A Matching Game-Based Data Collection Algorithm with Mobile Collectors

1
School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
2
School of Automation, South and East University, Nanjing 210018, China
*
Author to whom correspondence should be addressed.
Sensors 2020, 20(5), 1398; https://doi.org/10.3390/s20051398
Submission received: 6 February 2020
/
Revised: 20 February 2020
/
Accepted: 1 March 2020
/
Published: 4 March 2020
(This article belongs to the Collection Signal Processing, Control, and Estimation for Intelligent Sensor Systems)
Abstract
:Data collection is one of the key technologies in wireless sensor networks. Due to the limited battery resources of sensors, mobile collectors are introduced to collect data instead of multi-hop data relay. However, how to decrease the data delay based on the cooperation of mobile collectors is a main problem. To solve this problem, a matching game-based data collection algorithm is proposed. First, some high-level cluster heads are elected. Second, by introducing a matching game model, the data collection problem is modeled as a one to one matching problem. Then, according to the preferences of mobile collectors and cluster heads, the benefit matrices are established. Based on the proposed matching algorithm, each mobile collector selects a cluster head to collect the data packets. Performance analysis proves that the matching result is stable, optimal, and unique. Simulation results show that the proposed algorithm is superior to other existing approach in terms of the reduction in data delay.
1. Introduction
The wireless sensor network consists of a large number of sensor nodes. The sensor nodes monitor the environment, process the data packets and then send the data packets to other sensor nodes or the sink. With the development of computer network technology and sensor technology, wireless sensor networks are more and more widely used in various fields [1,2,3]. Whether the wireless sensor network is applied in which field, it is data-centric, that is, obtaining information as an important goal. The sink makes decisions based on the information obtained from the sensor nodes. Therefore, data collection is a key technology of a wireless sensor network.
Multi-hop transmission is commonly used in wireless sensor networks. Sensor nodes are divided into several clusters. Each cluster elects a cluster head. Ordinary nodes send information to the cluster head they are attached to. Cluster heads merge the information and send it to the sink. LEACH [4] algorithm is a classic cluster algorithm. First, at the beginning of each period, based on the number of cluster heads needed in the network and the number of times each node has been elected as the cluster head, some nodes are elected as cluster heads. Then other nodes decide which cluster heads they are attached to based on the signal strength received. A hybrid, energy-efficient, distributed clustering algorithm (HEED) [5], a stable election algorithm (SEP) [6] and a hierarchical agglomerative clustering algorithm (DHAC) [7] have improved the LEACH algorithm. In recent years, the clustering method and the method of cluster head selection are optimized, and many cluster algorithm have been proposed. However, using multi-hop transmission method, nodes consume a lot of energy in data transmission. Additionally, in many environments, the battery cannot be replaced after the nodes’ power is exhausted.
References [8,9,10,11] have introduced mobile sink to collect data. In traditional methods, the sink is static, and waits to receive data packets generated by sensor nodes. In order to reduce the energy consumption for sensor nodes sending data to the sink, the mobile sink is used in some scenarios. The mobile sink can move to the vicinity of the nodes to collect data within the monitored range. Due to the constant movement of the sink, the nodes need to broadcast their own information and track the sink constantly, which also consumes a lot of energy. Therefore, many literatures propose the idea of using mobile collectors to collect data packets.
Reference [12] has proposed a data collection method based on the genetic algorithm. First, the nodes within the network are divided into several clusters. Then the overlaps of the communication ranges are found. Mobile collectors move to these locations to collect data packets, and an algorithm is proposed to calculate the paths for them. The defect of the algorithm is that the data packets are sent to the sink after all the data packets have been collected, so the data delay is long. When there are multiple mobile collectors in the network, the delay can be reduced compared to only one mobile collector. The goal of reference [13] is to plan the paths of multiple mobile collectors and minimize the data delay. There is a probability that a region is visited by different mobile collectors, which results in the waste of resources. The reference [14] has divided the data collection problem into three problems: task scheduling, path calculation, and speed control. The greedy algorithm is introduced to assign tasks to mobile collectors. The mobile collectors need to visit each node, therefore the data delay is long. The goal of reference [15] is to select the optimal collection point. First a node sets itself as the collection point. Then it sends information to neighbor nodes within its multi-hop range, including its identification, the number of neighbor nodes and the distance from the sink. When it finds a node closer to the sink and having more neighbor nodes than it, it marks the node as a collection point. This algorithm is suitable for the environment where nodes are evenly distributed. When nodes are randomly distributed, it is difficult to get the optimal solution. The problem solved by reference [16] is how to plan a path for each mobile collector. This problem is defined as an optimization problem and solved by a linear programming approach. Reference [17] considers a scenario where an unmanned aerial vehicle collects data from a set of sensors on a straight line. Reference [18] proposes a fault tolerant algorithm for data aggregation to plan the itinerary for a mobile agent and another alternative itinerary in case of sensor nodes failure.
In this paper, the wireless sensor network is distributed in the monitored area. The sensor nodes are event-driven. The problem to be solved in this paper is, how multiple mobile collectors collaborate to collect event data packets generated by sensor nodes with the minimum data delay.
Game theory studies the decision-making behavior when decision-makers interact with each other. Game theory researches how individuals make decisions and how they are influenced by other players. Therefore, each participant’s decision includes the decisions of others. In general, game theory attempts to open the black box of individual decision-making.
The innovations of this paper include the following aspects.
- (1)
- The matching game model in game theory is introduced. The problem of cooperative data collection by multiple mobile collectors is modeled as the matching problem between mobile collectors and high-level cluster heads.
- (2)
- According to the preferences of mobile collectors and high-level cluster heads, their benefit ranking matrices are built. Then, a one-to-one matching algorithm is proposed.
- (3)
- Theoretical analysis proves that the matching result between mobile collectors and high-level cluster heads is stable, optimal and unique.
2. Data Collection Method Based on Matching Game Theory
2.1. Preliminaries
The following assumptions are made for our considered network environment in this paper.
- (1)
- Sensor nodes are distributed in the area of interest randomly, and all the sensors are static.
- (2)
- The positions of sensor nodes are obtained by GPS or existing positioning algorithms. All the sensor nodes have homogeneous capabilities, such as the sensing range, communication range, fusion power and ability of localization.
- (3)
- The sensor nodes are event-driven. They generate event packets when they detect events of interest to the sink. Then the event packets are sent to the sink by mobile collectors. The sink is static.
- (4)
- The network topology is connected.
Some definitions are given as follows.
Mobile collector: A mobile collector is a power unit which can move freely and carries radio frequency transceivers, which is expressed by , where is the identification of the mobile collector.
Visit: For any sensor node , if a mobile collector communicates with it and receives data packets from it, it is called that is visited by the mobile collector.
High-level cluster head: In the three-layer sensor network, sensor nodes are separated to play different roles, such as cluster heads and ordinary nodes. First, all nodes are grouped into low-level clusters and the low-level cluster heads are elected by a cluster algorithm. Then, the low-level cluster heads are organized into high-level clusters and high-level cluster heads are elected. A high-level cluster head is expressed by , where is the identification of the high-level cluster head.
Request sequence set: During a collection cycle, the data packets generated by ordinary sensor nodes are relayed to high-level cluster heads through low-level cluster head. When a high-level cluster head has received these data packets, it will send a request message to the sink. The request message received by the sink during a collection cycle constitutes a set named , which is expressed as Equation (1), where is the request information sent by the high-level cluster head named , is the time when the data packets received by were generated, is the priority of these data packets, and are the abscissa and ordinate of , respectively. There are two cases. In one case, the generation times and priorities of the data packets received by are the same. Then the generation time and priority are the values of and . In another case, the generation times and priorities of the data packets received by are different. Then is defined as the minimum of these generation times, and is defined as the maximum of these priorities.
