
A Bayesian Dynamical Approach for Human Action Recognition

Abstract
:1. Introduction
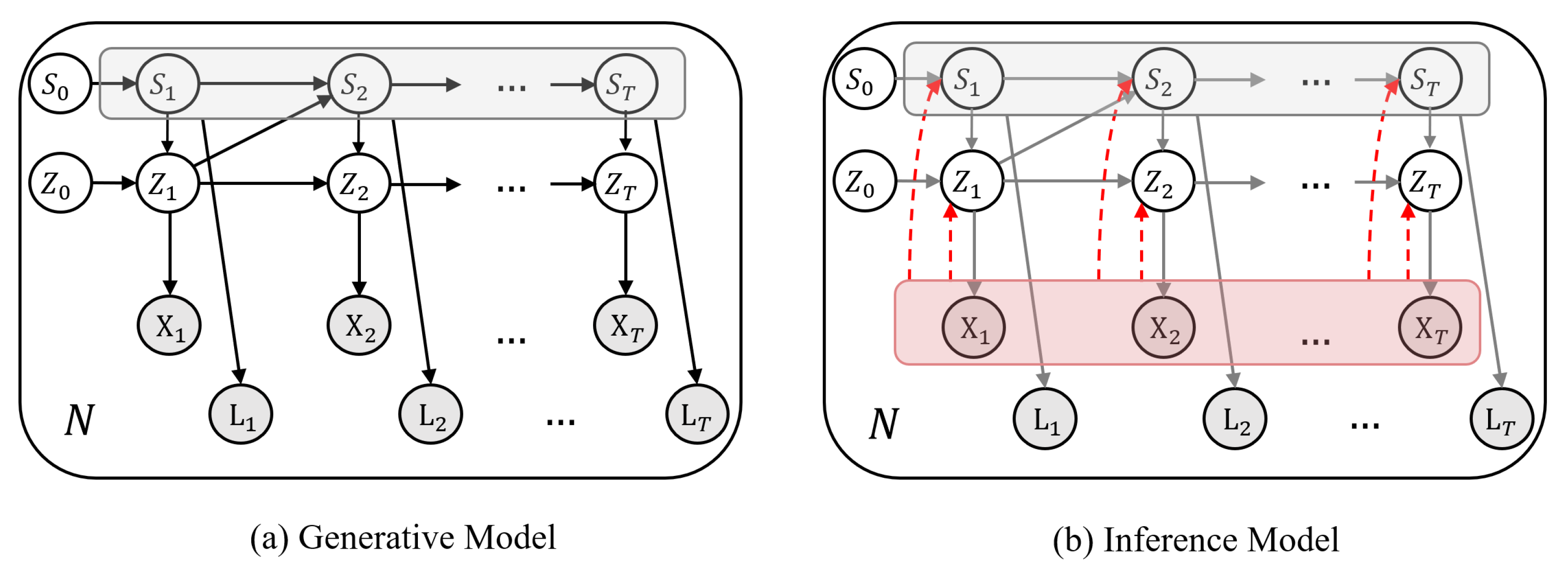
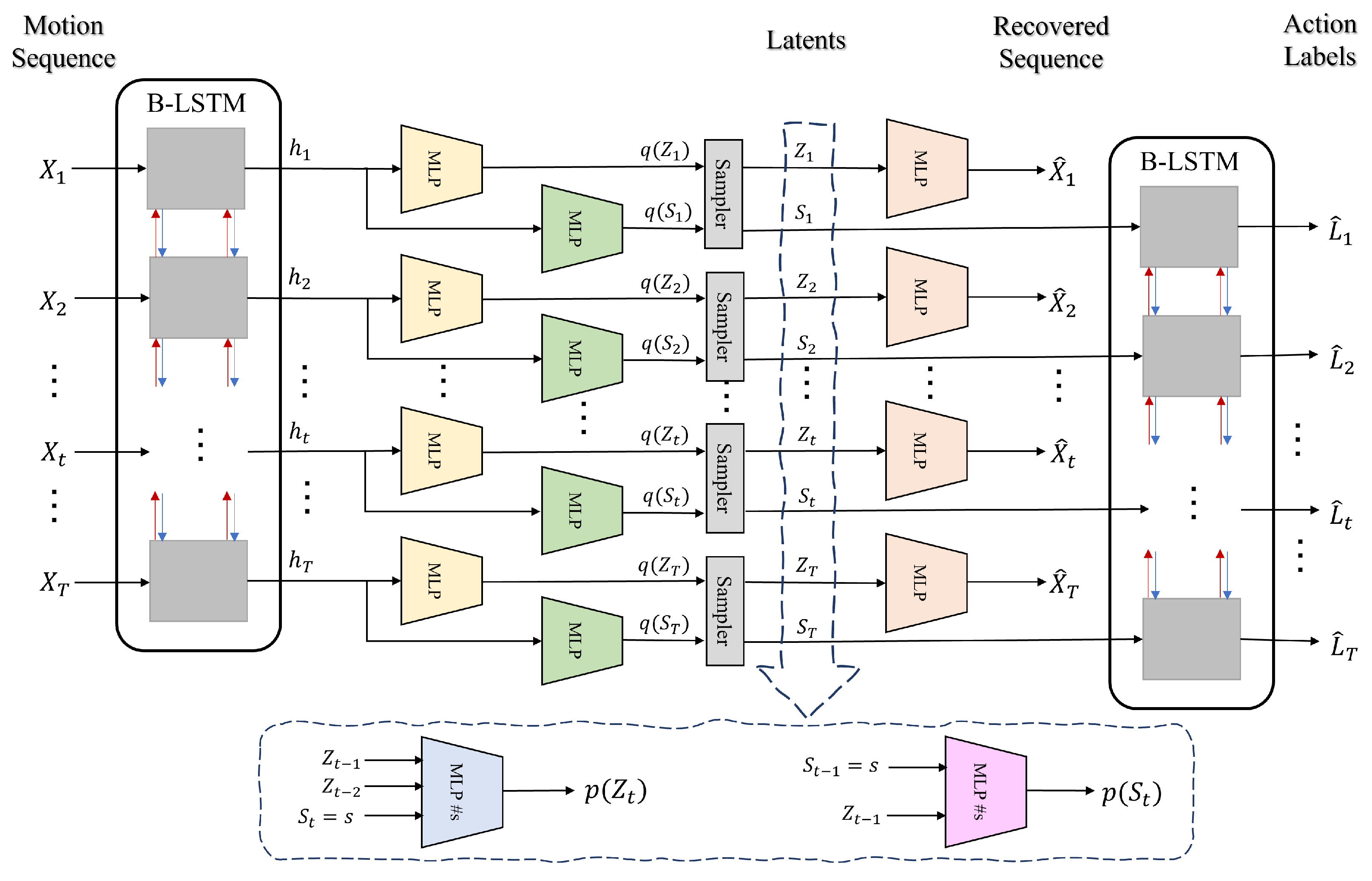
- In contrast to previous works which merely classify motion sequences into action labels and are not generative, our method, sketched in Figure 1 and Figure 2, in addition to action recognition, (I) segments motion data from a dynamical perspective by explicitly modeling temporal dynamics in a Bayesian approach, hence, (II) it allows dynamical prediction of skeletal motion from low-level representations. Specifically, (III) it welcomes multimodal, higher-order, and nonlinear temporal relations in motion data by employing a deep switching auto-regressive latent model.
- Our method can easily fill in missing entries in motion data due to its predictive nature which models transitions between time points and between action labels.
- Our method provides action labels per time point and can handle varying-length sequences.
- Our method uses a nonlinear second-order dynamical model to better capture skeletal dynamics, because first-order models are less effective in modeling acceleration (i.e., second-derivative of location) in motion data.
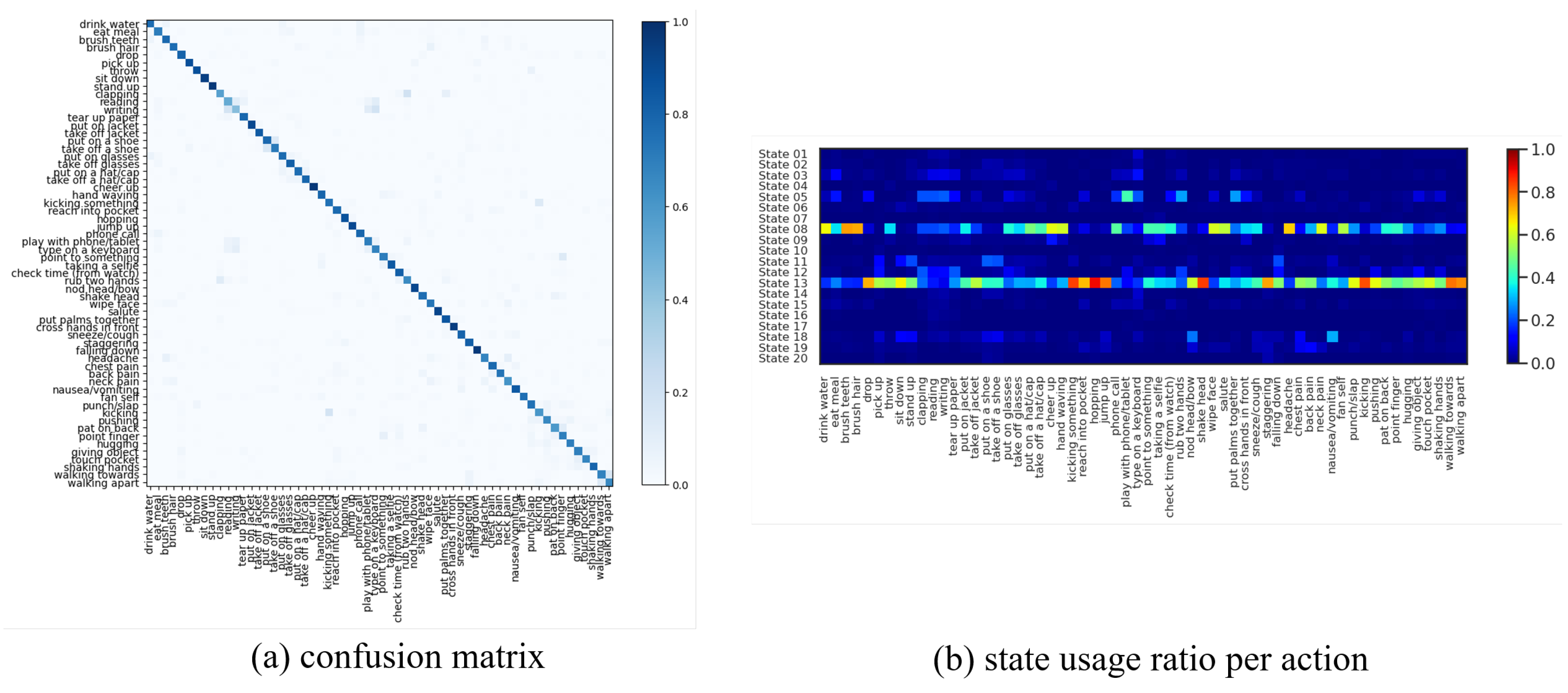
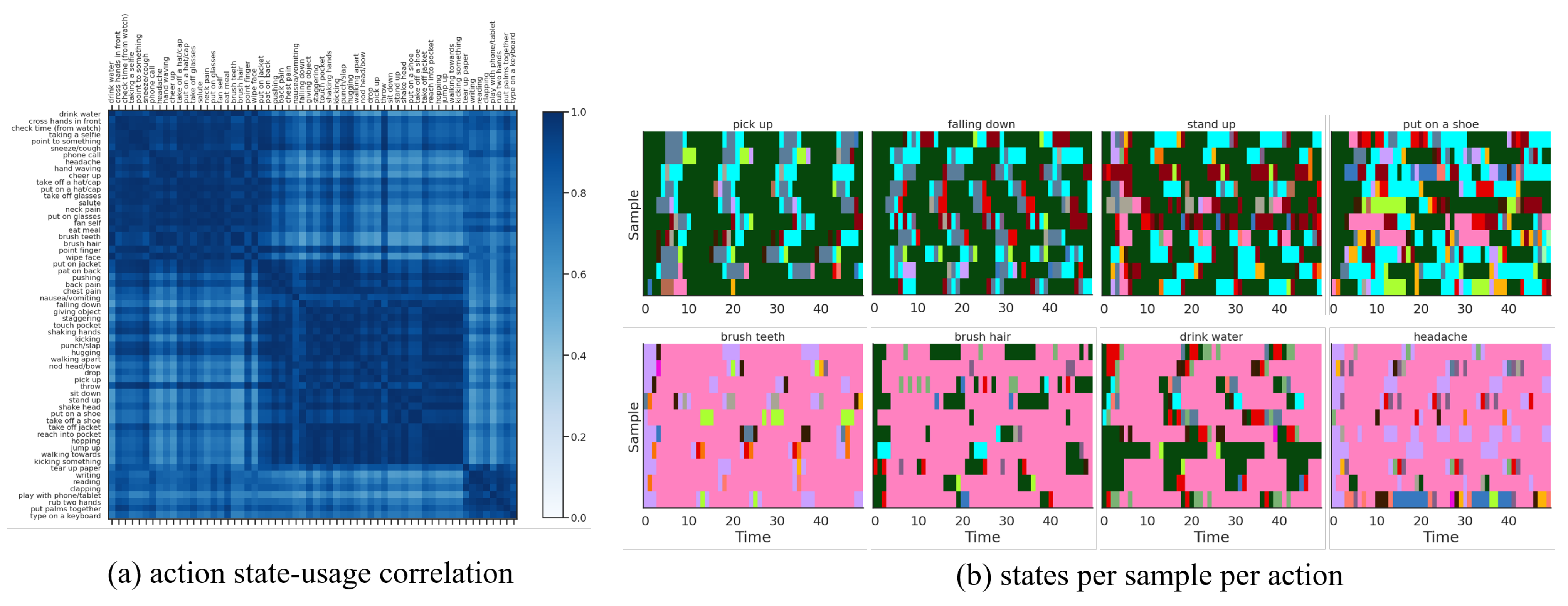
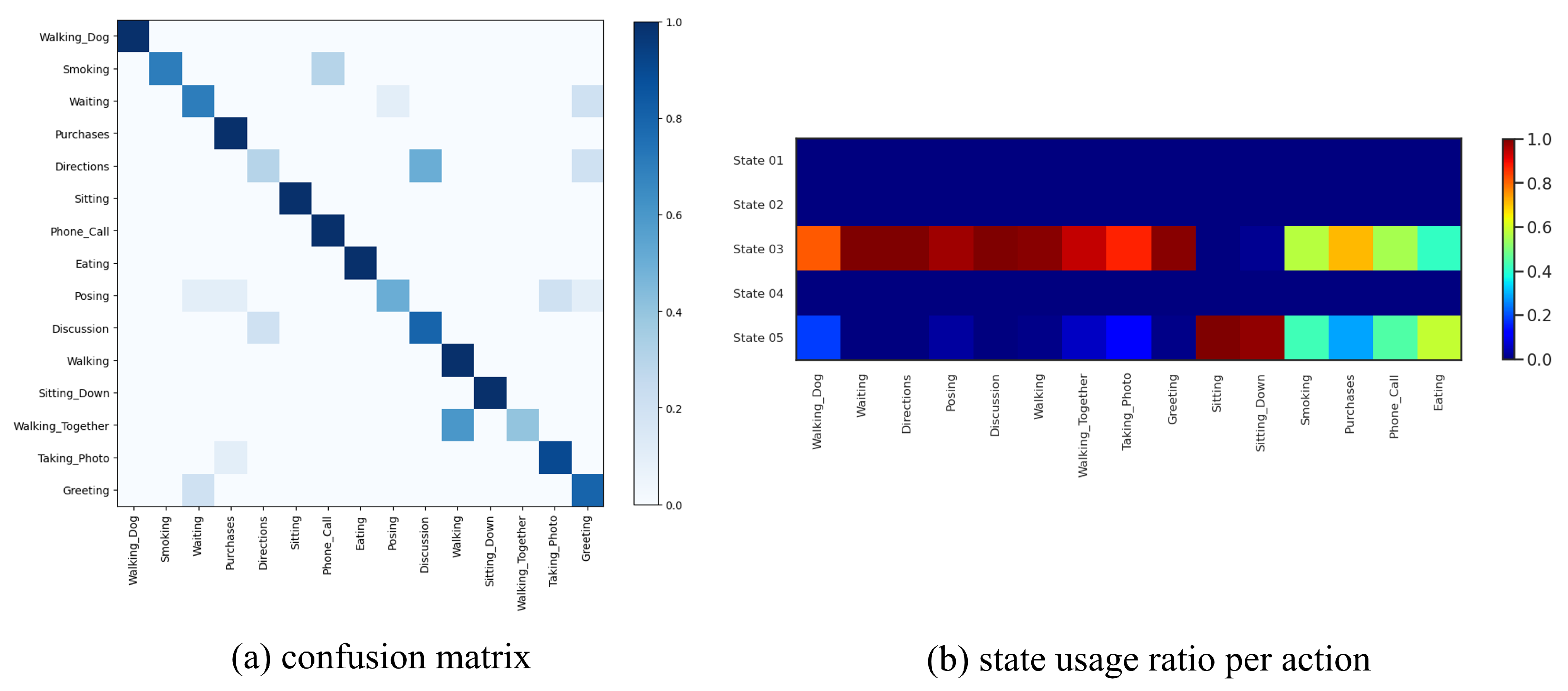
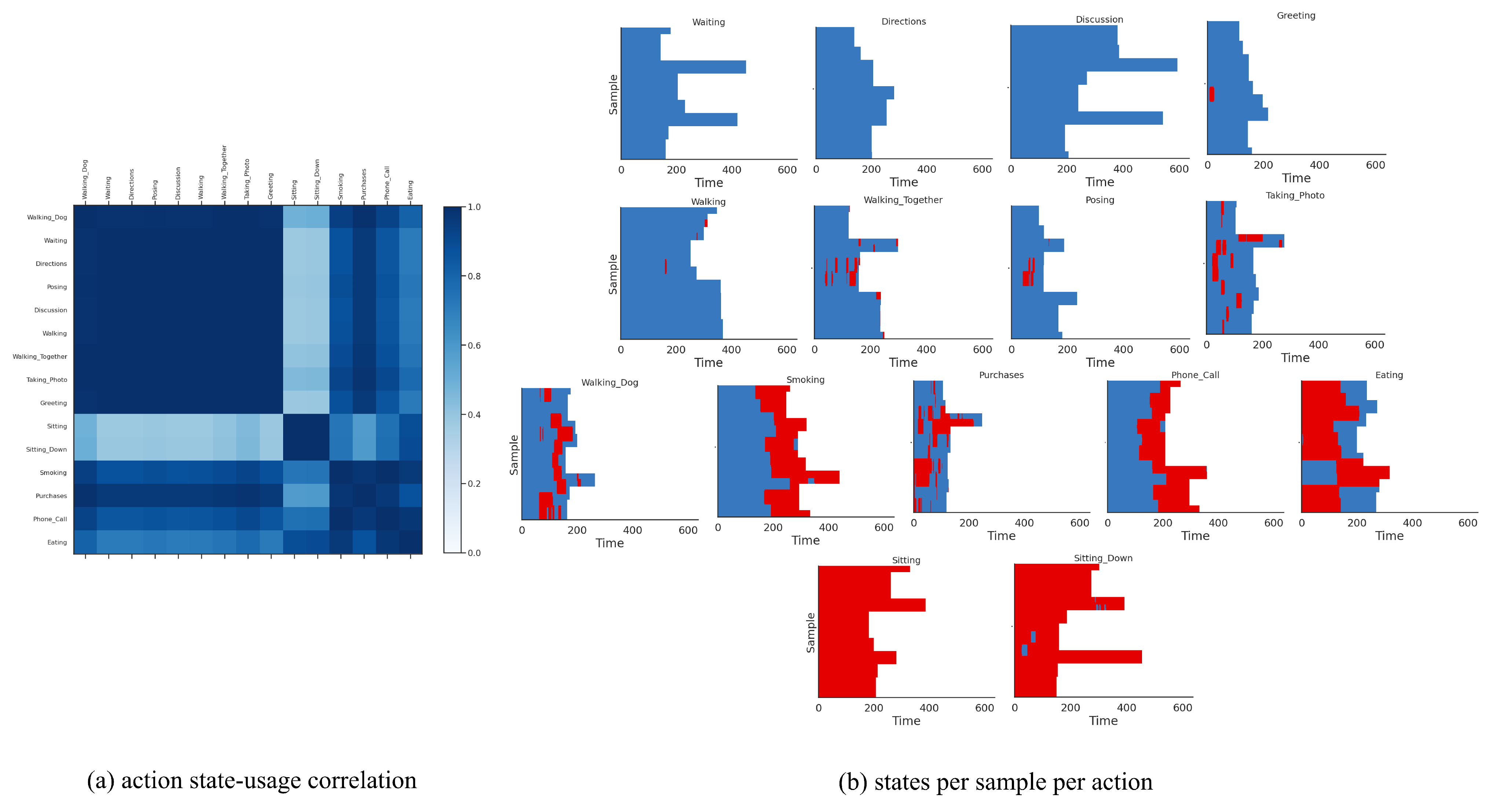
