
Rethinking the Dilated Encoder in TE-YOLOF: An Approach Based on Attention Mechanism to Improve Performance for Blood Cell Detection

Abstract
:1. Introduction
1.1. Background
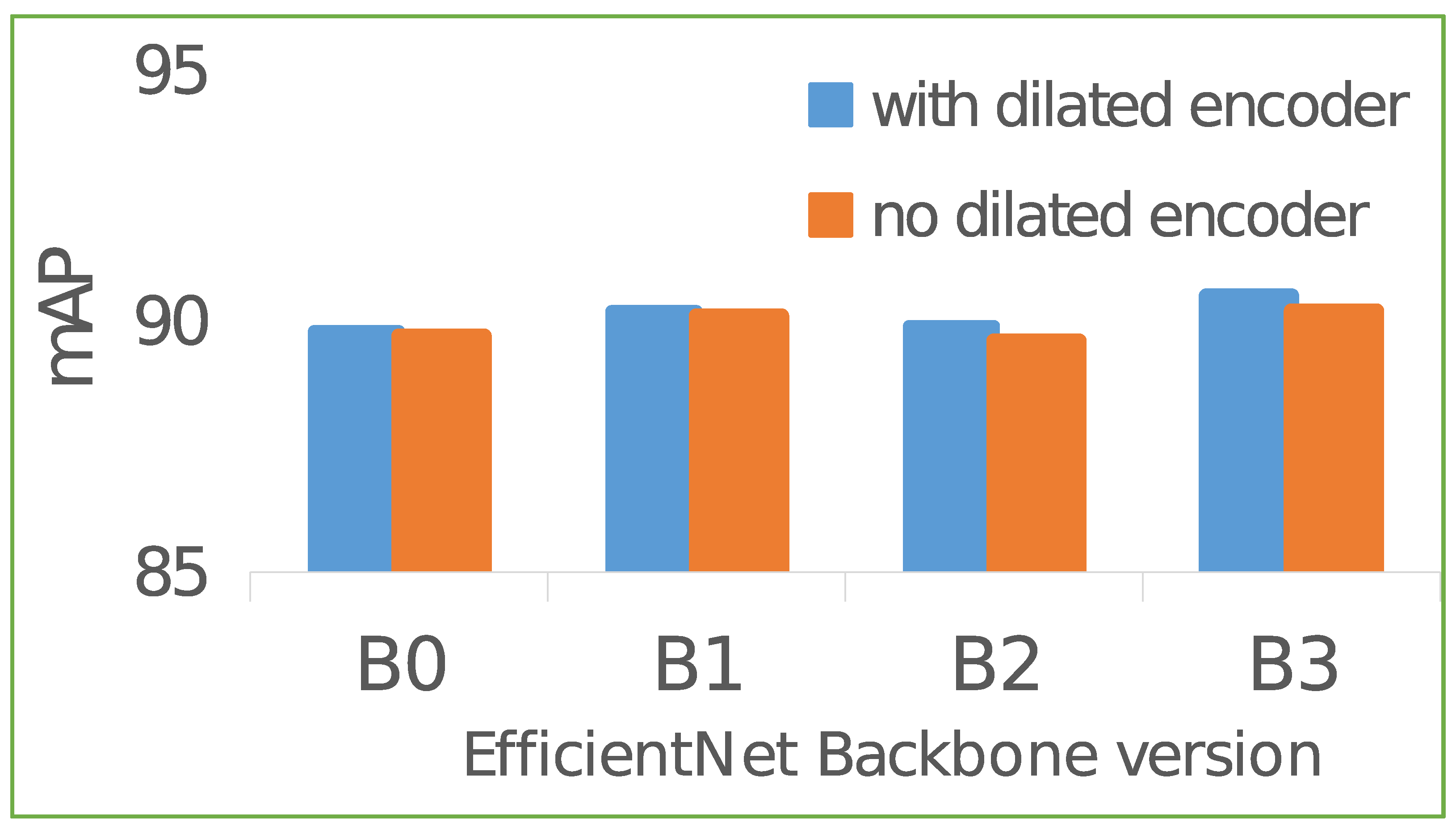
- Through experiments, we prove that the dilated encoder is a non-essential component in TE-YOLOF to address the problem of blood cell detection. This finding can reduce nearly one-third of the parameters of the original model, which reduce the model complexity from 9.94 M to 6.46 M.
- Attention mechanism is an effective way to increase model TE-YOLOF detection performance without greatly increasing model complexity on the blood cell detection task.
- The proposed attention mechanism ECAM can perform better on blood cell detection than other attention methods, such as SENet, CBAM, and so on. TE-YOLOF-B0 is still only 6.49 M after incorporating this module. Even the model complexity of ECBAM, which adds the spatial attention mechanism in CBAM into ECAM, is only 6.5 M.
