Deeply Recursive Low- and High-Frequency Fusing Networks for Single Image Super-Resolution


Abstract
:1. Introduction
- Proposing a deeply recursive low- and high-frequency fusing network (DRFFN) for SISR tasks, this network adopts the structure of parallel branches to extract the low- and high-frequency information of the image, respectively. The different complexities of the branches can reflect the frequency characteristics of diverse image information.
- Proposing a channel attention mechanism based on variance (VCA), it focuses the feature map with a smaller variance for the low-frequency branches due to uniform information distribution, while the channel with a larger variance is concerned for the high-frequency branches because of the vast deviation in information distribution.
- Proposing the cascading recursive learning of recursive units to keep DRFFN compact, where a deep recursive layer is learned, and the weights are shared by all convolutional recursions. It is worth mentioning that the performance of DRFFN is significantly improved by increasing depth without incurring any additional weight parameters, and it had the best performance among various methods in the experiments on all benchmark datasets.
2. Related Works
2.1. Residual Learning
2.2. Recursive Learning
2.3. Attention Mechanism
3. Proposed Method
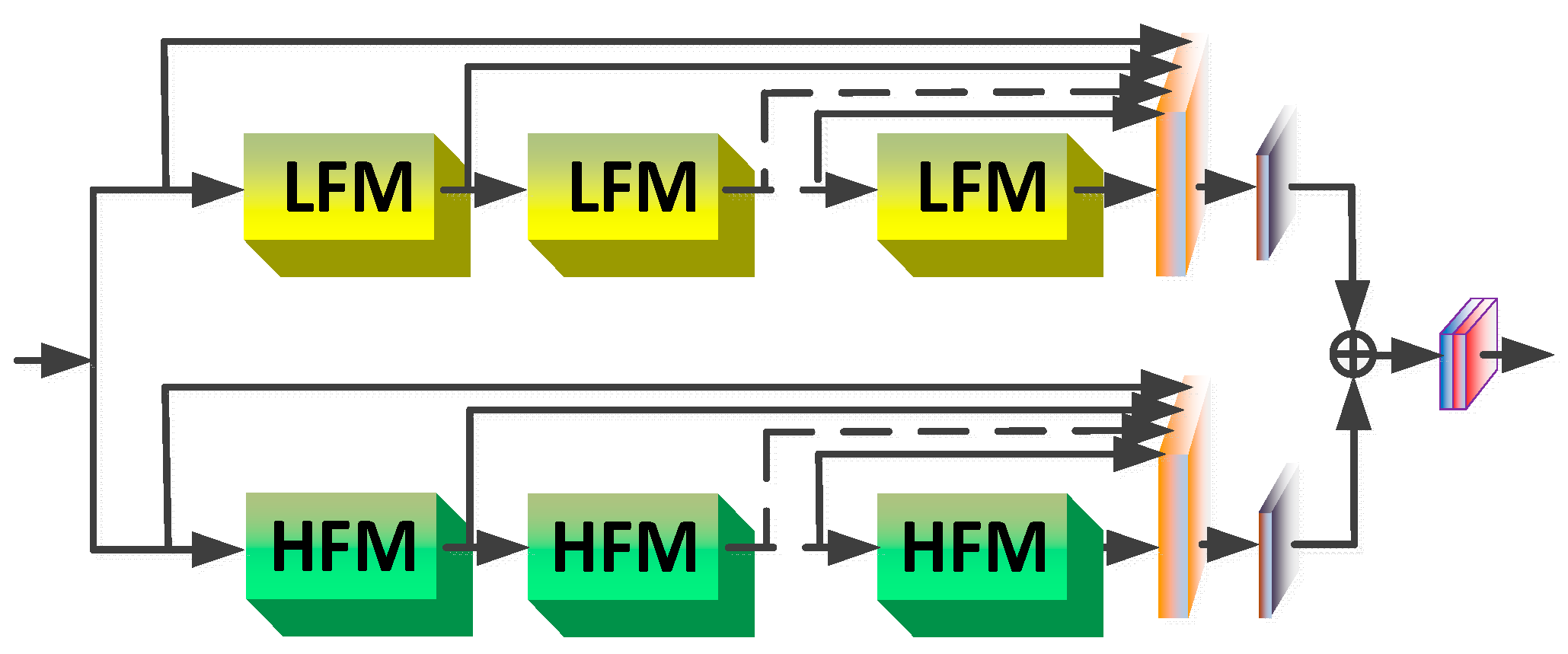
3.1. Network Architecture
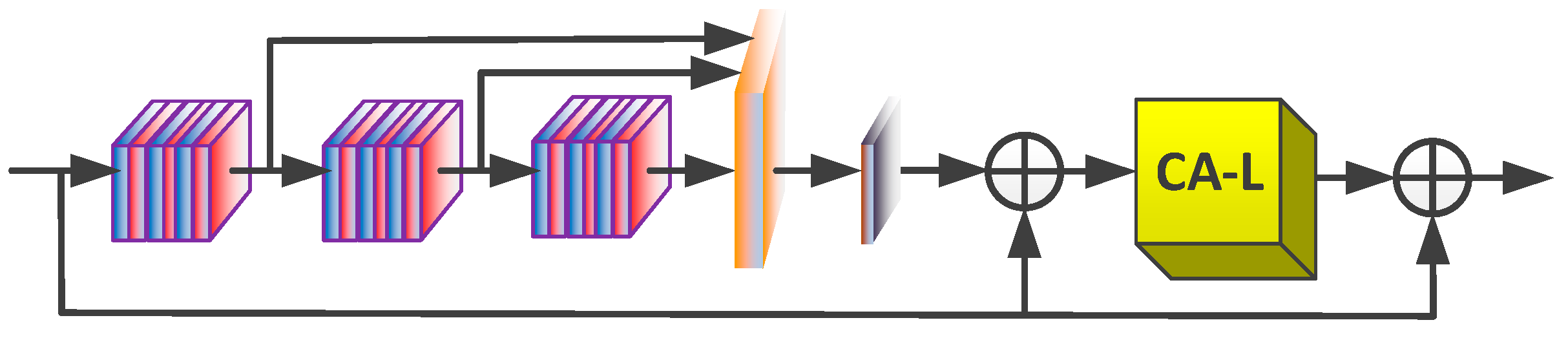
3.2. Deeply Recursive Frequency Fusing Module
3.3. Low-Frequency Module
3.4. High-Frequency Module
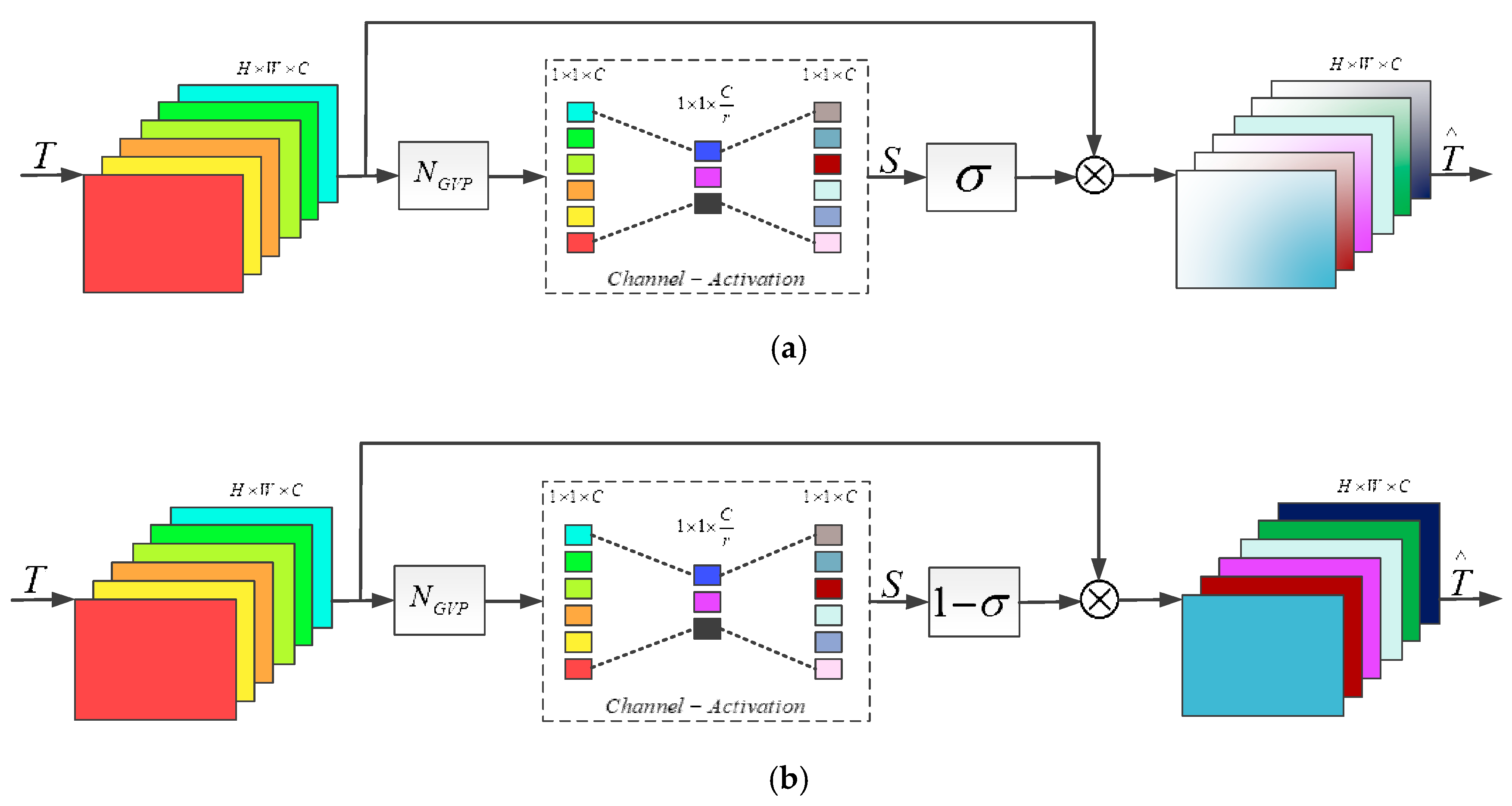
3.5. Channel Attention Block
3.6. Implementation Details
4. Experiments
4.1. Datasets
4.2. Training Settings
4.3. Ablation Studies
4.3.1. Skip Connections
4.3.2. Concatenation Aggregation
4.3.3. Variance-Based Channel Attention
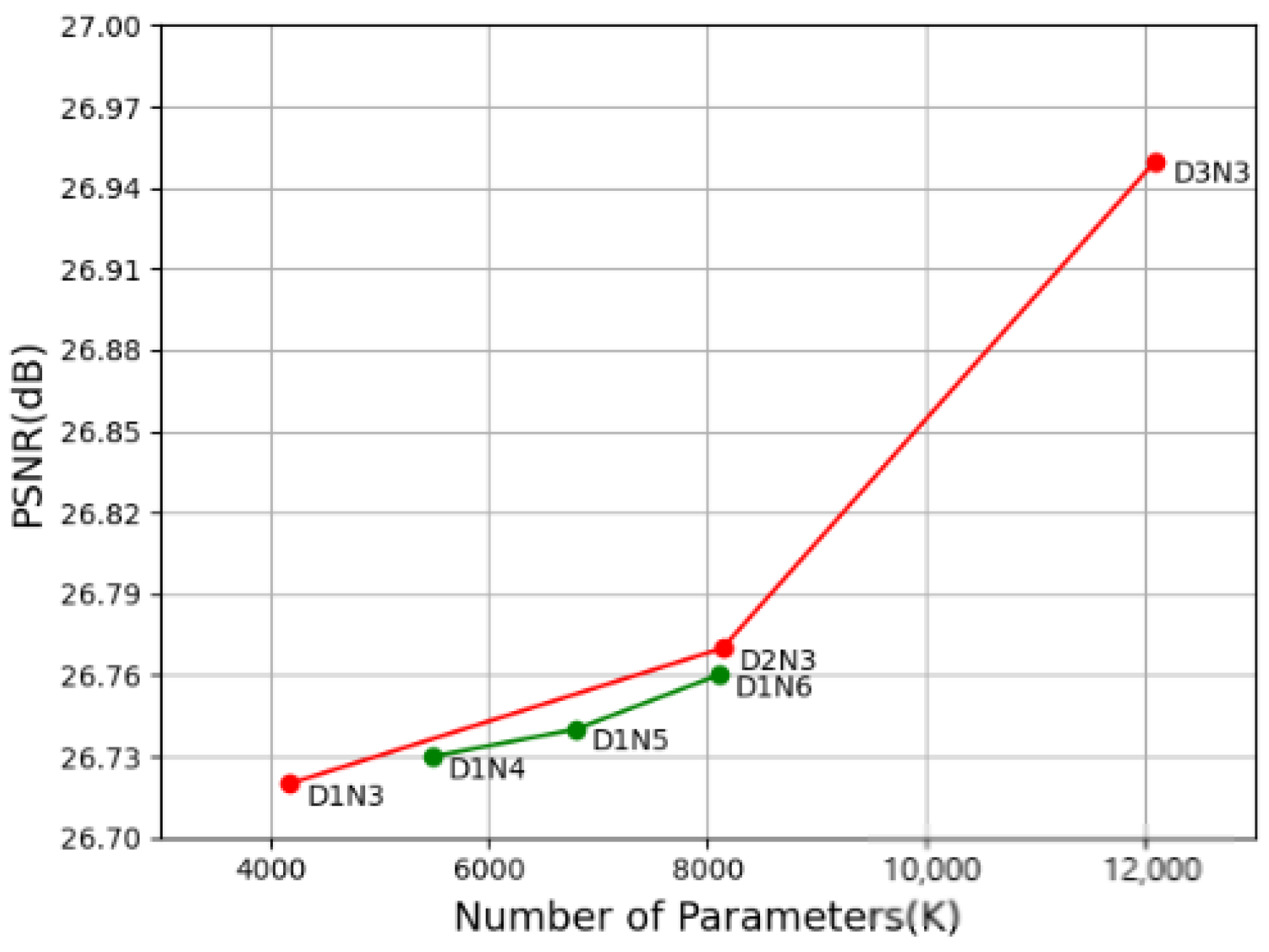
4.4. Model Analyses
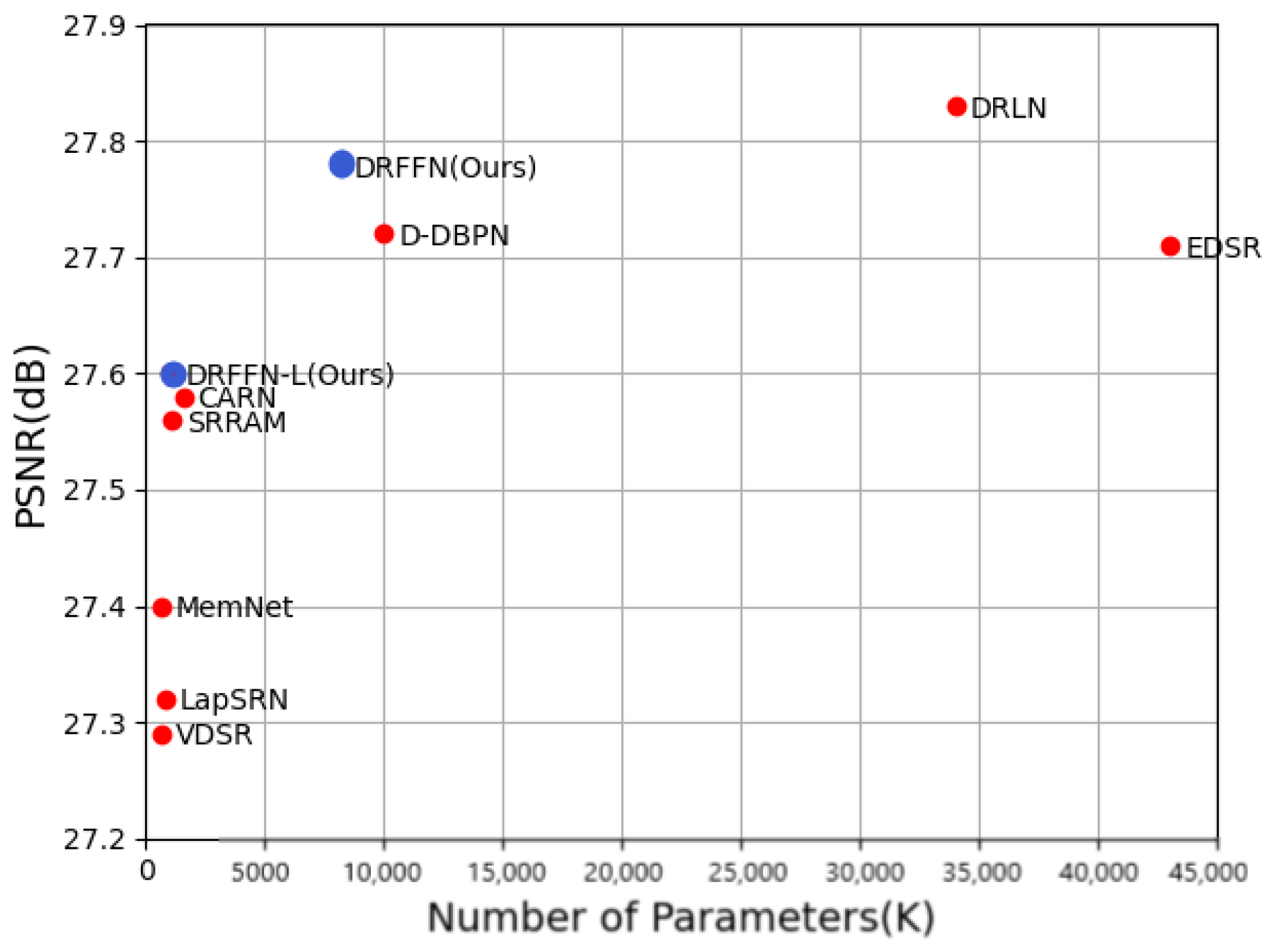
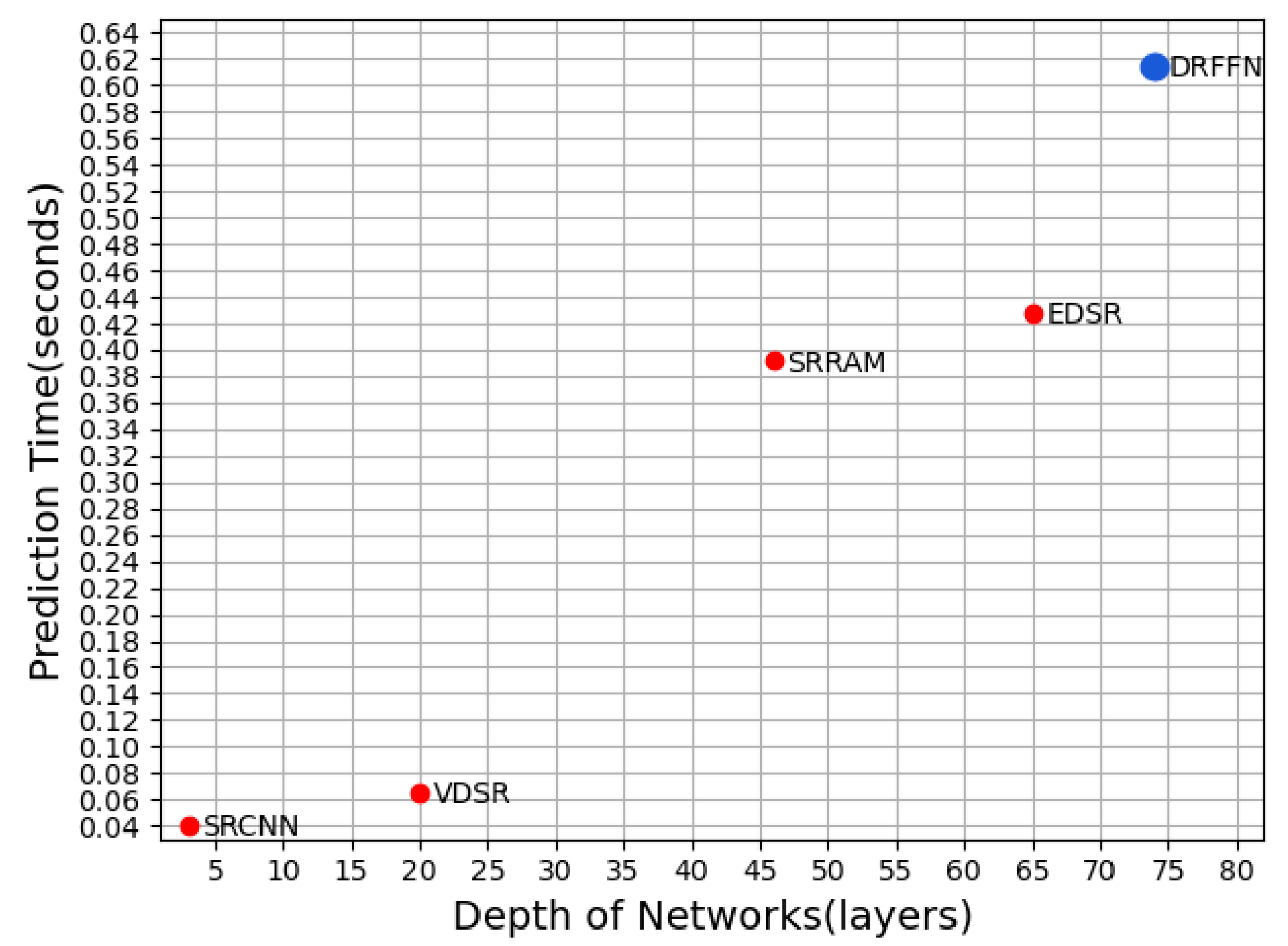
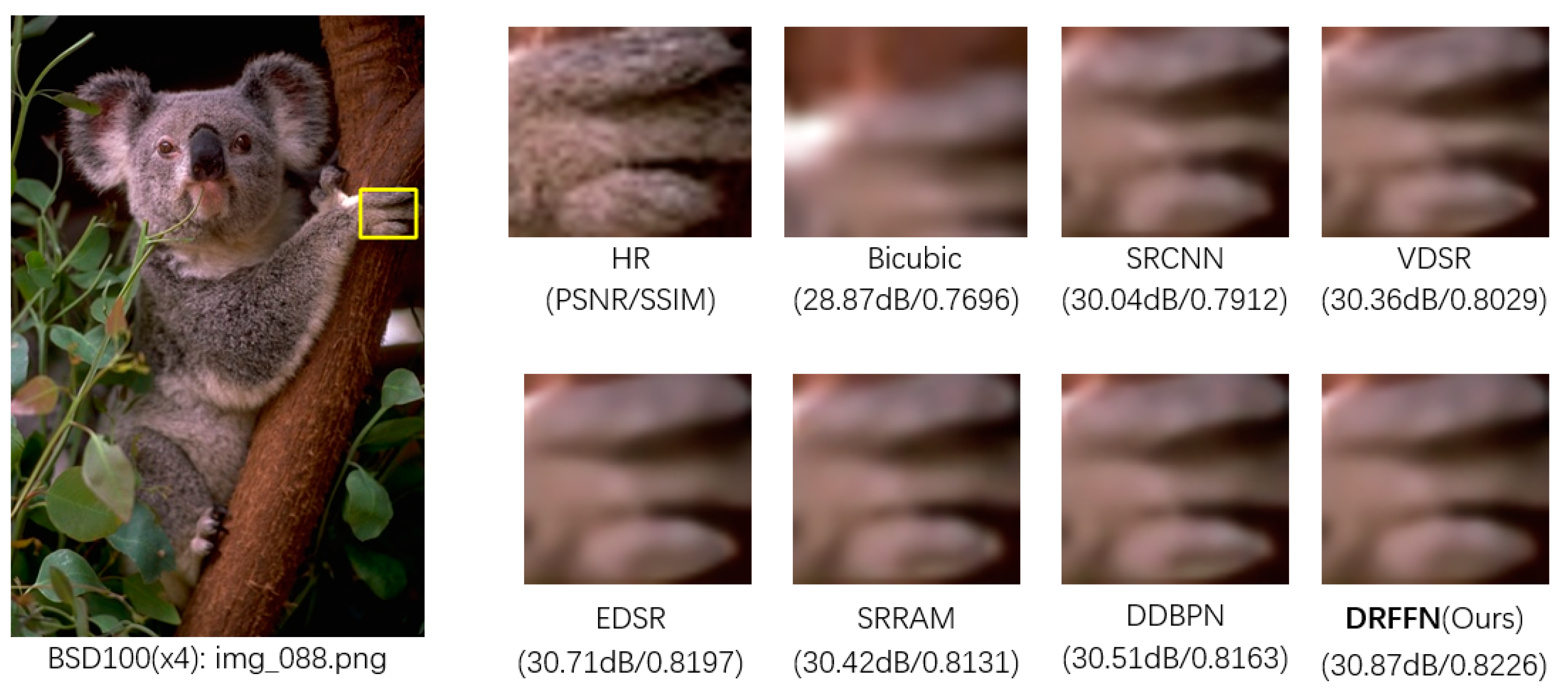
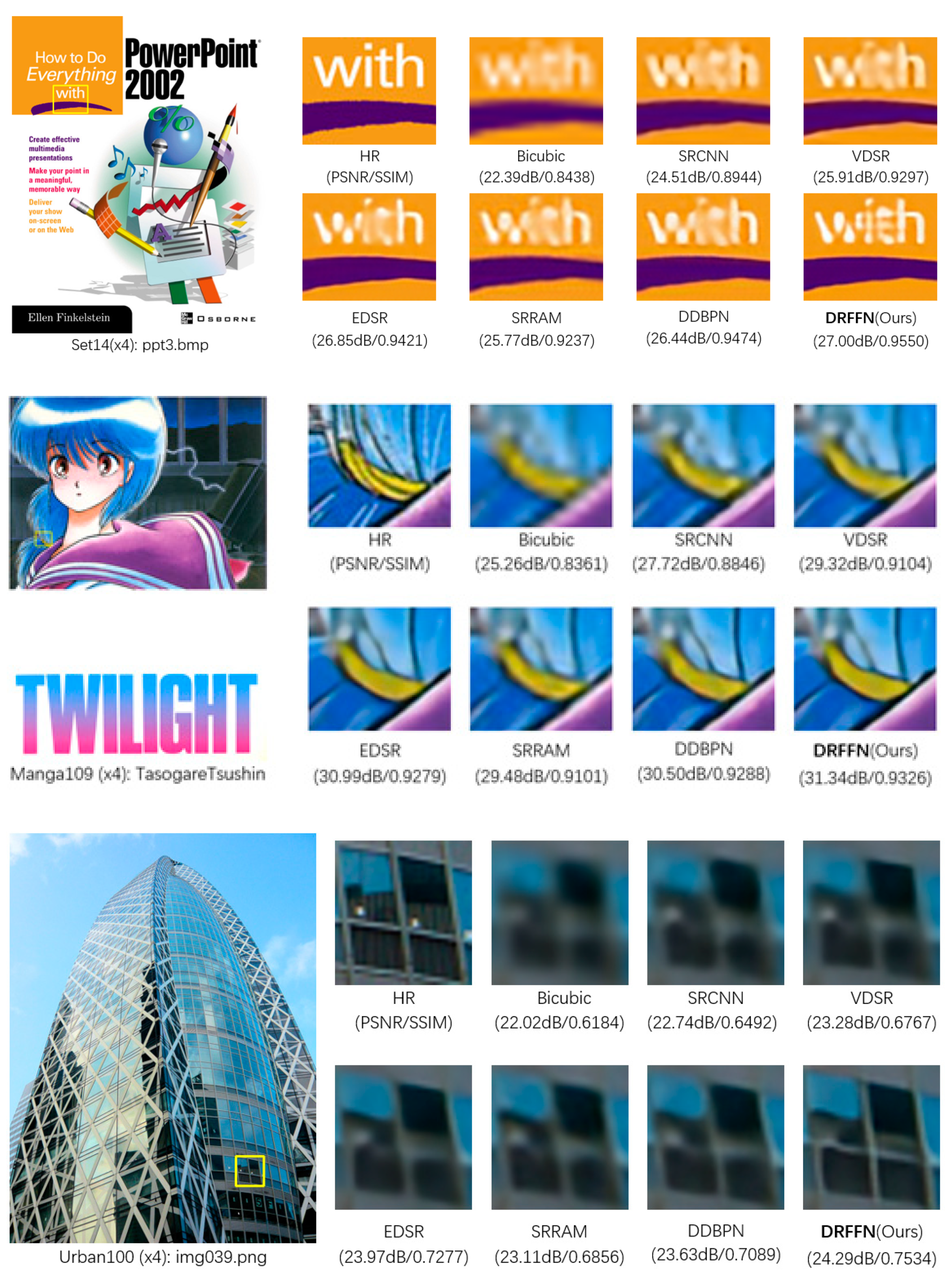
4.5. Comparison with State-of-the-Art Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Greenspan, H. Super-resolution in medical imaging. Comput. J. 2009, 52, 43–63. [Google Scholar] [CrossRef]
- Mudunuri, S.P.; Biswas, S. Low resolution face recognition across variations in pose and illumination. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1034–1040. [Google Scholar] [CrossRef] [PubMed]
