2. Preliminaries
In what follows, we suppose a vertex weighted graph with being a weighting function. If is an edge of G, we say that u and v are adjacent/connected and thus neighbors. Given a vertex v, we define the set of its neighbors, denoted by , as and we use to denote . The degree of a vertex v, denoted by , is defined as . A clique C is a subset of V s.t. any two vertices in C are mutually connected. A clique is said to be maximal if it is not a subset of any other clique. By convention we define size of a clique C, denoted by , to be the number of vertices in it. Given a graph G and a vertex subset , we use to denote the subgraph of G which is induced by , i.e., where . Given a graph G, we use and to denote the set of vertices and edges of G, respectively.
In the following, for the ease of discussions, we generalize the notion of a coloring and allow it to color vertices not in V, so a coloring has now been redefined as with . Then we say that are color classes and we redefine as Obviously according to new definitions, one coloring can have several representations, e.g., and represent the same coloring.
Given a graph G, we use to denote a certain coloring for it. Then Proposition 1 below shows that given any feasible coloring, its cost on any induced subgraph does not exceed that on the whole graph.
Proposition 1. Suppose and . If is a feasible coloring for G, then
is also a feasible coloring for ;
.
Throughout this paper, when we say an optimal coloring/solution, we mean a feasible coloring/solution with the minimum . Given a vertex u, we use to denote u’s color. In addition, we use to denote the operation which assigns u the color j, so assigns u a color which is equal to that of v, i.e., which puts u in the same vertex subset with v.
Given a tuple , we use to denote the number of components in t, so . For ease of expression, if t is an empty tuple, we define to be 0. Given a map and an element , if , then we say that y is x’s image under f or simply say is x’s image under f. Such notions will be useful when we discuss the removal of vertices in clique reductions. Finally, when given vertices u and v, we say that u is heavier (resp. lighter) than v if (resp. ).
2.1. A Reduction Framework
Below we will present notions that are related to graph reductions for the MinVWC problem. The first is an extension to a coloring which relates solutions for a subgraph to that for the whole graph.
Definition 1. Given a coloring and a vertex x s.t. , we define an extension to S with respect to , denoted by , as We also define S as an extension of itself. So an extension to S will not change the color of any vertices that have already been colored before. Instead, it will put a new vertex into one of the k existing vertex partitions if , or a new one if . Obviously given two operations and for extensions, we have , so the order of the operations does not matter.
Given a set , we use to denote , and we also say is an extension to S. Last if or is a feasible color for G, then we say that or is a feasible extension to S for G. Below we have a proposition that will be useful in proving other later propositions.
The proposition below illustrates that extending a coloring will not decrease its cost.
Proposition 2. Given a vertex and a coloring for , then for any .
Next, we define a type of subgraphs whose feasible solutions can be extended into feasible ones for the whole graph with the same .
Definition 2. Suppose and . If given any feasible coloring for , there exists an extension to , denoted by , such that is feasible for G and , then we say that is a VWC-reduced subgraph for G.
This notion of VWC-reduced subgraph has two nice properties which are shown in Propositions 3 and 4 below. In detail, Proposition 3 shows that the relation of the VWC-reduced subgraph is transitive and we can compute a VWC-reduced subgraph in an iterative way.
Proposition 3. Suppose , , is a VWC-reduced subgraph for and is a VWC-reduced subgraph for G, then is a VWC-reduced subgraph for G.
Proposition 4 shows that in order to find an optimal solution for G, we can first find an optimal solution for its VWC-reduced subgraphs.
Proposition 4. Suppose , and is a VWC-reduced subgraph of G, then
- 1.
given any optimal feasible solution for , there exists an extension to which is an optimal solution for G;
- 2.
given any non-optimal feasible solution for , there exist no extension to that is an optimal solution for G.
These propositions allow our algorithms to interleave between clique sampling and graph reduction, which is different from the approach in RedLS [
11] yet similar to that in FastWClq [
12]. This is why we titled this paper ‘iterative clique reductions’.
In what follows we will introduce a general principle for computing VWC-reduced subgraphs.
2.2. Clique Reductions
Below we will utilize the notion of VWC-reduced subgraph to introduce clique reductions which was initially proposed in [
11]. First, we introduce the notion of
absorb which illustrates that a vertex’s close neighborhood is a weak sub-structure of a clique.
Definition 3. Given a vertex u and a clique in G s.t. , , and , then we say that u is absorbed by C.
Note that the condition
guarantees that
always exists. Also notice that [
11] did not allow the equation in
to hold, but we extend their statements slightly.
Example 1. Consider in which denotes Vertex with a weight ω. Let and , then , and , thus and . So we say that is absorbed by C.
To make our descriptions more intuitive, we show C and separately below and moreover, in C a heavier vertex is shown in a darker color. If we left-shift , then we will find that there is a one-to-one map namely , s.t.
- 1.
, that is, u is no heavier than its image under ξ;
- 2.
and for any , , that is, images of u’s neighbors are no lighter than that of u, or we may roughly say that u’s image is the lightest compared to those of its neighbors.
Since , there exist at least 4 colors in any feasible solution for . For coloring vertices in , we only need colors, so there exists at least one color among that of which is not in use for , and we can use it to color u namely without causing any conflicts. Because , even though we assign the same color as that of , the lightest vertex in C, the of that coloring will not increase. So we can now simply ignore and later assign it an existing color after all its neighbors have been colored, depending on its weight as well as its neighbors’ colors. Obviously, this is a feasible extension that does not increase the cost of a coloring. Therefore is a VWC-reduced subgraph of .
