

Amplitude Constrained Vector Gaussian Wiretap Channel: Properties of the Secrecy-Capacity-Achieving Input Distribution

Abstract
:1. Introduction
1.1. Literature Review
1.2. Contributions and Paper Outline
1.3. Notation
2. Preliminaries
2.1. Oscillation Theorem
2.2. Low-Amplitude Regime
2.3. Connections to Other Optimization Problems
2.4. KKT Conditions
3. Main Results
3.1. A New Sufficient Condition on the Optimality of
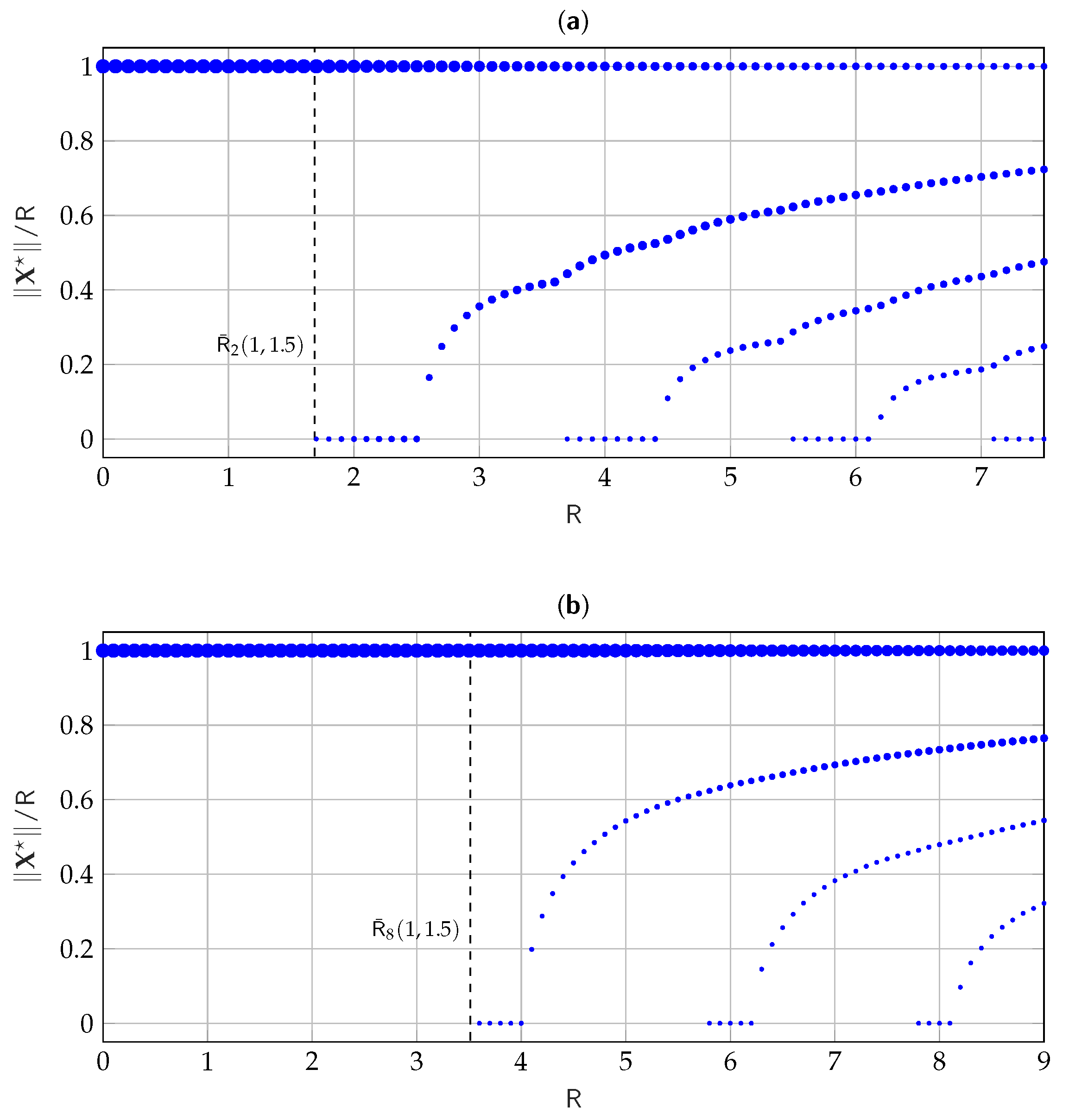
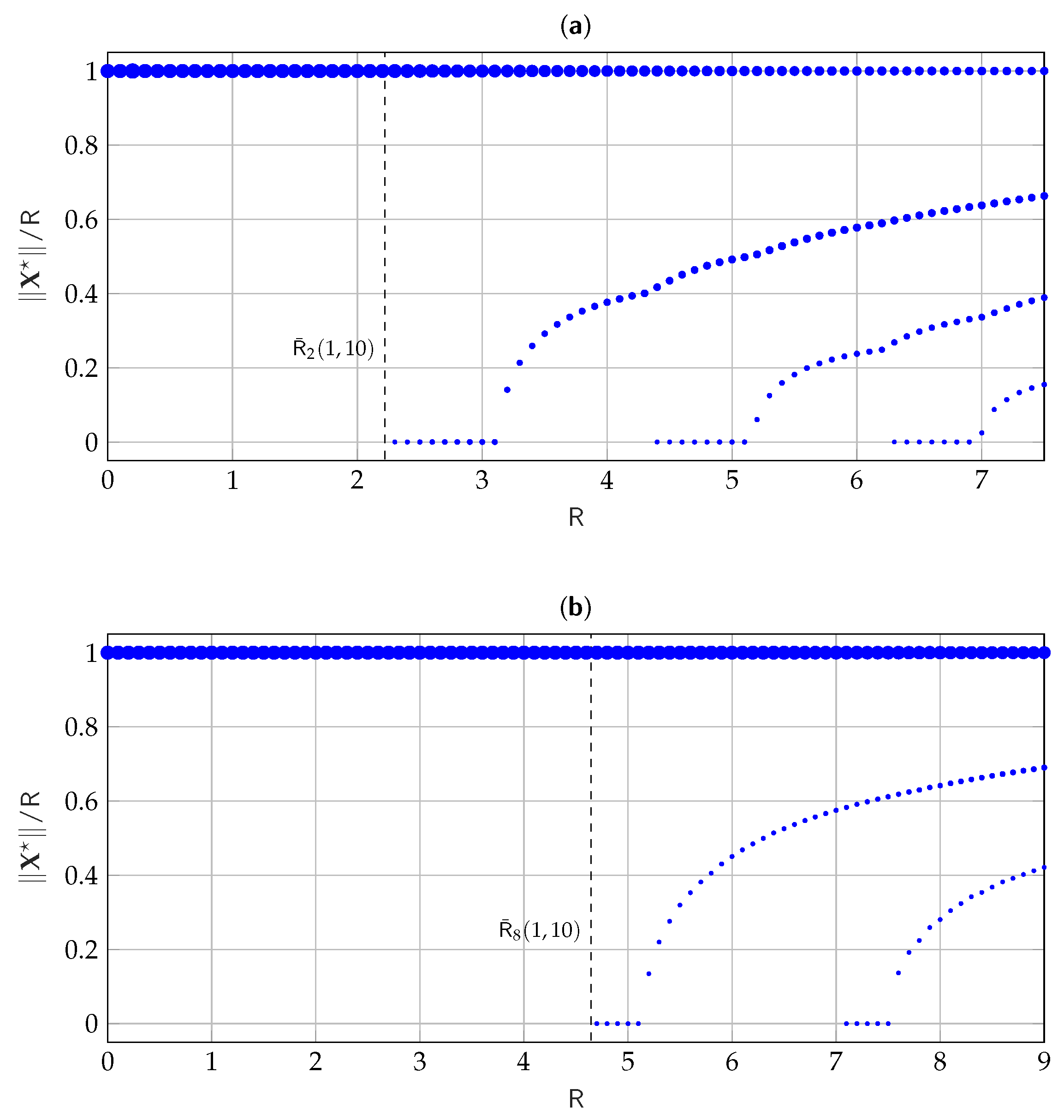
3.2. Characterizing the Low-Amplitude Regime
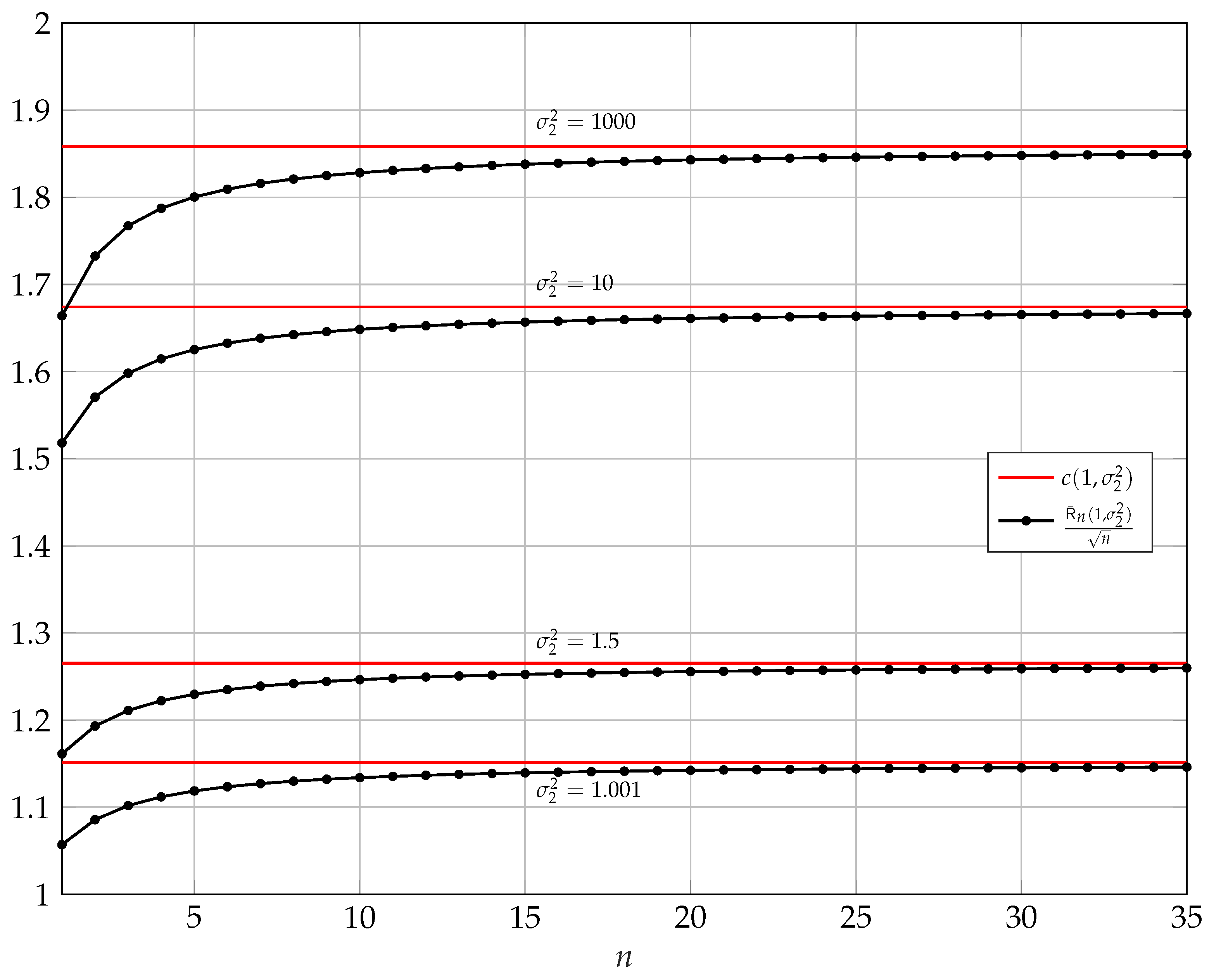
3.3. Large n Asymptotics
3.4. Scalar Case