1.2. Related Work
1.2.1. Blood Cell Detection
1.2.2. Attention Mechanisms
2. Results
2.1. Implementation Details
2.2. Dataset
2.3. Comparison with TE-YOLOF
2.4. Ablation Experiments
2.4.1. Different Channel Attention Module
2.4.2. Add Spatial Attention Module or Not
2.4.3. Spatial Attention Module Kernel Size
2.4.4. Reduction Ratio of MLP in ECAM
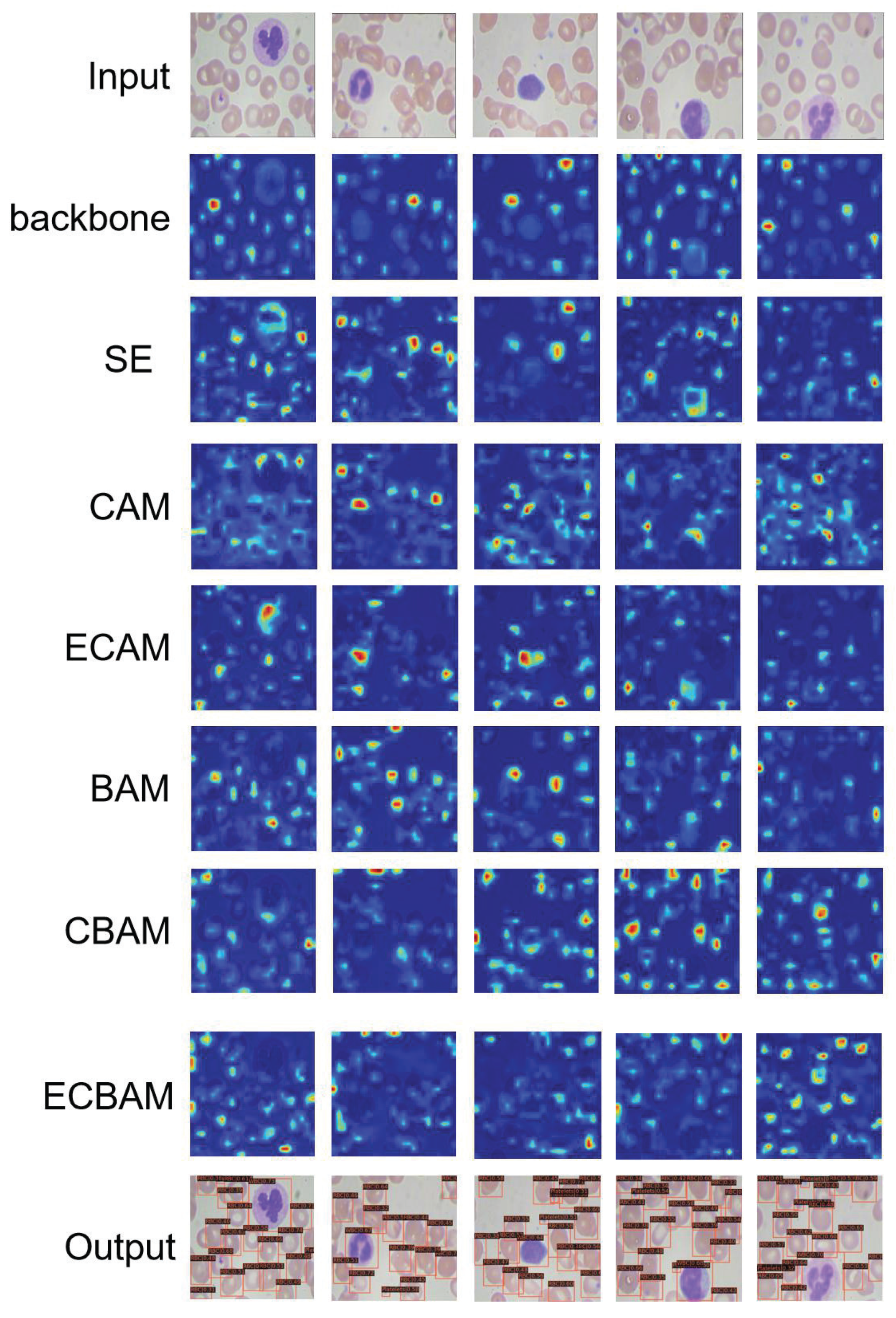
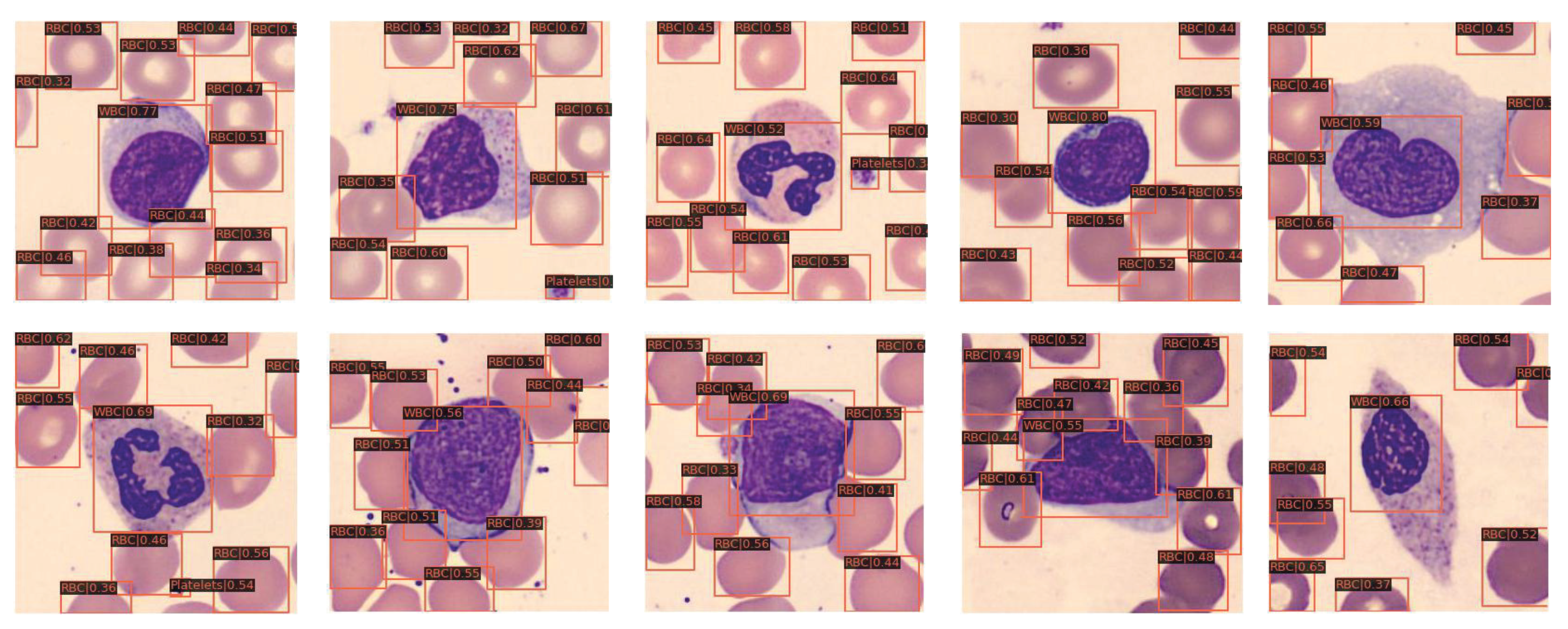
2.5. Visual Results
3. Discussion
4. Materials and Methods
4.1. Enhanced Channel Attention Module
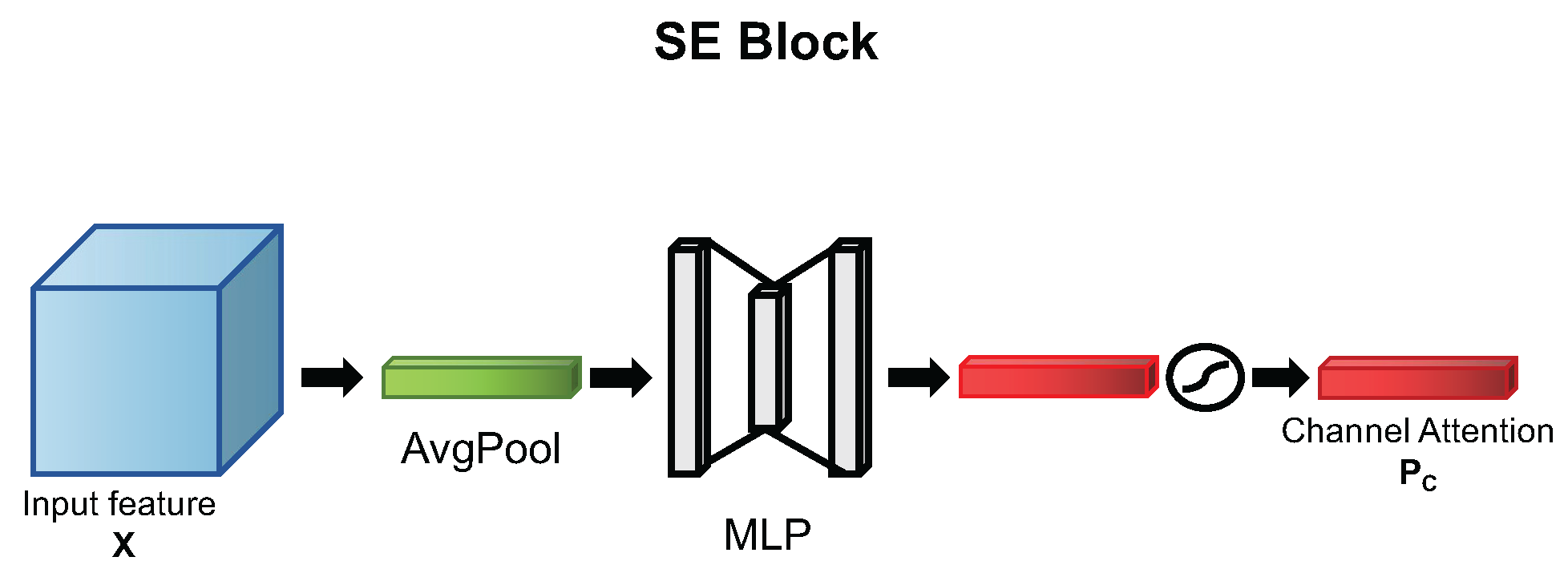
4.1.1. Review of SENet
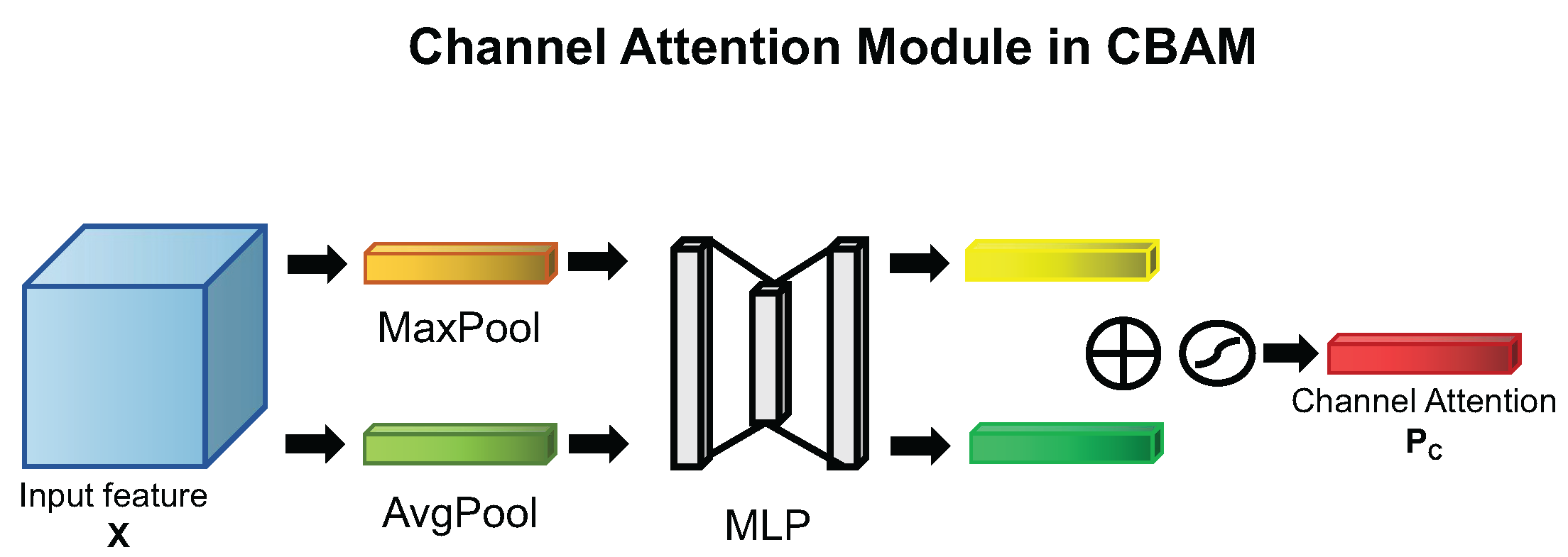
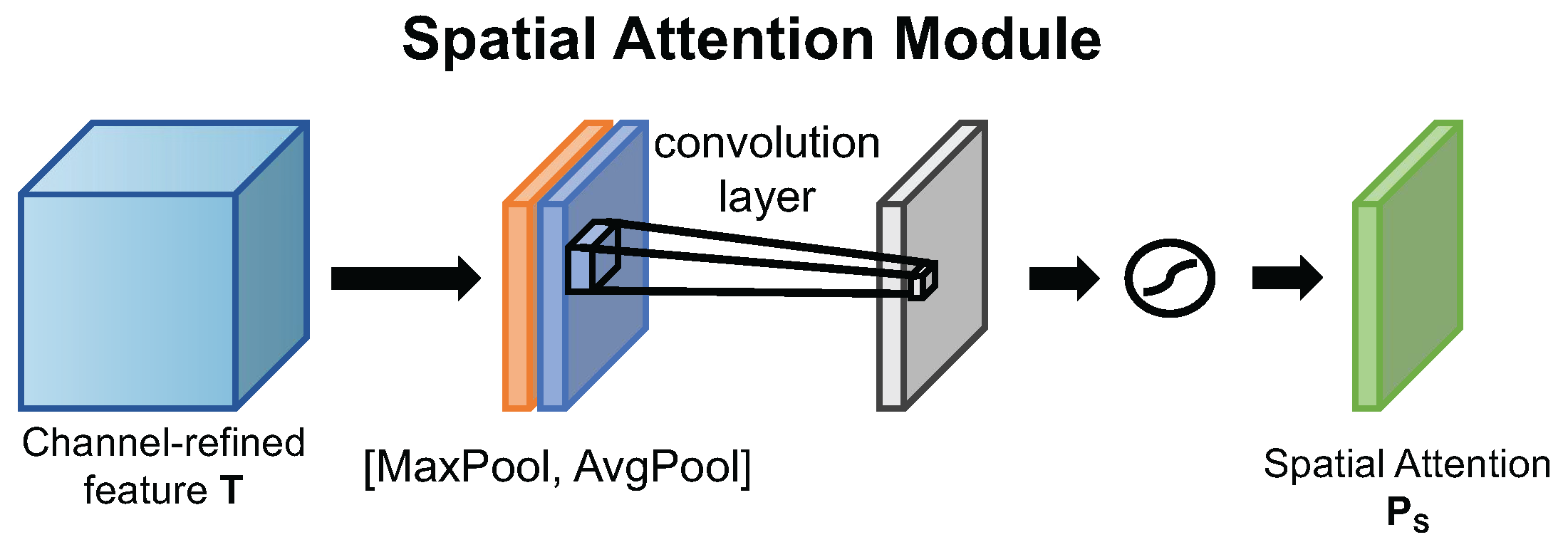
4.1.2. Motivated by CBAM
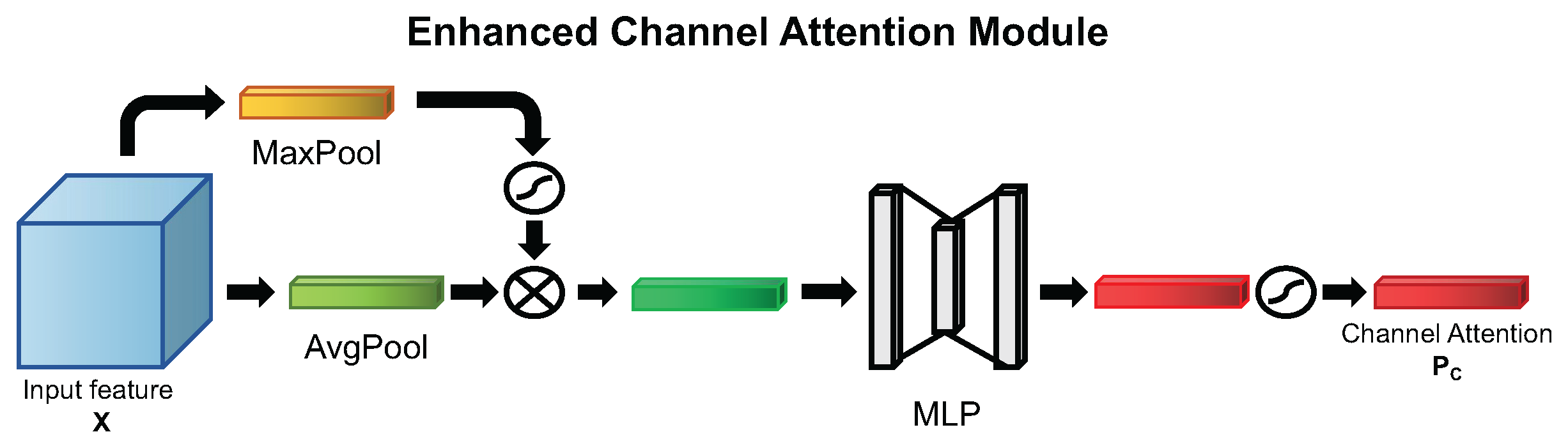
4.1.3. Enhanced Channel Attention Mechanism
Enhanced Channel Attention Module
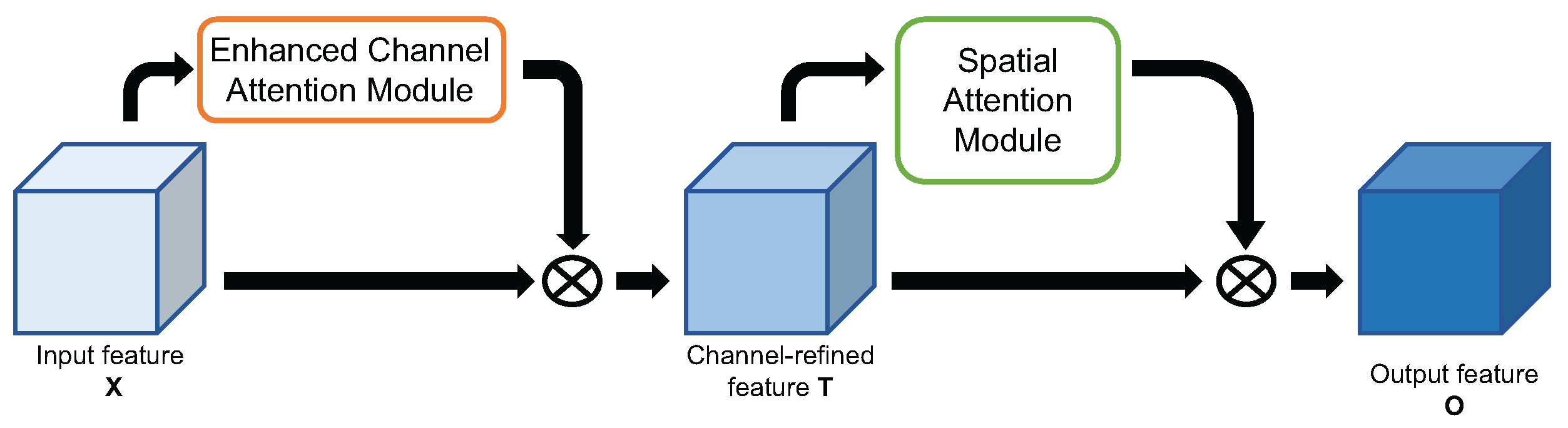
Enhanced CBAM
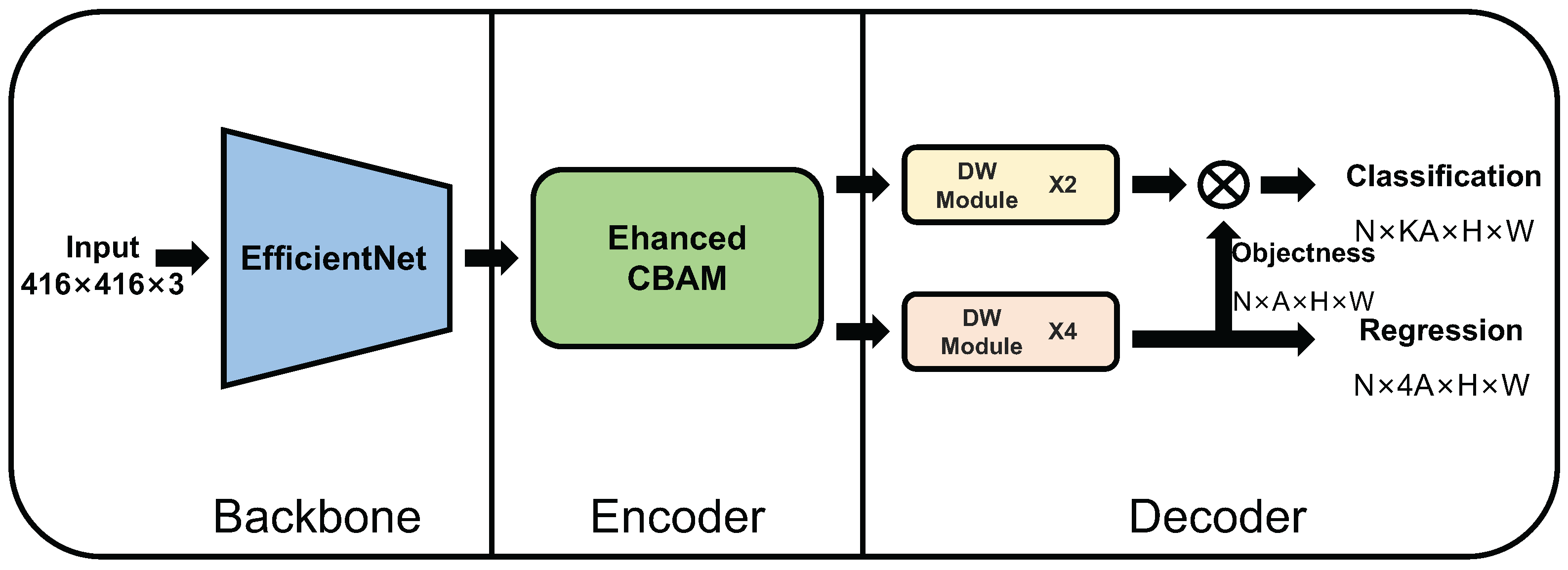
4.2. Enhanced Channel Attention Network
4.2.1. Backbone
4.2.2. Encoder
4.2.3. Decoder
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xing, F.; Xie, Y.; Su, H.; Liu, F.; Yang, L. Deep learning in microscopy image analysis: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4550–4568. [Google Scholar] [CrossRef] [PubMed]
- Gilbertson, J.; Patel, A.A.; Yagi, Y. Clinical slide digitization—Whole slide imaging in clinical practice experience from the University of Pittsburgh. Virtual Microsc. Virtual Slides Teach. Diagn. Res. 2005, 1, 239–254. [Google Scholar]