2.2. System Model
A wireless sensor network consists of many sensor nodes deployed in a monitored region. Each sensor node has a communication range , which is a circle with the position of the node as the center and as the radius. Each sensor node consists of four components: sensing unit, microcontroller unit, radio unit, and a battery. The topology of the sensor network is represented by the graph , where represents the set of sensor nodes and represents the set of wireless links. For any two different nodes , we say the wireless link if ; otherwise , where is the Euclidean distance between and . In order to form a topology for a wireless sensor network, the medium access control (MAC) protocol proposed in reference [19], named self-organizing medium access control for sensor networks (SMACS), is used in this paper. By SMACS [19], the sensor nodes can discover their neighbors and establish transmission/reception schedules for communicating with them. After the topology of the wireless sensor network is formed, mobile collectors can communicate with sensor nodes. Since the sensor nodes use time division multiple access (TDMA) technology, some time slots are reserved for mobile collectors to send invitations. When a mobile collector needs to communicate with a node, it moves to the communication range of this node, sends an invitation to the node and waits for a reply from the node. If the node is unwilling to establish a connection with the collector, it sends a rejection message to the mobile collector. If the node accepts the invitation from the mobile collector, it sends a reply to the collector. Then the collector is registered at the node, and the node allocates some time slots for the communication between them. When the communication between them ends, the collector informs the node to release the connection.
The problem of data collection can be solved by the following steps.
- (1)
- The wireless sensor network is grouped into three-layer clusters by a clustering algorithm.
- (2)
- During a collection cycle, the request sequence set is sent to each collector by the sink. Based on the matching game theory, each collector selects a high-level cluster head.
- (3)
- Each collector moves to the communication range of a high-level cluster head and visits it. Then the collector sends the data packets which it has received to the sink.
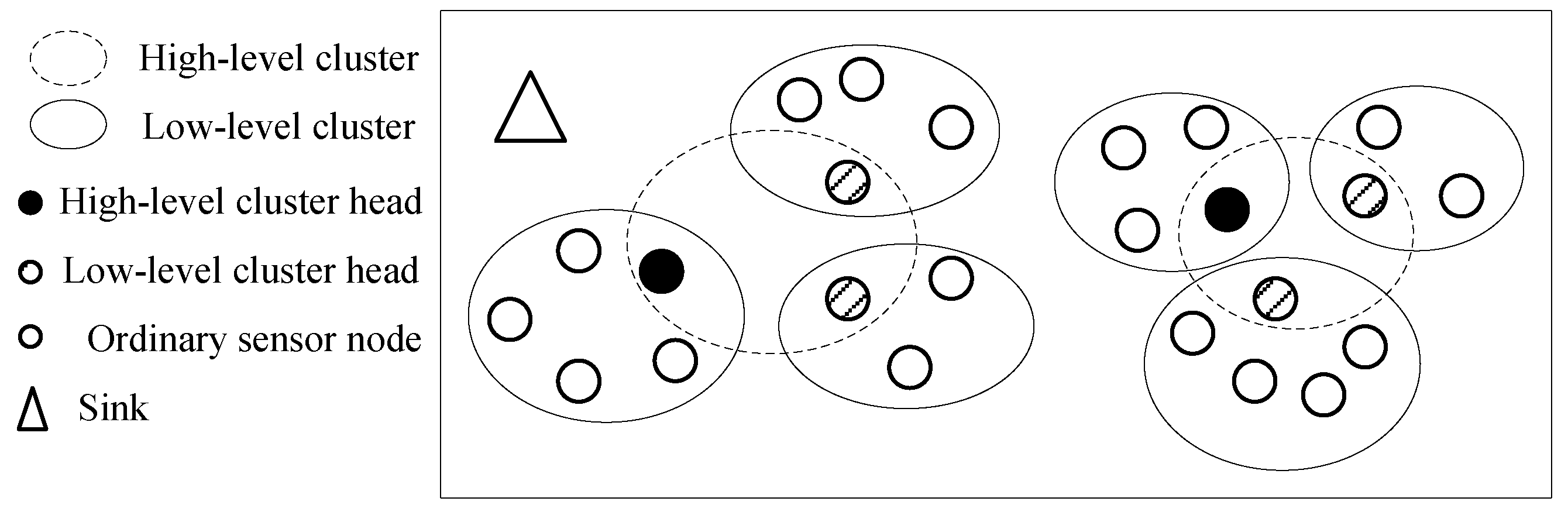
The step 1 can be solved by a clustering algorithm. Many literatures have proposed clustering algorithms, therefore the clustering algorithm is not the focus of this paper. For example, the self-organization clustering algorithm (SOC) proposed in reference [20] can be used in this paper. Architecture of the wireless sensor network is given in Figure 1. In step 3, the collectors communicate with high-level cluster heads and the sink, and relay data packets from high-level cluster heads to the sink. According to the above analysis, steps 1 and 3 are relatively easy to implement, so the focus of this paper is step 2.
A system that applies a one-to-one matching game model must satisfy at least two important assumptions.
- (1)
- From the beginning of the game, participants must belong to two disjoint sets. For example, the sets of the two sides are and , respectively, and satisfy Equation (2).
- (2)
- A match can only be formed after the agreement of both sides.
A number of mobile collectors are randomly scattered in the monitored area. During each collection cycle, each collector selects a high-level cluster head to visit by a matching-game based algorithm. This process is accomplished by the communication between collectors and high-level cluster heads. Let and denote the set of collectors and the set of high-level cluster heads which have received data packets from low-level clusters, respectively. Thus, their relationship satisfies Equation (3). The benefit matrices of the two sets and are represented by and , respectively, where and represent the number of elements in and , respectively. and make decisions based on and .
Suppose the symbol represents a strict preference relationship. For , , , represent three options. If prefers to , it can be expressed as . For , the following three conclusions hold.
- (1)
- The expression holds or the expression holds. Thus is complete.
- (2)
- If the expressions and hold, the expression holds. Thus is transferable.
- (3)
- is complete and transferable, therefore is rational.
Similarly, the preference of is rational. Therefore, and are two disjoint, rational sets. Furthermore, the problem studied in this paper can be modeled as a one-to-one matching problem between collectors and high-level cluster heads which have received data packets from low-level clusters.
Each mobile collector ranks the high-level cluster heads in the order of its preference. Suppose that the set of preferences of a mobile collector on the set is represented by . For example, Equation (4) shows that, ranks first, second, the last. This indicates that most wants to match , followed by , and finally , which can be expressed as , . Similarly, the set of preferences of a high-level cluster head on the set is represented by . Equation (5) shows that, ranks first, second, the last. The preference set of two sides is represented by . As shown in Equation (6), a two-sided matching market is expressed as .
Theorem 1.
The matching function: If, then. If, then. is called the matching object of. The set of matched elements is represented by.
Theorem 2.
The kernel of a matching game is equal to the set of stable matches.
When researching the matching game, one critical assumption is that the matching process is voluntary. An element can send a matching invitation to another element. It also can reject a matching invitation from another element. If a match process is not implemented, it is said to be blocked. This assumption determines the core problem of the matching process between and : the stability of the matching process.
If a match is upset by another match , is better than and is unstable. Therefore, if is not in the kernel, it must be blocked by another match . For any , if the expression is valid, is better than . Meanwhile, suppose the expression is valid. Then considers to be better than . In brief, matches that are not in the kernel must be unstable, and unstable matches must not be in the kernel.
Therefore, the problem studied in this paper is equivalent to finding a stable matching set for the bilateral matching problem .
2.3. Benefit Matrix
The stable matching set of is related to the benefit matrices of high-level cluster heads and mobile collectors , which is expressed by Equations (7) and (8), where is the number of high-level cluster head, and is the number of collectors. The calculation method of and is introduced in this section.
