In this section, we first implement our SQSLSR and HQSLSR on five artificial datasets to show their geometric meaning and compare them with LSR and DLSR. We also carry out our SQSLSR and HQSLSR on 16 UCI benchmark datasets, and compare their accuracy with LSR, DLSR, LRDLSR, WCSDLSR, linear discriminant analysis(LDA), QSSVM, reg-LSDWPTSVM [
22], SVM, and KRR. For convenience, SVMs with a linear kernel and rbf kernel are denoted by SVM-L and SVM-R, respectively. KRRs with an RBF kernel and polynomial kernel are denoted as KRR-R and KRR-P, respectively. Remarkably, on multi-class classification datasets, the SVM and QSSVM methods use the one-against-rest strategy [
30]. We adopt the five-fold cross-validation to select the parameters in these methods. The regularization parameters of SQSLSR and other methods are selected from the set
. The parameters of the RBF kernel and polynomial kernel are selected from the set
. All numerical experiments are executed using MATLAB R2020(b) on a computer with a 2.80 GHz (I7-1165G7) CPU and 16 G available memory.
5.1. Experimental Results on Artificial Datasets
We construct five artificial datasets to demonstrate the geometric meaning of our methods and the advantage of the -dragging technique. Datasets I-IV are binary classifications, where each dataset contains 300 points, and each class has 150 points. Dataset V has three