1. Introduction
Support vector machine (SVM) is one of the most popular machine learning methods, which is based on the statistical learning theory and the structural risk minimization principle [
1]. Moreover, it has unique advantages in solving practical problems, such as small sample data sets as well as nonlinear and high-dimensional pattern recognition [
2,
3,
4]. In SVM, the kernel function selection is a key part for nonlinear problems. The Radial Basis Function (RBF), as the most common kernel function, has the characteristics of fewer optimized parameters and better classification performance in terms of accuracy and stability, especially for high-dimensional data. However, the classification effect of the SVM is related to two factors. The first one is the quality of the input data set. The greater the degree of data set differentiation, the better the algorithm effects. The second one is the value of the error penalty parameters and the kernel parameters. In order to achieve the best classification effect and the maximum generalization of the SVM, many researchers have proposed different solutions to solve the two issues above.
One of the most widespread methods for selecting these two key parameters is using the grid algorithm to traverse and compare iteratively. This method can achieve relatively good results, but it is time-consuming [
5]. Therefore, some researchers proposed using the meta-heuristic algorithm to find the best parameter value within the specified range [
6,
7,
8,
9]. The most commonly used meta-heuristic algorithms are the genetic algorithms. They perform well in solving large-scale nonlinear problems [
10,
11]. However, they are easy to fall into the local optimal value and fail to find the global optimal solution [
12,
13,
14], since the algorithm follows the natural law of information exchange and evolution among populations. Another meta-heuristic algorithm used to find the optimal parameters is particle swarm optimization (PSO), which mimics the information exchange between birds in searching for food to find the optimal result in the population. Each iteration of the algorithm will be adjusted according to the results of the previous iteration, which greatly improves the efficiency. Compared with the cross-mutation of the genetic algorithm, it is more targeted, which weakens its randomness. However, the PSO algorithm is as easy as the genetic algorithm to fall into local optimum, resulting in large errors in the results [
15,
16]. Mafarja et al. proposed the Binary Dragonfly Algorithm for minimizing all features using the wrapper feature selection algorithms to enhance the classification accuracy [
17]. By taking a mutational approach and scanning the area surrounding the explorers, Binary Al-Biruni Earth Radius Optimization is able to deliver cutting-edge exploration capabilities. It ensures diversity and thorough exploration by shuffling the order of responses between repetitions [
18]. Khafaga et al. proposed the Binary Dipper Throated Optimization (bDTO) method to optimize the weighted ensemble model by the DTO algorithm. Once the significant features are selected, the optimized weighted ensemble model is employed to predict the gain values of metamaterial antenna [
19]. The Binary Cat Swarm Optimization (BCSO) algorithm includes two major modes: tracing and seeking modes. However, the traditional BCSO has the chance of becoming trapped in the local optima [
20].
Many scholars have improved the PSO algorithm in recent years. The most common method is the change of inertia weight, which can improve the global search ability of the algorithm [
21,
22,
23]. Inertial weight
w is a very important parameter in the PSO algorithm, which plays an important role in the global searching ability of the algorithm. It increases the diversity of the population and speeds up the convergence speed. Clerc proposed that the value of
w was 0.729 [
24,
25]. Trelea suggested that
w should be 0.6 [
14,
26]. The smaller
w is, the stronger the local search ability of the algorithm is and, consequently, the faster the algorithm converges. However, it is easier to fall into local convergence, and its search ability in new regions is relatively deficient. The larger
w is, the stronger the global search ability of the algorithm is, and the more diversity the population reflects. However, it is easy to miss the optimal point when
w is large, thus leading to non-convergence. Therefore, it is of importance to adjust the value of
w dynamically to obtain the right value at different times. At the earliest, Shi and Eberhart proposed adjusting the inertia weight
w by the way of linear decline [
27]. In their view, the minimum value of
w is taken as the bottom line, and the value of
w decreases linearly from the maximum to the minimum with the number of iterations. As the actual optimization process is nonlinear and complex, the linear decline way is not in line with the actual rules of optimization. It did not consider the situation of all the particles in the population and had no strong adjustment, so it is easy to fall into local optimum and cannot obtain better results.
