
Second-Order Side-Channel Analysis Based on Orthogonal Transform Nonlinear Regression

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
2.1. Power Model
2.2. Regression Analysis
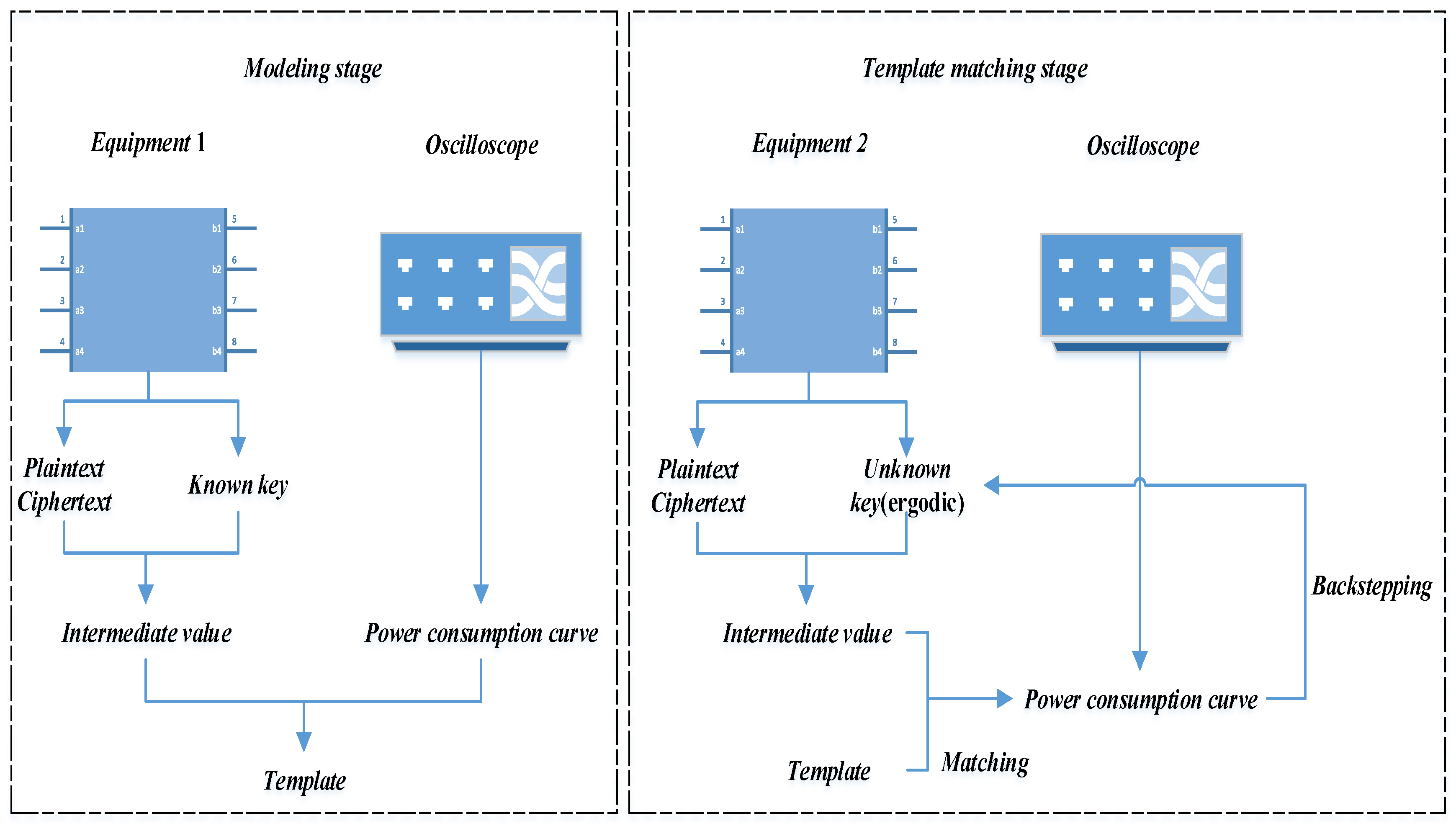
2.3. Template Analysis Based on Linear Regression
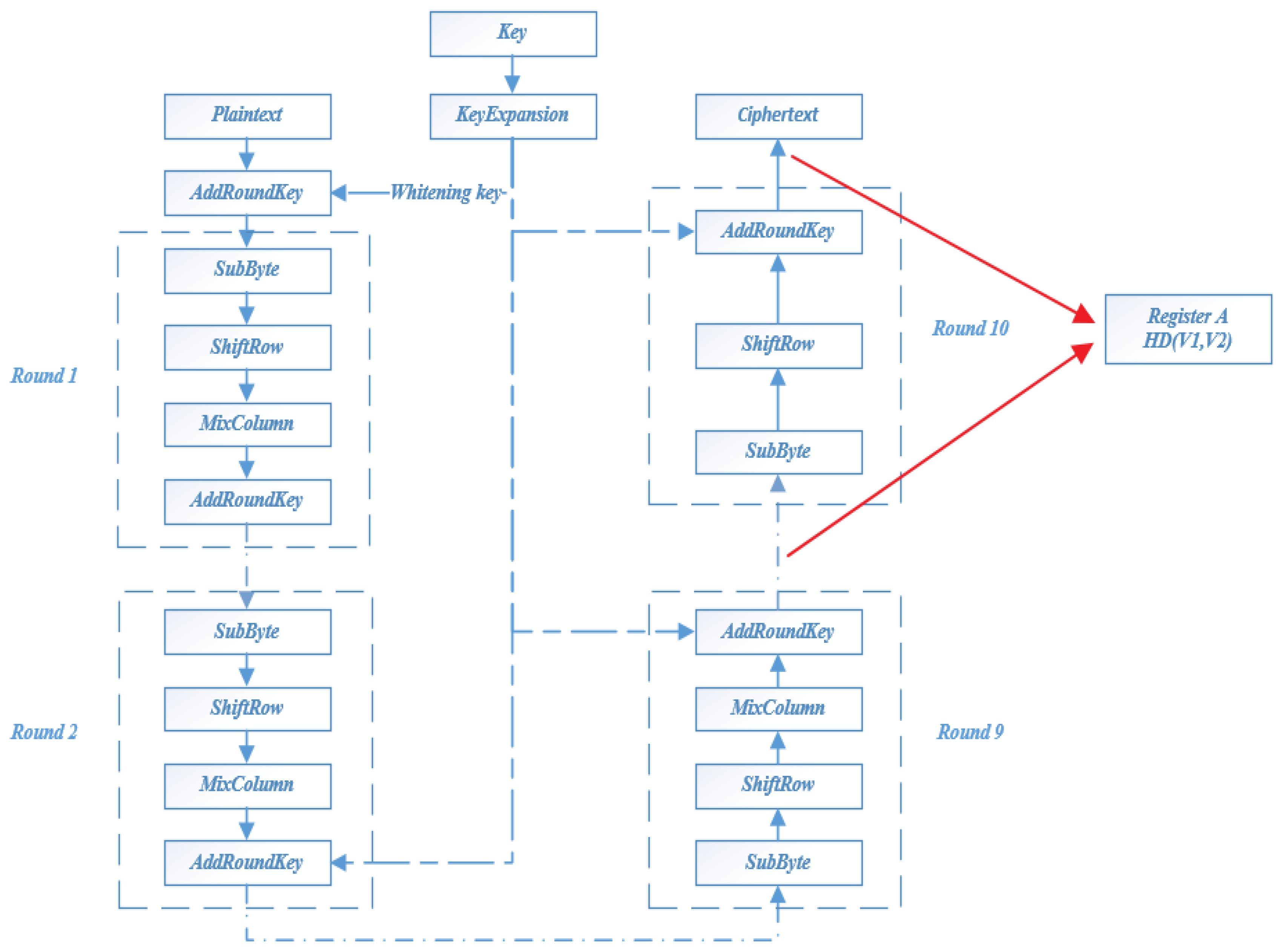
2.4. AES-128 Algorithm
3. Orthogonal Transformation Nonlinear Regression Analysis
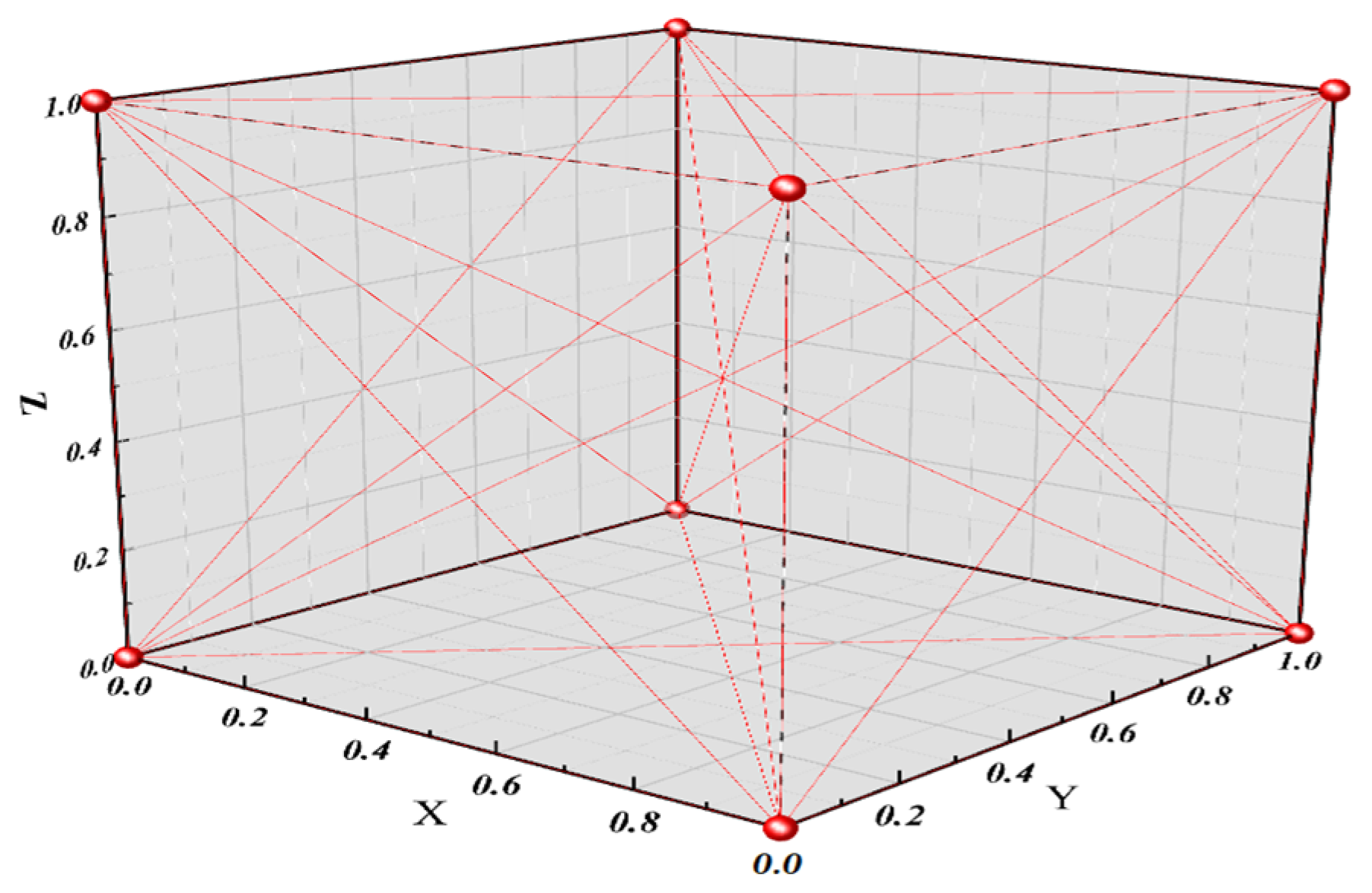
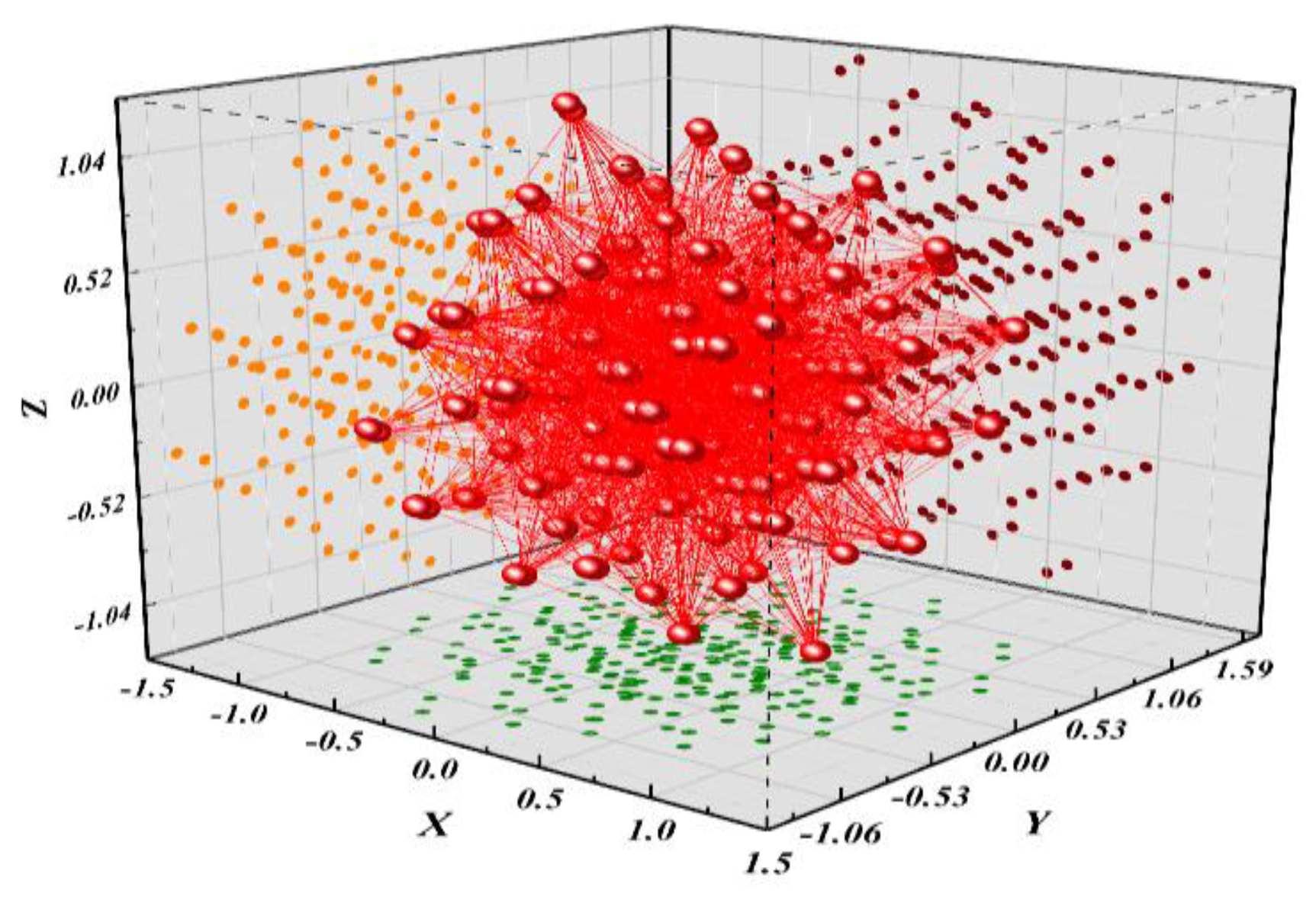
3.1. Orthogonal Transformation Nonlinear Regression Model
3.2. Second-Order Template Analysis Based on Orthogonal Transform Nonlinear Regression
| Algorithm 1 Second-order Template analysis based on orthogonal transform nonlinear regression |
| Begin |
| for S = 1:16 |
| /*Template building stage*/ |
| for p = 1:num |
| end |
| /*template analysis stage*/ |
| for k = 0:255 |
| for p = 1:num |
| end |
| for i = 1:Leakage_point |
| Corr(k + 1, i) = |ρ((:,i), (:,i))| |
| end |
| end |
| [m, n] = find(corr = max (max(corr))) |
| Correct_key(1,S) = m − 1 |
| end |
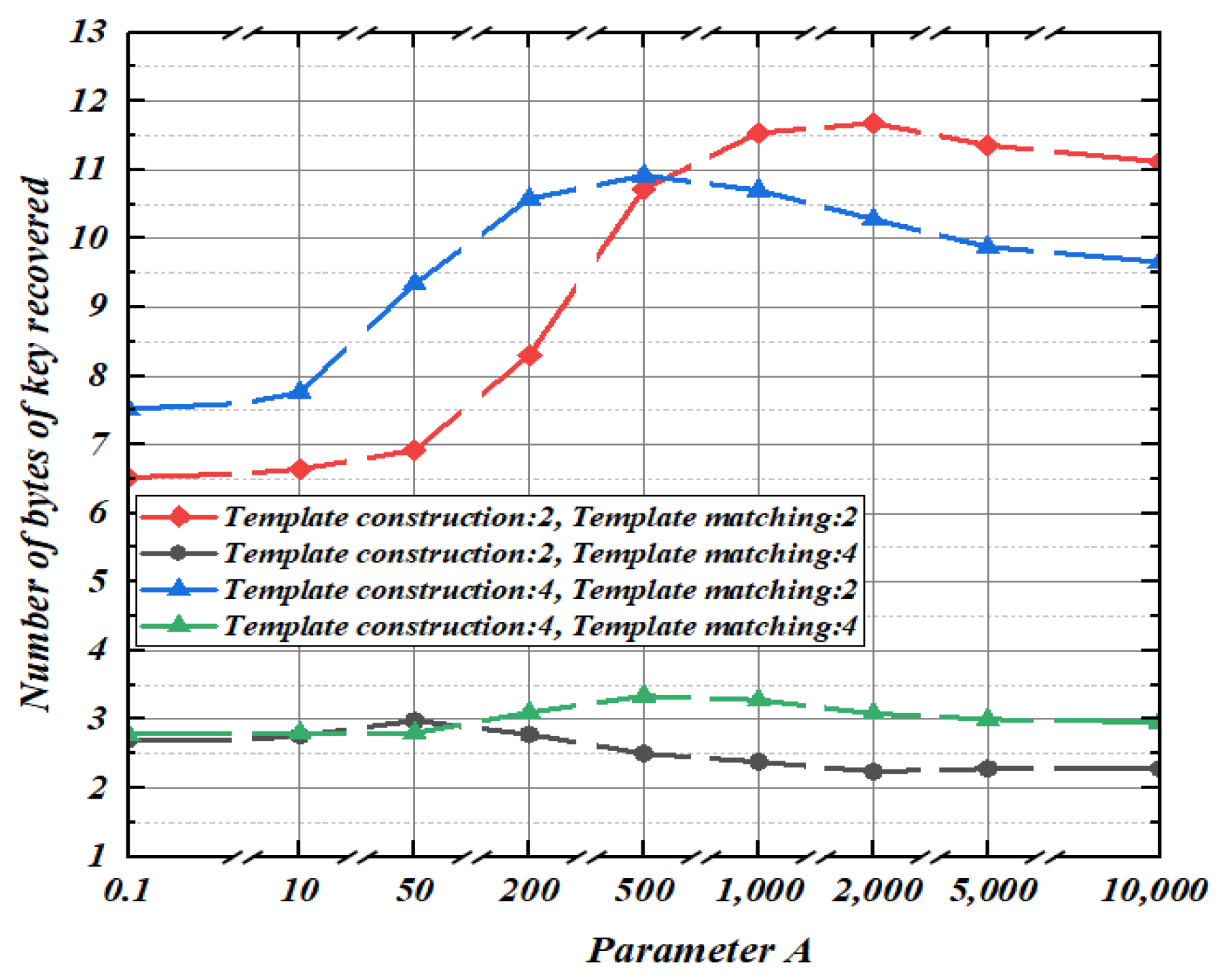
3.3. Parameter Selection
4. Theoretical Analysis
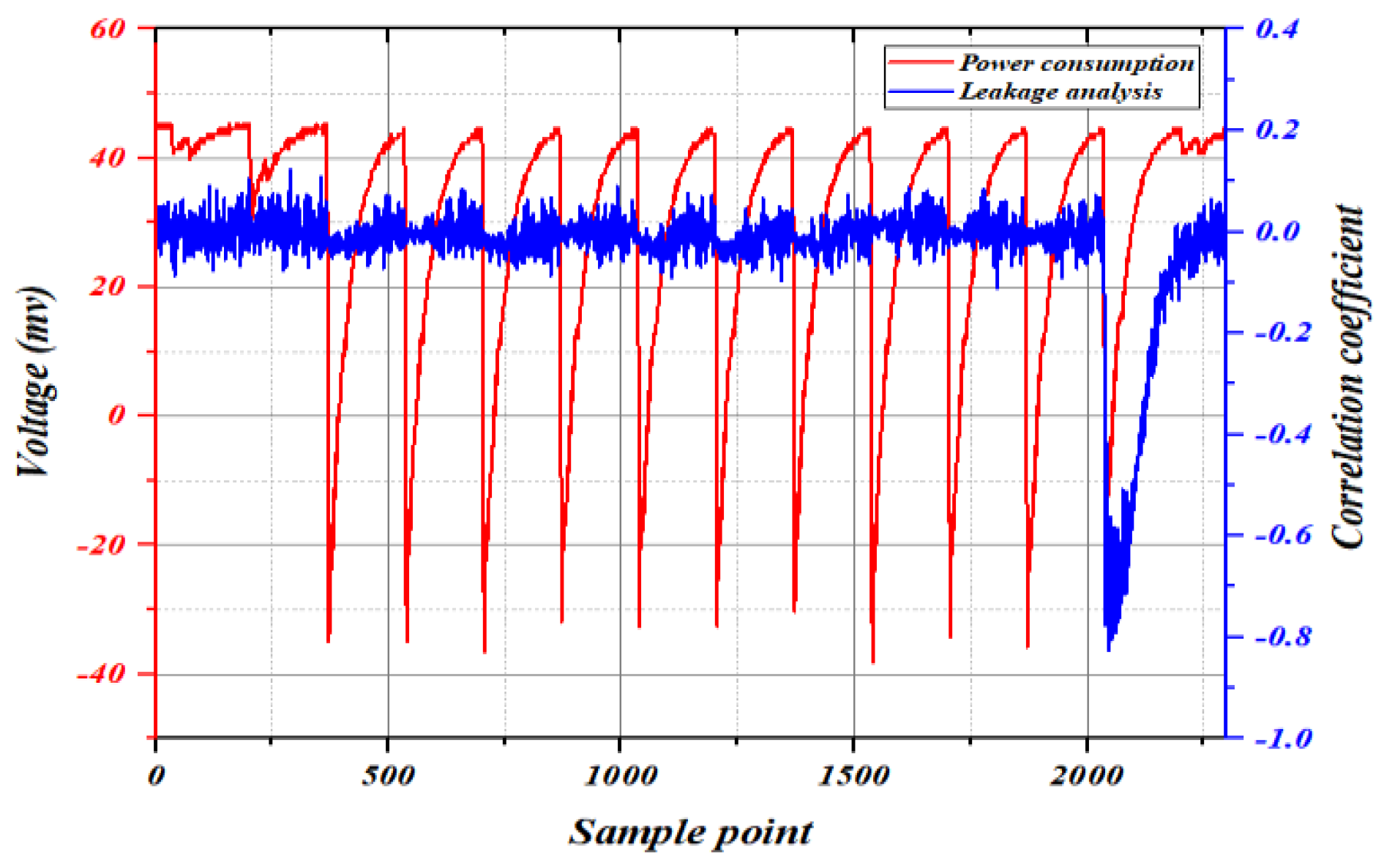
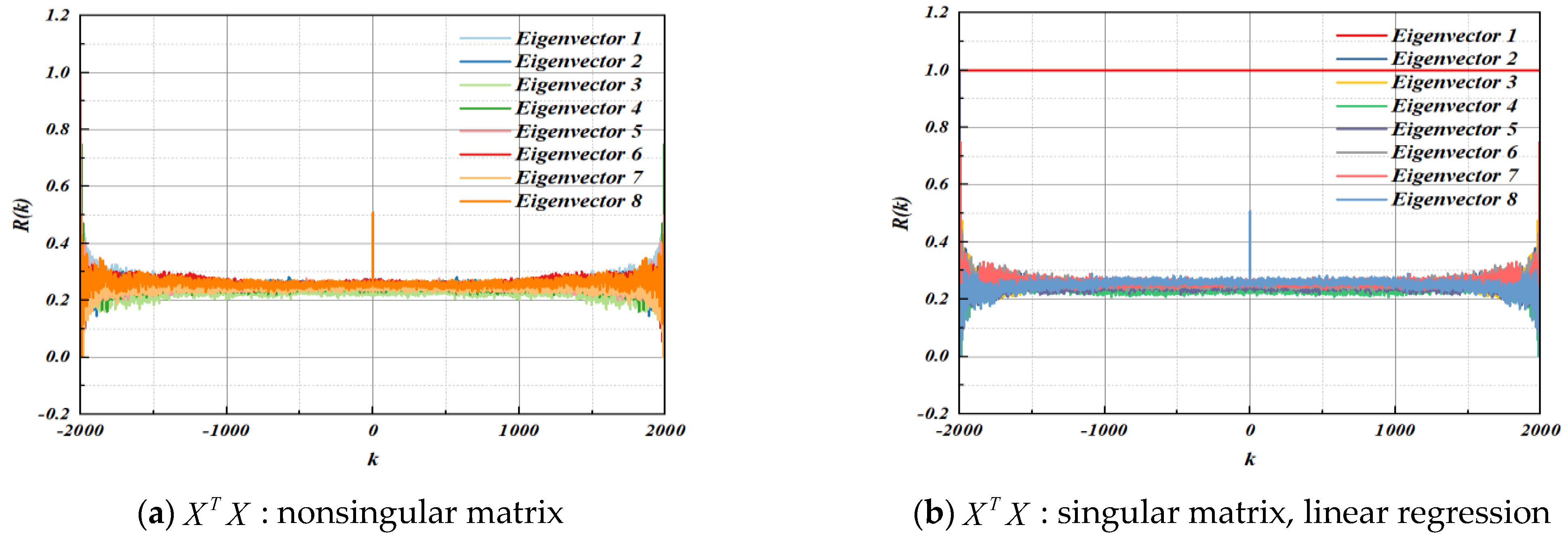
