

HE-YOLOv5s: Efficient Road Defect Detection Network
 ,
,
Abstract
:1. Introduction
- (1)
- The feature fusion part was modified to obtain a feature map more suitable for this work and one detection head was reduced.
- (2)
- The number of C3 modules of the backbone network was pruned.
- (3)
- Introduced Ghostmodule and BottleneckTransformer modules in the SPPF module to obtain a new SPPF module.
- (4)
- Added NAMAttention attention mechanism between the backbone and the Neck network.
2. Related Work
2.1. The YOLO Family of Models
2.2. SPP and Its Improvement
2.3. Feature Fusion
2.4. Model Pruning
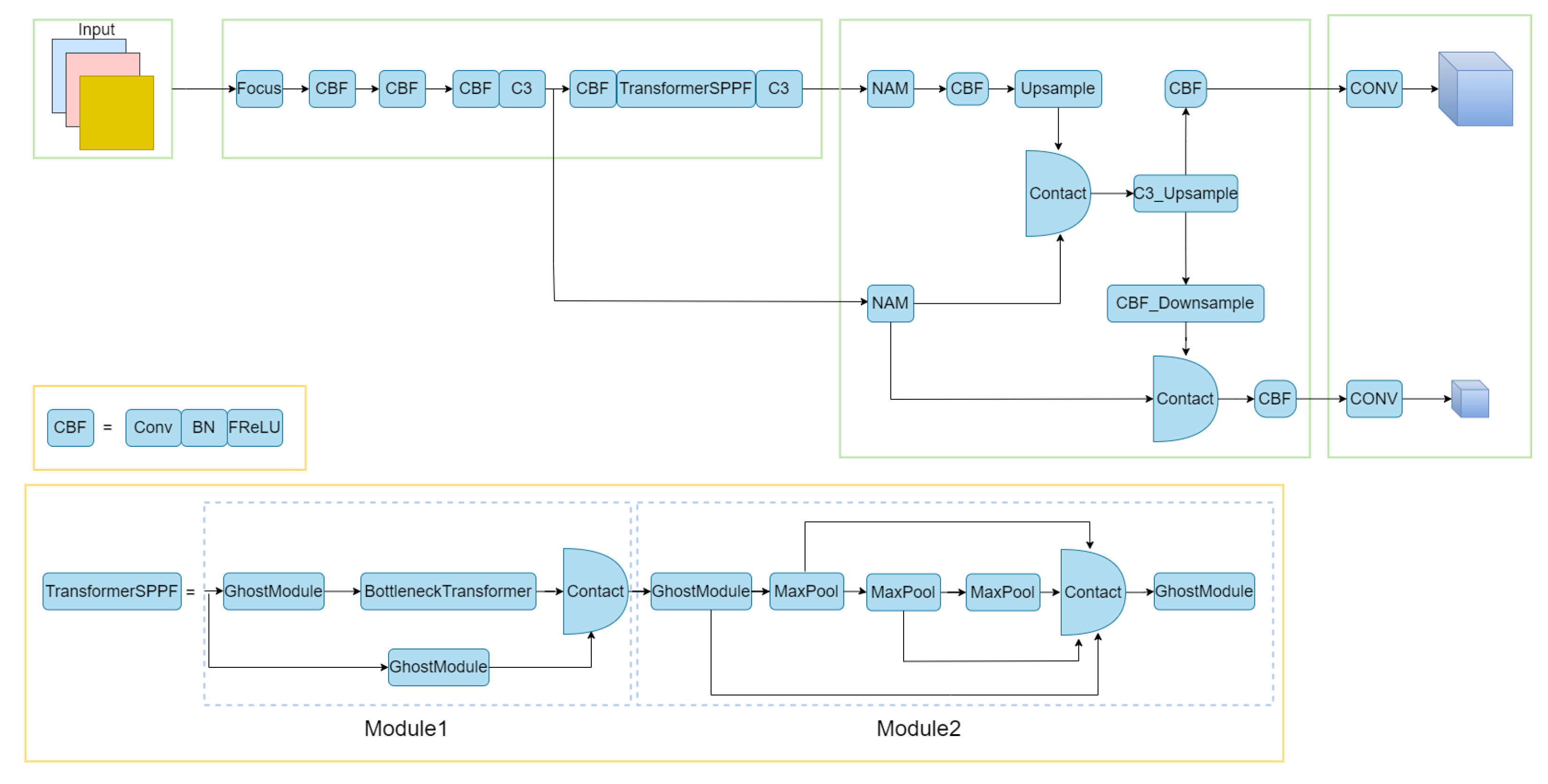
3. The Proposed Model