Reference [6] has proposed the energy consumption model of sensor nodes. When the transmitter sends -bit information to the receiver with a distance of , the energy consumed is expressed by Equation (9). Where is the amplification coefficient, and is the multipath fading coefficient. The radio dissipates per bit to run the radio circuitry. We find that, the farther the sender and receiver are, the more energy they consume while communicating. In addition, each sensor node has a fixed communication range. When a collector wants to communicate with a cluster head, if it is not within the communication range of the cluster head, it needs to move to the range first. The farther it is from the cluster head, the longer it needs to move, and the greater the data delay. If it is within the communication range of the cluster head, it can communicate with the cluster head without moving. The closer they are, the less energy the cluster head consumes when communicating with it. Therefore, no matter from the perspective of energy consumption or data delay, the benefit of a high-level cluster head is mainly affected by the distance to the matched collector. If a high-level cluster head selects a collector , the benefit of is represented by Equation (10), where is the distance between and , and is the weight of the distance factor.
When a collector selects a high-level cluster head to visit, it considers the following three factors: (1) the time when the data packet was generated; (2) the priority of the data packet; (3) the distance between them. If a collector selects a high-level cluster head , the benefit of is represented by Equation (11), where , , can be obtained by querying in request sequence set , is the distance between and and , , are weights of the three factors.
Analytic hierarchy process (AHP) is a mathematical-based technology to derive the deciding factors for complex problems [21]. According to AHP, the decision maker indicates the strength of preference by the pairwise comparison between deciding factors. By answering the two questions “Which of the two is more important?” and “By how much?” the pairwise comparison is finished [22]. In this paper, the pairwise comparison results are expressed by a matrix in Equation (12).
The square matrix satisfies the Equation (13), where is characteristic value, and the nonzero vector is called the eigenvector of corresponding to . Constructing a weight vector contains three elements of , , , as shown in Equation (14). satisfies the Equation (15), which is proved in Equation (16). Therefore, the weights of the three factors can be obtained by computing the eigenvector of when the characteristic value is equal to 3. That is, to solve the homogeneous linear Equation (17), where is the unit matrix.
2.4. The One-to-One Matching Algorithm
After the benefit matrices are built, a one-to-one matching algorithm is proposed in this section. Some definitions are given as follows.
Theorem 3.
: The identification of the high-level cluster head which pre-matches with;
Theorem 4.
: The identification of the collector which pre-matches with;
Theorem 5.
: The matching state vector of;
Theorem 6.
: The matching state vector of;
Theorem 7.
: A pointer to an element in.
The steps of the one-to-one matching algorithm are as follows.
Step 1: During each collection cycle, for any collector , it computes the benefit matrix , which is expressed as Equation (18), where is defined by Equation (11). There is a special case. If a high-level cluster head has not received any data packet, the benefit for selecting it is equal to 0. For any high-level cluster head , it computes the benefit matrix , which is expressed as Equation (19), where is defined by Equation (10). There is also a special case. If a high-level cluster head has not received any data packet, the benefit for it selecting any collector is equal to 0.
Step 2: For any collector , it arranges the elements in in descending order according to their values. Then the high-level cluster heads are sorted according to the arrangement result, which is represented by Equation (20). That is, represents the high-level cluster head which benefits the most, represents the second, and so on. Initially, sends invitations to the high-level cluster head represented by .
Step 3: Assuming the high-level cluster head which receives the invitation from is . The following situations are discussed.
(1) If has not pre-matched any collector, satisfies the Equation (21). The following two situations are discussed.
(i) At the same time, if only receives the invitation from , accepts this invitation. Then, , , and are expressed by Equations (22)–(25), respectively.
(ii) At the same time, if receives invitations from multiple collectors, it inquires about , and selects the collector which benefits the most. If this collector is , accepts the invitation from . Otherwise, if this collector is not , assuming , accepts the invitation from , and refuses the invitations from other collectors. After is refused by , it, in turn, invites the cluster heads arranged behind in . Then repeat step 3 until each cluster head has pre-matched with a collector.
(2) If has been pre-matched a collector, assuming , and must satisfy the Equations (22) and (26). The following two situations are discussed.
(i) if and satisfy Equation (27), notifies to cancel the original pre-match , and accepts the invitation from . Then the pre-match is established, and is expressed by Equation (28).
(ii) If and satisfy Equation (29), refuses the invitations from . Then invites the cluster heads arranged behind in in turn. Then repeat step 3 until each cluster head has pre-matched a collector.
THEOREM 1 According to the matching algorithm proposed in this paper, there must exist a set of stable matches for the matching problem between and , and the matching result is stable, optimal and unique.
Proof.
According to the matching algorithm proposed in this paper, initially, each collector sends invitations to the high-level cluster head which benefits it the most. If a cluster head receives invitations from multiple collectors, it selects one collector which benefits it the most to accept its invitation, and rejects other collectors. Then these rejected collectors send invitations to their second preferred cluster heads. The algorithm terminates when all cluster heads are matched. Since the number of cluster heads is limited and the number of collectors is greater than or equal to the number of cluster heads, each cluster head must be able to find a collector to match it. Additionally, since the matching process is voluntary, the matching result must be consistent with the individual rationality. □
The next step is to prove that the matching result obtained by the matching algorithm is stable. Suppose and satisfy Equations (30) and (31). and prefer to form a match. That is, the Equations (32) and (33) are satisfied. Thus will send an invitation to . The following two situations are discussed. (i) if has not pre-matched any collector, will accept the invitation from . If it receives an invitation from later, it will refuse this invitation. (ii) if has had a pre-matching collector, will refuse this original pre-matching object and pre-match . and have not formed a matching pair until the matching algorithm is finished. Thus must refuse the invitation from , and the match cannot block . Therefore, the matching result is stable.
Then prove that the matching result is optimal. Suppose there is another matching result better than . Then there is at least one cluster head satisfying the inequality (34), and must block . So is unstable. As previously proved, is stable. Hence this assumption does not exist, and is optimal.
Finally, prove that the matching result is unique. As previously proved, is optimal. Suppose there is another matching result , and is another optimal match different from . Then there is at least one cluster head satisfying the inequality in Equation (35). Since is optimal, the inequality in Equation (36) holds. Since is optimal, the inequality in Equation (34) holds. Since means strict preference, the relationship between and must satisfy Equation (37). This conclusion contradicts the assumption that is different from . Therefore, is unique.
In conclusion, this matching result obtained by the matching algorithm proposed in this paper is stable, optimal and unique.
The pseudo code of the matching algorithm is given as follows.