- Lobanov, A.P. Resolution limits in astronomical images. arXiv 2005, arXiv:astro-ph/0503225. [Google Scholar]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Kim, K.I.; Kwon, Y. Single-image super-resolution using sparse regression and natural image prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1127–1133. [Google Scholar] [PubMed]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Qiu, Y.; Wang, R.; Tao, D.; Cheng, J. Embedded block residual network: A recursive restoration model for single-image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4180–4189. [Google Scholar]
- Kim, J.-H.; Choi, J.-H.; Cheon, M.; Lee, J.-S. Ram: Residual attention module for single image super-resolution. arXiv 2018, arXiv:1811.12043. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Athens, Greece, 7–10 October 2018; pp. 2472–2481. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Anwar, S.; Barnes, N. Densely residual laplacian super-resolution. arXiv 2019, arXiv:1906.12021. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 391–407. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4491–4500. [Google Scholar]
- Park, S.-J.; Son, H.; Cho, S.; Hong, K.-S.; Lee, S. Srfeat: Single image super-resolution with feature discrimination. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 439–455. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 723–731. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 252–268. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Zhao, Y.; Wang, R.-G.; Jia, W.; Wang, W.-M.; Gao, W. Iterative projection reconstruction for fast and efficient image upsampling. Neurocomputing 2017, 226, 200–211. [Google Scholar] [CrossRef] [Green Version]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012. [Google Scholar]
- Ioffe, S. Batch renormalization: Towards reducing minibatch dependence in batch-normalized models. Adv. Neural Inf. Process. Syst. 2017, 30, 1945–1953. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Choi, J.-S.; Kim, M. A deep convolutional neural network with selection units for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 154–160. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, X.; Feng, J.; Peng, Q.; Yan, S. Diversified visual attention networks for fine-grained object classification. IEEE Trans. Multimed. 