- The sequence of discrete latents in our method enables multi-modal dynamical modeling and at the same time provides visual/qualitative and quantitative interpretations about motion primitives that gave rise to each action class, which were not possible with previous methods.
- Our method is probabilistic and provides confidence intervals for its estimations and predictions.
2. Related Works
2.1. Dynamical Systems Modeling
2.2. Action Recognition
3. Problem Formulation
3.1. Generative Model
3.1.1. Discrete Markovian Prior
3.1.2. Switching Autoregressive Prior
3.1.3. Emission Model for Action Labels
3.1.4. Emission Model for Motion Sequence
3.2. Inference Model
3.2.1. Variational Distributions for Discrete and Continuous Latents ,
3.2.2. ELBO Derivation
3.3. Summary of the Proposed Method
4. Experimental Results
4.1. 3D Skeletal Datasets
4.2. Performance Metric
4.3. Comparison Baselines
4.4. Implementation Details
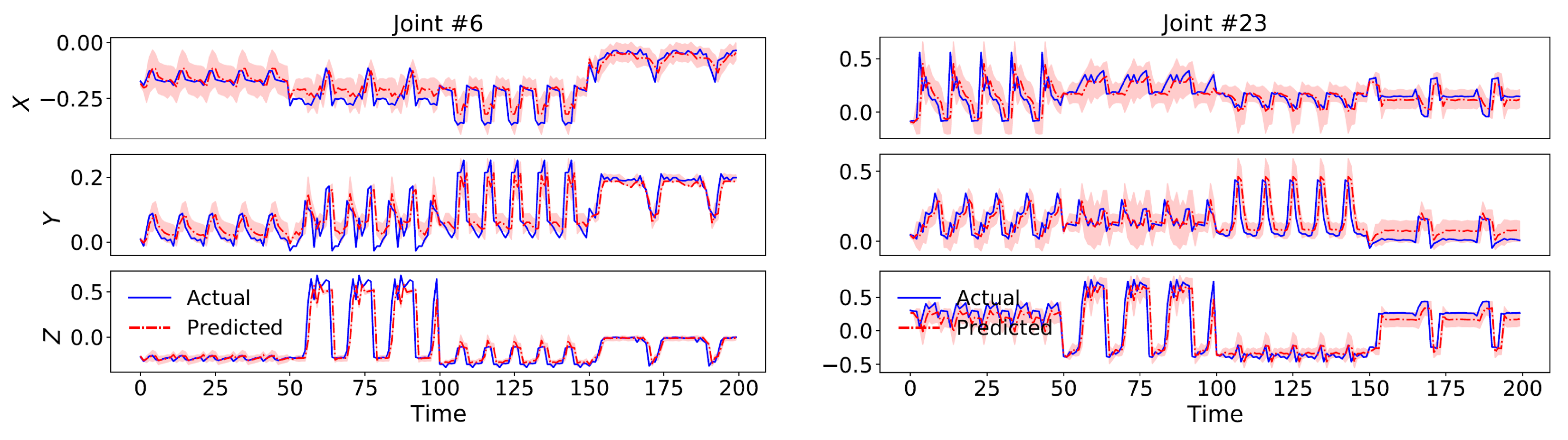
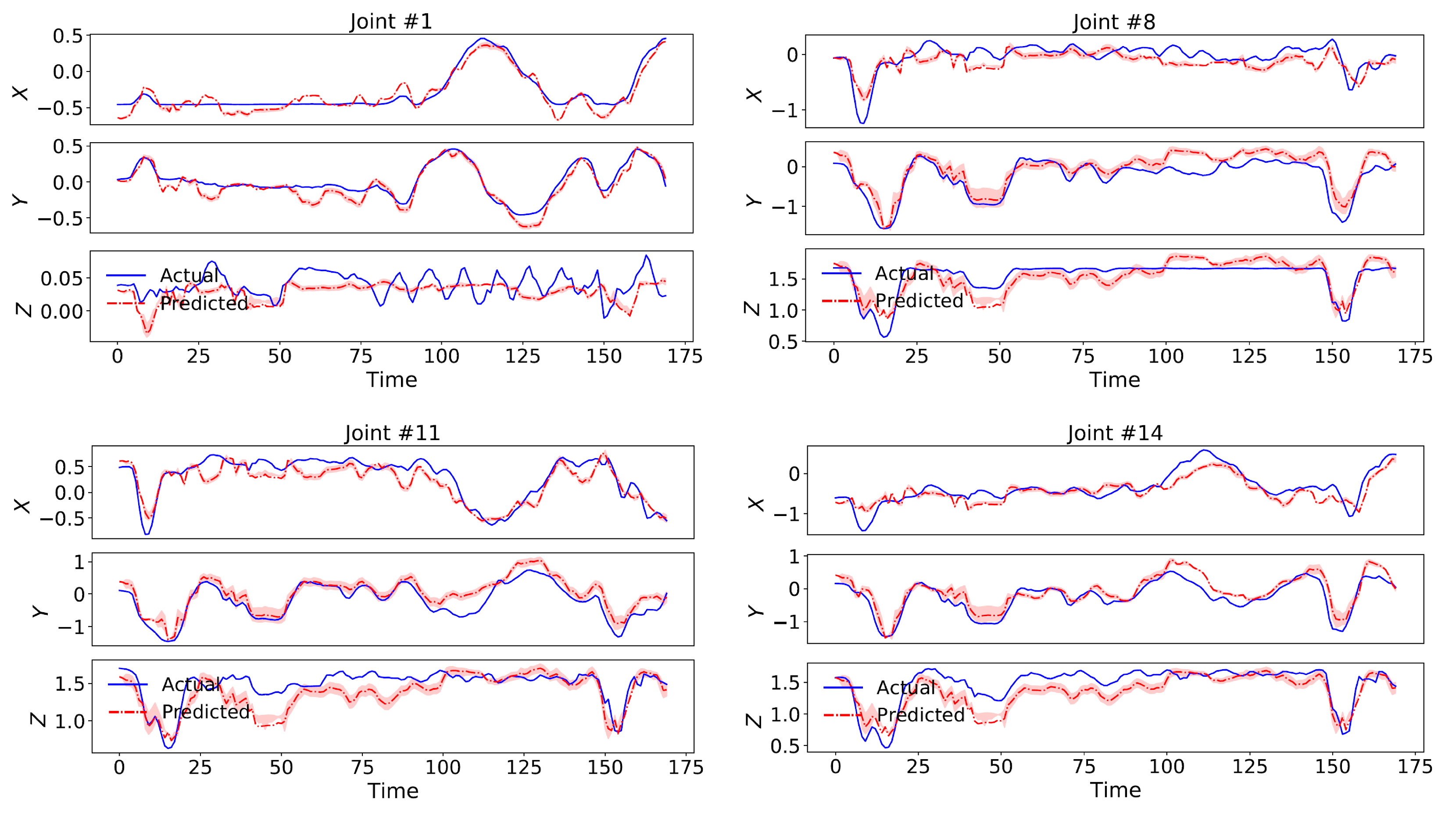
4.5. Evaluation Results on NTU RGB+D 60 Dataset
4.6. Evaluation Results on Human3.6M Dataset
4.7. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moeslund, T.; Hilton, A.; Krüger, V. A survey of advances in vision-based human motion capture and analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar] [CrossRef]
- Birch, M.C.; Quinn, R.D.; Hahm, G.; Phillips, S.M.; Drennan, B.; Fife, A.; Verma, H.; Beer, R.D. Design of a cricket microrobot. In Proceedings of the 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 1109–1114. [Google Scholar] [CrossRef]
