

Kaniadakis’s Information Geometry of Compositional Data

1
De Castro Statistics, Collegio Carlo Alberto, 10122 Torino, Italy
2
Department of Mathematics, University of Genoa, 16144 Genova, Italy
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(7), 1107; https://doi.org/10.3390/e25071107
Submission received: 29 June 2023
/
Revised: 20 July 2023
/
Accepted: 21 July 2023
/
Published: 24 July 2023
(This article belongs to the Special Issue Twenty Years of Kaniadakis Entropy: Current Trends and Future Perspectives)
{kind=link}
{kind=link}
{kind=link}
Abstract
:We propose to use a particular case of Kaniadakis’ logarithm for the exploratory analysis of compositional data following the Aitchison approach. The affine information geometry derived from Kaniadakis’ logarithm provides a consistent setup for the geometric analysis of compositional data. Moreover, the affine setup suggests a rationale for choosing a specific divergence, which we name the Kaniadakis divergence.
1. Introduction
This paper describes Kaniadakis’ statistics as a methodology in data science. Precisely, we discuss Kaniadakis’ formalism for defining an affine structure on the open probability simplex. We present the methods in some generality and use them for the exploratory analysis of compositional data. The illustrating example is a small dataset, and we do not discuss any scaling issues of our methods. However, the dataset has an independent interest in financial risk analysis.
1.1. Why a Geometric Methodology
Kaniadakis’ logarithm [1,2] generalises the ordinary logarithm in a way that supports the development of deformed exponential families, deformed statistical divergences, and deformed entropy. Kaniadakis was originally motivated by the applications to non-extensive statistical physics in the sense of [3,4]. In this paper, we present the geometry of the probability simplex as a system of two affine spaces in duality from the perspective of information geometry (IG) [5]. The affine setup was first applied to deformed statistical models in [6].
The systematic use of this formal geometric perspective provides a robust and unified rationale for discussing key descriptive concepts. Defining geometry is much more than providing a topology or a distance. We provide a definition of affine geodesics and a natural duality so that the orthogonal surfaces of the geodesics are well-defined by a specific divergence function. The divergence level sets form a neighbourhood system and, eventually, a topology. In this setup, we define the barycentre, the displacement from the barycentre, and dimensionality reduction. For the standard affine geometry of the probability simplex, see, for example, the tutorial reference [7]. We use a special kind of Kaniadakis’ logarithm that appears with a different name in compositional data (CoDa) ([8] Example 4.20).
1.2. CoDa
Compositional data (or CoDa) are the data where all of a (row) vector’s (i.e., ) components are strictly positive real values, can also have zero values, and thus contain solely relative information; the composition is called a D-part composition. Compositional data are often expressed in closed form and totalled a fixed value, such as 1 for parts per unit or 100 for percentage measurements ([9] Chapter 2).
Compositional data are often found in geosciences and other scientific disciplines, and classification, discrimination, and categorization need to be adapted to the case of CoDa. CoDa analysis is closely related to geosciences and biology, where the data are mostly expressed as proportions or concentrations without mentioning the total size or amount explicitly [10].
Significant advancement has been accomplished during the last thirty to forty years. Recently, the term CoDa analysis has been employed to “Insist on the idea that the study goals or hypotheses, which place more of an emphasis on relative than absolute values, are what ultimately determine composition rather than the data, which may not be pieces of a whole or may not have a fixed sum” [11]. These qualities make CoDa analysis the most powerful tool for applications outside the tradition of hard sciences [12]. Current studies in management, economics, and social sciences have shown in practice the benefits of compositional methods in handling a wide variety of problems, which range from market shares and customer segmentation to tourism, transport systems, financial ratios, and many more (see [11,13,14,15]).
1.3. CoDa and Systemic Financial Risk
The Center for Risk Management at the University of Lausanne (http://www.crml.ch, accessed on 28 June 2023) provides systemic risk assessments for European financial institutions, which we used in our empirical study using the above Kaniadakis methods. The dataset enables the determination of SRISK country-level values, a market-based systemic risk indicator first proposed in [16,17] and most recently examined in [18].
