
The Search of Association of HLA Class I and Class II Alleles with COVID-19 Mortality in the Russian Cohort


Abstract
:1. Introduction
2. Results
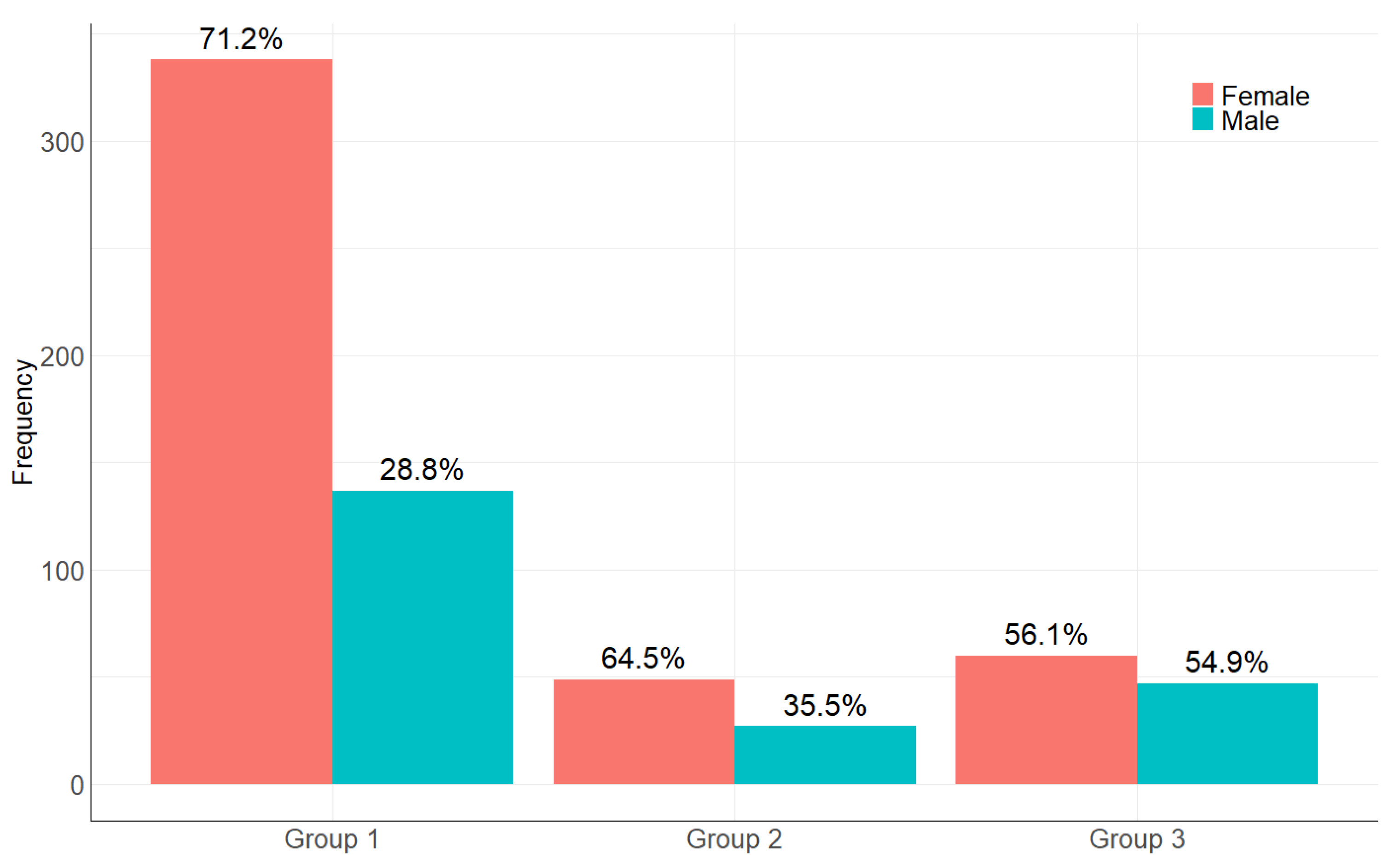
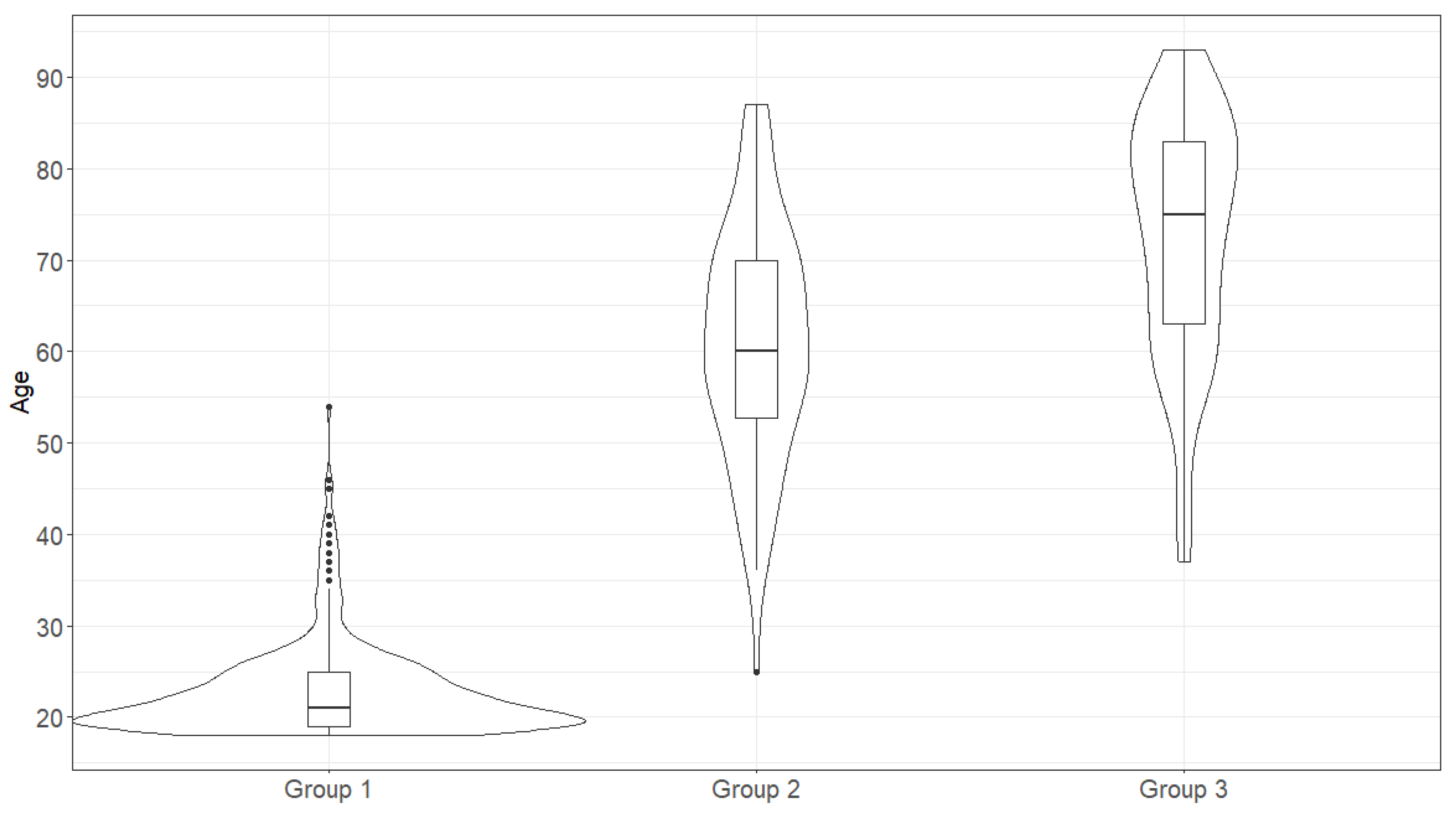
2.1. The Age and Sex Distribution in the Studied Samples
2.2. The Distribution of Allele Frequencies, the Hardy-Weinberg Equilibrium and the Influence of the Gene Linkage Disequilibrium in the Studied Samples
2.3. The Distances upon Pairwise Comparisons
2.4. Estimation of the Allele Distribution at Locus and Allele Levels
2.5. Comparison of Haplotype Frequencies
2.6. Logistic Regression
3. Materials and Methods
3.1. Subjects
3.2. Biomaterial Collection
3.3. gDNA Isolation, Library Preparation and Sequencing
- Quality threshold for reads (low quality reads were trimmed or discarded);
- Lowest absolute and relative coverage for each position;
- The highest number of differences (insertions, substitutions, deletions) from the group average for each read;
- Maximum relative position error—the number of differences (insertions, substitutions, deletions) from the consensus sequence in each position should not exceed the specified threshold;
- The highest average error per read for a group;
- The lowest number of reads in groups for each exon (I-class 2,3,4 exons, II-class-2,3 exons);
- The allelic imbalance should not exceed a given threshold; the ratio of the read number for the exons from each allele and the sum of these ratios;
- The presence of phantom (cross-mapping) and chimeric sequences;
- The percentage of combined, clustered, and used for typing reads computed for each sample.
3.4. Statistical Analysis
3.5. Used Formulas
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meyerowitz-Katz, G.; Merone, L. A Systematic Review and Meta-Analysis of Published Research Data on COVID-19 Infection Fatality Rates. Int. J. Infect. Dis. 2020, 101, 138–148. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization COVID-19 Weekly Epidemiological Update. World Heal. Organ. 2023, 125, 1–33.