Later, Shi and Eberhart introduced the random inertia weighting strategy, which changed the value of
w by introducing a random function [
27]. Some scholars put forward the nonlinear decreasing method to adjust the inertia weight, such as the decreasing inertia weight adjustment strategy in the form of a parabola by Chatterjee and Siarry [
28]. Jiang et al. used the change of cosine function to realize the nonlinear decreasing strategy [
24]. This nonlinear decreasing method improves the searching efficiency of the algorithm to a certain extent. It can overcome the premature convergence of the algorithm and reduce the probability of falling into local extreme value to a certain extent [
29,
30,
31]. Lu et al. introduced the concept of personalized inertia weight. This method judges the current position of each particle by comparing its fitness with the average fitness of the population. Based on the state, the inertia weight of a particle with a better position is reduced, and the particle is focused on the development of the current region. For the particles in poor positions, the inertia weight of the particle is increased, causing the particle to focus on potential area exploration [
32].
In the above algorithms, the values of
w in the early stage are large, so they have a strong global search ability. However, with the decrease of
w in the later stage, the algorithm easily falls into the local optimum, resulting in the loss of population diversity, and the convergence speed of the algorithm will also slow down. Therefore, in the later part of the algorithm, the
w value will still become very small. In this way, the group does not have diversity, it is easy to fall into a local extreme value, and it does not have a strong global search ability. At the same time, the cosine function cannot be adjusted in time for specific situations. The flexibility of the equation is poor [
33,
34,
35].
The application of SVM relies on training in corresponding data sets to build corresponding models. The rapid development of modern society leads to the explosive growth of all kinds of information and data [
36]. The growth is not only in quantity but also in more and more diversified forms of data, such as text documents, pictures and gene sequences [
37]. Faced with such massive data and complex forms of expression, it is impossible to carry out the practical application without filter and process. At the same time, the relationship and characteristics of massive data in modern society also have wider application space [
38,
39]. Therefore, data screening and dimension reduction of complex data are becoming more and more important, while the feature selection method is the key to achieving the above applications. Feature selection is a widely used data processing method, which selects the conforming features and excludes the non-conforming features according to the set evaluation criteria [
40]. New data sets are obtained by the feature selection of the original data sets, which can improve the accuracy and efficiency of the algorithm in classification, regression, prediction and other tasks. It makes the models we generate more accurate and easier to understand.
The main methods of feature selection include wrapping, filtering and embedded methods. Most feature selection methods are derived and improved from these three methods. Some scholars use SVM classifier for feature selection. When redundant features or interference features exist, the performance of the classifier will be significantly reduced. In addition, forward feature selection and backward feature selection are commonly used in feature selection by classifier. Different feature selection methods should be applied to data sets with different characteristics.
In order to further improve the accuracy of SVM classification, we intend to solve it from two different perspectives. First, an efficient new multi-class feature selection method is proposed, which is simple and intuitive. When using the hybrid model of particle swarm optimization support vector machine (PSO-VM) to evaluate the proposed feature selection method, not only the accuracy is greatly improved but also the training time is shortened, and a good effect is achieved. Then, to address the drawback of the elementary PSO algorithm where it is easy to fall into local optimum, a method based on the dynamic change of the inertia weight is proposed to optimize the PSO, which can enhance the global searching ability of PSO and expand the diversity of the population. The improved PSO algorithm is used to optimize the parameters of SVM, which improves the performance of the model and enhances the generalization ability of the model. In summary, the main contributions of this paper are presented as follows:
A new feature selection method is proposed. In the formula, the numerator is the sum of the mean values of the variances between classes, and the denominator is the dispersion coefficient to measure the dispersion degree of each eigenvalue within the class. When the numerator is larger and the denominator is smaller, the gap between classes will be larger and the gap within each class will be smaller. The discretization coefficient can describe the differences between classes more accurately and have a better performance than other ways. The proposed feature selection method can improve the classification accuracy and shorten the training time of the classifier.
An improved method for the inertia factor in PSO is proposed, which dynamically changes the inertia factor. We use the logarithmic function and random number to improve the changing process. It not only ensures that the inertia weight can decrease nonlinearly but also meets the necessary conditions for its convergence. In addition, a random function is introduced to ensure that the algorithm has a strong search ability in the early stage, and it will not be premature in the later stage. This algorithm can improve the accuracy of the search.
The proposed feature selection method is combined with the proposed Dynamic Weighted Particle Swarm Optimization (DWPSO) algorithm to improve the classification accuracy of the SVM and shorten the whole experiment time.
This paper is organized as follows.
Section 2 introduces the method of the feature selection.
Section 3 makes a brief introduction to SVM, PSO and introduces the DWPSO-SVM model.
Section 4 describes the experiments performed and the obtained results.
