

On the Security of Offloading Post-Processing for Quantum Key Distribution

Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
1.3. Outline of the Work
2. Quantum Key Distribution
2.1. QKD Post-Processing
- Sifting removes non-relevant information from the raw key (e.g., in conjugate coding protocols, events prepared and measured in different bases are deleted). Additionally, events not received by Bob are discarded in discrete-variable protocols (cf. Section 3).
- Error estimation determines an upper bound on the information leaked to an adversary on the quantum channel and can provide information to optimize the subsequent information reconciliation. Although more advanced methods have been proposed in the literature, this is typically accomplished by cut-and-choose methods. Additionally, the idea of using a confirmation phase to replace error estimation was proposed by Lütkenhaus [13].
- Information reconciliation, which often uses methods from forward error correction, aims at correcting all errors in the remaining raw key so that the sender and receiver should obtain identical keys. The classical (non-quantum) messages exchanged in this process must not leak information on the final key. Typically, the leakage is tracked and treated during the privacy amplification step.
- Confirmation detects non-identical keys (for which information reconciliation has failed) with a probability close to one. If non-identical keys are detected, then the parties either go back to the information reconciliation step or abort the QKD protocol.
- Finally, privacy amplification eliminates the information leaked during all protocol steps (quantum and classical) from the final key by running a (strong) randomness extraction protocol between the peers.
2.2. Motivation to Offload Post-Processing
3. Outsourcing Information Reconciliation
3.1. Linear One-Way Information Reconciliation
3.2. Protocol for Offloading Direct Reconciliation
3.3. On Outsourcing Reverse Reconciliation
- A one-time pad (OTP);
- Permutation;
- Padding (i.e., adding dummy (error) bits).
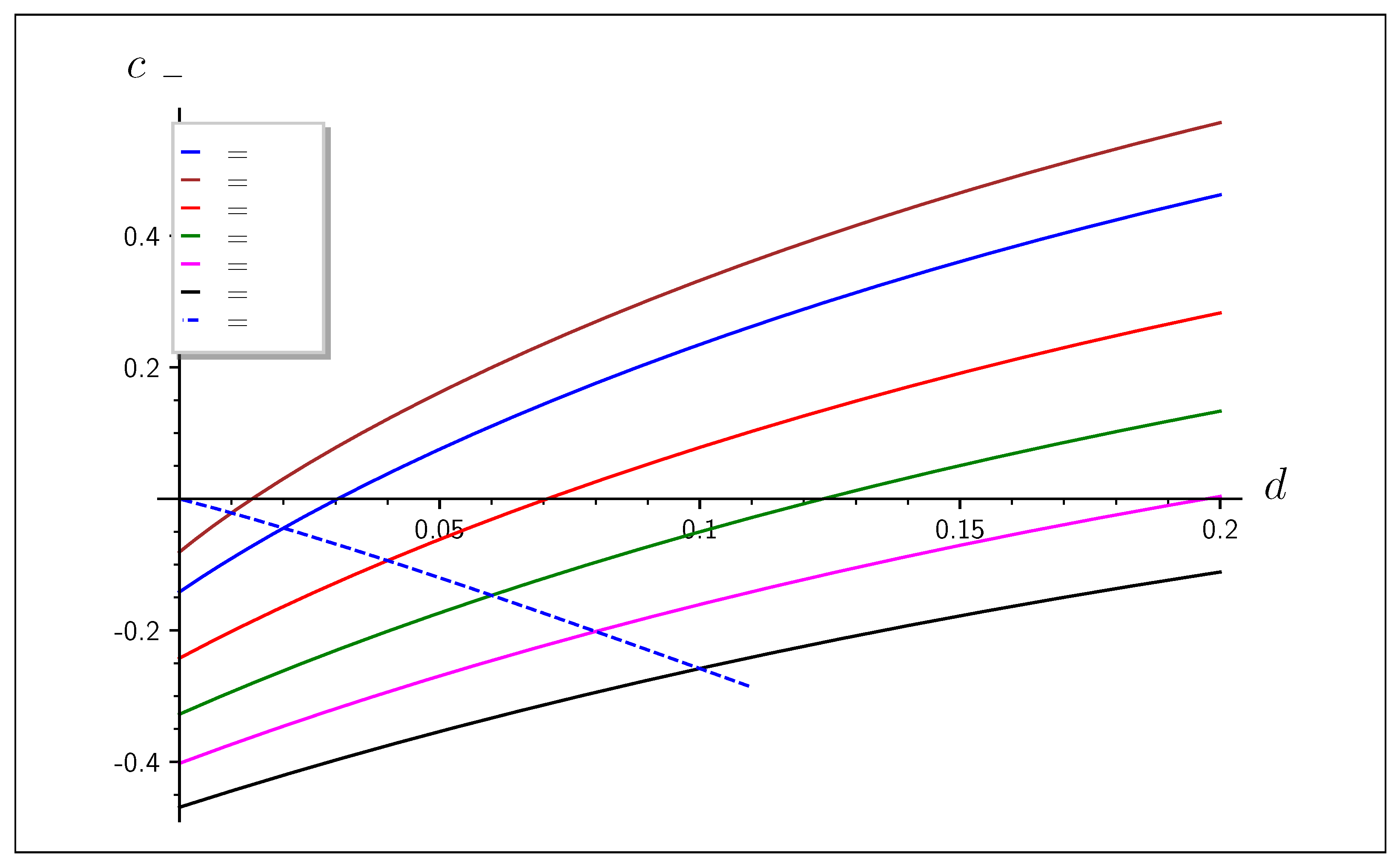
3.4. Verifiability of Outsourced IR
- Check if ; otherwise, abort the process.