- Mao, R.; Qiu, Y.; He, J.S.; Tan, J.Y.; Li, X.H.; Liang, J.; Shen, J.; Zhu, L.R.; Chen, Y.; Iacucci, M.; et al. Manifestations and Prognosis of Gastrointestinal and Liver Involvement in Patients with COVID-19: A Systematic Review and Meta-Analysis. Lancet Gastroenterol. Hepatol. 2020, 5, 667–678. [Google Scholar] [CrossRef] [PubMed]
- Spinato, G.; Fabbris, C.; Polesel, J.; Cazzador, D.; Borsetto, D.; Hopkins, C.; Boscolo-Rizzo, P. Alterations in Smell or Taste in Mildly Symptomatic Outpatients With SARS-CoV-2 Infection. JAMA 2020, 323, 2089. [Google Scholar] [CrossRef] [PubMed]
- Vetter, P.; Vu, D.L.; L’Huillier, A.G.; Schibler, M.; Kaiser, L.; Jacquerioz, F. Clinical Features of COVID-19. BMJ 2020, 369, m1470. [Google Scholar] [CrossRef]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Xiang, J.; Wang, Y.; Song, B.; Gu, X.; et al. Clinical Course and Risk Factors for Mortality of Adult Inpatients with COVID-19 in Wuhan, China: A Retrospective Cohort Study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef]
- Wang, F.; Huang, S.; Gao, R.; Zhou, Y.; Lai, C.; Li, Z.; Xian, W.; Qian, X.; Li, Z.; Huang, Y.; et al. Initial Whole-Genome Sequencing and Analysis of the Host Genetic Contribution to COVID-19 Severity and Susceptibility. Cell Discov. 2020, 6, 83. [Google Scholar] [CrossRef]
- The Severe Covid-19 GWAS Group Genomewide Association Study of Severe Covid-19 with Respiratory Failure. N. Engl. J. Med. 2020, 383, 1522–1534. [CrossRef]
- Cascella, M.; Rajnik, M.; Aleem, A.; Dulebohn, S.C. Features, Evaluation, and Treatment of Coronavirus Disease; Napoli, R.D., Sivoravong, J.C., Burkhardt, C., Eds.; StatPearls Publishing: Tampa, Fl, USA, 2022; Volume 1. [Google Scholar]
- Dutta, M.; Dutta, P.; Medhi, S.; Borkakoty, B.; Biswas, D. Polymorphism of HLA Class I and Class II Alleles in Influenza A(H1N1)Pdm09 Virus Infected Population of Assam, Northeast India. J. Med. Virol. 2018, 90, 854–860. [Google Scholar] [CrossRef]
- Stephens, H.A.F. HLA and Other Gene Associations with Dengue Disease Severity. Curr. Top. Microbiol. Immunol. 2010, 338, 99–114. [Google Scholar] [CrossRef]
- Teixeira, S.L.M.; De Sá, N.B.R.; Campos, D.P.; Coelho, A.B.; Guimarães, M.L.; Leite, T.C.N.F.; Veloso, V.G.; Morgado, M.G. Association of the HLA-B*52 Allele with Non-Progression to AIDS in Brazilian HIV-1-Infected Individuals. Genes Immun. 2014, 15, 256–262. [Google Scholar] [CrossRef]
- Ding, S.J.; Zhang, Y.; Zhang, X.M.; Jiang, X.L.; Pang, B.; Song, Y.H.; Wang, J.X.; Pei, Y.W.; Zhu, C.F.; Wang, X.J.; et al. Correlation Between HLA-A, B and DRB1 Alleles and Severe Fever with Thrombocytopenia Syndrome. PLoS Negl. Trop. Dis. 2016, 10, e0005076. [Google Scholar] [CrossRef]
- Goverdhan, S.V.; Howell, M.W.; Mullins, R.F.; Osmond, C.; Hodgkins, P.R.; Self, J.; Avery, K.; Lotery, A.J. Association of HLA Class I and Class II Polymorphisms with Age-Related Macular Degeneration. Investig. Ophthalmol. Vis. Sci. 2005, 46, 1726–1734. [Google Scholar] [CrossRef]
- Nguyen, A.; David, J.K.; Maden, S.K.; Wood, M.A.; Weeder, B.R.; Nellore, A.; Thompson, R.F. Human Leukocyte Antigen Susceptibility Map for Severe Acute Respiratory Syndrome Coronavirus 2. J. Virol. 2020, 94, 510–520. [Google Scholar] [CrossRef]
- Barquera, R.; Collen, E.; Di, D.; Buhler, S.; Teixeira, J.; Llamas, B.; Nunes, J.M.; Sanchez-Mazas, A. Binding Affinities of 438 HLA Proteins to Complete Proteomes of Seven Pandemic Viruses and Distributions of Strongest and Weakest HLA Peptide Binders in Populations Worldwide. Hla 2020, 96, 277–298. [Google Scholar] [CrossRef]