- Gong, C.; Travers, M.J.; Astley, H.C.; Li, L.; Mendelson, J.R.; Goldman, D.I.; Choset, H. Kinematic gait synthesis for snake robots. Int. J. Robot. Res. 2016, 35, 100–113. [Google Scholar] [CrossRef]
- Hoff, J.; Ramezani, A.; Chung, S.J.; Hutchinson, S. Synergistic Design of a Bio-Inspired Micro Aerial Vehicle with Articulated Wings. In Proceedings of the Robotics: Science and Systems 2016, Ann Arbor, MI, USA, 18–22 June 2016. [Google Scholar]
- Santello, M.; Flanders, M.; Soechting, J.F. Postural hand synergies for tool use. J. Neurosci. 1998, 18, 10105–10115. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Li, W.; Li, C.; Hou, Y. Action recognition based on joint trajectory maps with convolutional neural networks. Knowl. Based Syst. 2018, 158, 43–53. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Xia, R.; Liu, X.; Huang, Q. Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1066–1071. [Google Scholar]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 499–508. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7912–7921. [Google Scholar]
- Ackerson, G.; Fu, K. On state estimation in switching environments. IEEE Trans. Autom. Control. 1970, 15, 10–17. [Google Scholar] [CrossRef]
- Chang, C.B.; Athans, M. State estimation for discrete systems with switching parameters. IEEE Trans. Aerosp. Electron. Syst. 1978, AES-14, 418–425. [Google Scholar] [CrossRef]
