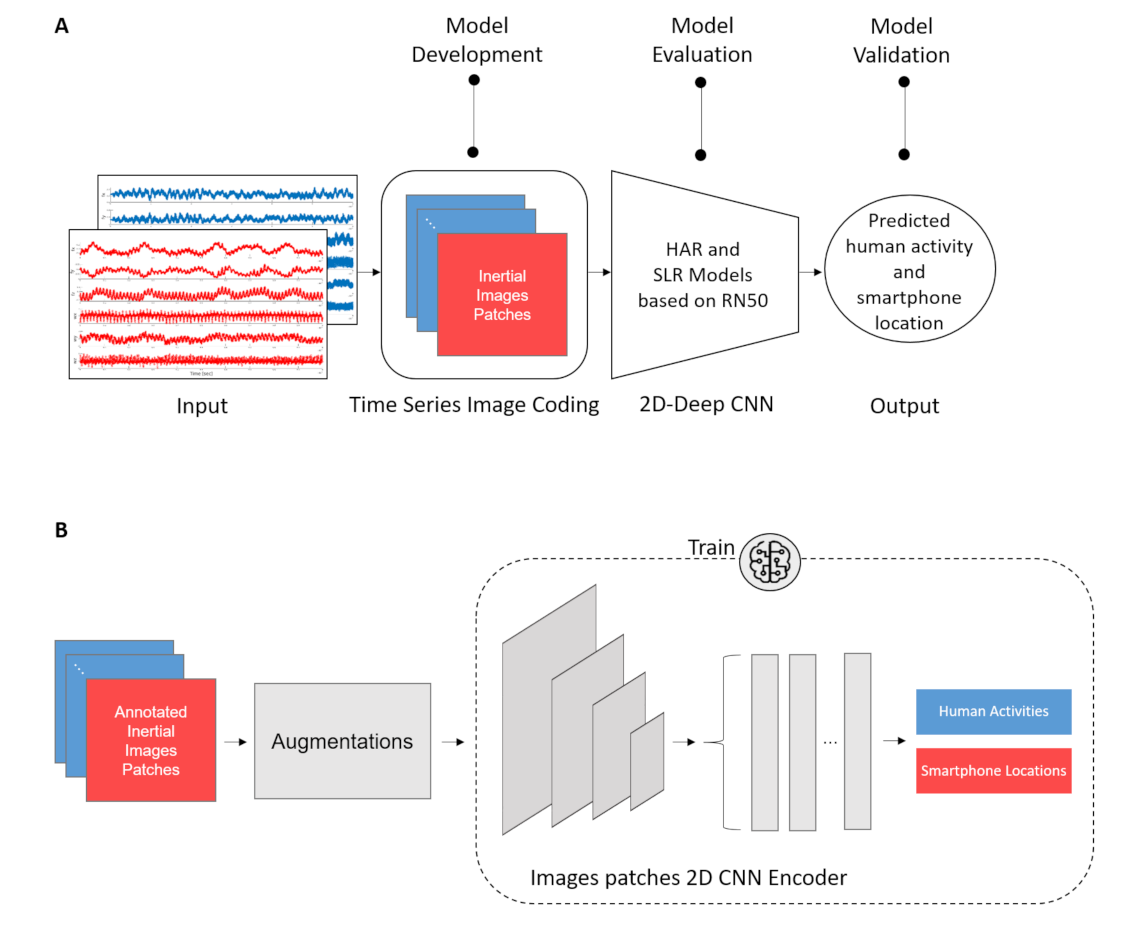
3. INIM: Inertial Images
3.1. Encoding Time-Series Signals to Inertial Images
- Step 1: Normalize the specific force vector, , (accelerometer output):where is the normalized specific force vector defined at epoch (time index) k by its three components:
- Step 2: The normalized accelerometer signals from n epochs are stacked in matrix :
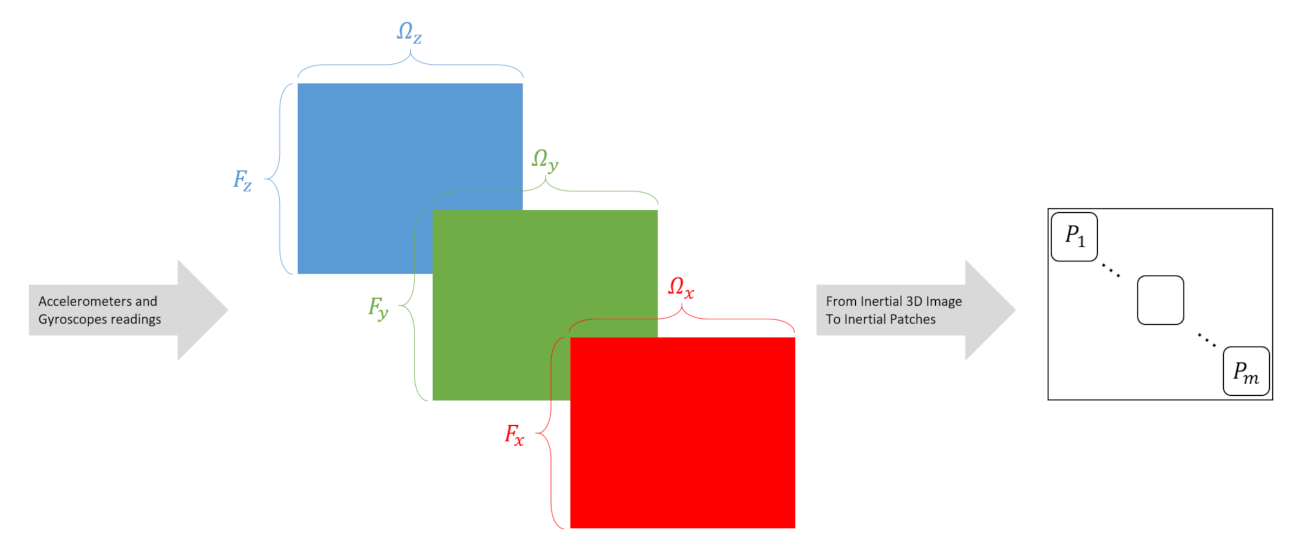
- Step 3: Each angular velocity measurement (gyroscope output) vectorfrom n samples are used to construct the following matrix:
- Then, the inertial image, termed INIM, is constructed stacking the three layers:
- Step 5: The values of (19) are scaled in the range of by multiplying them by 255.
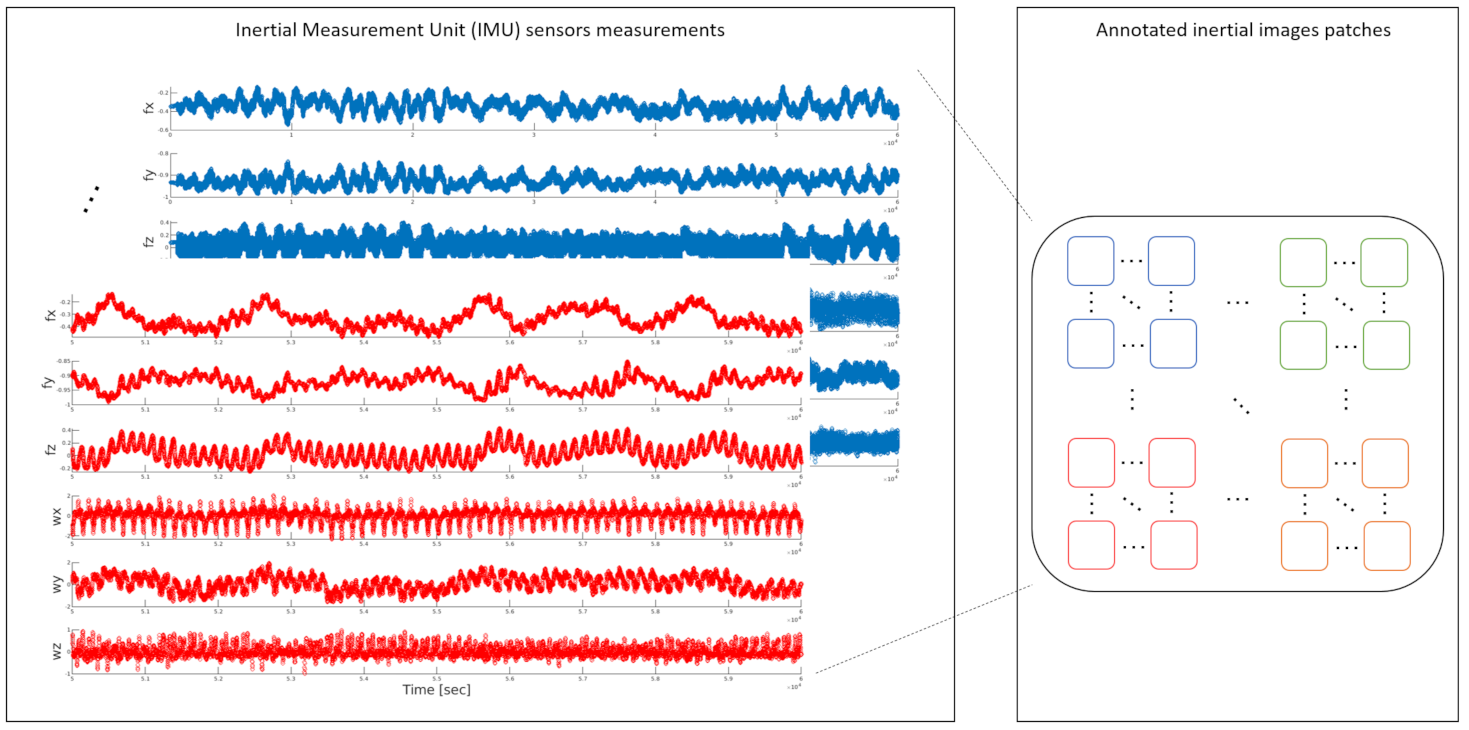
- Step 6: Finally, the image is cropped into m non-overlapped patches based on the network input size s, as follows:where , is of dimension .Notice that the total number of patches is , yet we require no overlap between the accelerometer and gyroscopes data. Therefore, only the diagonal patches are taken into account, resulting in patches, as illustrated in Figure 2.
