
Numerical Ecology and Social Network Analysis of the Forest Community in the Lienhuachih Area of Taiwan


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Areas
2.2. Experimental Design
2.3. Statistical Methods
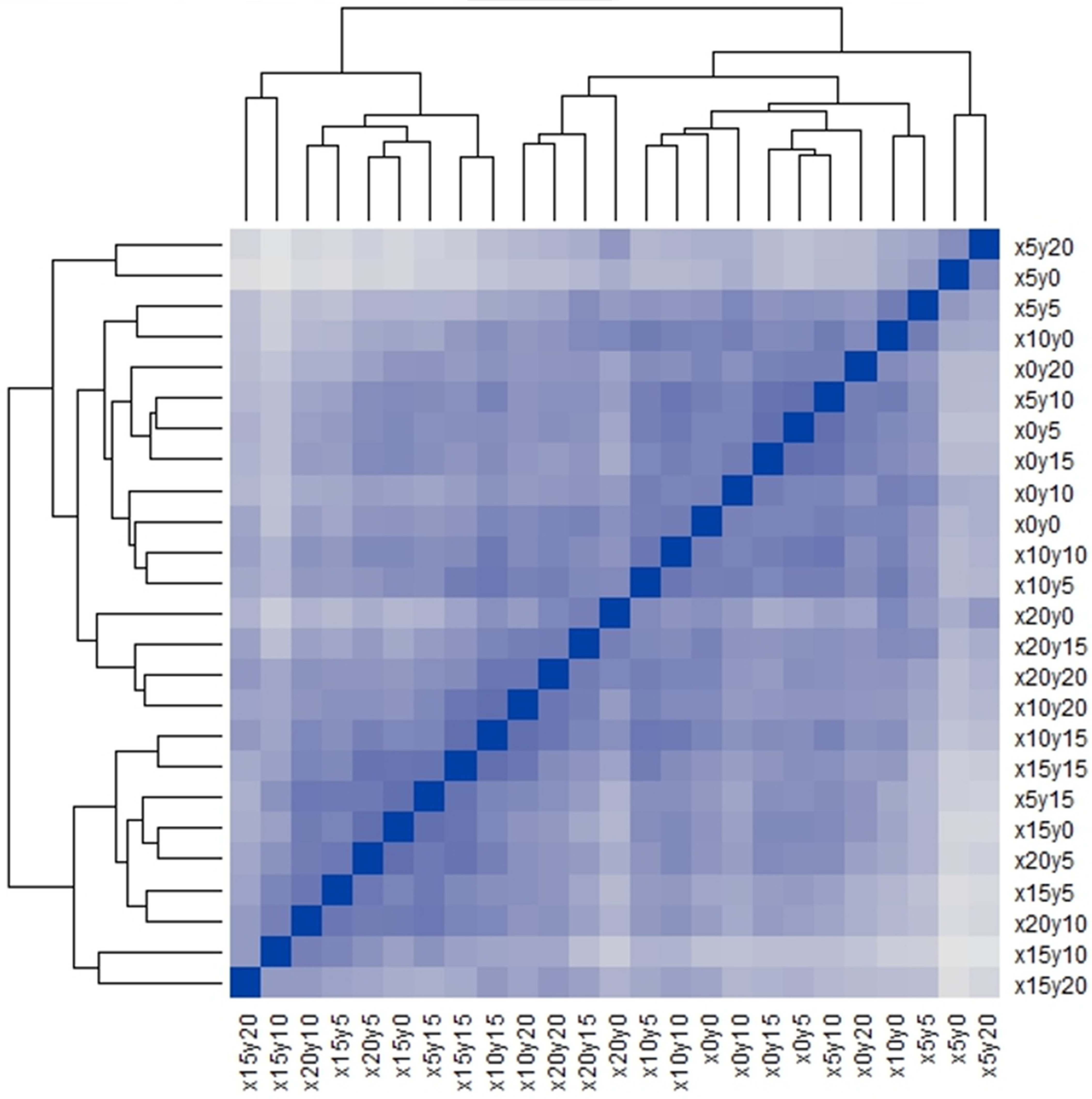
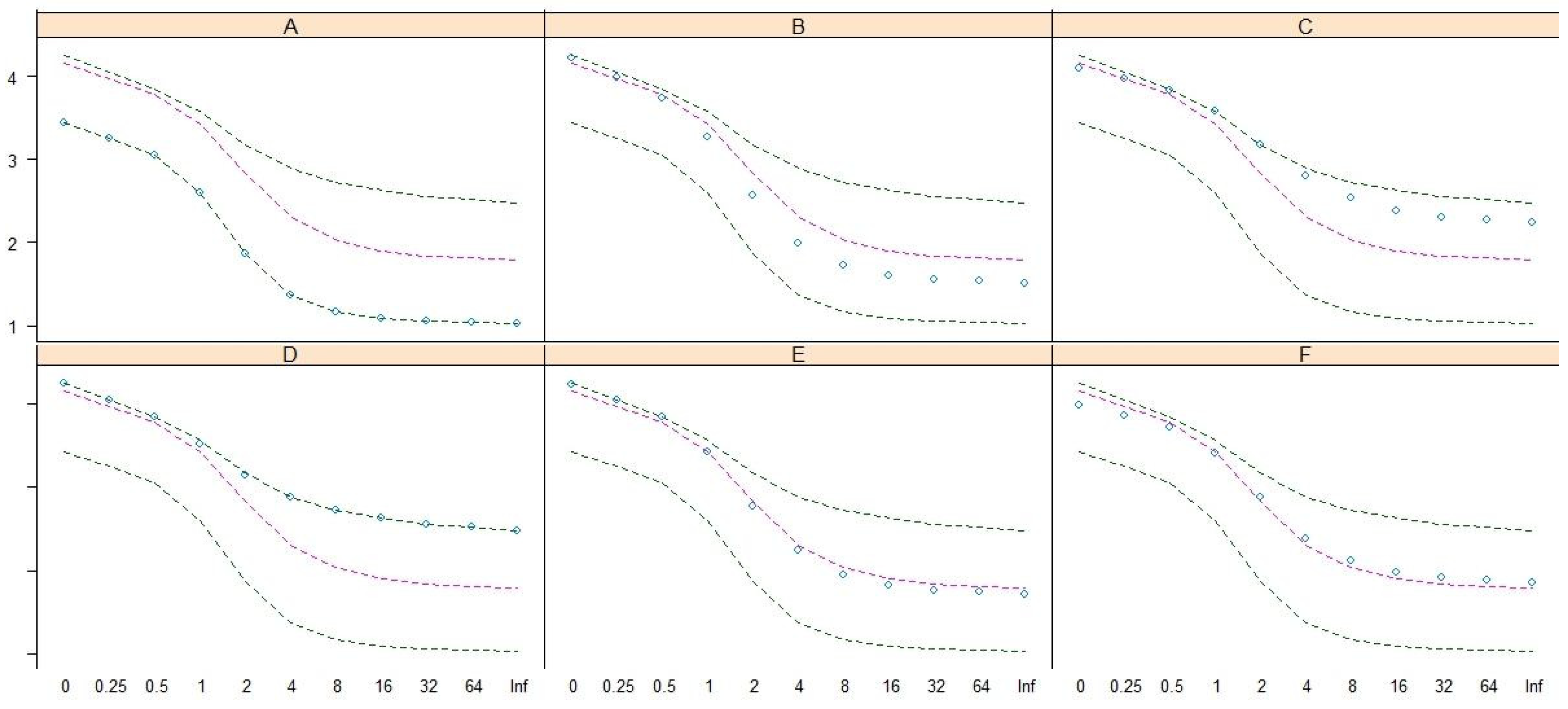
- The seriated heat map is a novel method that has been recently applied to numerical taxonomy [13]. The advantage of this method is that it simultaneously implements clustering and ordination visualizations in a plot [15,16]. The Q-Q-type seriated heat map [13,15,16], which employs the Bray–Curtis dissimilarity index [17,18,19], was used to detect possible community patterns in this study.
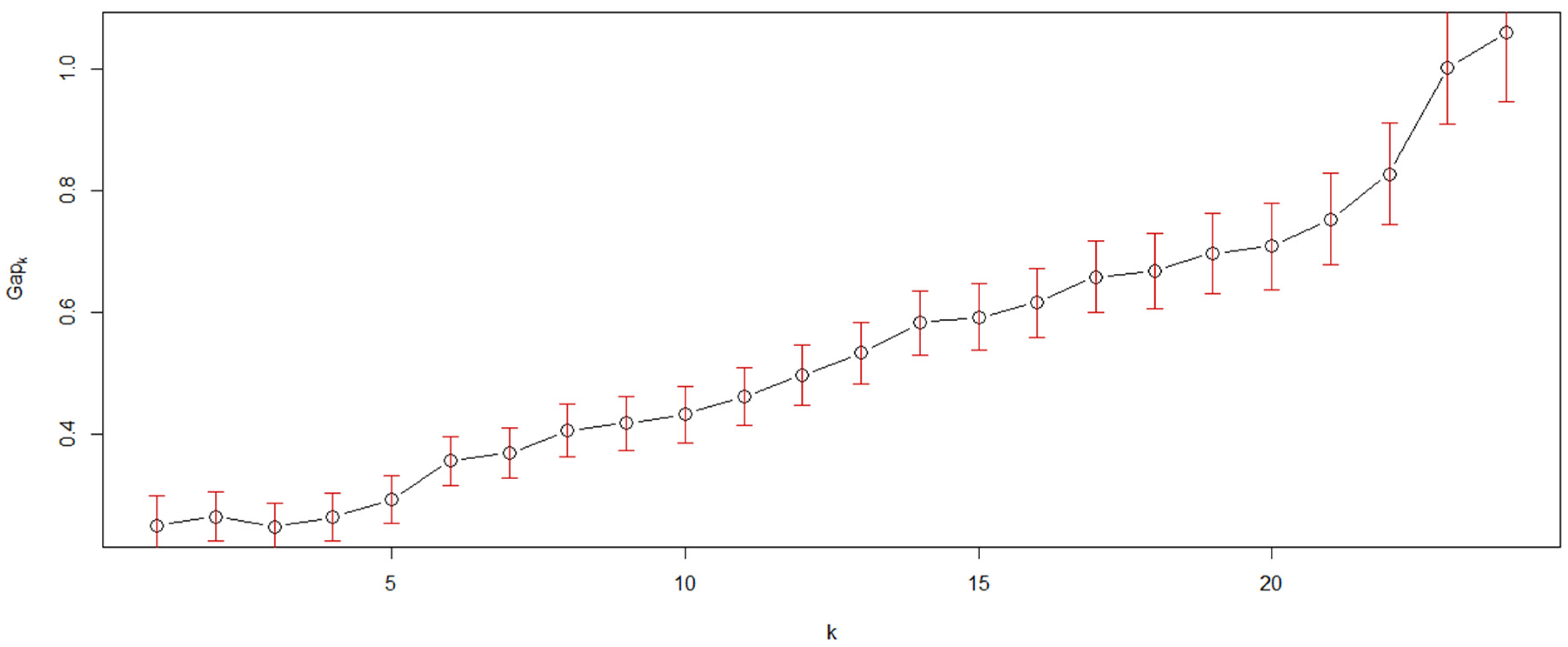
- The gap statistic, Gapk, is a goodness of clustering measure obtained after running 10,000 Monte Carlo samples [20,21] and was employed to estimate the number of community patterns hidden in the seriated heat map. Next, the detected community patterns were coded in capital letters for subsequent analyses.