In general, we have a proposition below [
11].
Proposition 5. Given a graph G and a vertex u, if there exists a clique C s.t. u is absorbed by C, then is a VWC-reduced subgraph of G.
So if a vertex is absorbed by a clique, it can be removed in order to obtain a VWC-reduced subgraph.
Example 2. Now we continue with Example 1.
- 1.
In , we find that is absorbed by C, so we have is a VWC-reduced subgraph of . Similarly we have is that of and is that of .
- 2.
By Proposition 3, we have is that of . Also we have an optimal coloring for is and .
- 3.
Considering Proposition 4, there exists a feasible extension to , denoted by , s.t. is an optimal solution for . In detail, for coloring the removed vertices in , we can follow the reversed order of the reductions before.
- 4.
So an optimal coloring for is and .
![Entropy 25 01376 i007]()
Furthermore we only have to focus on maximal cliques as is shown by the proposition below.
Proposition 6. If u is absorbed by a clique in G, then it must be absorbed by a maximal clique in G.
From the propositions above, we can see that whether a vertex can be removed to obtain a VWC-reduced subgraph or not depends on the quality of the cliques in hand. Below we define a partial order ⊑ between cliques which indicates whether vertices absorbed by one clique are a subset of those absorbed by the other.
Definition 4. Given a graph and its two cliques and where and , we define a partial order ⊑ s.t. iff
- 1.
;
- 2.
for .
So if , then leads to reductions that are at least as effective as that result from . In what follows, if , we say that is subsumed by . Obviously we have a proposition below which shows that the ⊑ relation is transitive.
Proposition 7. Given a graph and its three cliques , if and , then .
Then we have two propositions which show that if , then we can keep and ignore .
Proposition 8. Suppose u is a vertex and are cliques s.t. and , then if u is absorbed by , then it is also absorbed by .
The proposition below states that if there occur reductions among , and their vertices where , then keeping is at least as good as keeping .
Proposition 9. Suppose are cliques s.t. and where and , if and , then we have for any , if is absorbed by , then is absorbed by .
So if we utilize and to perform clique reductions where , we can simply ignore and keep .
2.3. A State-of-the-Art Reduction Method
To date, as we know, the only work on reductions for vertex weighted coloring is RedLS [
11], which constructs promising cliques like FastWClq [
12] and combines these cliques in an appropriate way to obtain a ‘relaxed’ partition set. Then it utilizes this set to perform reductions and compute lower bounds. So RedLS consists of clique sampling and graph reductions as successive procedures without interleaving.
Notice that FastWClq alternates between clique sampling and graph reduction and it benefits much from this approach. Hence it will be interesting to try whether such an alternating approach would lead to better reductions in vertex weighted coloring. Fortunately, the reduction framework introduced above allows us to do so.
For simplicity, we will put the details of RedLS in
Section 4, where we will be able to reuse our notations and algorithms for succinct presentation.
3. Our Algorithm
Our reduction algorithm consists of three successive procedures: Algorithms 1 and 2 and post reductions in
Section 3.3. As to Algorithm 1, we will first run it with maximum-weight vertices assigned to
in Line 1 and then run it again with maximum-degree vertices in the same way.
3.1. Sampling Promising Cliques
Algorithm 1 samples promising cliques that may lead to considerable reductions with three components as below.
In Line 7, we adopt depth-first search to enumerate all maximal cliques which contain vertices only in
. This operation can be costly, so in
Section 3.4, we will set a cutoff for it. To be specific, before each enumeration, we will first put all related vertices into a list and shuffle this list randomly, then we will pick decision vertices one after another in this list to construct maximal cliques. By decision vertices, we mean those vertices that can both be included and excluded to form different maximal cliques.
Furthermore, Lines 8, 9, 10, and 16 will be introduced in Definition 8. Lines 21 and 22 are based on Proposition 16 and will be introduced in detail there.
| Algorithm 1: PromisingCliqueReductions |
![Entropy 25 01376 i001]() |
3.1.1. Geometric Representations
First, we introduce a notation for representing weight distributions within given cliques.
Definition 5. Given a clique s.t. where , we define its weight list, denoted by , to be .
Second, we introduce an operator for appending items to the end of a weight list, and it is somewhat like counterparts for vector in C++, ArrayList in Java, or list in Python.
Definition 6. Given a list of weights L and a weight ω, we define as if and as if .
In order to describe properties of our algorithms intuitively, we introduce Euclidean geometric representations of a list of weights in a rectangular coordinate system as below.
| Algorithm 2: BetterBoundReductions |
![Entropy 25 01376 i002]() |
| Algorithm 3: updateTopLevelWeights |
![Entropy 25 01376 i003]() |
Definition 7. Given a list of positive numbers , we draw a curve on the Rectangular Coordinate Plane with the list of coordinates by connecting adjacent points, and we call this curve the derived curve of L.
