
Diversity-Aware Marine Predators Algorithm for Task Scheduling in Cloud Computing

Abstract
:1. Introduction
- (1)
- The DAMPA is proposed for resolving TSCC in reducing makespan and energy consumption and increasing throughput.
- (2)
- To avoid premature convergence, the predator crowding degree ranking strategy is designed, and the comprehensive learning strategy is applied.
- (3)
- A stage-independent control of the stepsize-scaling strategy is designed to balance the exploration and exploitation abilities.
2. Related Works
3. Problem Formulation
3.1. Task Scheduling
3.2. Mathematical Model
3.2.1. Makespan
3.2.2. Energy Consumption
3.2.3. Throughput
3.2.4. Fitness Function
4. The Proposed Algorithm
4.1. The Overview of MPA
4.1.1. Elite and Prey Matrix
4.1.2. Optimization Process
| Algorithm 1 MPA |
|
4.2. The DAMPA Algorithm
4.2.1. The Predator Crowding Degree Ranking Strategy
| Algorithm 2 Crowding degree ranking algorithm. |
|
4.2.2. Comprehensive Learning Strategy
| Algorithm 3 Comprehensive learning strategy. |
|
4.2.3. Stage-Independent Control of Stepsize-Scaling Strategy
| Algorithm 4 DAMPA |
|
4.2.4. Complexity Analysis
5. Experiment and Analysis
5.1. Data Set
5.1.1. Case1
5.1.2. Case2
5.2. Parameter Setting
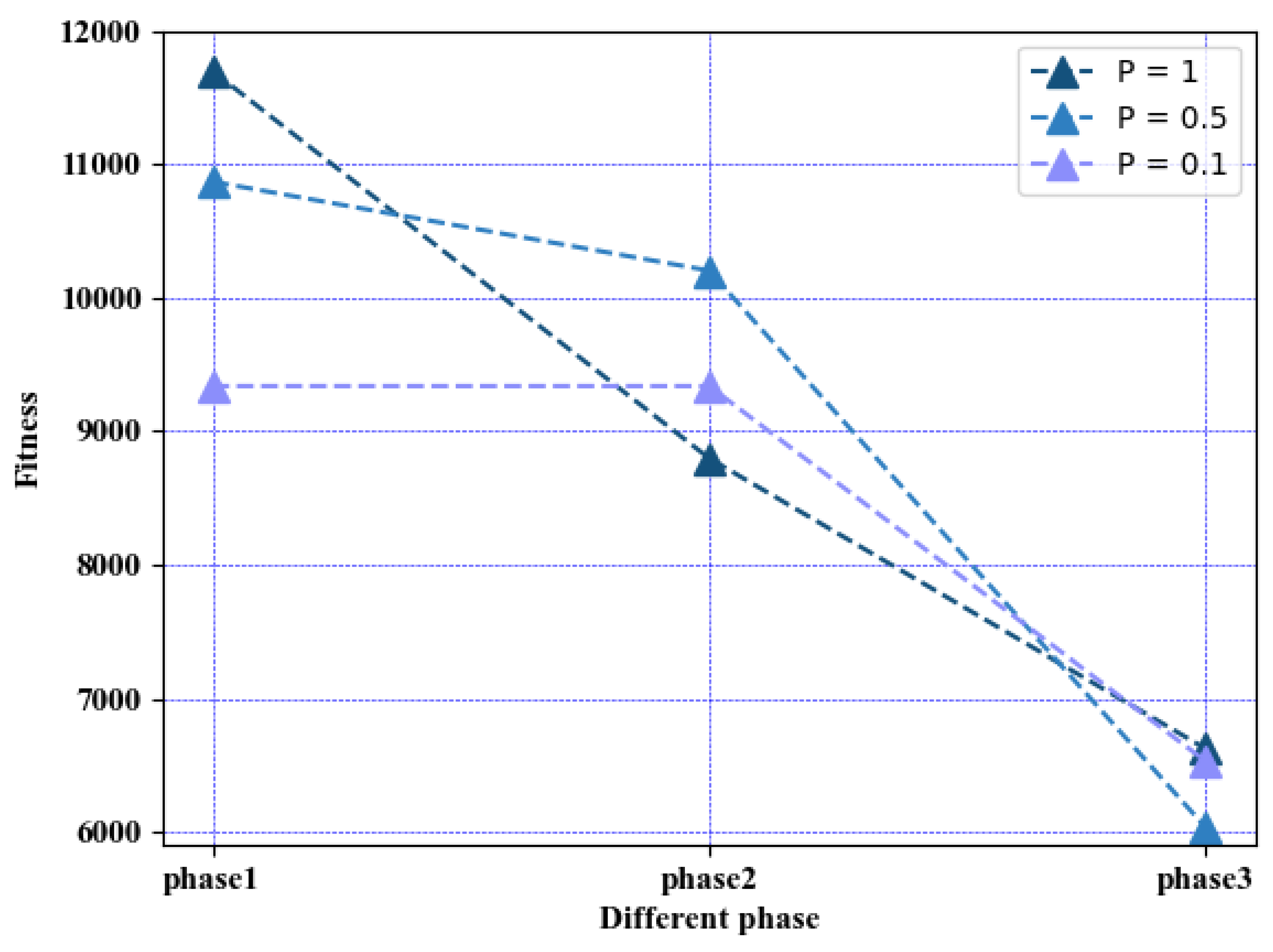
5.3. Discretization
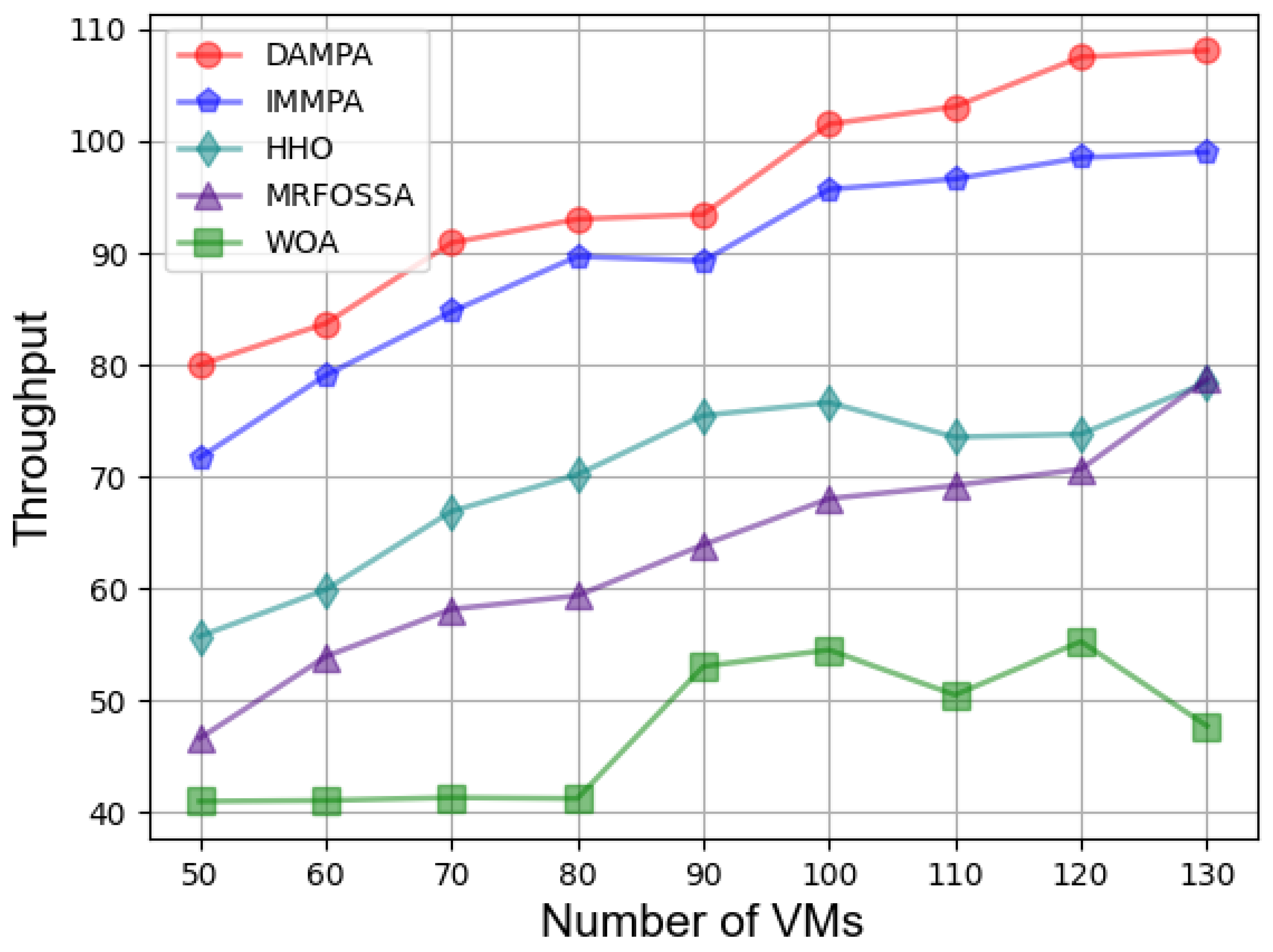
5.4. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rimal, B.P.; Maier, M. Workflow Scheduling in Multi-Tenant Cloud Computing Environments. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 290–304. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Sumari, P.; Gandomi, A.H. Applications, Deployments, and Integration of Internet of Drones (IoD): A Review. IEEE Sens. J. 2021, 21, 25532–25546. [Google Scholar] [CrossRef]