| Algorithm: The one-to-one matching algorithm |
| 1 for do 2 3 4 5 6 7 end for 8 for do 9 10 11 end for 12 13 while do 14 for do 15 if then 16 invite the cluster head 17 if then 18 19 20 21 22 23 24 else 25 if then 26 if 27 28 29 else 30 doesn’t invite any cluster head 31 else 32 33 34 35 36 else 37 doesn’t invite any cluster head 38 end if 39 end if 40 end if 41 end if 42 end for 43 end while |
3. Simulation Results
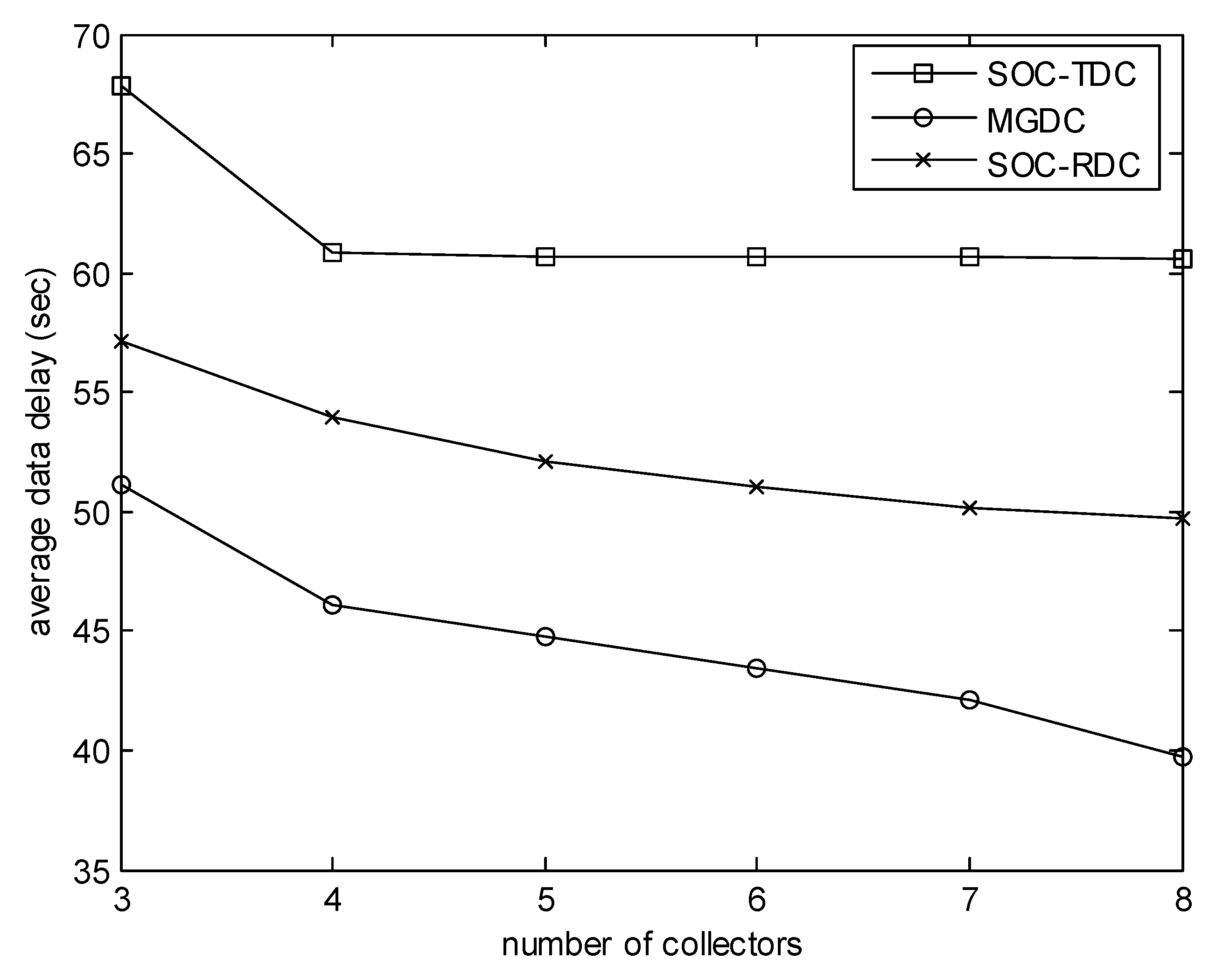
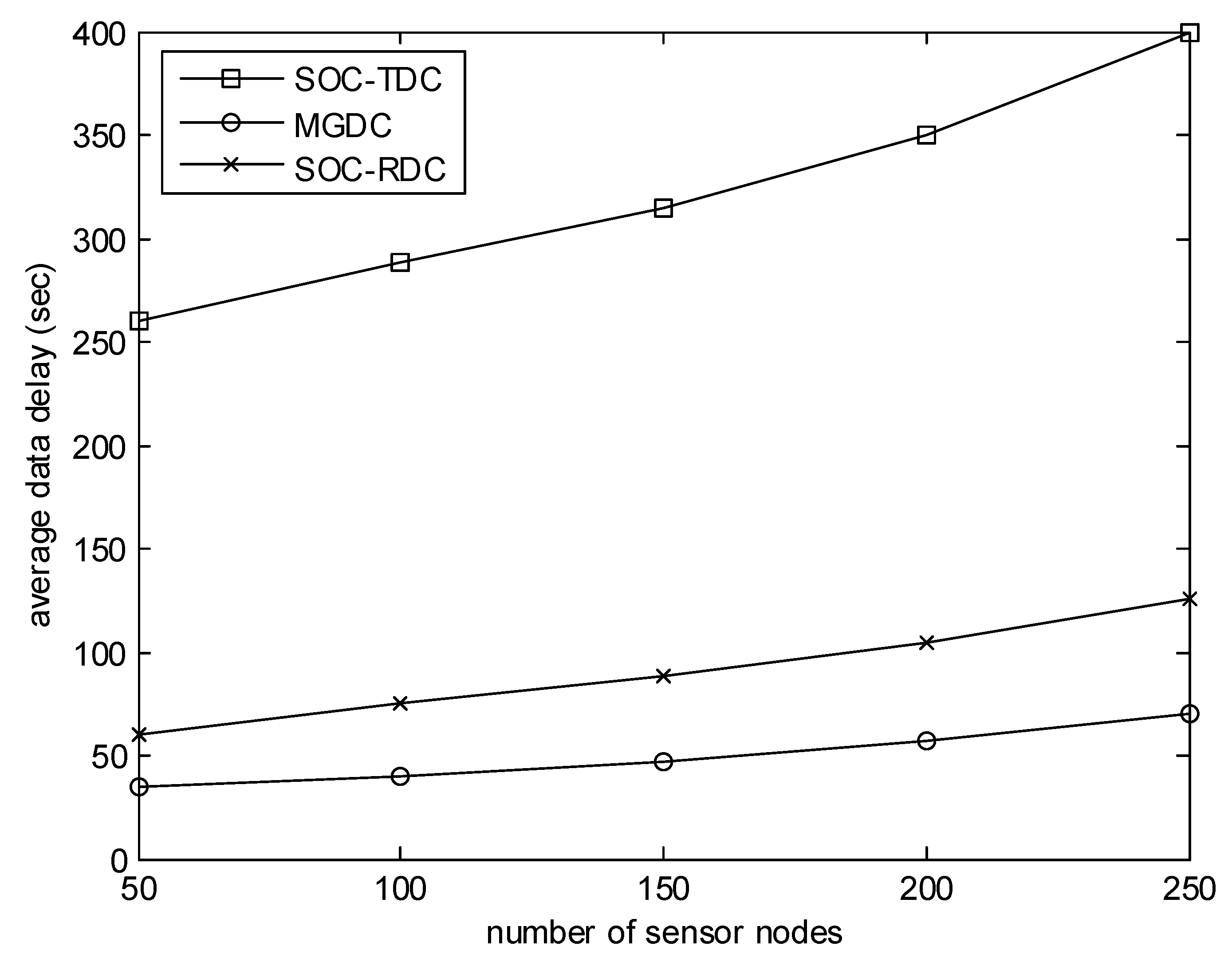
The performance of the matching algorithm proposed in this paper is evaluated by simulations in this section. In our simulations, sensor nodes are distributed uniformly in a square field without obstacles. The sink is located in the center of the area. Sensor nodes are event triggered. The parameter values used in the simulation are listed in Table 1. The simulations are performed using MATLAB R2017a. The communication range of each sensor node is set to 30 m. When a collector needs to communicate with a cluster head, if it is not within the communication range of the cluster head, it moves to the range first. Then it stops and sends an invitation message to the cluster head. If the cluster head accepts the invitation, a connection will be established between them. Then the cluster head stars sending data packets to the collector. After the collector has received the data packets, it notifies the cluster head to release the connection. Then the collector moves to another collection point. The matching game-based data collection algorithm for wireless sensor networks proposed in this paper is called MGDC. The matching game-based data collection algorithm (MGDC) is compared with the region based data collection algorithm (SOC-RDC) and the time based data collection algorithm (SOC-TDC) proposed in [20].