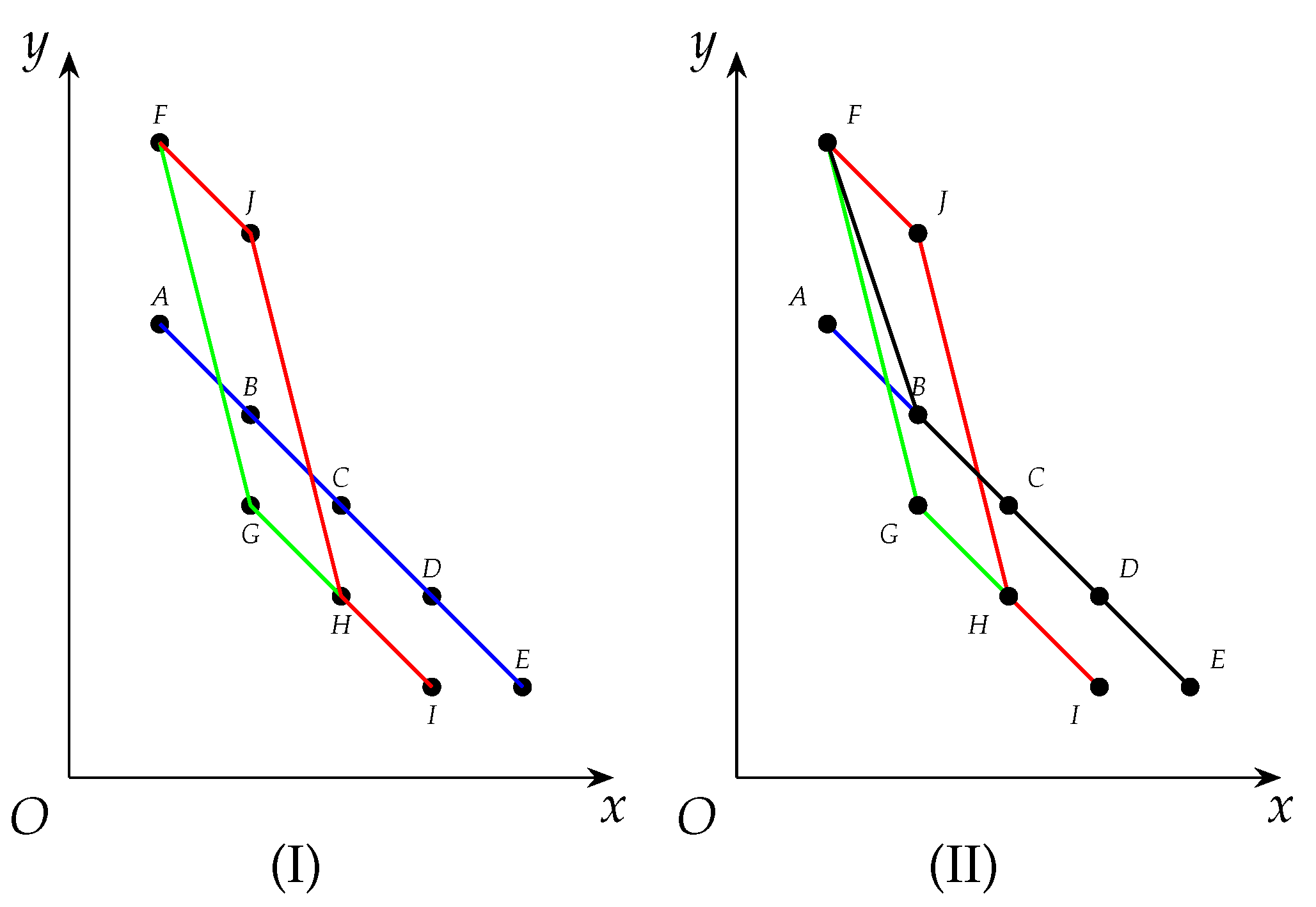
Example 3. Notice . There are three maximal cliques, , and with , and . We draw the derived curves of , and as (blue), (green) and (red) in (I) in Figure 1. On the other hand, we draw the derived curve of
which has just been updated with respect to
and
successively in Algorithm 3 as
(black) in (II) in
Figure 1.
In detail, when has just been updated with respect to , its derived curve exactly overlaps that of .
Next when has just been updated with respect to , a part of its derived curve, namely , has moved to its top-right, namely , so the derived curve of has turned into . Notice that having been updated with respect to and , the derived curve of is the bottom-left most curve that is not exceeded by that of and . In other words, has become the tightest envelope of that of and .
Actually, if we switch the order of and in the procedure above, we will obtain the same sequence in . In general, from the second time on, each time Algorithm 3 ends with being updated, parts of the derived curve of move to their top-right.
Now we consider the derived curves of and and define several notions below which describe the relationship between a vertex weighted clique and a list of non-increasing weights.
Definition 8. Given a list of weights s.t. and a clique C with and ,
- 1.
we say that C is covered by L iff and for any ;
- 2.
we say that C intersects with L at l iff and ;
- 3.
we say that C deviates above L at l iff or .
Example 4. Consider Example 3 with having been updated with respect to and . By referring to (II) in Figure 1, we can find the following. - 1.
and are covered by .
- 2.
intersects with at 2, 3, 4 and 5 (see , , and ). intersects with at 1 (see ).
- 3.
deviates above at 2 (see ).
Obviously, we have a proposition below which helps determine whether a clique is effective in reductions.
Proposition 10. - 1.
iff is covered by .
- 2.
If is covered by , is covered by , then is covered by .
- 3.
If deviates above L at certain l and is covered by L, then .
