
Improving Multiple Pedestrian Tracking in Crowded Scenes with Hierarchical Association

Abstract
:1. Introduction
- We follow the tracking-by-regression pattern and propose a hierarchical strategy for online multiple pedestrian tracking, especially for crowded scenes. By our deliberate design, the proposed method successfully locates and tracks many small and partially occluded objects.
- We seamlessly incorporate the hierarchical strategy into our tracking framework and capture spatial–temporal cues by constructing a history-aware mask. Thus, we can directly infer both obvious and partially occluded pedestrians.
2. Related Work
2.1. Tracking-by-Detection
2.2. New MPT Directions
2.3. Tracking in Crowded Scenes
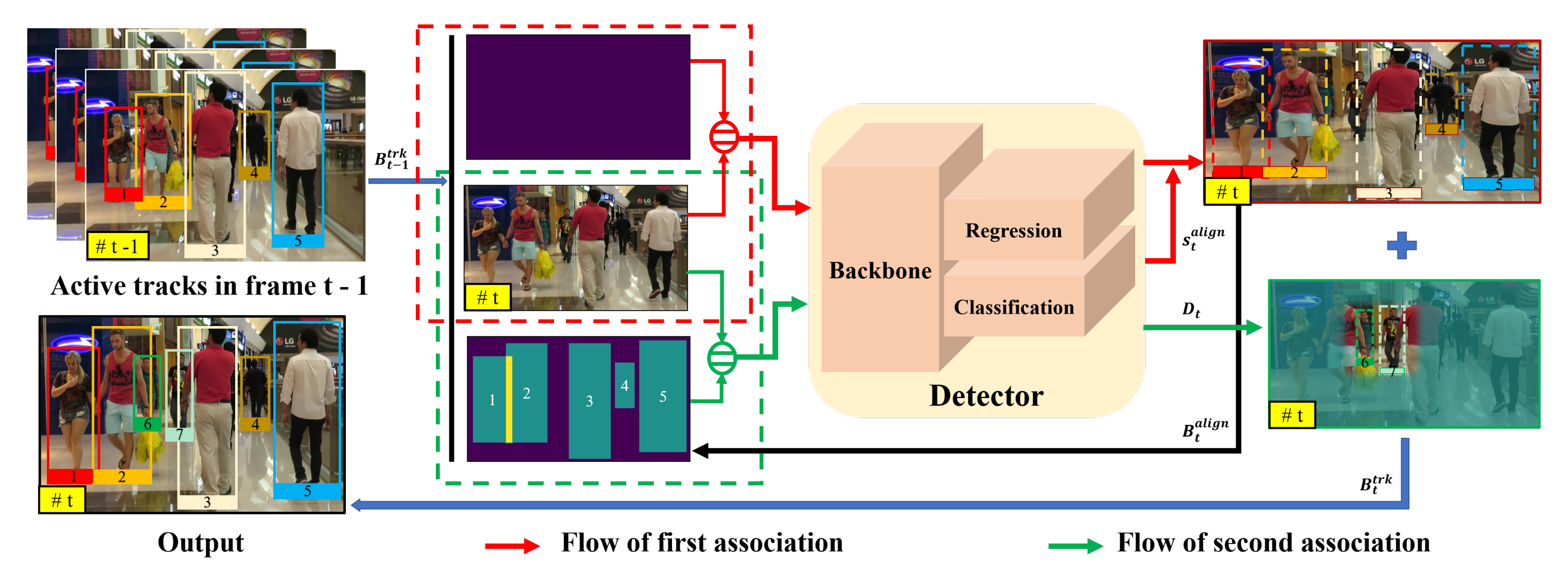
3. Proposed Method
3.1. Problem Formulation
3.2. Network Architecture
3.3. Inference Algorithm
3.3.1. First Association
3.3.2. Second Association
| Algorithm 1 The proposed tracker. |
| Input: Video sequence of frame at time t and public detection set of detections for frame . |
| Output: Trajectory set , with as a list of ordered object bounding boxes . |
|
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.2.1. Training
4.2.2. Inference
4.3. Benchmark Evaluation
4.4. Ablation Studies
4.5. Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep Affinity Network for Multiple Object Tracking. arXiv 2018, arXiv:1810.11780. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking Objects as Points. arXiv 2020, arXiv:2004.01177. [Google Scholar]
- Yang, K.; Li, D.; Dou, Y. Towards Precise End-to-End Weakly Supervised Object Detection Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8371–8380. [Google Scholar] [CrossRef] [Green Version]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple people tracking by lifted multicut and person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3539–3548. [Google Scholar]
- Lan, L.; Tao, D.; Gong, C.; Guan, N.; Luo, Z. Online Multi-Object Tracking by Quadratic Pseudo-Boolean Optimization. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3396–3402. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to track and track to detect. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3038–3046. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Bergmann, P.; Meinhardt, T.; Leal-Taixé, L. Tracking without bells and whistles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar]
- Wang, G.; Wang, Y.; Zhang, H.; Gu, R.; Hwang, J.N. Exploit the connectivity: Multi-object tracking with trackletnet. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 482–490. [Google Scholar]
- Xu, J.; Cao, Y.; Zhang, Z.; Hu, H. Spatial-temporal relation networks for multi-object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3988–3998. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Henschel, R.; Zou, Y.; Rosenhahn, B. Multiple people tracking using body and joint detections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xiang, J.; Xu, G.; Ma, C.; Hou, J. End-to-end learning deep crf models for multi-object tracking. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 275–288. [Google Scholar] [CrossRef]
- Peng, J.; Wang, T.; Lin, W.; Wang, J.; See, J.; Wen, S.; Ding, E. TPM: Multiple Object Tracking with Tracklet-Plane Matching. Pattern Recognit. 2020, 107, 107480. [Google Scholar] [CrossRef]
- Feng, W.; Lan, L.; Luo, Y.; Yu, Y.; Zhang, X.; Luo, Z. Near-Online Multi-Pedestrian Tracking via Combining Multiple Consistent Appearance Cues. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1540–1554. [Google Scholar] [CrossRef]