- Houssein, E.H.; Gad, A.G.; Wazery, Y.M.; Suganthan, P.N. Task Scheduling in Cloud Computing Based on Meta-Heuristics: Review, Taxonomy, Open Challenges, and Future Trends. Swarm Evol. Comput. 2021, 62, 100841. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, H. Deep Reinforcement Learning Enhanced Greedy Algorithm for Online Scheduling of Batched Tasks in Cloud in Cloud HPC Systems. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 3003–3014. [Google Scholar] [CrossRef]
- Velliangiri, S.; Karthikeyan, P.; Arul Xavier, V.M.; Baswaraj, D. Hybrid Electro Search with Genetic Algorithm for Task Scheduling in Cloud Computing. Ain Shams Eng. J. 2021, 12, 631–639. [Google Scholar] [CrossRef]
- Shukla, D.K.; Kumar, D.; Kushwaha, D.S. WITHDRAWN: Task Scheduling to Reduce Energy Consumption and Makespan of Cloud Computing Using NSGA-II. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Cui, Z.; Zhang, J.; Wu, D.; Cai, X.; Wang, H.; Zhang, W.; Chen, J. Hybrid Many-Objective Particle Swarm Optimization Algorithm for Green Coal Production Problem. Inf. Sci. 2020, 518, 256–271. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Attiya, I. An Improved Henry Gas Solubility Optimization Algorithm for Task Scheduling in Cloud Computing. Artif. Intell. Rev. 2021, 54, 3599–3637. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris Hawks Optimization: Algorithm and Applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Faramarzi, A.; Heidarinejad, M.; Mirjalili, S.; Gandomi, A.H. Marine Predators Algorithm: A Nature-Inspired Metaheuristic. Expert Syst. Appl. 2020, 152, 113377. [Google Scholar] [CrossRef]
