
A Real-Time and Robust Neural Network Model for Low-Measurement-Rate Compressed-Sensing Image Reconstruction

Abstract
:1. Introduction
- This paper proposes RootsNet for a small step toward truly trustworthy deep-learning-based CS image reconstruction. Instead of being a black-box as its counterparts are, RootsNet integrates the CS mechanism into the network to prevent error propagation. The error-injection test in Section 4.2.4 shows RootsNet is much more robust than its counterparts.
- RootsNet enables real-time reconstruction and supports different measurement rates in a single net for general measurement matrices. Section 4.2 validates this feature.
- RootsNet successfully reconstructs super-low measurement rates that are impossible for traditional optimization-theory-based methods. The qualitative evaluation on two real-world applications, presented in Section 4.1, shows this powerful ability. At least 60% of the measurement time is saved in one microwave testing system using the proposed method. The proposed method achieves extremely low measurement rates, which saved at least 95% of storage in one pipeline monitoring system. The quantitative evaluation, presented in Section 4.2.3, also validates this ability.
2. Compressed Sensing Measurement Theory
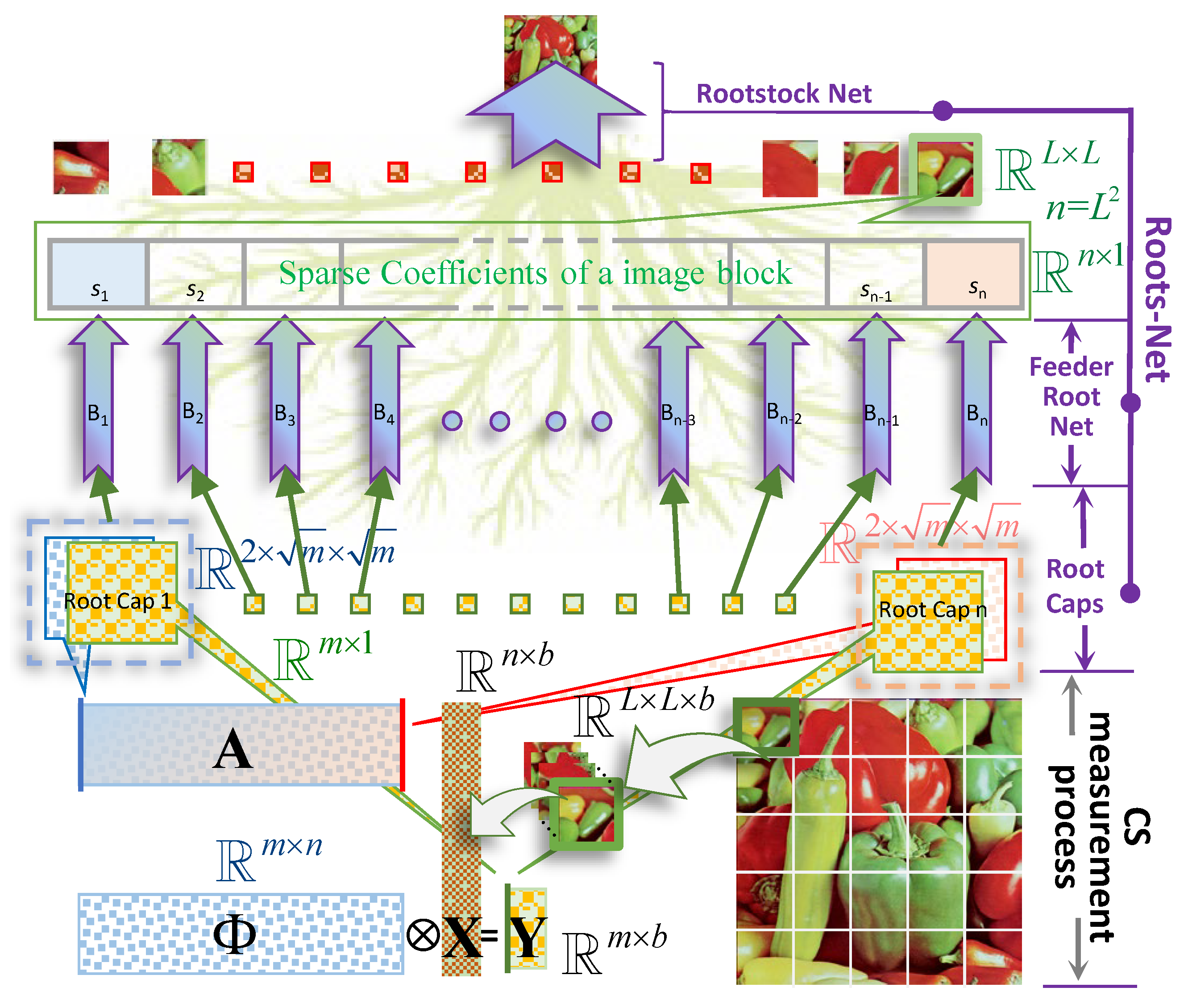
3. The Proposed Rootsnet
3.1. Overall Structure of RootsNet
3.2. Key Modules in RootsNet
3.2.1. Root Caps
3.2.2. The Feeder Root Net Module
3.2.3. The Rootstock Net Module
3.3. The Underlying Information Theory for RootsNet
3.4. Training Methods
4. Experimental Results
4.1. Qualitative Evaluation in Real-World Applications for Low Measurement Rates Reconstruction
4.1.1. Application in Near-Field Microwave Imaging
4.1.2. Application in Pipeline Inspection Robot
4.2. Quantitative Evaluation on SET11
4.2.1. The Influence of Sparse Basis and Roostock Net Module
4.2.2. The Influence of Feeder Root Branch Number on RootsNet
4.2.3. The Influence of Measurement Rates on RootsNet
4.2.4. Evaluation of Robustness
4.2.5. Evaluation of Reconstruction Time
4.2.6. Evaluation of Reconstruction Quality
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, K.; Cui, W.; Xu, X. Superresolution Radar Imaging via Peak Search and Compressed Sensing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Cui, Y.; Yin, L.; Zhou, H.; Gao, M.; Tang, X.; Deng, Y.; Liang, Y. Compressed sensing based on L1 and TGV regularization for low-light-level images denoising. Digit. Signal Process. 2023, 136, 103975. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, L.; Wang, X.; Shen, X.; Li, L. Secure Remote Sensing Image Registration Based on Compressed Sensing in Cloud Setting. IEEE Access 2019, 7, 36516–36526. [Google Scholar] [CrossRef]