- Romero-López, J.P.; Carnalla-Cortés, M.; Pacheco-Olvera, D.L.; Ocampo-Godínez, J.M.; Oliva-Ramírez, J.; Moreno-Manjón, J.; Bernal-Alferes, B.; López-Olmedo, N.; García-Latorre, E.; Domínguez-López, M.L.; et al. A Bioinformatic Prediction of Antigen Presentation from SARS-CoV-2 Spike Protein Revealed a Theoretical Correlation of HLA-DRB1*01 with COVID-19 Fatality in Mexican Population: An Ecological Approach. J. Med. Virol. 2021, 93, 2029–2038. [Google Scholar] [CrossRef]
- Langton, D.J.; Bourke, S.C.; Lie, B.A.; Reiff, G.; Natu, S.; Darlay, R.; Burn, J.; Echevarria, C. The Influence of HLA Genotype on the Severity of COVID-19 Infection. Hla 2021, 98, 14–22. [Google Scholar] [CrossRef]
- Shkurnikov, M.; Nersisyan, S.; Jankevic, T.; Galatenko, A.; Gordeev, I.; Vechorko, V.; Tonevitsky, A. Association of HLA Class I Genotypes With Severity of Coronavirus Disease-19. Front. Immunol. 2021, 12, 641900. [Google Scholar] [CrossRef]
- Sanchez-Mazas, A. HLA Studies in the Context of Coronavirus Outbreaks. Swiss Med. Wkly. 2020, 150, w20248. [Google Scholar] [CrossRef]
- Tomita, Y.; Ikeda, T.; Sato, R.; Sakagami, T. Association between HLA Gene Polymorphisms and Mortality of COVID-19: An in Silico Analysis. Immun. Inflamm. Dis. 2020, 8, 684–694. [Google Scholar] [CrossRef]
- Iturrieta-Zuazo, I.; Rita, C.G.; García-Soidán, A.; de Malet Pintos-Fonseca, A.; Alonso-Alarcón, N.; Pariente-Rodríguez, R.; Tejeda-Velarde, A.; Serrano-Villar, S.; Castañer-Alabau, J.L.; Nieto-Gañán, I. Possible Role of HLA Class-I Genotype in SARS-CoV-2 Infection and Progression: A Pilot Study in a Cohort of Covid-19 Spanish Patients. Clin. Immunol. 2020, 219, 108572. [Google Scholar] [CrossRef] [PubMed]
- Warren, R.L.; Birol, I. HLA alleles measured from COVID-19 patient transcriptomes reveal associations with disease prognosis in a New York cohort. PeerJ 2021, 9, e12368. [Google Scholar] [CrossRef] [PubMed]
- Pisanti, S.; Deelen, J.; Gallina, A.M.; Caputo, M.; Citro, M.; Abate, M.; Sacchi, N.; Vecchione, C.; Martinelli, R. Correlation of the Two Most Frequent HLA Haplotypes in the Italian Population to the Differential Regional Incidence of Covid-19. J. Transl. Med. 2020, 18, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Warren, R.L.; Birol, I. HLA Predictions from the Bronchoalveolar Lavage Fluid and Blood Samples of Eight COVID-19 Patients at the Pandemic Onset. Bioinformatics 2021, 36, 5271–5273. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhang, W.; Zhang, J.; He, J.; Zhu, F. Distribution of HLA Allele Frequencies in 82 Chinese Individuals with Coronavirus Disease-2019 (COVID-19). Hla 2020, 96, 194–196. [Google Scholar] [CrossRef]
- Sakuraba, A.; Haider, H.; Sato, T. Population Difference in Allele Frequency of HLA-C*05 and Its Correlation with Covid-19 Mortality. Viruses 2020, 12, 1333. [Google Scholar] [CrossRef]
- Beerli, P. Pairwise Distance Methods. Comput. Evol. Biol. 2005, No BSC5936-Fall, 1–7. [Google Scholar]
- Holsinger, K.E.; Weir, B.S. Genetics in Geographically Structured Populations: Defining, Estimating and Interpreting FST. Nat. Rev. Genet. 2009, 10, 639–650. [Google Scholar] [CrossRef]
- Robinson, J.; Barker, D.J.; Georgiou, X.; Cooper, M.A.; Flicek, P.; Marsh, S.G.E. IPD-IMGT/HLA Database. Nucleic Acids Res. 2020, 48, D948–D955. [Google Scholar] [CrossRef]
