1. Introduction
Reinforcement learning (RL) aims to develop computer systems with the ability to learn how to behave optimally, or nearly so, in an unknown dynamic environment. An RL task typically involves an agent interacting with the environment, which is often modeled as a Markov decision process (MDP), and the agent’s goal is to find a policy maximizing some notion of reward. In most settings in RL, the MDP is initially unknown beyond its state and action spaces. Hence, the agent aims to learn a near-optimal policy using the experiences collected from the environment.
A classical setting in RL is off-policy learning [
1], where one tries to learn the optimal action–value function (i.e., Q-function) through the data collected under some
behavior or
logging policy. Perhaps the most famous off-policy learning algorithm is the celebrated Q-learning algorithm [
2], whose improved variants, combined with deep neural networks as function approximators, played key roles in many recent breakthroughs in RL [
3,
4]. More precisely, Q-learning and its variants fall under the category of
model-free methods, in which one tries to directly estimate the optimal value function—without estimating the true model (MDP)—from the collected experience, from which a near-optimal policy could be straightforwardly derived. This approach is in stark contrast to the
model-based counterpart, where one first attempts to estimate the unknown model parameters (i.e., MDP parameters that include transition probabilities and rewards) from the collected experience and then finds an optimal policy in the estimated model.
Off-policy learning in finite MDPs is by now well understood, and the existing literature (e.g., [
5,
6,
7,
8,
9]) exhibit algorithms that admit PAC-type sample complexity guarantees. Precisely speaking, these algorithms are guaranteed to return a near-optimal policy, with respect to a prescribed accuracy, with high probability if the amount of collected experience exceeds a certain (algorithm-dependent) function of the MDP parameters (and relevant input parameters). Most of these works study unstructured tabular MDPs, where the advertised sample complexity bounds scale, among other things, with the size of the state–action space. Thus, despite their appealing performance guarantees, most of these algorithms only work reasonably well when the size of the underlying MDP is small. On the other hand, many practical tasks can be modeled by MDPs with huge state spaces (or even infinite), but they often exhibit some structural properties. Ignoring such structural properties and directly applying the above algorithms would lead to a prohibitively large sample complexity bound, which may imply a huge learning phase in the worst case. Alternatively, one could leverage the structure in the MDP to speed up the exploration. In fact, exploiting the structure allows the agent to use the collected observations from the environment to reduce the uncertainty in the model parameter for many
similar state–action pairs at each time slot. As a result, the learning performance would depend on the effective size of the state space (or the effective number of unknown parameters). Various notions of structures have been studied in MDPs, which include the Lipschitz continuity of MDP parameters (e.g., rewards and transition functions) [
10,
11,
12,
13], factorization structure [
14,
15,
16], and equivalence relations [
17,
18,
19,
20,
21,
22]. These works reveal that exploiting the underlying structure in the environment in various RL tasks leads to massive empirical performance gain (over structure-oblivious algorithms) and to significantly improved performance bounds. However, exploiting structure often poses additional challenges.
This work is motivated by tabular RL problems, where the (potentially large) state–action space admits a natural partitioning such that within each element of the partition (or class), the state–action pairs have
similar transition probabilities. There exist several ways to characterize the similarity between the transition distribution of two state–action pairs. Here, we consider a notion implying that they are (almost) identical up to some permutation. As we shall see in later sections, this notion of structure induces an equivalence relation in the state–action space. This model has been considered in prior work [
18,
23,
24], where model-based algorithms were presented to exploit such a structure in the context of regret minimization in episodic or average-reward MDPs. However, their proposed ideas and techniques are specific to a model-based approach, where the model parameters are directly estimated, and cannot be used to incorporate the knowledge of the equivalence structure into a model-free algorithm. Model-free algorithms have played a pivotal role in the recent success of RL to solving complex tasks arising in real-world applications (e.g., autonomous driving and continuous control [
25]). Hence, it sounds promising to study the gain one could obtain using model-free methods when leveraging the equivalence structure, thereby extending the theoretical analysis in [
18,
24] beyond model-based methods.
Contributions. We make the following contributions. We study off-policy learning in discounted finite MDPs, admitting some equivalence structure in their state–action space. We introduce a new model-free algorithm, called QL-ES (Q-learning with equivalence structure), which is a variant of (asynchronous) Q-learning tailored to exploit the equivalence structure in the MDP, when a prior knowledge on the structure is provided to the agent. We report a non-asymptotic PAC-type sample complexity bound for QL-ES, thereby establishing its sample efficiency. This bound also allows us to quantify the superiority of QL-ES over Q-learning analytically. As it turns out, the sample efficiency gain of QL-ES over Q-learning is captured by an MDP-dependent quantity
that is defined in terms of the associated covering times in the MDP; see
Section 5 for details. Analytically establishing the dependence of the gain ratio
on the number
S of states in a given MDP seems difficult, although it is possible to numerically compute it. Nonetheless, we present a simple example where
, thus showcasing that QL-ES in some domains may require
much fewer (by a factor of
S) samples than Q-learning. Furthermore, we numerically compute
for a few families of MDPs built using standard environments (with increasing
S), thereby showcasing the theoretical superiority of QL-ES over Q-learning. Through extensive numerical experiments on standard domains, we show that Q-function estimates under QL-ES converge much faster than those obtained from (structure-oblivious) Q-learning. These results demonstrate that the empirical performance gain from exploiting the equivalence structure could be massive, even in simple domains. To our best knowledge, QL-ES is the first provably efficient model-free algorithm to exploit the equivalence structure in MDPs.
2. Related Work
Similarity and equivalence in MDPs. There is a rich literature on learning and exploiting various notions of structure in MDPs, where the aim is to leverage structure to alleviate the computational cost of finding an optimal policy (in the known MDP setting) or to speed up exploration (in the RL setting). Many such algorithms fall into the category of state abstraction (or aggregation) [
26,
27]. Approximate homomorphism is proposed to construct beneficial abstract models in MDPs [
28]. In the known MDP setting, Refs. [
29,
30] appear to be the first presenting the notion of equivalence between states based on
stochastic bi-simulation. The authors of [
31,
32] use
bi-simulation metrics as quantitative analogues of the equivalence relations to partition the state space by capturing similarities. In the RL setting, Refs. [
18,
19,
20,
33,
34] investigate
model-based algorithms that rely on the grouping of similar states (or state–action pairs) to speed up exploration. Ref. [
20] is the first to present an average-reward RL algorithm (in the regret setting), where the confidence intervals of similar states are aggregated. Ref. [
18] studies regret minimization in average-reward MDPs with equivalence structure and presents the C-UCRL algorithm, which is capable of exploiting the structure. The regret bound for C-UCRL depends on the number of classes in the MDP rather than the size of the state–action space. A similar equivalence structure was studied in [
17] in the context of multi-task RL, where similarities of the transition dynamics across tasks were extracted and exploited to speed up learning. Ref. [
24] studies the efficiency of hierarchical RL in the regret setting in scenarios where the hierarchical structure is defined with respect to the notion of equivalence; more precisely, it assumes that the underlying MDP can be decomposed into
equivalent sub-MDPs—i.e., smaller MDPs with identical reward and transition functions up to some known bijection mappings. Closest to our work, in terms of the structure definition, is [
18]. However, we restrict ourselves to a model-free approach where the model-based machinery presented in [
18] does not apply. Finally, we mention that there is some literature on exploiting equivalence in deep RL (e.g., [
21,
22]). However, none of these works study provably efficient learning methods to our best knowledge.