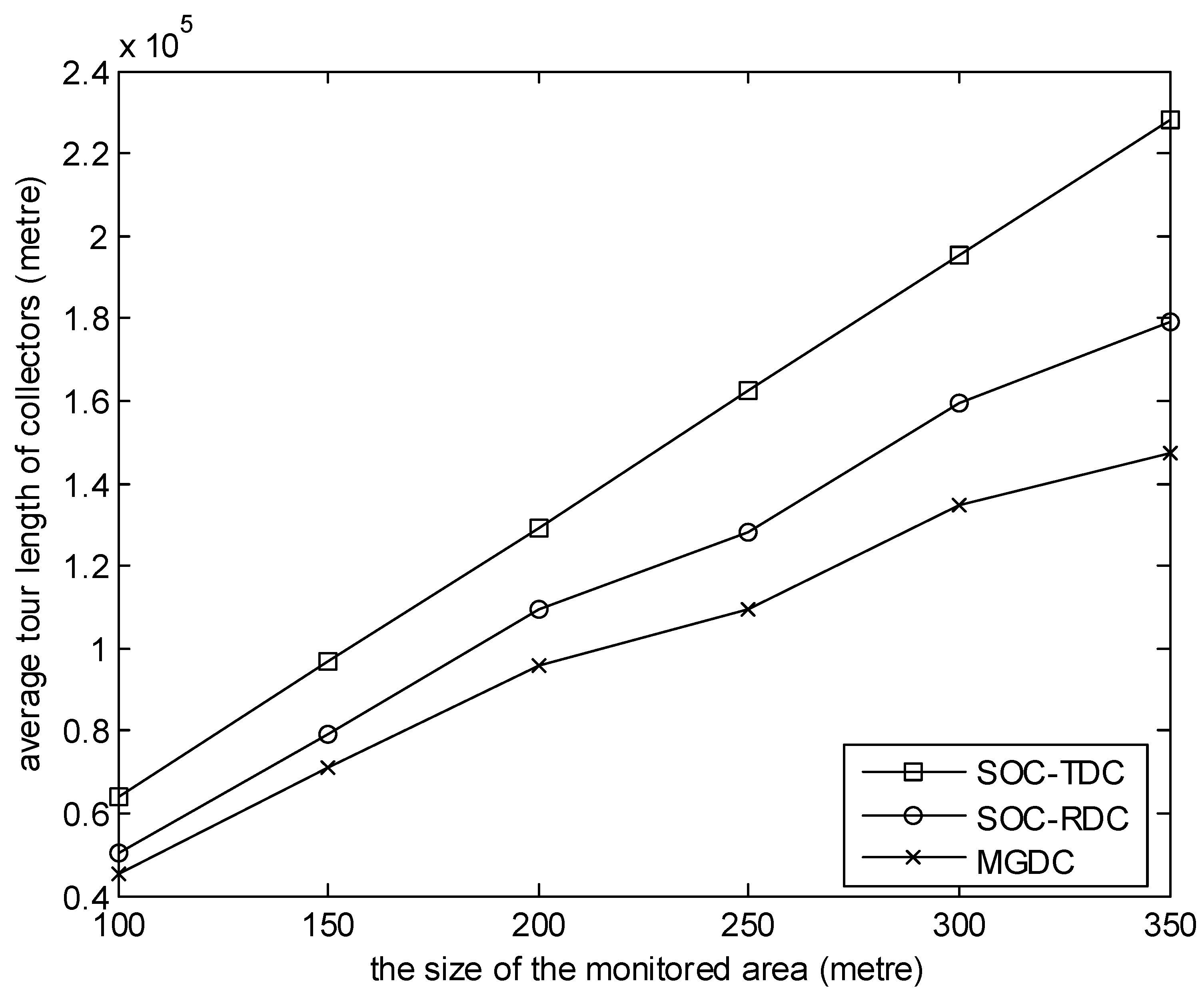
In the simulations shown in Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6, Equation (38) is satisfied. Figure 2 shows the relationship between the average tour length of collectors and the size of the monitored area during the simulation time. In the simulation, the number of collectors is 8, and the number of sensor nodes is 100. It can be observed from the figure that, with MGDC, the average tour length of collectors is smaller than that of SOC-RDC and SOC-TDC, and with the increase of the size of the monitored area, the gap between them increases. There are two reasons for this result. One reason is that, using SOC-TDC, the data packets generated at the same time are collected by one collector. These data packets may be scattered over different regions, so the collector moves a long distance to collect them. According to the MGDC, during a collection cycle, a collector only visit a high-level cluster head, so it moves a short distance. Another reason is, according to SOC-RDC, data packets generated at the same time are collected by several collectors, not one collector. Some collectors may select the same region. Under this circumstance, the sink randomly selects one of these collectors to collect data packets in this region. The choice may not be optimal. However, the matching result of MGDC between collectors and high level cluster heads is optimal. With the increase of the size of the monitored area, the distribution of sensor nodes is becoming more and more dispersed, so the advantages of MGDC are becoming more and more obvious.
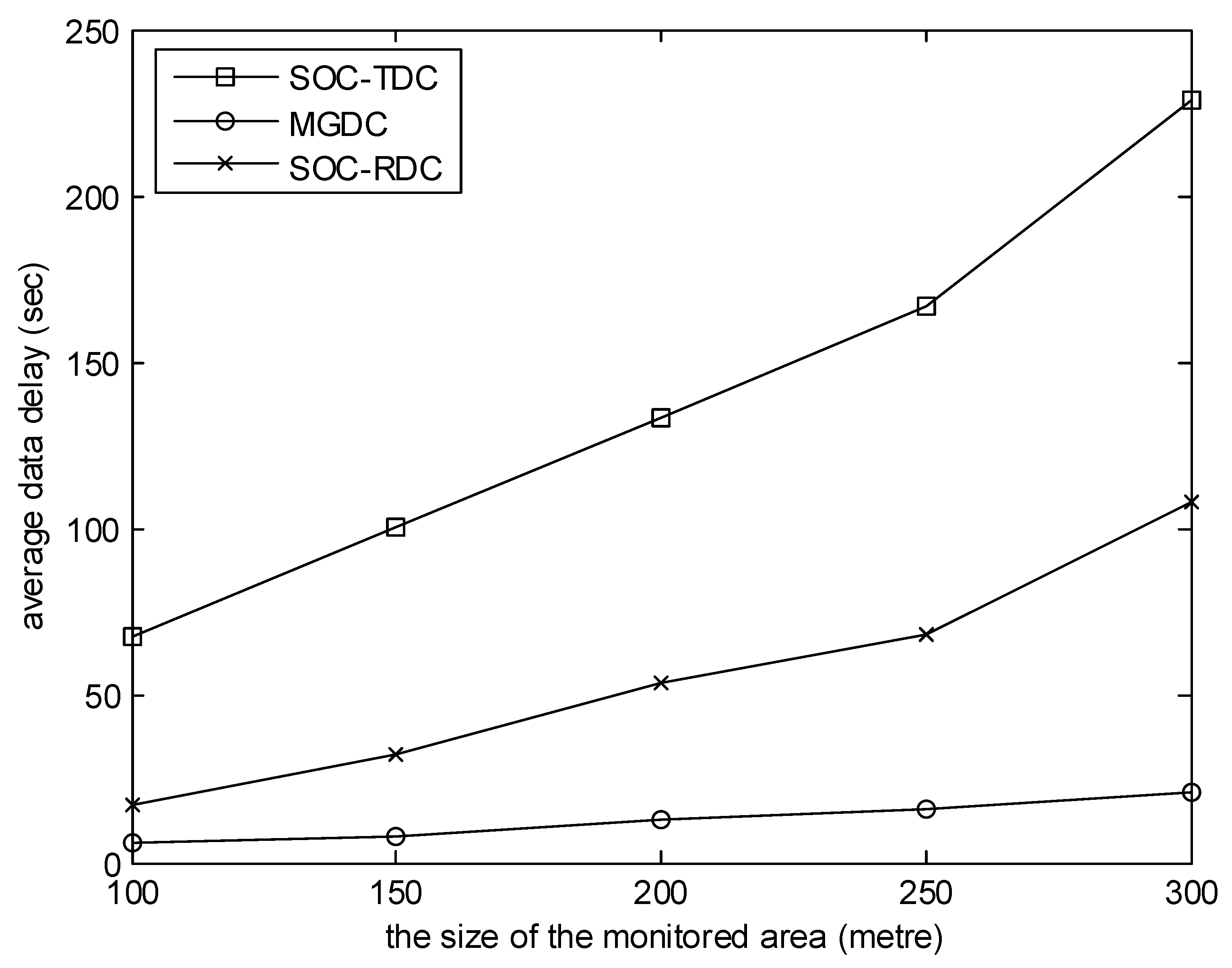
Figure 3 shows the relationship between the average data delay and the size of the monitored area during the simulation time. Data delay is the time difference between the data packet generated and the data packet collected by a collector. In the simulation, the number of collectors is 8, and the number of sensor nodes is 100. It can be seen from the figure that the average data delay of MGDC is smaller than that of SOC-RDC and SOC-TDC. And as the size of the monitored area increases, the gap between them increases. One reason is that, using MGDC, the average tour length of collectors is smaller than that of SOC-RDC and SOC-TDC. Another reason is that, using MGDC, the matching process between collectors and cluster heads takes into account several factors, such as time and position, rather than considering a single factor.