3.2. Backbone 2D Network Architectures
3.3. Summary
4. Analysis and Results
4.1. Datasets
- HAR1 [33]. This dataset was recorded, with 50Hz sampling rate, by 10 people. Five sets of inertial sensors were placed in: right jeans pocket, left jeans pocket, belt, right upper arm, and right wrist. Seven human activities were considered: Biking, Stationary, Sitting, Downstairs, Upstairs, Walking, and Jogging.
- HAR2 [34]. In this dataset 15 people (8 males/ 7 females) recorded inertial data sampled in 50Hz using seven sets of inertial sensors, each placed in a different location on the user: chest, forearm, head, shin, thigh, upper arm, and waist. There eight types of human activities were addressed: Stationary, Sitting, Downstairs, Upstairs, Walking, Jogging, Jumping, and Lying. In this work, only the first six activities were considered as they are most relevant to indoor navigation activities.
- HAR3 and HAR4 [35]. This dataset was recorded using three sets of inertial sensors: on the chest, attached over the wrist on the dominant arm, and on the dominant side’s ankle. Nine people collected the data which were sampled at 100 Hz. The dataset contains 18 different user activities, some describing dynamics related human activities like in HAR1 and HAR2 and some describing working with home appliances activities. In this work the activities of Downstairs and Upstairs were chosen to construct the HAR3 dataset. HAR4 datasets, contains Ironing and Vacuum cleaning activities. In that manner, distinguish is made between the activities types and nature.
- SLR [36]. In this dataset, recordings were made during walking. Seven people, each with a different smartphone, recorded 190 minuets of inertial data in sampling rate between 25 and 100 Hz. There, four smartphone modes were addressed: Pocket, Texting, Swing, and Talking.