The characteristics of SRISK are popular in the literature, and SRISK is mainly used to recognize weak institutions and countries with a system-wide impact before a crisis occurs [19] and can help forecast actual sector performance [20].
Most of the previous literature has mainly focused on the absolute values of SRISK. In this work, we focus on implementing the Kaniadakis methods to see the different European countries as a part of compositional data. We developed work started in [12], where they first introduced compositional data analysis to examine the distribution of relative contributions to SRISK connected with key European nations from 2008 to 2021.
Atchison [21] first introduced CoDa analysis. The research conducted by the [12] on financial data used the Atchison methods to examine how European nations contribute to the total amount of systemic risk (SRISK). They find that the distinctive quality of CoDa analysis, especially the Atchison geometry, is very effective in determining the threats of possible instability offered by smaller institutions and nations that might not completely emerge from the scale of their systemic risk.
1.4. Data and Methods
This paper first establishes a novel theoretical framework for compositional data using Kaniadakis’ logarithm. Second, we implement the Kaniadakis divergence on the compositional data and calculate the exponential and mixture displacements on compositional data. Next, we calculate the barycenter and deviation. The purpose of calculating the barycenter is to check how far the values of SRISK are from their centre value.
We consider ten European economies (Belgium, Denmark, France, Germany, Greece, Italy, Netherlands, Spain, Switzerland, and the UK) with annual SRISK measurements collected at the end of December for 2008–2021. Every number is stated in billions of Euros. Like most CoDa method applications, the sample does not cover Europe. Therefore, the ten components that make up our SRISK compositions are just a portion of all those that may be used. CoDa analysis, however, is predicated on the basic notion of sub-compositional coherence, which ensures that a compositional study conducted on a subset of components is consistent with the same analysis performed on the entire composition.
1.5. Kaniadakis’ Logarithm
We summarize the particular case of Kaniadakis’ logarithm with a purely algebraic form. In the suggestive formalism introduced by [22], the generalised logarithms are associated with the reciprocal derivative function A
Notice that the growth is linear in both directions.
Notice that the above equation reduces any polynomial in y and , for example:
and so on. This is an algebraic feature, and this theory is a case of algebraic statistics [23].
The main known properties of the logarithm and exponential are
1.6. Kaniadakis’ Exponential Form of a Positive Probability Function
If the sample space is a finite set, then the probability simplex on is , and the open probability simplex is .
For all , the function , A as in Equation (1), is strictly positive and provides a positive weight on . It is proportional, but usually not equal, to a probability function,
We will also write . The mapping is called the escort mapping; see [22]. See ([24] §3.1) for a discussion of its injectivity and surjectivity. We introduce a notation for the escort expectation, .
For , the Kaniadakis divergence can be defined by changes in the usual definition of the logarithm to the Kaniadakis logarithm and the probability function p with the escort :
Clearly, . If , from the concavity in Equation (3),
Fix . For all , define
then, for ,
Conversely, for all , if u is a random variable such that , the real function
is continuous, goes to 0 as , and, for , takes a value larger than 1 because of Equation (4):
In conclusion, there exists a function,
and provided , such that
Hence, we have
and the mapping
is a bijection with inverse
1.7. Properties of the Cumulant Function
Let us compute the derivatives of the function . We use a square bracket notation for the direction
From Equation (7),
It follows that, for each and , it holds
where ; see Equation (7).
If the curve has constant divergence, that is, , derivation provides
Notice that , but this does not imply unless the previous conditions hold true.
1.8. Bibliographical Notes
Similarly, and the convex conjugate of can be computed. See below for the duality and see also [7,25]. Kaniadakis logarithm and exponential were first introduced in [26,27]. The application to IG used here appeared in [6,24,28]. These papers discuss both the finite state space and the general state space.
