Intact Detection of Highly Occluded Immature Tomatoes on Plants Using Deep Learning Techniques


Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition and Labelling
2.2. Data Pre-Processing
2.2.1. Training and Validation Datasets
2.2.2. Test Dataset
2.3. Tomato Detection Model Generation
2.3.1. Train Multiple Tomato Detection Models and Select the Model with the Highest Accuracy
2.3.2. Detect Tomatoes Using the Selected Model on the Test Dataset
2.4. Evaluation Metrics
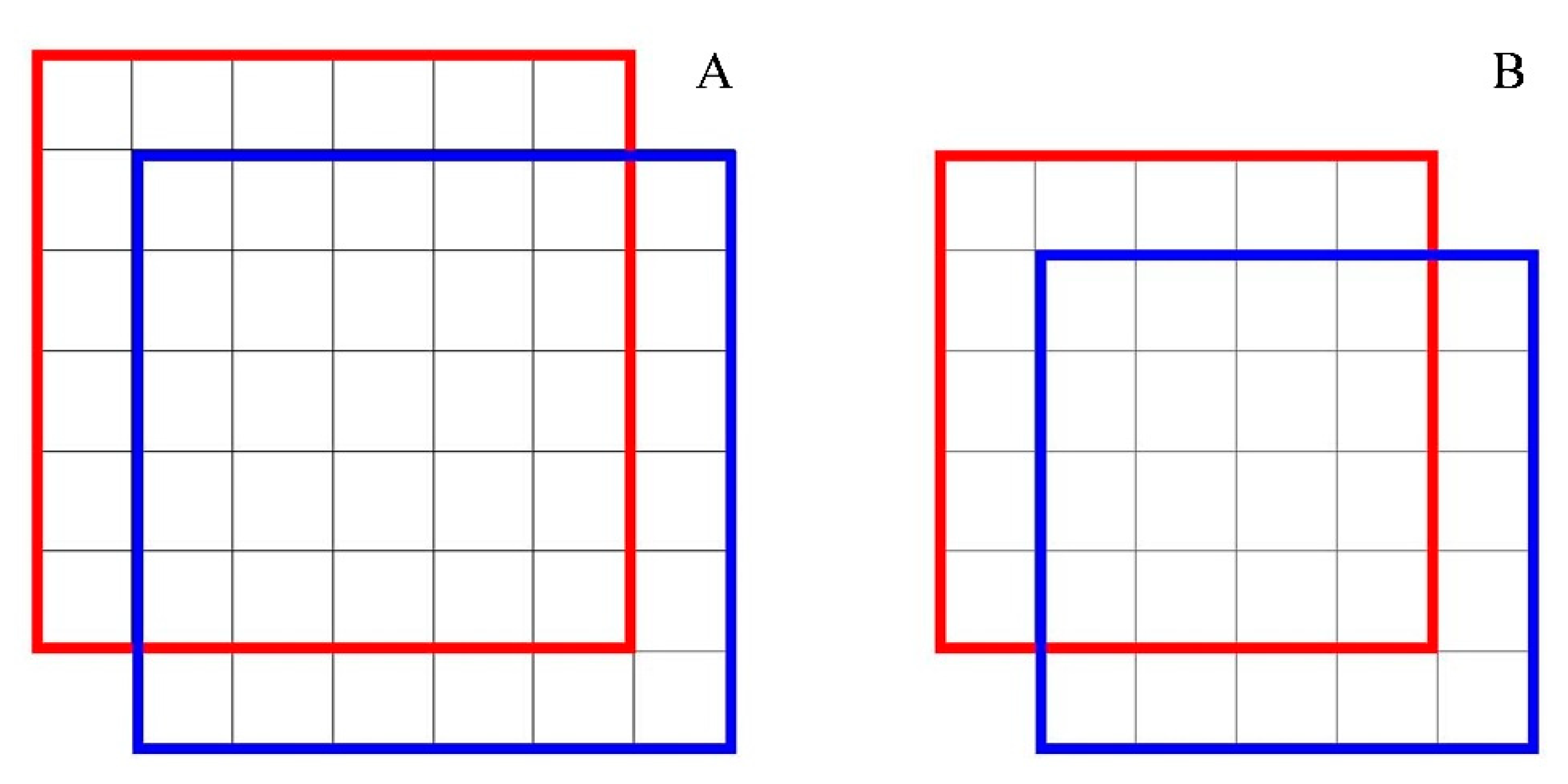
2.5. Tomato Localization
2.6. Tomato Size Estimation
3. Results