3.1.2. Algorithm Execution
As to the execution of Algorithm 3, the next proposition presents a sufficient and necessary condition in which will be updated.
Proposition 11. The in Algorithm 3 will be updated if and only if = or the input clique C deviates above at certain l.
Also, we have propositions below which illustrate how will be updated.
Proposition 12 (First Top-level Insertion)
. Suppose that and , then will successively be appended to the end of in Line 7 in Algorithm 3.
Proposition 13 (Successor Top-level Updates)
. Suppose where ,
- 1.
for any , will be replaced with in Line 5 in Algorithm 3 iff C deviates above at l;
- 2.
for any , a weight will be inserted in Line 7 in Algorithm 3 iff C deviates above at l.
The following proposition shows the relation between and C if it has been updated in Algorithm 3.
Proposition 14. If has been updated in Algorithm 3, then covers the clique C at the end of this algorithm.
Such a covering relation will still hold after Algorithm 3 returns program control back to Algorithm 1. Then we have a proposition about in Algorithm 1.
Proposition 15. - 1.
Right before the execution of Line 22, for any , is covered by .
- 2.
In Line 19, if C deviates above , then for any , we have .
Intuitively right before the execution of Line 21,
can do whatever any clique in
can, with exceptions being dealt with in
Section 3.3. In Line 19, if
C updates
, then it will be allowed an entry into
.
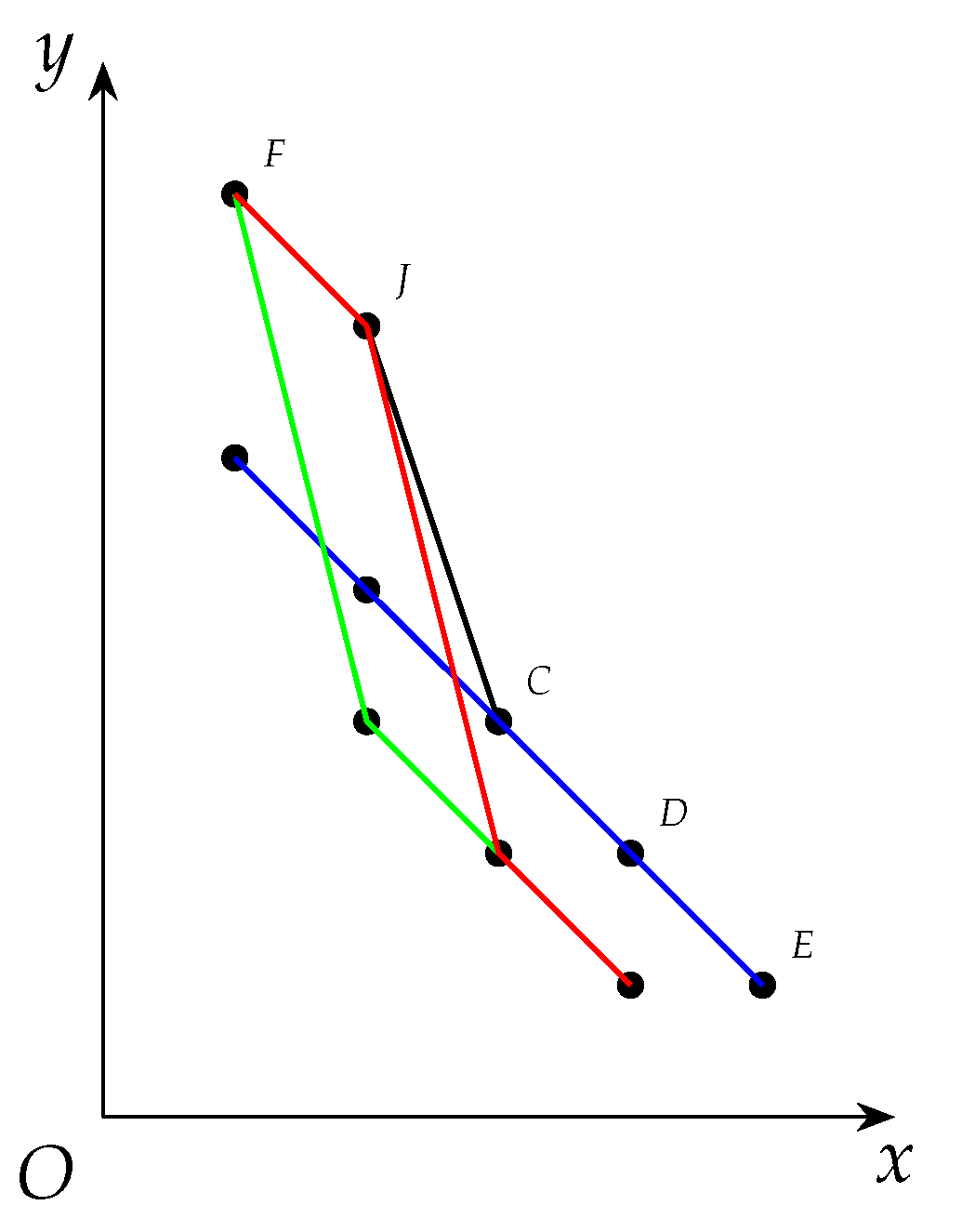
Example 5. After Algorithm 1 is run on in Example 3, has become and has been updated to be , as is shown as in Figure 2. The details are as follows. - 1.
because but . So either was refused to enter or it was removed from , depending on whether the algorithm found earlier than it found .