- Hamilton, J.D. Analysis of time series subject to changes in regime. J. Econom. 1990, 45, 39–70. [Google Scholar] [CrossRef]
- Ghahramani, Z.; Hinton, G.E. Variational learning for switching state-space models. Neural Comput. 2000, 12, 831–864. [Google Scholar] [CrossRef]
- Murphy, K.P. Switching Kalman Filters. Available online: https://www.cs.ubc.ca/~murphyk/Papers/skf.pdf (accessed on 15 August 2021).
- Fox, E.; Sudderth, E.B.; Jordan, M.I.; Willsky, A.S. Nonparametric Bayesian learning of switching linear dynamical systems. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 457–464. [Google Scholar]
- Linderman, S.; Johnson, M.; Miller, A.; Adams, R.; Blei, D.; Paninski, L. Bayesian Learning and Inference in Recurrent Switching Linear Dynamical Systems. Available online: http://proceedings.mlr.press/v54/linderman17a/linderman17a.pdf (accessed on 15 August 2021).
- Nassar, J.; Linderman, S.; Bugallo, M.; Park, I. Tree-Structured Recurrent Switching Linear Dynamical Systems for Multi-Scale Modeling. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Becker-Ehmck, P.; Peters, J.; Van Der Smagt, P. Switching Linear Dynamics for Variational Bayes Filtering. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 553–562. [Google Scholar]
- Farnoosh, A.; Azari, B.; Ostadabbas, S. Deep Switching Auto-Regressive Factorization: Application to Time Series Forecasting. arXiv 2020, arXiv:2009.05135. [Google Scholar]