- Oya, J.R.G.; Hidalgo-Fort, E.; Chavero, F.M.; Carvajal, R.G. Compressive-Sensing-Based Reflectometer for Sparse-Fault Detection in Elevator Belts. IEEE Trans. Instrum. Meas. 2020, 69, 947–949. [Google Scholar] [CrossRef]
- Sun, J.; Yan, C.; Wen, J. Intelligent Bearing Fault Diagnosis Method Combining Compressed Data Acquisition and Deep Learning. IEEE Trans. Instrum. Meas. 2018, 67, 185–195. [Google Scholar] [CrossRef]
- Tang, C.; Tian, G.Y.; Li, K.; Sutthaweekul, R.; Wu, J. Smart Compressed Sensing for Online Evaluation of CFRP Structure Integrity. IEEE Trans. Ind. Electron. 2017, 64, 9608–9617. [Google Scholar] [CrossRef]
- Najafabadi, H.E.; Leung, H.; Guo, J.; Hu, T.; Chang, G.; Gao, W. Structure-Aware Compressive Sensing for Magnetic Flux Leakage Detectors: Theory and Experimental Validation. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, S.; Wang, S.; Zhuang, S.; Wang, Q.; Zhao, W. Compressed Sensing Method for Health Monitoring of Pipelines Based on Guided Wave Inspection. IEEE Trans. Instrum. Meas. 2020, 69, 4722–4731. [Google Scholar] [CrossRef]
- Candés, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Lohit, S.; Kulkarni, K.; Kerviche, R.; Turaga, P.; Ashok, A. Convolutional Neural Networks for Noniterative Reconstruction of Compressively Sensed Images. IEEE Trans. Comput. Imaging 2018, 4, 326–340. [Google Scholar] [CrossRef]
- Shi, W.; Liu, S.; Jiang, F.; Zhao, D. Video Compressed Sensing Using a Convolutional Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 425–438. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 449–458. [Google Scholar]
- Hu, S.W.; Lin, G.X.; Lu, C.S. GPX-ADMM-Net: Interpretable Deep Neural Network for Image Compressive Sensing. IEEE Access 2021, 9, 158695–158709. [Google Scholar] [CrossRef]
- Seong, J.T. Review on non-iterative recovery frameworks in compressed sensing. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–2. [Google Scholar]
- Shi, W.; Jiang, F.; Liu, S.; Zhao, D. Image compressed sensing using convolutional neural network. IEEE Trans. Image Process. 2019, 29, 375–388. [Google Scholar] [CrossRef]
- Shi, W.; Jiang, F.; Liu, S. Scalable convolutional neural network for image compressed sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12290–12299. [Google Scholar]
- Ran, M.; Xia, W.; Huang, Y.; Lu, Z.; Bao, P.; Liu, Y.; Sun, H.; Zhou, J.; Zhang, Y. MD-recon-net: A parallel dual-domain convolutional neural network for compressed sensing MRI. IEEE Trans. Radiat. Plasma Med. Sci. 2020, 5, 120–135. [Google Scholar] [CrossRef]