- Sommer, C.; Gerlich, D.W. Machine learning in cell biology–teaching computers to recognize phenotypes. J. Cell Sci. 2013, 126, 5529–5539. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, S.; Mishra, S.; Asthana, P. Automated detection of acute leukemia using k-mean clustering algorithm. In Advances in Computer and Computational Sciences; Springer: Berlin, Germany, 2018; pp. 655–670. [Google Scholar]
- Rawat, J.; Singh, A.; Bhadauria, H.; Virmani, J. Computer aided diagnostic system for detection of leukemia using microscopic images. Procedia Comput. Sci. 2015, 70, 748–756. [Google Scholar] [CrossRef] [Green Version]
- Markiewicz, T.; Osowski, S.; Marianska, B.; Moszczynski, L. Automatic recognition of the blood cells of myelogenous leukemia using SVM. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2496–2501. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kutlu, H.; Avci, E.; Özyurt, F. White blood cells detection and classification based on regional convolutional neural networks. Med. Hypotheses 2020, 135, 109472. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Zhang, P.; Wang, L. Cell counting algorithm based on YOLOv3 and image density estimation. In Proceedings of the 2019 IEEE 4th international conference on signal and image processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 920–924. [Google Scholar]
- Tavakoli, S.; Ghaffari, A.; Kouzehkanan, Z.M.; Hosseini, R. New segmentation and feature extraction algorithm for classification of white blood cells in peripheral smear images. Sci. Rep. 2021, 11, 1–13. [Google Scholar] [CrossRef]
- Dinh, P.H. A novel approach based on three-scale image decomposition and marine predators algorithm for multi-modal medical image fusion. Biomed. Signal Process. Control 2021, 67, 102536. [Google Scholar] [CrossRef]
- Verma, A.; Babar, A. CovidNet: A Light-Weight CNN for the Detection of COVID-19 Using Chest X-ray Images. In Proceedings of the Advanced Computing: 10th International Conference, IACC 2020, Panaji, Goa, India, 5–6 December 2020; Revised Selected Papers, Part I. Springer Nature: Berlin, Germany, 2021; Volume 1367, p. 169. [Google Scholar]
- Sourab, S.Y.; Shuvo, H.R.; Hasan, R.; Masruf, T. Diagnosis of COVID-19 from Chest X-ray Images Using Convolutional Neural Networking with K-Fold Cross Validation. In Proceedings of the 2021 IEEE International Power and Renewable Energy Conference (IPRECON), Kollam, India, 24–26 September 2021; pp. 1–5. [Google Scholar]
- Shakarami, A.; Menhaj, M.B.; Mahdavi-Hormat, A.; Tarrah, H. A fast and yet efficient YOLOv3 for blood cell detection. Biomed. Signal Process. Control 2021, 66, 102495. [Google Scholar] [CrossRef]