4.2. Experimental Setup
4.3. Encoders: Image Size and Computational Speed
4.4. SLR
4.5. HAR
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Mul2Image (Ours) | |
|---|---|---|
| With Data Augmentation | Without Data Augmentation | |
| Jogging | 99.6%/99.1% | 98.2%/88.4% |
| Sitting | 95.3%/97.0% | 92.9%/94.8% |
| Downstairs | 99.1%/88.0% | 98.9%/90.1% |
| Upstairs | 98.9%/93.1% | 98.1%/73.3% |
| Stationary | 80.3%/42.1% | 79.6%/66.5% |
| Walking | 98.7%/85.4% | 96.1%/85.8% |
| Biking | 94.8%/96.6% | 82.5%/77.7% |
References
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A framework for hand gesture recognition based on accelerometer and EMG sensors. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Xu, R.; Zhou, S.; Li, W.J. MEMS accelerometer based nonspecific-user hand gesture recognition. IEEE Sens. J. 2011, 12, 1166–1173. [Google Scholar] [CrossRef]
- Taylor, W.; Shah, S.A.; Dashtipour, K.; Zahid, A.; Abbasi, Q.H.; Imran, M.A. An intelligent non-invasive real-time human activity recognition system for next-generation healthcare. Sensors 2020, 20, 2653. [Google Scholar] [CrossRef] [PubMed]
- Vepakomma, P.; De, D.; Das, S.K.; Bhansali, S. A-Wristocracy: Deep learning on wrist-worn sensing for recognition of user complex activities. In Proceedings of the 2015 IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 9–12 June 2015; pp. 1–6. [Google Scholar]
- Sun, Z.; Mao, X.; Tian, W.; Zhang, X. Activity classification and dead reckoning for pedestrian navigation with wearable sensors. Meas. Sci. Technol. 2008, 20, 015203. [Google Scholar] [CrossRef]
- Guo, S.; Xiong, H.; Zheng, X.; Zhou, Y. Indoor pedestrian trajectory tracking based on activity recognition. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 6079–6082. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Avci, A.; Bosch, S.; Marin-Perianu, M.; Marin-Perianu, R.; Havinga, P. Activity recognition using inertial sensing for healthcare, wellbeing and sports applications: A survey. In Proceedings of the 23th International Conference on Architecture of Computing Systems, Hannover, Germany, 22–23 February 2010; pp. 1–10. [Google Scholar]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef]
- Elhoushi, M.; Georgy, J.; Noureldin, A.; Korenberg, M. Online motion mode recognition for portable navigation using low-cost sensors. Navig. J. Inst. Navig. 2015, 62, 273–290. [Google Scholar] [CrossRef]
- Klein, I.; Solaz, Y.; Ohayon, G. Pedestrian dead reckoning with smartphone mode recognition. IEEE Sens. J. 2018, 18, 7577–7584. [Google Scholar] [CrossRef]
- Fang, S.H.; Fei, Y.X.; Xu, Z.; Tsao, Y. Learning transportation modes from smartphone sensors based on deep neural network. IEEE Sens. J. 2017, 17, 6111–6118. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Kevin, I.; Wang, K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-learning-enhanced human activity recognition for Internet of healthcare things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Asraf, O.; Shama, F.; Klein, I. PDRNet: A Deep-Learning Pedestrian Dead Reckoning Framework. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Chen, C.; Lu, X.; Markham, A.; Trigoni, N. Ionet: Learning to cure the curse of drift in inertial odometry. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, Q.; Ye, L.; Luo, H.; Men, A.; Zhao, F.; Huang, Y. Pedestrian stride-length estimation based on LSTM and denoising autoencoders. Sensors 2019, 19, 840. [Google Scholar] [CrossRef] [Green Version]