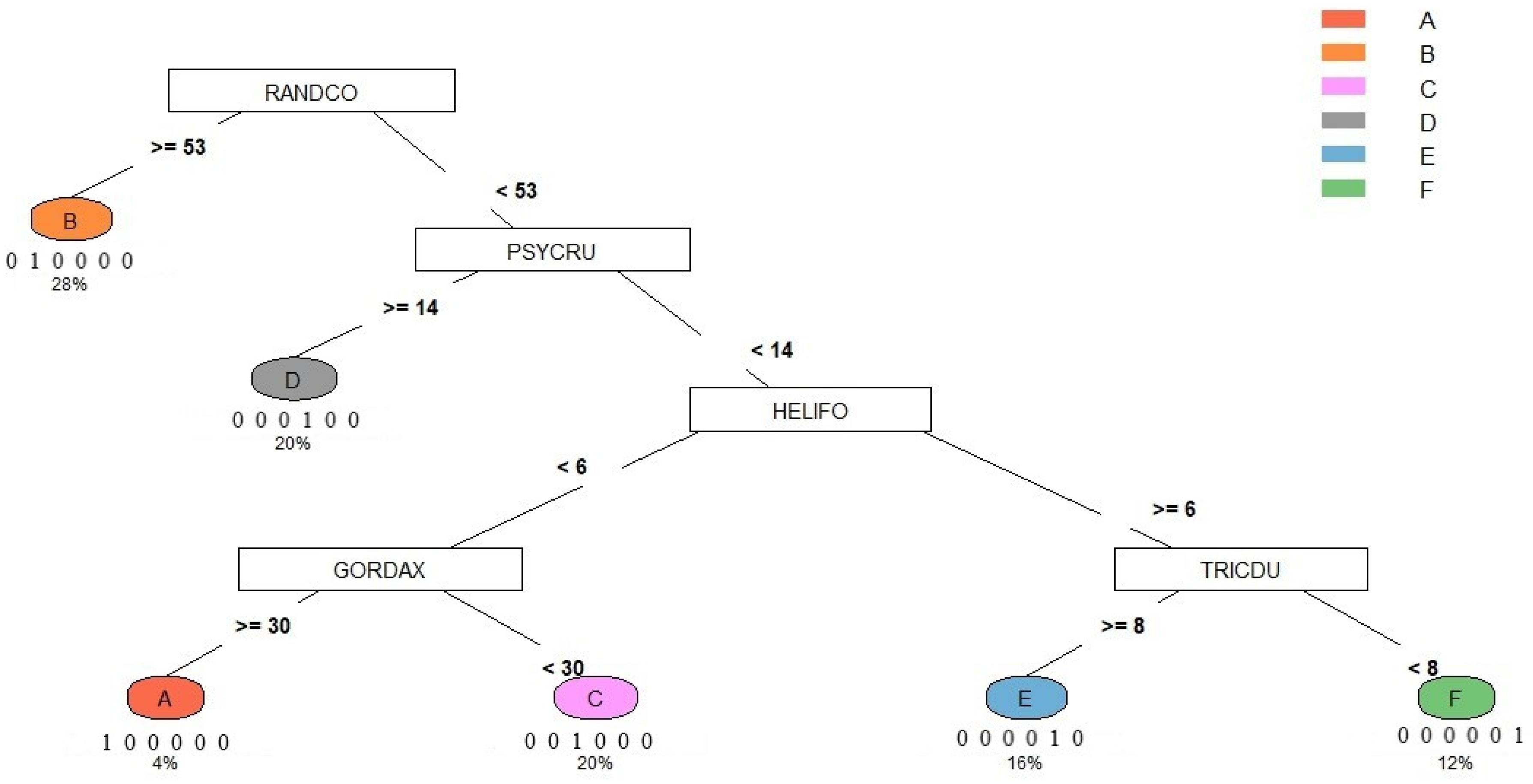
- This study adopted the classification and regression tree [50] of the dominant/characteristic species as the key to syntaxa in the Lienhuachih area of Taiwan.
3. Results
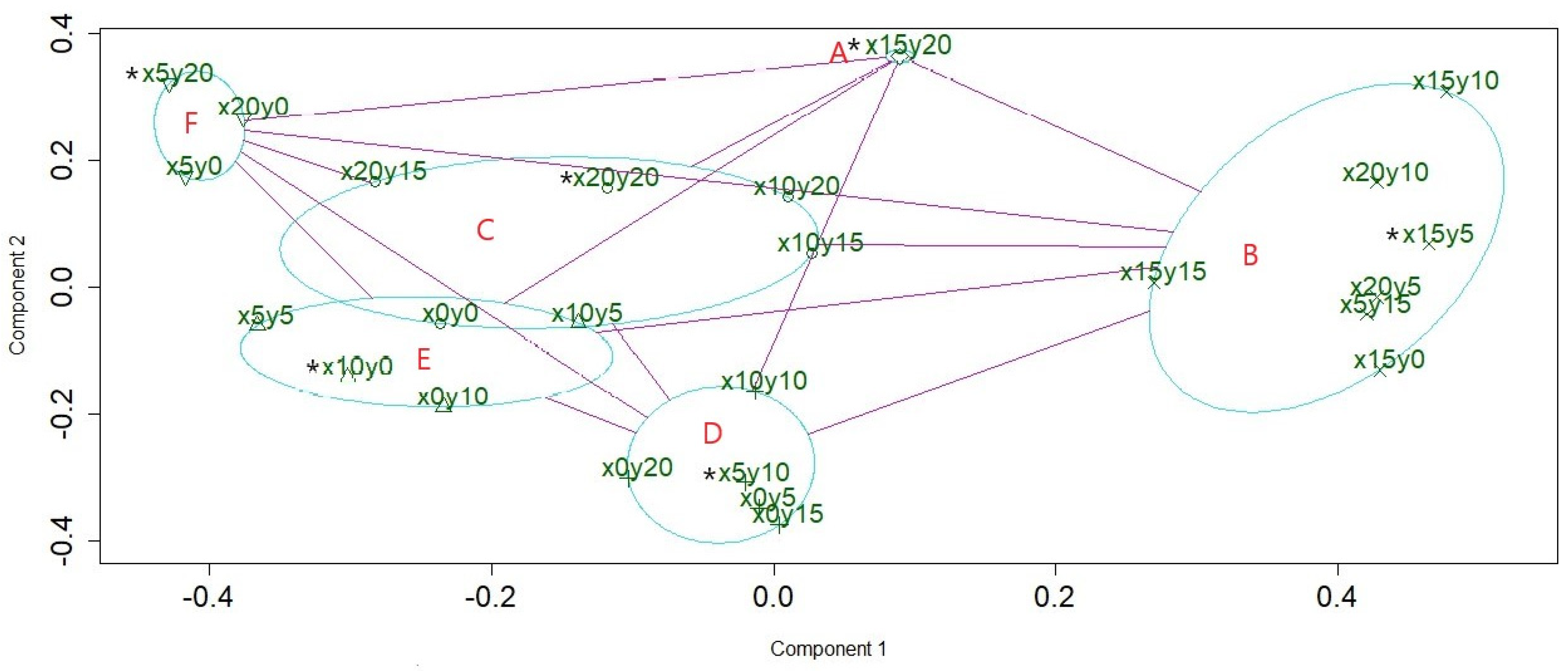
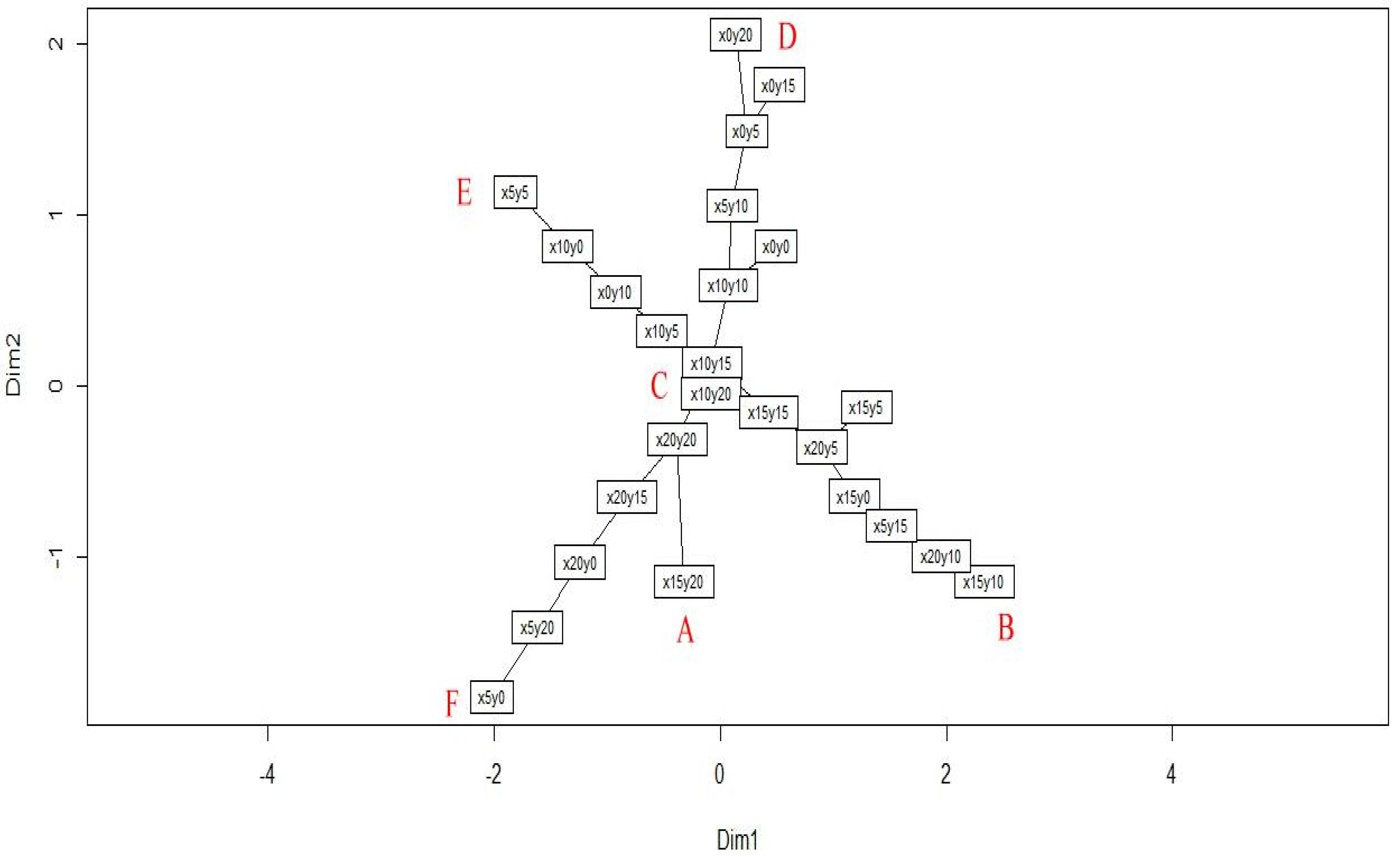
3.1. Vegetation Classification:
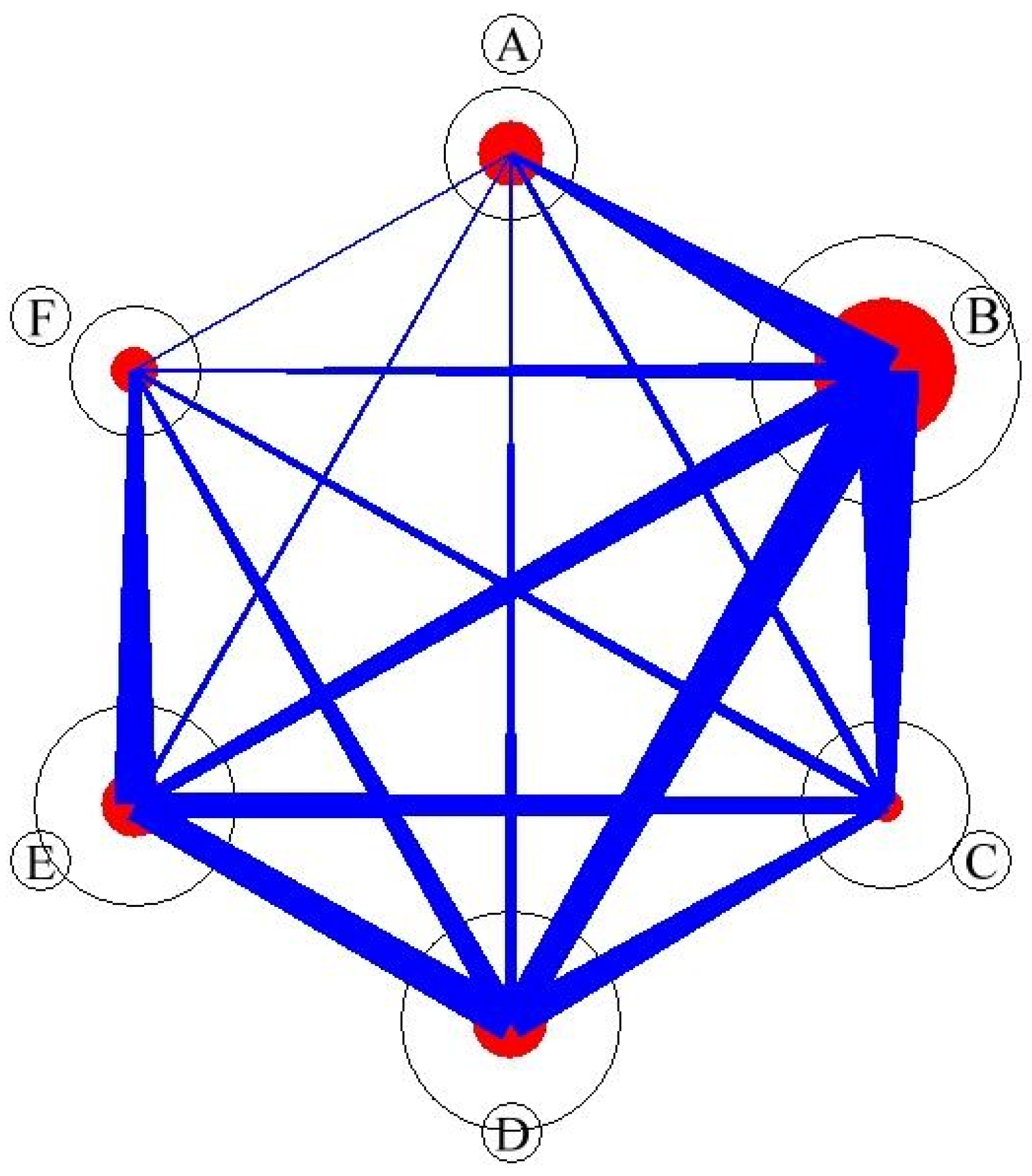
3.2. Social Networks Analysis
4. Discussion
Syntaxonomical Synopsis
- A
- Assoc. Gordonietum axillare Tung-Yu Hsieh et al., 2022 ass. nova hoc loco
- Nomenclature type releve’: x15y20 (holotypus hoc loco designatus).
- B
- Assoc. Randio cochinchinensis-Iletum goshiensis Tung-Yu Hsieh et al., 2022, ass. nova hoc loco
- Nomenclature type releve’: x15y5 (holotypus hoc loco designatus).
- C
- Assoc. Diospyro morrisianae-Meliosmetum squamulatae Tung-Yu Hsieh et al., 2022, ass. nova hoc loco
- Nomenclature type releve´: x20y20 (holotypus hoc loco designatus).
- D
- Assoc. Tricalysio dubiae-Psychotretum rubrae Tung-Yu Hsieh et al., 2022, ass. nova hoc loco
- Nomenclature type releve´: x5y10 (holotypus hoc loco designatus).
- E
- Assoc. Blasto cochinchinensis-Helicetum formosanae Tung-Yu Hsieh et al., 2022, ass. nova hoc loco
- Nomenclature type releve´: x10y0 (holotypus hoc loco designatus).
- F
- Assoc. Blasto cochinchinensis-Cinnamometum subaveniae Tung-Yu Hsieh et al., 2022, ass. nova hoc loco