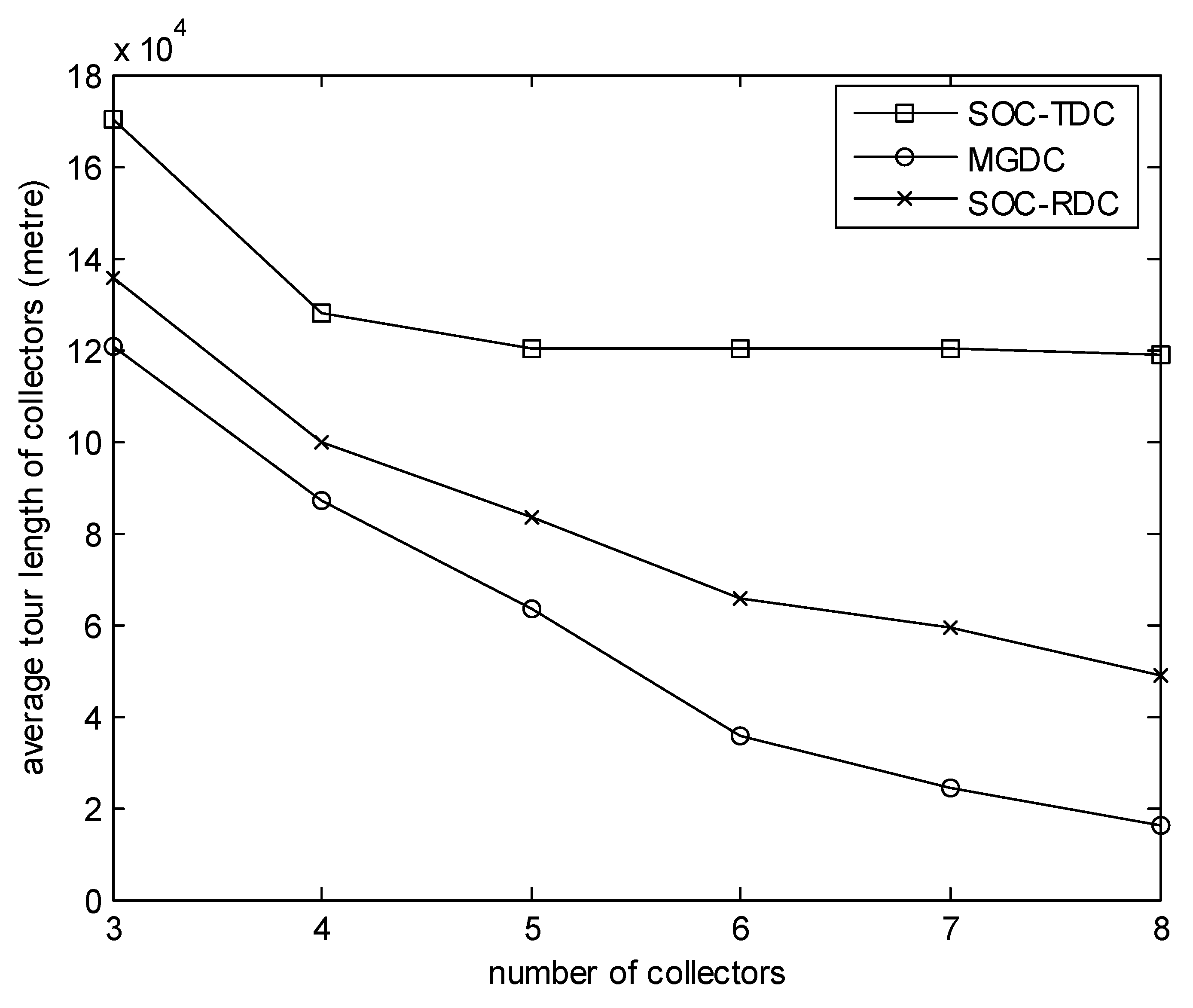
Figure 4 focuses on the effect of the number of collectors on the average tour length of collectors. In this experiment, the number of sensors is 100, and the size of the monitored area is 100 m. We can observe that when the number of collectors is small, the advantage of MGDC is not obvious. This is because, during the simulation time, when the number of high-level cluster heads which have received data packets is greater than the number of collectors, one collector needs to visit several cluster heads. The average tour length of collectors is long. Furthermore, when the number of collectors is small, the options of cluster heads are few, and the difference between SOC-RDC and MGDC is not obvious. However, when the number of collectors increases, the combinations between cluster heads and collectors increase, and the advantages of MGDC become more obvious. Since the data packets generated at the same time are collected by one collector according to SOC-TDC, as the number of collectors increases, some collectors are idle. Hence, for SOC-TDC, as more collectors are added, the impact on average tour length of collectors is not significant.
Figure 5 highlights the effect of the number of collectors on the average data delay. In this experiment, the number of sensors is 50, and the size of the monitored area is 100 m. We can find that MGDC performs better than SOC-RDC and SOC-TDC. The more the number of collectors, the more obvious the advantage of MGDC.
Figure 6 evaluates the effect of the number of sensor nodes on the average data delay. In this experiment, the number of collectors is 6, and the size of the monitored area is 400 m. As illustrated in Figure 6, when the number of sensor nodes increases, the average data delay increases. The reason is that, when the number of nodes is small, the number of high-level cluster heads is small, and there are few optional objects for collectors. The gap between MGDC and SOC-RDC is not obvious. With the increase of the number of sensor nodes, the number of clusters and nodes which have monitored events increases. There are more optional objects for collectors, and the gap between MGDC and SOC-RDC becomes more and more obvious.