2. Affine Space
The Kaniadakis non-parametric affine geometry of the open probability simplex is a variation of the standard case [7]. The main difference is the substitution of the expectation with the escort expectation.
2.1. Statistical Bundle
The statistical bundle is an expression of the tangent space of as a dually flat affine statistical manifold in the sense of [5]. The statistical bundle and each fiber are defined by
In our setup, each fibre is a finite-dimensional vector space and can be identified with its dual. However, it is convenient to distinguish the two statistical bundles. The previous one is called exponential statistical bundle, while the mixture statistical bundle is
For each couple , the mapping
is a bijection. The is the identity mapping, and
The co-cycle of mappings is the exponential parallel transport of the exponential statistical bundle.
The mapping defined for all , , and by
provides a duality between the fibres of and .
The dual of the exponential transport can be computed as follows. For , , and ,
Now, ; hence, the dual of the exponential transport is the mixture transport,
2.2. Velocity and Auto-Parallel Curves
The following computation is a version of the original argument about Fisher’s score. Let be a one-dimensional parametric statistical model, namely a curve in geometric language. We assume the curve is smooth and twice differentiable as a mapping in the vector space . For each random variable ,
The velocity of the curve is defined as
We can check that and . The Cramer–Rao bound is
The variation computed with the escort probability function, namely , appears in Equation (15) as a gradient of the expectation .
A curve is auto-parallel for the mixture trasport if
For and ,
so that
Let us compute the auto-parallel curves for the exponential transport,
For and ,
so that, for some function ,
Comparing with Equation (7), we have that the auto-parallel curve for the exponential transport is
As observed above,
2.3. Surfaces of Constant Divergence
We have observed that an auto-parallel curve starting at with velocity has the form of Equation (18). For given extreme points and , it holds that
in particular, .
The velocity of the auto-parallel curve at is constant,
Consider a curve starting at of the form,
and assume a divergence is constant, precisely
It holds
That is, this surface of equi-divergence is orthogonal to the auto-parallel curves in the sense of the quadratic form . This is actually the generalization of a well-known result in IG, where the Hessian of the cumulant function is the Fisher’s information matrix. See, for example, [5].
2.4. Displacement
The machinery introduced above allows for explicitly defining the affine structure as originally defined by [29]. A textbook on affine geometry is ([30] Ch. 2,3,9). Below, we call the following two (dual) displacements on the statistical bundle. The mixture displacement is
The exponential displacement is
Both displacements define affine coordinates in the statistical bundle. The easy proofs are the same as in the standard cases [7]. Each displacement defines an atlas of charts on the affine bundle.
The orthogonal surfaces of the affine exponential auto-parallel curves are discussed in the section above. The orthogonal surfaces to the affine mixture auto-parallel curves are easily observed to be associated with the other divergence. In fact, it is the classical result of the duality between the two divergences. See, for example, [5].
The availability of an affine bundle would allow for a coherent and straightforward definition of mechanical concepts such as velocity, acceleration, Lagrangian, and Hamiltonian. See [31,32] for the standard case. In the present paper, we develop the application to CoDa, and we stress the notion of affine barycenter and the fact that a system of charts can be observed as a preprocessing of data to be followed by any method adapted to actual vector data.
2.5. Barycenter and Deviation
Let be a sequence of CoDa points with strictly positive components and normalized to one. Each data point is a point in the open probability simplex. The affine coordinates (20) centered at p are
The mean value of the affine coordinates is
If the mean value computed in the centering q is , the difference is
Hence,
The probability function is the same in both cases. In fact,
because of the uniqueness of the normalizing constant.
In conclusion, the probability function
with as Equation (21) does not depend on the reference p. It is the barycentre of the given data points.
The displacement of each data point from the barycentre is
and the expression of each point in the barycentre is
A one-dimensional summary consistent with our formalism of the divergence of each point from the barycentre is the Kaniadakis’ divergence , which is the normalising constant in the equation above. Another option is the Kaniadakis’ divergence that appears in the representation of the barycentre in the data point .
