In this section, numerical experiments are conducted to the effectiveness of our proposed rank-adaptive tensor completion based on Tucker decomposition (RATC-TD) algorithm.
5.1. Test Problem 1: The Recovery of Third-Order Tensors
Many tensor recovery algorithms in the Tucker scheme require a priori given the rank of the tensor, but our method does not require this. In this test problem, synthetic data are considered, and we set the random composition tensor in the same way as [
9]. We consider the tensor
and obtain tensors by multiplying a randomly generated kernel
of size
with randomly generated factor matrices
, where
. So, the tensor
can be represented by
, and the number of entries of
is denoted by
. By setting tensors in this way, we can obtain random tensors and ensure that the obtained tensors have a low-rank structure, which can be handled well by the classical low-rank tensor recovery methods.
In this experiment, we set the tensor size as , the kernel size as , and the kernel data are randomly generated from the interval . The factor matrices are of size , and the data of factor matrices are randomly generated from . In order to show the robustness and reliability of our proposed algorithm, we add a small perturbation to the synthetic data. We add Gaussian noise with zero mean and standard deviation as times the element mean and take the tensor with Gaussian noise as the ground truth data. As described above, our algorithm does not require the rank in advance, and the algorithm takes the size of the tensor as the initial tensor rank. With the continuous operation of the algorithm, the tucker rank is constantly reduced, and the exact rank can be approximated.
We compare the proposed algorithm with other Tucker-decomposition-based tensor completion algorithms (that require appropriate ranks given a priori), including gHOI [
24], M
SA [
11] and Tucker–Wopt [
5], and test the sample estimation error
and out-of-sample estimation error
with different initial ranks at sampling rates
r (the proportion of known data in the total data) of
,
and
, respectively. The size of the observed index set
is
, and each index in
is randomly generated through the uniform distribution.
denotes the complementary set of
. The specific definitions of two kinds of errors are given by the following formulas:
where
is the result obtained by completion algorithms.
To ensure the generalization of the proposed algorithms, we set the error tolerance
on the observed data to 0.0025, which means we stop optimizing
with SVT when the relative error is less than
or the maximum number of iterations is reached. When using SVT to optimize
, we set the relative error
in the following format:
For the estimated tensor
obtained at each iteration in Algorithm 4, the relative error is assessed as (
32) and (
33), for other methods considered, the relative errors are also assessed using the same form. In addition to the relative error and the maximum number of iterations, Algorithm 4 also terminates if the difference of the relative errors obtained from the algorithm for two consecutive steps is less than a certain threshold
, i.e.,
where the
represents the relative error obtained at the
kth iteration.
The initial rank is set to
.
Table 1 and
Table 2 respectively show recovery error (
32) and (
33) of test problem 1. It can be seen that when the given initial rank does not match the ground truth data, gHOI, M
SA and Tucker–Wopt have large errors, while our RATC-TD has small errors. We emphasize that our proposed method does not require a given tensor rank; the initial rank of our proposed algorithm is set to the size of the tensor we aim to complete, i.e.,
size
.
In this experiment, we use our RATC-TD algorithm to estimate the tensor ranks. We next use the M
SA method to improve the estimated results. Our algorithm can be considered an initial step for other algorithms, and the effects of tensor completion are also sound when only our method is used for optimization. The recovery results without using M
SA are shown in
Table 3. As seen from
Table 2, since our method was used for optimization in advance, compared with the results obtained by simply using the M
SA method with a given rank, it gives a better recovery effect. Notably, our proposed algorithm can also stably complete the tensor under a small sampling rate and does not need to give an appropriate rank in advance.
5.2. Test Problem 2: The Recovery of Fourth-Order Tensors
Similarly to test problem 1, following the procedures in [
9], we in this test problem generate the object tensor
by multiplying a randomly generated kernel
with randomly generated factor matrices of size
. The ground truth data is defined by
with Gaussian noise added (the same setting as in test problem 1). For gHOI, M
SA, Tucker–Wopt and our proposed RATC-TD, different initial ranks are tested, and the sampling rate
r is set to
. The corresponding number of entries in the observed data set
is
, and the index of each entry in
is randomly generated through the uniform distribution. The errors for this test problem are shown in
Table 4, where
is the error on the observed data set (
32) and
is the error on the validation set (
33). It can be seen that our RATC-TD method performs well for this test problem.