- Marahatta, A.; Pirbhulal, S.; Zhang, F.; Parizi, R.M.; Choo, K.-K.R.; Liu, Z. Classification-Based and Energy-Efficient Dynamic Task Scheduling Scheme for Virtualized Cloud Data Center. IEEE Trans. Cloud Comput. 2021, 9, 1376–1390. [Google Scholar] [CrossRef]
- Hussain, M.; Wei, L.-F.; Lakhan, A.; Wali, S.; Ali, S.; Hussain, A. Energy and Performance-Efficient Task Scheduling in Heterogeneous Virtualized Cloud Computing. Sustain. Comput. Inform. Syst. 2021, 30, 100517. [Google Scholar] [CrossRef]
- Chen, X.; Cheng, L.; Liu, C.; Liu, Q.; Liu, J.; Mao, Y.; Murphy, J. A WOA-Based Optimization Approach for Task Scheduling in Cloud Computing Systems. IEEE Syst. J. 2020, 14, 3117–3128. [Google Scholar] [CrossRef]
- Abdullah, M.; Al-Muta’a, E.A.; Al-Sanabani, M. Integrated MOPSO Algorithms for Task Scheduling in Cloud Computing. IFS 2019, 36, 1823–1836. [Google Scholar] [CrossRef]
- Laili, Y.; Guo, F.; Ren, L.; Li, X.; Li, Y.; Zhang, L. Parallel Scheduling of Large-Scale Tasks for Industrial Cloud-Edge Collaboration. IEEE Internet Things J. 2021, 3231–3242. [Google Scholar] [CrossRef]
- Ali, I.M.; Sallam, K.M.; Moustafa, N.; Chakraborty, R.; Ryan, M.J.; Choo, K.-K.R. An Automated Task Scheduling Model Using Non-Dominated Sorting Genetic Algorithm II for Fog-Cloud Systems. IEEE Trans. Cloud Comput. 2020, 10, 2294–2308. [Google Scholar] [CrossRef]