- Optional: Check if the weight of is indeed below the threshold of the code or is consistent with the estimated error, and abort otherwise.
3.5. Multiparty Computation-Based Outsourcing
- In the first step, the variable nodes pass their values to the check nodes, where they are combined to compute the check value, which is zero when the check is fulfilled and one if not.
- In the second step, the values of the check nodes are passed back to the variable nodes, where they are aggregated (i.e., the number of check nodes not satisfied is counted for each variable node).
- Thirdly, the algorithm terminates if all checknodes are zero.
- Finally, the algorithm computes which variable nodes have to be flipped. Here, we used Gallager’s algorithm B [35] in our implementation, which basically compares the counts computed in step two against a threshold value to decide which bits are flipped. Although the threshold value for comparison is public, this comparison has to be carried out obliviously to protect the variable node state as well as the bit flip information.
| Algorithm 1: MPC version of bit flip decoding with Gallager’s Algorithm B |
 |
4. Offload Privacy Amplification
- Alice randomly generates a uniform string of a length defining the Toeplitz matrix and sends it to Bob.
- Alice computes as the final key.
- Bob receives from Alice and also computes his key as .
5. Use Cases
6. Conclusions
7. Patents
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Martinez-Mateo, J.; Pacher, C.; Peev, M.; Ciurana, A.; Martin, V. Demystifying the information reconciliation protocol cascade. Quantum Inf. Comput. 2015, 15, 453–477. [Google Scholar] [CrossRef]
- Pedersen, T.B.; Toyran, M. High performance information reconciliation for QKD with CASCADE. Quantum Inf. Comput. 2015, 419–434. [Google Scholar] [CrossRef]
- Mao, H.K.; Qiao, Y.C.; Li, Q. High-Efficient Syndrome-Based LDPC Reconciliation for Quantum Key Distribution. Entropy 2021, 23, 1440. [Google Scholar] [CrossRef] [PubMed]
- Pacher, C.; Abidin, A.; Lorünser, T.; Peev, M.; Ursin, R.; Zeilinger, A.; Larsson, J. Attacks on quantum key distribution protocols that employ non-ITS authentication. Quantum Inf. Process. 2016, 15, 327–362. [Google Scholar] [CrossRef] [Green Version]
- Maurhart, O.; Pacher, C.; Happe, A.; Lor, T.; Tamas, C.; Poppe, A.; Peev, M. New release of an open source QKD software: Design and implementation of new algorithms, modularization and integration with IPSec. In Proceedings of the QCRYPT 2013, Waterloo, ON, Canada, 5–9 August 2013. [Google Scholar]
- Wang, X.; Zhang, Y.; Yu, S.; Guo, H. High-speed implementation of length-compatible privacy amplification in continuous-variable quantum key distribution. IEEE Photonics J. 2018, 10, 1–10. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Li, Y.; Xu, B.; Ma, L.; Yang, J.; Huang, W. High-throughput GPU layered decoder of quasi-cyclic multi-edge type low density parity check codes in continuous-variable quantum key distribution systems. Sci. Rep. 2020, 10, 14561. [Google Scholar] [CrossRef]
- Yang, S.S.; Lu, Z.G.; Li, Y.M. High-Speed Post-Processing in Continuous-Variable Quantum Key Distribution Based on FPGA Implementation. J. Lightwave Technol. 2020, 38, 3935–3941. [Google Scholar] [CrossRef]
- Yang, S.S.; Liu, J.Q.; Lu, Z.G.; Bai, Z.L.; Wang, X.Y.; Li, Y.M. An FPGA-Based LDPC Decoder with Ultra-Long Codes for Continuous-Variable Quantum Key Distribution. IEEE Access 2021, 9, 47687–47697. [Google Scholar] [CrossRef]
- Müller-Quade, J.; Renner, R. Composability in quantum cryptography. New J. Phys. 2009, 11, 85006. [Google Scholar] [CrossRef] [Green Version]
- Wegman, M.N.; Carter, L. New Hash Functions and Their Use in Authentication and Set Equality. J. Comput. Syst. Sci. 1981, 22, 265–279. [Google Scholar] [CrossRef] [Green Version]