- 2.
(blue) and (red) are both covered by .
- 3.
As to the two cliques above, neither subsumes the other.
So in Line 19, implies . In other words, if holds, then C is not covered by any clique in , i.e., C is not subsumed by any clique in . In this sense, we add it to and this will not cause obvious redundancy.
Based on the discussion above, we have
Furthermore, for the sake of efficiency, we should keep as small as possible and as powerful as possible. So in Algorithm 1, if , i.e., is subsumed by C, then we will simply remove in Line 14 and this will do no harm to the power of . In addition, if does not intersects with the derived curve of , its reduction power is overwhelmed by , so we remove it in Line 18 as well.
3.1.3. Reductions Based on Top Level Weights
Next we have a proposition below which states that can be utilized for clique reductions.
Proposition 16. Given , then
- 1.
for any , there exists a clique and ;
- 2.
given any feasible coloring for G, ;
- 3.
given any vertex u s.t. and ,
- (a)
u is absorbed by some certain clique in G;
- (b)
and is a VWC-reduced subgraph of G.
Notice that Item 1 states that
is the
tightest envelope of all cliques that have been enumerated (See
Figure 2 above for details and intuition).
In this sense, if t was decreased or any of was decreased, the derived curve of would be left or down shift, which in turn, made at least one clique deviate above at some certain l. Therefore there must exist a color whose weight was smaller than its lower-bound.
Considering that weights of other colors are all underestimated, we have the sum of all components in the new variant of could never be achieved by any feasible coloring.
So in order to obtain a feasible coloring that avoids lower-bound conflicts in any enumerated cliques, we have to accept the cost revealed by
or even more. In a word, any feasible coloring for
G costs at least
, which will be shown and proved formally in Proposition 17 and has also been proved by [
11] in another approach.
Given a vertex
u, we represent it as a point
on the Rectangular Coordinate Plane
in order for intuition (See
Figure 3). Then we have
is strictly below the derived curve ofiffand, and such a location relation implies Items 3a and 3b above. Moreover each time one neighbor of
u is removed,
will be decreased by 1 and the point
will be left shift by 1. Meanwhile, when we enumerate cliques,
tend to move to its top-right. These opposite trends will gradually help reduce the input graph.
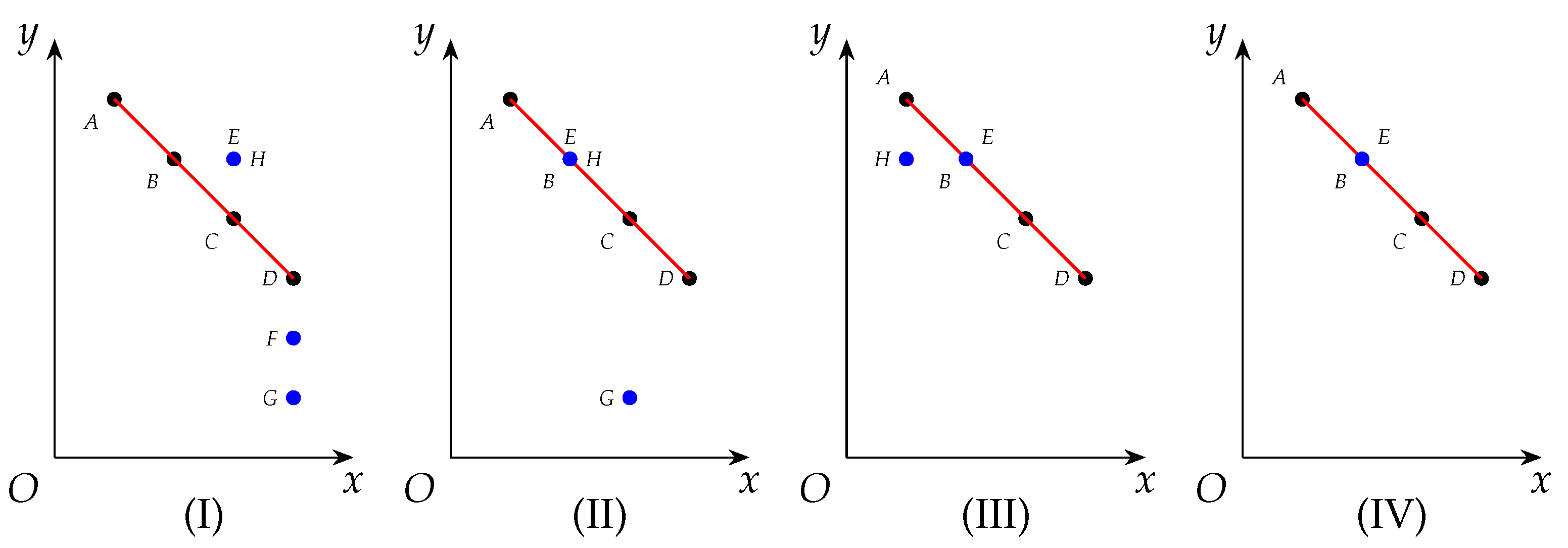
Example 6. Consider in Example 1 in which there exists a maximal clique with . As to the four other vertices with degrees , we represent them by , respectively, on a rectangular coordinate plane in (I) in Figure 3 below. For instance, the coordinate of is namely . Notice that and have the same degree and weight, so their corresponding points overlap on the coordinate plane, to be specific, and are represented by and , respectively, which overlap. On the other hand, we can utilize instead of specific cliques to perform clique reductions. For example, Line 21 in Algorithm 1 exploits to perform reductions based on Proposition 16 above. In detail, applyCliqueReductions(G, , S) performs clique reductions and obtain a VWC-reduced subgraph of G, but keeps all vertices in S in the returned subgraph. We do this for the following reason: In Line 21, since we are enumerating cliques in , we should keep all vertices in it. Otherwise, the procedure may crash. However, in Line 22, since we have completed the enumeration procedures, we do not have to keep any vertices in the VWC-reduced subgraph. We also remind readers that in the applyCliqueReductions procedure, each time one vertex is removed, all its neighbors will be taken into account for further reductions because their degrees have all been decreased by 1.
