1. Introduction
A lattice is a discrete subgroup of
, and is usually presented by a basis. There are infinitely many basis for a non-trivial lattice and we are usually interested in a basis with a short norm and that is orthogonal to other basis, which we call a good basis. Lattice reduction algorithms are designed to find high quality lattice basis, such as LLL reduction and BKZ reduction. The LLL reduction algorithm can be performed in polynomial time and outputs a LLL-reduced basis, which will be shorter and more orthogonal than the original basis. If you want a better lattice basis, then a stronger lattice reduction should be performed, which is what the BKZ reduction algorithm does. The BKZ algorithm is a generalization of the LLL algorithm with a higher block size that can output a much better lattice basis than LLL, and with costs that are exponential with time. With a good basis, we can solve hard problems in lattice with less effort, such as finding the short(est) vector in a lattice or the closest vector to a given target, called SVP and CVP, which are two hard problems in lattice. SVP asks to find the non-zero shortest vector in a given lattice, while CVP asks to find the closest lattice vector to a given target, in a given lattice. To find the short(est) vector in a lattice, there are currently four main methods we can use: enumeration [
1,
2,
3], sieving [
4,
5,
6,
7,
8], Voronoi cell [
9], and Gaussian sampling [
10]. Enumeration costs are exponential (of the dimension) in time but polynomial in memory. The best enumeration costs
in time. Sieving costs are exponential in both time and memory but the asymptotic time complexity is
for the best sieve algorithm, which is much lower than enumeration in a high dimension. In short, sieving is faster than enumeration when the dimension is larger than 80, approximately. The closest vector problem can be solved via Kannan’s embedding technique, which changes the closest vector problem into a shortest vector problem with 1 more dimension.
Breaking (EC)DSA and Diffie–Hellman with side-channel attacks usually results in a Hidden Number Problem (HNP), which can be converted into a shortest vector problem and solved by SVP algorithm. The Hidden Number Problem is proposed by D.Boneh and R.Venkatesan in 1996 [
11] to analyze the bit-security of the private key in some key exchange schemes, such as the Diffie–Hellman key exchange scheme. Later, P. Q. Nguyen and I. E. Shparlinski analyzed the security of Digital Signature Algorithm (DSA) with partially bit-leakage in the private key by HNP. There are two main methods used to solve HNP: the original approach is due to Bleichenbacher and relies on Fourier analysis technique [
12]. Another method is a lattice attack, which was discovered by Boenh and Venkatesan in Ref. [
11], in which they convert the HNP into a CVP and use the LLL algorithm together with Babai’s nearest plane algorithm [
13] to solve it. The time and memory consumption of Bleichenbacher’s method are higher compared with the lattice attack, since Bleichenbacher’s method needs exponential many samples while it only needs polynomial many samples for a lattice attack; however, the Bleichenbacher’s method can solve HNP with less known bits, such as HNP with only 1-bit leakage. However, as for the lattice attack, it is believed that with only 1-bit leakage, a lattice attack has difficulty succeeding [
12,
14], which is mainly because the lattice constructed by the adversary increases quickly to an unacceptable dimension with the decrease of the known bits.
In the general case of the Hidden Number Problem, the adversary knows some of the most significant bits of the hidden number multiples and some randomly sampled integers modulo for a given integer, which can be translated into modular equations for the hidden number. The hardness of HNP is mainly determined by the size of the modulus and the number of bits known to the adversary. When a lattice attack is applied to HNP, the number of samples affects the distance between the target vector and the lattice, and the dimension of the lattice is nearly the same as the number of samples used. A BDD solver is believed to succeed when the norm of the target vector is less than the shortest vector in the lattice, i.e.,
. When sieving is applied, the constraint on samples used can be relaxed by a scalar factor
, that is
. Since sieving is “more than SVP”, it outputs all the short vectors with a norm below a bound, thus providing more information. With the development of lattice reduction algorithms, Liu and Nguyen solve 160-bit with 2-bit leakage with BKZ2.0 [
15] in 2013. Albrecht and Heninger propose the idea of “predicate” [
16] and utilize it with General Sieve Kernel (G6K) [
17] to break the records. In 2022, Ref. [
18] use bits guessing to solve HNP, for each guess, which is a closest vector problem in the same lattice with a different target. As mentioned above, the less bits are known to the adversary, the harder the HNP instance becomes, since with less bits leakage the adversary needs to construct a lattice with a higher dimension.
Contributions. We propose an asymmetric lattice sieving algorithm to solve HNP. We use more samples for BKZ pre-processing step to derive a better lattice basis while using truncated lattice basis for sieving.