- Sun, J.Z.; Parthasarathy, D.; Varshney, K.R. Collaborative kalman filtering for dynamic matrix factorization. IEEE Trans. Signal Process. 2014, 62, 3499–3509. [Google Scholar] [CrossRef]
- Cai, Y.; Tong, H.; Fan, W.; Ji, P.; He, Q. Facets: Fast comprehensive mining of coevolving high-order time series. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 79–88. [Google Scholar]
- Bahadori, M.T.; Yu, Q.R.; Liu, Y. Fast multivariate spatio-temporal analysis via low rank tensor learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3491–3499. [Google Scholar]
- Yu, H.F.; Rao, N.; Dhillon, I.S. Temporal regularized matrix factorization for high-dimensional time series prediction. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 847–855. [Google Scholar]
- Takeuchi, K.; Kashima, H.; Ueda, N. Autoregressive tensor factorization for spatio-temporal predictions. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 1105–1110. [Google Scholar]
- Watter, M.; Springenberg, J.; Boedecker, J.; Riedmiller, M. Embed to control: A locally linear latent dynamics model for control from raw images. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2746–2754. [Google Scholar]
- Karl, M.; Soelch, M.; Bayer, J.; van der Smagt, P. Deep variational bayes filters: Unsupervised learning of state space models from raw data. Stat 2017, 1050, 3. [Google Scholar]