- Nomenclature type releve’: x5y20 (holotypus hoc loco designatus).
- Assoc. Blasto cochinchinensis-Ficetum fistulosae Tung-Yu Hsieh et al., 2022, ass. nova hoc loco
- Nomenclature type releve’: x5y20 (holotypus hoc loco designatus).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Von Humboldt, A.; Aimé, B. Ideen zu einer Geographi der Pflanzen nebst einem Naturgemalde der Tropenlander; Akad: Leipzig, Germany, 1807; p. 139. [Google Scholar]
- Waterton, C. From field to fantasy: Classifying nature, constructing Europe. Soc. Stud. Sci. 2002, 32, 177–204. [Google Scholar] [CrossRef]
- Braun-Blanquet, J. Pflanzensoziologie: Grundzüge der Vegetationskunde; Springer: Vienna, Austria, 1964; p. 865. [Google Scholar]
- Maarel, E.v.d.; Franklin, J. Vegetation Ecology, 2nd ed.; Wiley: Chichester, UK, 2012. [Google Scholar]
- Wildi, O. Data Analysis in Vegetation Ecology, 2nd ed.; CABI: Wallingford, UK, 2013. [Google Scholar]
- Jongman, R.G.H.; ter Braak, C.J.F.; van Tongeren, O.F. Data Analysis in Community and Landscape Ecology; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Legendre, P.; Legendre, L. Numerical Ecology; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Freeman, L.C. The Development of Social Network Analysis: A Study in the Sociology of Science; Empirical Press: Vancouver, BC, Canada, 2004; p. 205. [Google Scholar]