- Klein, I.; Asraf, O. StepNet—Deep learning approaches for step length estimation. IEEE Access 2020, 8, 85706–85713. [Google Scholar] [CrossRef]
- Vertzberger, E.; Klein, I. Attitude Adaptive Estimation with Smartphone Classification for Pedestrian Navigation. IEEE Sens. J. 2020, 21, 9341–9348. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, M.; Ordieres-Meré, J. Comparison of data preprocessing approaches for applying deep learning to human activity recognition in the context of industry 4.0. Sensors 2018, 18, 2146. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kirichenko, L.; Radivilova, T.; Bulakh, V.; Zinchenko, P.; Alghawli, A.S. Two Approaches to Machine Learning Classification of Time Series Based on Recurrence Plots. In Proceedings of the 2020 IEEE Third International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2020; pp. 84–89. [Google Scholar]
- Zhang, Y.; Hou, Y.; Zhou, S.; Ouyang, K. Encoding time series as multi-scale signed recurrence plots for classification using fully convolutional networks. Sensors 2020, 20, 3818. [Google Scholar] [CrossRef]
- Rajabi, R.; Estebsari, A. Deep Learning Based Forecasting of Individual Residential Loads Using Recurrence Plots. In Proceedings of the 2019 IEEE Milan PowerTech, Milan, Italy, 23–27 June 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Wagner, D.; Kalischewski, K.; Velten, J.; Kummert, A. Activity recognition using inertial sensors and a 2-D convolutional neural network. In Proceedings of the 2017 10th International Workshop on Multidimensional (nD) Systems (nDS), Zielona Góra, Poland, 13–15 September 2017; pp. 1–6. [Google Scholar]
- Ito, C.; Cao, X.; Shuzo, M.; Maeda, E. Application of CNN for human activity recognition with FFT spectrogram of acceleration and gyro sensors. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1503–1510. [Google Scholar]
- Wang, Z.; Oates, T. Imaging time-series to improve classification and imputation. arXiv 2015, arXiv:1506.00327. [Google Scholar]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.K.R. Imaging and fusing time series for wearable sensor-based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Hur, T.; Bang, J.; Lee, J.; Kim, J.I.; Lee, S. Iss2Image: A novel signal-encoding technique for CNN-based human activity recognition. Sensors 2018, 18, 3910. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Shen, C.; van den Hengel, A. Wider or Deeper: Revisiting the ResNet Model for Visual Recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J.M. Fusion of Smartphone Motion Sensors for Physical Activity Recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef] [PubMed]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Klein, I. Smartphone location recognition: A deep learning-based approach. Sensors 2020, 20, 214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]





| Layer Name | Output Size [Pixels] | 50-Layer Structure [Kernel Size, # Channels] |
|---|---|---|
| conv1 | 112 × 112 | stride 2, 7 × 7, 64 |
| conv2 | 56 × 56 | stride 2, max pool 3 × 3 X3 |
| conv3 | 28 × 28 | X4 |
| conv4 | 14 × 14 | X6 |
| conv5 | 7 × 7 | X3 |
| SLR [36] | HAR1 [33] | HAR2 [34] | HAR3 [35] | HAR4 [35] |
|---|---|---|---|---|
| Biking | Stationary | Downstairs | Ironing | |
| Texting | Stationary | Sitting | Upstairs | VacuumCleaning |
| Swing | Sitting | Downstairs | ||
| Talking | Downstairs | Upstairs | ||
| Upstairs | Walking | |||
| Walking | Jogging | |||
| Jogging |
| Activity/Dataset | SLR | HAR1 | HAR2 | HAR3 | HAR4 |