- Xu, F.; Li, X.; Yang, H.; Wang, Y.; Xiang, W. TE-YOLOF: Tiny and efficient YOLOF for blood cell detection. Biomed. Signal Process. Control 2022, 73, 103416. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Utah, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tong, X.; Wei, J.; Sun, B.; Su, S.; Zuo, Z.; Wu, P. ASCU-Net: Attention gate, spatial and channel attention u-net for skin lesion segmentation. Diagnostics 2021, 11, 501. [Google Scholar] [CrossRef]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 36–46. [Google Scholar]
- Lock, J.G.; Strömblad, S. Systems microscopy: An emerging strategy for the life sciences. Exp. Cell Res. 2010, 316, 1438–1444. [Google Scholar] [CrossRef] [PubMed]
- Atkins, C.G.; Buckley, K.; Blades, M.W.; Turner, R.F. Raman spectroscopy of blood and blood components. Appl. Spectrosc. 2017, 71, 767–793. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Su, M.C.; Cheng, C.Y.; Wang, P.C. A neural-network-based approach to white blood cell classification. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mandal, S.; Daivajna, V.; Rajagopalan, V. Machine learning based system for automatic detection of leukemia cancer cell. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019; pp. 1–4. [Google Scholar]
- Li, Y.; Xie, H.; Shin, H. 3D Object Detection Using Frustums and Attention Modules for Images and Point Clouds. Signals 2021, 2, 98–107. [Google Scholar] [CrossRef]
- Hu, J.; Yan, P.; Su, Y.; Wu, D.; Zhou, H. A method for classification of surface defect on metal workpieces based on twin attention mechanism generative adversarial network. IEEE Sens. J. 2021, 21, 13430–13441. [Google Scholar] [CrossRef]