- Krishnan, R.G.; Shalit, U.; Sontag, D. Structured inference networks for nonlinear state space models. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Fraccaro, M.; Kamronn, S.; Paquet, U.; Winther, O. A disentangled recognition and nonlinear dynamics model for unsupervised learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3601–3610. [Google Scholar]
- Becker, P.; Pandya, H.; Gebhardt, G.; Zhao, C.; Taylor, C.J.; Neumann, G. Recurrent Kalman Networks: Factorized Inference in High-Dimensional Deep Feature Spaces. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 544–552. [Google Scholar]
- Farnoosh, A.; Rezaei, B.; Sennesh, E.Z.; Khan, Z.; Dy, J.; Satpute, A.; Hutchinson, J.B.; van de Meent, J.W.; Ostadabbas, S. Deep Markov Spatio-Temporal Factorization. arXiv 2020, arXiv:2003.09779. [Google Scholar]
- Chang, Y.Y.; Sun, F.Y.; Wu, Y.H.; Lin, S.D. A memory-network based solution for multivariate time-series forecasting. arXiv 2018, arXiv:1809.02105. [Google Scholar]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long-and short-term temporal patterns with deep neural networks. In Proceedings of the ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Rangapuram, S.S.; Seeger, M.W.; Gasthaus, J.; Stella, L.; Wang, Y.; Januschowski, T. Deep state space models for time series forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7785–7794. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Sen, R.; Yu, H.F.; Dhillon, I.S. Think globally, act locally: A deep neural network approach to high-dimensional time series forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 4837–4846. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Muhammad, K.; Mustaqeem; Ullah, A.; Imran, A.S.; Sajjad, M.; Kiran, M.S.; Sannino, G.; de Albuquerque, V.H.C. Human action recognition using attention based LSTM network with dilated CNN features. Future Gener. Comput. Syst. 2021, 125, 820–830. [Google Scholar] [CrossRef]
- Kwon, S. Optimal feature selection based speech emotion recognition using two-stream deep convolutional neural network. Int. J. Intell. Syst. 2021, 36, 5116–5135. [Google Scholar]
- Hoffman, M.D.; Blei, D.M.; Wang, C.; Paisley, J. Stochastic variational inference. J. Mach. Learn. Res. 2013, 14, 1303–1347. [Google Scholar]
- Ranganath, R.; Wang, C.; David, B.; Xing, E. An adaptive learning rate for stochastic variational inference. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 298–306. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. Stat 2014, 1050, 1. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef]
- Sun, L.; Chen, X. Bayesian Temporal Factorization for Multidimensional Time Series Prediction. arXiv 2019, arXiv:1910.06366. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch; NeurIPS 2017 Autodiff Workshop: Long Beach, CA, USA, 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dhillon, I.S. Co-clustering documents and words using bipartite spectral graph partitioning. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 269–274. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| gModel | ||||