Section 5 discusses the main conclusions and future work.
2. Feature Selection
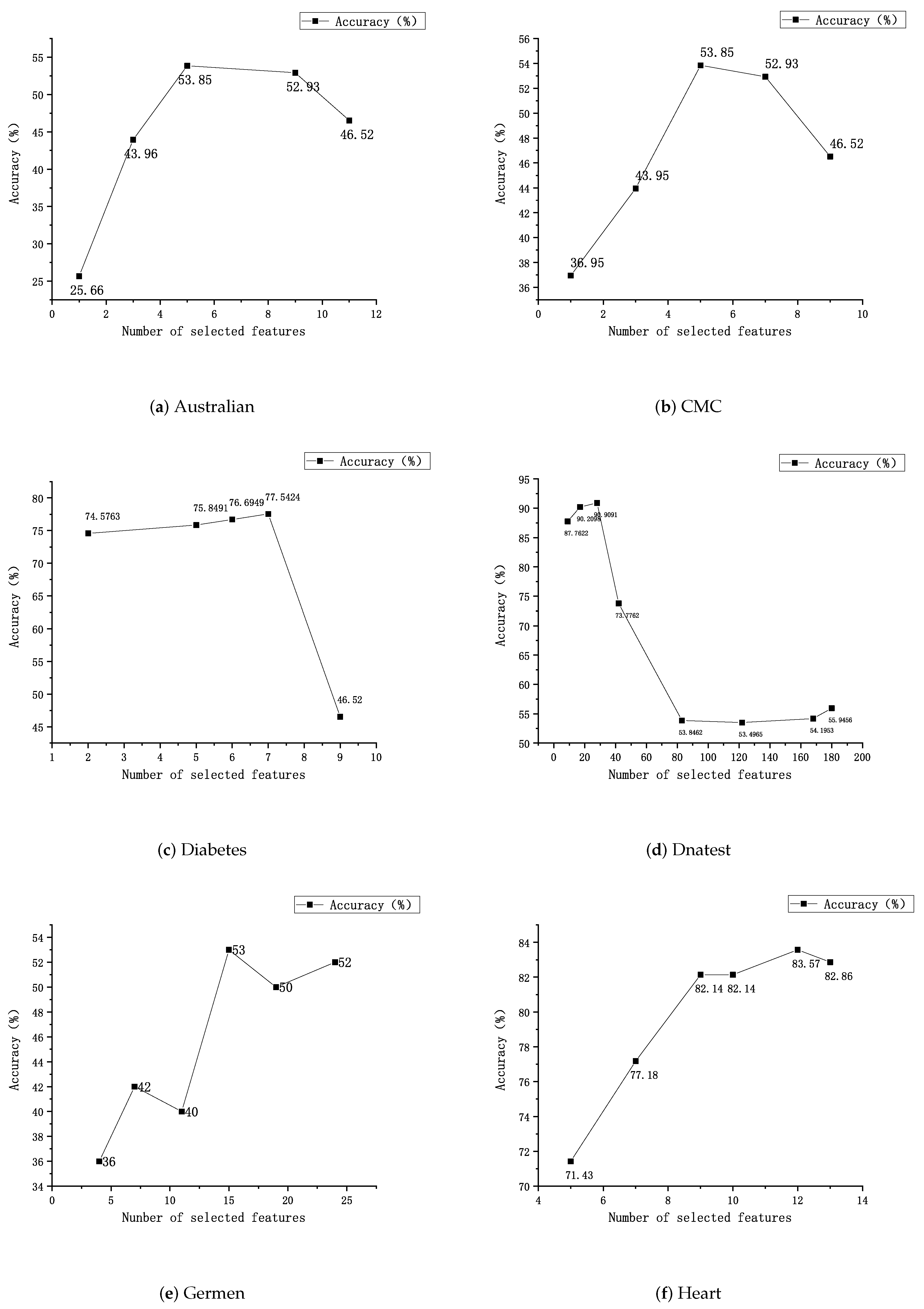
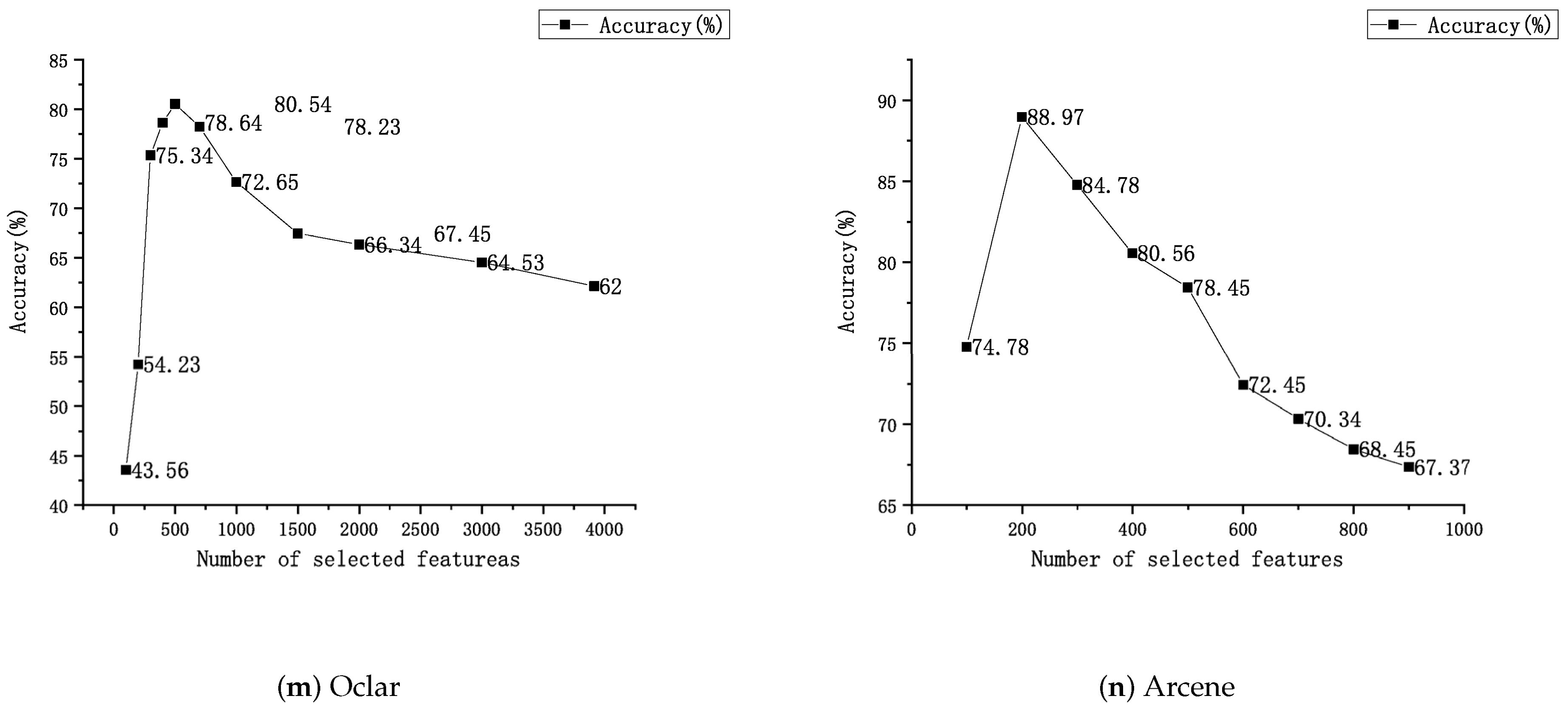
In this section, the new feature selection method called FS-score is detailed. By using this method, the key features can be selected, and the redundant or irrelevant features can be eliminated so as to build a better representation of data and improve both the accuracy and computation efficiency of classification algorithms.
The feature selection method selects the most effective feature for classification. Multi-classification feature selection refers to the feature selection on the data sets with multiple classes. To solve the problem of low classification accuracy of multi-classes and multi-feature data sets, the method to improve the efficiency of the algorithm and shorten the running time is proposed. The feature selection method is described as follows:
Given data set
is the
k-th sample in the data set, where
, and
is the number of samples of class
j. Then, the FS-score value of the
i-th feature in the data set is calculated below.
In Equations (
1) and (
2),
is the average characteristic value of the
i-th feature in the
j-th class.
is the average characteristic value of the
i-th feature in the whole data set.
p is the total number of classes.
is the characteristic value, where
j,
k and
i refer to the
j-th class, the
k-th sample and the
i-th feature, respectively.