- Chang, L.-W.; Chiu, S.-T.; Yang, K.-C.; Wang, H.-H.; Hwong, J.-L.; Hsieh, C.-F. Changes of plant communities classification and species composition along the micro-topography at the Lienhuachih Forest Dynamics Plot in the central Taiwan. Taiwania 2012, 57, 359–371. [Google Scholar] [CrossRef]
- Chang, L.-W.; Hwong, J.-L.; Chiu, S.-T.; Wang, H.-H.; Yang, K.-C.; Chang, H.-Y.; Hsieh, C.-F. Species composition, size-class structure, and diversity of the Lienhuachih Forest Dynamics Plot in a subtropical evergreen broad-leaved forest in central Taiwan. Taiwan J. For. Sci. 2010, 25, 81–95. [Google Scholar] [CrossRef]
- Yang, C.-J. The Study of Species Selection in Restoration Plan: An Example of Lienhuachih Region; National Taiwan University: Taipei, Taiwan, 2013. [Google Scholar]
- Chang, L.; Huang, J.; Luo, S.; Lee, P. Understory plant composition and its relations with environmental factors of the Lienhuachih forest dynamics plot at a subtropical evergreen broadleaf forest in central Taiwan. Taiwan J. For. Sci. 2015, 30, 245–257. [Google Scholar]
- Hsieh, T.-Y.; Ku, S.-M.; Chien, C.-T.; Liou, Y.-T. Classifier modeling and numerical taxonomy of Actinidia (Actinidiaceae) in Taiwan. Bot. Stud. 2011, 52, 337–357. [Google Scholar]
- R Core Team, R. A Language and Environment for Statistical Computing, 4.2.0, R Foundation for Statistical Computing: Vienna, Austria, 2022.