Compared with previous lattice sieving methods that do not use a BKZ pre-processing step or just yse the same number of samples for both steps, we use more samples for pre-processing and get a better lattice basis, which can benefit the sieving step. How to improve the lattice attack with more samples is a question, and the first solution to it is introduced by Ref. [
18], using more samples to find a special HNP instance, such as an instance with small multipliers. We take advantage of “more samples” by applying them to the pre-processing step after the lattice reduction, as the constraint introduced by each sample will propagate to other rows of the basis, and result in a better lattice basis, which is more orthogonal to each other.
We compare our algorithm with “sieve-pred”, the state-of-the-art algorithm mentioned in Ref. [
16]. We estimate the cost of our algorithms in various parameters and list it in
Table 1 and
Table 2. Our algorithm can solve the problem using less time, and the comparison between our algorithm and the state-of-the art algorithm is listed in
Table 3. We also experimentally verified the quality of lattice basis obtained by our BKZ pre-processing step, and compare it with previous methods. It turns out that after our BKZ pre-processing step, the lattice basis is more orthogonal compared with previous methods. We illustrate this result in
Section 6. To verify our algorithm, we apply it to HNP with only 1-bit leakage, and successfully solved them with a modulus up to 116-bit. We also successfully solved all the parameters reported in Refs. [
16,
18], and found that our algorithm needs less time. There are still some parameters that we cannot solve at this moment, mainly because the dimension of the lattice is too large.
2. Preliminaries
We use to denote the Euclidean norm and for infinity norm. We use to denote the ith entry of a vector and for the entry in the ith row and jth column of the matrix A. Index starts from 1 in this work.
2.1. Lattices
A lattice in is a discrete subgroup. Such a lattice is generated by a basis of linearly independent integer vectors, as . We define the volume of a lattice as , where B is an arbitrary basis of , volume is a lattice invariant since it is independent of the lattice basis used. We use to present the orthogonal projections. Particularly, means the identity. We use to present the Gram–Schmidt orthogonalization (GSO) of B, where the Gram–Schmidt vector . Let . We use to denote the ith successive minimum, which means the smallest r such that has i linearly independent vectors of the norm at most r. is the norm of a shortest vector in .
Let
be a measurable subset with finite volume, then we can use the Gaussian Heuristic to predicate the number of lattice points in
:
when
is a closed hyber ball of dimension
d, which leads to the predication of the length of a non-zero shortest vector in
. We use
to denote the expected length of a non-zero shortest vector in
, then
is given by:
which is the non-zero shortest vector in a lattice usually estimated by
.
2.2. Hard Lattice Problems
The Shortest Vector Problem (SVP) and Closest Vector Problem (CVP) are in a center position of lattice problems. Many problems can be transformed into hard problems in lattice, which can thus be solved via lattice algorithms.
Definition 1. (Shortest Vector Problem (SVP)).Given a lattice basis B, we need to find a non-zero shortest vector in , i.e., find a vector with
Definition 2. (Closest Vector Problem (CVP)).Given a lattice basis B and a target vector , we need to find a lattice vector closest to the target t. There is a reduction from CVP to SVP due to Kannan [1], which we refer to as Kannan’s embedding technique. For a closest vector problem with a lattice basis B and a target vector t, it constructswhere μ is the Kannan’s embedding factor. A recommended value for it is . For the vector v, which is closest to t, the corresponding vector is small. Definition 3. (-Bounded Distance Decoding ()).Given a lattice basis B and a target vector which satisfies , it asks to find the lattice vector which is closest to the target t.
In this paper, we will transform CVP into SVP by Kannan’s embedding technique, since it is thought to be more efficient.
2.3. Lattice Algorithms
Sieving [
4,
5,
6,
7,
8] takes a list of points as input, denoted as
, and searches for linear combinations of the points that are short. If the initial list is large enough, then it is believed that SVP can be solved by this process recursively. Each point in the list is sampled in polynomial time in
d.
Assuming that the distribution of the angles of the lattice points in
L is the same as the distribution of angles sampled randomly from the unit sphere, Phong Q. Nguyen and Thomas Vidick proposed a heuristic sieving algorithm with time complexity of
and memory complexity of
[
7]. Later, Thijs Larrhoven and Benne de Weger sped it up it with Locality Sensitive Hashing, achieving a time complexity of
and memory complexity of
[
8]. The asymptotically fastest sieve achieves a time complexity of
and a memory complexity of
, which is sped up by using the Locality Sensitive Filter [
5].
If the linear combination takes k points at the same time, it is called k-sieve. For example, 2-sieve searches for integer combinations of lattice vectors for . In high dimensions, we may use the 3-sieve since it requires less memory compared with 2-sieve, but more time consumption.