classifications, and each class has 20 points. As the decision functions of our proposed HQSLSR and SQSLSR methods, as well as the comparison methods LSR and DLSR, are all composed of K regression functions, we present K pairs of regression curves to display their classification results. Here, is the regression curve of the k-th class, is the regression curve of samples other than class k, k = 1, 2.
The first-class samples, and are indicated by the blue “+”, blue line and blue dotted line, respectively. The second-class samples, and are represented by the red “∘”, red line and red dotted line, respectively. The accuracy of each method on the artificial dataset is shown in the top right corner.
The artificial dataset I is linearly separable.
Figure 1 shows the results of the four methods, including LSR, DLSR, HQSLSR, and SQSLSR. It can be observed that
and
coincide;
and
coincide too. The samples of each class come close to the corresponding regression curve, and stay away from the regression curves of the other classes. In addition, the four methods can correctly classify the samples on this linear separable artificial dataset I.
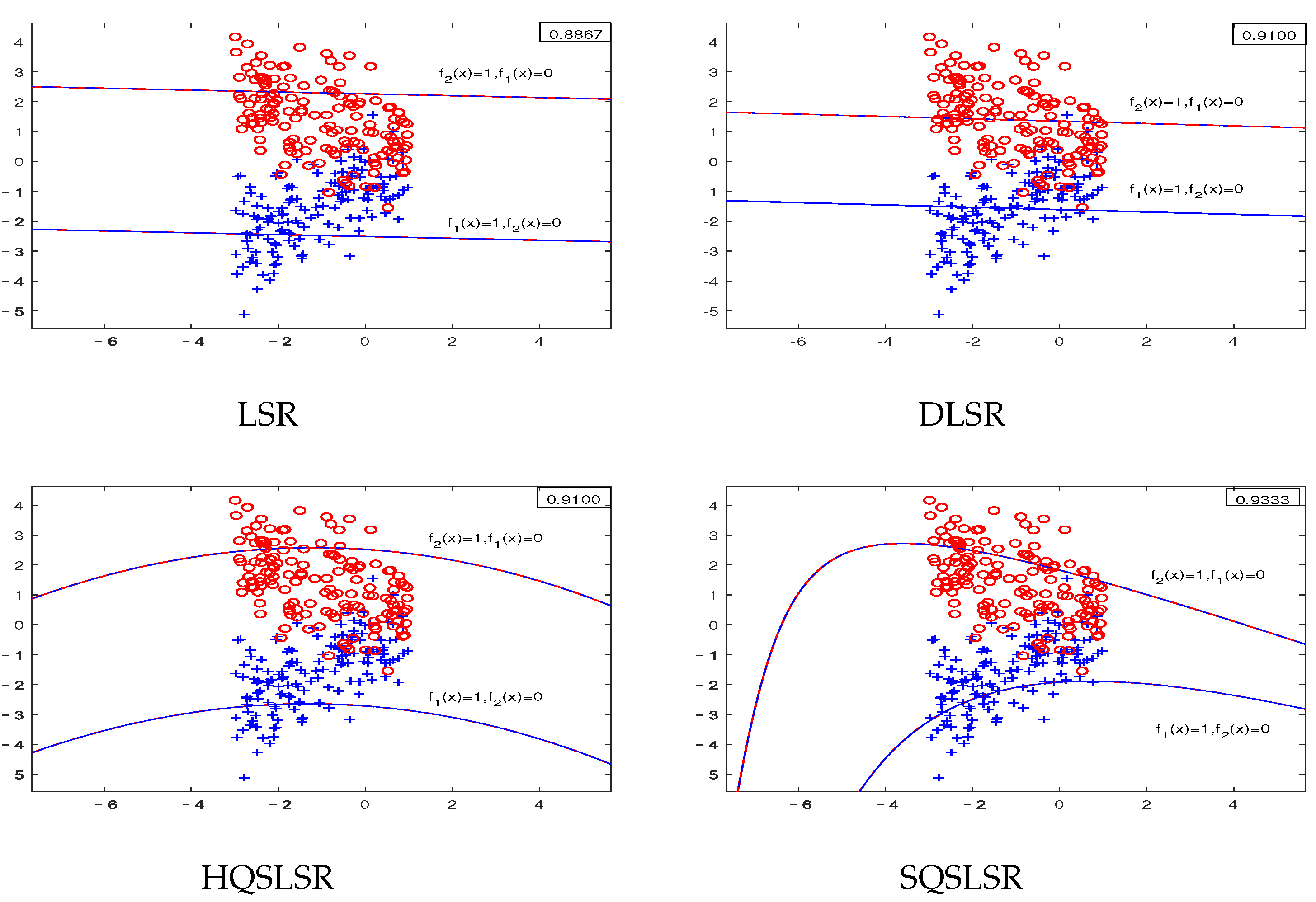
As shown in