5.3. Test Problem 3: The Recovery of Real Missing Pictures
In this test problem, real practical data are considered, and the performance of our RATC-TD is compared with that of gHOI and M
SA. The initial complete images considered are shown in
Figure 1. The data format of each image can be regarded as a third-order tensor. Each image here is stored as a tensor with size
, where the third dimension is 3, representing three color channels of red, green, and blue. The ground truth data
for this test problem are the images in
Figure 1 (details are as follows).
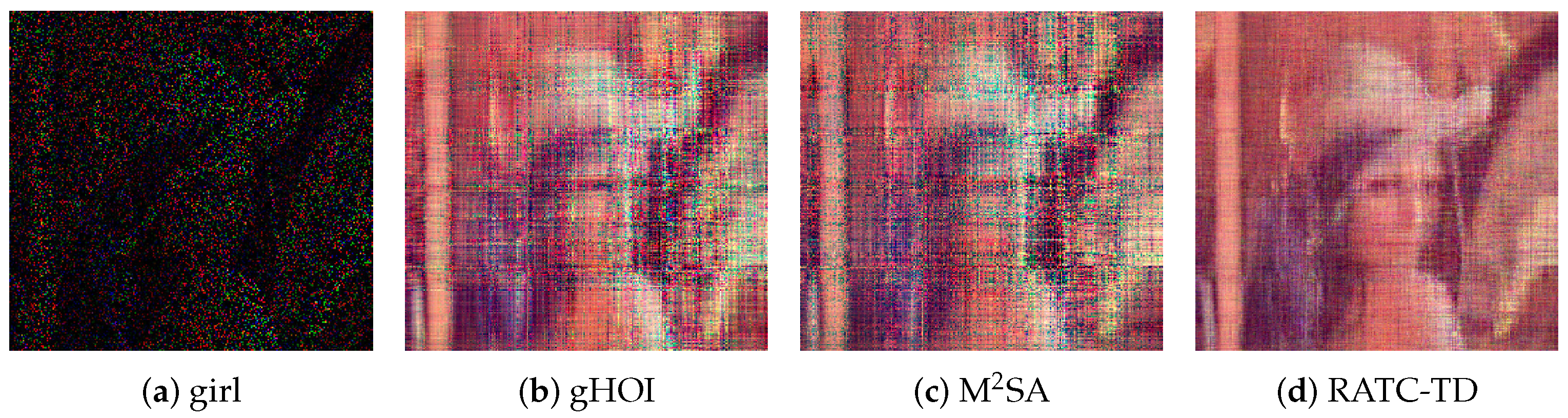
Two ways to construct partial images are considered, and our method is tested to recover the original images using the partial images. First, some black lines are added to the images, which can be considered a kind of structural missing, and the corrupted images are shown in the first column of
Figure 2. The black line parts of images correspond to
, and the rest correspond to
. Second, after the initial image is converted into the data format of a third-order tensor
, the observed index set
is constructed with each index randomly generated through the uniform distribution, and the size of
is
(where the sampling rate is
). The images associated with
are shown in the first column of
Figure 3.
From
Figure 2, it is clear that the images obtained by our RATC-TD are closer to the ground truth images than the ones obtained by gHOI and M
SA. The numerical results representing the qualities of recovery are shown in
Table 5. In addition to the errors
(
32) on the observation set and the errors
(
33) on the unobserved data set, we also use SSIM (structure similarity index measure) [
29] and PSNR (peak signal-to-noise ratio) parameters to evaluate the effect of our image restoration, which are often used to assess the quality of image restoration. SSIM ranges from 0 to 1; the larger the SSIM is, the smaller the image distortion is. Similarly, the larger the PSNR is, the less distortion there is. PSNR is used to measure the difference between two images. For the restored image
and the original image
, the PSNR between them is given by the following formula:
where
is the maximum value of the image pixel. In our test problem,
, and
is the mean square error between
and
. For the case with sampling rate
, the corresponding restoration results are shown in
Figure 3, and the numerical results representing the qualities of recovery are shown in
Table 6. In this case, we only use 10 percent of the ground truth data, but it can be seen that our RATC-TD gives effective recovery results for this test problem.
For the gHOI method and the MSA method, which need to be given the rank of the initial tensor in advance, we choose the initial rank as . It is worth noting that for real image data, it is difficult for us to know the exact Tucker rank in advance. When there is no way to know the rank in advance, in order to use gHOI and MSA to achieve data completion, the initial rank can only be constantly adjusted through experiments, or the rank is given based on prior experience.







{kind=link}
{kind=link}
{kind=link}
{kind=link}