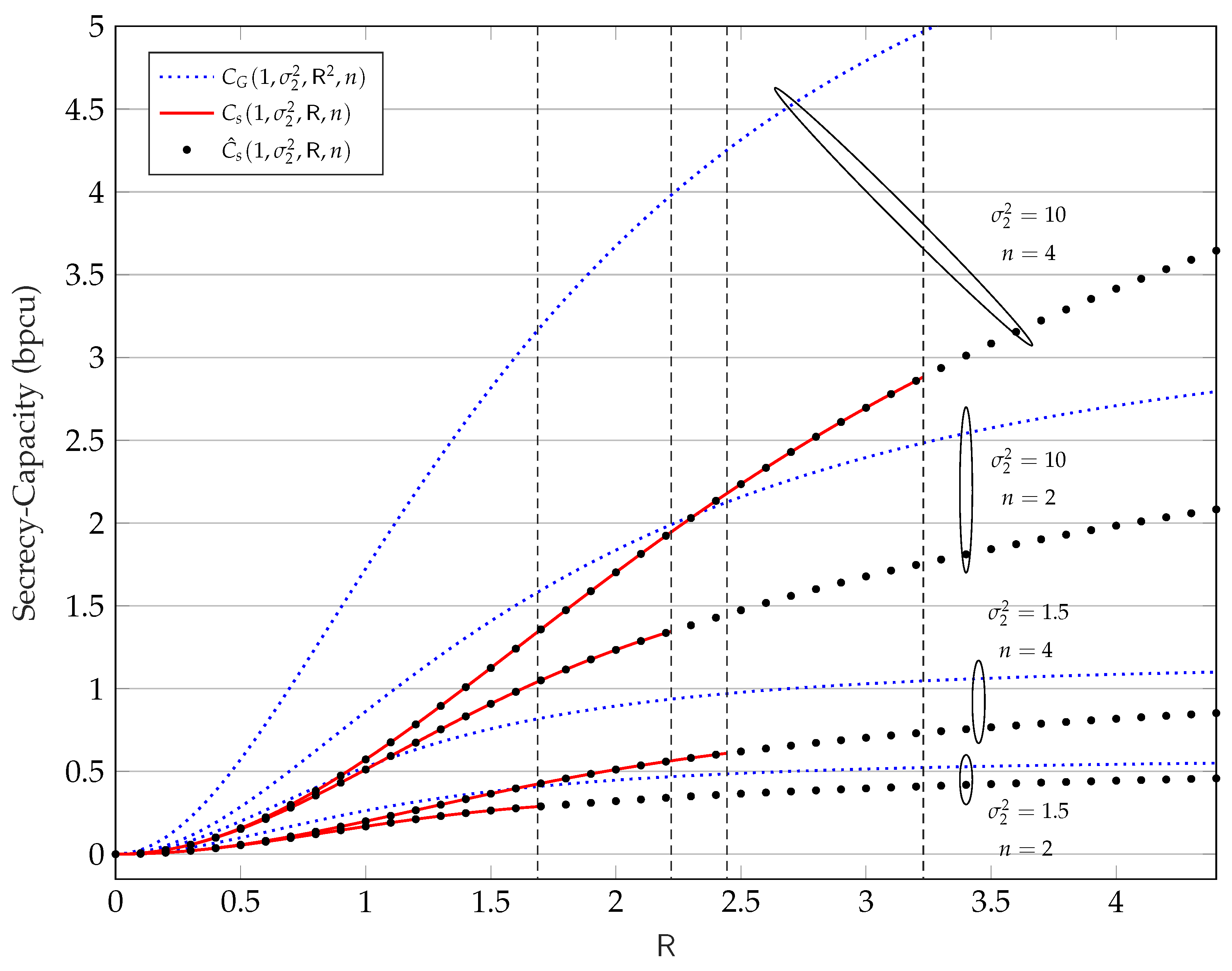
4. Secrecy Capacity Expression in the Low-Amplitude Regime
Large n Asymptotics
5. Beyond the Low-Amplitude Regime
5.1. Numerical Algorithm
| Algorithm 1 Secrecy capacity and optimal input pmf estimation |
|
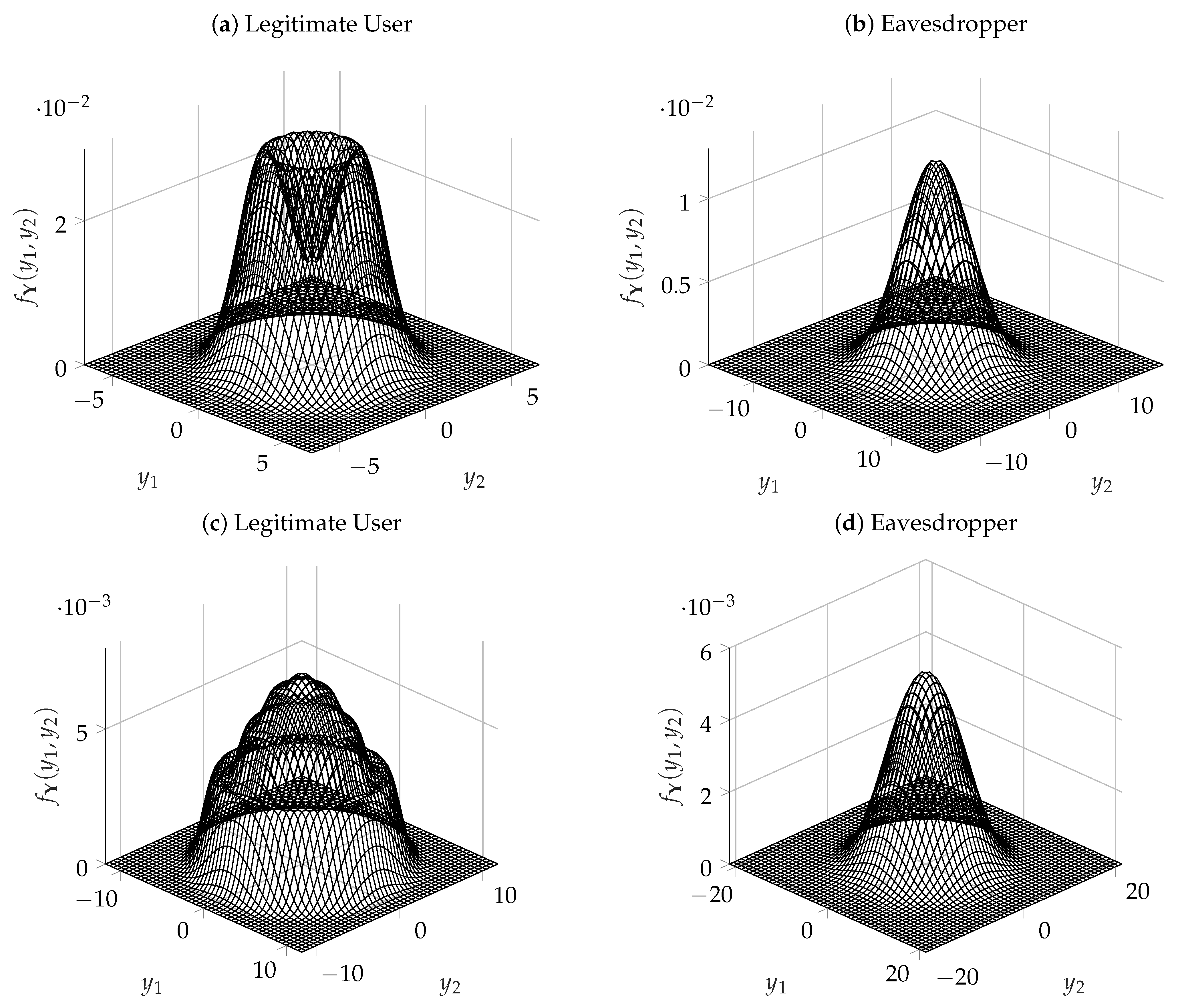
5.2. Numerical Results
