
Multi-Focus Image Fusion for Full-Field Optical Angiography

Abstract
:1. Introduction
- (1)
- An FFOA imaging system based on the absorption intensity fluctuation modulation effect was constructed to obtain multi-focus source images;
- (2)
- A novel FFOA image fusion method based on SR and CSF in the NSCT domain was developed. A contrast-based rule is proposed to fuse bandpass images, which can effectively detect the structural information of FFOA images;
- (3)
- The proposed method can effectively extend the depth of field of FFOA images and address the partial defocus problem of FFOA images caused by uneven surfaces and the varying thicknesses of biological samples. At the same time, it can also be extended to the public data sets and surpasses some state-of-the-art approaches in terms of subjective and objective evaluations.
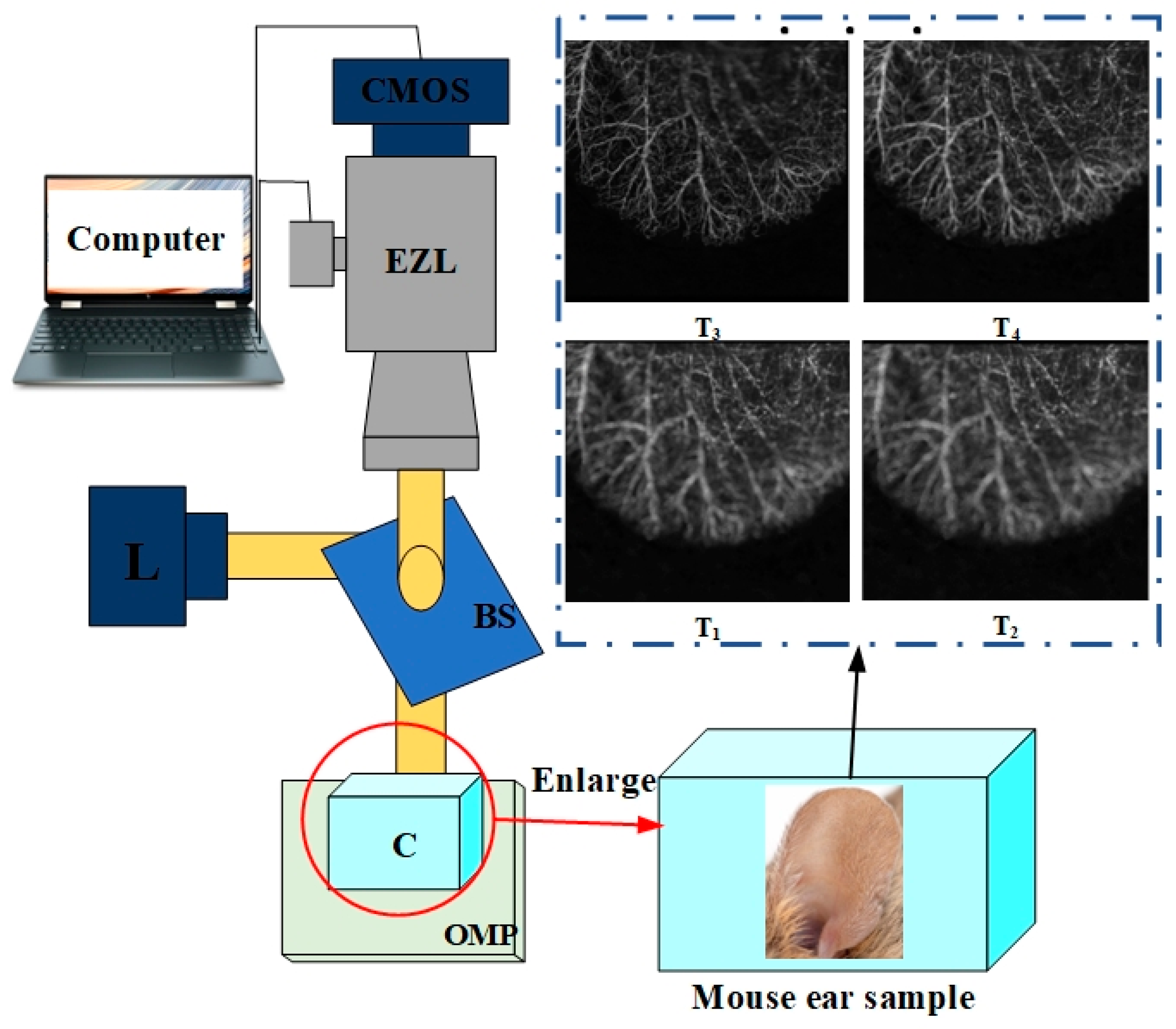
2. Proposed Imaging System
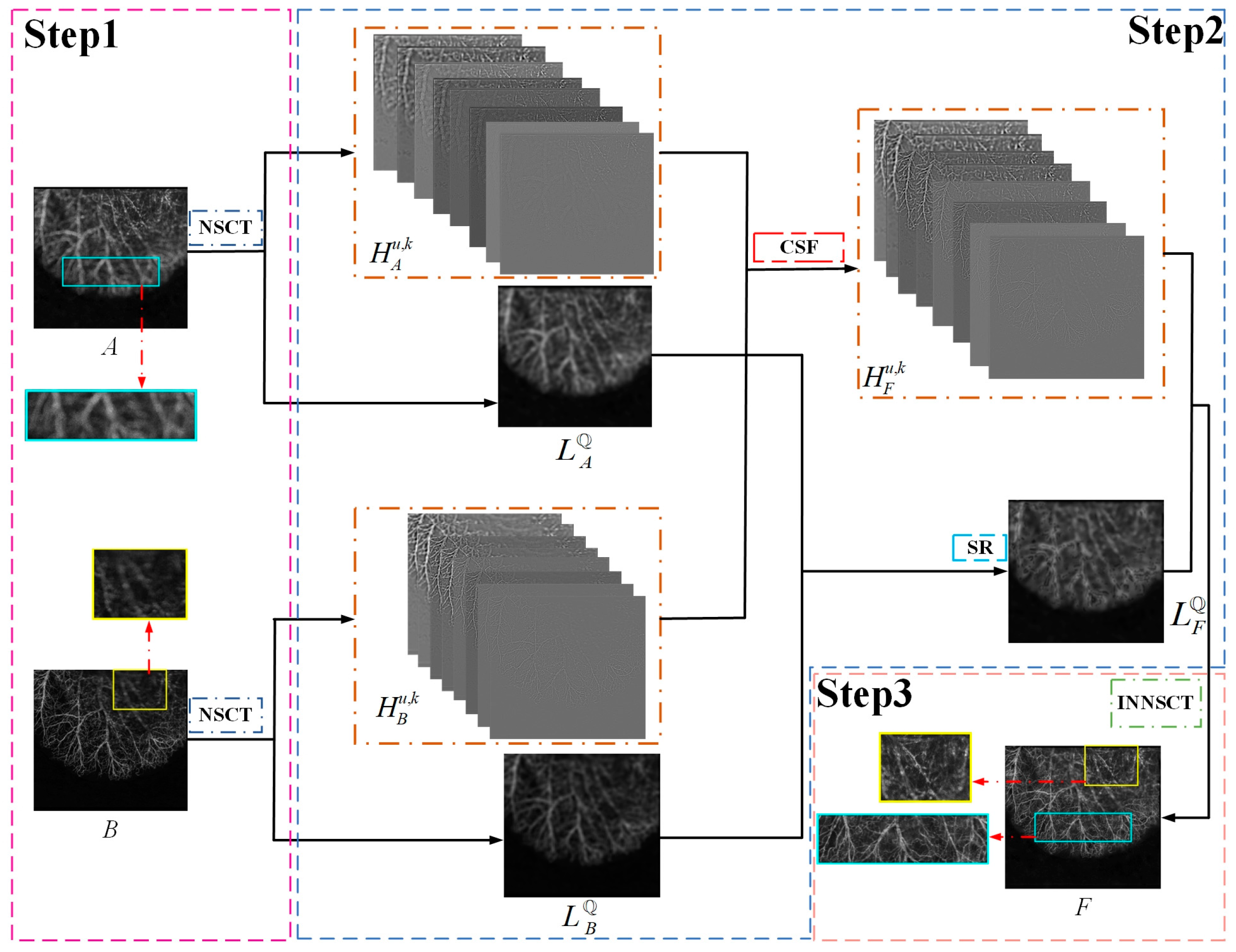
3. Proposed FFOA Fusion Model
3.1. Fusion of Low-Pass Images
- Step a: Block extraction and vectorization
- Step b: Sparse coding
- Step c: Sparse reconstruction
3.2. Fusion of Bandpass Images
3.3. Image Reconstruction
4. Experiments
4.1. Experimental Setup
4.1.1. Testing Images
4.1.2. Compared Methods
- (1)
- Adaptive and gradient joint constraint-based methods (MFF-GAN) [17];
- (2)
- Unified unsupervised network-based methods (U2Fusion) [18];
- (3)
- Swin transformer-based method (SwinFusion) [19];
- (4)
- Simultaneous convolutional sparse approximation-based methods (CSSA) [41];
- (5)
- Nonsubsampled contourlet transform (NSCT-SR) [13];
- (6)
- Contrast pyramid fusion algorithm (CPFA) [34].