- Zhu, G.; Wei, Z.; Lin, F. An object detection method combining multi-level feature fusion and region channel attention. IEEE Access 2021, 9, 25101–25109. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jiang, Z.; Liu, X.; Yan, Z.; Gu, W.; Jiang, J. Improved detection performance in blood cell count by an attention-guided deep learning method. OSA Contin. 2021, 4, 323–333. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–20 June 2020. [Google Scholar]
- Büscher, M. Flow cytometry instrumentation–an overview. Curr. Protoc. Cytom. 2019, 87, e52. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Dinh, P.H. Combining Gabor energy with equilibrium optimizer algorithm for multi-modality medical image fusion. Biomed. Signal Process. Control 2021, 68, 102696. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the Icml, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | #Params | GFLOPS | ||||||
|---|---|---|---|---|---|---|---|---|
| TE-YOLOF-B0 | 9.94 M | 6.21 G | 55.6 | 89.4 | 59.8 | 35.1 | 58.2 | 48.1 |
| - dilated encoder | 6.46 M | 2.73 G | 56.1 | 89.7 | 59.5 | 37.1 | 59.9 | 47.3 |
| + BAM | 6.46 M | 2.73 G | 55.5 | 89.8 | 57.2 | 36.1 | 58.8 | 44.1 |
| + CBAM | 6.5 M | 2.73 G | 56.8 | 90.3 | 60.6 | 36.0 | 59.8 | 49.4 |
| + ECBAM | 6.5 M | 2.73 G | 57.1 | 90.3 | 63.8 | 37.1 | 58.9 | 48.2 |
| TE-YOLOF-B1 | 12.45 M | 6.32 G | 57.8 | 90.1 | 64.5 | 38.4 | 62.2 | 46.1 |