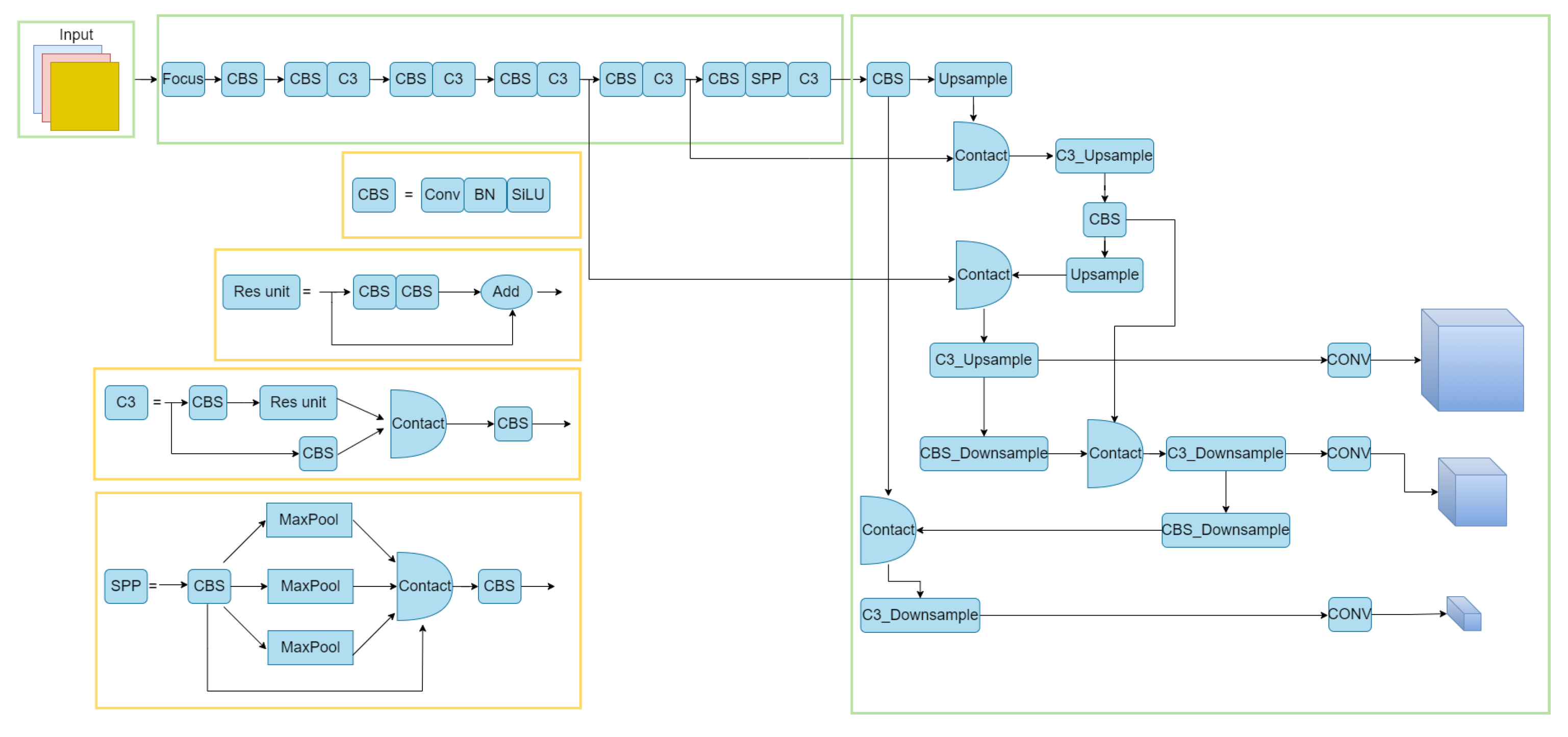
3.1. YOLOv5 Model
3.2. Pruning of the Backbone and NECK Networks
3.3. Activation Function
3.4. BottleneckTransformer-SPPF Module
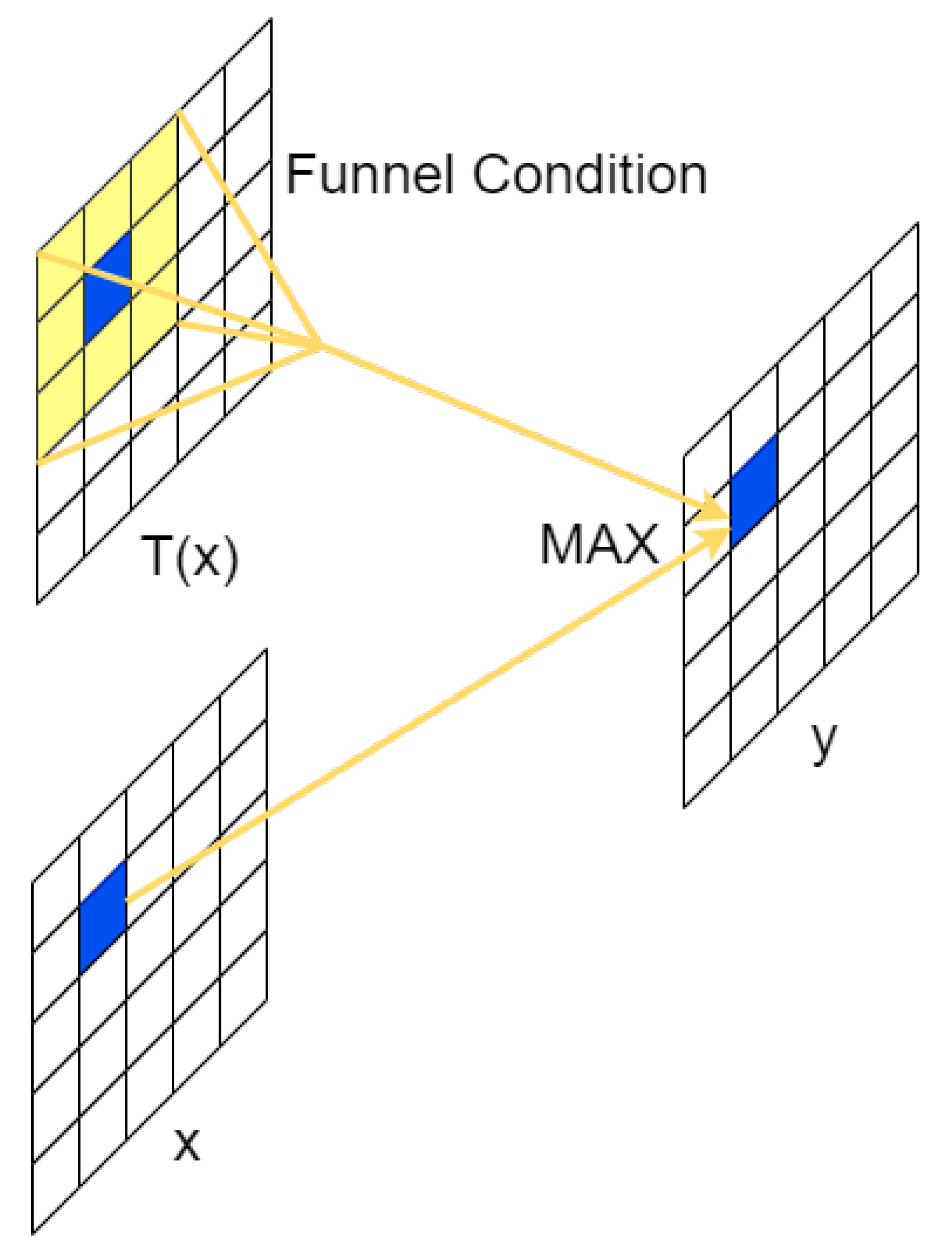
3.5. Replacing Upsampling
- (1)
- First, an image of size m × n is scaled k times to obtain an image of m/K × n/K.
