
Modeling Exact Frequency-Energy Distribution for Quakes by a Probabilistic Cellular Automaton

{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Model
2.1. The Random Domino Automaton
2.2. Evolution Rules
- If the chosen cell is empty, then it becomes occupied with some fixed probability, depending of the type of the cell. The value of probability is: for a creation cell, for an enlarging cell, and for a merging cell. The state of the chosen cell remains unchanged (i.e., empty) with probability , or , or , respectively.
- If the chosen cell is occupied, and it belongs to the cluster of size i, the whole cluster is removed (i.e., each cell in the cluster is emptied) with probability depending on the size i of the cluster. The state of the chosen cell stays the same (i.e., occupied) with probability .
3. Equations
3.1. Variables
3.2. Equations
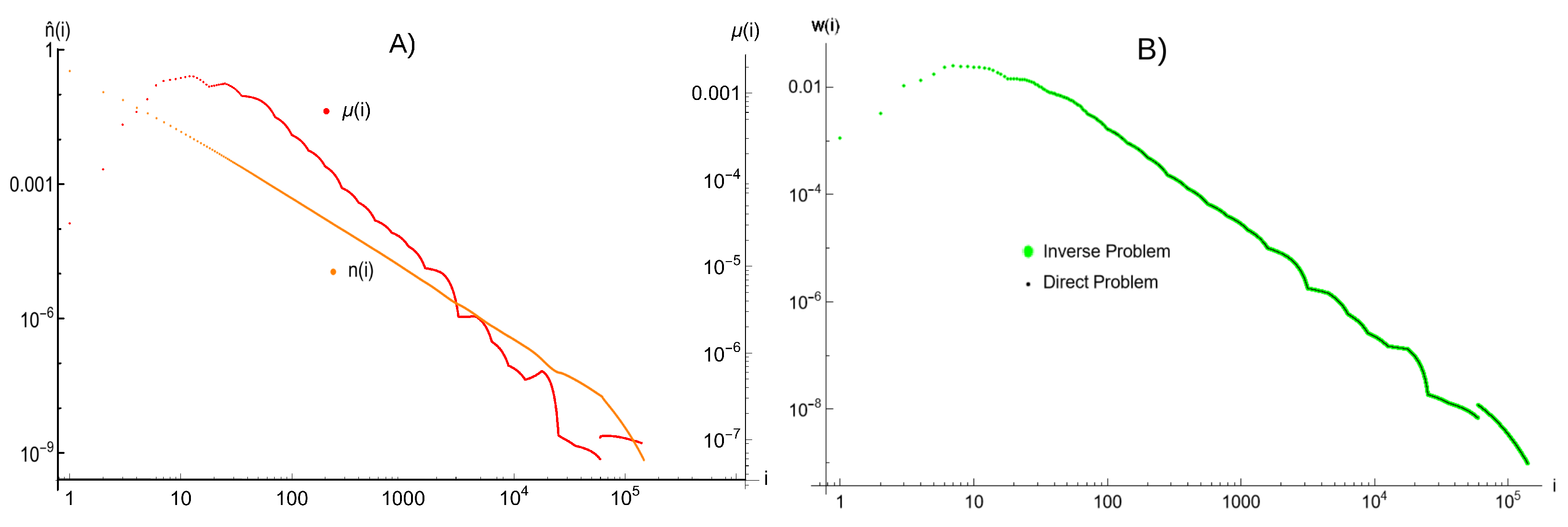
4. Inverse Problem
4.1. Formulation
4.2. The Procedure of the Solution to the Inverse Problem
5. Applications
5.1. Exponential Tail
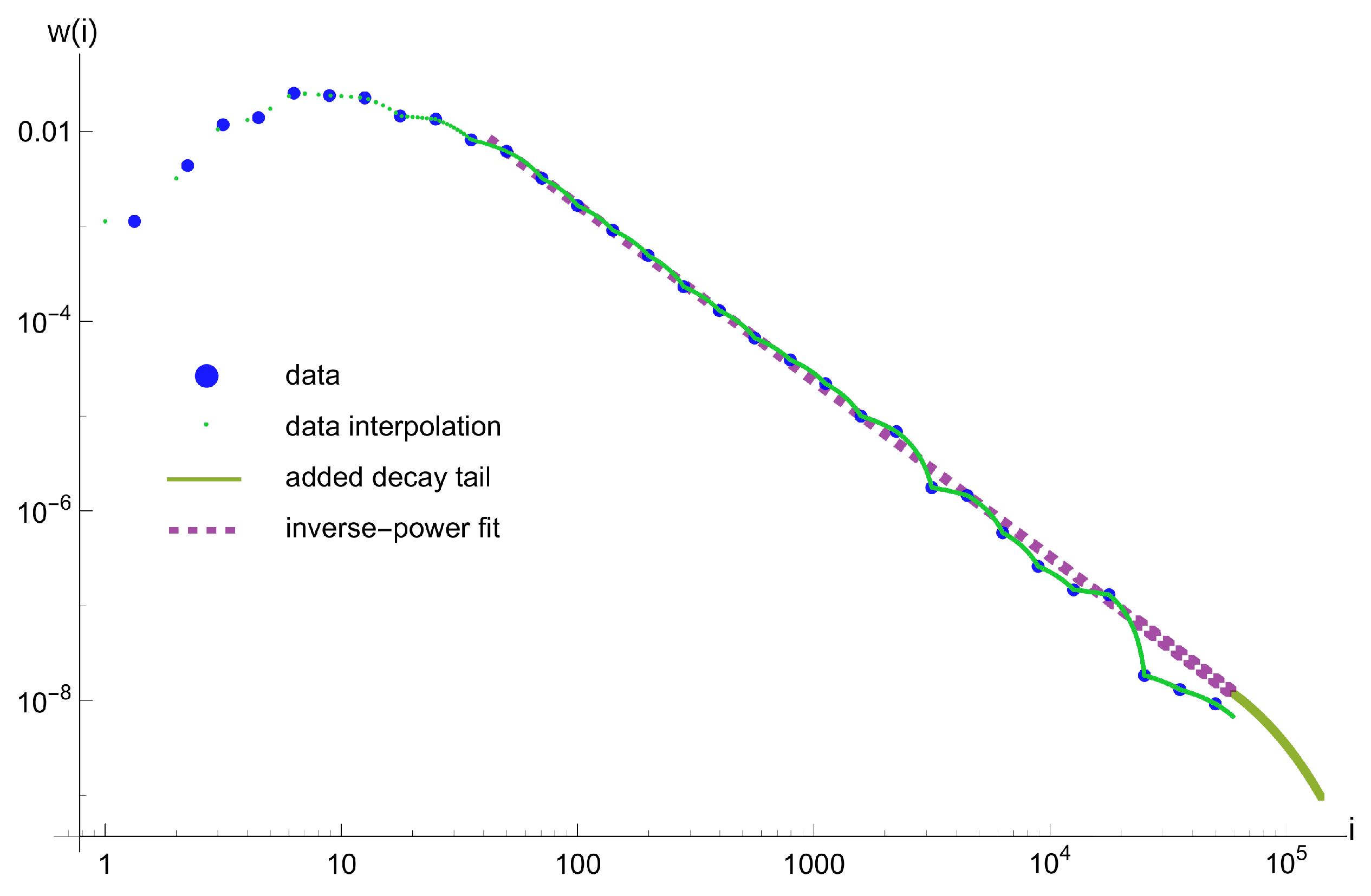
5.2. Seismic Data from LUMINEOS Network
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation of the System Equations
Appendix A.1. Balance Equation for ρ
Appendix A.2. Balance Equation for n
Appendix A.3. The Balance Equations for ’s
Appendix A.4. Equations for the Distribution of Clusters
References
- de Arcangelis, L.; Godano, C.; Grasso, J.R.; Lippiello, E. Statistical physics approach to earthquake occurrence and forecasting. Phys. Rep. 2016, 628, 1–91. [Google Scholar] [CrossRef]
- Ben-Zion, Y. Collective behavior of earthquakes and faults: Continuum-discrete transitions, progressive evolutionary changes, and different dynamic regimes. Rev. Geophys. 2008, 46, 2008RG000260. [Google Scholar] [CrossRef]
- Gutenberg, B.; Richter, C.F. Frequency of earthquakes in California. Bull. Seismol. Soc. Am. 1944, 34, 185–188. [Google Scholar] [CrossRef]
- Utsu, T.; Ogata, Y.; Matsu’ura, R.S. The Centenary of the Omori Formula for a Decay Law of Aftershock Activity. J. Phys. Earth 1995, 43, 1–33. [Google Scholar] [CrossRef]
- Sornette, D. Critical Phenomena in Natural Sciences: Chaos, Fractals, Selforganization and Disorder: Concepts and Tools; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Bak, P.; Christensen, K.; Danon, L.; Scanlon, T. Unified Scaling Law for Earthquakes. Phys. Rev. Lett. 2002, 88, 178501. [Google Scholar] [CrossRef]