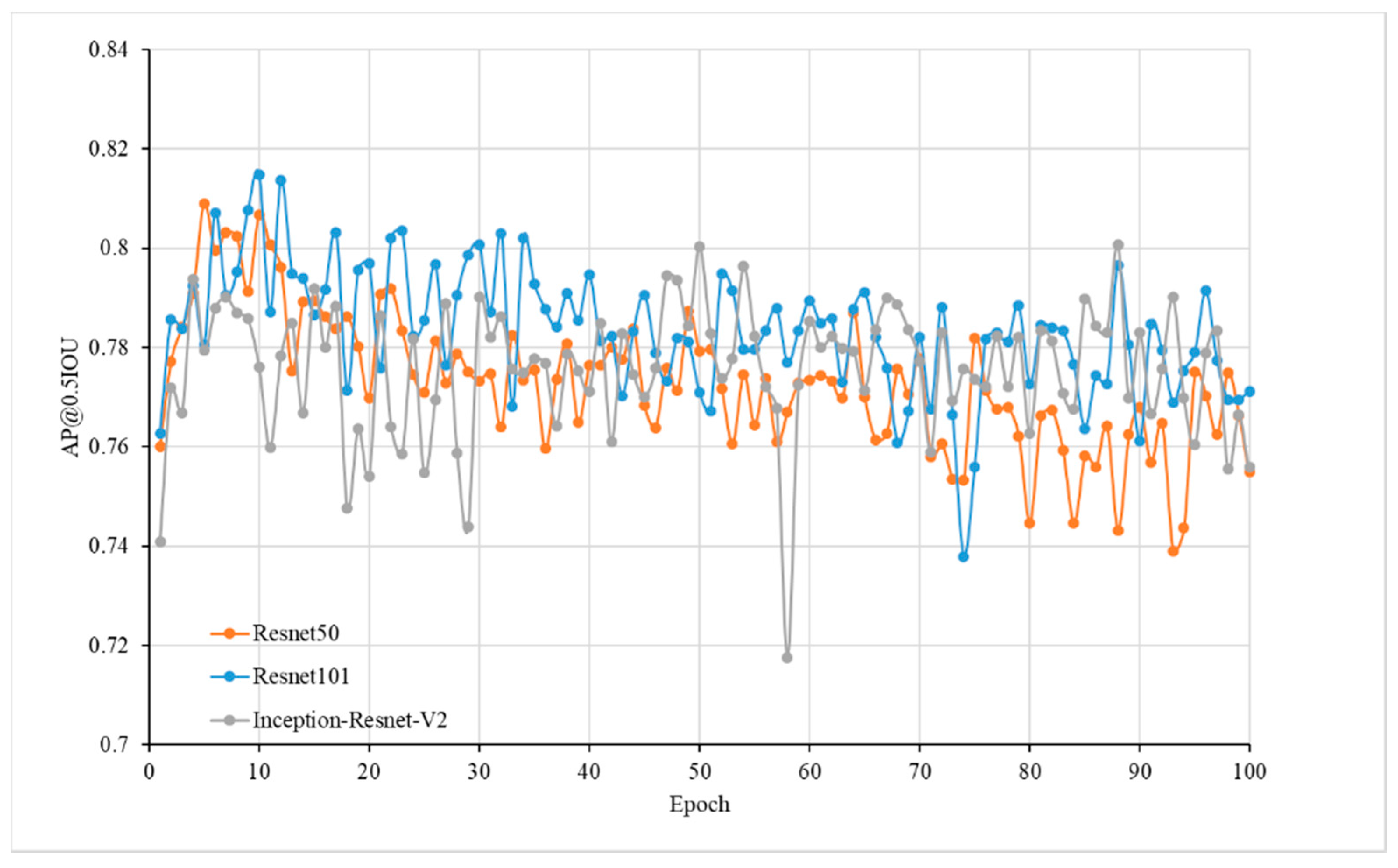
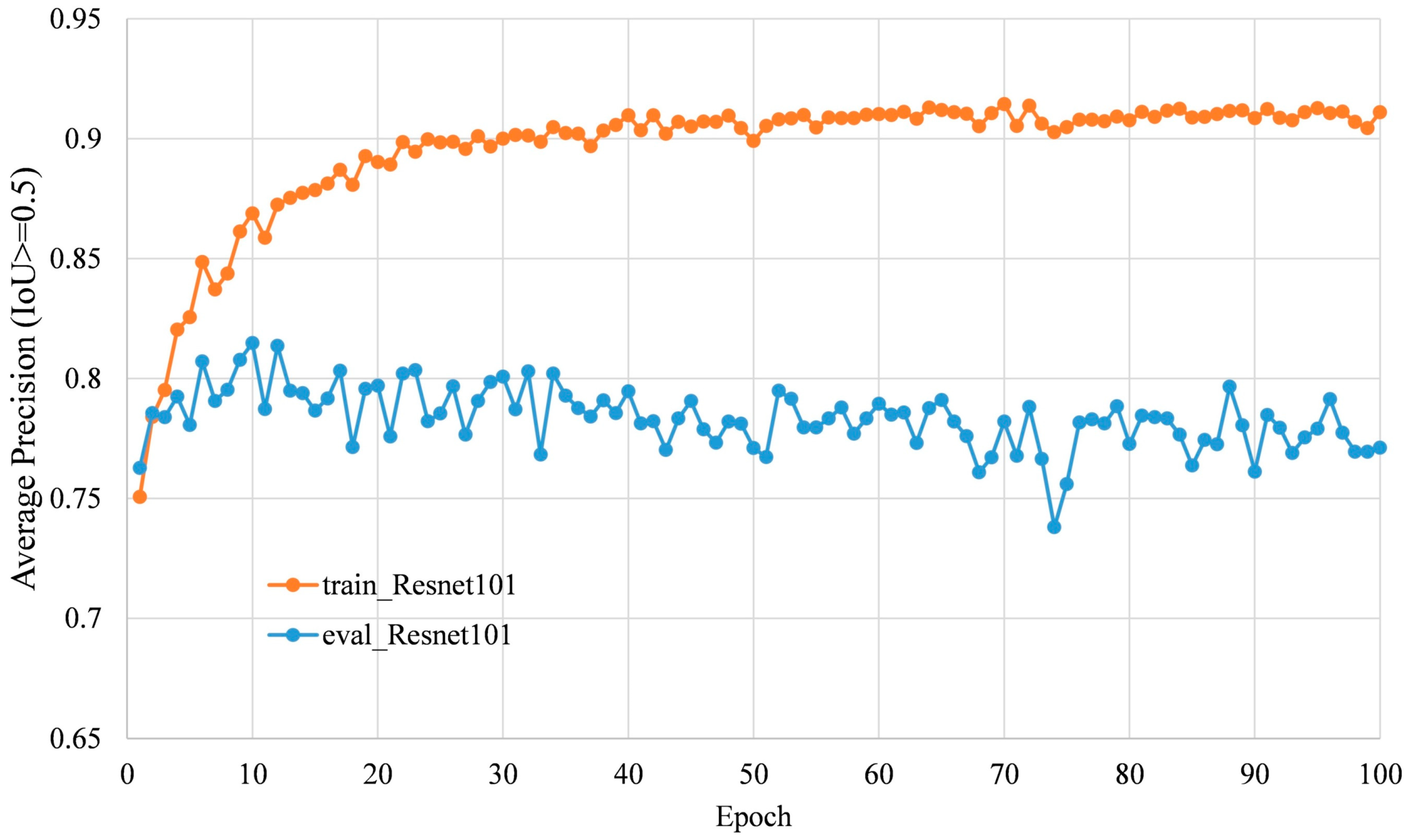
3.1. Accuracy Analysis of Deep Learning Models
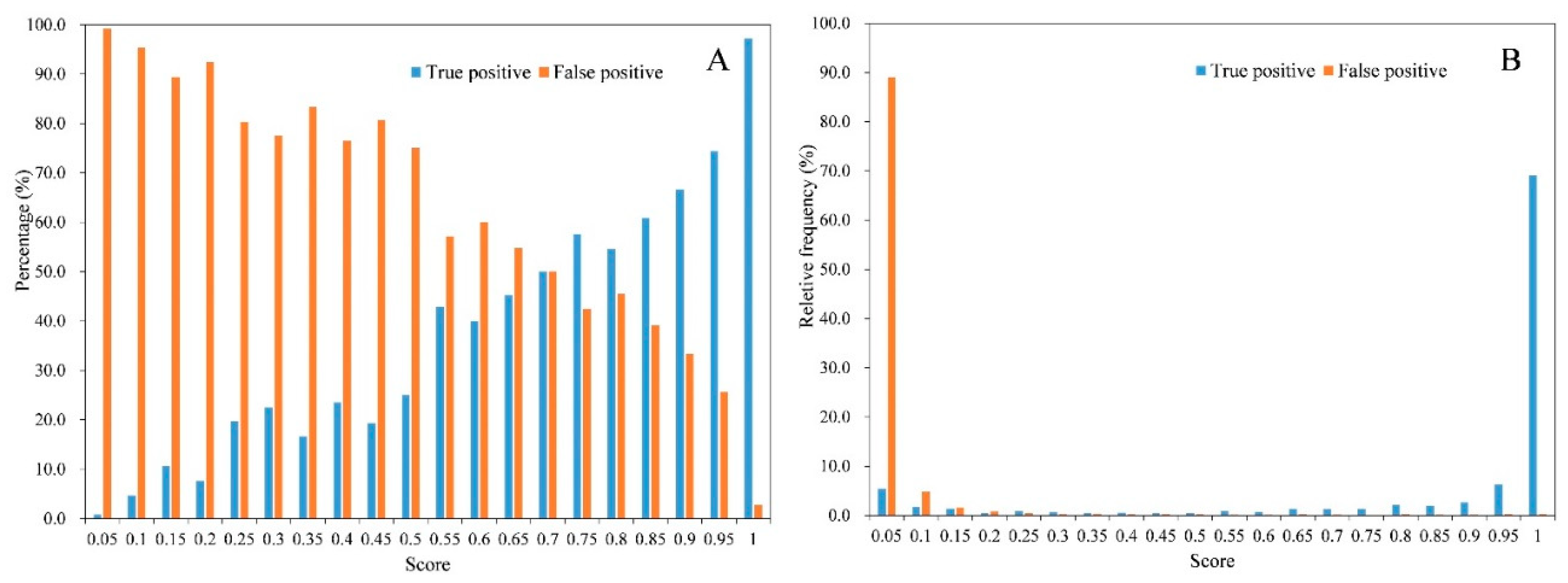
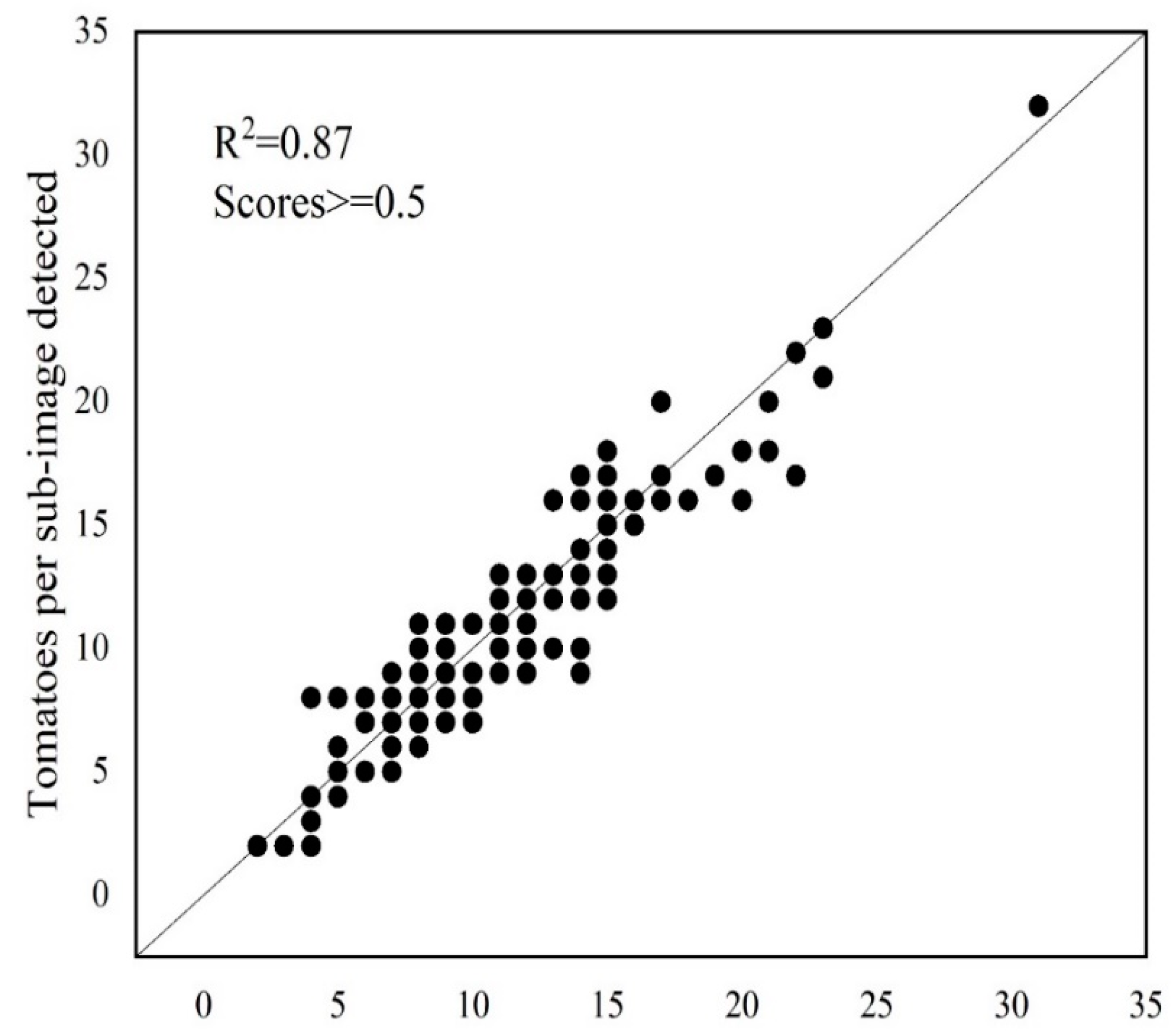
3.2. Tomato Counting Assessment
3.3. Tomato Localization for the Whole Cultivation Bed