| - dilated encoder | 8.97 M | 2.84 G | 57.3 | 89.4 | 67.0 | 43.6 | 58.5 | 47.3 |
| + BAM | 8.97 M | 2.84 G | 55.6 | 89.8 | 61.3 | 37.3 | 59.1 | 47.0 |
| + CBAM | 9 M | 2.84 G | 55.5 | 90.4 | 59.5 | 39.6 | 58.9 | 44.1 |
| + ECBAM | 9 M | 2.84 G | 57.2 | 90.4 | 66.0 | 39.3 | 60.0 | 44.6 |
| TE-YOLOF-B2 | 13.7 M | 6.4 G | 56.6 | 90.1 | 60.4 | 37.1 | 59.1 | 47.8 |
| - dilated encoder | 10.22 M | 2.92 G | 57.0 | 89.9 | 62.0 | 37.6 | 59.1 | 46.9 |
| + BAM | 10.22 M | 2.92 G | 58.3 | 89.9 | 62.0 | 40.3 | 60.2 | 46.8 |
| + CBAM | 10.25 M | 2.92 G | 56.5 | 90.4 | 59.2 | 38.2 | 57.8 | 47.7 |
| + ECBAM | 10.25 M | 2.92 G | 57.3 | 90.0 | 63.3 | 38.2 | 58.7 | 48.0 |
| TE-YOLOF-B3 | 16.76 M | 6.6 G | 58.4 | 90.6 | 66.0 | 40.4 | 59.6 | 47.5 |
| - dilated encoder | 13.28 M | 3.12 G | 57.6 | 90.2 | 61.7 | 34.4 | 61.0 | 49.2 |
| + BAM | 13.28 M | 3.12 G | 57.2 | 90.3 | 62.8 | 39.0 | 59.1 | 46.7 |
| + CBAM | 13.31 M | 3.12 G | 57.4 | 90.5 | 63.4 | 40.4 | 58.5 | 44.6 |
| + ECBAM | 13.31 M | 3.12 G | 57.3 | 90.5 | 65.2 | 39.3 | 60.6 | 44.9 |
| Model | Params | GFLOPS | |
|---|---|---|---|
| TE-YOLOF * | 6.46 M | 2.73 G | 89.7 |
| + ECA [29] | 6.46 M | 2.73 G | 89.0 |
| + CAM in CBAM [17] | 6.49 M | 2.73 G | 89.9 |
| + SE [16] | 6.49 M | 2.73 G | 90.0 |
| + ECAM | 6.49 M | 2.73 G | 90.1 |
| Model | Params | GFLOPS | |
|---|---|---|---|
| TE-YOLOF * | 6.46 M | 2.73 G | 89.7 |
| + CAM in CBAM [17] | 6.49 M | 2.73 G | 89.9 |