Q-learning and its variants. We provide a very brief overview of the works studying theoretical analysis of Q-learning and its variants. Q-learning [
2] has been around for more than three decades as a cheap and popular model-free method to solve finite, unknown discounted MDPs without estimating the model. Its convergence was investigated in an asymptotic flavor [
35,
36], and more recently in the non-asymptotic (finite-sample) regime in a series of work, including [
9,
37,
38,
39,
40]. To the best of our knowledge, Ref. [
9] reports the sharpest PAC-type sample complexity bound for the classical Q-learning. Some of these works present variants of Q-learning with improved sample complexity bounds using a variety of techniques, such as acceleration and variance reduction [
9,
40,
41]. Although the concept of equivalence in MDPs is not new, there is no work reporting PAC-type sample complexity bounds for model-free algorithms combined with equivalence relations, to our knowledge.
3. Problem Formulation
In this section, we present some necessary background and formulate the reinforcement learning problem considered in this paper. We use the following notations throughout. For a set B, denotes the set of all probability distributions over B. For an event E, denotes the indicator function of E: namely, it equals 1 if E holds, and 0 otherwise.
3.1. Discounted Markov Decision Processes
Let
be an infinite-horizon discounted MDP [
42], where
denotes a discrete state space with cardinality
S,
denotes a discrete action space with cardinality
A, and
is a discount factor.
represents the transition function such that
denotes the probability of transiting to state
when action
is chosen in state
. Further,
denotes the reward function supported on
such that
denotes the reward distribution when choosing action
in state
. We denote by
the mean of
. A stochastic (or randomized) policy
is a mapping that maps a state to a probability distribution over
. For a policy
, the value function of
is a mapping
defined as
where for all
,
,
, and
, and where the expectation is taken with respect to the randomness in rewards, next states, and actions sampled from
. The action–value function of a policy
, denoted by
, is defined as
The optimal value function is denoted by
and satisfies
for all
. It is well known that in any finite MDP, there exists a stationary deterministic policy
such that
, which is called an optimal policy [
42]. Similarly, the optimal state–action value function is defined as
for all
. An optimal policy
satisfies
for all
. Furthermore,
is the unique solution to the optimal Bellman equation [
42]:
3.2. The Off-Policy Learning Problem and Q-Learning
We consider the off-policy learning problem as follows. The agent is provided with some dataset collected according to some behavior or logging policy . Precisely speaking, takes the form of trajectory , where is some initial state, and where for each , , , and . The agent is given an accuracy parameter and a failure probability parameter , and its goal is to find an -optimal policy using as few samples as possible from .
We need to impose some assumptions on the behavior policy
to ensure that it is possible to learn a near-optimal policy only using
efficiently with PAC-type guarantees. To state the assumptions, we introduce some necessary definitions, which are borrowed from standard textbooks on Markov chains (e.g., [
43]) but are also standard in the theoretical analysis of Q-learning (e.g., [
9,
39]). Let
be a finite set. The
total variation distance between two distributions
and
defined over
is
. Now, consider an ergodic Markov chain
with state space
and transition function
, and let
be the unique stationary distribution of the chain. The Markov chain is said to be
uniformly ergodic if there exist some
and
such that for all
,
where
is the distribution of
given
.
Similar to [
9], we assume that the Markov chain induced by
is uniformly ergodic. This property ensures that all the states are visited infinitely often, and that convergence to the stationary distribution is performed at a geometric pace. This property is needed for the result presented in
Section 5.
The Q-learning algorithm. The Q-learning algorithm [
35] is perhaps the most famous model-free algorithm for learning an optimal policy in unknown tabular MDPs. As a model-free method, it directly learns the optimal Q-function
of the MDP (without estimating
P and
R), which can be used to derive a policy. The algorithm maintains an estimate
of the optimal
at each time step
t. Specifically, it starts from an arbitrary choice for
and updates
, at each
, as
where
is a suitably chosen learning rate. Precisely speaking, the update Equation (
1) corresponds to the asynchronous variant of Q-learning. The classical asymptotic performance analysis of Q-learning (in, for example, [
36]) indicates that if (i)
is exploratory enough such that all state–action pairs are visited infinitely often and (ii)
satisfies the following conditions, known as the Robbins–Monro conditions [
36,
44]:
then
almost surely, for any choice of
. For example, one such choice of the learning rate is as follows: for all
,
, where for any
,
denotes the number of visits to
up to time
t:
. The pseudo-code of Q-learning is described in Algorithm 1, where the learning rate sequence
is considered as input.
| Algorithm 1 Q-learning [2]. |
Input: dataset , maximum iterations T, learning rates |
Initialization:
|
for
do |
Sample action and observe and . |
Compute using ( 1). |
end for |
It is worth remarking that some studies consider off-policy learning in the online setting, where data are collected from the environment while executing the algorithm. In such online settings, it is possible to choose according to an adaptive (randomized) policy (usually defined as a function of the current estimate ), instead of sampling it from a fixed behavior policy. In doing so, the aim is to balance exploration and exploitation so as to collect higher rewards while learning the Q-function. A notable example is the -greedy policy, where at time t, is chosen greedily with respect to with probability , and chosen uniformly at random (from ) with probability . In the theoretical part of this paper, we consider a fixed behavior policy.
3.3. Similarity and Equivalence Classes
We now present a definition of the equivalence structure considered in this paper. We start by stating the following definition of similarity in finite MDPs as introduced in [
18]. A similar definition is provided in [
23].
Definition 1 (Similar state–action pairs [
18]).
Two state–action pairs and are called -similar if there exist mappings and such thatWe refer to as the
profile mapping
(or for short,
profile) for , and denote by the set of profile mappings across .
We stress that in Definition 1 may not be unique in general. The case of 0-similarity is of particular interest: it is evident from Definition 1 that if and are 0-similar, then and are identical up to some permutation from to . Furthermore, 0-similarity induces a partition of the state–action space as formalized below.
Definition 2 (Equivalence structure [
18]).
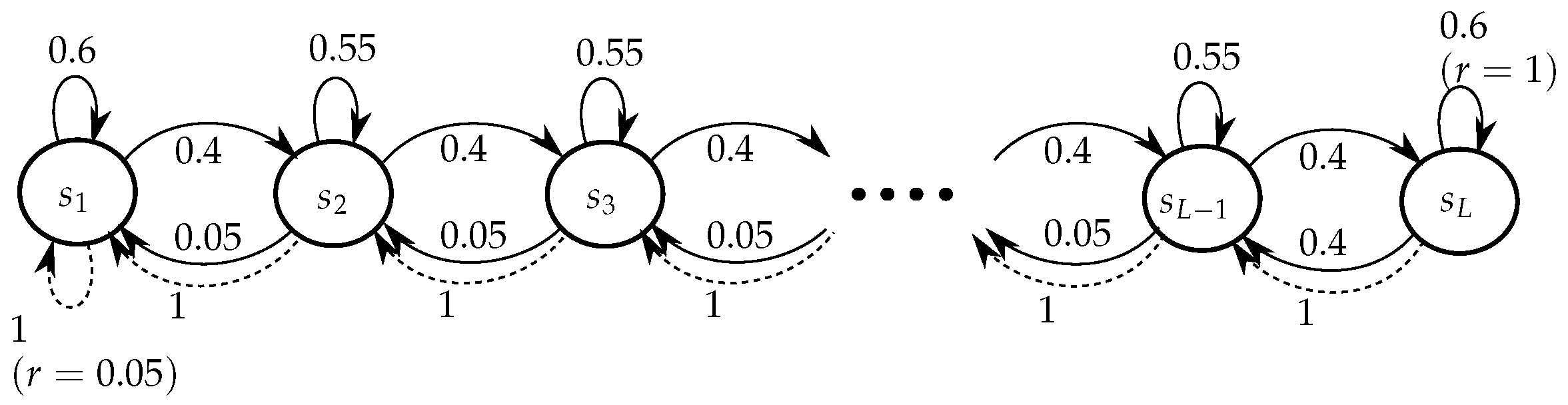
0-similarity is an equivalence relation and induces a canonical partition of . We refer to such a canonical partition as equivalence structure and denote it by . We further define . We provide an example to help understand Definition 2. Consider the RiverSwim environment [
45] with 6 states and
(see
Figure 1). The two pairs
and
are 0-similar since
and
, so there exist permutations
and
such that
. Additionally, all pairs
are 0-similar, and so are
. We thus identify an equivalence structure
of
as follows:
with
,
, and
.