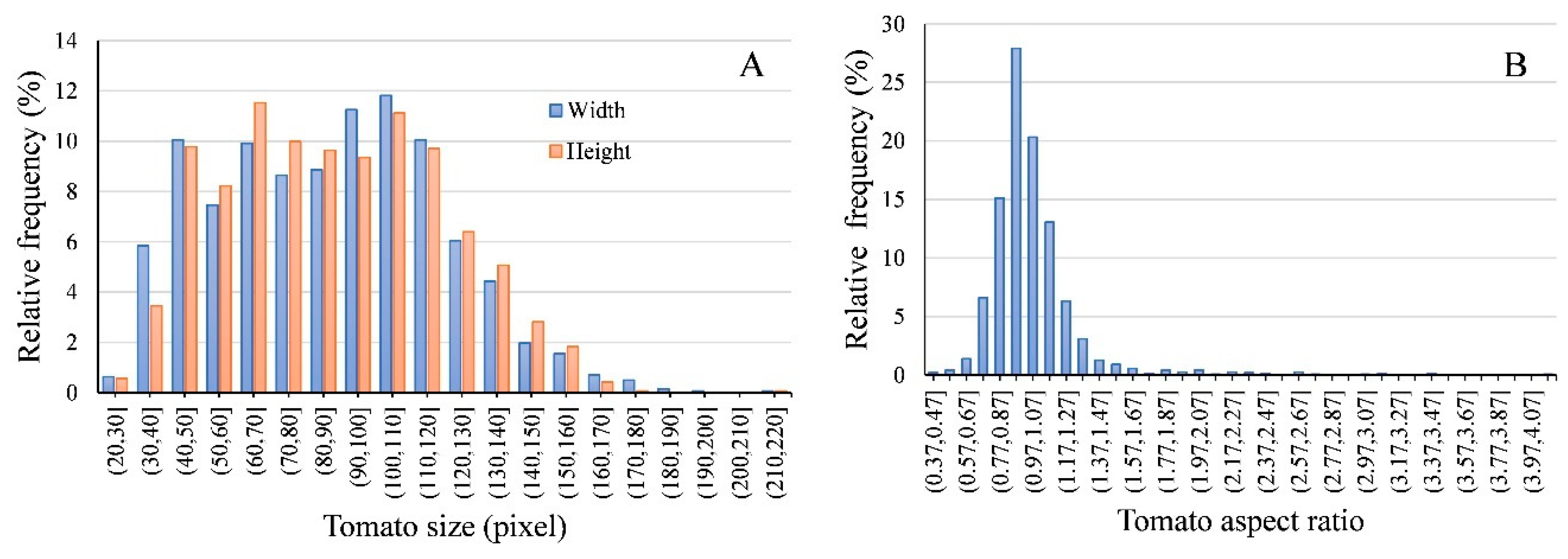
3.4. Tomato Size Estimation
4. Discussion
4.1. Accuracy Comparison with Other Tomato-on-Plant Detection Techniques Using RGB Images
4.2. Error Analysis
4.2.1. Overfitting
4.2.2. Manual Labelling
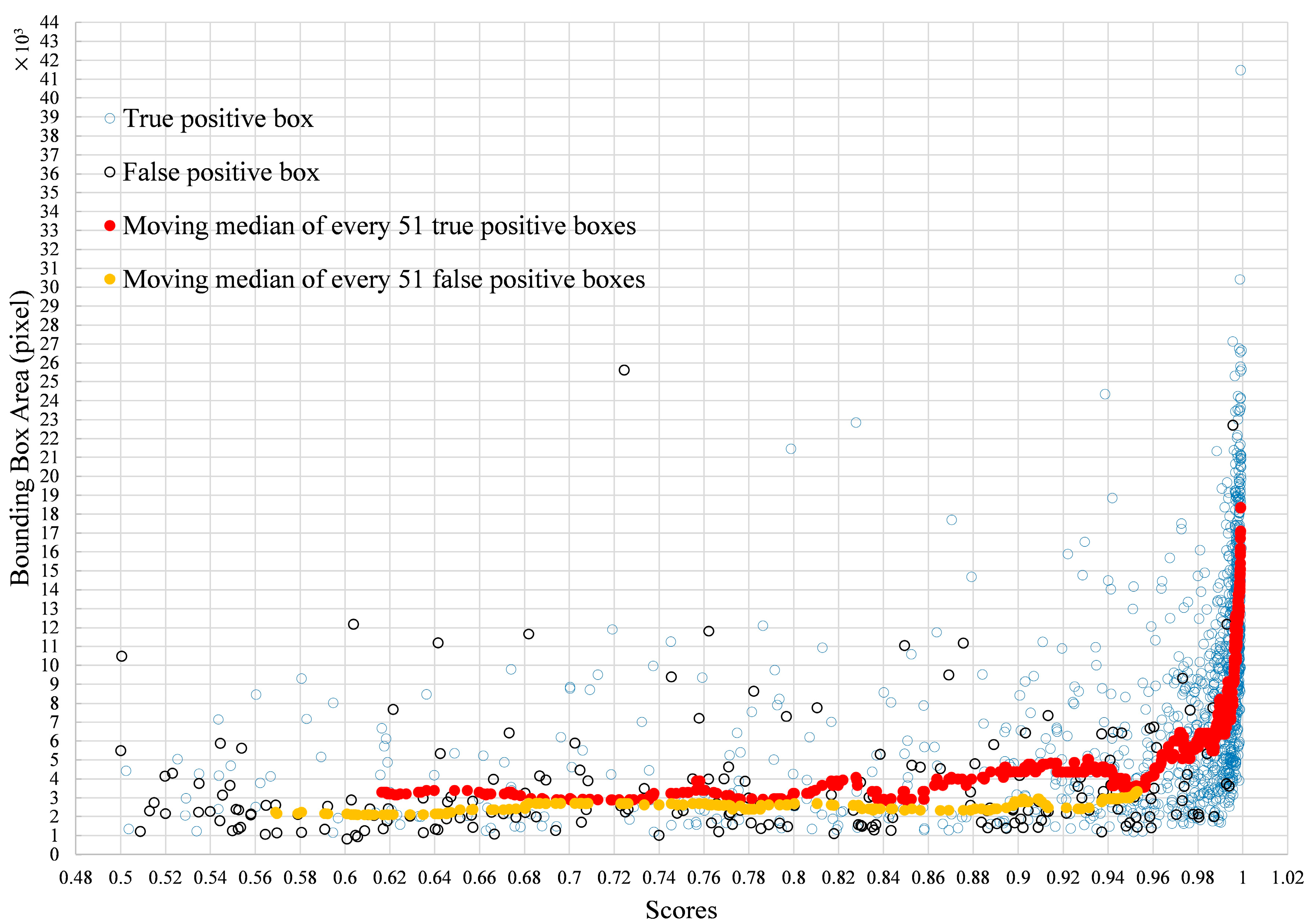
4.2.3. Influence of Tomato Size on Determination
4.3. Limitations
4.3.1. Long Training Time
4.3.2. Only Visible Tomatoes
4.3.3. Tomato Size Estimation in Images
4.4. Perspectives on Ripeness Estimation and Yield Prediction
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Peixoto, J.V.M.; Neto, C.M.; Campos, L.F.; Dourado, W.D.S.; Nogueira, A.P.; Nascimento, A.D. Industrial tomato lines: Morphological properties and productivity. Genet. Mol. Res. 2017, 16, 1–15. [Google Scholar] [CrossRef]
- Food and Agriculture Organization of the United Nations. FAOSTAT. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 29 October 2019).