- Excoffier, L.; Lischer, H.E.L. Arlequin Suite Ver 3.5: A New Series of Programs to Perform Population Genetics Analyses under Linux and Windows. Mol. Ecol. Resour. 2010, 10, 564–567. [Google Scholar] [CrossRef]
- Aickin, M.; Gensler, H. Adjusting for Multiple Testing When Reporting Research Results: The Bonferroni vs. Holm Methods. Am. J. Public Health 1996, 86, 726–728. [Google Scholar] [CrossRef]
- Liu, D.; Qiu, Y.; Zha, Y.; Li, W.; Li, D.; Wu, T. Association of HLA Class Ⅰ and Class Ⅱ Genes with Severe Acute Respiratory Syndrome in the Northern Chinese Population. Blood Genom. 2018, 2, 91–96. [Google Scholar] [CrossRef]
- Lin, M.; Tseng, H.K.; Trejaut, J.A.; Lee, H.L.; Loo, J.H.; Chu, C.C.; Chen, P.J.; Su, Y.W.; Lim, K.H.; Tsai, Z.U.; et al. Association of HLA Class I with Severe Acute Respiratory Syndrome Coronavirus Infection. BMC Med. Genet. 2003, 4, 9. [Google Scholar] [CrossRef]
- Ng, M.H.L.; Lau, K.; Li, L.; Cheng, S.; Chan, W.Y.; Hui, P.K.; Zee, B.; Leung, C.; Sung, J.J.Y. Association of Human-Leukocyte-Antigen Class I (B*0703) and Class II (DRB1*0301) Genotypes with Susceptibility and Resistance to the Development of Severe Acute Respiratory Syndrome. J. Infect. Dis. 2004, 190, 515–518. [Google Scholar] [CrossRef]
- Fricke-Galindo, I.; Falfán-Valencia, R. Genetics Insight for COVID-19 Susceptibility and Severity: A Review. Front. Immunol. 2021, 12, 622176. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Sex | Group 1 | Group 2 | Group 3 | |
|---|---|---|---|---|
| Female | 338 (71.2%) | 49 (64.5%) | 60 (56.1%) | χ2 = 9.6, df = 2, p-value < 0.05 |
| Male | 137 (28.8%) | 27 (35.5%) | 47 (43.9%) |
| Group Combination | Pearson’s Goodness-of-Fit Test Result |
|---|---|
| Group 1 + Group 2 | χ2 = 1.1, df = 1, p-value = 0.3 |
| Group 1 + Group 3 | χ2 = 8.51, df = 1, p < 0.05 |
| Group 2 + Group 3 | χ2 = 0.98, df = 1, p-value = 0.3 |
| Group 2A + Group 2B | χ2 = 6.4, df = 1, p < 0.05 |
| Group 2A + Group 3A | χ2 = 0.13, df = 1, p-value = 0.7 |
| Group 2A + Group 3B | χ2 = 0.55, df = 1, p-value = 0.46 |
| Group 2B + Group 3A | χ2 = 8.17, df = 1, p < 0.05 |
| Group 2B + Group 3B | χ2 = 3.95, df = 1, p < 0.05 |
| Group 3A + Group 3B | χ2 = 1.67, df = 1, p-value = 0.2 |
| Group Combination | Median Values in Compared Groups | The Wilcoxon Rank Sum Test with Continuity Correction | |
|---|---|---|---|
| First Group | Second Group | ||
| Group 1 + Group 2 | 21 | 60 | W = 193, p < 0.05 |
| Group 1 + Group 3 | 21 | 75 | W = 50,775, p < 0.05 |
| Group 2 + Group 3 | 60 | 75 | W = 2122.5, p < 0.05 |
| Group 2A + Group 3A | 71.5 | 80.5 | W = 573, p < 0.05 |
| Group 2B + Group 3B | 56 | 58 | W = 559.5, p < 0.05 |
| Locus | Group 1 | |||
|---|---|---|---|---|
| The Number of Genotypes | Observed Heterozygosity | Expected Heterozygosity | p-Value | |
| HLA-A | 475 | 0.897 | 0.88 | p < 0.05 |
| HLA-B | 475 | 0.96 | 0.95 | 0.09 |
| HLA-C | 475 | 0.91 | 0.91 | 0.42 |
| HLA-DRB1 | 475 | 0.94 | 0.93 | 0.67 |
| HLA-DQB1 | 475 | 0.88 | 0.86 | 0.5 |
| HLA-DPB1 | 475 | 0.75 | 0.75 | 0.9 |
| Group 2 | ||||
| HLA-A | 76 | 0.91 | 0.87 | 0.63 |
| HLA-B | 76 | 0.96 | 0.95 | 0.66 |
| HLA-C | 76 | 0.89 | 0.91 | 0.39 |
| HLA-DRB1 | 76 | 0.93 | 0.91 | 0.94 |
| HLA-DQB1 | 76 | 0.87 | 0.87 | 0.41 |
| HLA-DPB1 | 76 | 0.789 | 0.798 | 0.94 |
| Group 3 | ||||
| HLA-A | 157 | 0.87 | 0.86 | 0.3 |
| HLA-B | 157 | 0.96 | 0.95 | p < 0.05 |
| HLA-C | 157 | 0.92 | 0.90 | p < 0.05 |
| HLA-DRB1 | 157 | 0.94 | 0.92 | 0.06 |
| HLA-DQB1 | 157 | 0.86 | 0.87 | 0.34 |