- (2)
- Since the pixel points in the original image are known, we need to obtain the pixel values of the scaled image, we must find the pixel (x,y) corresponding to each pixel point (x,y) of the scaled image in the original image.
- (3)
- The 16 nearest pixel points of the original image from pixel (x,y) are compared with pixel (x,y), and the resulting parameter is used as the nearest 16 pixel points for calculating (x,y).
- (4)
- Find the 16 pixel point weights by the BiCubic function, where the BiCubic function is shown in Equation (1), and finally add the 16 pixel point weights to obtain the pixel value (x,y) after the scaled image, and finally the corresponding coordinates (x,y) of the original image can be obtained according to the proportional conversion relationship.
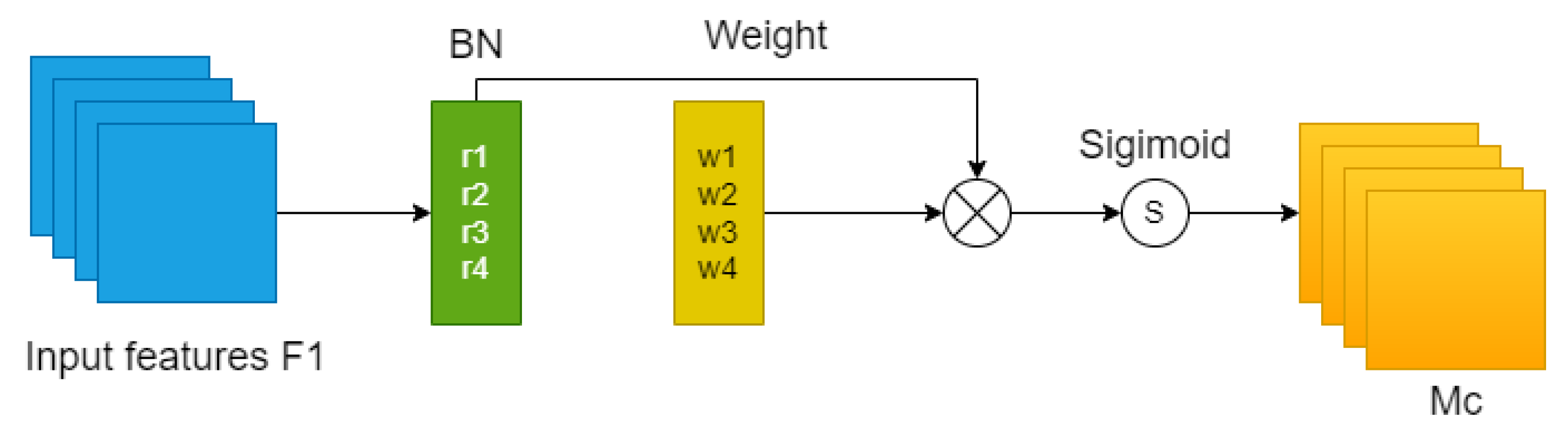
3.6. Adding Attention Mechanism
4. Experimental Details and Discussion
4.1. Experimental Details
4.1.1. Experimental Environment
4.1.2. Evaluation Metrics
- TP: number of samples correctly predicted by the model to be in the positive category
- FP: number of samples incorrectly predicted by the model to be in the positive category
- FN: number of samples incorrectly predicted by the model to be in the negative category
4.1.3. Training Model
4.1.4. Dataset
4.2. Discussion
4.2.1. Ablation Experiments
4.2.2. Comparison with YOLO Series Models
4.2.3. Compare My Optimization Model with Some Other Models
4.2.4. Comparison with Other Series Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, P.; Rau, P.L.P.; Salvendy, G. Road safety research in China: Review and appraisal. Traffic Inj. Prev. 2010, 11, 425–432. [Google Scholar] [CrossRef]
- Singh, S.K. Road traffic accidents in India: Issues and challenges. Transp. Res. Procedia 2017, 25, 4708–4719. [Google Scholar] [CrossRef]
- Zaloshnja, E.; Miller, T.R. Cost of crashes related to road conditions, United States, 2006. In Annals of Advances in Automotive Medicine/Annual Scientific Conference; Association for the Advancement of Automotive Medicine: Chicago, IL, USA, 2009; Volume 53, p. 141. [Google Scholar]
- Khan, M.H.; Babar, T.S.; Ahmed, I.; Babar, K.S.; Zia, N. Road traffic accidents: Study of risk factors. Prof. Med. J. 2007, 14, 323–327. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Zhou, Y.; Guo, X.; Hou, F.; Wu, J. Review of intelligent road defects detection technology. Sustainability 2022, 14, 6306. [Google Scholar] [CrossRef]
- Sholevar, N.; Golroo, A.; Esfahani, S.R. Machine learning techniques for pavement condition evaluation. Autom. Constr. 2022, 136, 104190. [Google Scholar] [CrossRef]
- Bello-Salau, H.; Aibinu, A.M.; Onwuka, E.N.; Dukiya, J.J.; Onumanyi, A.J. Image processing techniques for automated road defect detection: A survey. In Proceedings of the 2014 11th International Conference on Electronics, Computer and Computation (ICECCO), Abuja, Nigeria, 29 September–1 October 2014; pp. 1–4. [Google Scholar]