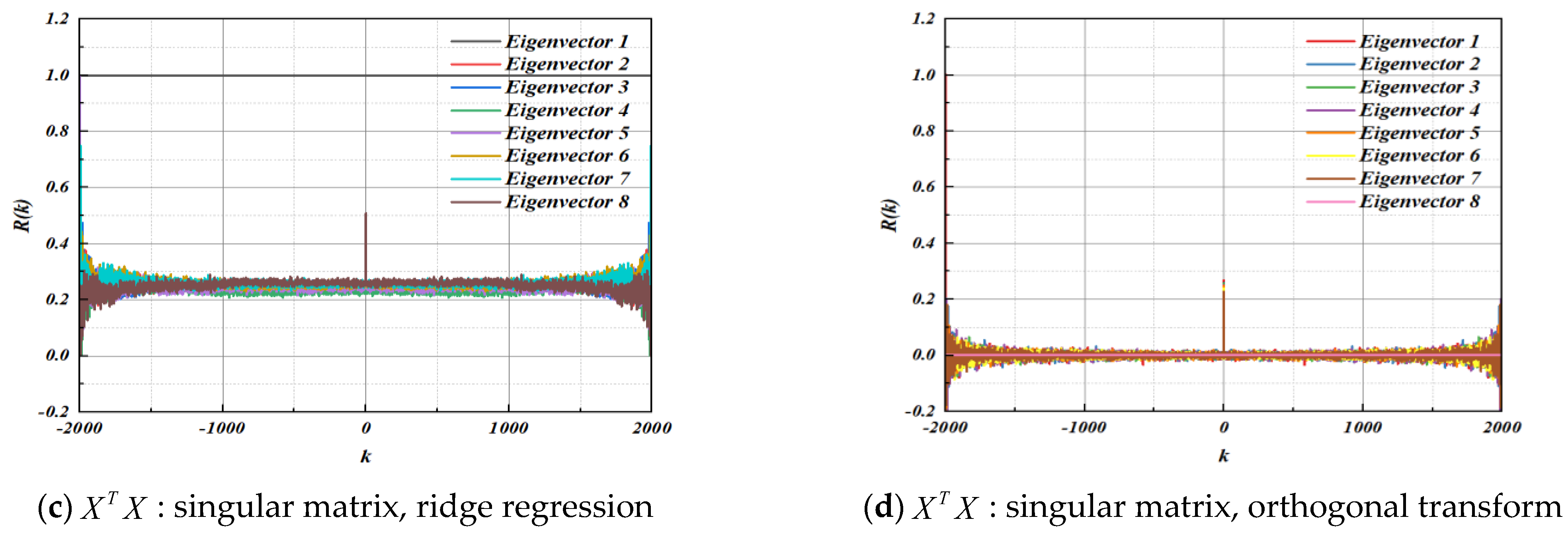
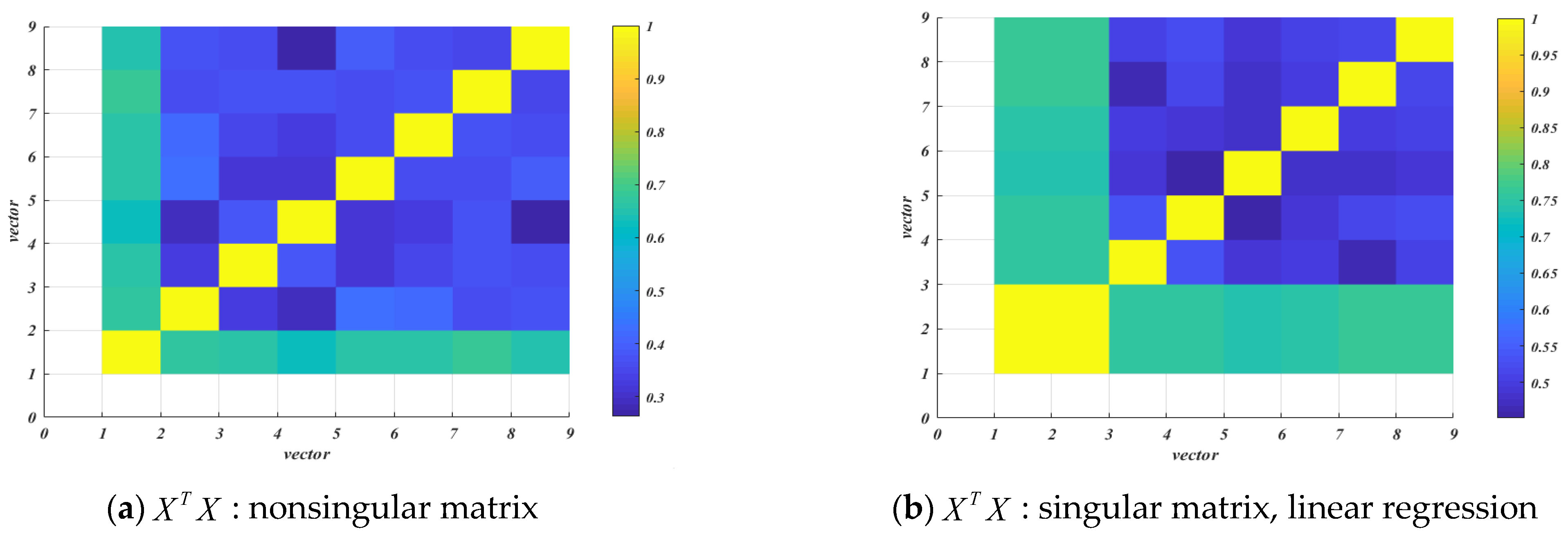
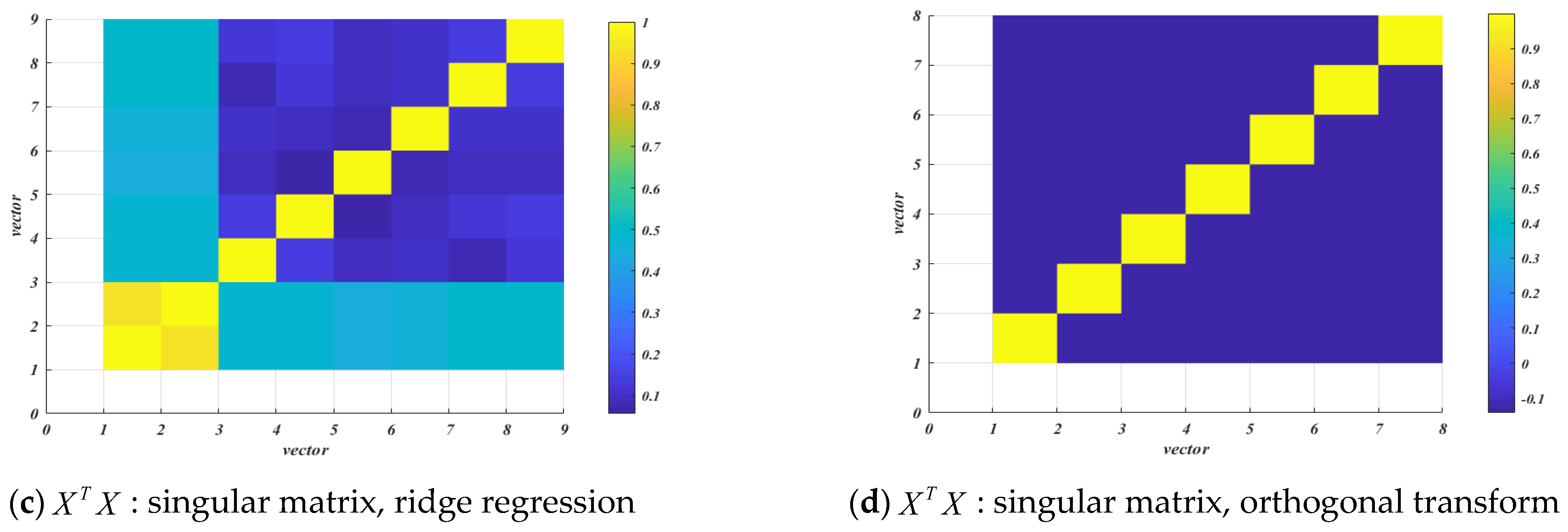
4.1. Autocorrelation Test
4.2. Cross Correlation Test
5. Security Analysis
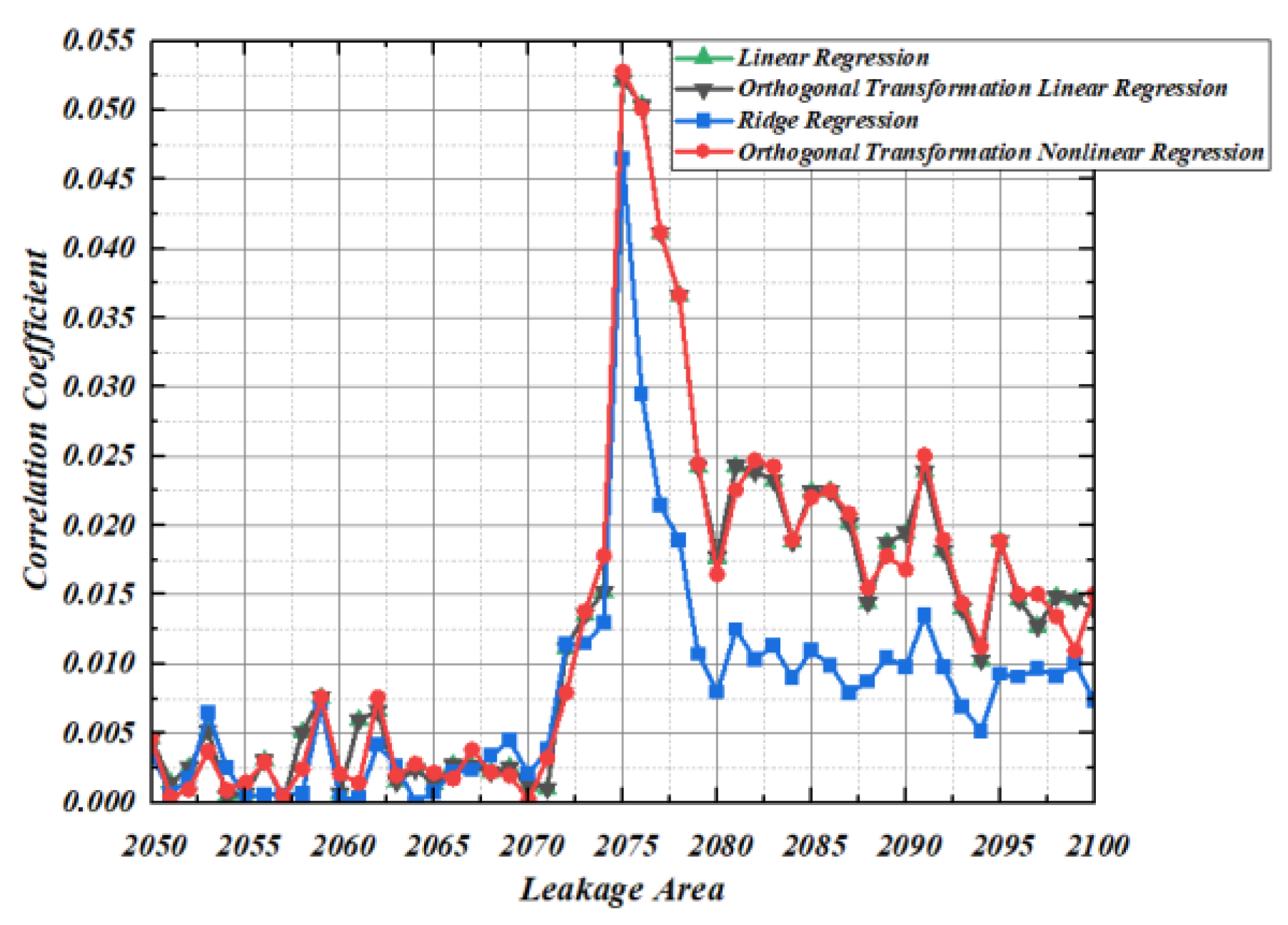
5.1. Correlation of Second-Order Template Based on Regression
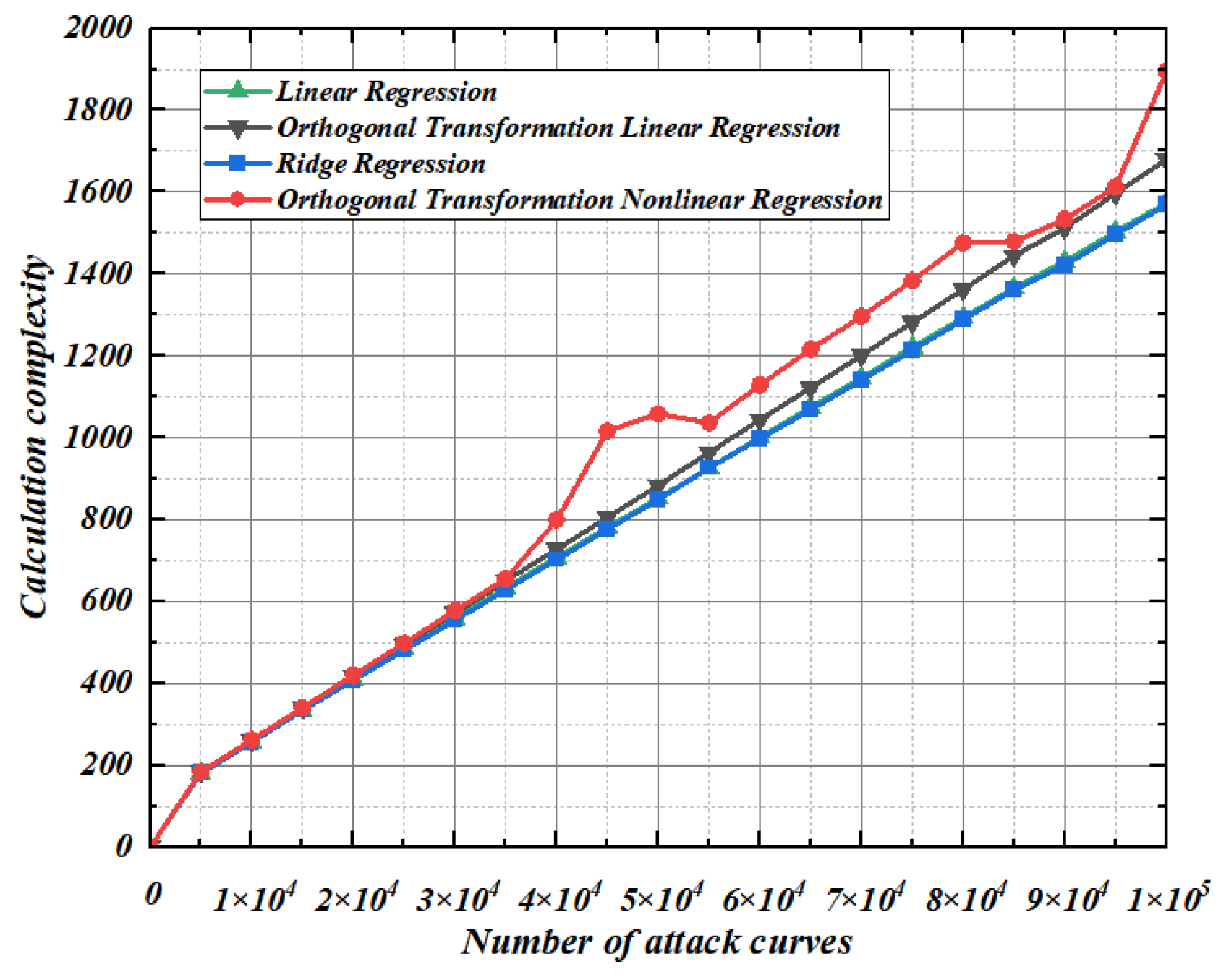
5.2. Calculation Complexity
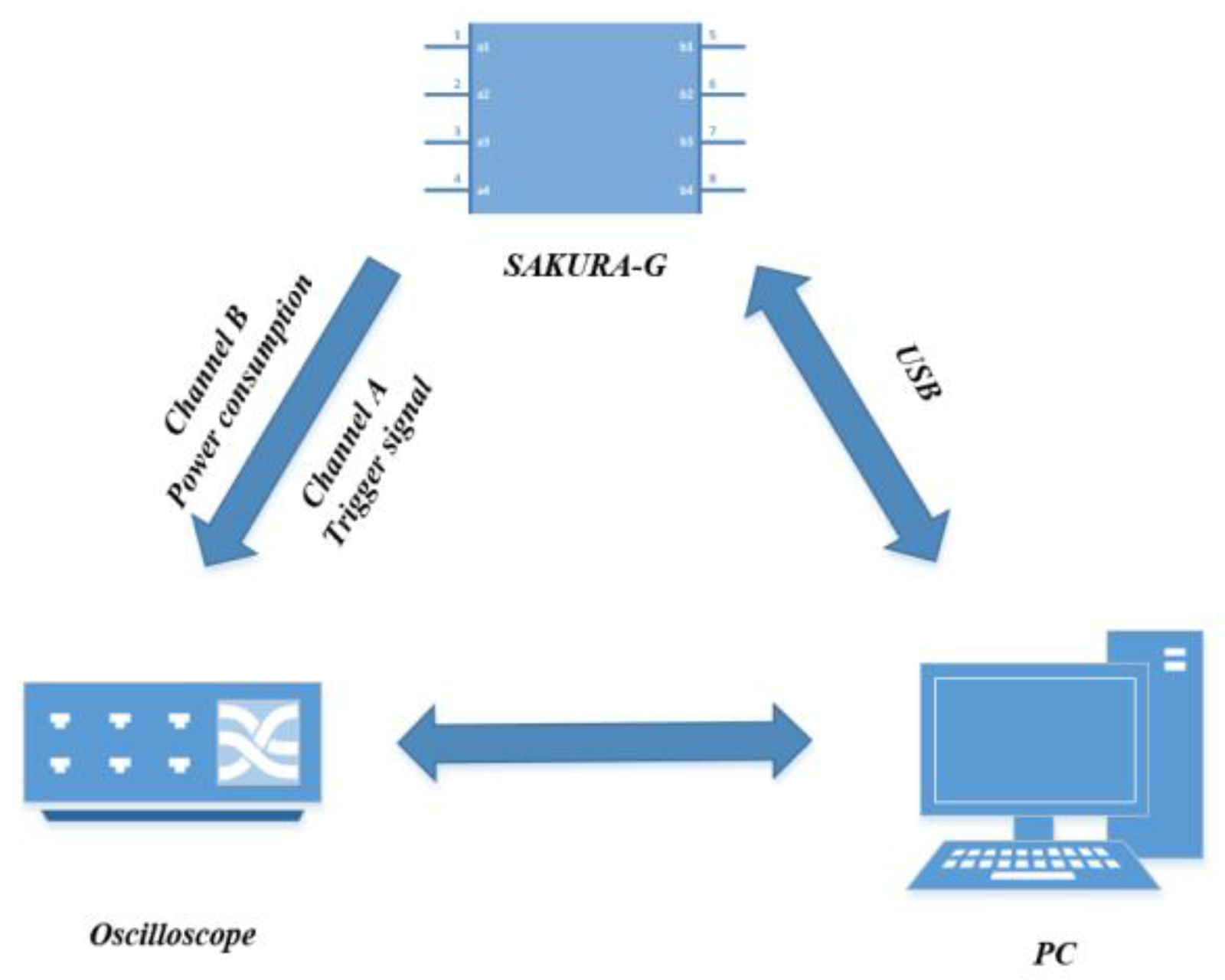
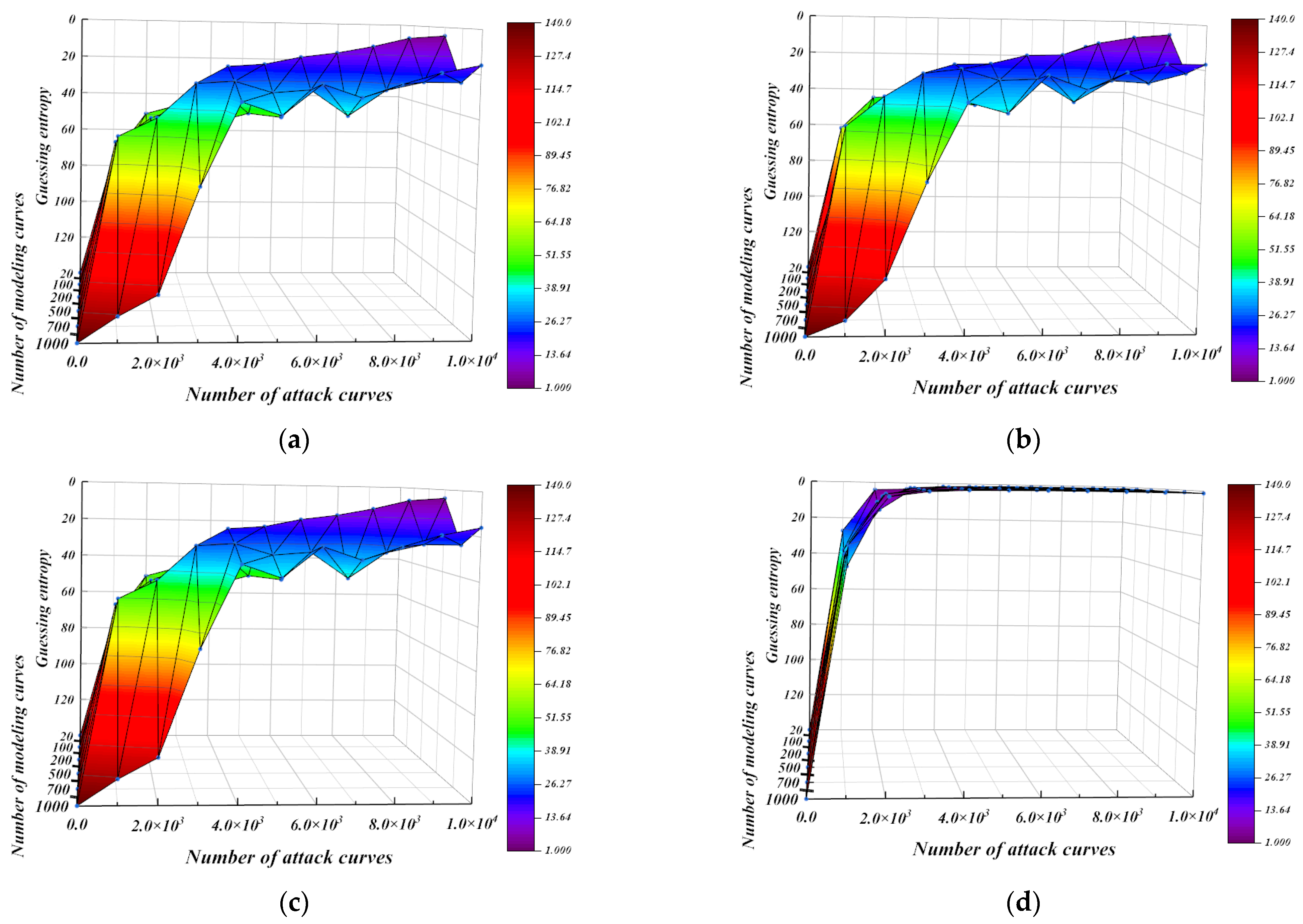
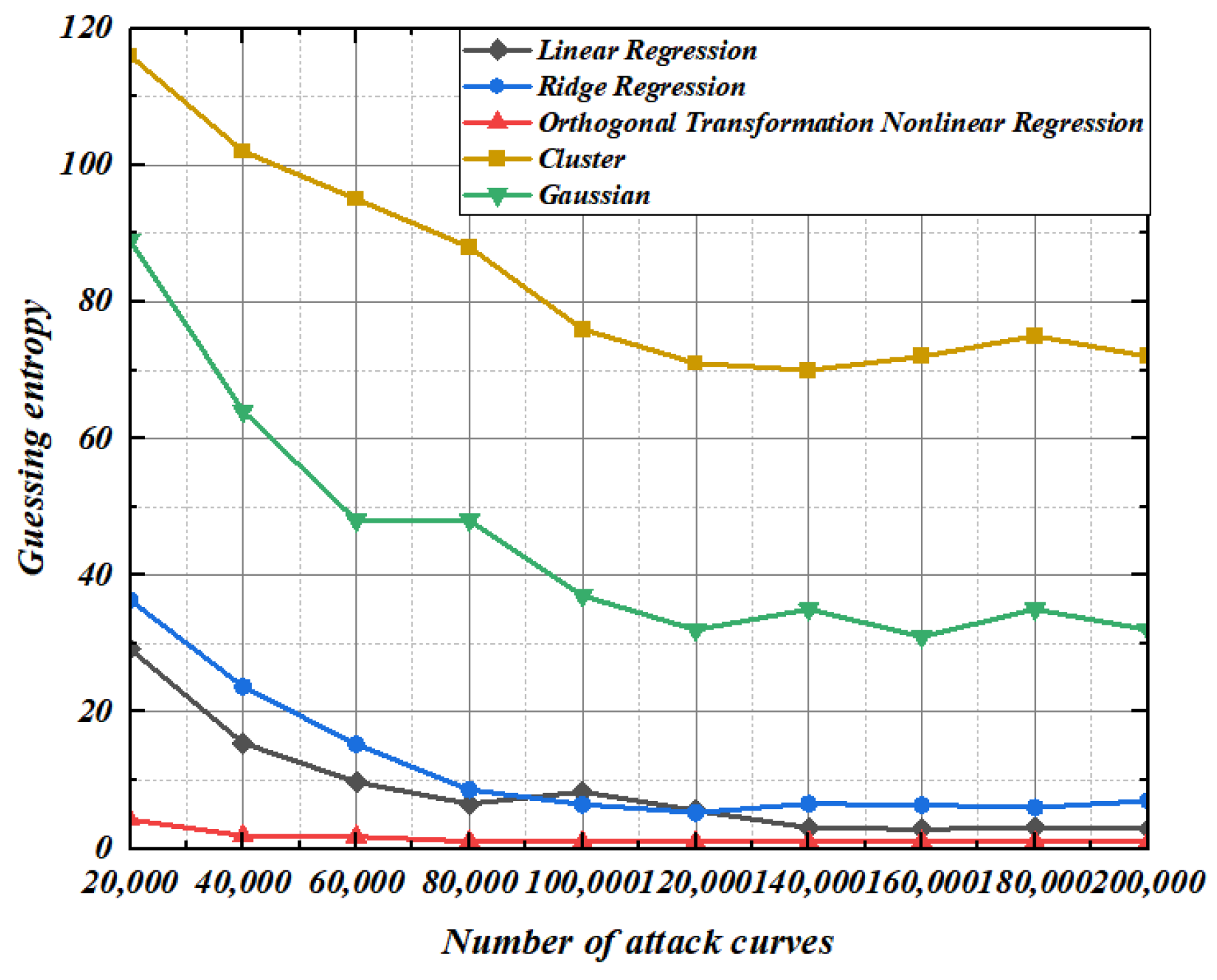
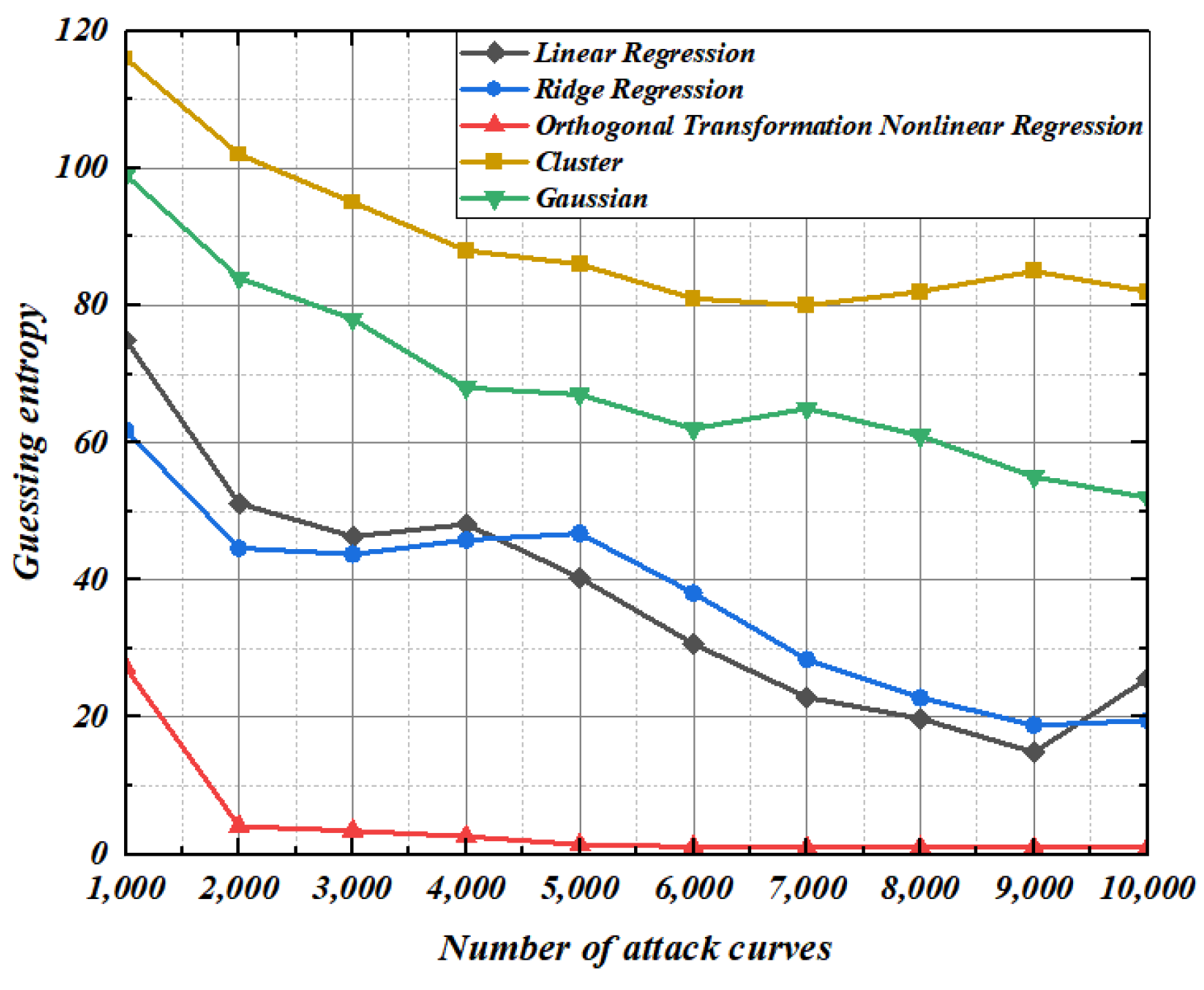
5.3. Guessing Entropy Experiment of Second-Order Template Based on Regression
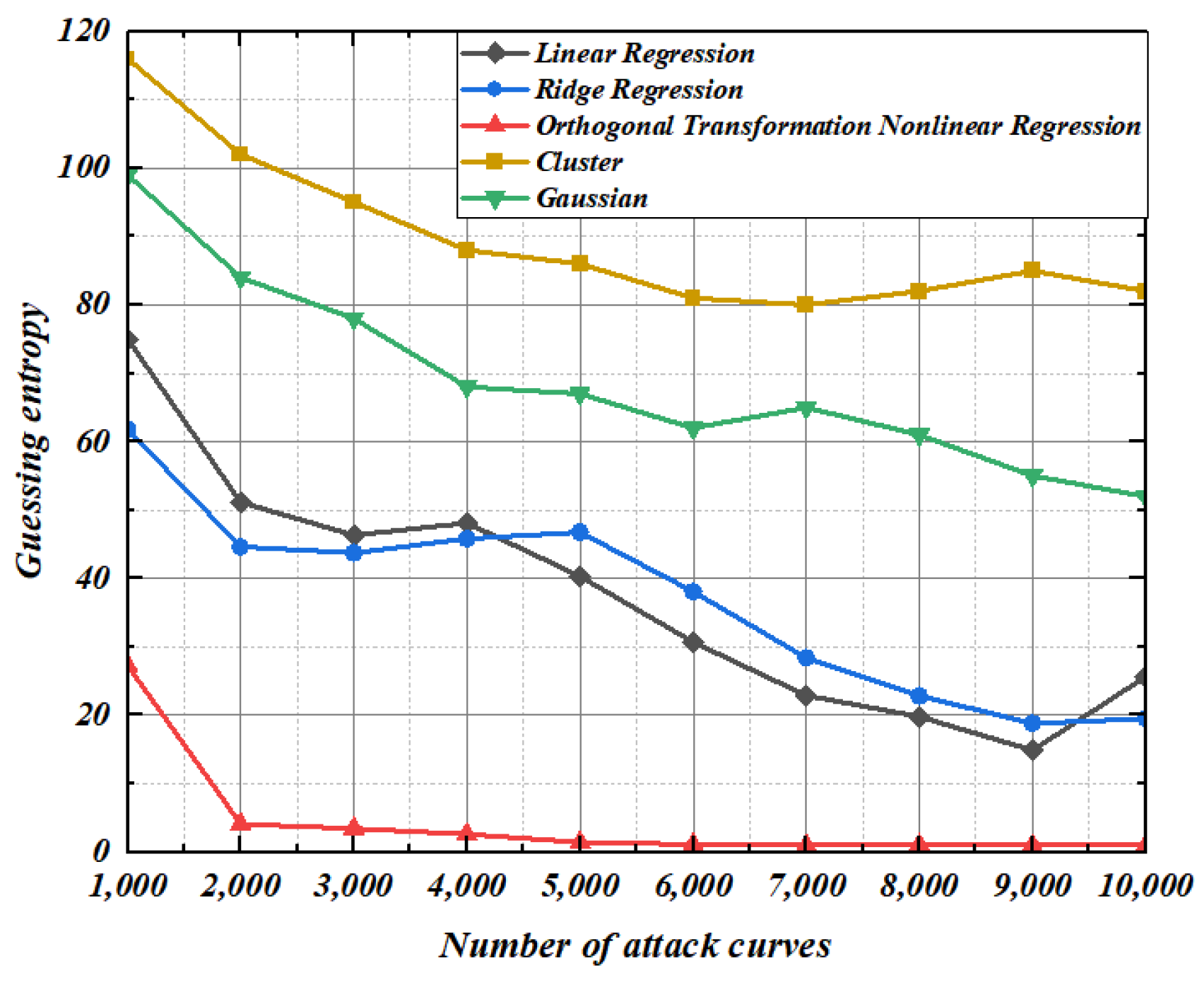
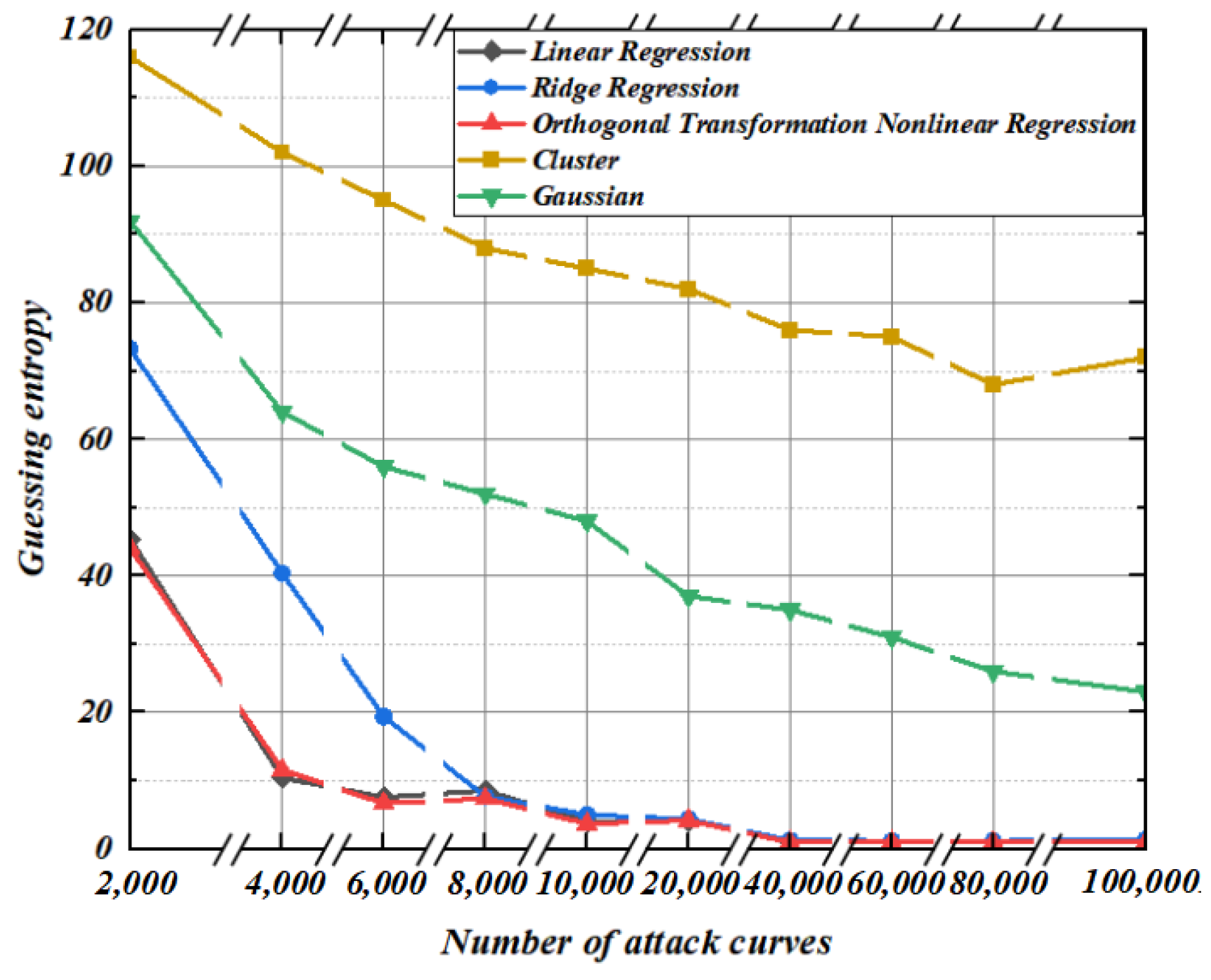
5.4. Guessing Entropy Experiment of Second-Order Template Analysis under Different Noise Conditions
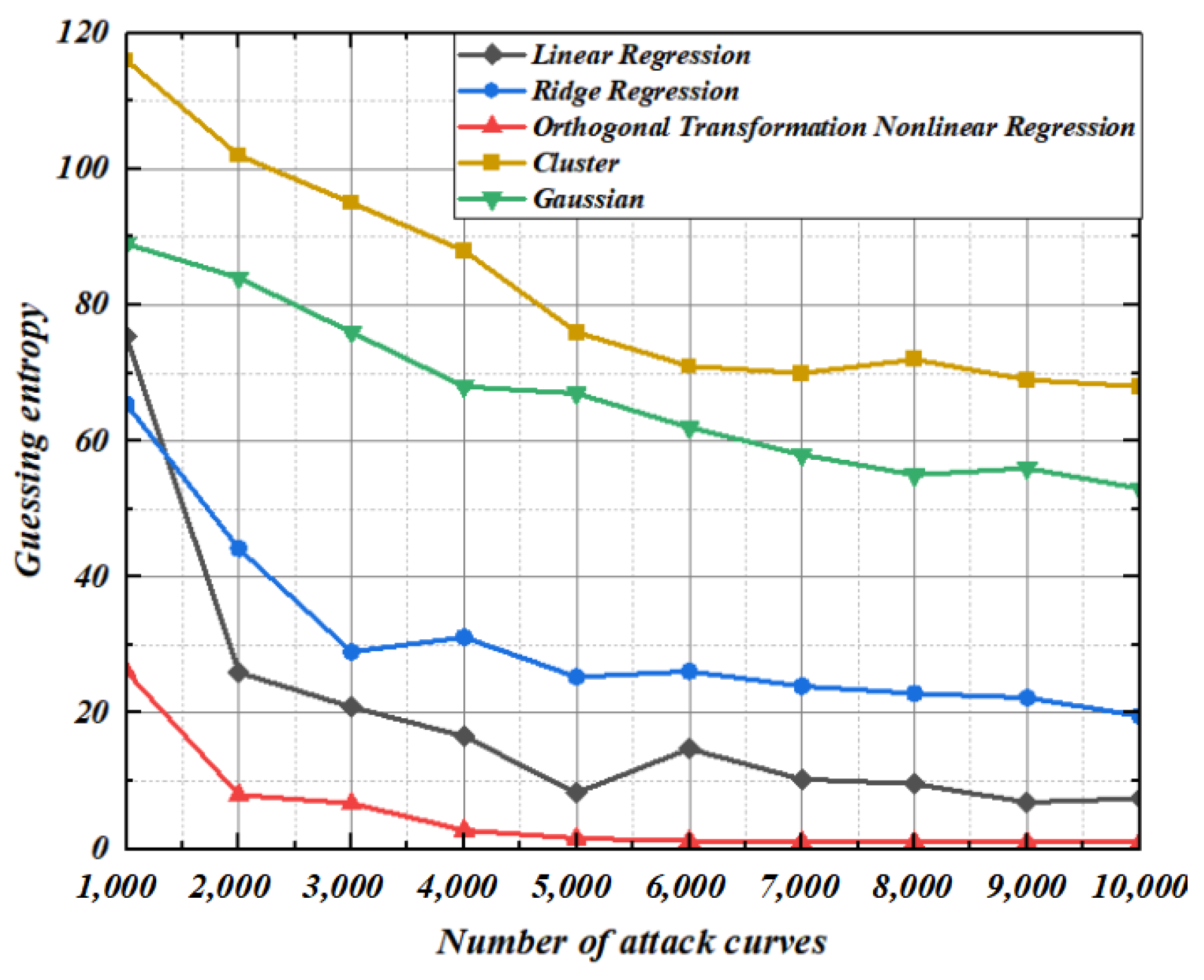
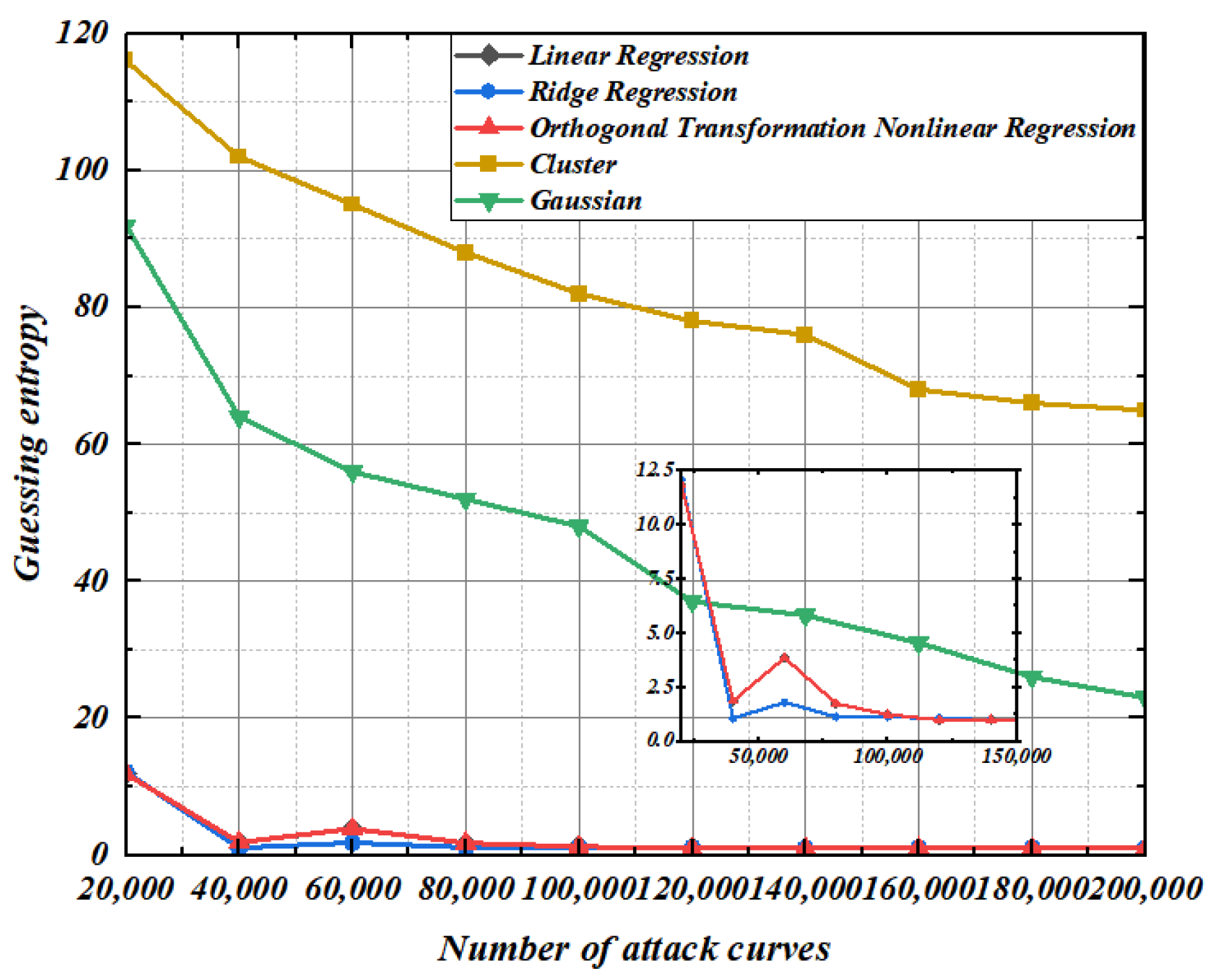
5.5. Guessing Entropy Experiment of Higher-Order Template Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kocher, P.C. Timing attacks on implementations of Diffie-Hellman, RSA, DSS, and other systems. In Proceedings of the Advances in Cryptology—CRYPTO’96: 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; pp. 104–113. [Google Scholar] [CrossRef] [Green Version]