Figure 2, the artificial dataset II includes some intersecting samples. Our methods outperform LSR and DLSR in terms of classification accuracy, because our HQSLSR and SQSLSR can obtain two pairs of regression curves, while LSR and DLSR can only obtain two pairs of straight regression lines. It is worth noting that the accuracy of SQSLSR is slightly higher than that of HQSLSR, because the SQSLSR uses the
-dragging technique to relax the binary labels into continuous real values, which enlarges the distances between different classes and makes the discrimination better.
Figure 3 shows the visualization results of the artificial dataset III, which is sampled from two parabolas. Note that our HQSLSR and SQSLSR can obtain parabolic-type regression curves while LSR and DLSR can only obtain straight regression lines, so our methods are more suitable for this nonlinearly separable dataset.
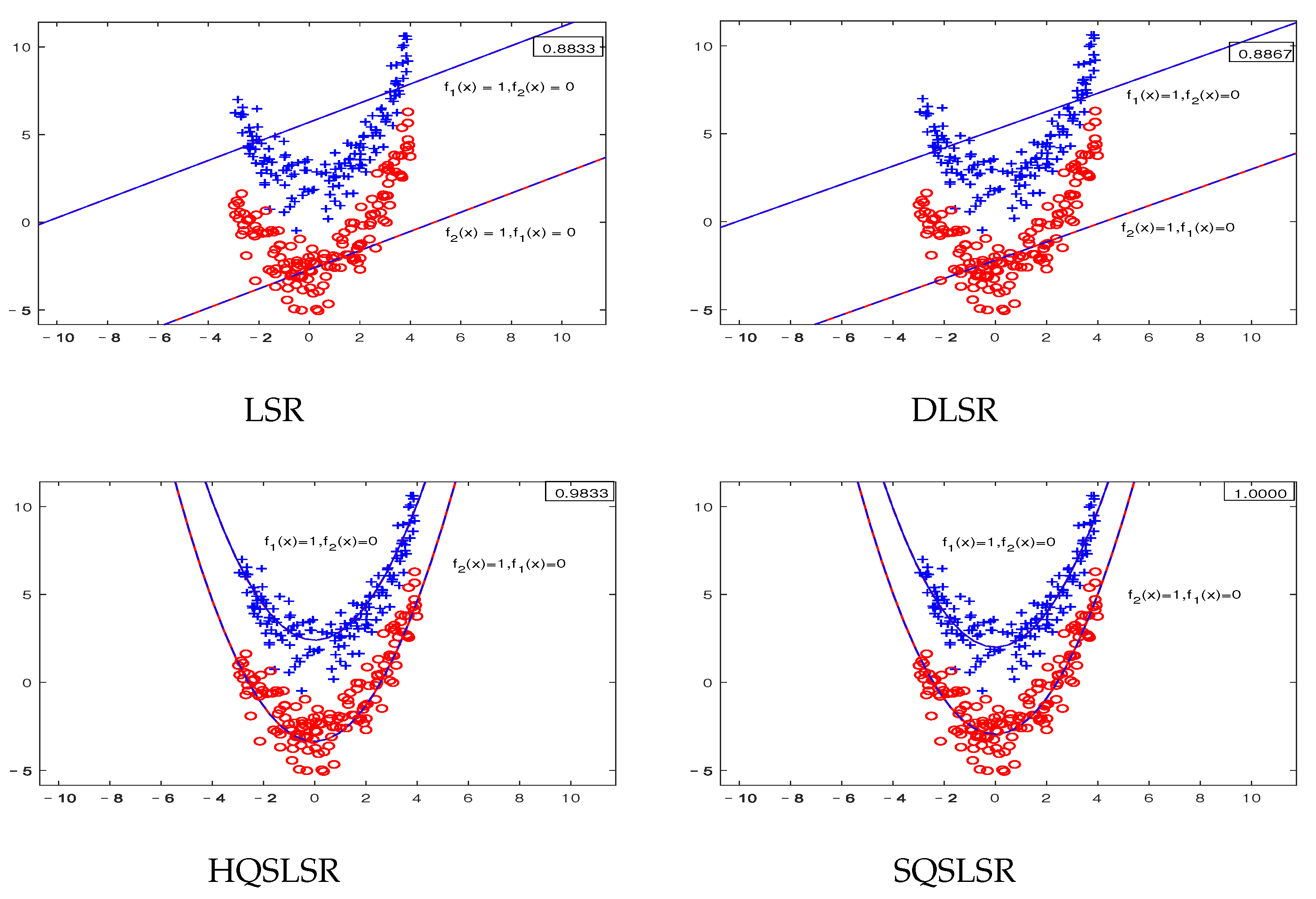
The results of the artificial dataset IV are shown in
Figure 4. The nonlinearly separable dataset IV is obtained by sampling from two concentric circles. Obviously, our HQSLSR and SQSLSR have higher accuracy for this classification task, as shown in
Figure 4. However, from the first two subfigures, it is not difficult to find that samples of these two classes are far away from their respective regression curves, resulting in poor results of LSR and DLSR. Note that
and
coincide and lie at the center of the concentric circles, which are not easy to observe. Thus we only display
and
, as shown in last two subfigures.