Notice that in Proposition 16 we require
rather than
, because we have to ensure that
u is absorbed by a clique that does not contain
u, which is coincident with the approach in [
11]. However, this method may fail to perform some reductions which can be performed by Proposition 5. Yet this is not a problem, because, at the end of our reductions, we will deal with that case. See
Section 3.3 for more details.
Example 7. Now we call applyCliqueReductions
which is based on Proposition 16 as below. See Figure 3 for visualization. - 1.
In (I) in Figure 3, we find that the derived curve of is and F is strictly below it, so Item 3 in Proposition 16 is applicable and the corresponding vertex is removed. - 2.
Because of the removal of , the degrees of , and are all decreased by 1, so their corresponding points on the coordinate plane are all left shift by 1 (see (II) in Figure 3). Notice that , , and overlap at this time. - 3.
Notice that is strictly below the derived curved of now, so we remove it like before, and this causes the left movement of (see (III) in Figure 3). - 4.
Analogously we remove because is strictly below now (see (IV) in Figure 3). - 5.
Note that removing is not allowed by Proposition 16, but it is permitted by Proposition 5. This shows the weakness of ourapplyCliqueReductionsprocedure, and we will address this issue in Section 3.3.
Obviously, in order to perform effective reductions, we want to be as big as possible. Hence, in Algorithm 2, we will try to increase their values. Furthermore, Proposition 16 is helpful in proving Proposition 17 below which computes a lower-bound of the cost of a feasible coloring.
Proposition 17. Given any feasible coloring S for G and , we have .
Also, we have a proposition below which will be helpful in
Section 3.3.
Proposition 18. Right before the execution of Line 22 in Algorithm 1, there do not exist any two cliques s.t. and .
3.2. Searching for Better Cliques
Given , Algorithm 2 attempts to increase the values of and it even tries to find a clique whose size is bigger than t. So if Algorithm 2 completes, it will be able to confirm the following.
In Algorithm 2, we use to denote whether is increased in the iteration for i. In Line 2, means that we fail to update . In our algorithm, there are two tricks that refer to as below.
If and we have confirmed that there are no cliques that improve , then there will be no cliques which improve .
If and we fail to update , then it will be hard for us to update as well, so we adopt a continue statement here to avoid probably hopeless efforts.
We also call the procedure applyCliqueReductions which was explained in the previous subsection. Notice that in Line 4, we enumerate maximal cliques which contain vertices in only. To be specific, when , we will do so by considering vertices with weights greater than only, because we are now focusing on increasing . Like the counterpart in Algorithm 1, we will shuffle related vertices randomly before each enumeration.
3.2.1. Increasing Top Level Weights
Like Algorithm 1, we also exploit depth-first search to enumerate maximal cliques. Yet different from it, we will rarely enumerate all such maximal cliques. Instead, once we have found a clique that increases any value among , we will immediately perform reductions and break the enumeration procedure (see Line 14). Below we have a proposition that illustrates a sufficient and necessary condition in which will be increased.
Proposition 19. As to the outermost loop in Algorithm 2, for any , will be increased if there exists a clique s.t. .