The proposed feature selection method is based on the value of
. In Equation (
1), the numerator is the sum of the mean values of the variances between classes, and the denominator is the dispersion coefficient to measure the dispersion degree of each eigenvalue within the class. The discretization coefficient can be used to describe the differences between classes more accurately. When the numerator is larger and the denominator is smaller, the gap between classes will be bigger and the gap within classes will be smaller. This feature will play an important role in the classification, and the discrimination ability of the feature will be stronger. Therefore, when the
value is larger, the probability of this feature being selected is higher.
The principle upheld by the feature selection method is that the larger the gap between categories and the smaller the gap within categories, the better the classification effect will be. In many other methods, numerators represent the approximate sum of distances between classes. If there is an extreme value, it is very easy to cause a too large or too small result, which will cause interference in the process of feature selection. In the FS-score method, the numerator is the sum of the mean values of various inter-class variances; it can avoid the interference caused by extreme values on feature selection. The denominator is the discrete coefficient to measure the dispersion degree of each feature value within the class. Using the discrete coefficient will make the description of the difference between classes more accurate and more intuitive.
The algorithm process will be elaborated in order, and the specific process is described in detail in Algorithm 1.
| Algorithm 1 An effective feature extraction method |
Input: The data set , the penalty parameters C, the kernel parameter , the number of iterations m. Procedure: - 1:
Value preprocessing: using to scale the eigenvalue. g is the scaled value, is the original value of the feature, and are the upper and lower bounds of the original eigenvalue, respectively. - 2:
For the sample, . Calculating using Equations ( 1) and ( 2). According to the value of features, the features are divided into u groups in descending order ( ). - 3:
Calculating the for each group.
Output:
|
5. Conclusions
In this paper, a new feature selection method is proposed, which can be used for the feature selection of the multi-class data sets. The PSO-SVM algorithm is used to test the proposed feature selection method on some UCI data sets. The experimental results demonstrate that the proposed method is effective on the data sets with a large number of features. Compared with the MVO-SVM method [