Note that for any finite MDP, Definition 2 trivially holds with
. There are many interesting environments that non-trivially admit the notion of equivalence structure in Definition 2. In such MDPs, it is often the case that the size
C of the structure is much smaller than the size of the state–action space, i.e.,
. For example, in a generic RiverSwim with
S states, one has
. Another example admitting an equivalence structure is the classical grid-world MDP, which is detailed in
Section 6.2.
Off-policy learning in MDPs with equivalence structures. In this work, we assume that the underlying MDP M admits an equivalence structure as introduced above. In other words, the transition function P is such that can be partitioned into classes, where the pairs in each class are 0-similar. We make the following assumption regarding the agent’s prior knowledge about .
Assumption A1. The agent has prior knowledge on .
Let denote the class that the pair belongs to. Assumption A1 implies that the agent knows for any pair and the associated profile mapping . Note, however, that the agent does not know the actual transition probabilities. Armed with such prior knowledge, we are interested in devising a model-free algorithm that is capable of leveraging the structure in M to improve the learning performance. We expect that the corresponding speed-up in learning the optimal Q-function could be significant in MDPs with .
We also make the following assumption regarding the reward function to ease the presentation. (This assumption has often been made in the literature on theoretical RL (e.g., [
6,
46]) since the main challenge in RL arises from unknown transition probabilities.)
Assumption A2.
The agent knows the reward function R.
4. The QL-ES Algorithm
In this section, we present a variant of Q-learning that exploits the equivalence structure in the environment to speed up the learning of the optimal Q-function. We call this algorithm QL-ES, which is short for ‘Q-learning with equivalence structure’.
QL-ES follows the same machinery of QL but is also built on the idea that the knowledge on and the corresponding profile mappings allows for using the triplet collected at each time t to update potentially multiple entries of . Precisely speaking, the Q-function update for a given pair requires a sample from and a sample from . Since the agent perfectly knows , it can determine , i.e., the class belongs to. Hence, it knows all other pairs belonging to the same class as . Then using (sampled from ) at time t, the agent can construct samples for all other pairs in as follows. If , then there is a mapping and a state such that . In other words, the sample obtained from is equivalent to obtaining a fresh sample from . As and are known, the agent finds , where denotes the inverse mapping of . In other words, acts as a counterfactual next-state for thanks to the knowledge on .
The agent thus uses
to update
for all
. In summary, we update
as follows: For all
,
where
is a sequence of suitably chosen learning rates, as in (
1). The pseudo-code of QL-ES is provided in Algorithm 2.
| Algorithm 2 QL-ES |
Input: dataset , maximum iterations T, learning rates , equivalence structure |
Initialization: . |
for
do |
Sample action and observe . |
Find . |
for do |
|
Compute using ( 2) |
end for |
end for |
When the underlying MDP admits some equivalence structure, QL-ES performs multiple updates of Q-function at any slot, in contrast to structure-oblivious Q-learning that updates only the Q-function of the current state–action pair. Thus, we expect learning the optimal Q-function under QL-ES to be faster than Q-learning; this will be corroborated by the numerical experiments in
Section 6. It is also worth mentioning that QL-ES is never worse than Q-learning, as for the trivial partition
, which holds for any finite MDP, QL-ES reduces to Q-learning.
Remark 1. The multiple updates used in QL-ES can be straightforwardly combined with many other variants of Q-learning, such as Speedy Q-learning [46] and UCB-QL [41]. We finally remark that some works in the literature on Q-learning use learning rates of the form , where and where f is some suitable function f satisfying the Robbins–Monro conditions, e.g., . Such learning rates in the case of QL-ES can be modified to , where for any , .
5. Theoretical Guarantee for QL-ES
In this section, we investigate the theoretical guarantee of QL-ES in terms of sample complexity in the PAC setting. Specifically, we are interested in characterizing the deviation between the optimal Q-function
and its estimate
computed by QL-ES after
T time steps. A relevant notion of deviation often studied in the literature (see, e.g., [
37,
38]) is the
-distance between
and
:
which captures the worst error (with respect to
) among various pairs. One may study the rate at which the error function
decays as a function of
T. Alternatively, one may characterize
the PAC sample complexity defined as the number
T of steps needed until
satisfies
with probability at least
, for pre-specified
and
. We consider the latter case.
Let us first recall the classic definition of cover time
, which is a standard notion in the literature on Markov chains as well as those studying theoretical guarantees of Q-learning (and its variants) [
9,
38,
39]. Let
and let
denote the
first time step such that all state–action pairs are visited at least once with probability at least
. Then, the cover time
is defined as the maximum value of
over all initial pairs
. Note that
depends on both the MDP
M and the behavior policy
. More precisely, it depends on the mixing properties of the Markov chain induced by
on
M. Further, we have
.
Next, we introduce a notion of cover time for equivalence classes, which is relevant to the performance analysis of QL-ES. We believe it can be of independent interest.
Definition 3. Let M be a finite MDP and be an equivalence structure in M. Given , let denote the first time step such that for each , some state–action pair in c is visited at least once with probability at least . Then, the cover time with respect to the equivalence structure in M, denoted by , is defined as the maximum value of over all initial choices of (i.e., the class the initial pair belongs to).
The following theorem provides a non-asymptotic sample complexity for QL-ES. It concerns constant learning rates, i.e., for all , where may depend on and , among other things.
Theorem 1. There exist some universal constants such that for any and , we have with probability greater than , provided that the number T of steps and learning rate α jointly satisfy A proof of this theorem is provided in
Appendix A. Our proof is an adaptation of the of the proof of Theorem 2 in [
9], which concerns the sample complexity of Q-learning.
Comparison with sample complexity of Q-learning. Theorem 1 tells us that the number of steps to have
with high probability depends on
(up to some logarithmic factors), where
, defined in Definition 3, is the cover time with respect to
. Comparing this result against the sample of complexity of Q-learning (e.g., Theorem 2 in [
9]) reveals that using QL-ES yields an improvement over Q-learning by a factor of
, where
This ratio
is a problem-dependent constant (depending on both
M and
). It also depends on the behavior policy
in view of the definitions of the cover times. It is evident that
for any choice of
M and
. For a given MDP
M, the ratio
can be numerically computed; we report numerical values of
for several domains in
Section 6.3. On the other hand, deriving the analytical bounds on the ratio
for any
M appears to be complicated and tedious, if possible at all. Nonetheless, it is possible to construct simple problem instances, where one can derive analytical bounds on
.