2017, 19, 1245–1256. [Google Scholar] [CrossRef] [Green Version]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Han, W.; Chang, S.; Liu, D.; Yu, M.; Witbrock, M.; Huang, T.S. Image super-resolution via dual-state recurrent networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1654–1663. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.-H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Honolulu, HI, USA, 21–26 July 2017; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Orhan, A.E.; Pitkow, X. Skip connections eliminate singularities. arXiv 2017, arXiv:1701.09175. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module Name | Options | ||||||
|---|---|---|---|---|---|---|---|
| Skip Connection | √ | × | √ | × | √ | × | √ |
| Concatenation Aggregation | × | √ | √ | × | × | √ | √ |
| Variance-based Channel Attention | × | × | × | √ | √ | √ | √ |
| PSNR (dB) | 32.35 | 32.33 | 32.43 | 32.41 | 32.47 | 32.45 | 32.50 |
| Method | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | ×2 | 33.68/0.9304 | 30.24/0.8691 | 29.56/0.8453 | 26.88/0.8405 | 30.80/0.9399 |
| SRCNN | 36.66/0.9542 | 32.45/0.9067 | 31.36/0.8879 | 29.51/0.8946 | 35.60/0.9663 | |
| FSRCNN | 36.98/0.9556 | 32.62/0.9087 | 31.50/0.8904 | 29.85/0.9009 | 36.67/0.9710 | |