- Fu, Z.; Angelini, F.; Chambers, J.; Naqvi, S.M. Multi-level cooperative fusion of GM-PHD filters for online multiple human tracking. IEEE Trans. Multimed. 2019, 21, 2277–2291. [Google Scholar] [CrossRef] [Green Version]
- Yoon, K.; Gwak, J.; Song, Y.M.; Yoon, Y.C.; Jeon, M.G. OneShotDA: Online Multi-Object Tracker With One-Shot-Learning-Based Data Association. IEEE Access 2020, 8, 38060–38072. [Google Scholar] [CrossRef]
- Chu, P.; Ling, H. Famnet: Joint learning of feature, affinity and multi-dimensional assignment for online multiple object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6172–6181. [Google Scholar]
- Wang, F.; Luo, L.; Zhu, E. Two-Stage Real-Time Multi-object Tracking with Candidate Selection. In Proceedings of the MultiMedia Modeling, Prague, Czech Republic, 22–24 June 2021; Lokoč, J., Skopal, T., Schoeffmann, K., Mezaris, V., Li, X., Vrochidis, S., Patras, I., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 49–61. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Yang, C.; Yang, F.; Zhuang, Y.; Zhang, Z.; Jia, H.; Xie, X. Trajectory factory: Tracklet cleaving and re-connection by deep siamese bi-gru for multiple object tracking. In Proceedings of the International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Kieritz, H.; Hubner, W.; Arens, M. Joint detection and online multi-object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1459–1467. [Google Scholar]
- Liu, Q.; Chu, Q.; Liu, B.; Yu, N. GSM: Graph Similarity Model for Multi-Object Tracking. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence—International Joint Conferences on Artificial Intelligence Organization, Yokohama, Japan, 11–17 July 2020; pp. 530–536. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Liang, C.; Zhang, Z.; Lu, Y.; Zhou, X.; Li, B.; Ye, X.; Zou, J. Rethinking the competition between detection and ReID in Multi-Object Tracking. arXiv 2020, arXiv:2010.12138. [Google Scholar]
- Wu, J.; Cao, J.; Song, L.; Wang, Y.; Yang, M.; Yuan, J. Track to Detect and Segment: An Online Multi-Object Tracker. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Guo, S.; Wang, J.; Wang, X.; Tao, D. Online Multiple Object Tracking With Cross-Task Synergy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hornakova, A.; Henschel, R.; Rosenhahn, B.; Swoboda, P. Lifted Disjoint Paths with Application in Multiple Object Tracking. In Proceedings of the 37th International Conference on Machine Learning (ICML), Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Saleh, F.; Aliakbarian, S.; Rezatofighi, H.; Salzmann, M.; Gould, S. Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Gao, X.; Jiang, T. OSMO: Online Specific Models for Occlusion in Multiple Object Tracking under Surveillance Scene. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 201–210. [Google Scholar] [CrossRef]
- Tokmakov, P.; Li, J.; Burgard, W.; Gaidon, A. Learning to Track with Object Permanence. In Proceedings of the ICCV, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Khurana, T.; Dave, A.; Ramanan, D. Detecting Invisible People. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Rukhovich, D.; Sofiiuk, K.; Galeev, D.; Barinova, O.; Konushin, A. IterDet: Iterative Scheme for ObjectDetection in Crowded Environments. arXiv 2020, arXiv:2005.05708. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Ess, A.; Leibe, B.; Van Gool, L. Depth and appearance for mobile scene analysis. In Proceedings of the IEEE International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Henschel, R.; Leal-Taixé, L.; Cremers, D.; Rosenhahn, B. Improvements to frank-wolfe optimization for multi-detector multi-object tracking. arXiv 2017, arXiv:1705.08314. [Google Scholar]