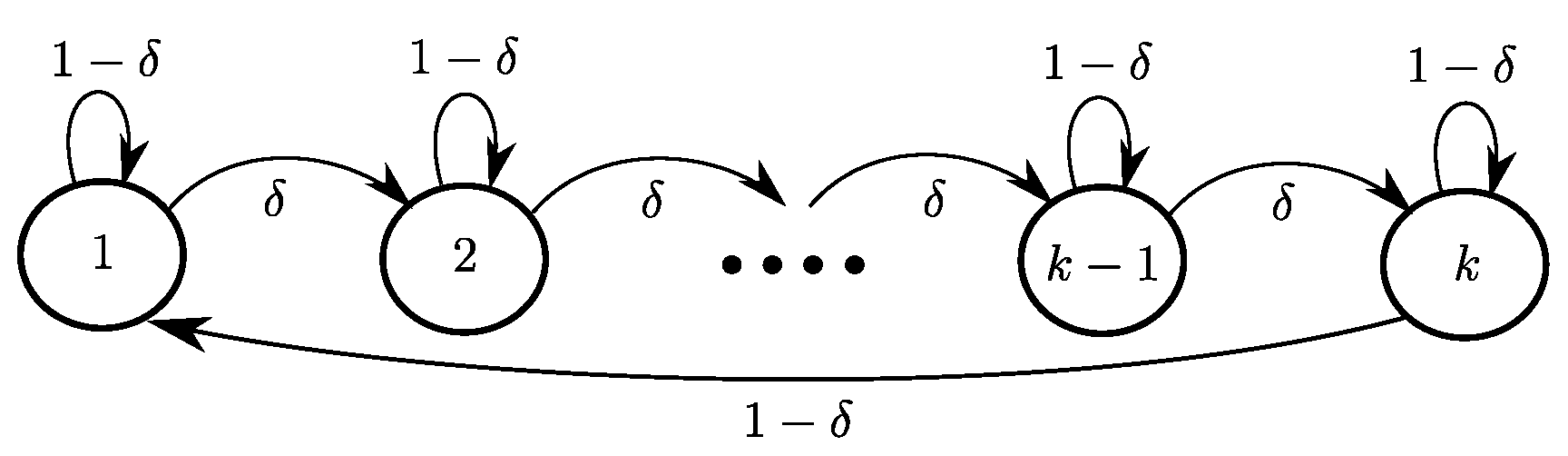
Figure 2 portrays one such example; this example is a simple Markov chain but can be easily extended to become an MDP. Easy calculations show that
and
so that
. Hence, one here has
. This simple example demonstrates that the gain of QL-ES over Q-learning in some domains could be as large as
, the size of the state space. Additionally, Theorem 1 reveals that in such domains, the theoretical sample complexity bound of QL-ES does not depend on
S but on
C, the number of classes in
.
We refer the reader to the results in
Section 6.3, where we present numerical bounds on
in some MDPs, which serve as the standard domain in the RL literature.
6. Simulation Results
This section is devoted to reporting numerical experiments conducted to examine the performance of QL-ES against the (structure-oblivious) Q-learning algorithm. First, we present the considered evaluation metrics and environments. Then we present numerical assessment of for these environments. Finally, we report empirical sample complexities of QL-ES and Q-learning in the environments.
6.1. Evaluation Metrics
We consider two evaluation metrics in the experiments:
- (i)
Max-norm Q-value Error defined as ;
- (ii)
Total Policy Error defined as , where denotes the greedy policy w.r.t. , i.e., for all s.
The metric (i), which is in line with the definition of sample complexity studied in
Section 5, captures the maximum difference between
and
over all state–action pairs and allows us to empirically study the convergence speed of
toward
. The second metric captures the quality of the estimate
in terms of inferred policies. Evidently, the quantity
returns the number of states at which
prescribes a sub-optimal action. Hence, the metric (ii) may capture how bad the policy derived from
(i.e.,
) would be, compared to
, had we stopped at time step
t. Equivalently, we may compute the metric (ii) via
Working with (
4) is preferred, as then, one may not worry about how ties (in
) are broken when either
or
is not unique.
6.2. Environments
We consider two environments: RiverSwim and GridWorld. These are classical MDPs widely used in the RL literature. Both render suitability to demonstrate the numerical performance of QL-ES since each allows us to define a family of MDPs with progressive difficulty levels.
RiverSwim and variants. A generic RiverSwim MDP with
L states is shown in
Figure 1, which extends the classical 6-state RiverSwim presented in [
45]. This MDP is constructed so that efficient exploration is required to obtain the optimal policy. The larger the number
L of states, the more exploration is required. The
L-state RiverSwim (with
) admits an equivalence structure with
regardless of
L. We consider RiverSwim instances with various
L so as to have MDPs with progressive difficulty levels while having a fixed number of classes. In some experiments, we consider a slightly modified version of RiverSwim, which we shall call
Perturbed RiverSwim. It is identical to RiverSwim (
Figure 1) except that in any state
, where
is even,
and
. It is clear that there are
classes in a
L-state Perturbed RiverSwim.
GridWorld. We also consider 2-room and 4-room grid-world MDPs with different grid sizes.
Figure 3 shows a
2-room and a
4-room grid-worlds, respectively. In both environments, the agent starts at the upper-left corner (in red) and is supposed to reach the lower-right corner (in yellow), where it is given a reward of 1 and then sent back to the initial red state. At each step, the agent has four possible actions (hence,
): Going up, left, down, or right. Black squares indicate the wall where the agent is not able to penetrate through. After executing a given action, the agent has a probability of
to stay in the same state, has a probability of
to move to the desired direction, and has a probability of
and
to move to the other two possible directions. If the wall blocks the agent, it stays where it is, and the transition probability of the next state is added to that of the current state.
It is clear that the grid-world MDPs above admit some equivalence structure. In the case of 2-room (respectively, 4-room), the state–action space is of size 84 (respectively, 160), while the number of classes remains 8 in both. In
Table 1, we also present six examples of grid-world environments with walls defined according to the way mentioned above. In the introduced 2-room and 4-room MDPs, the number of state–action pairs changes with the increase in the grid size, while the number of classes remains fixed.
6.3. Bounds on the Ratio
We recall from
Section 5 that the theoretical gain of QL-ES over Q-learning in terms of sample efficiency is captured by the problem-dependent quantity
. In this subsection, we compute
for the introduced environments with the aim of providing insights into the growth of
as the number
S of states grows. Specifically, we consider RiverSwim, Perturbed RiverSwim (introduced in
Section 6.2), and GridWorld MDPs, each with growing number of states. In each case, we report empirical values for
and
together with the corresponding
confidence intervals. The empirical
is computed as the median value (across 100 independent runs for every possible initial state-action pair) of the number of steps it takes to discover all state-action pairs starting from a given initial state-action pair. A similar procedure is used for
.
Table 2,
Table 3 and
Table 4 summarize empirical values of
and
(together with the associated
confidence intervals denoted by
) for RiverSwim, Perturbed RiverSwim, and 2-room GridWorld, respectively, with varying number of states in each case. In the case of GridWorld, we ran a uniform agent (sampling each action uniformly), wheres in RiverSwim MDPs, the agent samples R (resp. L) with probability
(resp.
).
These results reveal that is much smaller than in all cases. Furthermore, they indicate that while grows rapidly as S increases (in any family of the MDPs considered), experiences a much smaller growth. As for the ratio , we report as the lower confidence bound obtained by dividing the lower value in the CI for by the upper value in the CI for . This is a rather conservative estimate of the true but ensures that with probability at least . The reported values demonstrate that in these environments, grows rapidly as the size of state space grows. This observation verifies that the theoretical gain of QL-ES over Q-learning can be significant.
6.4. Experimental Results with Exact Equivalence Structure
We now turn to reporting experimental results for QL-ES and Q-learning in RiverSwim and GridWorld. In the following figures, QL indicates the standard Q-learning algorithm (Algorithm 1). We used a constant learning rate and -greedy policy (with values of to be specified later). Furthermore, all the results are averaged over 100 independent runs, and the corresponding confidence intervals are shown.