| VDSR | 37.53/0.9587 | 33.05/0.9127 | 31.90/0.8960 | 30.77/0.9141 | 37.22/0.9750 | |
| LapSRN | 37.52/0.9591 | 32.99/0.9124 | 31.80/0.8949 | 30.41/0.9101 | 37.27/0.9740 | |
| EDSR | 38.11/0.9602 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | 39.10/0.9773 | |
| MemNet | 37.78/0.9597 | 33.28/0.9142 | 32.08/0.8978 | 31.31/0.9195 | 37.72/0.9740 | |
| D-DBPN | 38.09/0.9600 | 33.85/0.9190 | 32.27/0.9000 | 32.55/0.9324 | 38.89/0.9775 | |
| CARN | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | 38.36/0.9764 | |
| SRRAM | 37.82/0.9592 | 33.48/0.9171 | 32.12/0.8983 | 32.05/0.9264 | 38.89/0.9775 | |
| SRFBN | 38.11/0.9609 | 33.82/0.9196 | 32.29/0.9010 | 32.62/0.9328 | 38.86/0.9774 | |
| DRLN | 38.27/0.9616 | 34.28/0.9231 | 32.44/0.9028 | 33.37/0.9390 | 39.58/0.9786 | |
| DRFFN(Ours) | 38.16/0.9649 | 34.02/0.9248 | 32.23/0.9075 | 32.81/0.9369 | 39.45/0.9781 | |
| Bicubic | ×3 | 30.40/0.8686 | 27.54/0.7741 | 27.21/0.7389 | 24.46/0.7349 | 26.95/0.8556 |
| SRCNN | 32.75/0.9090 | 29.29/0.8215 | 28.41/0.7863 | 26.24/0.7991 | 30.48/0.9117 | |
| FSRCNN | 33.16/0.9140 | 29.42/0.8242 | 28.52/0.7893 | 26.41/0.8064 | 31.10/0.9210 | |
| VDSR | 33.66/0.9213 | 29.78/0.8318 | 28.83/0.7976 | 27.14/0.8279 | 32.01/0.9340 | |