- Li, Y.; Wang, H.; Zhang, Y.; Martin, C. Can the world’s favorite fruit, tomato, provide an effective biosynthetic chassis for high-value metabolites? Plant Cell Rep. 2018, 37, 1443–1450. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Food and Agriculture Organization of the United Nations. Tomato | Land & Water. Available online: http://www.fao.org/land-water/databases-and-software/crop-information/tomato/en/ (accessed on 29 October 2019).
- Sinivasan, R. Safer Tomato Production Methods: A Field Guide for Soil Fertility and Pest Management; AVRDC-The World Vegetable Center: Shanhua, Taiwan, 2010; Volume 10–740, ISBN 92-9058-182-4. [Google Scholar]
- Rutledge, A.D. Commercial Greenhouse Tomato Production. Available online: https://extension.tennessee.edu/publications/Documents/pb1609.pdf (accessed on 16 April 2020).
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Austin, P. A Compartment Model of the Effect of Early-Season Temperatures on Potential Size and Growth of “Delicious” Apple Fruits. Ann. Bot. 1999, 83, 129–143. [Google Scholar] [CrossRef] [Green Version]
- Malik, Z.; Ziauddin, S.; Shahid, A.R.; Safi, A. Detection and Counting of On-Tree Citrus Fruit for Crop Yield Estimation. IJACSA Int. J. Adv. Comput. Sci. Appl. 2016, 7. [Google Scholar] [CrossRef]
- Jha, S.N.; Kingsly, A.R.P.; Chopra, S. Physical and mechanical properties of mango during growth and storage for determination of maturity. J. Food Eng. 2006, 72, 73–76. [Google Scholar] [CrossRef]
- Somov, A.; Shadrin, D.; Fastovets, I.; Nikitin, A.; Matveev, S.; Seledets, I.; Hrinchuk, O. Pervasive Agriculture: IoT-Enabled Greenhouse for Plant Growth Control. IEEE Pervasive Comput. 2018, 17, 65–75. [Google Scholar] [CrossRef]
- Ling, X.; Zhao, Y.; Gong, L.; Liu, C.; Wang, T. Dual-arm cooperation and implementing for robotic harvesting tomato using binocular vision. Robot. Auton. Syst. 2019, 114, 134–143. [Google Scholar] [CrossRef]
- Khoshroo, A.; Arefi, A.; Khodaei, J. Detection of red tomato on plants using image processing techniques. Agric. Commun. 2014, 2, 9–15. [Google Scholar]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On plant detection of intact tomato fruits using image analysis and machine learning methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef] [Green Version]
- Gan, H.; Lee, W.S.; Alchanatis, V.; Ehsani, R.; Schueller, J.K. Immature green citrus fruit detection using color and thermal images. Comput. Electron. Agric. 2018, 152, 117–125. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Sang, N. Detecting citrus fruits and occlusion recovery under natural illumination conditions. Comput. Electron. Agric. 2015, 110, 121–130. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Liu, G.; Mao, S.; Kim, J.H. A mature-tomato detection algorithm using machine learning and color analysis. Sensors 2019, 19, 2023. [Google Scholar] [CrossRef] [Green Version]
- Rahnemoonfar, M.; Sheppard, C. Deep Count: Fruit counting based on deep simulated learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting apples and oranges with deep learning: A data-driven approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Walsh, K.; Verma, B. On-Tree Mango Fruit Size Estimation Using RGB-D Images. Sensors 2017, 17, 2738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schillaci, G.; Pennisi, A.; Franco, F.; Longo, D. Detecting Tomato Crops in Greenhouses Using a Vision Based Method. In Proceedings of the International Conference RAGUSA SHWA 2012 on “Safety Health and Welfare in Agriculture and in Agro-food Systems”, Ragusa, Italy, 3–6 September 2012; pp. 252–258. [Google Scholar]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of Key Organs in Tomato Based on Deep Migration Learning in a Complex Background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. Acm. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.R.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S.; et al. A weakly supervised deep learning framework for sorghum head detection and counting. Plant Phenomics 2019, 2019, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Desai, S.V.; Chandra, A.L.; Guo, W.; Ninomiya, S.; Balasubramanian, V.N. An adaptive supervision framework for active learning in object detection. arXiv 2019, arXiv:1908.02454. [Google Scholar]