3. Data Analysis
This section will use some geometric concepts derived from Kaniadakis’ IG. It should be noted that our formalism is, in principle, affine and does not include any properly defined distance.
3.1. Kaniadakis Divergence
First, we compute the Kaniadakis divergence defined in Equation (5). Each point in in Figure 1 is the Kaniadakis divergence of the CoDa point corresponding to the year in the i-th row with respect to the CoDa point for the year in the j-th column. For example, the Kaniadakis divergence between 2008 and 2009 is . Most values are smaller than one, except when the reference distribution corresponds to 2008 or 2009 for the most recent years. The year 2009 deviates significantly from the other years.
3.2. Mixture Displacement
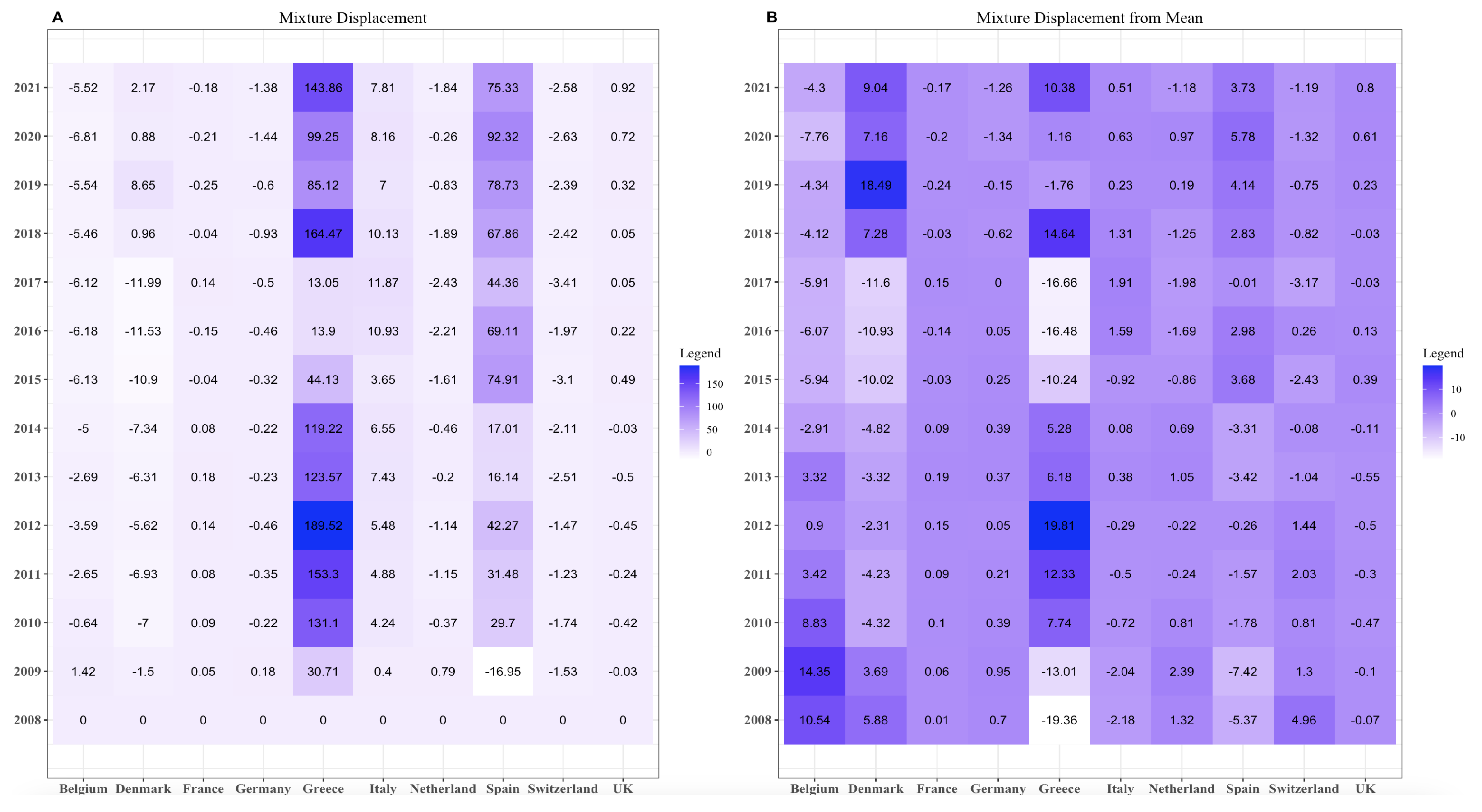
Equation (19) provides instructions for computing the mixture displacement. From Figure 2, the mixture displacement for Greece and Spain is very high for all the years. The value for Spain in 2009 was less than zero—the only negative value for Spain. On the contrary, all other countries do not have too many high values.