- Banfi, F.; Maurer, U.; Portmann, C.; Zhu, J. Composable and Finite Computational Security of Quantum Message Transmission. In Proceedings of the Theory of Cryptography; Hofheinz, D., Rosen, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 282–311. [Google Scholar]
- Lütkenhaus, N. Estimates for practical quantum cryptography. Phys. Rev. A 1999, 59, 3301–3319. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Z.; Plews, A.; Takahashi, R.; Doi, K.; Tam, W.; Sharpe, A.; Dixon, A.; Lavelle, E.; Dynes, J.; Murakami, A.; et al. 10-Mb/s Quantum Key Distribution. J. Lightwave Technol. 2018, 36, 3427–3433. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; Yang, S.; Wonfor, A.; White, I.; Penty, R. Demonstration of high-speed and low-complexity continuous variable quantum key distribution system with local local oscillator. Sci. Rep. 2021, 11, 9454. [Google Scholar] [CrossRef]
- Neppach, A.; Pfaffel-Janser, C.; Wimberger, I.; Loruenser, T.; Meyenburg, M.; Szekely, A.; Wolkerstorfer, J. Key management of quantum generated keys in IPSEC. In Proceedings of the International Conference on Security and Cryptography SECRYPT 2008, Porto, Portugal, 26–29 July 2008. [Google Scholar]
- Bennett, C.H.; Brassard, G. Quantum cryptography: Public key distribution and coin tossing. In Proceedings of the IEEE International Conference on Computers, Systems, and Signal Processing, Bangalore, India, 9–12 December 1984. [Google Scholar]
- Grünenfelder, F.; Boaron, A.; Rusca, D.; Martin, A.; Zbinden, H. Performance and security of 5 GHz repetition rate polarization-based quantum key distribution. Appl. Phys. Lett. 2020, 117, 144003. [Google Scholar] [CrossRef]
- Brassard, G.; Salvail, L. Secret-Key Reconciliation by Public Discussion. In Proceedings of the Advances in Cryptology—EUROCRYPT ’93, Workshop on the Theory and Application of of Cryptographic Techniques, Lofthus, Norway, 23–27 May 1993. [Google Scholar]
- Pacher, C.; Grabenweger, P.; Martinez-Mateo, J.; Martin, V. An information reconciliation protocol for secret-key agreement with small leakage. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015. [Google Scholar]
- Elkouss, D.; Martinez, J.; Lancho, D.; Martin, V. Rate compatible protocol for information reconciliation: An application to QKD. In Proceedings of the 2010 IEEE Information Theory Workshop on Information Theory (ITW 2010), Dublin, Ireland, 30 August–3 September 2010. [Google Scholar]
- Mani, H.; Gehring, T.; Grabenweger, P.; Ömer, B.; Pacher, C.; Andersen, U.L. Multiedge-type low-density parity-check codes for continuous-variable quantum key distribution. Phys. Rev. A 2021, 103, 062419. [Google Scholar] [CrossRef]
- Slepian, D.S.; Wolf, J.K. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Wyner, A.D.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Scarani, V.; Bechmann-Pasquinucci, H.; Cerf, N.J.; Dusek, M.; Lütkenhaus, N.; Peev, M. The security of practical quantum key distribution. Rev. Mod. Phys. 2009, 81, 1301–1350. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Mateo, J.; Elkouss, D.; Martin, V. Blind Reconciliation. arXiv 2012, arXiv:1205.5729. [Google Scholar] [CrossRef]
- Maurer, U.M. Secret key agreement by public discussion from common information. IEEE Trans. Inf. Theory 1993, 39, 733–742. [Google Scholar] [CrossRef] [Green Version]
- Furrer, F. Reverse-reconciliation continuous-variable quantum key distribution based on the uncertainty principle. Phys. Rev. A 2014, 90, 042325. [Google Scholar] [CrossRef] [Green Version]
- Leverrier, A.; Grosshans, F.; Grangier, P. Finite-size analysis of a continuous-variable quantum key distribution. Phys. Rev. A 2010, 81. [Google Scholar] [CrossRef] [Green Version]
- Ben-Or, M.; Goldwasser, S.; Wigderson, A. Completeness theorems for non-cryptographic fault-tolerant distributed computation. In Proceedings of the Twentieth Annual ACM Symposium on Theory of Computing (STOC ’88), Chicago, IL, USA, 2–4 May 1988. [Google Scholar]