- Chatterjee, S.; Saeedfar, P.; Tofangchi, S.; Kolbe, L.M. Intelligent Road Maintenance: A Machine Learning Approach for surface Defect Detection. In Proceedings of the ECIS 2018, Portsmouth, UK, 23–28 June 2018; p. 194. [Google Scholar]
- Li, H.; Song, D.; Liu, Y.; Li, B. Automatic pavement crack detection by multi-scale image fusion. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2025–2036. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Kei, L.S.; Li, C. Automatic pixel-level pavement crack detection using information of multi-scale neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision based data driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Lau, S.L.H.; Chong, E.K.P.; Yang, X.; Wang, X. Automated pavement crack segmentation using u-net-based convolutional neural network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Liu, J.; Yang, X.; Lau, S.; Wang, X.; Luo, S.; Lee, V.C.S.; Ding, L. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 1291–1305. [Google Scholar] [CrossRef]
- Asadi, P.; Mehrabi, H.; Asadi, A.; Ahmadi, M. Deep convolutional neural networks for pavement crack detection using an inexpensive global shutter RGB-D sensor and ARM-based single-board computer. Transp. Res. Rec. 2021, 2675, 885–897. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper_files/paper/2015/hash/14bfa6bb14875e45bba028a21ed38046-Abstract.html (accessed on 5 July 2023). [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 2778–2788. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Lian, X.; Pang, Y.; Han, J.; Pan, J. Cascaded hierarchical atrous spatial pyramid pooling module for semantic segmentation. Pattern Recognit. 2021, 110, 107622. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. Matnet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef]
- Hu, L.; Li, Y. Micro-YOLO: Exploring Efficient Methods to Compress CNN based Object Detection Model. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021), Online, 4–6 February 2021; pp. 151–158. [Google Scholar]
- Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, faster and better for real-time UA V applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Xu, X.; Zhang, X.; Zhang, T. Lite-yolov5: A lightweight deep learning detector for on-board ship detection in large-scene sentinel-1 sar images. Remote Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Sun, J. Funnel activation for visual recognition. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 351–368. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv 2019, arXiv:1905.09418. [Google Scholar]
- Zhou, T.; Li, L.; Li, X.; Feng, C.-M.; Li, J.; Shao, L. Group-Wise Learning for Weakly Supervised Semantic Segmentation. IEEE Trans. Image Process. 2022, 31, 799–811. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper_files/paper/2015/hash/33ceb07bf4eeb3da587e268d663aba1a-Abstract.html (accessed on 5 July 2023).