Equation (21) provides the mean value. After determining the mean, we compute the mixture displacement using the mean as a reference. We check that our values abruptly go from −10 to 10. However, the results for Greece and Spain decrease when the mixture displacement from the mean is calculated.
3.3. Exponential Displacement
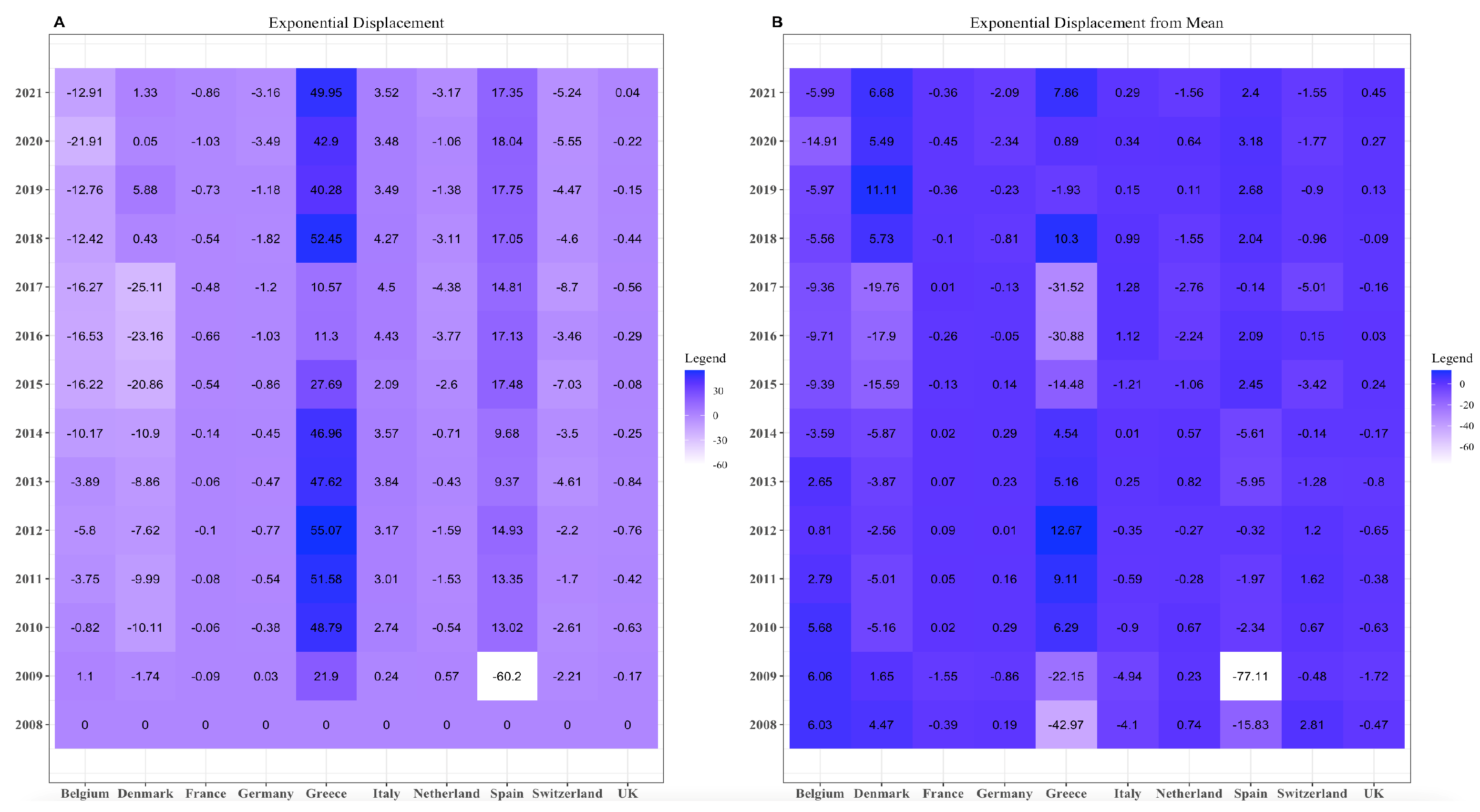
As above, Equation (20) returns the exponential displacement. Further, Figure 3 is the empirical result of Equation (20). As for the mixture displacement, we can see that Spain and Greece have higher displacement than other European countries. The value for Spain in the year 2009 is meagre.
If the mean is the reference point, the exponential displacement ranges from 0 to −60. The only significant changes are for the nations of Spain and Greece, where our values for 2009 for Spain decreased by about 18 times, and, for Greece, our values decreased significantly.
4. Conclusions and Discussion
In this research, we applied a particular type of divergence, Kaniadakis divergence, to compositional data, aligned with the symmetrised ratio transformation in ([8] Example 4.20). The dataset being examined spans the years 2008 through 2021. First, we built a theoretical framework for Kaniadakis divergence, mixture displacement, and exponential displacement.
Section 1 provided the mathematical framework for determining divergence and displacement, while Section 2 demonstrated how to apply those mathematical algorithms to compositional data. In the application, we found that Spain and Greece have more fluctuations when compared to the other European countries. The values of the mixture and exponential displacement confirm that Spain and Greece faced some financial crises compared to other countries.
This simple application shows the potential of IG for application to compositional data analysis. We suggest that Kaniadakis’ logarithm can reduce the computations for monitoring systemic risk to algebraic computations. The Kaniadakis logarithm, mixture, and exponential displacement on compositional data can be considered to broaden traditional research methods for compositional data analysis.
We would like to add a few words regarding the specific tools and formalism we used here. First, we mimicked one of the possible presentations of non-parametric IG by following the basic dually-flat setup step by step. Another successful presentation of non-parametric IG starts with properly defining the divergences and deriving the geometry; see, for example, [33]. A popular approach, not equivalent to the affine one, defines the geometry of the probability simplex by introducing a metric tensor. As in other geometric theories, one should carefully distinguish between choosing charts and introducing a topology.
In the present approach, we define the charts so that the associated manifold is affine; in this setup, some specific divergences appear as naturally associated with the geometry and the basic statistical notion, namely the pairing between measures and random variables. Everything is applied to simple data manipulation in the spirit of Aitchison’s methods.
No claim of optimality is made. The existence of many different but topologically equivalent divergences is only natural in our setup, where the topology actually depends on the geometry and not the other way around. Whenever needed, a choice must be based on some additional assumption. We carefully check the simple, useful operations on data, such that the geodesic connecting two given points, the velocity of variation, the barycentre, and the deviation from the barycentre are all defined correctly.
Author Contributions
Writing—review & editing, G.P. and M.S. All authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under Marie Skłodowska-Curie GA No. 101034449.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are publicly available on the website (http://www.crml.ch, accessed on 1 May 2023).