- Xiong, Y.; Huang, S.; Wu, M.; She, J.; Jiang, K. A Johnson’s-Rule-Based Genetic Algorithm for Two-Stage-Task Scheduling Problem in Data-Centers of Cloud Computing. IEEE Trans. Cloud Comput. 2019, 7, 597–610. [Google Scholar] [CrossRef]
- Pirozmand, P.; Hosseinabadi, A.A.R.; Farrokhzad, M.; Sadeghilalimi, M.; Mirkamali, S.; Slowik, A. Multi-Objective Hybrid Genetic Algorithm for Task Scheduling Problem in Cloud Computing. Neural Comput. Appl. 2021, 33, 13075–13088. [Google Scholar] [CrossRef]
- Pang, S.; Li, W.; He, H.; Shan, Z.; Wang, X. An EDA-GA Hybrid Algorithm for Multi-Objective Task Scheduling in Cloud Computing. IEEE Access 2019, 7, 146379–146389. [Google Scholar] [CrossRef]
- Xu, J.; Hao, Z.; Zhang, R.; Sun, X. A Method Based on the Combination of Laxity and Ant Colony System for Cloud-Fog Task Scheduling. IEEE Access 2019, 7, 116218–116226. [Google Scholar] [CrossRef]
- Attiya, I.; Elaziz, M.A.; Abualigah, L.; Nguyen, T.N.; El-Latif, A.A.A. An Improved Hybrid Swarm Intelligence for Scheduling IoT Application Tasks in the Cloud. IEEE Trans. Ind. Inf. 2022, 18, 6264–6272. [Google Scholar] [CrossRef]
- Walia, N.K.; Kaur, N.; Alowaidi, M.; Bhatia, K.S.; Mishra, S.; Sharma, N.K.; Sharma, S.K.; Kaur, H. An Energy-Efficient Hybrid Scheduling Algorithm for Task Scheduling in the Cloud Computing Environments. IEEE Access 2021, 9, 117325–117337. [Google Scholar] [CrossRef]
- Domanal, S.G.; Guddeti, R.M.R.; Buyya, R. A Hybrid Bio-Inspired Algorithm for Scheduling and Resource Management in Cloud Environment. IEEE Trans. Serv. Comput. 2020, 13, 3–15. [Google Scholar] [CrossRef]