6. Proof of Theorem 3
Estimation Theoretic Representation
7. Proof of Theorem 4
8. Proof of Theorem 5
8.1. Implicit Upper Bound
8.2. Explicit Upper Bound
9. Proof of Theorem 6
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
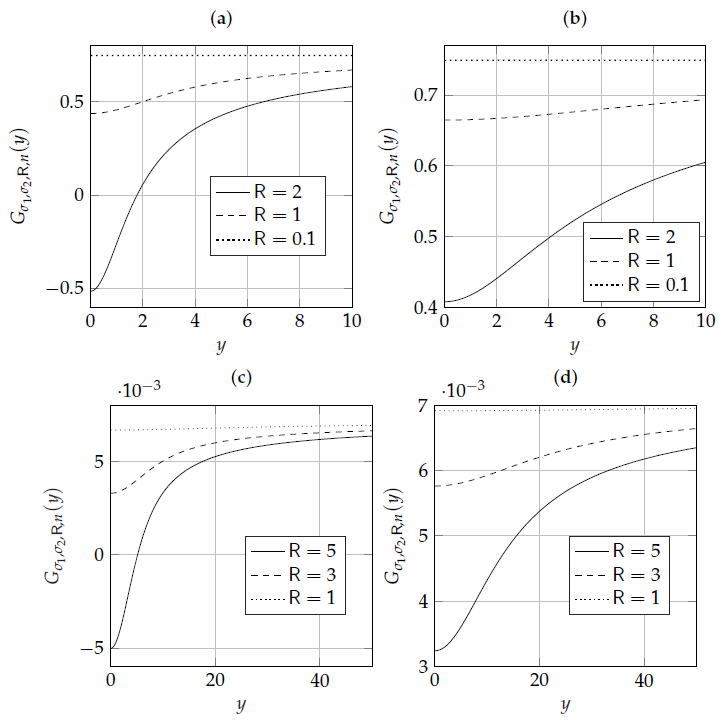
Appendix A. Examples of the Function Gσ1,σ2,R,n

Appendix B. Derivative of the Secrecy-Density
Appendix C. Proof of Theorem 7
Appendix D. Proof of Theorem 8
Appendix E. Partial Derivatives for the Gradient Ascent Algorithm
References
- Favano, A.; Barletta, L.; Dytso, A. Simulated Data. Available online: https://github.com/ucando83/WiretapCapacity (accessed on 26 April 2023).