4.1.3. Testing Platform
4.1.4. Quantitative Evaluation Metrics
4.2. Discussion of Parameter Selection
4.3. Fusion Results and Discussion
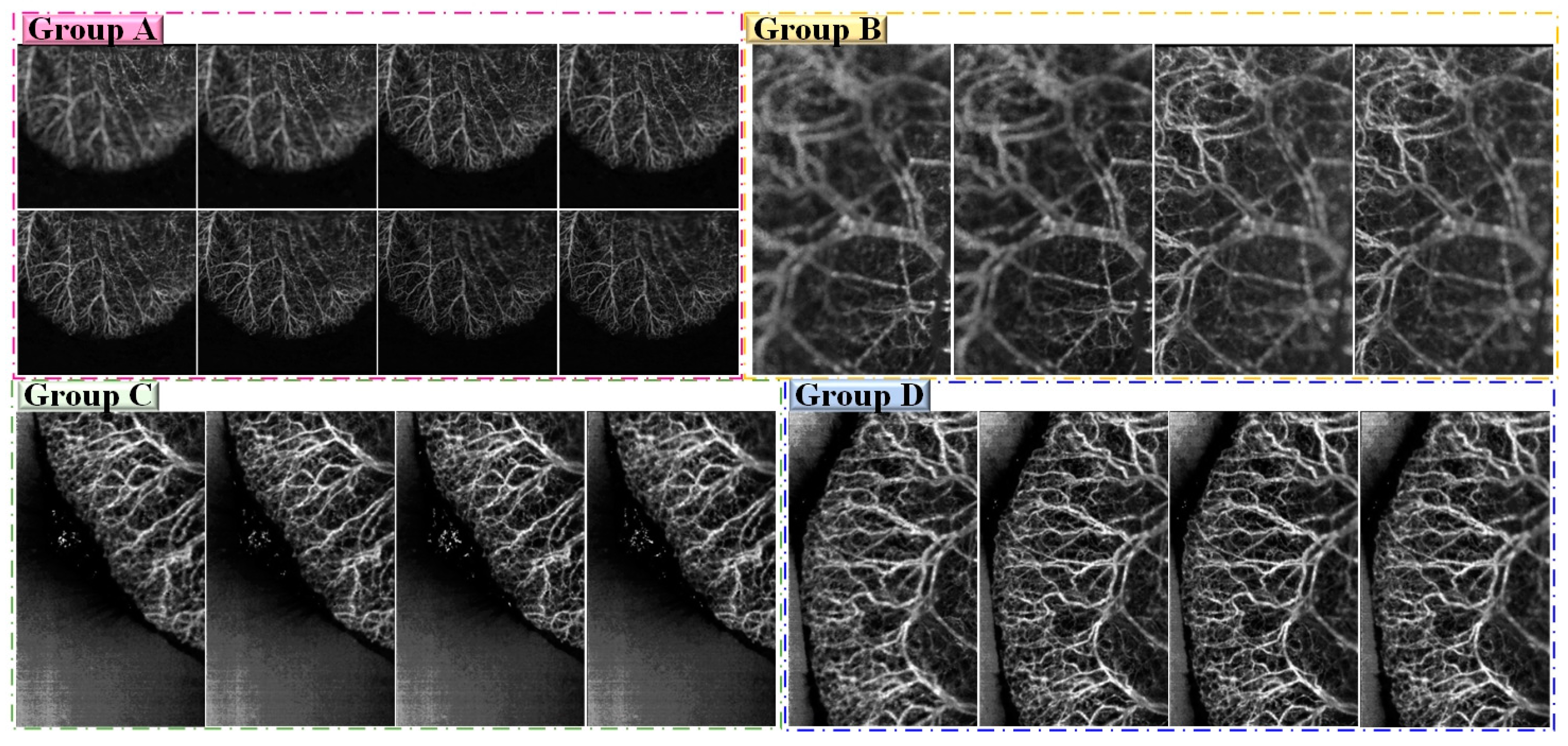
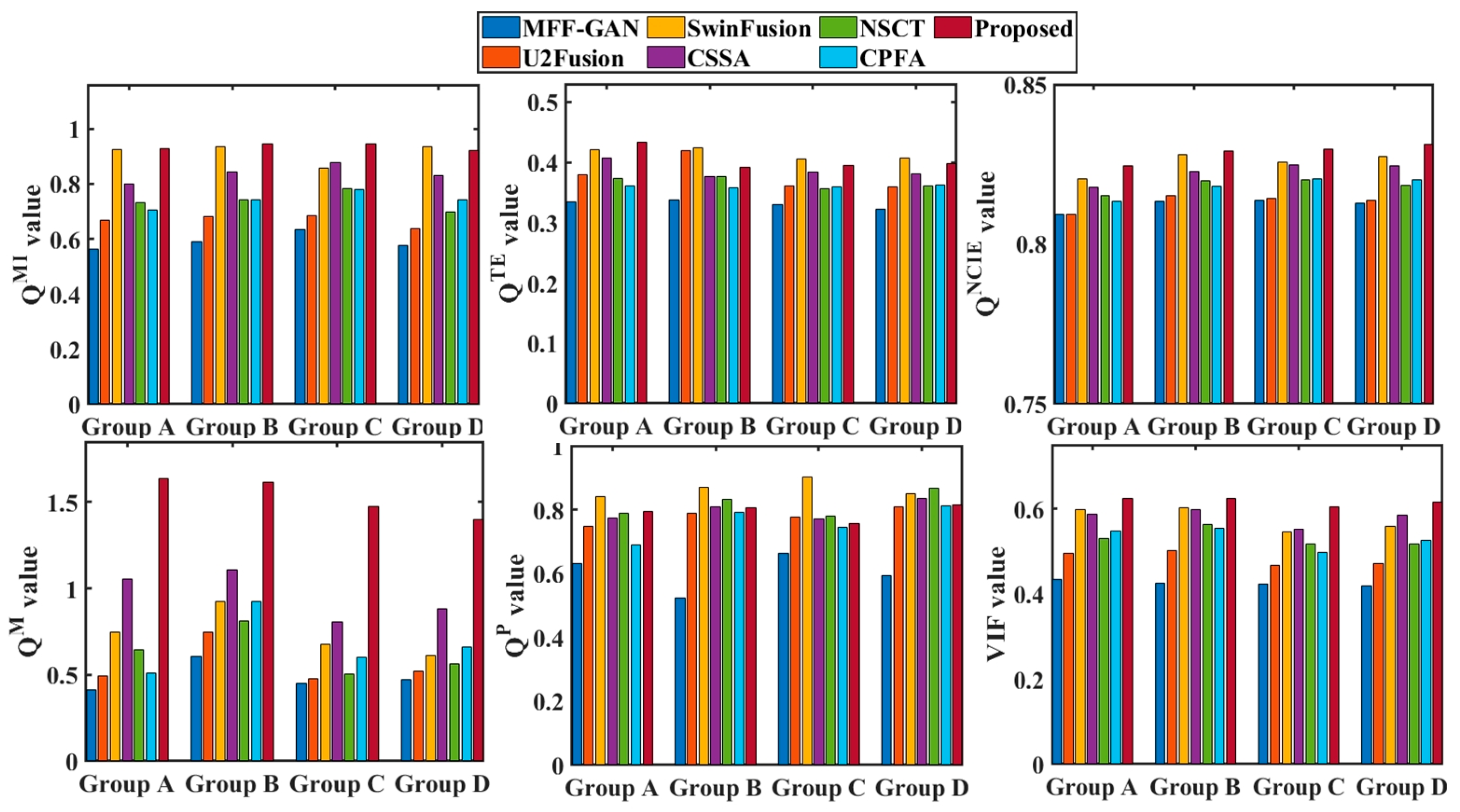
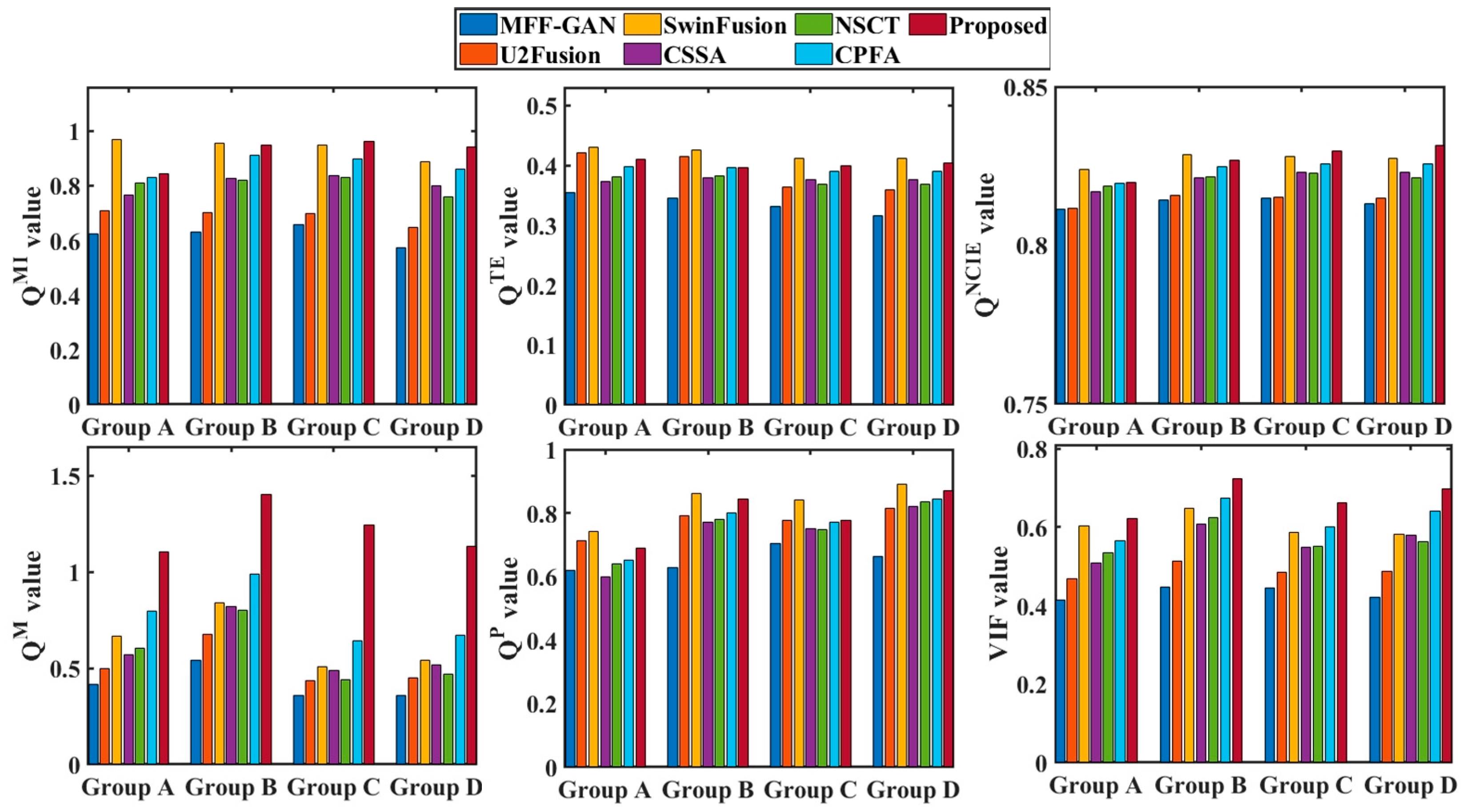
4.3.1. Subjective Evaluation
4.3.2. Objective Evaluation
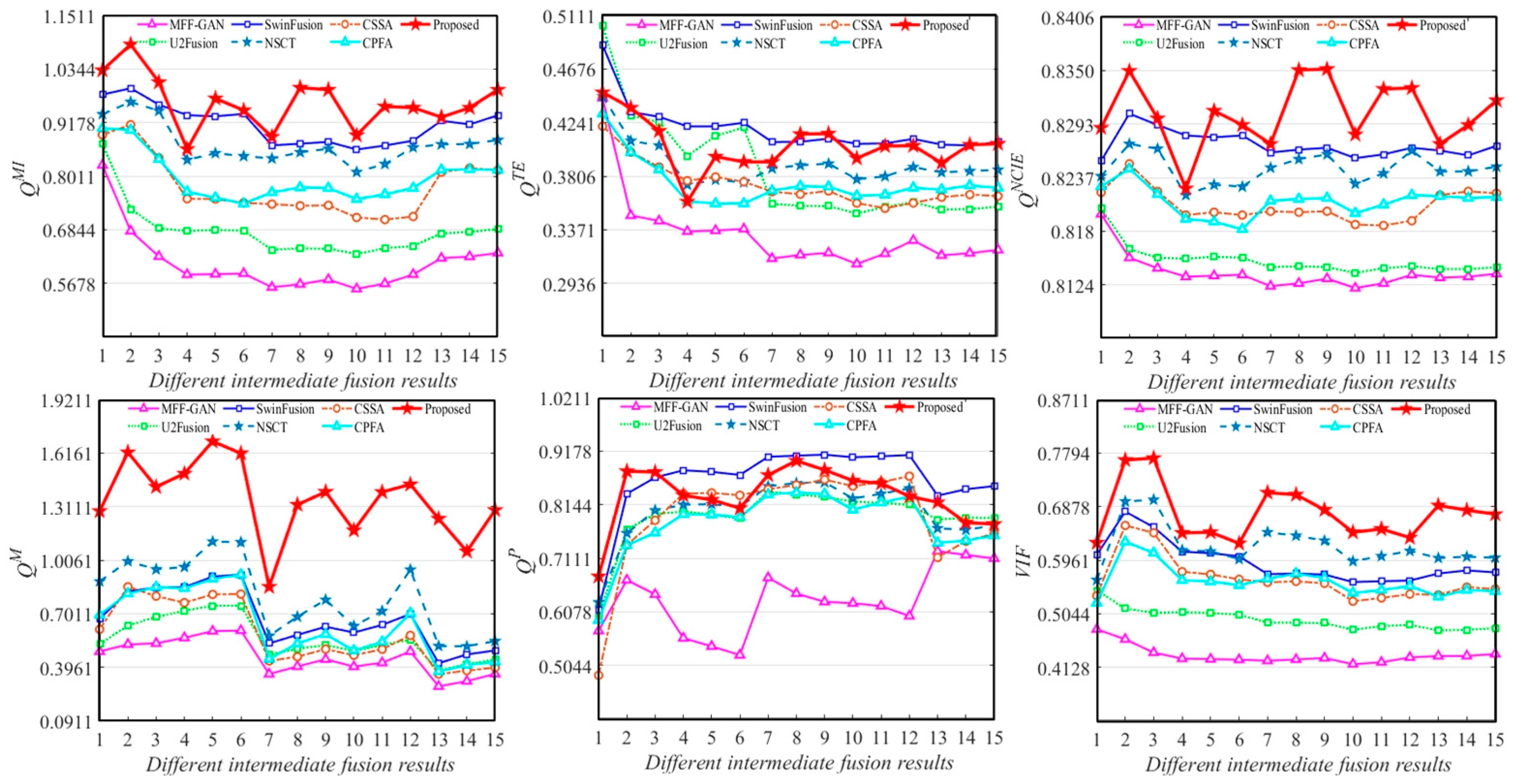
4.4. Extended to More Public Datasets
4.5. Computational Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miao, P.; Lin, X.J.; Feng, S.H.; Xie, B.H.; Zhang, Q.; Liu, C.W.; Yang, G.Y. In-vivo brain blood flow imaging based on laser speckle contrast imaging and synchrotron radiation microangiography. Laser Phys. 2014, 24, 085603. [Google Scholar] [CrossRef]
- Provost, J.; Papadacci, C.; Demene, C.; Gennisson, J.L.; Tanter, M.; Pernot, M. 3-D Ultrafast Doppler Imaging Applied to the Noninvasive Mapping of Blood Vessels In Vivo. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2015, 62, 1467–1472. [Google Scholar] [CrossRef] [PubMed]
- Dubois, A.; Grieve, K.; Moneron, G.; Lecaque, R.; Vabre, L.; Boccara, C. Ultrahigh-resolution full-field optical coherence tomography. Appl. Opt. 2004, 43, 2874–2883. [Google Scholar] [CrossRef] [PubMed]
- Li, X.L.; Wang, X.P.; Cheng, X.Q.; Tan, H.S.; Li, X.S. Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection. Entropy 2022, 24, 1527. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, L.; Li, H.F.; Chen, X. Multi-focus image fusion with deep residual learning and focus property detection. Inf. Fusion 2022, 86–87, 1–16. [Google Scholar] [CrossRef]
- Li, H.F.; He, X.G.; Tao, D.P.; Tang, Y.Y.; Wang, R.X. Joint medical image fusion, denoising and enhancement via discriminative low-rank sparse dictionaries learning. Pattern Recognit. 2018, 79, 130–146. [Google Scholar] [CrossRef]
- Li, X.S.; Zhou, F.Q.; Tan, H.S.; Chen, Y.Z.; Zuo, W.X. Multi-focus image fusion based on nonsubsampled contourlet transform and residual removal. Signal Process. 2021, 184, 108062. [Google Scholar] [CrossRef]
- Li, H.F.; Wang, Y.T.; Yang, Z.; Wang, R.X.; Li, X.; Tao, D.P. Discriminative Dictionary Learning-Based Multiple Component Decomposition for Detail-Preserving Noisy Image Fusion. IEEE Trans. Instrum. Meas. 2020, 69, 1082–1102. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Zhao, P.; Ma, Y.Z.; Fan, X.L. Multi-focus image fusion with joint guided image filtering. Signal Process.-Image Commun. 2021, 92, 116128. [Google Scholar] [CrossRef]