- Earle, D.; Hurley, C.B. Advances in dendrogram seriation for application to visualization. J. Comput. Graph. Stat. 2015, 24, 1–25. [Google Scholar] [CrossRef]
- Hahsler, M.; Buchta, C.; Hornik, K. Seriation: Infrastructure for Ordering Objects Using Seriation, R Package Version 1.3.6. 2022. Available online: https://CRAN.r-project.org/package=seriation (accessed on 1 January 2022).
- Bray, J.R.; Curtis, J.T. An ordination of the upland forest communities of southern Wisconsin. Ecol. Monogr. 1957, 27, 325–349. [Google Scholar] [CrossRef]
- Oksanen, J.; Simpson, G.; Blanchet, F.; Kindt, R.; Legendre, P.; Minchin, P.; O’Hara, R.; Solymos, P.; Stevens, M.; Szoecs, E.; et al. Vegan: Community Ecology Package, R Package Version 2.6-2. 2022. Available online: https://CRAN.r-project.org/package=vegan (accessed on 18 June 2022).
- Faith, D.P.; Minchin, P.R.; Belbin, L. Compositional dissimilarity as a robust measure of ecological distance. Vegetatio 1987, 69, 57–68. [Google Scholar] [CrossRef]
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster Analysis Basics and Extensions, R Package Version 2.0.7-1. 2018. Available online: https://CRAN.r-project.org/package=cluster (accessed on 1 July 2018).
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. B 2002, 63, 411–423. [Google Scholar] [CrossRef]
- Reynolds, A.P.; Richards, G.; de la Iglesia, B.; Rayward-Smith, V.J. Clustering rules: A comparison of partitioning and hierarchical clustering algorithms. J. Math. Model. Algorithms 2006, 5, 475–504. [Google Scholar] [CrossRef]
- Pison, G.; Struyf, A.; Rousseeuw, P.J. Displaying a clustering with CLUSPLOT. Comput. Stat. Data Anal. 1999, 30, 381–392. [Google Scholar] [CrossRef] [Green Version]
- Rényi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley symposium on mathematical statistics and probability, Berkeley; 1961; pp. 547–561. [Google Scholar]
- Hill, M.O. Diversity and evenness: A unifying notation and its consequences. Ecology 1973, 54, 427–432. [Google Scholar] [CrossRef]
- Kindt, R.; Van Damme, P.; Simons, A.J. Tree diversity in western Kenya: Using profiles to characterise richness and evenness. Biodivers. Conserv. 2006, 15, 1253–1270. [Google Scholar] [CrossRef]
- Tóthmérész, B. Comparison of different methods for diversity ordering. J. Veg. Sci. 1995, 6, 283–290. [Google Scholar] [CrossRef]
- Caruso, T.; Pigino, G.; Bernini, F.; Bargagli, R.; Migliorini, M. The Berger-Parker index as an effective tool for monitoring the biodiversity of disturbed soils: A case study on Mediterranean oribatid (Acari: Oribatida) assemblages. Biodivers. Conserv. 2006, 16, 3277–3285. [Google Scholar] [CrossRef]
- Lau, M.K.; Borrett, S.R.; Hines, D.E.; Singh, P. EnaR: Tools for Ecological Network Analysis, R Package Version 3.0.0. 2017. Available online: https://CRAN.R-project.org/package=enaR (accessed on 15 January 2017).
- Borrett, S.R.; Lau, M.K. EnaR: An R package for ecosystem network analysis. Methods Ecol. Evol. 2014, 5, 1206–1213. [Google Scholar] [CrossRef] [Green Version]
- Scott, J. Social Network Analysis, 4th ed.; SAGE Publications: London, UK, 2017; p. 227. [Google Scholar]
- Dormann, C.F.; Gruber, B.; Fründ, J. Introducing the bipartite Package: Analysing Ecological Networks. R News 2008, 8, 8–11. [Google Scholar]
- Dormann, C.F.; Fruend, J.; Grube, B. Bipartite: Visualising Bipartite Networks and Calculating Some (Ecological) Indices, R Package Version 2.08. 2017. Available online: https://CRAN.R-project.org/package=bipartite (accessed on 22 January 2017).