- Wyner, A.D. The wire-tap channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Leung-Yan-Cheong, S.; Hellman, M. The Gaussian wire-tap channel. IEEE Trans. Inf. Theory 1978, 24, 451–456. [Google Scholar] [CrossRef]
- Bloch, M.; Barros, J. Physical-Layer Security: From Information Theory to Security Engineering; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Oggier, F.; Hassibi, B. A Perspective on the MIMO Wiretap Channel. Proc. IEEE 2015, 103, 1874–1882. [Google Scholar] [CrossRef]
- Liang, Y.; Poor, H.V.; Shamai (Shitz), S. Information theoretic security. Found. Trends Commun. Inf. Theory 2009, 5, 355–580. [Google Scholar] [CrossRef]
- Poor, H.V.; Schaefer, R.F. Wireless physical layer security. Proc. Natl. Acad. Sci. USA 2017, 114, 19–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mukherjee, A.; Fakoorian, S.A.A.; Huang, J.; Swindlehurst, A.L. Principles of physical layer security in multiuser wireless networks: A survey. IEEE Commun. Surv. Tutor. 2014, 16, 1550–1573. [Google Scholar] [CrossRef] [Green Version]
- Gopala, P.K.; Lai, L.; El Gamal, H. On the secrecy capacity of fading channels. IEEE Trans. Inf. Theory 2008, 54, 4687–4698. [Google Scholar] [CrossRef] [Green Version]
- Bloch, M.; Barros, J.; Rodrigues, M.R.; McLaughlin, S.W. Wireless information-theoretic security. IEEE Trans. Inf. Theory 2008, 54, 2515–2534. [Google Scholar] [CrossRef]
- Khisti, A.; Tchamkerten, A.; Wornell, G.W. Secure broadcasting over fading channels. IEEE Trans. Inf. Theory 2008, 54, 2453–2469. [Google Scholar] [CrossRef] [Green Version]
- Liang, Y.; Poor, H.V.; Shamai, S. Secure communication over fading channels. IEEE Trans. Inf. Theory 2008, 54, 2470–2492. [Google Scholar] [CrossRef] [Green Version]
- Shafiee, S.; Liu, N.; Ulukus, S. Towards the secrecy capacity of the Gaussian MIMO wire-tap channel: The 2-2-1 channel. IEEE Trans. Inf. Theory 2009, 55, 4033–4039. [Google Scholar] [CrossRef] [Green Version]
- Khisti, A.; Wornell, G.W. Secure transmission with multiple antennas–Part II: The MIMOME wiretap channel. IEEE Trans. Inf. Theory 2010, 56, 5515–5532. [Google Scholar] [CrossRef] [Green Version]
- Oggier, F.; Hassibi, B. The secrecy capacity of the MIMO wiretap channel. IEEE Trans. Inf. Theory 2011, 57, 4961–4972. [Google Scholar] [CrossRef] [Green Version]
- Guo, D.; Shamai, S.; Verdú, S. Mutual information and minimum mean-square error in Gaussian channels. IEEE Trans. Inf. Theory 2005, 51, 1261–1282. [Google Scholar] [CrossRef] [Green Version]
- Bustin, R.; Liu, R.; Poor, H.V.; Shamai, S. An MMSE approach to the secrecy capacity of the MIMO Gaussian wiretap channel. Eurasip J. Wirel. Commun. Netw. 2009, 2009, 370970. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Shamai, S. A note on the secrecy capacity of the multiple-antenna wiretap channel. IEEE Trans. Inf. Theory 2009, 55, 2547–2553. [Google Scholar] [CrossRef]
- Loyka, S.; Charalambous, C.D. An algorithm for global maximization of secrecy rates in Gaussian MIMO wiretap channels. IEEE Trans. Commun. 2015, 63, 2288–2299. [Google Scholar] [CrossRef] [Green Version]
- Loyka, S.; Charalambous, C.D. Optimal signaling for secure communications over Gaussian MIMO wiretap channels. IEEE Trans. Inf. Theory 2016, 62, 7207–7215. [Google Scholar] [CrossRef] [Green Version]
- Ozel, O.; Ekrem, E.; Ulukus, S. Gaussian wiretap channel with amplitude and variance constraints. IEEE Trans. Inf. Theory 2015, 61, 5553–5563. [Google Scholar] [CrossRef]
- Soltani, M.; Rezki, Z. Optical wiretap channel with input-dependent Gaussian noise under peak-and average-intensity constraints. IEEE Trans. Inf. Theory 2018, 64, 6878–6893. [Google Scholar] [CrossRef]