- Fu, X.; Sun, Y.; Wang, H.; Li, H. Task Scheduling of Cloud Computing Based on Hybrid Particle Swarm Algorithm and Genetic Algorithm. Clust. Comput. 2021. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Elhoseny, M.; Song, H. Energy-Aware Metaheuristic Algorithm for Industrial-Internet-of-Things Task Scheduling Problems in Fog Computing Applications. IEEE Internet Things J. 2021, 8, 12638–12649. [Google Scholar] [CrossRef]
- Yousri, D.; Fathy, A.; Rezk, H. A New Comprehensive Learning Marine Predator Algorithm for Extracting the Optimal Parameters of Supercapacitor Model. J. Energy Storage 2021, 42, 103035. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Elhoseny, M.; Bashir, A.K.; Jolfaei, A.; Kumar, N. Energy-Aware Marine Predators Algorithm for Task Scheduling in IoT-Based Fog Computing Applications. IEEE Trans. Ind. Inf. 2021, 17, 5068–5076. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Value |
|---|---|---|
| DAMPA | P1 | 0.05 |
| P2 | 0.5 | |
| P3 | 1 | |
| IMMPA | P | 1 |
| HHO | 1.5 | |
| WOA | b | 1 |
| MRFOSSA | S | 2 |
| Tasks | DAMPA | IMMPA | HHO | MRFOSSA | WOA |
|---|---|---|---|---|---|
| 100 | 1191 | 1233 | 1426 | 1553 | 1800 |
| 200 | 2603 | 2730 | 2854 | 3167 | 3453 |
| 300 | 3790 | 3898 | 4065 | 4588 | 4491 |
| 400 | 4989 | 5081 | 5260 | 5939 | 5705 |
| 500 | 6207 | 6251 | 6614 | 7255 | 7167 |
| 600 | 7490 | 7515 | 7943 | 8496 | 8361 |
| 700 | 8557 | 8665 | 8725 | 9693 | 9093 |
| 800 | 9710 | 9781 | 10,036 | 10,908 | 10,676 |
| Tasks | DAMPA | IMMPA | HHO | MRFOSSA | WOA |
|---|---|---|---|---|---|
| 100 | 8.16 | 8.37 | 9.22 | 9.74 | 11.89 |
| 200 | 15.19 | 16.40 | 16.87 | 19.24 | 20.82 |