The LLL Algorithm was developed by A. K. Lenstra, H. W. Lenstra, Jr and L. Lovasz in 1982, which can solve the approximate SVP by achieving an approximation factor of . Given a parameter , a lattice basis is LLL reduced if the Gram–Schmidt orthogonalization of B satisfies for , and (Lovasz conditions). Let , then the first vector of a LLL reduced basis satisfies . For , the LLL algorithm can be computed in polynomial time in the dimension.
The BKZ Algorithm was proposed by Schnorr in 1987 [
19,
20] and can be seen as a generalization variant of the LLL algorithm. It obtains higher quality of the output lattice basis, however, with a running time in exponential in the dimension
d. The BKZ algorithm uses an oracle that solves SVP in the
dimension “block”, and inserts the short vector to the lattice basis recursively. It first finds the shortest vector in the first block
and the shortest in
will be inserted to the basis. It then proceeds to the next “block” until it reaches the last “block”
, which is called a BKZ-tour. After a BKZ-tour, the algorithm will go to the first block and continue this process until the lattice basis remains unchanged. A small, constant number of BKZ-tour is enough for many applications.
The SVP oracle can be instantiated by enumeration or sieving. When it is instantiated by enumeration, it achieves a running time of and a polynomial memory cost in . As for sieving, the asymptotic time complexity becomes and the memory complexity is .
2.4. The Hidden Number Problem
In order to study the bit-security of private keys in the Diffie–Hellman key exchange scheme, the Hidden Number Problem (HNP) was first proposed by D. Boneh and R. Venkatesan in 1996 [
11], who converted the HNP to CVP, using the LLL algorithm to solve it.
In the Hidden Number Problem, is the fixed number known to the public and is the secret. Given many random , there is an oracle that on inputs t outputs a tuple such that , where means the unique number such that . Suppose we have queried the oracle m times and have m tuples , then the problem asks to recover the secret from these tuples. We will write it as ,.
The hardness of HNP is mainly determined by the number of leakage and the modulus size; more precisely, it is determined by . The larger the value is, the harder the HNP is.
An important application of HNP is to mount the side channel attack on (EC)DSA. We will introduce DSA and ECDSA, and then take DSA as an example to explain how to transform it into HNP.
2.5. Digital Signature Algorithm (DSA)
In DSA, p is the modulus and is an element of order q, with . Here is a hash function H which maps an arbitrary-length input into . The private key is and the public key is .
A DSA signature is composed of two integers
r and
s, generated as follows:
where
k is a random number in
and is unique for each signature.
In order to verify a signature on given a pair
, one needs to compute
and check whether it equals to
r.
2.6. The Elliptic Curve Digital Signature Algorithm (ECDSA)
ECDSA is an elliptic curve variant of DSA, and is one of the most used signature schemes. In ECDSA, the private key is a randomly generated large number
x and the public key is computed by
, where
G is the base point and the multiplication is the scalar multiplication on an elliptic curve. An ECDSA signature is composed of two integers
r and
s, which are computed as follows:
where
p is the modulus and
k is a random number that is unique for each signature. We call it nonce, and
is the hash of the message.
2.7. (EC)DSA as HNP
In the general case of a side-channel attack against (EC)DSA, some of the most significant bits of the signature nonce k will be reveled to the adversary. Without loss of generality, we assume that these bits are zero. We will use DSA as an example to explain how to mount a lattice attack on DSA.
Since
, we rearrange it and then have
. Write
, where
denotes the known part of the nonce
k, and without loss of generality we assume that
,
is the unknown part. We then have:
Let
and
, then we have a HNP equation:
2.8. Solving the HNP with Lattices
Recall that we have
m tuples
, satisfying
. Boneh and Venkatesan construct the following lattice basis and solve it via a BDD oracle:
Lattice
is generated by the rows of
B. The target vector is
and the lattice vector
is close to
t, with
. We will call
v as the hidden vector since it contains the information about the hidden number
. This method can only solve HNP with large leakage. For small leakages such as 2-bit or 1-bit leakage it will not succeed.
We can solve this BDD problem via CVP methods or use Kannan’ embedding technique to change it into a shortest vector problem.
Martin R.Albrecht and Nadia Heninger use two techniques to improve the attack [
16]: the recentering technique and the elimination method. These two techniques play an important role in pushing the boundaries of the unique shortest vector scenario.
The recentering technique is first described in Ref. [
21] and provides a significant improvement in practice. It works as follows: since
, we can reduce the size of
by 1 bit via letting
, thus
. Now we have reduced
by 1 bit because
.
The elimination method is described in Ref. [
16]. It works as follows: since we have
m equations
, we rearrange these equations and then we have:
for each equation
, we rearrange it to get
thus we have a new HNP instance with
and
, now the secret is
and we have
relations about it.