- Soltani, M.; Rezki, Z. The Degraded Discrete-Time Poisson Wiretap Channel. arXiv 2021, arXiv:2101.03650. [Google Scholar]
- Nam, S.H.; Lee, S.H. Secrecy Capacity of a Gaussian Wiretap Channel with One-bit ADCs is Always Positive. In Proceedings of the 2019 IEEE Information Theory Workshop (ITW), Visby, Sweden, 25–28 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Dytso, A.; Egan, M.; Perlaza, S.M.; Poor, H.V.; Shitz, S.S. Optimal Inputs for Some Classes of Degraded Wiretap Channels. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Karlin, S. Pólya type distributions, II. Ann. Math. Stat. 1957, 28, 281–308. [Google Scholar] [CrossRef]
- Dytso, A.; Al, M.; Poor, H.V.; Shamai Shitz, S. On the Capacity of the Peak Power Constrained Vector Gaussian Channel: An Estimation Theoretic Perspective. IEEE Trans. Inf. Theory 2019, 65, 3907–3921. [Google Scholar] [CrossRef]
- Favano, A.; Ferrari, M.; Magarini, M.; Barletta, L. The Capacity of the Amplitude-Constrained Vector Gaussian Channel. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 426–431. [Google Scholar] [CrossRef]
- Berry, J.C. Minimax estimation of a bounded normal mean vector. J. Multivar. Anal. 1990, 35, 130–139. [Google Scholar] [CrossRef] [Green Version]
- Dytso, A.; Yagli, S.; Poor, H.V.; Shamai (Shitz), S. The Capacity Achieving Distribution for the Amplitude Constrained Additive Gaussian Channel: An Upper Bound on the Number of Mass Points. IEEE Trans. Inf. Theory 2020, 66, 2006–2022. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; Thomas, J. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Han, T.S.; Endo, H.; Sasaki, M. Reliability and Secrecy Functions of the Wiretap Channel Under Cost Constraint. IEEE Trans. Inf. Theory 2014, 60, 6819–6843. [Google Scholar] [CrossRef]
- Barletta, L.; Dytso, A. Amplitude-Constrained Gaussian Wiretap Channel: Computation of the Optimal Input Distribution. In Proceedings of the 2022 IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 5–8 September 2022; pp. 106–111. [Google Scholar] [CrossRef]
- Rose, K. A mapping approach to rate-distortion computation and analysis. IEEE Trans. Inf. Theory 1994, 40, 1939–1952. [Google Scholar] [CrossRef] [Green Version]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef] [Green Version]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Yasui, K.; Suko, T.; Matsushima, T. An algorithm for computing the secrecy capacity of broadcast channels with confidential messages. In Proceedings of the 2007 IEEE International Symposium on Information Theory (ISIT), Nice, France, 24–29 June 2007; pp. 936–940. [Google Scholar] [CrossRef]
- Verdú, S. Mismatched estimation and relative entropy. IEEE Trans. Inf. Theory 2010, 56, 3712–3720. [Google Scholar] [CrossRef]
- Segura, J. Bounds for ratios of modified Bessel functions and associated Turán-type inequalities. J. Math. Anal. Appl. 2011, 374, 516–528. [Google Scholar] [CrossRef] [Green Version]
- Baricz, Á. Bounds for Turánians of modified Bessel functions. Expo. Math. 2015, 33, 223–251. [Google Scholar] [CrossRef] [Green Version]
- Tijdeman, R. On the number of zeros of general exponential polynomials. In Proceedings of the Indagationes Mathematicae; North-Holland: Amsterdam, The Netherlands, 1971; Volume 74, pp. 1–7. [Google Scholar]
- Esposito, R. On a relation between detection and estimation in decision theory. Inf. Control 1968, 12, 116–120. [Google Scholar] [CrossRef] [Green Version]
- Dytso, A.; Poor, H.V.; Shitz, S.S. A general derivative identity for the conditional mean estimator in Gaussian noise and some applications. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 1183–1188. [Google Scholar] [CrossRef]