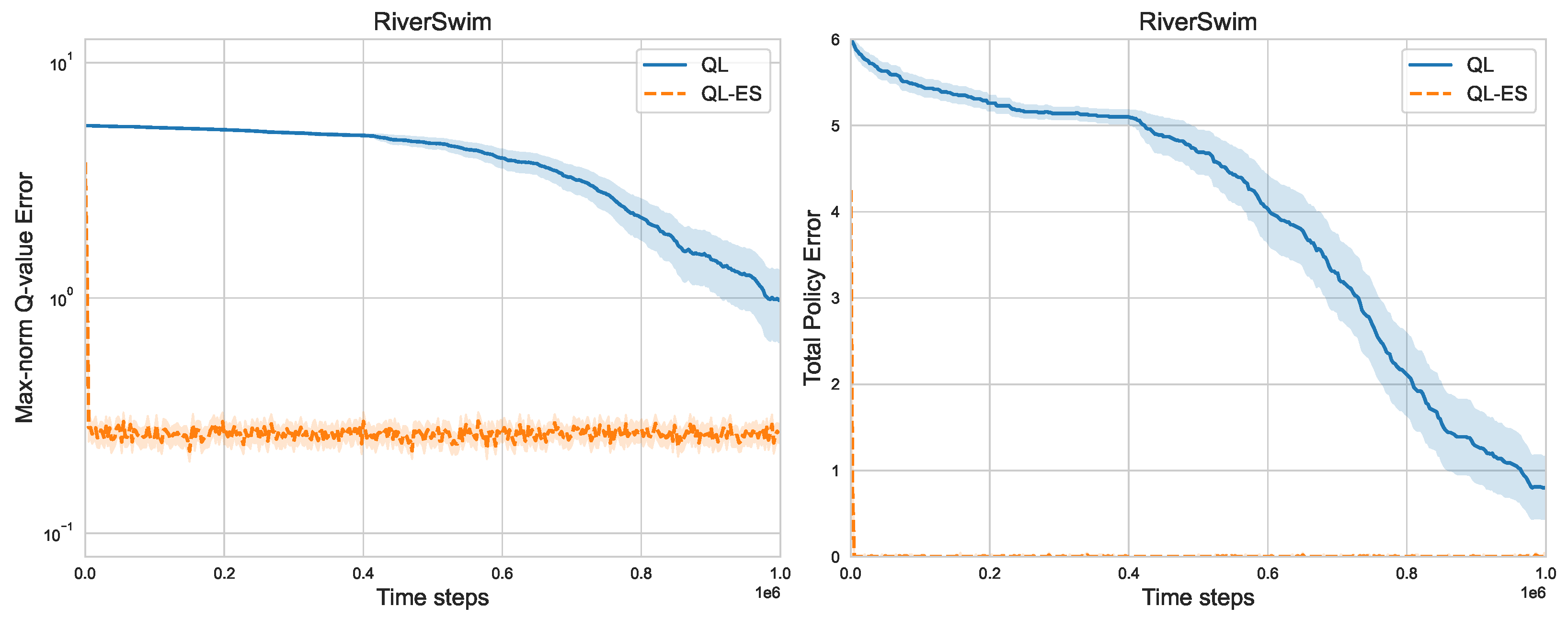
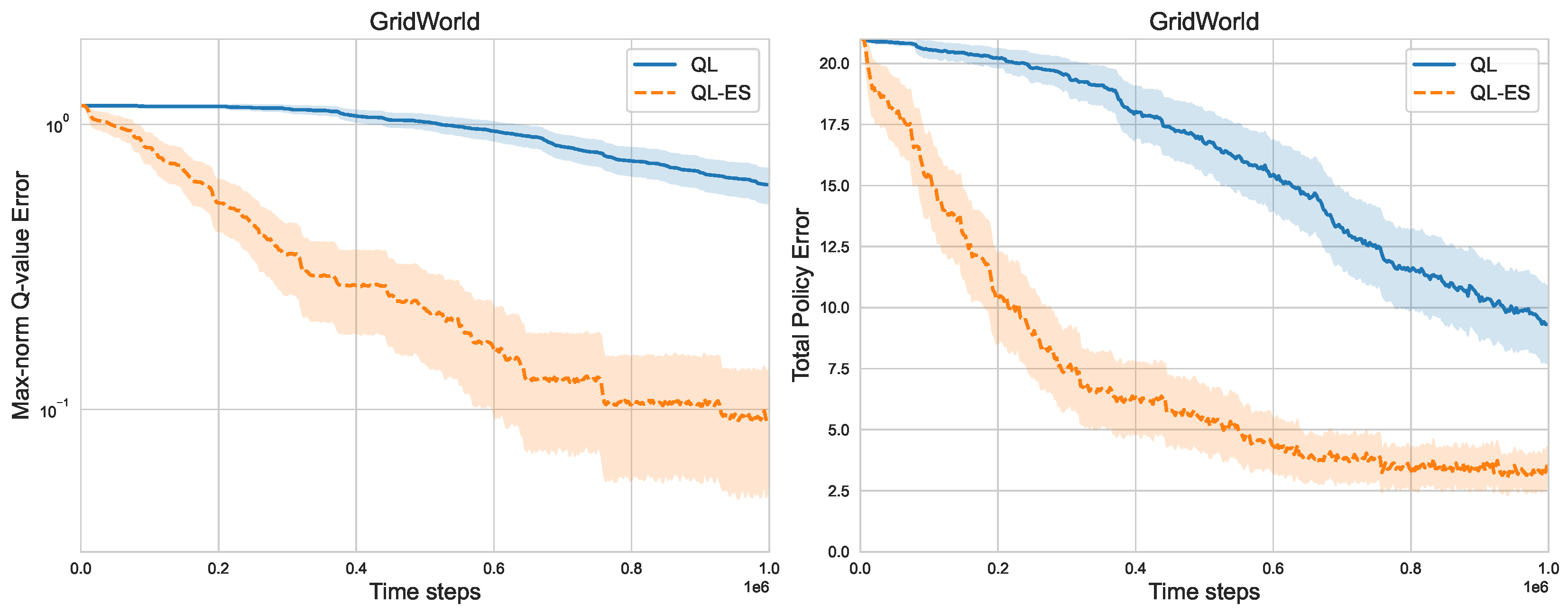
Figure 4 presents the max-norm Q-value error and total policy error under both QL-ES and Q-learning in a 6-state RiverSwim, where we set
and
. It is evident that QL-ES significantly outperforms Q-learning. The Q-value error under Q-learning decays at a very slow rate until about about
steps. After this step, the decay rate increases tangibly. In contrast, the Q-value error under QL-ES decays at a much faster speed. Under Q-learning, the total policy error remains above 5 until time step
, which implies that only one state has learned its optimal policy. On the contrary, the total policy error under QL-ES drops to the vicinity of 0 very quickly. These results verify that the empirical gain of leveraging the equivalence structures in MDPs, in terms of the number of samples, can be significant.