- Ma, J.L.; Zhou, Z.Q.; Wang, B.; Miao, L.J.; Zong, H. Multi-focus image fusion using boosted random walks-based algorithm with two-scale focus maps. Neurocomputing 2019, 335, 9–20. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.F. A novel multi-focus image fusion method using multiscale shearing non-local guided averaging filter. Signal Process. 2020, 166, 107252. [Google Scholar] [CrossRef]
- Chen, X.; Liu, L.; Kong, X.Y. The fusion of infrared and visible images via decomposition-based structure transfer and local saliency detection. Opt. Laser Technol. 2022, 149, 107787. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.P.; Wang, Z.F. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Xiao, B.; Ou, G.; Tang, H.; Bi, X.L.; Li, W.S. Multi-Focus Image Fusion by Hessian Matrix Based Decomposition. IEEE Trans. Multimed. 2020, 22, 285–297. [Google Scholar] [CrossRef]
- Li, G.F.; Lai, W.J.; Qu, X.D. Pedestrian detection based on light perception fusion of visible and thermal images. Opt. Laser Technol. 2022, 156, 108466. [Google Scholar] [CrossRef]
- Amin-Naji, M.; Aghagolzadeh, A.; Ezoji, M. Ensemble of CNN for multi-focus image fusion. Inf. Fusion 2019, 51, 201–214. [Google Scholar] [CrossRef]
- Zhang, H.; Le, Z.L.; Shao, Z.F.; Xu, H.; Ma, J.Y. MFF-GAN: An unsupervised generative adversarial network with adaptive and gradient joint constraints for multi-focus image fusion. Inf. Fusion 2021, 66, 40–53. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.Y.; Jiang, J.J.; Guo, X.J.; Ling, H.B. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Ma, J.Y.; Tang, L.F.; Fan, F.; Huang, J.; Mei, X.G.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Xing, C.D.; Wang, M.L.; Dong, C.; Duan, C.W.; Wang, Z.S. Using Taylor Expansion and Convolutional Sparse Representation for Image Fusion. Neurocomputing 2020, 402, 437–455. [Google Scholar] [CrossRef]