| HLA-DPB1 | 157 | 0.83 | 0.77 | 0.78 |
| Group 1 | Group 2 | Group 3 | |
|---|---|---|---|
| Group 1 | - | ||
| Group 2 | 0.00086 (p-value = 0.14) | - | |
| Group 3 | −0.00003 (p-value = 0.44) | 0.00075 (p-value = 0.2) | - |
| Locus | Selection Principle | Chi-Square | Freedom Degrees | p-Value |
|---|---|---|---|---|
| HLA-A | V1 | 254.4 | 272 | 0.77 |
| V2 | 48.2 | 64 | 0.93 | |
| HLA-B | V1 | 644.5 | 644 | 0.49 |
| V2 | 124.7 | 106 | 0.10 | |
| HLA-C | V1 | 286.1 | 290 | 0.55 |
| V2 | 37.7 | 46 | 0.91 | |
| HLA-DRB1 | V1 | 417.4 | 430 | 0.66 |
| V2 | 73.0 | 72 | 0.44 | |
| HLA-DQB1 | V1 | 214.9 | 168 | p < 0.05 |
| V2 | 37.3 | 32 | 0.24 | |
| HLA-DPB1 | V1 | 164.8 | 158 | 0.34 |
| V2 | 61.1 | 48 | 0.1 |
| Group Combination | Method | HLA Locus | Significant Allele (Number, Group) | Chi-Square, df, p-Value | Adj p-Value (Holm-Bonf) |
|---|---|---|---|---|---|
| 1 + 2 + 3 | V1 | A* | 23:01_24:02 (n = 2, group 2; n = 0, group 1, group 3) | 16.7, 2, p < 0.05 | p < 0.05 |
| V2 | DQB* | 05:03:01G (n = 8, group 1; n = 8, group 2; n = 7, group 3) | 13.9, 2, p < 0.05 | p < 0.05 | |
| 1 + (2 + 3) | V2 | DQB* | 05:03:01G (n = 8, group 1; n = 15, group 2 + 3) | 9.8, 1, p < 0.05 | p < 0.05 |
| 1 + 2 | V2 | DQB* | 05:03:01G (n = 8, group 1; n = 8, group 2) | 11.2, 1, p < 0.05 | p < 0.05 |
| 1 + 3A | V1 | B* | 07:02_13:02 (n = 7, group 3A; n = 3, group 1) | 23.2, 1, p < 0.05 | p < 0.05 |
| V2 | B* | 27:02 (n = 8, group 3A; n = 24, group 1) | 11.6, 1, p < 0.05 | p < 0.05 | |
| 1 + 3B | V1 | C* DQB1* | 12:03_15:02 (n = 3, group 3B; n = 3, group 1) 03:03_06:03 (n = 2, group 3B; n = 0, group 1) | 12.8, 1, p < 0.05 16.0, 1, p < 0.05 | p < 0.05 p < 0.05 |
| № | Haplotype | Group Number | Fisher’s Exact Test | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 2A | 2B | 3 | 3A | 3B | Group Combination | p-Value | ||
| 1 | A*33:01:01G~ B*14:02:01G~ C*08:02:01G~ DRB1*01:02:01G~ DQB1*05:01:01G~ DPB1*04:01:01G | 9 | 5 | 3 | 2 | 1 | 1 | 0 | Group 1 + Group 2 Group 1 + Group 3 Group 2 + Group 3 | p < 0.05 0.47 p < 0.05 |
| 2 | A*33:01:01G~ B*14:02:01G~ C*08:02:01G~ DRB1*01:02:01G~ DQB1*05:01:01G | 11 | 5 | 3 | 2 | 1 | 1 | 0 | Group 1 + Group 2 Group 1 + Group 3 Group 2 + Group 3 | 0.06 0.31 p < 0.05 |
| 3 | A*33:01:01G~ B*14:02:01G~ C*08:02:01G | 14 | 5 | 3 | 2 | 2 | 2 | 0 | Group 1 + Group 2 Group 1 + Group 3 Group 2 + Group 3 | 0.17 0.14 p < 0.05 |
| 4 | B*14:02:01G~ C*08:02:01G | 24 | 7 | 4 | 3 | 3 | 3 | 0 | Group 1 + Group 2 Group 1 + Group 3 Group 2 + Group 3 Group 2A + Group 3A | 0.18 0.17 p < 0.05 0.2 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.06 *** (0.02) |
| SexMale | 1.87 (2.01) |
| Age:SexMale | −0.04 (0.03) |
| Constant | 3.9 *** (1.14) |
| Observation | 183 |
| Log Likelihood | −97.19 |
| Akaike Inf. Crit | 208.38 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.08 *** (0.06) |
| SexMale | −0.97 *** (0.38) |
| HLA-C*08:02:01G-carriage | 1.64 ** (0.78) |
| HLA-C*12:02:01G-carriage | −2.47 ** (1.25) |
| HLA-C*15:02:01G-carriage | −1.8 * (0.99) |
| HLA-C*16:02:01G-carriage | 15.1 (996.86) |
| Constant | 5.51 *** (1.07) |
| Observation | 183 |
| Log Likelihood | −97.19 |
| Akaike Inf. Crit | 208.38 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.06 *** (0.02) |
| SexMale | 2.26 (2.09) |
| HLA-C*08:02:01G-carriage | 1.87 ** (0.81) |
| Age:SexMale | −0.05 (0.03) |
| Constant | 3.94 *** (1.15) |
| Observation | 183 |
| Log Likelihood | −101.58 |