- Corral, Á. Local distributions and rate fluctuations in a unified scaling law for earthquakes. Phys. Rev. E 2003, 68, 035102(R). [Google Scholar] [CrossRef]
- Corral, Á. Long-Term Clustering, Scaling, and Universality in the Temporal Occurrence of Earthquakes. Phys. Rev. Lett. 2004, 92, 108501. [Google Scholar] [CrossRef]
- Saichev, A.; Sornette, D. “Universal” Distribution of Interearthquake Times Explained. Phys. Rev. Lett. 2006, 97, 078501. [Google Scholar] [CrossRef]
- Touati, S.; Naylor, M.; Main, I.G. Origin and Nonuniversality of the Earthquake Interevent Time Distribution. Phys. Rev. Lett. 2009, 102, 168501. [Google Scholar] [CrossRef]
- Varotsos, P.A.; Sarlis, N.V.; Tanaka, H.K.; Skordas, E.S. Similarity of fluctuations in correlated systems: The case of seismicity. Phys. Rev. E 2005, 72, 041103. [Google Scholar] [CrossRef]
- Varotsos, P.A.; Sarlis, N.V.; Skordas, E.S.; Tanaka, H.K.; Lazaridou, M.S. Attempt to distinguish long-range temporal correlations from the statistics of the increments by natural time analysis. Phys. Rev. E 2006, 74, 021123. [Google Scholar] [CrossRef] [PubMed]
- Białecki, M. On Mechanistic Explanation of the Shape of the Universal Curve of Earthquake Recurrence Time Distributions. Acta Geophys. 2015, 63, 1205–1215. [Google Scholar] [CrossRef]
- Louis, P.-Y.; Nardi, F.R. (Eds.) Probabilistic Cellular Automata; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Jimenez, A. Cellular automata to describe seismicity: A review. Acta Geophys. 2013, 61, 1325–1350. [Google Scholar] [CrossRef]
- Białecki, M.; Czechowski, Z. On One-to-One Dependence of Rebound Parameters on Statistics of Clusters: Exponential and Inverse-Power Distributions Out of Random Domino Automaton. JPSJ 2013, 82, 014003. [Google Scholar] [CrossRef]
- Kravchinsky, E.; van der Baan, M. Magnitude-Frequency Distributions and Slip-History Predictions for Earthquakes Using Cellular Automata and Absorbing Markov Chains. J. Geophys. Res. Solid Earth 2022, 127, e2021JB022480. [Google Scholar] [CrossRef]
- IS EPOS (2017), Episode: LGCD. Available online: https://tcs.ah-epos.eu/#episode:LGCD (accessed on 16 May 2023).
- Orlecka-Sikora, B.; Lasocki, S.; Kocot, J.; Szepieniec, T.; Grasso, J.R.; Garcia-Aristizabal, A.; Schaming, M.; Urban, P.; Jones, G.; Stimpson, I.; et al. An open data infrastructure for the study of anthropogenic hazards linked to georesource exploitation. Sci. Data 2020, 7, 89. [Google Scholar] [CrossRef]