- Li, H.; Yang, M.; Yu, Z. Joint image fusion and super-resolution for enhanced visualization via semi-coupled discriminative dictionary learning and advantage embedding. Neurocomputing 2021, 422, 62–84. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.; Zhu, R.; Wang, Z.; Feng, Y.; Zhang, X. A multi-focus image fusion framework based on multi-scale sparse representation in gradient domain. Signal Process. 2021, 189, 108254. [Google Scholar] [CrossRef]
- Li, H.F.; Xu, J.J.; Yu, Z.T.; Luo, J.B. Jointly Learning Commonality and Specificity Dictionaries for Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 7345–7358. [Google Scholar] [CrossRef]
- Li, X.S.; Zhou, F.Q.; Tan, H.S. Joint image fusion and denoising via three-layer decomposition and sparse representation. Knowl.-Based Syst. 2021, 224, 107087. [Google Scholar] [CrossRef]
- Jie, Y.; Li, X.; Zhou, F.; Tan, H. Medical image fusion based on extended difference-of-Gaussians and edge-preserving. Expert Syst. Appl. 2023, 227, 120301. [Google Scholar] [CrossRef]
- Li, H.F.; Liu, X.K.; Yu, Z.T.; Zhang, Y.F. Performance improvement scheme of multifocus image fusion derived by difference images. Signal Process. 2016, 128, 474–493. [Google Scholar] [CrossRef]
- Li, X.S.; Zhou, F.Q.; Tan, H.S.; Zhang, W.N.; Zhao, C.Y. Multimodal medical image fusion based on joint bilateral filter and local gradient energy. Inf. Sci. 2021, 569, 302–325. [Google Scholar] [CrossRef]
- Yin, M.; Liu, X.N.; Liu, Y.; Chen, X. Medical Image Fusion With Parameter-Adaptive Pulse Coupled Neural Network in Nonsubsampled Shearlet Transform Domain. IEEE Trans. Instrum. Meas. 2019, 68, 49–64. [Google Scholar] [CrossRef]
- Li, X.; Tan, H.; Zhou, F.; Wang, G.; Li, X. Infrared and visible image fusion based on domain transform filtering and sparse representation. Infrared Phys. Technol. 2023, 131, 104701. [Google Scholar] [CrossRef]
- Jie, Y.; Zhou, F.; Tan, H.; Wang, G.; Cheng, X.; Li, X. Tri-modal medical image fusion based on adaptive energy choosing scheme and sparse representation. Measurement 2022, 204, 112038. [Google Scholar] [CrossRef]
- Li, X.S.; Wan, W.J.; Zhou, F.Q.; Cheng, X.Q.; Jie, Y.C.; Tan, H.S. Medical image fusion based on sparse representation and neighbor energy activity. Biomed. Signal Process. Control 2023, 80, 104353. [Google Scholar] [CrossRef]