To demonstrate the scalability of QL-ES, in
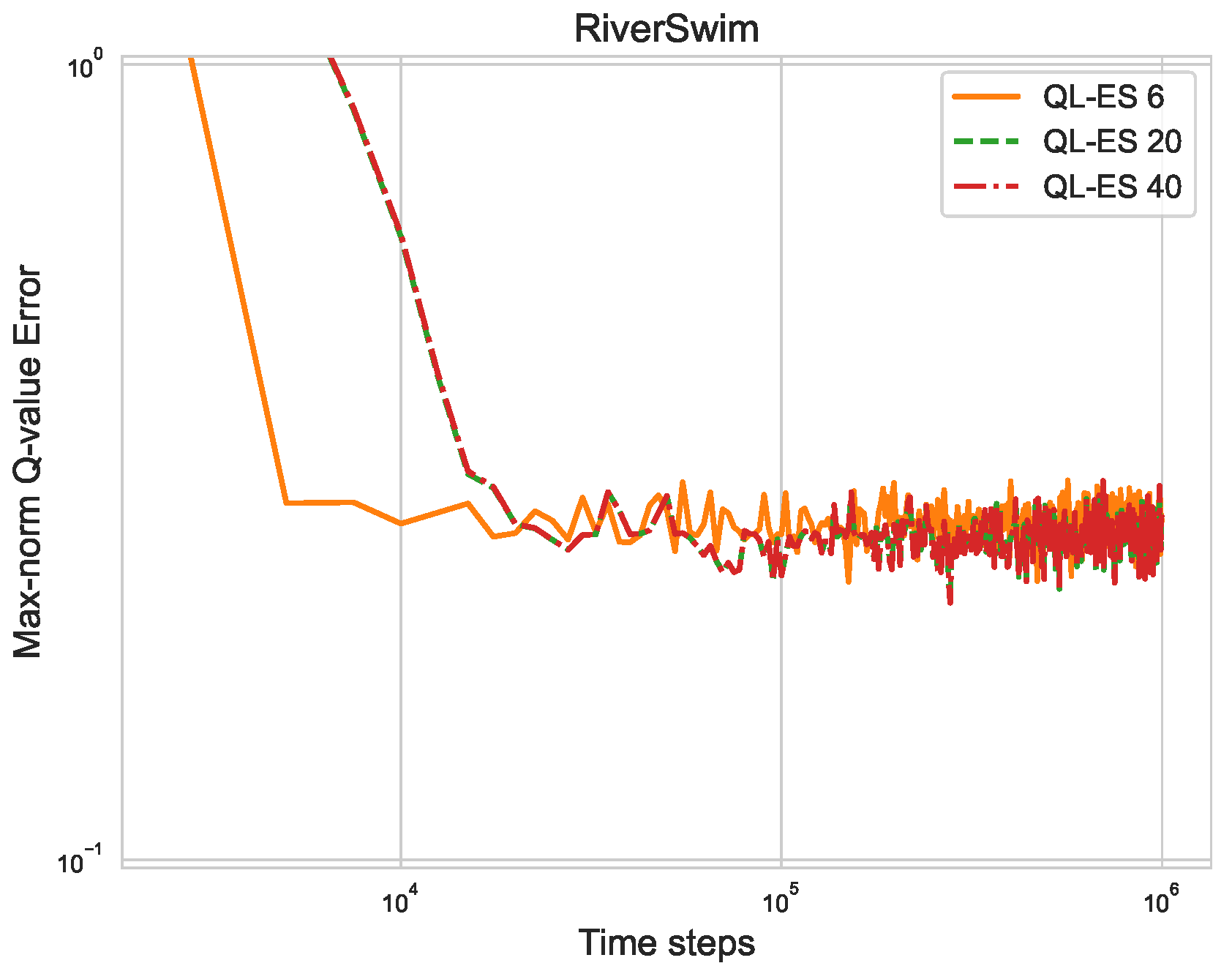
Figure 5, we present the Q-value error under QL-ES in RiverSwim instances with 6, 20, and 40 states. As the figure shows, although the error in the 6-state RiverSwim starts decaying much earlier than the others, all of them exhibit a similar rate of decay. Moreover, the curves corresponding to 20-state and 40-state instances are almost indistinguishable. This result showcases MDPs where the sample complexity of QL-ES does not scale with the size of the state–action space and is mostly determined by the number of classes.
We now turn to the results for GridWorld MDPs.
Figure 6 and
Figure 7 show the results for QL-ES and Q-learning in 2-room and 4-room GridWorld MDPs, where we used
and
in the 2-room and
and
in the 4-room.
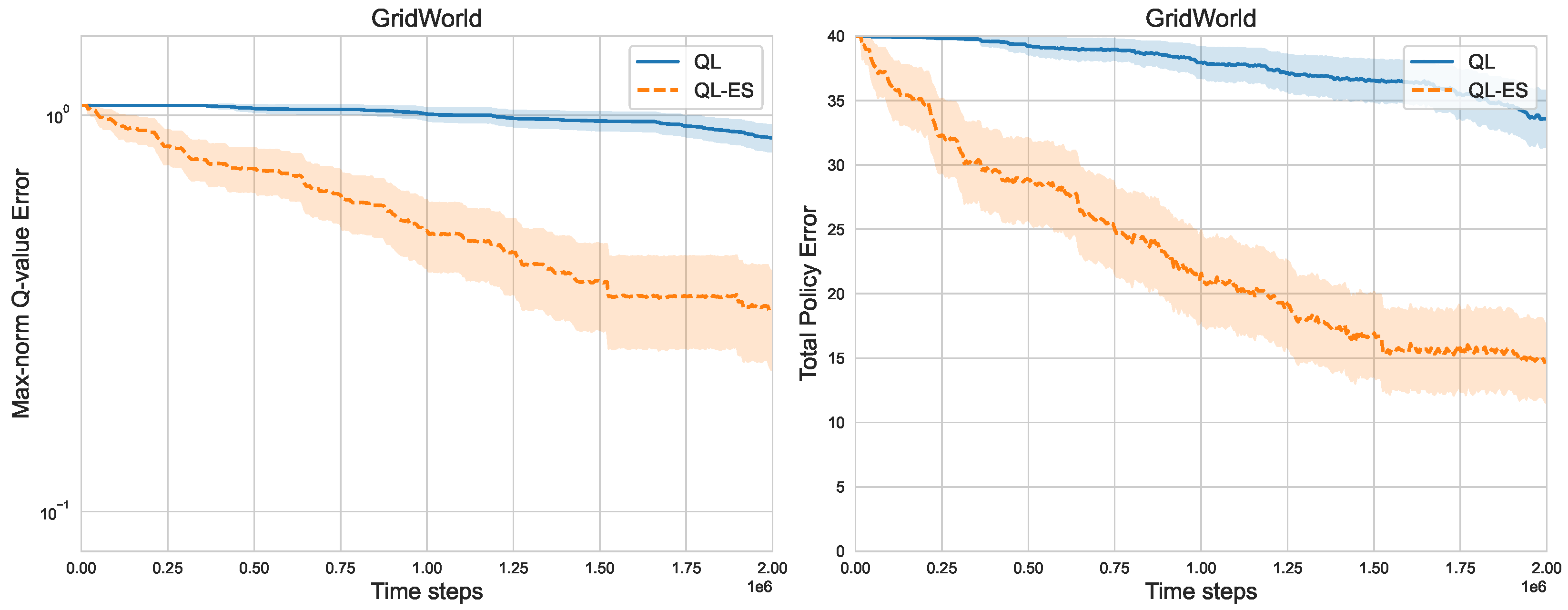
As in RiverSwim MDPs, QL-ES significantly outperforms Q-learning in the grid-world environments. For Q-learning, the Q-value error remains considerable, even for
samples. Although both QL-ES and Q-learning do not fully learn an optimal policy by the end of the run, the total policy error decays much faster under QL-ES. Overall, the results demonstrate that exploiting equivalence structure is beneficial in grid-world MDPs. Comparing
Figure 6 and
Figure 7, it is evident that QL-ES still obtains relatively better performance than Q-learning with the increase in state space. Moreover, similar trends are expected when conducting this experiment in larger grid-world MDPs.