| Akaike Inf. Crit | 213.16 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.09 *** (0.02) |
| SexMale | −1.27 *** (0.42) |
| HLA-DRB1*01:01:01G-carriage | 1.05 ** (0.48) |
| HLA-DRB1*01:02:01G-carriage | 2.52 ** (1.24) |
| HLA-DRB1*04:05:01G-carriage | −20.16 (3956.18) |
| HLA-DRB1*08:04:01G-carriage | −18.68 (3956.18) |
| HLA-DRB1*09:01:02G-carriage | −17.64 (1574.57) |
| HLA-DRB1*12:01:01G-carriage | 1.31 (0.84) |
| HLA-DRB1*14:03:01G-carriage | −18.64 (3956.18) |
| HLA-DRB1*14:05:01G-carriage | 19.08 (3956.18) |
| Constant | 6.11 *** (1.2) |
| Observation | 183 |
| Log Likelihood | −90.14 |
| Akaike Inf. Crit | 202.28 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.06 *** (0.02) |
| SexMale | −1.71 *** (2.07) |
| HLA-DRB1*01:01:01G-carriage | 1.1 ** (0.45) |
| Age:SexMale | −0.04 (0.03) |
| Constant | 3.7 *** (1.16) |
| Observation | 183 |
| Log Likelihood | −101.49 |
| Akaike Inf. Crit | 212.98 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.08 *** (0.02) |
| SexMale | −1.1 *** (0.39) |
| HLA-DQB1*04:01:01G-carriage | −16.68 (882.74) |
| HLA-DQB1*05:01:01G-carriage | 0.99 ** (0.41) |
| HLA-DQB1*05:03:01G-carriage | 1.08 (0.66) |
| Constant | 5.14 *** (1.05) |
| Observation | 183 |
| Log Likelihood | −99.25 |
| Akaike Inf. Crit | 210.5 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.06 *** (0.02) |
| SexMale | 1.69 (2.02) |
| HLA-DQB1*05:01:01G-carriage | 0.94 ** (0.40) |
| Age:SexMale | −0.04 (0.03) |
| Constant | 3.68 *** (1.16) |
| Observation | 183 |
| Log Likelihood | −101.77 |
| Akaike Inf. Crit | 213.53 |
| Dependent Variable: Outcome | |
|---|---|
| Age | −0.06 *** (0.02) |
| SexMale | 1.96 ** (2.08) |
| HLA-C*08:02:01G-carriage | 1.91 ** (0.85) |
| HLA-DRB1*01:01:01G-carriage | 1.1 ** (0.47) |
| Age:SexMale | −0.05 (0.03) |
| Constant | 3.82 *** (1.18) |
| Observation | 183 |
| Log Likelihood | −98.76 |
| Akaike Inf. Crit | 209.53 |
| Group Name | Designation | Number |
|---|---|---|
| Control group (participants of the bone marrow donor registry) | 1 | 475 |
| Recovered patients with severe symptoms | 2 | 76 |
| Recovered patients with severe symptoms (under 65 y.o.) | 2A | 30 |
| Recovered patients with severe symptoms (above 65 y.o.) | 2B | 46 |
| Deceased patients | 3 | 157 |
| Deceased patients (under 65 y.o.) | 3A | 74 |
| Deceased patients (above 65 y.o.) | 3B | 33 |
| Group 1 (Control Group) | Aged 65 y.o. or Below |
|---|---|
| The number of patients | total 475 |
| Age, median, Q25–Q75 | 21 (19–25) |
| Sex | |
| Female | 338 |
| Male | 137 |
| Group 2 (Recovered) | Aged 65 y.o. or Below | Aged Above 65 y.o. |
|---|---|---|
| The number of patients | 46 | 30 |
| Age, median (Q25–Q75) | 56 (47–59) | 72 (69–78) |
| Sex | ||
| Female | 24 | 25 |
| Male | 22 | 5 |
| Group 3 (Deceased) | Aged 65 y.o. or Below | Aged Above 65 y.o. |
|---|---|---|
| The number of patients | 33 | 74 |
| Age, median (Q25–Q75) | 58 (54–62) | 81 (75–86) |
| Sex | ||
| Female | 15 | 45 |
| Male | 18 | 29 |
| Selection Principle | The Example of the Data | Freedom Degrees |
|---|---|---|
| The joint analysis of an allele pair (V1). | ‘24:02_68:24’, ‘25:01_68:02’, ‘03:01_30:04’, ‘24:02_32:01’, ‘01:01_02:01’, ‘01:01_25:01’, ‘01:02_29:02’, ‘02:01_30:01’, ‘33:01_68:01’, ‘25:01_33:01’, ‘03:02_68:01’, ‘01:01_29:02’, …. ‘02:05_11:01’, ‘01:01_68:01’, ‘23:01_23:01’, ‘03:01_29:02’, ‘02:01_24:02’, ‘03:01_33:03’, ‘24:02_29:02’, ‘02:01_68:01’, ‘33:01_68:02’, ‘03:01_23:01’, ‘24:02_24:02’, ‘25:01_32:01’, ‘11:01_30:01’, ‘01:01_03:01’, ‘02:01_30:04’, ‘23:01_30:01’ | 337 |