- Ma, L.; Tang, S.; Black, M.J.; Van Gool, L. Customized multi-person tracker. In Proceedings of the Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018; pp. 612–628. [Google Scholar]
- Brasó, G.; Leal-Taixé, L. Learning a neural solver for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6247–6257. [Google Scholar]
- Dai, P.; Weng, R.; Choi, W.; Zhang, C.; He, Z.; Ding, W. Learning a Proposal Classifier for Multiple Object Tracking. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Tian, W.; Lauer, M.; Chen, L. Online multi-object tracking using joint domain information in traffic scenarios. IEEE Trans. Intell. Transp. Syst. 2019, 21, 374–384. [Google Scholar] [CrossRef]
- Chu, P.; Fan, H.; Tan, C.C.; Ling, H. Online Multi-Object Tracking with Instance-Aware Tracker and Dynamic Model Refreshment. arXiv 2019, arXiv:1902.08231. [Google Scholar]
- Li, X.; Liu, Y.; Wang, K.; Yan, Y.; Wang, F.Y. Multi-Target Tracking with Trajectory Prediction and Re-Identification. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 5028–5033. [Google Scholar]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How To Train Your Deep Multi-Object Tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6787–6796. [Google Scholar]
- Keuper, M.; Tang, S.; Andres, B.; Brox, T.; Schiele, B. Motion segmentation & multiple object tracking by correlation co-clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 140–153. [Google Scholar]
- Chu, Q.; Ouyang, W.; Liu, B.; Zhu, F.; Yu, N. DASOT: A Unified Framework Integrating Data Association and Single Object Tracking for Online Multi-Object Tracking. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 10672–10679. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Bochinski, E.; Senst, T.; Sikora, T. Extending IOU based multi-object tracking by visual information. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Yoon, Y.C.; Kim, D.Y.; Song, Y.m.; Yoon, K.; Jeon, M. Online Multiple Pedestrians Tracking using Deep Temporal Appearance Matching Association. Inf. Sci. 2020, 561, 326–351. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Ke, W.; Xiong, Z. Multiplex labeling graph for near-online tracking in crowded scenes. IEEE Internet Things J. 2020, 7, 7892–7902. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | MOTA ↑ | IDF1 ↑ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|---|
| FWT [47] | offline | 47.8 | 44.3 | 8886 | 85,487 | 852 |
| GCRA [27] | offline | 48.2 | 48.6 | 5104 | 88,586 | 821 |
| LMP [7] | offline | 48.8 | 51.3 | 6654 | 86,245 | 481 |
| HCC [48] | offline | 49.3 | 50.7 | 5333 | 86,795 | 391 |
| CRFTrack [17] | offline | 50.3 | 54.4 | 7148 | 82,746 | 702 |
| TPM [18] | offline | 51.3 | 47.9 | 2701 | 85,504 | 420 |
| MPNTrack [49] | offline | 58.6 | 61.7 | 4949 | 70,252 | 354 |
| LPC_MOT [50] | offline | 58.8 | 67.6 | 6167 | 68,432 | 435 |
| JCSTD [51] | online | 47.4 | 41.1 | 8076 | 86,638 | 1266 |
| MOTDT [7] | online | 47.6 | 50.9 | 9253 | 85,431 | 792 |
| KCF16 [52] | online | 48.8 | 47.2 | 5875 | 86,567 | 906 |
| PV [53] | online | 50.4 | 47.5 | 2600 | 86,780 | 702 |
| Tracktor [11] | online | 54.4 | 52.5 | 3280 | 79,149 | 682 |