| 300 | 22.00 | 23.10 | 24.08 | 26.72 | 26.69 |
| 400 | 28.52 | 29.14 | 29.83 | 33.70 | 32.55 |
| 500 | 35.21 | 35.79 | 37.44 | 40.28 | 39.73 |
| 600 | 41.77 | 41.80 | 44.25 | 48.53 | 48.17 |
| 700 | 47.32 | 47.93 | 48.22 | 55.33 | 51.20 |
| 800 | 53.43 | 53.43 | 55.70 | 62.34 | 62.05 |
| Algorithm | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|---|---|
| IMMPA | 2.60% | 7.38% | 4.76% | 2.14% | 1.62% | 0.07% | 1.28% | 0% |
| MRFOSSA | 16.27% | 21.06% | 17.69% | 15.38% | 12.59% | 13.93% | 14.48% | 14.30% |
| HHO | 11.56% | 9.99% | 8.64% | 4.41% | 5.96% | 5.60% | 1.86% | 4.08% |
| WOA | 31.37% | 27.05% | 17.59% | 12.40% | 11.37% | 13.28% | 7.58% | 13.89% |
| Tasks | DAMPA | IMMPA | HHO | MRFOSSA | WOA |
|---|---|---|---|---|---|
| 100 | 2400 | 2424 | 2915 | 3137 | 3591 |
| 200 | 5108 | 5453 | 5754 | 6356 | 6834 |
| 300 | 7625 | 8037 | 8321 | 9202 | 8954 |
| 400 | 10,122 | 10,294 | 10,382 | 11,922 | 11,378 |
| 500 | 12,484 | 12,741 | 13,236 | 14,433 | 14,280 |
| 600 | 14,934 | 14,946 | 15,753 | 16,993 | 16,674 |
| 700 | 17,165 | 17,245 | 17,490 | 19,413 | 18,185 |
| 800 | 19,286 | 19,719 | 19,989 | 21,859 | 21,316 |
| Algorithm | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|---|---|
| IMMPA | 0.99% | 6.33% | 5.12% | 1.67% | 2.01% | 0.07% | 0.46% | 0.11% |
| MRFOSSA | 23.47% | 19.63% | 17.13% | 15.10% | 13.50% | 12.11% | 11.57% | 11.76% |
| HHO | 17.64% | 11.22% | 8.35% | 2.50% | 5.68% | 5.19% | 1.85% | 3.51% |
| WOA | 33.14% | 25.25% | 14.83% | 11.04% | 12.57% | 10.43% | 5.60% | 9.52% |
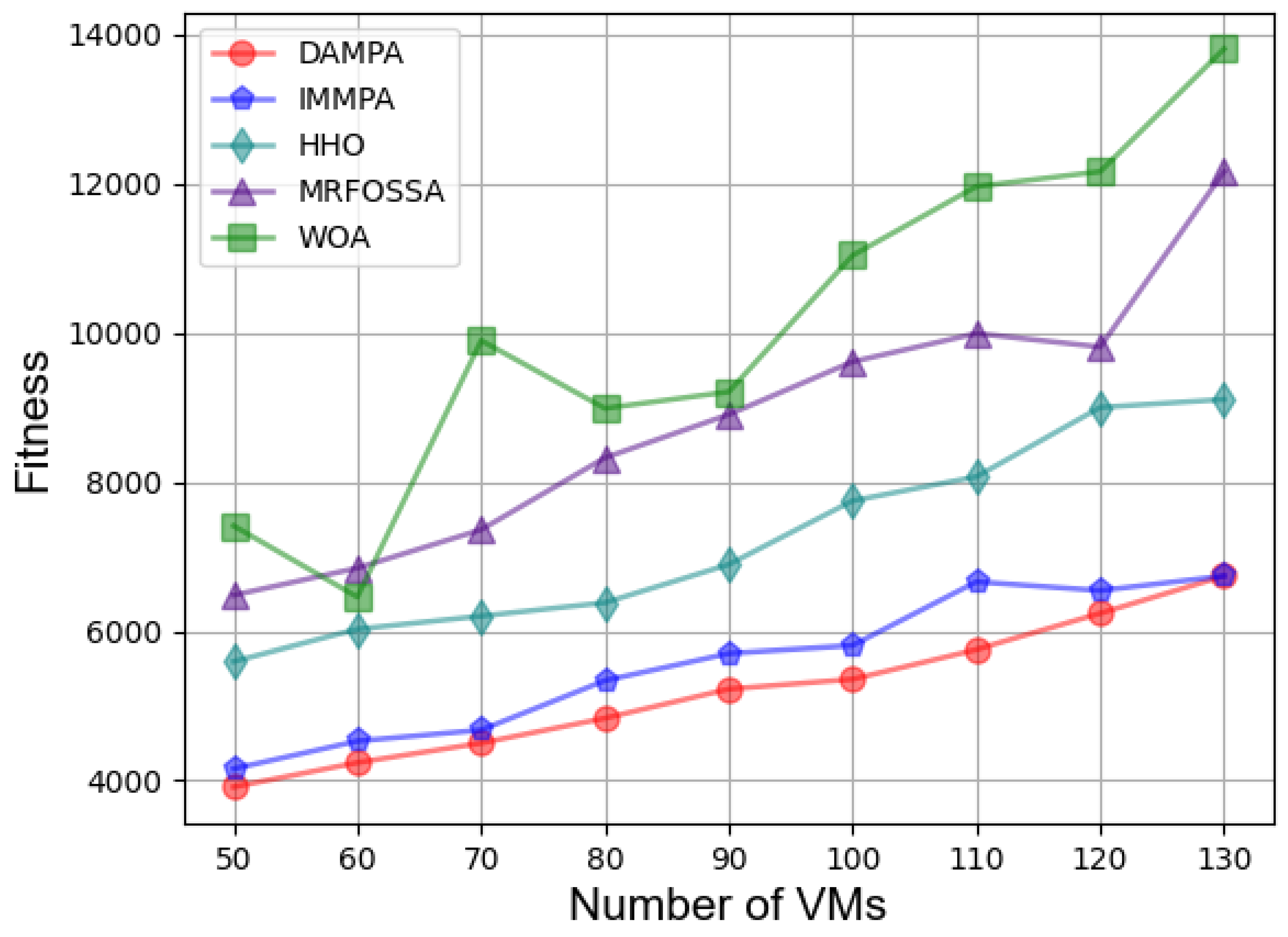