- Barletta, L.; Dytso, A. Scalar Gaussian Wiretap Channel: Bounds on the Support Size of the Secrecy-Capacity-Achieving Distribution. In Proceedings of the 2021 IEEE Information Theory Workshop (ITW), Kanazawa, Japan, 17–21 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Favano, A.; Barletta, L.; Dytso, A. On the Capacity Achieving Input of Amplitude Constrained Vector Gaussian Wiretap Channel. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 850–855. [Google Scholar] [CrossRef]
- Favano, A. The Capacity of Amplitude-Constrained Vector Gaussian Channels. Ph.D. Dissertation, Politecnico di Milano, Milan, Italy, 2022. [Google Scholar]
- Lapidoth, A.; Moser, S.M. Capacity bounds via duality with applications to multiple-antenna systems on flat-fading channels. IEEE Trans. Inf. Theory 2003, 49, 2426–2467. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | MMSE | ptp | ||||
|---|---|---|---|---|---|---|
| 1.001 | 1.5 | 10 | 1000 | |||
| 1 | 1.057 | 1.057 | 1.161 | 1.518 | 1.664 | 1.666 |
| 2 | 1.535 | 1.535 | 1.687 | 2.221 | 2.450 | 2.454 |
| 3 | 1.908 | 1.909 | 2.098 | 2.768 | 3.061 | 3.065 |
| 4 | 2.223 | 2.224 | 2.444 | 3.229 | 3.575 | 3.580 |
| 5 | 2.501 | 2.501 | 2.750 | 3.634 | 4.026 | 4.031 |
| 6 | 2.751 | 2.752 | 3.025 | 3.999 | 4.432 | 4.438 |
| 7 | 2.981 | 2.982 | 3.278 | 4.334 | 4.805 | 4.811 |
| 8 | 3.195 | 3.196 | 3.513 | 4.646 | 5.151 | 5.158 |
| 9 | 3.395 | 3.396 | 3.733 | 4.937 | 5.475 | 5.483 |
| 10 | 3.585 | 3.586 | 3.941 | 5.213 | 5.781 | 5.789 |
| 11 | 3.765 | 3.766 | 4.139 | 5.475 | 6.072 | 6.080 |
| 12 | 3.936 | 3.938 | 4.328 | 5.725 | 6.350 | 6.359 |
| 13 | 4.101 | 4.102 | 4.509 | 5.964 | 6.616 | 6.625 |
| 14 | 4.259 | 4.260 | 4.683 | 6.195 | 6.872 | 6.881 |
| 15 | 4.412 | 4.413 | 4.851 | 6.417 | 7.119 | 7.128 |
| 16 | 4.560 | 4.561 | 5.013 | 6.632 | 7.357 | 7.367 |
| 17 | 4.702 | 4.704 | 5.170 | 6.839 | 7.588 | 7.598 |
| 18 | 4.841 | 4.842 | 5.323 | 7.041 | 7.812 | 7.823 |
| 19 | 4.976 | 4.977 | 5.471 | 7.238 | 8.030 | 8.041 |
| 20 | 5.107 | 5.109 | 5.616 | 7.429 | 8.242 | 8.254 |
| 21 | 5.235 | 5.237 | 5.756 | 7.615 | 8.449 | 8.461 |
| 22 | 5.360 | 5.362 | 5.894 | 7.797 | 8.651 | 8.663 |
| 23 | 5.483 | 5.484 | 6.028 | 7.974 | 8.848 | 8.860 |
| 24 | 5.602 | 5.603 | 6.159 | 8.148 | 9.041 | 9.054 |
| 25 | 5.719 | 5.720 | 6.288 | 8.318 | 9.230 | 9.243 |
| 26 | 5.834 | 5.835 | 6.414 | 8.485 | 9.416 | 9.428 |
| 27 | 5.946 | 5.948 | 6.538 | 8.649 | 9.597 | 9.610 |
| 28 | 6.056 | 6.058 | 6.659 | 8.809 | 9.775 | 9.789 |
| 29 | 6.165 | 6.166 | 6.778 | 8.967 | 9.951 | 9.964 |
| 30 | 6.271 | 6.273 | 6.895 | 9.122 | 10.123 | 10.136 |
| 31 | 6.376 | 6.378 | 7.010 | 9.274 | 10.292 | 10.306 |
| 32 | 6.479 | 6.481 | 7.124 | 9.424 | 10.458 | 10.472 |
| 33 | 6.580 | 6.582 | 7.235 | 9.571 | 10.622 | 10.636 |
| 34 | 6.680 | 6.682 | 7.345 | 9.717 | 10.783 | 10.798 |
| 35 | 6.779 | 6.780 | 7.453 | 9.860 | 10.942 | 10.957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Favano, A.; Barletta, L.; Dytso, A. Amplitude Constrained Vector Gaussian Wiretap Channel: Properties of the Secrecy-Capacity-Achieving Input Distribution. Entropy 2023, 25, 741. https://doi.org/10.3390/e25050741
Favano A, Barletta L, Dytso A. Amplitude Constrained Vector Gaussian Wiretap Channel: Properties of the Secrecy-Capacity-Achieving Input Distribution. Entropy. 2023; 25(5):741. https://doi.org/10.3390/e25050741
Chicago/Turabian StyleFavano, Antonino, Luca Barletta, and Alex Dytso. 2023. "Amplitude Constrained Vector Gaussian Wiretap Channel: Properties of the Secrecy-Capacity-Achieving Input Distribution" Entropy 25, no. 5: 741. https://doi.org/10.3390/e25050741