- Chaum, D.; Crepeau, C.; Damgdr, I. Multiparty unconditionally secure protocols. In Proceedings of the Twentieth Annual ACM Symposium on Theory of Computing (STOC ’88), Chicago, IL, USA, 2–4 May 1988. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Raeini, M.G.; Nojoumian, M. Secure error correction using multiparty computation. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC 2018), Las Vegas, NV, USA, 8–10 January 2018. [Google Scholar]
- Richardson, T.J.; Urbanke, R.L. The capacity of low-density parity-check codes under message-passing decoding. IEEE Trans. Inf. Theory 2001, 47, 599–618. [Google Scholar] [CrossRef]
- Gallager, R.G. Low-Density Parity-Check Codes; MIT Press: Cambridge, MA, USA, 1963. [Google Scholar]
- Lorünser, T.; Wohner, F. Performance Comparison of Two Generic MPC-frameworks with Symmetric Ciphers. In Proceedings of the 17th International Joint Conference on e-Business and Telecommunications, SCITEPRESS—Science and Technology Publications, Virtual Conference, 8–10 July 2020. [Google Scholar]
- Feldman, J.; Wainwright, M.J.; Karger, D.R. Using linear programming to decode binary linear codes. IEEE Trans. Inf. Theory 2005, 51. [Google Scholar] [CrossRef] [Green Version]
- Feldman, J. Decoding Error-Correcting Codes via Linear Programming. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2003. [Google Scholar]
- Toft, T. Solving Linear Programs Using Multiparty Computation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5628 LNCS, pp. 90–107. [Google Scholar] [CrossRef]
- Lorünser, T.; Wohner, F.; Krenn, S. A Verifiable Multiparty Computation Solver for the Assignment Problem and Applications to Air Traffic Management. arXiv 2022, arXiv:2205.03048. [Google Scholar]
- Milovancev, D.; Honz, F.; Vokic, N.; Laudenbach, F.; Hübel, H.; Schrenk, B. Ultra-Low Noise Balanced Receiver with >20 dB Quantum-to-Classical Noise Clearance at 1 GHz. In Proceedings of the European Conference on Optical Communication, (ECOC 2021), Bordeaux, France, 13–16 September 2021. [Google Scholar]
- Milovančev, D.; Vokić, N.; Pacher, C.; Khan, I.; Marquardt, C.; Boxleitner, W.; Hübel, H.; Schrenk, B. Towards Integrating True Random Number Generation in Coherent Optical Transceivers. IEEE J. Sel. Top. Quantum Electron. 2020, 26, 1–8. [Google Scholar] [CrossRef]
- Treiber, A.; Poppe, A.; Hentschel, M.; Ferrini, D.; Lorünser, T.; Querasser, E.; Matyus, T.; Hübel, H.; Zeilinger, A. Fully automated entanglement-based quantum cryptography system for telecom fiber networks. New J. Phys. 2009, 11, 20. [Google Scholar] [CrossRef]
- Loruenser, T.; Querasser, E.; Matyus, T.; Peev, M.; Wolkerstorfer, J.; Hutter, M.; Szekely, A.; Wimberger, I.; Pfaffel-Janser, C.; Neppach, A. Security processor with quantum key distribution. In Proceedings of the Application-Specific Systems, Architectures and Processors (ASAP 2008), Leuven, Belgium, 2–4 July 2008. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Block Size | Bitwidth | Circuit Depth | Time | Data | Rounds | Bitrate@10iter |
|---|---|---|---|---|---|---|
| (s) | (MB) | (bps) | ||||
| 1000 | 4 | 9 | 0.06 | 3.0 | 65 | 1571 |
| 1000 | 8 | 11 | 0.09 | 3.8 | 80 | 1116 |
| 10,000 | 4 | 9 | 0.11 | 4.4 | 85 | 8932 |
| 10,000 | 8 | 11 | 0.14 | 4.7 | 95 | 7054 |
| 100,000 | 4 | 9 | 1.2 | 44 | 805 | 8354 |
| 100,000 | 8 | 11 | 1.4 | 47 | 846 | 7117 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lorünser, T.; Krenn, S.; Pacher, C.; Schrenk, B. On the Security of Offloading Post-Processing for Quantum Key Distribution. Entropy 2023, 25, 226. https://doi.org/10.3390/e25020226
Lorünser T, Krenn S, Pacher C, Schrenk B. On the Security of Offloading Post-Processing for Quantum Key Distribution. Entropy. 2023; 25(2):226. https://doi.org/10.3390/e25020226
Chicago/Turabian StyleLorünser, Thomas, Stephan Krenn, Christoph Pacher, and Bernhard Schrenk. 2023. "On the Security of Offloading Post-Processing for Quantum Key Distribution" Entropy 25, no. 2: 226. https://doi.org/10.3390/e25020226