- Ravelomanantsoa, A.; Rabah, H.; Rouane, A. Compressed Sensing: A Simple Deterministic Measurement Matrix and a Fast Recovery Algorithm. IEEE Trans. Instrum. Meas. 2015, 64, 3405–3413. [Google Scholar] [CrossRef]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- You, D.; Zhang, J.; Xie, J.; Chen, B.; Ma, S. Coast: Controllable arbitrary-sampling network for compressive sensing. IEEE Trans. Image Process. 2021, 30, 6066–6080. [Google Scholar] [CrossRef]
- You, D.; Xie, J.; Zhang, J. ISTA-Net++: Flexible deep unfolding network for compressive sensing. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for compressive sensing MRI. Adv. Neural Inf. Process. Syst. 2016, 29, 1–12. [Google Scholar]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. ADMM-CSNet: A deep learning approach for image compressive sensing. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 521–538. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, X.; Gui, G. Co-robust-ADMM-net: Joint ADMM framework and DNN for robust sparse composite regularization. IEEE Access 2018, 6, 47943–47952. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Liu, J.; Wen, F.; Zhu, C. AMP-Net: Denoising-based deep unfolding for compressive image sensing. IEEE Trans. Image Process. 2020, 30, 1487–1500. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Yu, Z.L.; Gu, Z.; Cheng, Y.; Gong, H. Deep Unfolding With Weighted ℓ2 Minimization for Compressive Sensing. IEEE Internet Things J. 2020, 8, 3027–3041. [Google Scholar] [CrossRef]
- Chan, S.H.; Wang, X.; Elgendy, O.A. Plug-and-play ADMM for image restoration: Fixed-point convergence and applications. IEEE Trans. Comput. Imaging 2016, 3, 84–98. [Google Scholar] [CrossRef]
- Prono, L.; Mangia, M.; Marchioni, A.; Pareschi, F.; Rovatti, R.; Setti, G. Deep Neural Oracle With Support Identification in the Compressed Domain. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 458–468. [Google Scholar] [CrossRef]
- Wu, Y.; Rosca, M.; Lillicrap, T. Deep compressed sensing. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6850–6860. [Google Scholar]
- Zhang, J.; Zhao, C.; Gao, W. Optimization-inspired compact deep compressive sensing. IEEE J. Sel. Top. Signal Process. 2020, 14, 765–774. [Google Scholar] [CrossRef]
- Metzler, C.A.; Maleki, A.; Baraniuk, R.G. From denoising to compressed sensing. IEEE Trans. Inf. Theory 2016, 62, 5117–5144. [Google Scholar] [CrossRef]
- Rossi, P.V.; Kabashima, Y.; Inoue, J. Bayesian online compressed sensing. Phys. Rev. E 2016, 94, 022137. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.; Tian, G.; Boussakta, S.; Wu, J. Feature-Supervised Compressed Sensing for Microwave Imaging Systems. IEEE Trans. Instrum. Meas. 2020, 69, 5287–5297. [Google Scholar] [CrossRef]