|---|---|---|---|---|---|
| 1064, 355 | - | - | - | - | |
| Texting | 1808, 603 | - | - | - | - |
| Swing | 441, 147 | - | - | - | - |
| Talking | 242, 81 | - | - | - | - |
| Biking | - | 932, 233 | - | - | - |
| Stationary | - | 932, 233 | 1144, 159 | - | - |
| Downstairs | - | 932, 233 | 411, 50 | 986, 418 | - |
| Upstairs | - | 699, 116 | 534, 70 | 1098, 470 | - |
| Walking | - | 932, 233 | 789, 167 | - | - |
| Jogging | - | 932, 233 | 472, 62 | - | - |
| Sitting | - | 932, 233 | 1299, 149 | - | - |
| Ironing | - | - | - | - | 2229, 963 |
| VacuumCleaning | - | - | - | - | 1649, 696 |
| Image Encoder Method | Average Time [Sec] per Ten Image Patches | Size of Images Patches [Pixels] |
|---|---|---|
| Iss2Image | 0.25 | 224 × 3 × 3 |
| eIss2Image | 0.26 | 224 × 6 × 3 |
| Mul2Image (Ours) | 0.39 | 224 × 224 × 3 |
| Smartphone Location | 1D-CNN | Iss2Image | eIss2Image | Mul2Image (Ours) |
|---|---|---|---|---|
| 98.8% | 98.9% | 99.7% | 99.2% | |
| Texting | 96.9% | 99.2% | 99.8% | 99.8% |
| Swing | 97.2% | 98.0% | 99.3% | 100% |
| Talking | 95.7% | 97.5% | 100% | 96.3% |
| Method | Accuracy |
|---|---|
| 1D-CNN | 97.7% |
| Iss2Image | 98.8% |
| eIss2Image | 99.7% |
| Mul2Image (Ours) | 99.1% |
| Activity | Image Encoder Method | ||
|---|---|---|---|
| Iss2Image | eIss2Image | Mul2Image (Ours) | |
| Jogging | 99.6%/100% | 100%/100% | 99.6%/99.1% |
| Sitting | 78.5%/65.7% | 96.6%/91.0% | 95.3%/97.0% |
| Downstairs | 88.0%/78.1% | 95.3%/83.3% | 99.1%/88.0% |
| Upstairs | 82.9%/45.7% | 90.9%/50.0% | 98.9%/93.1% |
| Stationary | 90.1%/55.4% | 97.9%/71.7% | 80.3%/42.1% |
| Walking | 90.6%/79.0% | 97.0%/77.3% | 98.7%/85.4% |
| Biking | 97.0%/99.1% | 100%/99.6% | 94.8%/96.6% |
| Activity | Image Encoder Method | ||
|---|---|---|---|
| Iss2Image | eIss2Image | Mul2Image (Ours) | |
| Jogging | 93.2%/100% | 93.2%/100% | 99.2%/100% |
| Sitting | 99.7%/100% | 100%/99.3% | 95.7%/94.0% |
| Downstairs | 68.2%/24.0% | 71.8%/26.0% | 96.4%/96.0% |
| Upstairs | 74.4%/95.7% | 78.9%/95.7% | 97.0%/98.6% |
| Stationary | 98.6%/17.0% | 100%/79.2% | 88.1%/95.6% |
| Walking | 85.8%/76.0% | 91.4%/37.7% | 95.4%/94.0% |
| Activity | Image Encoder Method | ||
|---|---|---|---|
| Iss2Image | eIss2Image | Mul2Image (Ours) | |
| Downstairs | 95.2%/77.0% | 98.0%/81.1% | 88.8%/81.8% |
| Upstairs | 99.2%/97.3% | 92.4%/98.1% | 89.4%/91.7% |
| Activity | Image Encoder Method | ||
|---|---|---|---|
| Iss2Image | eIss2Image | Mul2Image (Ours) | |
| Ironing | 99.0%/71.9% | 98.0%/72.0% | 87.5%/86.6% |
| VacuumCleaning | 96.9%/74.5% | 99.1%/75.6% | 80.4%/76.4% |
| Image Encoder Method | Dataset | Overall Accuracy | Final Rank | ||||
|---|---|---|---|---|---|---|---|
| SLR | HAR1 | HAR2 | HAR3 | HAR4 | |||
| Iss2Image | 98.8% | 67.6% | 76.9% | 87.7% | 72.9% | 80.8% | 3 |
| eIss2Image | 99.7% | 72.9% | 84.3% | 90.0% | 73.5% | 83.9% | 2 |
| Mul2Image (Ours) | 99.1% | 95.6% | 85.3% | 88.6% | 82.3% | 88.6% | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daniel, N.; Klein, I. INIM: Inertial Images Construction with Applications to Activity Recognition. Sensors 2021, 21, 4787. https://doi.org/10.3390/s21144787
Daniel N, Klein I. INIM: Inertial Images Construction with Applications to Activity Recognition. Sensors. 2021; 21(14):4787. https://doi.org/10.3390/s21144787
Chicago/Turabian StyleDaniel, Nati, and Itzik Klein. 2021. "INIM: Inertial Images Construction with Applications to Activity Recognition" Sensors 21, no. 14: 4787. https://doi.org/10.3390/s21144787