Acknowledgments
G.P. enjoys the support of de Castro Statistics, Collegio Carlo Alberto, and is a member of INDAM/GNAFA. Both G.P. and M.S. thank Francesco Porro (DIMA U. Genova) for providing and explaining the datasets. They also thank Eva Riccomagno (DIMA U. Genova) for carefully reading and providing advice on the final version of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| CoDa | Compositional Data |
| SRISK | Systemic Risk |
| IG | Information Geometry |
References
- Kaniadakis, G. Non-linear kinetics underlying generalized statistics. Phys. A 2001, 296, 405–425. [Google Scholar] [CrossRef] [Green Version]
- Kaniadakis, G. H-theorem and generalized entropies within the framework of nonlinear kinetics. Phys. Lett. A 2001, 288, 283–291. [Google Scholar] [CrossRef] [Green Version]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Statist. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Tsallis, C. Introduction to nonextensive statistical mechanics. In Approaching a Complex World; Springer: New York, NY, USA, 2009; p. xvii+382. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RI, USA, 2000; p. x+206, (Translated from the 1993 Japanese original by Daishi Harada). [Google Scholar]
- Pistone, G. κ-exponential models from the geometrical viewpoint. Eur. Phys. J. B Condens. Matter Phys. 2009, 71, 29–37. [Google Scholar] [CrossRef] [Green Version]
- Chirco, G.; Pistone, G. Dually affine Information Geometry modeled on a Banach space. arXiv 2022, arXiv:2204.00917. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J.J.; Tolosana-Delgado, R. Modelling and Analysis of Compositional Data; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Pawlowsky-Glahn, V.; Egozcue, J.J. Compositional data and their analysis: An introduction. Geol. Soc. Lond. Spec. Publ. 2006, 264, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Egozcue, J.J.; Pawlowsky-Glahn, V. Compositional data: The sample space and its structure. Test 2019, 28, 599–638. [Google Scholar] [CrossRef]
- Coenders, G.; Ferrer-Rosell, B. Compositional data analysis in tourism: Review and future directions. Tour. Anal. 2020, 25, 153–168. [Google Scholar] [CrossRef]
- Fiori, A.M.; Porro, F. A compositional analysis of systemic risk in European financial institutions. Ann. Financ. 2023, 19, 1–30. [Google Scholar] [CrossRef]
- Boonen, T.J.; Guillen, M.; Santolino, M. Forecasting compositional risk allocations. Insur. Math. Econ. 2019, 84, 79–86. [Google Scholar] [CrossRef] [Green Version]
- Grifoll, M.; Ortego, M.; Egozcue, J. Compositional data techniques for the analysis of the container traffic share in a multi-port region. Eur. Transp. Res. Rev. 2019, 11, 1–15. [Google Scholar] [CrossRef]
- Linares-Mustarós, S.; Coenders, G.; Vives-Mestres, M. Financial performance and distress profiles. From classification according to financial ratios to compositional classification. Adv. Account. 2018, 40, 1–10. [Google Scholar] [CrossRef]
- Acharya, V.; Engle, R.; Richardson, M. Capital shortfall: A new approach to ranking and regulating systemic risks. Am. Econ. Rev. 2012, 102, 59–64. [Google Scholar] [CrossRef] [Green Version]
- Acharya, V.V.; Richardson, M.P. (Eds.) Restoring Financial Stability: How to Repair a Failed System; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2009; Volume 542. [Google Scholar]
- Engle, R. Systemic risk 10 years later. Annu. Rev. Financ. Econ. 2018, 10, 125–152. [Google Scholar] [CrossRef]
- Stolbov, M.; Shchepeleva, M. Systemic risk in Europe: Deciphering leading measures, common patterns and real effects. Ann. Financ. 2018, 14, 49–91. [Google Scholar] [CrossRef]
- Engle, R.; Jondeau, E.; Rockinger, M. Systemic risk in Europe. Rev. Financ. 2015, 19, 145–190. [Google Scholar] [CrossRef]