| LapSRN | 33.82/0.9227 | 29.79/0.8320 | 28.82/0.7973 | 27.07/0.8271 | 32.21/0.9350 | |
| EDSR | 34.65/0.9280 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | 34.17/0.9476 | |
| MemNet | 34.09/0.9248 | 30.00/0.8350 | 28.96/0.8001 | 27.56/0.8376 | 32.51/0.9369 | |
| CARN | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | 33.49/0.9440 | |
| SRRAM | 34.30/0.9256 | 30.32/0.8417 | 29.07/0.8039 | 28.12/0.8507 | / | |
| SRFBN | 34.70/0.9292 | 30.51/0.8461 | 29.24/0.8084 | 28.73/0.8641 | / | |
| DRLN | 34.78/0.9303 | 30.73/0.8488 | 29.36/0.8117 | 29.21/0.8772 | 34.71/0.9509 | |
| DRFFN(Ours) | 34.81/0.9458 | 30.85/0.8634 | 29.39/0.8289 | 28.66/0.8544 | 34.38/0.9518 | |
| Bicubic | ×4 | 28.43/0.8109 | 26.00/0.7023 | 25.96/0.6678 | 23.14/0.6574 | 24.89/0.7866 |
| SRCNN | 30.48/0.8628 | 27.50/0.7513 | 26.90/0.7103 | 24.52/0.7226 | 27.58/0.8555 | |
| FSRCNN | 30.70/0.8657 | 27.59/0.7535 | 26.96/0.7128 | 24.60/0.7258 | 27.90/0.8610 | |
| VDSR | 31.25/0.8838 | 28.02/0.7678 | 27.29/0.7252 | 25.18/0.7525 | 28.83/0.8870 | |
| LapSRN | 31.54/0.8866 | 28.09/0.7694 | 27.32/0.7264 | 25.21/0.7553 | 29.09/0.8900 | |
| EDSR | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | 31.02/0.9184 | |