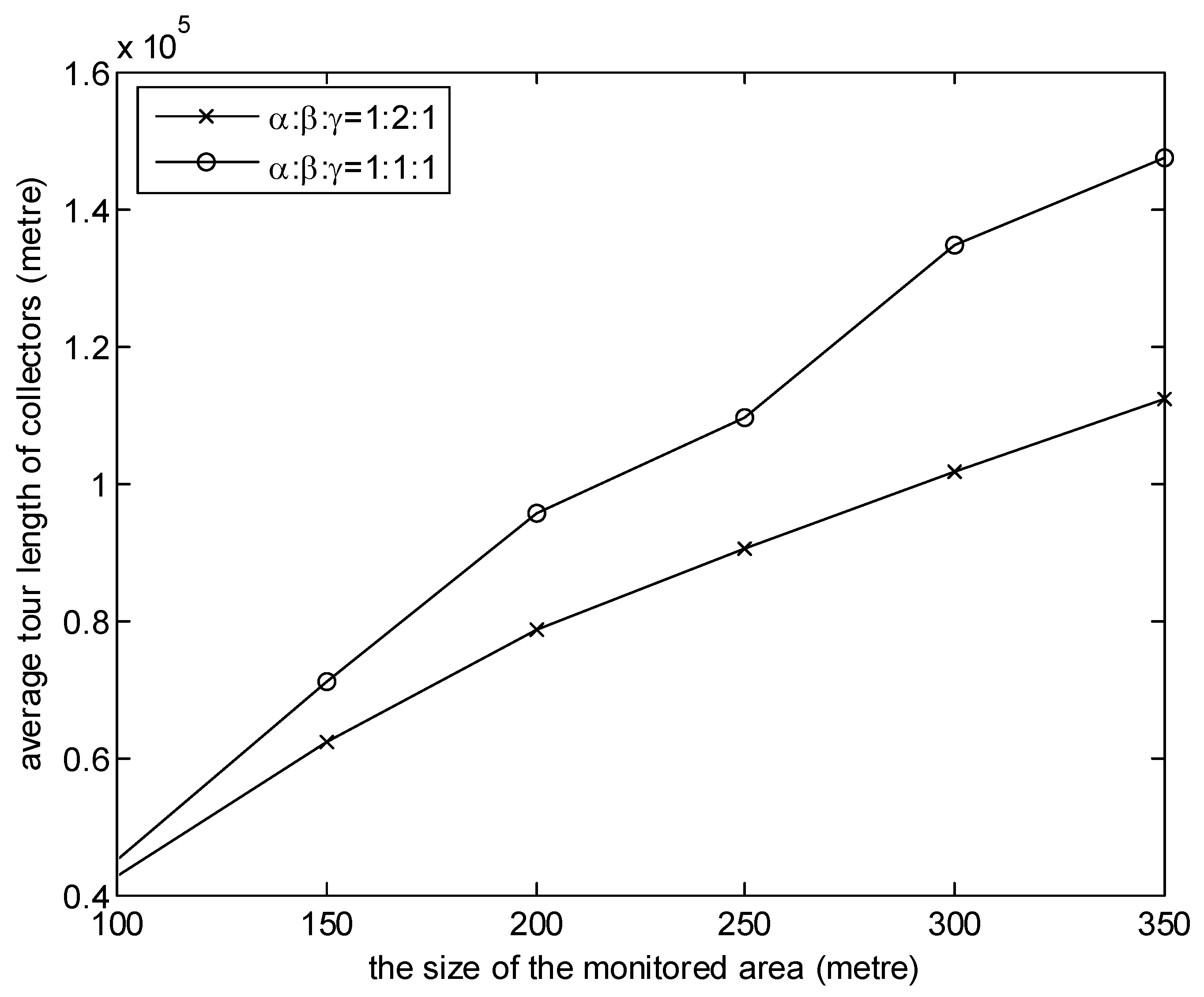
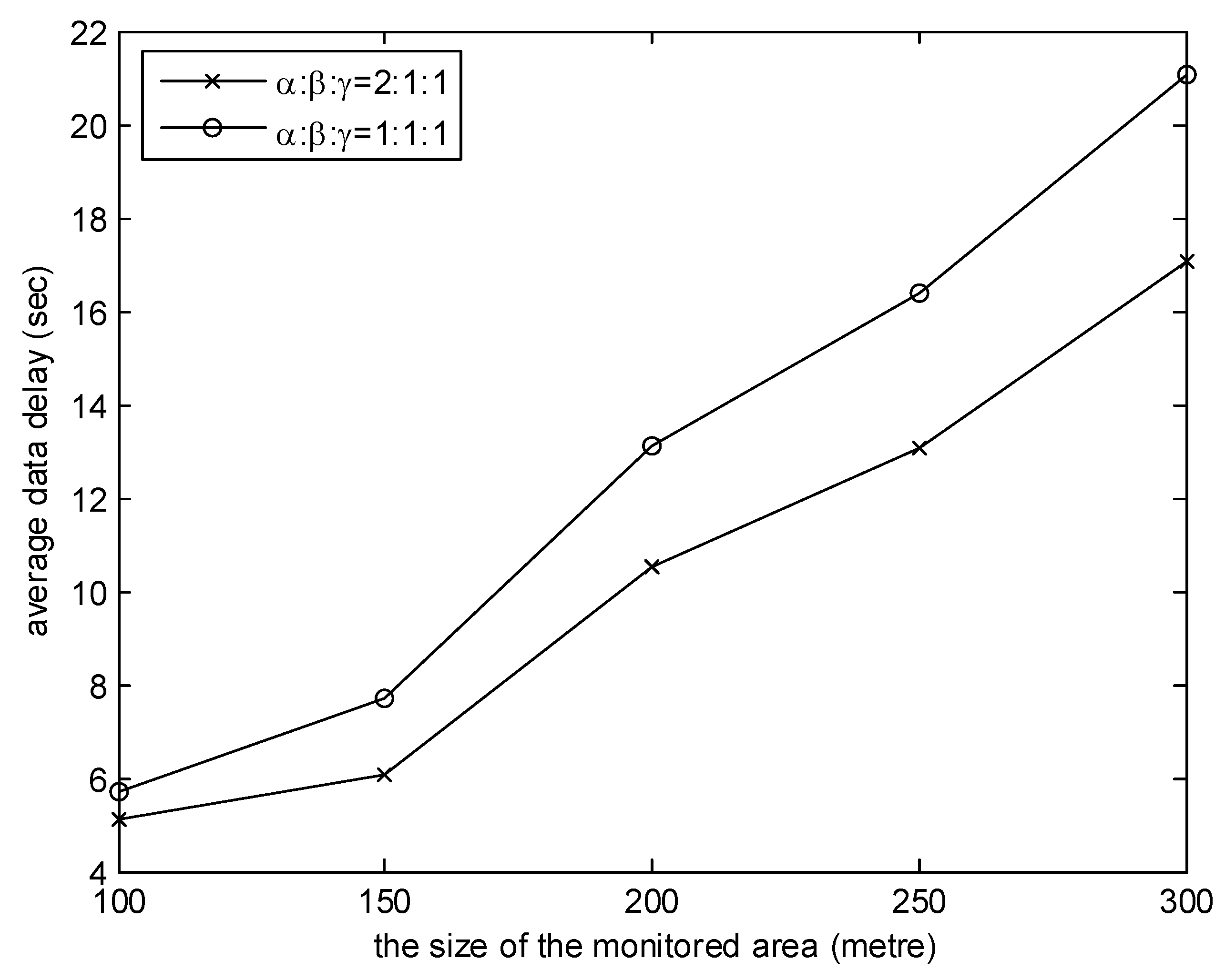
Figure 7 and Figure 8 investigate the effects of the weights of three factors of MGDC. In the simulations, the number of collectors is 8. It is observed from the graph in Figure 7 that the higher the proportion of , the shorter the average moving distance. This is because, when the proportion of is high, according to the benefit of the collector obtained from Equation (11), collectors will give priority to the near cluster head. As illustrated in Figure 8, the higher the proportion of , the smaller the data delay. The reason is that, when the proportion of is high, according to the benefit of the collector obtained from Equation (11), the cluster head which has collected the data packets with the earlier generation time will be the first choice of collectors.