- Kocher, P.C.; Jaffe, J.M.; Jun, B. Differential power analysis. In Proceedings of the Advances in Cryptology—CRYPTO’99: 19th Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 1999; pp. 388–397. [Google Scholar] [CrossRef] [Green Version]
- Brier, E.; Clavier, C.; Olivier, F. Correlation power analysis with a leakage model. In Proceedings of the Cryptographic Hardware and Embedded Systems-CHES 2004: 6th International Workshop, Cambridge, MA, USA, 11–13 August 2004; pp. 16–29. [Google Scholar]
- Cherisey, E.D.; Gillley, S.; Rioul, O. Best Information is Most Successful: Mutual Information and Success Rate in Side-Channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 49–79. [Google Scholar] [CrossRef]
- Prouff, E.; Rivain, M.; Be’van, R. Statistical Analysis of second-order Differential Power Analysis. IEEE Trans. Comput. 2009, 58, 799–811. [Google Scholar] [CrossRef]
- Whitnall, C.; Oswald, E. A Comprehensive Evaluation of Mutual Information Analysis Using a Fair Evaluation Framework. In Proceedings of the Advances in Cryptology–CRYPTO 2011: 31st Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; pp. 316–334. [Google Scholar] [CrossRef] [Green Version]
- Batina, L.; Gierlichs, B.; Prouff, E.; Rivain, M.; Standaert, F.-X.; Veyrat-Charvillon, N. Mutual Information Analysis: A Comprehensive Study. J. Cryptol. 2011, 24, 269–291. [Google Scholar] [CrossRef] [Green Version]
- Chari, S.; Rao, J.R.; Rohatgi, P. Template attacks. In Proceedings of the Cryptographic Hardware and Embedded Systems-CHES 2002: 4th International Workshop, Redwood Shores, CA, USA, 13–15 August 2002; pp. 13–28. [Google Scholar] [CrossRef] [Green Version]
- Archambeau, C.; Peeters, E.; Standaert, F.; Quisquater, J. Template attacks in principal subspaces. In Proceedings of the Cryptographic Hardware and Embedded Systems-CHES 2006: 8th International Workshop, Yokohama, Japan, 10–13 October 2006; pp. 1–14. [Google Scholar]
- Standaert, F.; Archambeau, C. Using subspace-based template attacks to compare and combine power and electromagnetic information leakages. In Proceedings of the Cryptographic Hardware and Embedded Systems–CHES 2008: 10th International Workshop, Washington, DC, USA, 10–13 August 2008; pp. 411–425. [Google Scholar] [CrossRef] [Green Version]