| MemNet | 31.74/0.8893 | 28.26/0.7723 | 27.40/0.7281 | 25.50/0.7630 | 29.42/0.8942 | |
| D-DBPN | 32.47/0.8980 | 28.82/0.7860 | 27.72/0.7400 | 26.38/0.7946 | 30.91/0.9137 | |
| CARN | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | 30.40/0.9082 | |
| SRRAM | 32.13/0.8932 | 28.54/0.7800 | 27.56/0.7650 | 26.05/0.7834 | / | |
| SRFBN | 32.47/0.8983 | 28.81/0.7868 | 27.72/0.7409 | 26.60/0.8051 | 31.15/0.9160 | |
| DRLN | 32.63/0.9002 | 28.94/0.7900 | 27.83/0.7444 | 26.98/0.8119 | 31.54/0.9196 | |
| DRFFN(Ours) | 32.50/0.9077 | 28.88/0.8002 | 27.78/0.7550 | 26.25/0.7735 | 31.08/0.9185 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Lu, G. Deeply Recursive Low- and High-Frequency Fusing Networks for Single Image Super-Resolution. Sensors 2020, 20, 7268. https://doi.org/10.3390/s20247268
Yang C, Lu G. Deeply Recursive Low- and High-Frequency Fusing Networks for Single Image Super-Resolution. Sensors. 2020; 20(24):7268. https://doi.org/10.3390/s20247268
Chicago/Turabian StyleYang, Cheng, and Guanming Lu. 2020. "Deeply Recursive Low- and High-Frequency Fusing Networks for Single Image Super-Resolution" Sensors 20, no. 24: 7268. https://doi.org/10.3390/s20247268