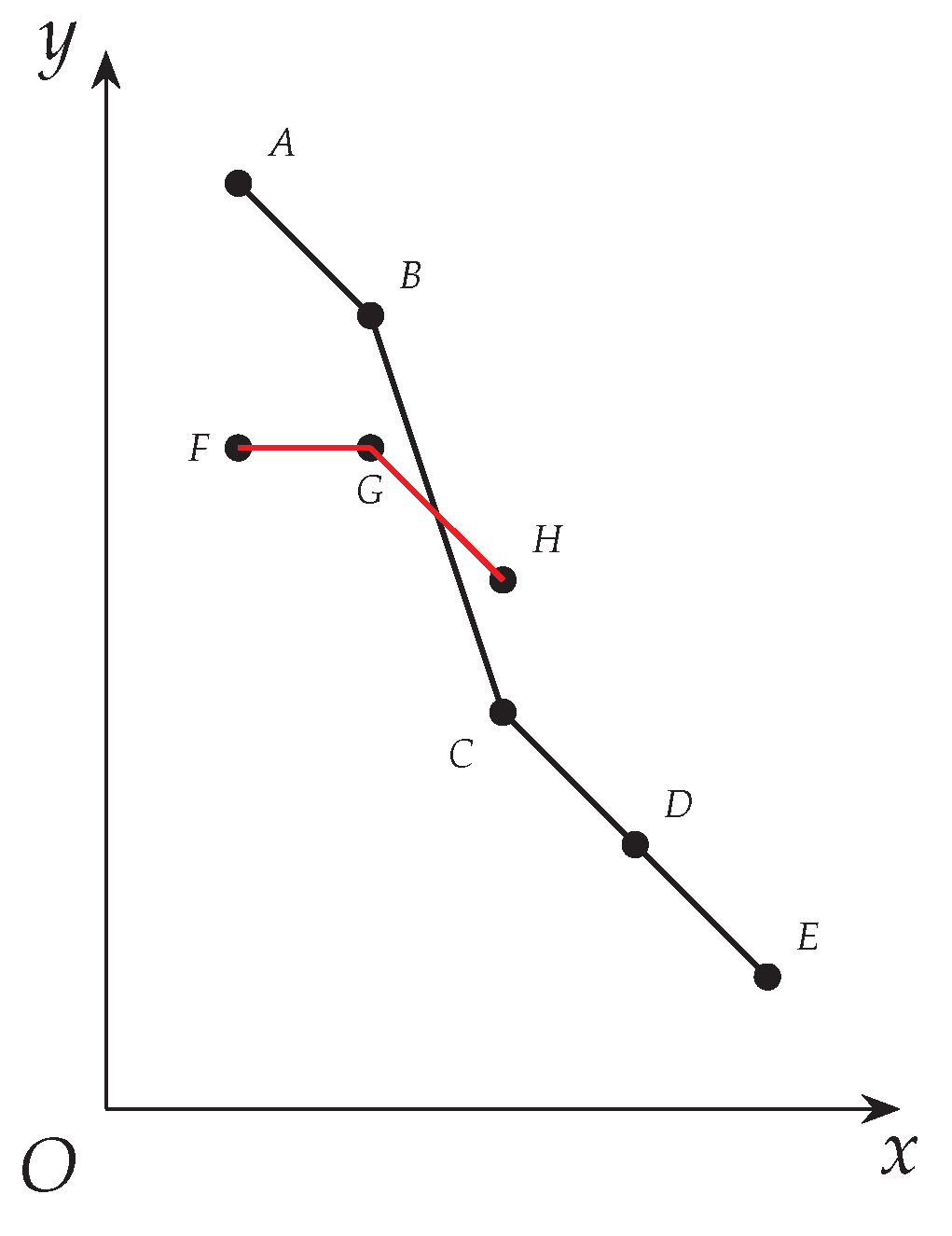
Example 8. Suppose we have , and we are now focusing on increasing whose current value is 3. Suppose among vertices with weights greater than , we have found a clique C with whose derived curve deviates above that of at 3 (see and in Figure 4). So can now increase to be 4, and we will start another iteration to check whether can further increase. Notice that Line 14 breaks the clique enumeration loop and the program control of this algorithm will eventually be returned to Line 3 with an increased . We do this for the following reason: Since we have increased , any vertices that have a weight bigger than the previous but not bigger than the current will not help further increase . Hence, we eliminate these vertices from and enumerate maximal cliques again with respect to the same i (see Line 14). With a smaller , we can increase to its maximum possible value more efficiently. In a word, we increase gradually until it reaches its maximum. Notice that Line 7 might also increase t, so long as the algorithm has found a clique that is bigger than any that have been found. Last we remind readers that although we are focusing on increasing , there could be side effects that we increase as well where , so long as we have found a clique that contains sufficiently many vertices with big weights.
3.2.2. Effects of Better Cliques
There is a chance that the clique C obtained in Line 4 is not a maximal clique for the whole graph G, thus there may exist another clique in G that is a superset of C and has more reduction power. Alternatively, C may expand to a bigger clique by including vertices with a weight not greater than and lead to more reductions. Yet this is not a problem. If such a case exists, the full reduction power will be exploited in later iterations.
In the first few iterations of the outermost loop, i is relatively small and thus is relatively big, which is likely to result in a relatively small , so enumerating cliques in probably costs relatively little time. Moreover, these cliques may lead to effective reductions which significantly decrease the time cost of later enumerations. When , we have , thus in the worst case, we will have to enumerate all maximal cliques in G, which seems to be time-consuming and thus infeasible. Yet this is not so serious, because
Last we remind readers that as
i increases and
decreases,
becomes larger and larger, and thus enumerating cliques will become more and more time-consuming, so we need to set a cutoff for enumerations (see
Section 3.4). Due to this cutoff, once we fail to confirm that
has achieved its maximum, we will not make any effort to confirm whether
has arrived at its best possible value for any
.
Moreover, we have a proposition below which shows that, given sufficient run time, Algorithm 2 will be able to increase to its maximum possible value for any , where is the maximum size of a clique in G.
Proposition 20. As to the outermost loop in Algorithm 2, we have
- 1.
for any , right before i is increased by 1, there exist no cliques which deviate above at i.
- 2.
for , when the iteration ends, there exist no cliques which deviate above at i.
Then by this proposition, we have a theorem below which shows that our clique reduction algorithm is as effective as the counterpart which enumerates all maximal cliques in G, if time permits. To describe this theorem we first define the equality relation between two lists in Definition 9.
Definition 9. Given two list of weights and we say that iff and for any .
Theorem 1. Let be the returned after Algorithms 1 and 2 are executed successively, and be the returned after Algorithm 4 is executed, then .