6.5. The Gain in the Case of -Similar Pairs
We now investigate the case where the MDP may not admit any equivalence structure but admits
-similarity across its state–action space; see Definition 1. To this effect, we introduce
Modified RiverSwim and
Modified GridWorld defined as follows. The
Modified RiverSwim is identical to 6-state RiverSwim (
Figure 1), except that its non-zero transition probabilities under
and
are changed from
to
. The
Modified GridWorld is identical to
2-room grid-world, except that the non-zero transition probabilities under (
,down), (
,down), and (
,down) are set to
instead of
. Modified RiverSwim admits an equivalence structure, but we remark that it satisfies
-similarity with
. Similarly, Modified GridWorld satisfies
-similarity with
.
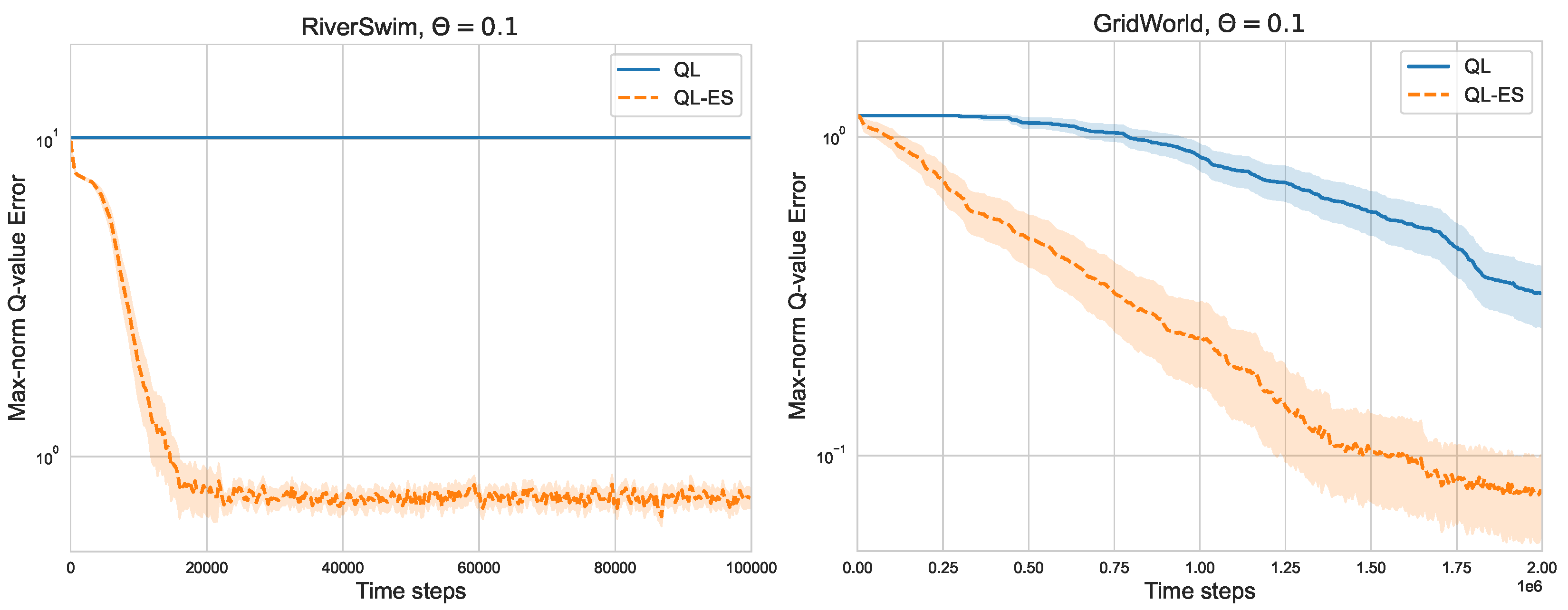
Figure 8 shows the results in Modified RiverSwim (with
) and Modified GridWorld (
). It is evident that in both cases, QL-ES still achieves smaller Q-value error than Q-learning.
6.6. The Impact of Partially Using the Structure
Considering MDPs with huge state–action spaces, it is necessary to take into account the feasibility of using only a few equivalent pairs. This thus naturally leads to the question as to whether only using a few equivalent pairs would lead to a reasonable performance gain. Therefore, here we investigate the convergence speed when choosing a subset of equivalent state–action pairs at each time step, rather than considering all the state–action pairs in the same class.
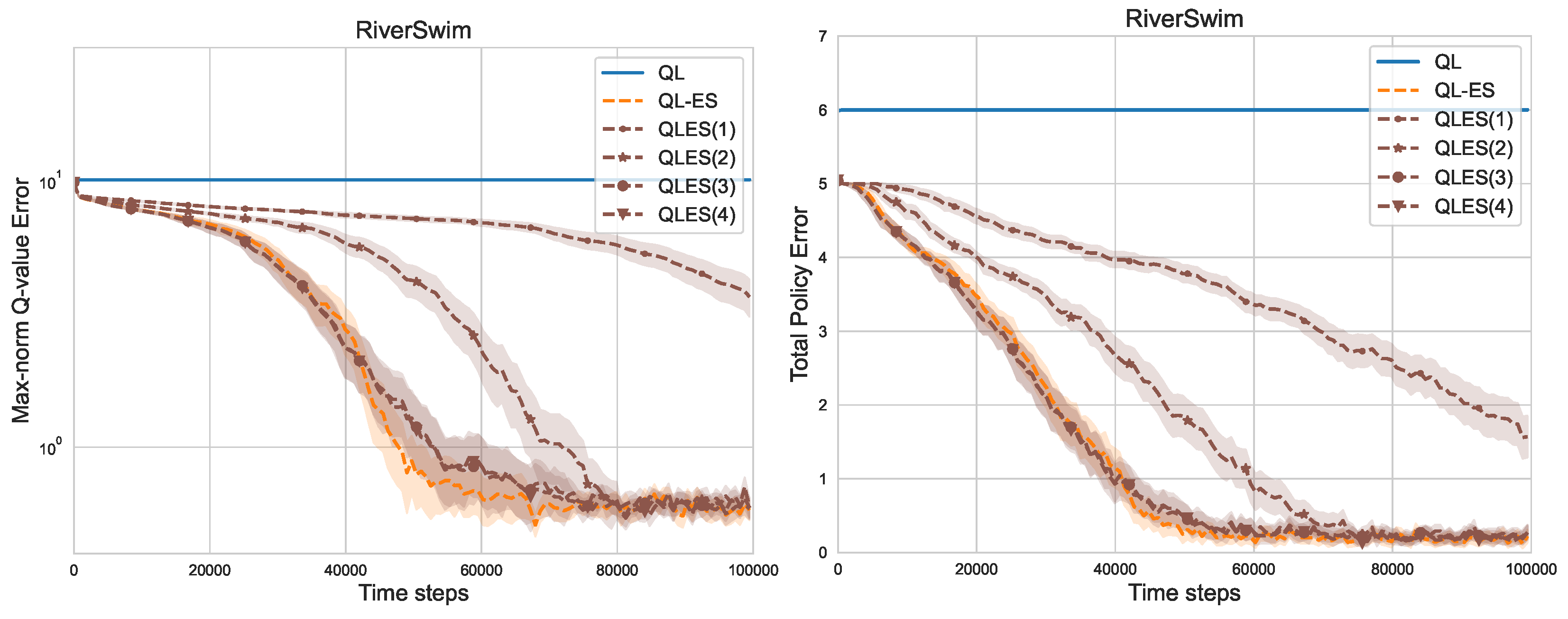
As shown in
Figure 9, we can still obtain reasonable performance only considering a few equivalent pairs. The numbers in brackets represent how many equivalent pairs are used. In RiverSwim with 6 states (
), the performance of QLES(3) and QLES(4) is comparable to QL-ES. Interestingly, we already observe a significant improvement over Q-learning using QLES(1), i.e., when using only one additional observation in the Q-learning update.