4. Conclusions
Sensor nodes consume most of energy for data transmission and the battery of sensor nodes cannot be replaced in many complex environments, therefore it is necessary to introduce mobile collectors to collect data. Since the speed of collectors is limited, it will cause data delay. Therefore, the problem of this paper is how to make multiple collectors cooperate with each other to reduce data delay. Based on the matching game theory, the problem is modeled as a one-to-one matching problem between collectors and high-level cluster heads. Then, a one-to-one matching algorithm is proposed. Simulation results show that as the size of the monitored area, the number of collectors and the number of sensors increase, the advantage of this algorithm in reducing data delay becomes more and more obvious.
Author Contributions
C.Z. designed the algorithm, analyzed the data, and wrote the paper; S.F. revised the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (No. 61903198).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, J.; Lin, Z.W.; Tsai, P.W.; Xu, L. Entropy-driven data aggregation method for energy-efficient wireless sensor networks. Inf. Fusion. 2020, 56, 103–113. [Google Scholar] [CrossRef]
- Tao, L.; Zhang, X.M.; Liang, W.F. Efficient Algorithms for Mobile Sink Aided Data Collection From Dedicated and Virtual Aggregation Nodes in Energy Harvesting Wireless Sensor Networks. IEEE Trans. Green Commun. Netw. 2019, 3, 1058–1071. [Google Scholar] [CrossRef]
- Yang, S.S.; Adeel, U.; Tahir, Y.; McCann, J.A. Practical Opportunistic Data Collection in Wireless Sensor Networks with Mobile Sinks. IEEE Trans. Mob. Comput. 2017, 16, 1420–1433. [Google Scholar] [CrossRef] [Green Version]
- Heinzelman, W.R.; Chandrakasan, A.P.; Balakrishnan, H. An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wireless Commun. 2002, 1, 660–670. [Google Scholar] [CrossRef] [Green Version]
- Younis, O.; Fahmy, S. HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans. Mob. Comput. 2004, 3, 366–379. [Google Scholar] [CrossRef] [Green Version]
- Smaragdakis, G.; Matta, I.; Bestavros, A. SEP: A stable election protocol for clustered heterogeneous wireless sensor networks. In Proceedings of the Second International Workshop on Sensor and Actor Network Protocols and Applications, Boston, MA, USA, 22 August 2004; pp. 1–11. [Google Scholar]
- Lung, C.H.; Zhou, C.J. Using hierarchical agglomerative clustering in wireless sensor networks: An energy-efficient and flexible approach. Ad Hoc Netw. 2010, 8, 328–344. [Google Scholar] [CrossRef]
- Oh, S.; Lee, E.; Park, S.; Jung, J.; Kim, S.H. Communication scheme to support sink mobility in multi-hop clustered wireless sensor networks. In Proceedings of the 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, Australia, 20–23 April 2010; pp. 866–872. [Google Scholar] [CrossRef]
- Nitesh, K.; Azharuddin, M.; Jana, P. Minimum spanning tree-based delay-aware mobile sink traversal in wireless sensor networks. Int. J. Commun. Syst. 2017, 30, 1–11. [Google Scholar] [CrossRef]
- Jain, S.; Shah, R.C.; Brunette, W.; Borriello, G.; Roy, S. Exploiting mobility for energy efficient data collection in wireless sensor networks. Mob. Netw. Appl. 2006, 11, 327–339. [Google Scholar] [CrossRef] [Green Version]
- Tashtarian, F.; Sohraby, K.; Varasteh, A. Multihop data gathering in wireless sensor networks with a mobile sink. Int. J. Commun. Syst. 2017, 30, 1–14. [Google Scholar] [CrossRef]
- Wu, S.Y.; Liu, J.S. Evolutionary path planning of a data mule in wireless sensor network by using shortcuts. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation, Beijing, China, 6–11 July 2014; pp. 2708–2715. [Google Scholar] [CrossRef]
- Kim, D.; Uma, R.N.; Abay, B.H.; Wu, W.L.; Wang, W.; Tokuta, A.O. Minimum latency multiple data mule trajectory planning in wireless sensor networks. IEEE Trans. Mob. Comput. 2014, 13, 838–851. [Google Scholar] [CrossRef]
- Sugihara, R.; Gupta, R.K. Optimal speed control of mobile node for data collection in sensor networks. IEEE Trans. Mob. Comput. 2010, 9, 127–139. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, Y.Y. Bounded relay hop mobile data gathering in wireless sensor networks. IEEE Trans. Comput. 2012, 61, 265–277. [Google Scholar] [CrossRef]
- Dasgupta, R.; Yoon, S. Energy-efficient deadline-aware data-gathering scheme using multiple mobile data collectors. Sensors 2017, 17, 742. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gong, J.; Chang, T.H.; Shen, C.; Chen, X. Flight time minimization of UAV for data collection over wireless sensor networks. IEEE J. Sel. Areas Commun. 2018, 36, 1942–1954. [Google Scholar] [CrossRef] [Green Version]
- EI Fissaoui, M.; Beni-Hssane, A.; Saadi, M. Energy efficient and fault tolerant distributed algorithm for data aggregation in wireless sensor networks. J. Ambient Intell. Humaniz. Comput. 2019, 10, 569–578. [Google Scholar] [CrossRef]
- Sohrabi, K.; Gao, J.; Ailawadhi, V.; Pottie, G.J. Protocols for self-organization of a wireless sensor network. IEEE Pers. Commun. 2000, 7, 16–27. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Fei, S.M.; Zhou, X.P. Energy efficient data collection in hierarchical wireless sensor networks. China Commun. 2012, 9, 79–88. [Google Scholar] [CrossRef]
- Saaty, T.L. Fundamentals of the analytic network process-dependence and feedback in decision-making with a single network. J. Syst. Sci. Syst. Eng. 2004, 2, 129–157. [Google Scholar] [CrossRef]
- Song, Q.Y.; Jamalipour, A. A network selection mechanism for next generation networks. In Proceedings of the IEEE International Conference on Communications, Seoul, Korea, 16–20 May 2005; pp. 1418–1422. [Google Scholar]
Figure 1.
Architecture of the wireless sensor network.

Figure 2.
The size of the monitored area versus average tour length of collectors.

Figure 3.
The size of the monitored area versus average data delay.

Figure 4.
Number of collectors versus average tour length of collectors.

Figure 5.
Number of collectors versus average data delay.

Figure 6.
Number of sensor nodes versus average data delay.

Figure 7.
The effect of the weights on average tour length of collectors.

Figure 8.
The effect of the weights on average data delay.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation parameters.
| Parameters | Values |
|---|---|
| radio bandwidth of sink (Mbps) | 1 |
| sensing range of a sensor node (m) | 20 |
| transmission range of a mobile collector (m) | 35 |
| speed of a mobile collector (m/s) | 5 |
| event packet size (bytes) | 100 |
| request packet size (bytes) | 25 |
| packet head size (bytes) | 25 |
| simulation time (s) | 40,000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, C.; Fei, S. A Matching Game-Based Data Collection Algorithm with Mobile Collectors. Sensors 2020, 20, 1398. https://doi.org/10.3390/s20051398
AMA Style
Zhang C, Fei S. A Matching Game-Based Data Collection Algorithm with Mobile Collectors. Sensors. 2020; 20(5):1398. https://doi.org/10.3390/s20051398
Chicago/Turabian StyleZhang, Chun, and Shumin Fei. 2020. "A Matching Game-Based Data Collection Algorithm with Mobile Collectors" Sensors 20, no. 5: 1398. https://doi.org/10.3390/s20051398
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.