| Algorithm | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | Ave |
|---|---|---|---|---|---|---|---|---|---|---|
| IMMPA | 10.48% | 5.53% | 7.07% | 4.00% | 4.64% | 6.09% | 6.33% | 8.50% | 8.68% | 6.81% |
| MRFOSSA | 41.76% | 35.60% | 36.11% | 36.33% | 31.64% | 33.12% | 33.00% | 34.33% | 27.27% | 34.35% |
| HHO | 30.43% | 28.57% | 26.53% | 24.79% | 19.27% | 24.79% | 28.89% | 31.38% | 27.63% | 26.92% |
| WOA | 48.77% | 50.94% | 54.63% | 55.74% | 43.26% | 46.33% | 51.12% | 48.65% | 55.94% | 50.60% |
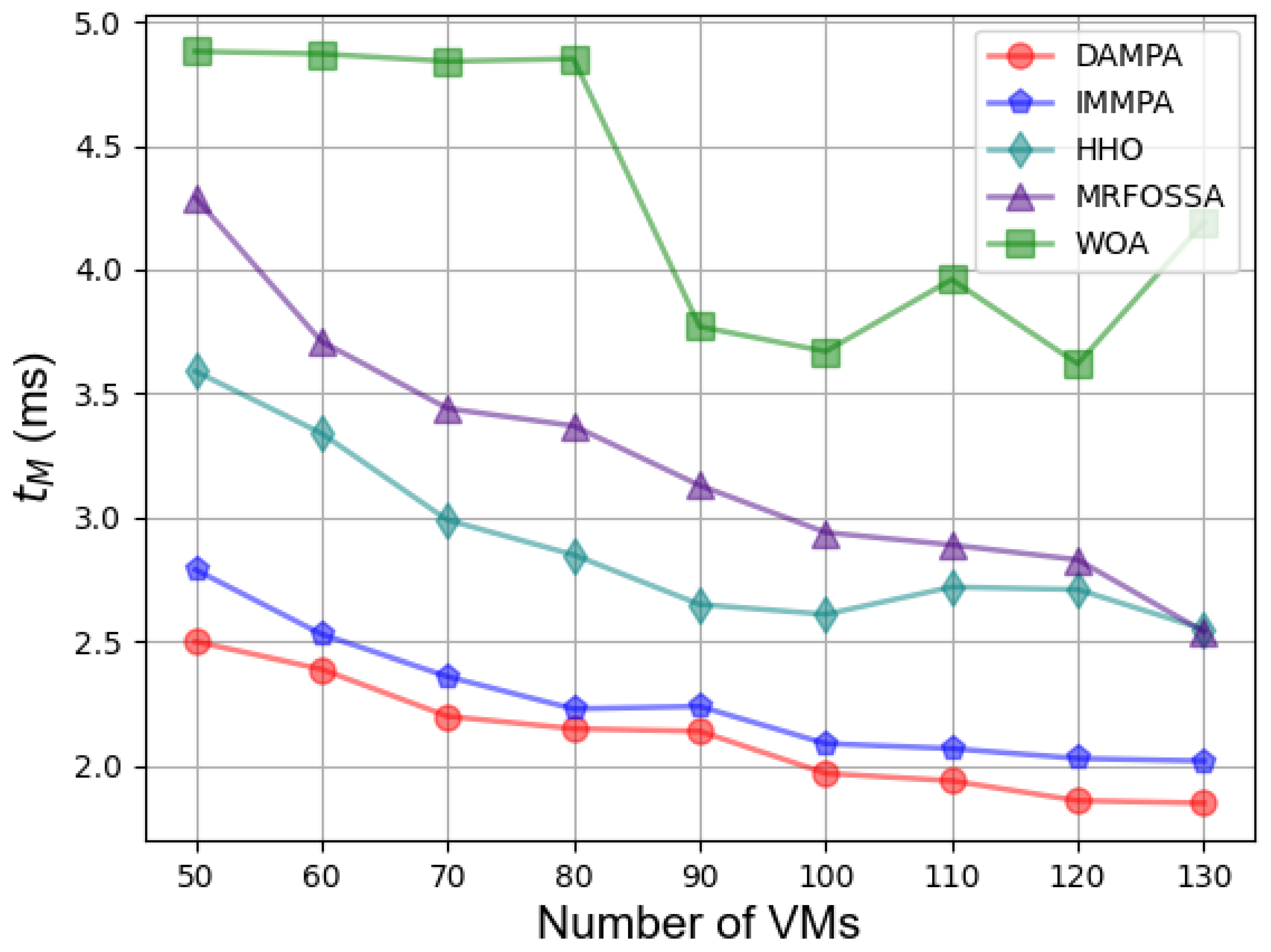
| Algorithm | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | Ave |
|---|---|---|---|---|---|---|---|---|---|---|
| IMMPA | 6.97% | 2.40% | 8.39% | 11.11% | 3.77% | 6.10% | 9.08% | 4.15% | 4.69% | 6.30% |
| MRFOSSA | 40.32% | 36.14% | 40.76% | 43.65% | 36.02% | 37.61% | 40.16% | 37.41% | 35.37% | 38.60% |
| HHO | 30.82% | 23.23% | 31.51% | 30.60% | 21.41% | 27.46% | 29.33% | 25.65% | 23.34% | 27.04% |
| WOA | 48.46% | 33.39% | 54.38% | 49.19% | 41.11% | 49.75% | 53.25% | 44.35% | 53.61% | 47.50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Zhang, Y. Diversity-Aware Marine Predators Algorithm for Task Scheduling in Cloud Computing. Entropy 2023, 25, 285. https://doi.org/10.3390/e25020285
Chen D, Zhang Y. Diversity-Aware Marine Predators Algorithm for Task Scheduling in Cloud Computing. Entropy. 2023; 25(2):285. https://doi.org/10.3390/e25020285
Chicago/Turabian StyleChen, Dujing, and Yanyan Zhang. 2023. "Diversity-Aware Marine Predators Algorithm for Task Scheduling in Cloud Computing" Entropy 25, no. 2: 285. https://doi.org/10.3390/e25020285