- Dormann, C.F.; Fründ, J.; Blüthgen, N.; Gruber, B. Indices, graphs and null models: Analyzing bipartite ecological networks. Open Ecol. J. 2009, 2, 7–24. [Google Scholar] [CrossRef]
- Memmott, J.; Waser, N.M.; Price, M.V. Tolerance of pollination networks to species extinctions. Proc. R. Soc. Lond. B Biol. Sci. 2004, 271, 2605–2611. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. RandomForest: Breiman and Cutler’s Random Forests for Classification and Regression. R Package Version 2.6-2. 2018. Available online: https://CRAN.r-project.org/package=randomForest (accessed on 11 June 2018).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Beckett, S.J. Improved community detection in weighted bipartite networks. R. Soc. Open Sci. 2016, 3, 140536. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, X.; Murata, T. An efficient algorithm for optimizing bipartite modularity in bipartite networks. J. Adv. Comput. Intell. Intell. Inform. 2010, 14, 408–415. [Google Scholar] [CrossRef]
- Dormann, C.F.; Strauss, R. Detecting modules in quantitative bipartite networks: The QuaBiMo algorithm. Methods Ecol. Evol. 2013, 5, 90–98. [Google Scholar] [CrossRef] [Green Version]
- Holt, R.D. Predation, apparent competition, and the structure of prey communities. Theor. Popul. Biol. 1977, 12, 197–229. [Google Scholar] [CrossRef]
- Morris, R.J.; Lewis, O.T.; Godfray, H.C.J. Experimental evidence for apparent competition in a tropical forest food web. Nature 2004, 428, 310–313. [Google Scholar] [CrossRef] [PubMed]
- Carvalheiro, L.G.; Biesmeijer, J.C.; Benadi, G.; Fründ, J.; Stang, M.; Bartomeus, I.; Kaiser-Bunbury, C.N.; Baude, M.; Gomes, S.I.; Merckx, V. The potential for indirect effects between co-flowering plants via shared pollinators depends on resource abundance, accessibility and relatedness. Ecol. Lett. 2014, 17, 1389–1399. [Google Scholar] [CrossRef] [Green Version]
- Morris, R.J.; Lewis, O.T.; Godfray, H.C.J. Apparent competition and insect community structure: Towards a spatial perspective. Ann. Zool. Fenn. 2005, 42, 449–462. [Google Scholar]
- Muller, C.; Adriaanse, I.; Belshaw, R.; Godfray, H. The structure of an aphid–parasitoid community. J. Anim. Ecol. 1999, 68, 346–370. [Google Scholar] [CrossRef]
- Gotelli, N.J.; Graves, G.R. Null Models in Ecology; Smithsonian Institution Press: Washington, DC, USA, 1996; p. 368. [Google Scholar]
- Pimm, S.L. Food Webs; Chapman and Hall: London, UK, 1982; p. 219. [Google Scholar]
- Therneau, T.; Atkinson, B. Rpart: Recursive Partitioning and Regression Trees, R Package Version 4.1.16. 2022. Available online: https://CRAN.R-project.org/package=rpart (accessed on 8 October 2022).
- Blüthgen, N.; Menzel, F.; Hovestadt, T.; Fiala, B.; Blüthgen, N. Specialization, constraints, and conflicting interests in mutualistic networks. Curr. Biol. 2007, 17, 341–346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stone, L.; Roberts, A. Competitive exclusion, or species aggregation? Oecologia 1992, 91, 419–424. [Google Scholar] [CrossRef] [PubMed]
- Schluter, D. A variance test for detecting species associations, with some example applications. Ecology 1984, 65, 998–1005. [Google Scholar] [CrossRef]
- Condit, R. Tropical Forest Census Plots; Springer: New York, NY, USA, 1998; p. 211. [Google Scholar]
- Li, C.-F.; Zelený, D.; Chytrý, M.; Chen, M.-Y.; Chen, T.-Y.; Chiou, C.-R.; Hsia, Y.-J.; Liu, H.-Y.; Yang, S.-Z.; Yeh, C.-L. Chamaecyparis montane cloud forest in Taiwan: Ecology and vegetation classification. Ecol. Res. 2015, 30, 771–791. [Google Scholar] [CrossRef]
- Bruelheide, H.; Chytrý, M. Towards unification of national vegetation classifications: A comparison of two methods for analysis of large data sets. J. Veg. Sci. 2000, 11, 295–306. [Google Scholar] [CrossRef]
- Bruelheide, H. A new measure of fidelity and its application to defining species groups. J. Veg. Sci. 2000, 11, 167–178. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.-C. Recognition and proposal on the vegetation classification system of China. Chin. J. Plant Ecol. 2011, 35, 882–892. [Google Scholar] [CrossRef]
- Jennings, M.D.; Faber-Langendoen, D.; Loucks, O.L.; Peet, R.K.; Roberts, D. Standards for associations and alliances of the US National Vegetation Classification. Ecol. Monogr. 2009, 79, 173–199. [Google Scholar] [CrossRef]
- Mucina, L. Classification of vegetation: Past, present and future. J. Veg. Sci. 1997, 8, 751–760. [Google Scholar] [CrossRef]
- Weber, H.E.; Moravec, J.; Theurillat, J.P. International code of phytosociological nomenclature. J. Veg. Sci. 2000, 11, 739–768. [Google Scholar] [CrossRef]
- Rodwell, J.S. The UK National Vegetation Classification. Phytocoenologia 2018, 48, 133–140. [Google Scholar] [CrossRef]
- Song, Y.-C.; Xu, G.-S. A scheme of vegetation classification of Taiwan, China. Acta Bot. Sin. 2003, 45, 883–895. [Google Scholar]
- Li, C.F.; Chytrý, M.; Zelený, D.; Chen, M.Y.; Chen, T.Y.; Chiou, C.R.; Hsia, Y.J.; Liu, H.Y.; Yang, S.Z.; Yeh, C.L. Classification of Taiwan forest vegetation. Appl. Veg. Sci. 2013, 16, 698–719. [Google Scholar] [CrossRef]