- Tang, C.; Tian, G.Y.; Wu, J. Segmentation-oriented Compressed Sensing for Efficient Impact Damage Detection on CFRP Materials. IEEE/ASME Trans. Mechatron. 2021, 26, 2528–2537. [Google Scholar] [CrossRef]
- Bacca, J.; Gelvez-Barrera, T.; Arguello, H. Deep coded aperture design: An end-to-end approach for computational imaging tasks. IEEE Trans. Comput. Imaging 2021, 7, 1148–1160. [Google Scholar] [CrossRef]
- Zonzini, F.; Zauli, M.; Mangia, M.; Testoni, N.; Marchi, L.D. Model-Assisted Compressed Sensing for Vibration-Based Structural Health Monitoring. IEEE Trans. Ind. Inf. 2021, 17, 7338–7347. [Google Scholar] [CrossRef]
- Candés, E.J.; Romberg, J.K.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar] [CrossRef]
- Küng, R.; Jung, P. Robust nonnegative sparse recovery and 0/1-Bernoulli measurements. In Proceedings of the 2016 IEEE Information Theory Workshop (ITW), Cambridge, UK, 11–14 September 2016; pp. 260–264. [Google Scholar]
- Cai, T.T.; Wang, L. Orthogonal matching pursuit for sparse signal recovery with noise. IEEE Trans. Inf. Theory 2011, 57, 4680–4688. [Google Scholar] [CrossRef]
- Wei, P.; He, F. The Compressed Sensing of Wireless Sensor Networks Based on Internet of Things. IEEE Sens. J. 2021, 21, 25267–25273. [Google Scholar] [CrossRef]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Guo, T.; Zhang, T.; Lim, E.; López-Benítez, M.; Ma, F.; Yu, L. A Review of Wavelet Analysis and Its Applications: Challenges and Opportunities. IEEE Access 2022, 10, 58869–58903. [Google Scholar] [CrossRef]
- Nielsen, M. On the Construction and Frequency Localization of Finite Orthogonal Quadrature Filters. J. Approx. Theory 2001, 108, 36–52. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Normalized iterative hard thresholding: Guaranteed stability and performance. IEEE J. Sel. Top. Signal Process. 2010, 4, 298–309. [Google Scholar] [CrossRef]
- Wright, S.J.; Nowak, R.D.; Figueiredo, M.A. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 2009, 57, 2479–2493. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | MR | 0.3 | 0.25 | 0.2 | 0.15 | 0.1 | |
|---|---|---|---|---|---|---|---|
| Methods | |||||||
| OMP [40] | 564.3 | 172.5 | 58.9 | 15.6 | 6.3 | ||
| IHT [46] | 571.8 | 176.5 | 57.7 | 12.5 | 5.7 | ||
| SpaRSA [47] | 692.3 | 224.1 | 71.8 | 22.6 | 9.2 | ||
| OMP-block | 99.7 | 32.9 | 10.0 | 2.8 | 0.9 | ||
| IHT-block | 96.1 | 30.8 | 9.3 | 2.4 | 0.8 | ||
| SpaRSA-block | 192.4 | 58.8 | 18.0 | 4.9 | 1.4 | ||
| ReconNet [13] | 0.021 | 0.022 | 0.021 | 0.021 | 0.021 | ||
| ISTA-Net+ [20] | 0.048 | 0.048 | 0.048 | 0.047 | 0.048 | ||