- Li, J.; Han, D.; Wang, X.; Yi, P.; Yan, L.; Li, X. Multi-Sensor Medical-Image Fusion Technique Based on Embedding Bilateral Filter in Least Squares and Salient Detection. Sensors 2023, 23, 3490. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Guo, B.L. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process. 2009, 89, 1334–1346. [Google Scholar] [CrossRef]
- Wang, M.Y.; Wu, N.S.; Huang, H.H.; Luo, J.X.; Lan, G.P.; Zeng, Y.G.; Wang, X.H.; Xiong, H.L.; Han, D.G.; Tan, H.S. Large-depth-of-field full-field optical angiography. J. Biophotonics 2019, 12, e201800329. [Google Scholar] [CrossRef] [PubMed]
- Li, H.F.; Zhou, W.Y.; Yu, Z.T.; Yang, B.; Jin, H.P. Person re-identification with dictionary learning regularized by stretching regularization and label consistency constraint. Neurocomputing 2020, 379, 356–369. [Google Scholar] [CrossRef]
- Pati, Y.; Rezaiifar, R.; Krishnaprasad, P. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; Volume 1, pp. 1–3. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Zhu, Z.Q.; He, X.Y.; Qi, G.Q.; Li, Y.Y.; Cong, B.S.; Liu, Y. Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z.F. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Cvejic, N.; Canagarajah, C.N.; Bull, D.R. Image fusion metric based on mutual information and Tsallis entropy. Electron. Lett. 2006, 42, 626–627. [Google Scholar] [CrossRef]
- Veshki, F.G.; Vorobyov, S.A. Convolutional Simultaneous Sparse Approximation with Applications to RGB-NIR Image Fusion. arXiv 2022, arXiv:2203,09913. [Google Scholar]
- Wang, Q.; Shen, Y.; Jin, J. Performance evaluation of image fusion techniques. Image Fusion Algorithms Appl. 2008, 19, 469–492. [Google Scholar]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.-w.; Liu, B. A novel image fusion metric based on multi-scale analysis. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; pp. 965–968. [Google Scholar]
- Zhao, J.Y.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control 2007, 3, 1433–1447. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Blasch, E.; Xue, Z.Y.; Zhao, J.Y.; Laganiere, R.; Wu, W. Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision: A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94–109. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Methods | References |