Note that Algorithm 4 can be time-consuming even for sparse graphs.
| Algorithm 4: computeTopLevelWeightsWithBF(G) |
![Entropy 25 01376 i004]() |
3.3. Post Reductions
Section 3.1 mentions that we have not fully exploited Proposition 5 to perform reductions, so in this subsection, we deal with the remaining case. At this stage, for each vertex, we will examine whether it is absorbed by some certain clique in
and perform reductions if so.
3.4. Implementation Issues
Although we apply various tricks to enumerate diverse cliques for effective reductions, our algorithm may still become stuck in dense subgraphs, so we have to set a certain cutoff for our algorithm.
We believe that a good reduction algorithm should not focus too much on a local subgraph, so our cutoff will prevent each clique enumeration from spending too much time. The impact of this compromise is that we have to sacrifice some good properties above, to be specific, we now cannot expect that all values in will increase to their maximum. Yet in our parameter setting, there are still quite a few values that are confirmed to achieve their optimum.
Furthermore, in some large graphs, we may need to consider a great many vertices and enumerate cliques that contain them, so there could be numerous enumerations. Hence, even though each enumeration needs a small amount of time, the total time cost of so many enumerations might not be affordable, so we also need to limit the total amount of time spent on enumerations.
3.4.1. Limiting The Number of Decisions Made in Each Enumeration
Notice that we adopt a depth-first search to enumerate maximal cliques in Algorithms 1 and 2. During each depth-first enumeration, decisions of whether a vertex should be included in the current clique have to be made, and the search has to traverse both branches recursively, so there may be an exponential number of decisions for a single depth-first enumeration. Hence, in any enumeration, if has been unable to be improved within consecutive decisions, we will simply stop this enumeration and go on to the next one.
3.4.2. Limiting Running Time
Some benchmark graphs contain a large number of vertices that are of the greatest weights or degrees, so there can be a great amount of enumerations in Algorithm 1. Moreover as to Algorithm 2, there can be many candidate vertices that may form a clique to improve a particular component in , hence numerous enumerations may be performed as well.
Even though we limit the number of decisions and thus limit the time spent in each enumeration, too many enumerations may still cost our algorithm so much time. Hence in practice, we employ another parameter T to limit the running time of our algorithm. More specifically in Algorithm 2, we will check whether the total time spent from the very beginning of our whole algorithm is greater than T. If so we will simply stop Algorithm 2 and turn to post reductions.
In fact, if Algorithm 2 is stopped because of this parameter, there can be cases as below. For the sake of presentation, we let K be the number of components in which is equal to the size of the greatest clique that has been found.
Algorithm 2 is unable to tell whether there exists a clique C s.t. and C is able to improve a particular component in .
Algorithm 2 has confirmed that any clique containing at most K vertices will not improve . Yet it is unable to confirm whether there exists a clique whose size is bigger than K.
3.4.3. Programming Tricks
In graph algorithms, there is a common procedure as follows. Given a graph and its two vertices
u and
v, determine whether
u and
v are neighbors. In our program, this procedure is called frequently, so we have to implement it efficiently. However, it is unsuitable to store large sparse graphs by adjacency matrices. Therefore, we adopted a hash-based data structure which was proposed in [
18] to do so.
In our algorithm, we often have to obtain vertices of certain weights or degrees. Moreover, as vertices are removed, the degrees of their neighbors will be decreased. Furthermore, our algorithm interleaves between clique sampling and graph reductions, which requires us to maintain such relations in time. So we need efficient data structures to maintain vertices of each degree and/or weight in the reduced graph. Hence, we adapted the so-called Score-based Partition in [
19] to do so.
4. Related Works
To our best knowledge, the only algorithm on reductions for vertex weighted coloring is RedLS [
11], and its details are shown in Algorithm 5. In this algorithm,
C is a candidate clique being constructed and each vertex in
is connected to each one in
C. Hence, any single vertex in
can be added into
C to form a greater clique.
| Algorithm 5: RedLS |
![Entropy 25 01376 i005]() |
In Line 2, 1% of the vertices in
V are randomly collected to obtain
. As to the outer loop starting from Line 4, each vertex like
v in
is picked and a maximal clique containing
v is constructed from Lines 6 to 11, based on a heuristic inspired by FastWClq [
12]. In the inner loop starting from Line 8, Line 9 picks a vertex
u in
, Line 10 places the vertex
u into
C, and Line 11 eliminates vertices which are not connected to every one in
C, i.e., which are impossible to be added into
C to make greater cliques.
Notice that Line 9 selects a next vertex to put into C with some look-head technique. To be specific, rather than choose the heaviest vertices and maximize current benefits, it tries to maximize the total weight of the remaining possible vertices, i.e., , with a hope for greater future benefits. So given a vertex v, Algorithm 5 always aims to look for maximum or near-maximum weight cliques that contain it.
Each time a maximal clique C is constructed, Algorithm 5 will compare with C and updates if needed (see Line 12). Actually RedLS adopts the so-called ‘relaxed’ vertex partition, yet the effects are equivalent to our descriptions with in Algorithm 5. After enumerating cliques with respect to vertices in , Algorithm 5 will call the applyCliqueReductions procedure and perform reductions based on Proposition 16. However, when determining whether a vertex namely u can be removed, it always takes in the whole graph as u’s degree, i.e., no degree decrease will be taken into account. In a nutshell, RedLS consists of clique sampling and graph reductions as successive procedures, which is different from our interleaving approach.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}