- Mucina, L.; Bültmann, H.; Dierßen, K.; Theurillat, J.P.; Raus, T.; Čarni, A.; Šumberová, K.; Willner, W.; Dengler, J.; García, R.G. Vegetation of Europe: Hierarchical floristic classification system of vascular plant, bryophyte, lichen, and algal communities. Appl. Veg. Sci. 2016, 19, 3–264. [Google Scholar] [CrossRef]
- Hsieh, T.-Y.; Hatch, K.A.; Chang, Y.-M. Phlegmariurus changii (Huperziaceae), a new hanging firmoss from Taiwan. Am. Fern J. 2012, 102, 283–288. [Google Scholar] [CrossRef]
- Turland, N.J.; Wiersema, J.H.; Barrie, F.R.; Greuter, W.; Hawksworth, D.L.; Herendeen, P.S.; Knapp, S.; Kusber, W.-H.; Li, D.-Z.; Marhold, K.; et al. International Code of Nomenclature for Algae, Fungi, and Plants (Shenzhen Code) Adopted by the Nineteenth International Botanical Congress Shenzhen, China, July 2017; Koeltz Botanical Books: Glashütten, Germany, 2018. [Google Scholar]
- Hsieh, T.-Y.; Hsu, T.-C.; Kono, Y.; Ku, S.-M.; Peng, C.-I. Gentiana bambuseti (Gentianaceae), a new species from Taiwan. Bot. Stud. 2007, 48, 349–355. [Google Scholar]
- Balpinar, N.; Kavgaci, A.; Bingöl, M.Ü.; Ketenoğlu, O. Diversity and gradients of vegetation of Sivrihisar Mountains (Eskişehir-Turkey). Acta Bot. Croat. 2018, 77, 18–27. [Google Scholar] [CrossRef]
- Peng, C.-I.; Hsieh, T.-Y.; Ngyuen, Q.H. Begonia kui (sect. Coelocentrum, Begoniaceae), a new species from Vietnam. Bot. Stud. 2007, 48, 127–132. [Google Scholar]
- Chen, J.-H.; Hsieh, T.-Y.; Chen, W.-Z.; Chen, C.-H.; Chang, Y.-M. A new species of the cicada genus Euterpnosia (Hemiptera: Cicadidae) from Taiwan, with morphometric approaches. Formos. Entomol. 2021, 41, 192–207. [Google Scholar]
- Hsieh, T.-Y. Taxonomy and distribution of indigenous Actinidia in Taiwan. Ph.D. Thesis, National Chung-Hsing University, Taichung, Taiwan, 2011. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indices | Values |
|---|---|
| number of syntaxa | 6 |
| number of taxa | 108 |
| connectance | 0.54 |
| number of compartments | 1 |
| web asymmetry | 0.89 |
| extinction slopes of taxon | 77.41 |
| extinction slopes of syntaxon | 3.52 |
| C-Score of taxon | 0.38 |
| C-Score of syntaxon | 0.2 |
| V-Ratio of taxon | 2.14 |
| V-Ratio of syntaxon | 10.39 |
| togetherness of taxa | 0.17 |
| togetherness of syntaxa | 0.35 |
| mean number of shared syntaxon per taxon | 1.85 |
| mean number of shared taxa per syntaxon | 37.27 |
| robustness of taxa | 0.99 |
| robustness of syntaxa | 0.76 |
| Syntaxon | A | B | C | D | E | F | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Species | sc | cv | sc | cv | sc | cv | sc | cv | sc | cv | sc | cv | |
| 1 | GORDAX | 0.16 | ILEXGO | 1.03 | MELISQ | 0.23 | PSYCRU | 0.51 | HELIFO | 0.97 | CINNSU | 0.55 | |
| 2 | ILEXLO | 0.16 | SYZYBU | 1.02 | ENGERO | 0.18 | SCHEOC | 0.48 | STYRSU | 0.69 | ORMOFO | 0.54 | |
| 3 | MELACA | 0.15 | RANDCO | 1.02 | BLASCO | 0.18 | LITSAC | 0.43 | BLASCO | 0.22 | FICUFI | 0.15 | |
| 4 | SCHISU | 0.15 | EUONLA | 0.57 | HELIRE | 0.18 | MICHCO | 0.26 | BEILER | 0.13 | SAURTR | 0.15 | |
| 5 | ILEXMI | 0.06 | RHAPIN | 0.23 | TRICDU | 0.17 | HELICO | 0.25 | CLERCY | 0.12 | ARDIQU | 0.13 | |
| Syntaxon | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| A | 0.52 | 0.24 | 0.09 | 0.09 | 0.05 | 0.01 |
| B | 0.06 | 0.54 | 0.12 | 0.17 | 0.09 | 0.02 |
| C | 0.05 | 0.31 | 0.19 | 0.2 | 0.18 | 0.06 |
| D | 0.03 | 0.25 | 0.11 | 0.36 | 0.19 | 0.05 |
| E | 0.02 | 0.17 | 0.13 | 0.22 | 0.34 | 0.12 |
| F | 0.02 | 0.09 | 0.1 | 0.15 | 0.28 | 0.36 |
| Type Releve’ | ARDIQU | BLASCO | CINNSU | CRYPCH | DIOSMO | EUONLA | FICUFI | GORDAX | HELIFO | HELIRE | ILEXLO | ILEXGO | MALLPA | MELACA | MELISQ | ORMOFO | PSYCRU | RANDCO | SAURTR | SCHEOC | SYZYBU | TRICDU | Syntaxon Code |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x15y20 | 3 | 0 | 2 | 1 | 1 | 10 | 0 | 57 | 0 | 1 | 6 | 0 | 0 | 7 | 0 | 3 | 0 | 4 | 0 | 1 | 3 | 2 | A |
| x15y5 | 31 | 0 | 7 | 0 | 20 | 62 | 0 | 8 | 0 | 30 | 0 | 25 | 21 | 3 | 0 | 3 | 2 | 318 | 0 | 2 | 52 | 33 | B |
| x20y20 | 13 | 30 | 6 | 6 | 21 | 12 | 0 | 3 | 0 | 3 | 0 | 0 | 1 | 0 | 1 | 9 | 1 | 21 | 0 | 12 | 2 | 4 | C |
| x5y10 | 49 | 14 | 21 | 14 | 9 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 3 | 0 | 0 | 9 | 18 | 33 | 0 | 24 | 2 | 61 | D |
| x10y0 | 17 | 121 | 6 | 16 | 10 | 0 | 0 | 0 | 28 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 8 | 4 | 0 | 28 | 0 | 10 | E |
| x5y20 | 2 | 25 | 0 | 7 | 2 | 0 | 6 | 0 | 10 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 1 | 0 | 1 | 4 | 0 | 0 | F |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsieh, T.-Y.; Yang, C.-J.; Li, F.; Chiou, C.-R. Numerical Ecology and Social Network Analysis of the Forest Community in the Lienhuachih Area of Taiwan. Diversity 2023, 15, 60. https://doi.org/10.3390/d15010060
Hsieh T-Y, Yang C-J, Li F, Chiou C-R. Numerical Ecology and Social Network Analysis of the Forest Community in the Lienhuachih Area of Taiwan. Diversity. 2023; 15(1):60. https://doi.org/10.3390/d15010060
Chicago/Turabian StyleHsieh, Tung-Yu, Chun-Jheng Yang, Feng Li, and Chyi-Rong Chiou. 2023. "Numerical Ecology and Social Network Analysis of the Forest Community in the Lienhuachih Area of Taiwan" Diversity 15, no. 1: 60. https://doi.org/10.3390/d15010060