| TrctrD16 [54] | online | 54.8 | 53.4 | 2955 | 78,765 | 645 |
| Tracktor++v2 [11] | online | 56.2 | 54.9 | 2394 | 76,844 | 617 |
| GSM [29] | online | 57.0 | 58.2 | 4332 | 73,573 | 475 |
| TADAM [33] | online | 59.1 | 59.5 | 2540 | 71,542 | 529 |
| Ours | online | 59.7 | 53.3 | 3437 | 69,227 | 885 |
| Method | Type | MOTA ↑ | IDF1 ↑ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|---|
| jCC [55] | offline | 51.2 | 54.5 | 25,937 | 247,822 | 1802 |
| FWT [47] | offline | 51.3 | 47.6 | 24,101 | 247,921 | 2648 |
| eTC17 [12] | offline | 51.9 | 50.8 | 31,572 | 232,659 | 3050 |
| JBNOT [16] | offline | 52.6 | 50.8 | 31,572 | 232,659 | 3050 |
| CRF_TRA [17] | offline | 53.1 | 53.7 | 27,194 | 234,991 | 2518 |
| TPM [18] | offline | 54.2 | 52.6 | 13,739 | 242,730 | 1824 |
| MPNTrack [49] | offline | 58.8 | 61.7 | 17,413 | 213,594 | 1185 |
| LPC_MOT [50] | offline | 59.0 | 66.8 | 23,102 | 206,948 | 1122 |
| DASOT17 [56] | online | 49.5 | 51.8 | 33,640 | 247,370 | 4142 |
| MTDF17 [20] | online | 49.6 | 45.2 | 37,124 | 241,768 | 5567 |
| YOONKJ17 [21] | online | 51.4 | 54.0 | 29,051 | 243,202 | 2118 |
| MOTDT17 [7] | online | 50.9 | 52.7 | 24,069 | 250,768 | 2474 |
| FAMnet [22] | online | 52.0 | 48.7 | 14,138 | 253,616 | 3072 |
| Tracktor [11] | online | 53.5 | 52.3 | 12,201 | 248,047 | 2072 |
| Tracktor++v2 [11] | online | 56.3 | 55.1 | 8866 | 235,449 | 1987 |
| GSM [29] | online | 56.4 | 57.8 | 14,379 | 230,174 | 1485 |
| TADAM [33] | online | 59.7 | 58.7 | 9676 | 216,029 | 1930 |
| Ours | online | 60.6 | 54.3 | 10,494 | 208,861 | 2956 |
| Method | Type | MOTA ↑ | IDF1 ↑ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|---|
| IOU_19 * [57] | offline | 35.8 | 25.7 | 24,427 | 319,696 | 15,676 |
| V_IOU * [58] | offline | 46.7 | 46.0 | 33,776 | 261,964 | 2589 |
| MPNTrack [49] | offline | 57.6 | 59.1 | 16,953 | 201,384 | 1210 |
| LPC_MOT [50] | offline | 56.3 | 62.5 | 11,726 | 213,056 | 1562 |
| SORT20 [1] | online | 42.7 | 45.1 | 27,521 | 264,694 | 4470 |
| DD_TAMA19 * [59] | online | 47.6 | 48.7 | 38,194 | 252,934 | 2437 |
| MLT [60] | online | 48.9 | 54.6 | 45,660 | 246,803 | 2187 |
| Tracktor * [11] | online | 51.3 | 47.6 | 16,263 | 253,680 | 2584 |
| Tracktor++v2 [11] | online | 52.6 | 52.7 | 6930 | 236,680 | 1648 |
| TADAM [33] | online | 56.6 | 51.6 | 39,407 | 182,520 | 2690 |
| Ours | online | 59.9 | 55.3 | 12,458 | 192,846 | 2353 |
| Method | MOTA ↑ | IDF1 ↑ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|
| Tracktor [11] | 70.6 | 65.4 | 3652 | 175,955 | 1441 |
| w/o His | 71.2 | 64.9 | 2906 | 172,471 | 1703 |
| Full model | 72.5 | 65.0 | 3736 | 163,418 | 2062 |
| Method | MOTA ↑ | IDF1 ↑ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|
| w/o CMC & LMM | 58.0 | 51.7 | 11,223 | 48,090 | 2658 |
| w/o LMM | 61.4 | 59.5 | 12,309 | 47,349 | 2682 |
| w/o CMC | 59.6 | 54.3 | 11,259 | 48,066 | 2514 |
| Full model | 62.3 | 63.0 | 12,180 | 47,349 | 2682 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, C.; Luo, Z. Improving Multiple Pedestrian Tracking in Crowded Scenes with Hierarchical Association. Entropy 2023, 25, 380. https://doi.org/10.3390/e25020380
Xiao C, Luo Z. Improving Multiple Pedestrian Tracking in Crowded Scenes with Hierarchical Association. Entropy. 2023; 25(2):380. https://doi.org/10.3390/e25020380
Chicago/Turabian StyleXiao, Changcheng, and Zhigang Luo. 2023. "Improving Multiple Pedestrian Tracking in Crowded Scenes with Hierarchical Association" Entropy 25, no. 2: 380. https://doi.org/10.3390/e25020380