- Aitchison, J. The Statistical Analysis of Compositional Data; Monographs on Statistics and Applied Probability; Chapman & Hall: London, UK, 1986; p. xvi+416. [Google Scholar] [CrossRef]
- Naudts, J. Generalised exponential families and associated entropy functions. Entropy 2008, 10, 131–149. [Google Scholar] [CrossRef] [Green Version]
- Pistone, G.; Riccomagno, E.; Wynn, H.P. Algebraic Statistics: Computational Commutative Algebra in Statistics; Monographs on Statistics and Applied Probability; Chapman & Hall/CRC: Boca Raton, FL, USA, 2001; Volume 89, p. xvii+160. [Google Scholar]
- Montrucchio, L.; Pistone, G. A Class of Non-parametric Deformed Exponential Statistical Models. In Geometric Structures of Information; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 15–35. [Google Scholar] [CrossRef] [Green Version]
- Pistone, G. Information Geometry of the Probability Simplex: A Short Course. Nonlinear Phenom. Complex Syst. 2020, 23, 221–242. [Google Scholar] [CrossRef]
- Kaniadakis, G. Statistical mechanics in the context of special relativity. II. Phys. Rev. E 2005, 72, 036108. [Google Scholar] [CrossRef] [Green Version]
- Kaniadakis, G. Statistical mechanics in the context of special relativity. Phys. Rev. E 2002, 66, 056125. [Google Scholar] [CrossRef] [Green Version]
- Montrucchio, L.; Pistone, G. Deformed Exponential Bundle: The Linear Growth Case. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 239–246. [Google Scholar] [CrossRef]
- Weyl, H. Space—Time—Matter; Dover: New York, NY, USA, 1952; (Translation of the 1921 RAUM ZEIT MATERIE). [Google Scholar]
- Berger, M. Geometry I; Universitext; Springer: Berlin, Germany, 1994; p. xiv+427, (Translated from the 1977 French original by M. Cole and S. Levy, Corrected reprint of the 1987 translation). [Google Scholar]
- Pistone, G. Lagrangian Function on the Finite State Space Statistical Bundle. Entropy 2018, 20, 139. [Google Scholar] [CrossRef] [PubMed]
- Chirco, G.; Malagò, L.; Pistone, G. Lagrangian and Hamiltonian dynamics for probabilities on the statistical bundle. Int. J. Geom. Methods Mod. Phys. 2022, 19, 2250214. [Google Scholar] [CrossRef]
- Eguchi, S. Second order efficiency of minimum contrast estimators in a curved exponential family. Ann. Statist. 1983, 11, 793–803. [Google Scholar] [CrossRef]
Figure 1.
Kaniadakis divergence on compositional data.

Figure 2.
(A) Mixture displacement on compositional data by taking 2008 as a reference and (B) mixture displacement on compositional data by taking mean as reference.
Figure 2.
(A) Mixture displacement on compositional data by taking 2008 as a reference and (B) mixture displacement on compositional data by taking mean as reference.

Figure 3.
(A) Exponential displacement on compositional data by taking 2008 as a reference and (B) exponential displacement on compositional data by taking mean as a reference.
Figure 3.
(A) Exponential displacement on compositional data by taking 2008 as a reference and (B) exponential displacement on compositional data by taking mean as a reference.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pistone, G.; Shoaib, M. Kaniadakis’s Information Geometry of Compositional Data. Entropy 2023, 25, 1107. https://doi.org/10.3390/e25071107
AMA Style
Pistone G, Shoaib M. Kaniadakis’s Information Geometry of Compositional Data. Entropy. 2023; 25(7):1107. https://doi.org/10.3390/e25071107
Chicago/Turabian StylePistone, Giovanni, and Muhammad Shoaib. 2023. "Kaniadakis’s Information Geometry of Compositional Data" Entropy 25, no. 7: 1107. https://doi.org/10.3390/e25071107
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.