| Input | ||||
| 1 | FC ReLU | FC ReLU | FC ReLU | FC ReLU |
| 2 | FC ReLU | AvgPool() | FC | FC ReLU |
| 3 | FC | FC ReLU | FC ReLU | |
| 4 | FC | FC | ||
| iModel | ||||
| Input | ||||
| 1 | FC ReLU | FC ReLU | ||
| 2 | FC ReLU | FC ReLU | ||
| 3 | FC | FC | ||
| Classification Accuracy (%) | Dynamical Prediction (NRMSE%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Ours | P-LSTM | Ablation | Ours | rSLDS | SLDS | BTMF | RKN | LSTNet | |
| Dataset | Ours | |||||||||
| NTU (x-view) | 76.60 | 70.27 | 69.81 | 17.23 | 22.45 | 22.19 | 18.81 | 22.64 | 20.22 | |
| NTU (x-sub) | 67.52 | 62.93 | 60.74 | 18.34 | 23.68 | 25.49 | 21.86 | 25.63 | 24.15 | |
| Human3.6M | 78.33 | 71.67 | 73.33 | 20.76 | 27.99 | 28.57 | 23.83 | 24.04 | 23.12 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farnoosh, A.; Wang, Z.; Zhu, S.; Ostadabbas, S. A Bayesian Dynamical Approach for Human Action Recognition. Sensors 2021, 21, 5613. https://doi.org/10.3390/s21165613
Farnoosh A, Wang Z, Zhu S, Ostadabbas S. A Bayesian Dynamical Approach for Human Action Recognition. Sensors. 2021; 21(16):5613. https://doi.org/10.3390/s21165613
Chicago/Turabian StyleFarnoosh, Amirreza, Zhouping Wang, Shaotong Zhu, and Sarah Ostadabbas. 2021. "A Bayesian Dynamical Approach for Human Action Recognition" Sensors 21, no. 16: 5613. https://doi.org/10.3390/s21165613