2], the proposed method performs better on some data sets, such as the Hear and Ionosphere data sets, with an accuracy rate 2.73% and 2.56% higher than MVO-SVM, respectively. Similarly, compared with the GA-SVM method [
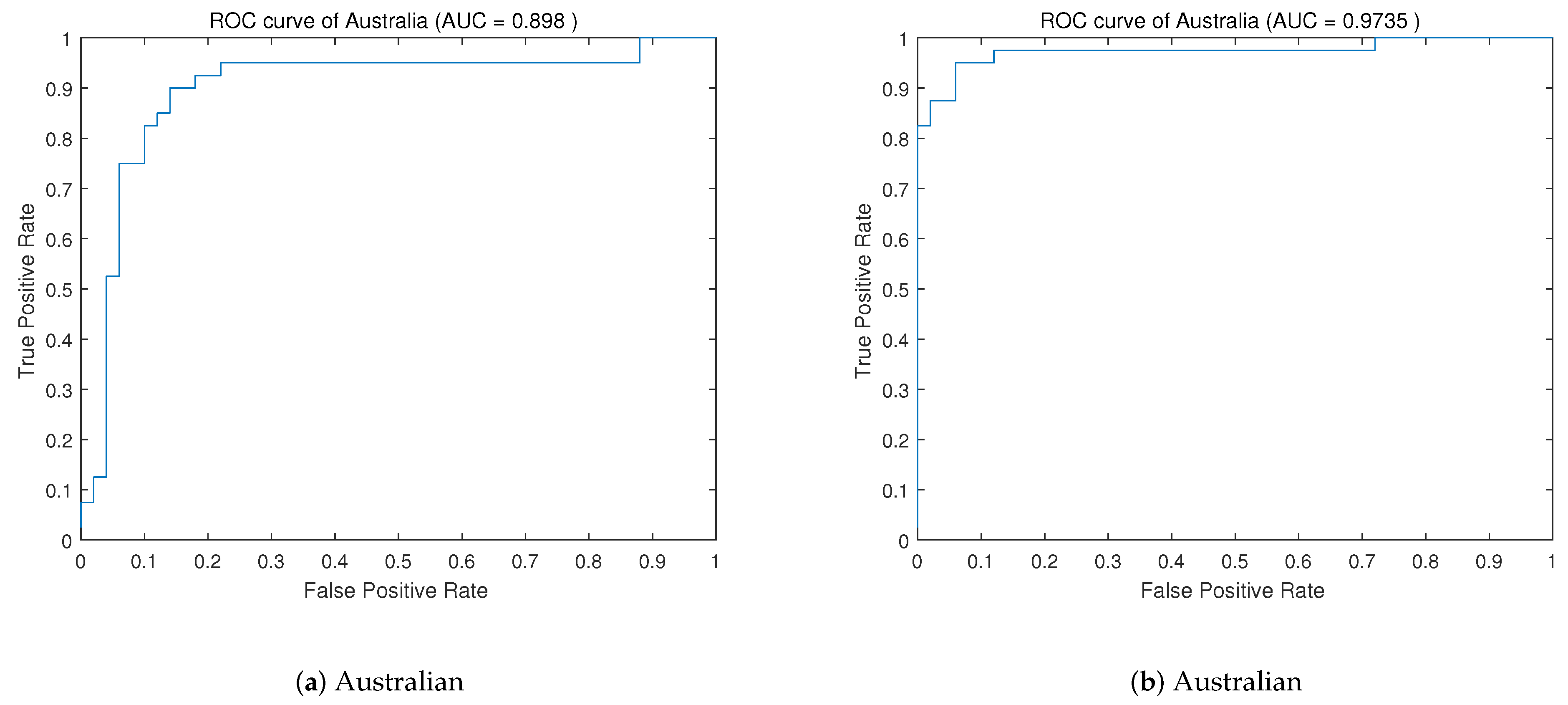
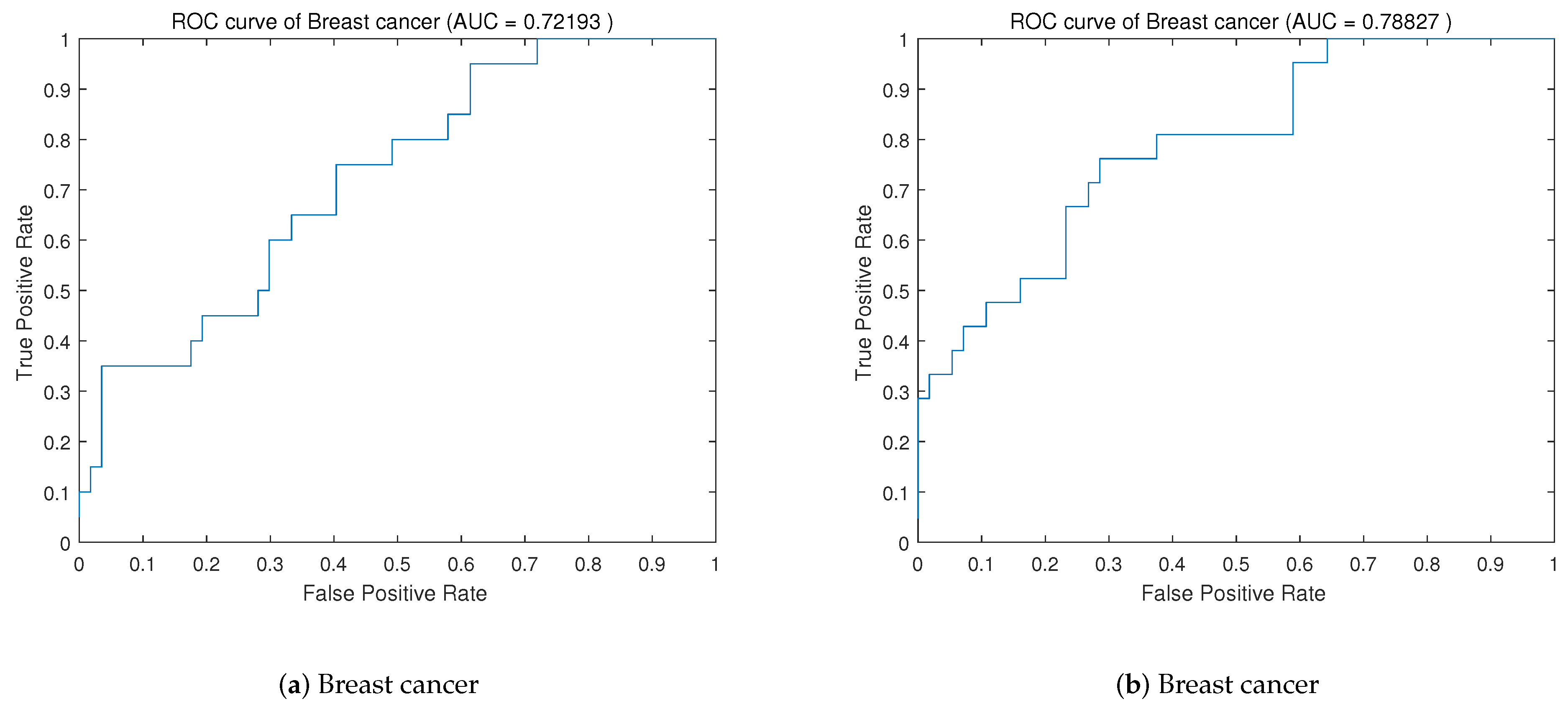
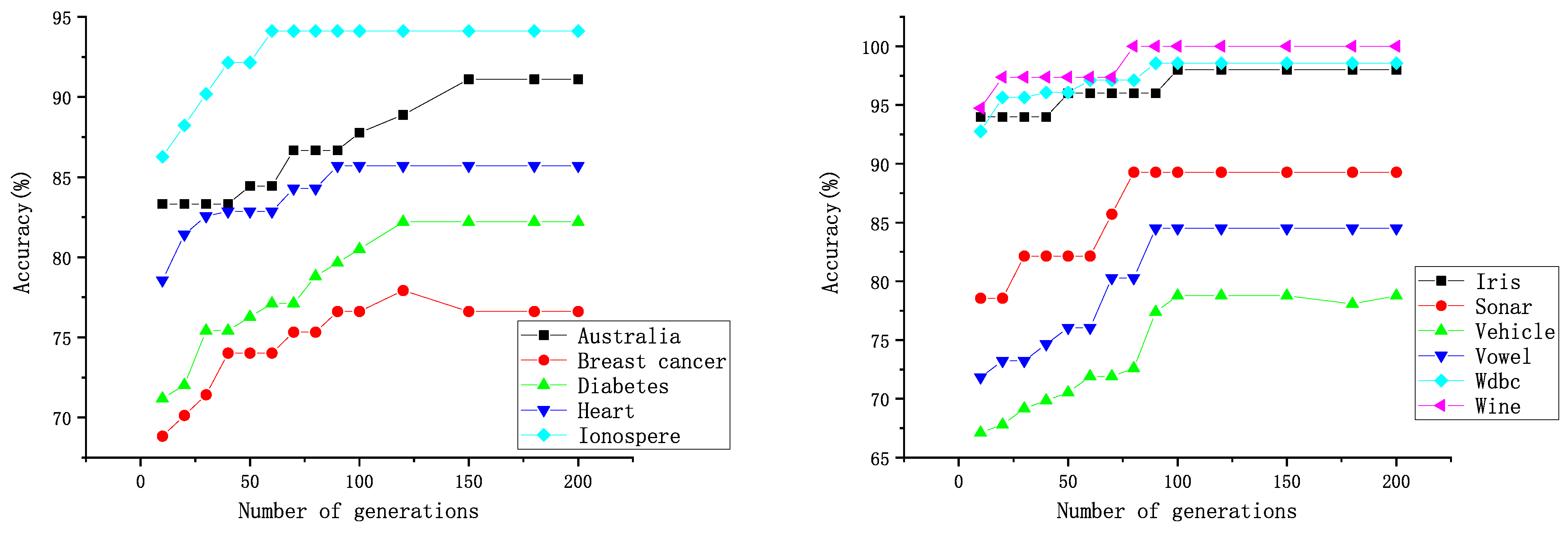
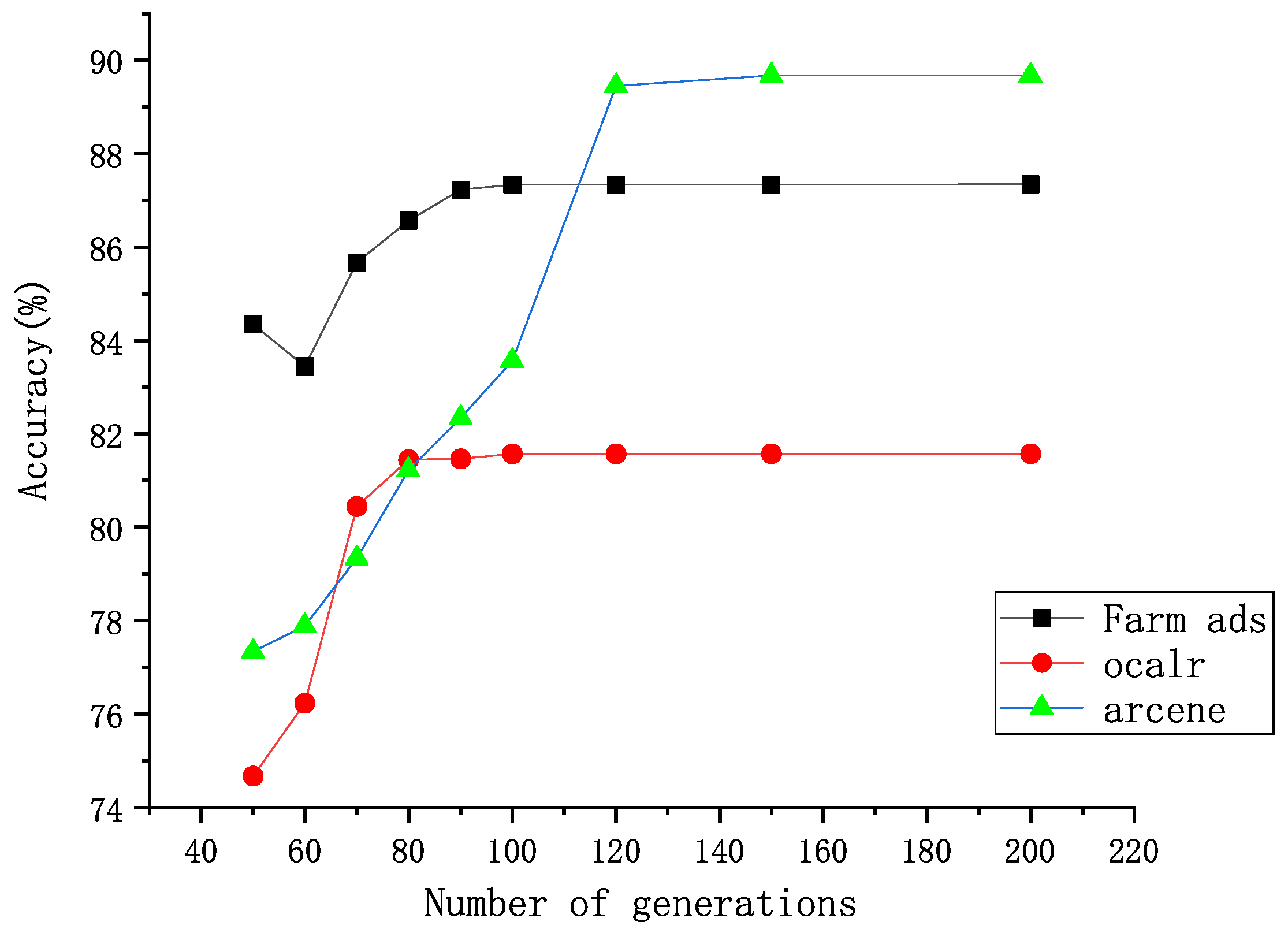
3], in the terms of the two indicators TNR and TPR, the proposed method also performs better on most data sets. For example, DWPSO is 17% higher on TPR and 1.33% higher on TNR than GA-SVM on the data sets Diabetes and Ionosphere. The classification accuracy is significantly improved, and the training time is significantly reduced.
Using the proposed feature selection method, an improved PSO algorithm is proposed to optimize the SVM parameters and RBF kernel parameters. By improving the variation of the inertia factor in the PSO algorithm, the population diversity in the later stage of the PSO algorithm can be increased to avoid premature convergence. In addition, the inertia factor can be adjusted and changed according to the actual situation. The experimental results show that compared with the hybrid algorithm of elementary particle swarm and SVM, the DWPSO-SVM is improved on all data sets in terms of accuracy, TPR, and TNR. Compared with other PSO algorithms and the meta-heuristic algorithms, our proposed algorithm is also optimal on most data sets, which proved that our improved algorithm has a significant effect on improving the accuracy of SVM.
The instability is the limitation of PSO, while the grid algorithm has good stability but poor efficiency. How to combine the advantages of these two algorithms needs to be explored in the next step. In fact, there are some redundant and invalid samples when applying the proposed feature selection algorithm. How to efficiently screen the redundant samples in the data set is also a problem that we want to focus on in the future. The training time can be decreased, since the accuracy of the DWPSO-SVM has satisfied almost all of the situations. For example, some scholars have proposed using the meta-learning method to reduce the training time. However, the meta-learning methods always make the accuracy of the classifier decrease. Therefore, we will attempt to reduce the training time of the classifier on the premise of maintaining accuracy and stability.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}