Meanwhile, the total policy error is less than or close to one. This shows that the optimal policy is correctly learned in almost all the states.
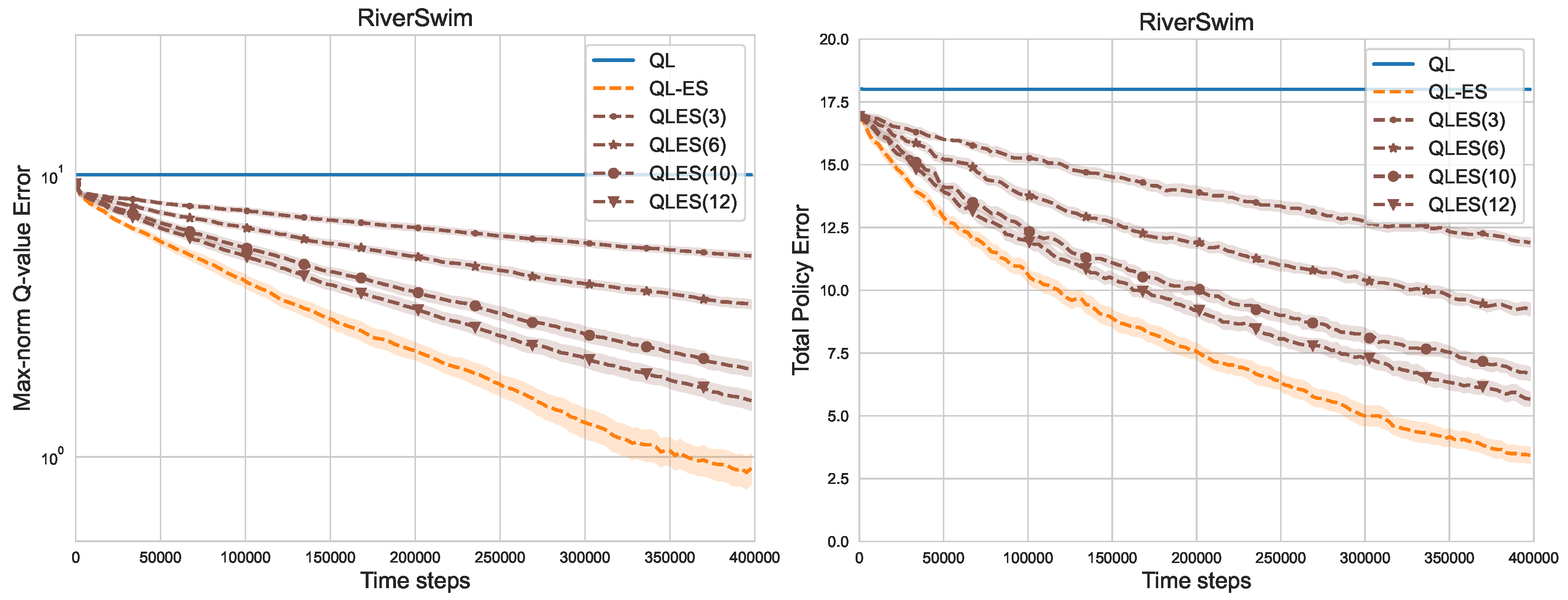
In 20-state RiverSwim (
), algorithms with few equivalent pairs can still achieve excellent performance, albeit not as good as QL-ES. Additionally, as
Figure 10 shows, using more equivalent pairs leads to better sample efficiencies in MDPs with large state space. Concerning QLES(3)-QLES(12), the Q-value error gets smaller when more equivalent pairs are used.
From the perspective of policy, even QLES(3) and QLES(6) manage to find optimal actions significantly faster than Q-learning. In addition, QLES(10) is far superior to QLES(6) because of the quite smaller Q-value error and total policy error. The results show that algorithms with a suitable number of equivalent pairs are sufficient to learn an optimal policy in most states reasonably fast.













{kind=link}
{kind=link}
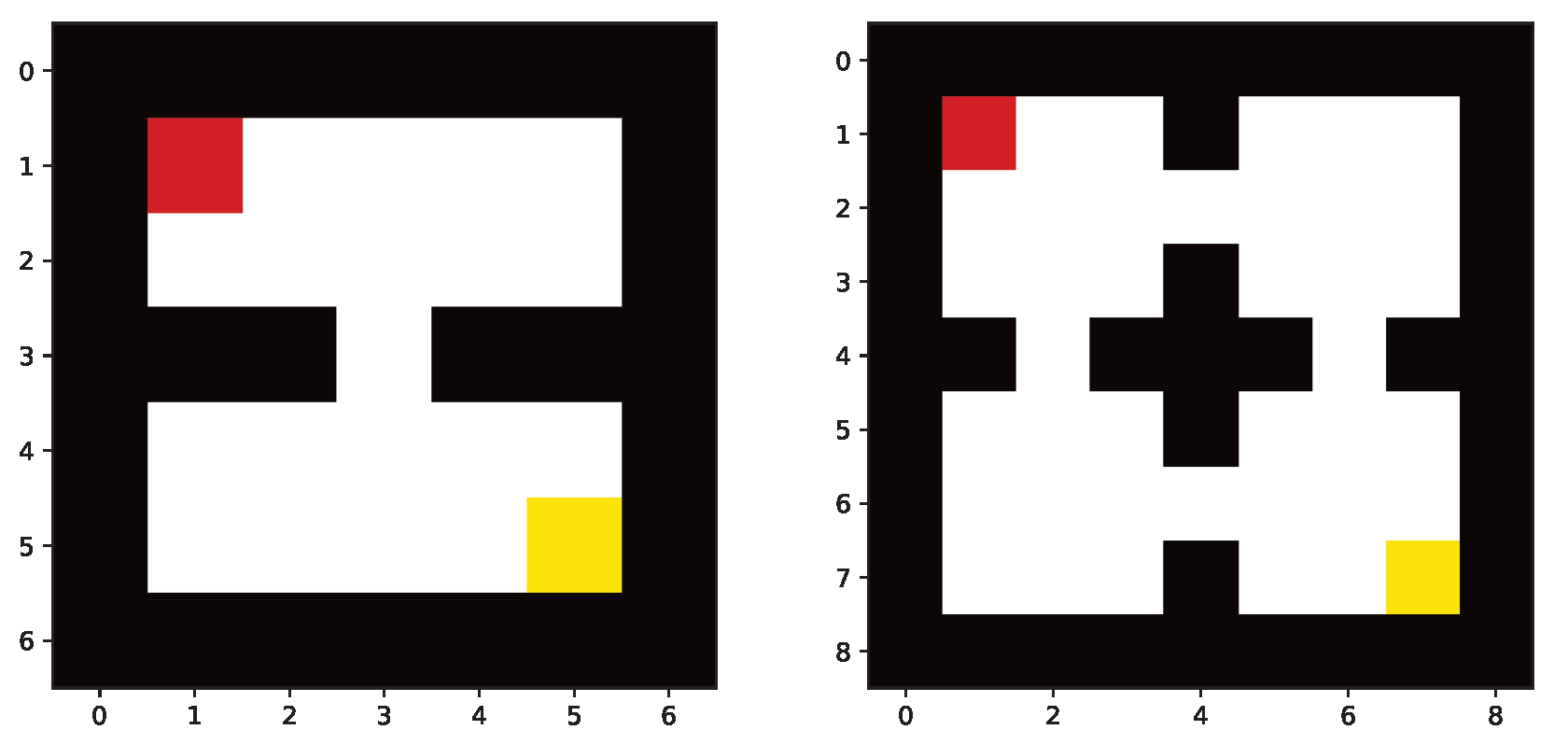{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}