|---|---|---|
| Spatial domain-based methods | Scheme based on difference-of-Gaussians | [25] |
| Joint guided image filtering-based approach | [9] | |
| Random-walk estimation-based method | [10] | |
| Multi-scale shearing nonlocal guided averaging filter-based scheme | [11] | |
| Deep learning-based method | CNN with integrated learning-based scheme | [16] |
| Joint adaptive and gradient constraints-based method | [17] | |
| Unsupervised fusion network-based method | [18] | |
| Swin transformer-based method | [19] | |
| Multi-scale transform-based methods | Hessian matrix-based method | [14] |
| Domain transform filtering-based approach | [29] | |
| Adaptive energy choosing-based scheme | [30] | |
| Neighbor energy activity operator-based scheme | [31] | |
| Embedding bilateral filter in least squares-based method | [32] | |
| NSCT-based method | [13] | |
| Residual removal technique-based approach | [7] | |
| Sparse representation-based methods | Taylor expansion-based approach | [20] |
| Joint fusion and super-resolution scheme | [21] | |
| Multi-scale sparse representation-based image fusion scheme | [22] |
| Metrics | Parameter M | ||||||
| 3 | 5 | 7 | 9 | 11 | 13 | 15 | |
| QMI | 0.9371 | 0.9347 | 0.9393 | 0.9289 | 0.9371 | 0.9371 | 0.9371 |
| QTE | 0.4012 | 0.4007 | 0.4018 | 0.3998 | 0.4012 | 0.4012 | 0.4012 |
| QNCIE | 0.8324 | 0.8323 | 0.8326 | 0.8317 | 0.8324 | 0.8324 | 0.8324 |
| QM | 1.4355 | 1.4309 | 1.4437 | 1.3900 | 1.4355 | 1.4355 | 1.4355 |
| QP | 0.8187 | 0.8180 | 0.8193 | 0.8183 | 0.8187 | 0.8187 | 0.8187 |
| VIF | 0.6179 | 0.6175 | 0.6177 | 0.6159 | 0.6179 | 0.6179 | 0.6179 |
| Metrics | Parameter p | ||||||
| 5 | 7 | 9 | 11 | 13 | 15 | 17 | |
| QMI | 0.9343 | 0.9371 | 0.9343 | 0.9345 | 0.9371 | 0.9371 | 0.9081 |
| QTE | 0.4009 | 0.4012 | 0.4007 | 0.4009 | 0.4012 | 0.4012 | 0.3907 |
| QNCIE | 0.8322 | 0.8324 | 0.8322 | 0.8322 | 0.8324 | 0.8324 | 0.8332 |
| QM | 1.4308 | 1.4355 | 1.4374 | 1.4418 | 1.4396 | 1.4396 | 0.9644 |
| QP | 0.8179 | 0.8187 | 0.8180 | 0.8192 | 0.8189 | 0.8189 | 0.8073 |
| VIF | 0.6187 | 0.6179 | 0.6175 | 0.6176 | 0.6176 | 0.6176 | 0.6176 |
| Metrics | Parameter r | ||||||
| 0.035 | 0.04 | 0.045 | 0.05 | 0.055 | 0.06 | 0.065 | |