- Lerman, L.; Bontempi, G.; Markowitch, O. The bias–variance decomposition in profiled attacks. J. Cryptograph. Eng. 2015, 5, 255–267. [Google Scholar] [CrossRef]
- Ishai, Y.; Sahai, A.; Wagner, D. Private circuits: Securing hardware against probing attacks. In Proceedings of the Advances in Cryptology―CRYPTO, Santa Barbara, CA, USA, 17–21 August 2003; pp. 463–481. [Google Scholar]
- Choudary, O.; Kuhn, M.G. Efficient Template attacks. In Proceedings of the Smart Card Research and Advanced Applications: 12th International Conference, CARDIS 2013, Berlin, Germany, 27–29 November 2013; pp. 253–270. [Google Scholar] [CrossRef] [Green Version]
- Oswald, E.; Mangard, S. Template Attacks on Masking—Resistance Is Futile. In Proceedings of the Topics in Cryptology–CT-RSA 2007: The Cryptographers’ Track at the RSA Conference 2007, San Francisco, CA, USA, 5–9 February 2007; pp. 243–256. [Google Scholar] [CrossRef]
- Agrawal, D.; Archambeault, B.; Rao, J.R. The EM side-channel(s). In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2002, Redwood Shores, CA, USA, 13–15 August 2002; pp. 29–45. [Google Scholar] [CrossRef] [Green Version]
- Montminy, D.P.; Baldwin, R.O.; Temple, M.A. Differential electromagnetic attacks on a 32-bit microprocessor using software defined radios. IEEE Trans. Inf. Secur. 2013, 8, 2101–2114. [Google Scholar] [CrossRef]