| CSNet+ [16] | 0.028 | 0.027 | 0.028 | 0.028 | 0.028 | ||
| GPX-ADMM [14] | 0.071 | 0.069 | 0.070 | 0.069 | 0.069 | ||
| AMP-Net-2BM [26] | 0.032 | 0.031 | 0.031 | 0.033 | 0.031 | ||
| AMP-Net-9BM [26] | 0.041 | 0.042 | 0.041 | 0.041 | 0.041 | ||
| RootsNet-SinglePC | 0.047 | 0.046 | 0.046 | 0.047 | 0.047 | ||
| RootsNet-Distributed | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | ||
| PSNR/SSIM | MR | 0.3 | 0.25 | 0.1 | 0.05 | 0.01 | |
|---|---|---|---|---|---|---|---|
| Methods | |||||||
| OMP [40] | 29.91/0.8641 | 28.65/0.8517 | 24.37/0.7143 | 21.26/0.5646 | 17.65/0.2426 | ||
| IHT [46] | 29.31/0.8602 | 28.58/0.8500 | 24.43/0.7108 | 21.17/0.5538 | 17.22/0.2331 | ||
| SpaRSA [47] | 30.86/0.8994 | 29.42/0.8676 | 26.12/0.7729 | 22.13/0.6629 | 19.17/0.3016 | ||
| OMP-block | 27.14/0.8449 | 26.48/0.8303 | 23.60/0.7002 | 20.03/0.5321 | 16.895/0.2234 | ||
| IHT-block | 26.66/0.8346 | 25.21/0.8151 | 23.52/0.6985 | 19.65/0.5482 | 16.01/0.1951 | ||
| SpaRSA-block | 28.23/0.8537 | 27.70/0.8497 | 25.42/0.8177 | 21.72/0.5771 | 17.62/0.2568 | ||
| D-AMP [32] | 32.64/0.7544 | 31.62/0.7233 | 19.87/0.3757 | 14.38/0.1034 | 5.58/0.0034 | ||
| ReconNet [13] | 33.17/0.938 | 32.07/0.9246 | 27.63/0.8487 | 21.73/0.6211 | 17.54/0.4426 | ||
| DCS [30] | 21.98/0.5358 | 21.85/0.5166 | 21.53/0.4546 | 17.67/0.2235 | 12.51/0.1937 | ||
| ISTA-Net+ [20] | 33.66/0.9330 | 32.27/0.9127 | 25.93/0.7840 | 18.34/0.4715 | 17.12/0.3251 | ||
| CSNet+ [16] | 33.90/0.9449 | 32.76/0.9322 | 27.76/0.8513 | 21.07/0.6103 | 20.09/0.5334 | ||
| GPX-ADMM [14] | 33.85/0.9501 | 32.43/0.9382 | 26.96/0.8561 | 19.13/0.5421 | 18.21/0.4653 | ||
| AMP-Net-2BM [26] | 35.21/0.9530 | 33.92/0.9417 | 28.67/0.8654 | 20.82/0.5614 | 20.41/0.5539 | ||
| AMP-Net-9BM [26] | 36.03/0.9586 | 34.63/0.9481 | 29.40/0.8779 | 21.88/0.6441 | 20.20/0.5581 | ||
| RootsNet | 34.16/0.9542 | 32.84/0.9471 | 28.86/0.8597 | 24.74/0.7734 | 22.73/0.7335 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Song, H.; Zeng, Y.; Guo, X.; Tang, C. A Real-Time and Robust Neural Network Model for Low-Measurement-Rate Compressed-Sensing Image Reconstruction. Entropy 2023, 25, 1648. https://doi.org/10.3390/e25121648
Chen P, Song H, Zeng Y, Guo X, Tang C. A Real-Time and Robust Neural Network Model for Low-Measurement-Rate Compressed-Sensing Image Reconstruction. Entropy. 2023; 25(12):1648. https://doi.org/10.3390/e25121648
Chicago/Turabian StyleChen, Pengchao, Huadong Song, Yanli Zeng, Xiaoting Guo, and Chaoqing Tang. 2023. "A Real-Time and Robust Neural Network Model for Low-Measurement-Rate Compressed-Sensing Image Reconstruction" Entropy 25, no. 12: 1648. https://doi.org/10.3390/e25121648