- Rudziński, Ł.; Lasocki, S.; Orlecka-Sikora, B.; Wiszniowski, J.; Olszewska, D.; Kokowski, J.; Mirek, J. Integrating Data under the European Plate Observing System from the Regional and Selected Local Seismic Networks in Poland. Seismol. Res. Lett. 2021, 92, 1717–1725. [Google Scholar] [CrossRef]
- Drossel, B.; Schwabl, F. Self-Organized Critical Forest-Fire Model. Phys. Rev. Lett 1992, 69, 1629–1632. [Google Scholar] [CrossRef]
- Białecki, M. Properties of a Finite Stochastic Cellular Automaton Toy Model of Earthquakes. Acta Geophys. 2015, 63, 923–956. [Google Scholar] [CrossRef]
- Białecki, M. From statistics of avalanches to microscopic dynamics parameters in a toy model of earthquakes. Acta Geophys. 2013, 61, 1677–1689. [Google Scholar] [CrossRef]
- Kanamori, H. Quantification of Earthquakes. Nature 1978, 271, 411–414. [Google Scholar] [CrossRef]
- Deluca, A.; Corral, Á. Fitting and goodness-of-fit test of non-truncated and truncated power-law distributions. Acta Geophys. 2013, 61, 1351–1394. [Google Scholar] [CrossRef]
- Clel, J.; Williams, M.A.K. Anomalous diffusion driven by the redistribution of internal stresses. Phys. Rev. E 2021, 104, 014123. [Google Scholar]
- Clel, J.; Williams, M.A.K. Analytical Investigations into Anomalous Diffusion Driven by Stress Redistribution Events: Consequences of Levy Flights. Mathematics 2022, 10, 3235. [Google Scholar]
- Białecki, M. Motzkin numbers out of Random Domino Automaton. Phys. Lett. A 2012, 376, 3098–3100. [Google Scholar] [CrossRef]
- Białecki, M. Catalan numbers out of a stochastic cellular automaton. J. Math. Phys. 2019, 60, 012701. [Google Scholar] [CrossRef]
- Czechowski, Z.; Budek, A.; Bialecki, M. Bi-SOC-states in one-dimensional random cellular automaton. Chaos 2017, 27, 103123. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Białecki, M.; Gałka, M.; Bagchi, A.; Gulgowski, J. Modeling Exact Frequency-Energy Distribution for Quakes by a Probabilistic Cellular Automaton. Entropy 2023, 25, 819. https://doi.org/10.3390/e25050819
Białecki M, Gałka M, Bagchi A, Gulgowski J. Modeling Exact Frequency-Energy Distribution for Quakes by a Probabilistic Cellular Automaton. Entropy. 2023; 25(5):819. https://doi.org/10.3390/e25050819
Chicago/Turabian StyleBiałecki, Mariusz, Mateusz Gałka, Arpan Bagchi, and Jacek Gulgowski. 2023. "Modeling Exact Frequency-Energy Distribution for Quakes by a Probabilistic Cellular Automaton" Entropy 25, no. 5: 819. https://doi.org/10.3390/e25050819