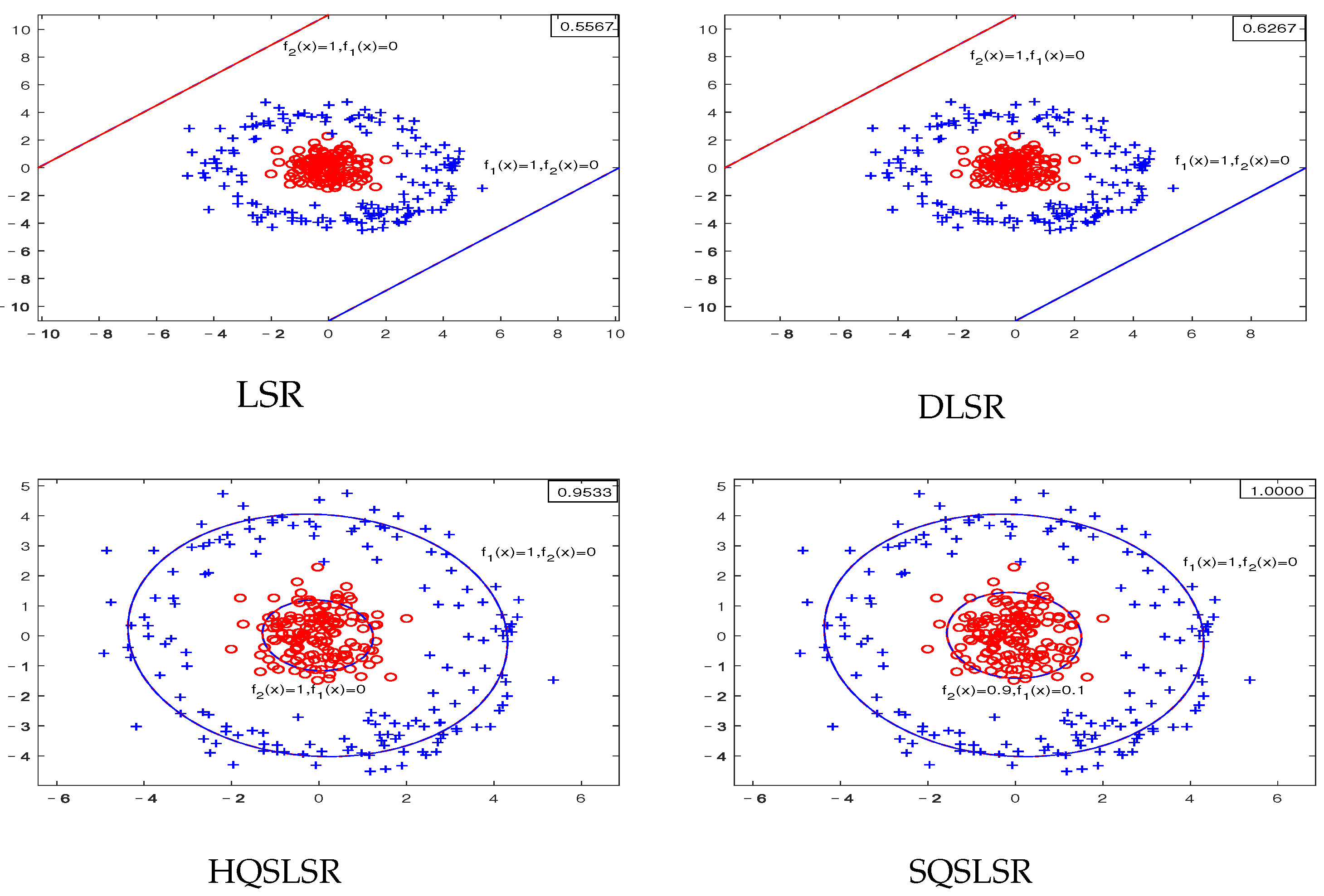
We conducted experiments on the artificial dataset V to investigate the influence of the
-dragging technique. The dataset consists of 60 samples from three classes, with 20 samples from each class arranged in three groups: left, middle, and right. By solving the optimization problems of HQSLSR (
15) and SQSLSR (
23) on dataset V, we obtained the corresponding regression labels
and
, where
represent the three regression functions solved by HQSLSR and SQSLSR, respectively. The difference caused by the
-dragging technique is represented by
, which includes three components related to the corresponding three classes.
Figure 5 illustrates the relationship between the index of training samples and the three components of the difference
.
According to the results presented in
Figure 5b, the first component of the difference matrix
exhibits positive values for the first 20 samples, while negative values are observed for the last 40 samples. This observation suggests that the introduction of the
-dragging technique has effectively increased the gap in the first component of the difference matrix
between the first class and the remaining classes. Additionally,
Figure 5c,d demonstrate that the second and third components of the difference matrix
highlight the second and third classes of samples, respectively. Therefore, the
-dragging technique has successfully enlarged the differences in regression labels among samples from different classes, thereby enhancing the robustness of the model.