| Two alleles separately analyzed based on the number of carriers (V2) | ‘26:01’, ‘30:02’, ‘69:01’, ‘25:01’, ‘30:01’, ‘31:01’, ‘68:02’, ‘02:17’, ‘01:01’, ‘23:01’, ‘33:01’, ‘02:05’, ‘01:03’, ‘02:01’, ‘33:03’, ‘24:03’, ‘29:02’, ‘32:01’, ‘30:04’, ‘03:02’, ‘29:01’, ‘02:07’, ‘11:01’, ‘66:01’, ‘68:01’, ‘68:24’, ‘03:01’, ‘02:06’, ‘24:02’, ‘01:02’ | 46 |
| Paper | Comment (Population) | A* | B* | C* | DRB1* | DQB1* | DPB1* |
|---|---|---|---|---|---|---|---|
| Our results | Comparison of deceased and recovered patients with population data (Russian) | 14:02 | 08:02 | 01:01 01:02 | 05:03 05:01 | ||
| Haplotypes | B*14:02:01G~C*08:02:01G A*02:01:01G~B*27:02:01G~C*02:02:02G DRB1*01:01:01G~DQB1*05:01:01G ~DPB1*04:02:01G DRB1*07:01:01G~DQB1*02:01:01G ~DPB1*17:01:01G | ||||||
| SARS HLA associations | |||||||
| [33] | The association between HLA genes (Low typing resolution) and SARS (Chinese) | 26 | 04, 16, 09 | ||||
| [34] | Analysis of SARS severity in patients and high risk health care workers groups (Taiwanese) | 46:01 54:01 13:01 | |||||
| [35] | The association between SARS and HLA alleles (Chinese) | 07:03 | 03:01 | 06:01 | |||
| COVID-19 HLA associations | |||||||
| [7] | Patients with severe symptoms compared with mild ones (Chinese) | 11:01 | 51:01 13:02 | 14:02 | 14:04 01:01 12:01 | 03:01 | |
| [15] | Vulnerable/persistent to COVID-19 in silico (805 distinct populations) | 02:02 25:01 | 46:01 15:03 | 01:02 12:03 | |||
| [16] | Binding affinity of the HLA proteins to the SARS-CoV-2 proteome (10 groups including different populations) | 02:01 24:03 68:02 | 14:02 14:03 | 01:02 07:01 | |||
| [26] | HLA allele frequencies in 82 humans with COVID-19 (Chinese) | 15:27 | 07:29 | ||||
| [24] | Correlation between HLA haplotypes and COVID-19 (Italian) | 01:01 02:01 | 18:01 08:01 | 07:01 07:01 | 03:01 11:04 | ||
| [18] | The influence of HLA genotype on COVID-19 severity (North European) | 04:01 | |||||
| [17] | The in silico correlation between COVID-19 fatality and HLA (Mexican) | 01:01 | |||||
| [27] | Regression analysis of mortality across 74 countries (Japan, China, Russia etc.) | 05 | |||||
| [21] | The in silico association between HLA and COVID-19 mortality in 19 countries (Thailand, England, USA, Japan etc.) | 02:01 11:01 24:02 | |||||
| [36] | The association susceptibility and severity of COVID-19 review | 25:01 02:02 | 15:27 46:01 15:03 | 01:02 07:29 12:03 | |||
| [23] | The in silico retrospective prediction of HLA for COVID-19 prognosis (American) | 11:01 | 04:01 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheranev, V.; Bulusheva, I.; Vechorko, V.; Korostin, D.; Rebrikov, D. The Search of Association of HLA Class I and Class II Alleles with COVID-19 Mortality in the Russian Cohort. Int. J. Mol. Sci. 2023, 24, 3068. https://doi.org/10.3390/ijms24043068
Cheranev V, Bulusheva I, Vechorko V, Korostin D, Rebrikov D. The Search of Association of HLA Class I and Class II Alleles with COVID-19 Mortality in the Russian Cohort. International Journal of Molecular Sciences. 2023; 24(4):3068. https://doi.org/10.3390/ijms24043068
Chicago/Turabian StyleCheranev, Valery, Irina Bulusheva, Valery Vechorko, Dmitriy Korostin, and Denis Rebrikov. 2023. "The Search of Association of HLA Class I and Class II Alleles with COVID-19 Mortality in the Russian Cohort" International Journal of Molecular Sciences 24, no. 4: 3068. https://doi.org/10.3390/ijms24043068