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Omata, H.; Kashiyama, T.; Sekimoto, Y. Global Road Damage Detection: State-of-the-art Solutions. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5533–5539. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type and Number of Tests Performed | D00 | D01 | D10 | D20 | D40 | D43 | D44 | D50 |
|---|---|---|---|---|---|---|---|---|
| Numbers | 5307 | 141 | 3501 | 6717 | 4523 | 639 | 4025 | 2888 |
| YOLOv5s HE-YOLOv5s | |||||||
|---|---|---|---|---|---|---|---|
| Feature fusion | - | + | + | + | + | + | + |
| Delete parameter | - | - | + | + | + | + | + |
| SiLU to FreLU | - | - | - | + | + | + | + |
| BottleneckTransformer-SPPF | - | - | - | - | + | + | + |
| Add NAM | - | - | - | - | - | + | + |
| Map (%) | 56.79 | 56.82 | 52.63 | 57.23 | 57.57 | 58.59 | 58.87 |
| FPS (ms) | 81.81 | 110.96 | 141.41 | 120.89 | 119.73 | 95.88 | 90.61 |
| Size (M) | 27.88 | 21.55 | 20.82 | 21.20 | 21.20 | 21.79 | 21.81 |
| Precision (%) | 81.01 | 76.55 | 76.10 | 78.73 | 80.39 | 81.23 | 82.02 |
| Tiny-YOLOv4 | YOLOv4 | YOLOv5s | Tiny-YOLOx | HE-YOLOv5s | |
|---|---|---|---|---|---|
| Map (%) | 52.45 | 55.67 | 56.79 | 58.70 | 58.87 |
| FPS (ms) | 160.22 | 41.14 | 81.81 | 72.90 | 90.61 |
| Size (M) | 23.08 | 250.41 | 27.88 | 19.91 | 21.81 |
| Precision (%) | 67.41 | 73.67 | 81.01 | 75.62 | 82.02 |
| FR-CNN | YOLOv4 | Ultralytics-YOLO | Improved YOLOv4 | HE-YOLOv5s | |
|---|---|---|---|---|---|
| Proposed team name | E-LAB | AIRS-CSR | IMSC | SIS Lab | Ynu |
| F1 | 0.47 | 0.55 | 0.67 | 0.63 | 0.65 |
| Mobilnetv2-SSD | Effcientdet | Resnet50-Centernet | HE-YOLOv5s | |
|---|---|---|---|---|
| Map (%) | 45.94 | 40.05 | 56.69 | 58.87 |
| FPS (ms) | 96.97 | 28.65 | 60.15 | 90.61 |
| Size (M) | 18.29 | 15.45 | 127.94 | 21.81 |
| Precision (%) | 81.50 | 80.60 | 79.29 | 82.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Duan, M.; Ding, G.; Ding, H.; Hu, P.; Zhao, H. HE-YOLOv5s: Efficient Road Defect Detection Network. Entropy 2023, 25, 1280. https://doi.org/10.3390/e25091280
Liu Y, Duan M, Ding G, Ding H, Hu P, Zhao H. HE-YOLOv5s: Efficient Road Defect Detection Network. Entropy. 2023; 25(9):1280. https://doi.org/10.3390/e25091280
Chicago/Turabian StyleLiu, Yonghao, Minglei Duan, Guangen Ding, Hongwei Ding, Peng Hu, and Hongzhi Zhao. 2023. "HE-YOLOv5s: Efficient Road Defect Detection Network" Entropy 25, no. 9: 1280. https://doi.org/10.3390/e25091280