| + CBAM | 6.5 M | 2.73 G | 90.3 |
| + SE [16] | 6.49 M | 2.73 G | 90.0 |
| + SE + SAM in CBAM | 6.5 M | 2.73 G | 90.2 |
| + ECAM | 6.49 M | 2.73 G | 90.1 |
| + ECBAM | 6.5 M | 2.73 G | 90.3 |
| Kernel Size | Params | GFLOPS | |
|---|---|---|---|
| 3 | 6.49 M | 2.73 G | 89.8 |
| 5 | 6.49 M | 2.73 G | 90.2 |
| 7 | 6.5 M | 2.73 G | 90.3 |
| 9 | 6.5 M | 2.73 G | 90.2 |
| 11 | 6.5 M | 2.73 G | 89.7 |
| Reduction Ratio | Params | GFLOPS | |
|---|---|---|---|
| 2 | 6.72 M | 2.73 G | 89.8 |
| 4 | 6.59 M | 2.73 G | 89.3 |
| 8 | 6.53 M | 2.73 G | 90.0 |
| 16 | 6.5 M | 2.73 G | 90.3 |
| 32 | 6.48 M | 2.73 G | 90.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Lyu, H.; Xiang, W. Rethinking the Dilated Encoder in TE-YOLOF: An Approach Based on Attention Mechanism to Improve Performance for Blood Cell Detection. Int. J. Mol. Sci. 2022, 23, 13355. https://doi.org/10.3390/ijms232113355
Xu F, Lyu H, Xiang W. Rethinking the Dilated Encoder in TE-YOLOF: An Approach Based on Attention Mechanism to Improve Performance for Blood Cell Detection. International Journal of Molecular Sciences. 2022; 23(21):13355. https://doi.org/10.3390/ijms232113355
Chicago/Turabian StyleXu, Fanxin, He Lyu, and Wei Xiang. 2022. "Rethinking the Dilated Encoder in TE-YOLOF: An Approach Based on Attention Mechanism to Improve Performance for Blood Cell Detection" International Journal of Molecular Sciences 23, no. 21: 13355. https://doi.org/10.3390/ijms232113355