Based on the experimental results presented above, it can be concluded that the regression curve should be close to the samples from the k-th class while being distant from the samples of other classes. The K pairs of regression curves can be modeled as arbitrary quadratic surfaces in the plane. This approach enables HQSLSR and its softened version (SQSLSR) to achieve higher accuracy. SQSLSR utilizes the -dragging technique to relax the labels, which forces the regression labels of different classes to move in opposite directions, thereby increasing the distances between classes. Consequently, SQSLSR exhibits better discriminative ability than HQSLSR.
5.2. Experimental Results on Benchmark Datasets
In order to validate the performances of our HQSLSR and SQSLSR, we compare them with linear methods LSR, DLSR, LDA, SVM-L, LRDLSR, WCSDLSR, and nonlinear methods QSSVM, SVM-R, KRR-R, KRR-P, and reg-LSDWPTSVM. These methods are implemented on 16 UCI benchmark datasets. Numerical results are obtained by repeating five-fold cross-validation five times, including average accuracy (Acc), standard deviation (Std), and computing time (Time). The best results are highlighted in boldface. Lastly, we also calculated the sensitivity and specificity of each method on six datasets to further evaluate their classification performances.
Table 1 summarizes the basic information about the 16 UCI benchmark datasets, which are taken from the website
https://archive.ics.uci.edu/ml/index.php (the above datasets accessed on 18 August 2021).
In
Table 2, we show the experimental results of the above 13 methods on the 16 benchmark datasets. It is obvious from
Table 2 that our HQSLSR and SQSLSR outperform linear methods LSR, LDA, DLSR, LRDLSR, WCSDLSR, and SVM-L in terms of classification accuracy on almost all datasets. Moreover, the accuracy of our HQSLSR and SQSLSR are similar to other nonlinear classification methods: SVM-R, SVM-P, KRR-R, KRR-P, QSSVM, and reg-LSDWPTSVM. Note that our SQSLSR has the highest classification accuracy on most datasets. In addition, in terms of computation time, our methods not only have less time cost than the compared nonlinear methods, but also have a narrow gap with the fastest linear method LSR. In general, our HQSLSR and SQSLSR can achieve higher accuracy without increasing the time cost too much, and the generalization ability of SQSLSR in particular is better.
To further evaluate the classification performances of these 13 methods, we show the specificity and sensitivity of the 13 methods on the datasets in
Table 3. It can be seen from
Table 3, our HQSLSR and SQSLSR perform well in terms of specificity and sensitivity on most of the benchmark datasets.
5.4. Statistical Analysis
In this subsection, we use the Friedman test [
31] and the Neymani test [
32] to further illustrate the differences between our two methods and other methods.
First, we carry out the Friedman test, where the original hypothesis is that all methods have the same classification accuracy and computation time. We ranked these 13 methods based on their accuracy and computation time on the 16 benchmark datasets and presented the average rank
for each algorithm in
Table 4 and
Table 5. Let
N and
s denote the number of datasets and algorithms, respectively. The relevant statistics are obtained by
where
follows an
F-distribution with degrees of freedom
and
. According to Equation (
35), we obtain two Friedman statistics
, which are
and
, and the critical value corresponding to
is
. Since
, we reject the original hypothesis.
Rejection of the original hypothesis suggests that our HQSLSR, SQSLSR, and other methods perform differently in terms of accuracy and computation time. To further distinguish these methods in terms of classification accuracy and computation time, a Nemenyi test is further adopted, and the critical difference is calculated with the following equation:
when
,
, we obtain
by Equation (
36).
Figure 7 and
Figure 8 visually display the results of the Friedman test and the Nemenyi post hoc test. The average rank of each method is marked along the axis. Groups of methods that are not significantly different are connected by red lines.
On the one hand, our methods HQSLSR and SQSLSR are not very different from SVM-R, KRR-R, and KRR-P and are significantly better than LSR, DLSR, LDA, SVM-L, and QSSVM in terms of classification accuracy. On the other hand, our methods HQSLSR and SQSLSR are not very different from LSR, DLSR, and LDA and are significantly better than WCSDLSR, KRR-R, KRR-P, SVM-L, reg-LSDWPTSVM, SVM-R, and QSSVM in terms of computation time. In general, our HQSLSR and SQSLSR can achieve higher accuracy while maintaining relatively small computation time.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}