| QMI | 0.9124 | 0.9190 | 0.9283 | 0.9350 | 0.9316 | 0.9336 (2) | 0.9333 |
| QTE | 0.3951 | 0.3971 | 0.3987 | 0.4002 (2) | 0.3999 | 0.4001 | 0.4005 |
| QNCIE | 0.8305 | 0.8310 | 0.8318 | 0.8323 | 0.8321 | 0.8322 (2) | 0.8322 (2) |
| QM | 1.3693 | 1.3815 | 1.4052 | 1.4395 (2) | 1.4246 | 1.4341 | 1.4434 |
| QP | 0.8192 | 0.8182 | 0.8185 | 0.8167 | 0.8172 | 0.8163 | 0.8167 |
| VIF | 0.6141 | 0.6143 | 0.6158 | 0.6167 (2) | 0.6168 | 0.6165 | 0.6162 |
| Metrics | Parameter | ||||||
| 45 | 55 | 57 | 59 | 61 | 63 | 65 | |
| QMI | 0.9014 | 0.9041 | 0.9342 | 0.9371 | 0.9340 | 0.9336 | 0.9003 |
| QTE | 0.3891 | 0.3906 | 0.4008 | 0.4012 | 0.4005 | 0.4005 | 0.3894 |
| QNCIE | 0.8296 | 0.8298 | 0.8322 | 0.8324 | 0.8322 | 0.8322 | 0.8295 |
| QM | 1.3504 | 1.3702 | 1.4258 | 1.4355 | 1.4349 | 1.4268 | 1.3454 |
| QP | 0.8208 | 0.8270 | 0.8168 | 0.8187 | 0.8172 | 0.8168 | 0.8209 |
| VIF | 0.6148 | 0.6170 | 0.6169 | 0.6179 | 0.6169 | 0.6168 | 0.6145 |
| Source Images | Metrics | MFF-GAN | U2Fusion | SwinFusion | CSSA | CPFA | Proposed |
|---|---|---|---|---|---|---|---|
| Lytro dataset | QMI | 0.8201(3) | 0.7302 | 0.8400(2) | 0.7890 | 0.1763 | 0.9924 |
| QTE | 0.3863 | 0.4116 | 0.3962(3) | 0.3894 | 0.2263 | 0.4087(2) | |
| QNCIE | 0.8251(3) | 0.8212 | 0.8258(2) | 0.8242 | 0.8054 | 0.8337 | |
| QM | 0.4878(3) | 0.3790 | 0.4798 | 0.4865 | 2.6280 | 2.0777(2) | |
| QP | 0.7931(3) | 0.7461 | 0.8038(2) | 0.7871 | 0.0562 | 0.8626 | |
| VIF | 0.4901 | 0.4625 | 0.5475(2) | 0.5211(3) | 0.1706 | 0.6253 |
| Methods | MFF-GAN | U2Fusion | SwinFusion | CSSA | NSCT | CPFA | Proposed |
|---|---|---|---|---|---|---|---|
| Time/s | 3.91(3) | 0.66(2) | 74.00(6) | 142.49(7) | 5.14(4) | 0.10 | 51.56(5) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jie, Y.; Li, X.; Wang, M.; Tan, H. Multi-Focus Image Fusion for Full-Field Optical Angiography. Entropy 2023, 25, 951. https://doi.org/10.3390/e25060951
Jie Y, Li X, Wang M, Tan H. Multi-Focus Image Fusion for Full-Field Optical Angiography. Entropy. 2023; 25(6):951. https://doi.org/10.3390/e25060951
Chicago/Turabian StyleJie, Yuchan, Xiaosong Li, Mingyi Wang, and Haishu Tan. 2023. "Multi-Focus Image Fusion for Full-Field Optical Angiography" Entropy 25, no. 6: 951. https://doi.org/10.3390/e25060951