- Chandra, A.L.; Desai, S.V.; Balasubramanian, V.N.; Ninomiya, S.; Guo, W. Active Learning with weak supervision for cost-effective panicle detection in cereal crops. arXiv 2019, arXiv:1910.01789. [Google Scholar]
- Sørensen, R.A.; Rasmussen, J.; Nielsen, J.; Jørgensen, R. Thistle Detection Using Convolutional Neural Networks. In Proceedings of the 2017 EFITA WCCA Congress, Montpellier, France, 2–6 July 2017; pp. 161–162. [Google Scholar]
- Jiang, Z.; Liu, C.; Hendricks, N.P.; Ganapathysubramanian, B.; Hayes, D.J.; Sarkar, S. Predicting County Level Corn Yields Using Deep Long Short Term Memory Models. arXiv 2018, arXiv:1805.12044. [Google Scholar]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep Gaussian Process for Crop Yield Prediction Based on Remote Sensing Data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; pp. 4559–4565. [Google Scholar]
- Shadrin, D.; Pukalchik, M.; Uryasheva, A.; Tsykunov, E.; Yashin, G.; Rodichenko, N.; Tsetserukou, D. Hyper-spectral NIR and MIR data and optimal wavebands for detection of apple tree diseases. arXiv 2020, arXiv:2004.02325. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Date | Time | Photo Number | Photo Size (pixels) |
|---|---|---|---|---|
| Seki farm | 19 May 2015 | Day | 229 | 3456 × 5184 |
| 22 January 2016 | 349 | 5184 × 3456 | ||
| Tanashi green house | 21 January 2016 | Day | 30 | |
| Night | 32 |
| Dataset | Location | Date | Time | Photo Number | Subimage Number | Image Size (pixels) |
|---|---|---|---|---|---|---|
| Train dataset | Seki farm | 19 May 2015 | Day | 452 | 1779 | 864 × 1296 |
| 22 January 2016 | 1296 × 864 | |||||
| Tanashi green house | 21 January 2016 | Day | ||||
| Night | ||||||
| Evaluation dataset | Seki farm | 22 January 2016 | Day | 129 | 511 | |
| Tanashi green house | 21 January 2016 | Day | ||||
| Night |
| Dataset | Location | Date | Time | Photo Number | Subimage Number | Image Nize (pixels) |
|---|---|---|---|---|---|---|
| Test dataset | Seki farm | 22 January 2016 | Day | 59 | 135 | 1296 × 864 |
| Author | Method | Accuracy |
|---|---|---|
| Schillaci et al., 2012 [28] | Scanning window with support vector machine | Twenty true positives against 26 false positive |
| Khoshroo et al., 2014 [13] | Colour analysis and region growing | Overall classification accuracy: 82.38% |
| Yamamoto et al., 2014 [14] | Pixel-based segmentation, blob-based segmentation, X-means clustering | Recall: 0.8, precision: 0.88 |
| Zhao et al., 2016 [18] | AdaBoost classifier and colour analysis | True positives rate: 96.5% False positive rate: 10.8% Missing (False negative) rate: 3.5% |
| Sun et al., 2018 [29] | Faster R-CNN with Resnet 50 | mAP (green and red tomatoes): 90.9% |
| Liu et al., 2019 [19] | Machine learning and colour analysis | F1 score: 92.15% |
| Liu et al., 2020 [30] | Yolo-tomato | F1 score: 93.91%, AP: 96.40% |
| This paper | Faster R-CNN with Resnet 101 | F1 score: 83.67%, AP: 87.83% |
| Box Area (Pixel) | True Positive Boxes | False Positive Boxes |
|---|---|---|
| ≤1000 | 0.00% | 0.97% |
| ≤2000 | 5.59% | 28.99% |
| ≤3000 | 13.97% | 59.42% |
| ≤4000 | 20.83% | 72.95% |
| ≤5000 | 28.33% | 81.16% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, Y.; Chen, T.-S.; Ninomiya, S.; Guo, W. Intact Detection of Highly Occluded Immature Tomatoes on Plants Using Deep Learning Techniques. Sensors 2020, 20, 2984. https://doi.org/10.3390/s20102984
Mu Y, Chen T-S, Ninomiya S, Guo W. Intact Detection of Highly Occluded Immature Tomatoes on Plants Using Deep Learning Techniques. Sensors. 2020; 20(10):2984. https://doi.org/10.3390/s20102984
Chicago/Turabian StyleMu, Yue, Tai-Shen Chen, Seishi Ninomiya, and Wei Guo. 2020. "Intact Detection of Highly Occluded Immature Tomatoes on Plants Using Deep Learning Techniques" Sensors 20, no. 10: 2984. https://doi.org/10.3390/s20102984