- Schramm, K.; Wollinger, T.; Paar, C. A new class of collision attacks and its application to DES. In Proceedings of the Fast Software Encryption: 10th International Workshop, FSE 2003, Lund, Sweden, 24–26 February 2003; pp. 206–222. [Google Scholar]
- Bogdanov, A.; Kizhvatov, I. Beyond the limits of DPA: Combined side-channel collision attacks. IEEE Trans. Comput. 2012, 61, 1153–1164. [Google Scholar] [CrossRef] [Green Version]
- Biham, E.; Shamir, A. Differential fault analysis of secret key cryptosystems. In Proceedings of the Advances in Cryptology—CRYPTO’97: 17th Annual International Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 1997; pp. 513–525. [Google Scholar]
- Li, Y.; Sakiyama, K.; Gomisawa, S. Fault sensitivity analysis. In Proceedings of the Cryptographic Hardware and Embedded Systems, CHES 2010: 12th International Workshop, Santa Barbara, CA, USA, 17–20 August 2010; pp. 320–334. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.; Chen, M.; Wang, Z.Y. Fault rate analysis: Breaking masked AES hardware implementations efficiently. IEEE Trans. Circuits Syst. II Express Briefs 2013, 60, 517–521. [Google Scholar] [CrossRef]
- Prouff, E.; Strullu, R.; Benadjil, A.R. Study of deep learning techniques for side-channel analysis and introduction to ASCAD database. J. Cryptogr. Eng. 2018, 10, 2018–2064. [Google Scholar] [CrossRef]
- Robyns, P.; Quax, P.; Lamotte, W. Improving CEMA using correlation optimization. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 1–24. [Google Scholar] [CrossRef]
- Carbone, M.; Conin, V.; Cornelie, M. Deep learning to evaluate secure RSA implementations. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 132–161. [Google Scholar] [CrossRef]
- Hospodar, G.; Gierlichs, B.; Mulder, E.D. Machine learning in side channel analysis: A first study. J. Cryptogr. Eng. 2011, 1, 293–302. [Google Scholar] [CrossRef]
- Wang, W.J.; Yu, Y.; Standaert, F.X.; Liu, J.R.; Guo, Z.; Gu, D.W. Ridge-Based DPA: Improvement of Differential Power Analysis For Nanoscale Chips. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1301–1316. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Wang, W.; Yu, Y.; Standaert, F.; Gu, D.; Xu, S.; Zhang, C. Ridge-based profiled differential power analysis. In Proceedings of the Topics in Cryptology–CT-RSA 2017: The Cryptographers’ Track at the RSA Conference 2017, San Francisco, CA, USA, 14–17 February 2017; pp. 347–362. [Google Scholar] [CrossRef]
- Doget, J.; Prouff, E.; Rivain, M.; Standaert, F.-X. Univariate Side Channel Attacks and Leakage Modeling. J. Cryptogr. Eng. 2011, 1, 123–144. [Google Scholar] [CrossRef]
- Whitnall, C.; Oswald, E. Robust Profiling for DPA-Style Attacks. In Proceedings of the Cryptographic Hardware and Embedded Systems--CHES 2015: 17th International Workshop, Saint-Malo, France, 13–16 September 2015; pp. 13–16. [Google Scholar] [CrossRef] [Green Version]





















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Ding, Q. Second-Order Side-Channel Analysis Based on Orthogonal Transform Nonlinear Regression. Entropy 2023, 25, 505. https://doi.org/10.3390/e25030505
Jiang Z, Ding Q. Second-Order Side-Channel Analysis Based on Orthogonal Transform Nonlinear Regression. Entropy. 2023; 25(3):505. https://doi.org/10.3390/e25030505
Chicago/Turabian StyleJiang, Zijing, and Qun Ding. 2023. "Second-Order Side-Channel Analysis Based on Orthogonal Transform Nonlinear Regression" Entropy 25, no. 3: 505. https://doi.org/10.3390/e25030505