There are two advantages of this method: . it can reduce the dimension of the lattice by 1, also making the secret and the unknown parts equal sized.
Let
, with these two techniques, Martin R. Albrecht and Nadia Heninger construct a new lattice
generated by:
There is a short vector
in
with norm
. The parameter
w is actually the Kannan’s embedding factor and a recommended value for it is
. Furthermore,
w is also the upper bound of the known bits after using recentering technique, since
.
3. Algorithm
We propose a two-step algorithm to solve the HNP. The algorithm is composed of a pre-processing algorithm and a sieving algorithm. The pre-processing algorithm takes m samples as input and outputs a BKZ- reduced basis with dimension, which is smaller than the original dimension .
Compared to only using BKZ reduction, we use sieving to reduce the dimension of the lattice, which is because the success condition of BKZ is different from it than sieving, mainly due to the fact that sieving can produce exponentially many short vectors while BKZ reduction cannot. The difference of dimension between BKZ and sieving is listed in
Table 1, and it can be seen that for the parameters considered in this paper, the difference is large, for example, 36 for 1-bit leakage and the 116-bit modulus.
Compared with only using sieving, we add a pre-processing step; the cost is negligible when compared with the sieving step, but it produces a better lattice basis. We experimentally verified the effect of the pre-processing step and find that the basis obtained by our BKZ pre-processing step is more orthogonal than the other BKZ algorithm.
The sieving algorithm will output a list of all the short vectors with a norm smaller than and we will check the list for the desired hidden number .
3.1. Baseline
Assume that we have
m tuples of
. We will use the recentering technique and elimination technique mentioned above to pre-process the HNP instances, and construct a lattice in the same way as Ref. [
16]. We then choose a submatrix for it and apply lattice sieving.
3.2. Pre-Processing Algorithm
We use more samples to construct lattice basis B because it can take advantage of more information about the secret and results in a better basis for solving HNP. In this way, after the BKZ- reduction, more information about the secret will propagate to every row of the basis, and more constraints are used to the lattice basis.
After the BKZ- reduction we will choose a submatrix of B. We choose the last two columns because they contain the information about the secret, since the expected hidden vector is . We choose columns in the rest randomly, so the result in the hidden vector comes to .
In this way, we have a matrix
that has
m rows and
columns,
. It is clear that
has linear dependence in rows. We will therefore apply the LLL algorithm to it. There are two benefits we can get from the LLL algorithm: first, it can eliminate the linear dependence in rows conveniently, and furthermore, by using it we can get a more orthogonal basis (see Algorithm 1).
| Algorithm 1 Pre-processing algorithm. |
- Input:
m tuples of , parameter and block size - Output:
A BKZ reduced basis - 1:
Construct a lattice basis with , denoted as B - 2:
Perform BKZ reduction on B, which results in a BKZ reduced basis - 3:
Sample columns randomly from the first columns of B, create a matrix with the sampled columns together with the last 2 columns of , and all the rows of - 4:
Perform LLL algorithm on to eliminate linear dependence in rows - 5:
Delete the first rows, which are all-zero, to obtain a matrix C - 6:
return C
|
3.3. Sieving
We apply the lattice sieving algorithm to the dimension lattice . The sieving algorithm will output all the short vectors with a norm less than in , and we check the list for candidates.
We will explain how to choose
to ensure that this algorithm succeeds with a high probability in the next section. We point out that since the hidden vector in
is
, we can therefore recover
from the
th column of
v, and thus calculate
as described in Algorithm 2, lines 4–5.
| Algorithm 2 Sieving for HNP. |
- Input:
A lattice basis C of dimension - Output:
The hidden number for the HNP - 1:
Perform sieving on the lattice to get a list L of all short vectors with norm less than - 2:
for allv in the list L do - 3:
if and then - 4:
Compute - 5:
Compute - 6:
if satisfies all the tuples then - 7:
break; - 8:
return() - 9:
else - 10:
continue; - 11:
end if - 12:
end if - 13:
end for - 14:
return(“Failed.”)
|
5. Experiment on HNP
We apply the two-step algorithm on several HNP instances with only 1-bit leakage. All the experiments are performed by SageMath and G6K [
17] on Intel Xeon Platinum 8280 @ 224x 4GHz. We use “uSVP” to present the method of solving HNP via uSVP, such as using the BKZ algorithm to solve HNP, and the corresponding number of samples needed is estimated by
. When sieving is applied, we use
to estimate the number of samples needed, since “sieving is more than SVP”.
stands for the difference of samples needed for uSVP and sieving. It can be seen that sieving can use a much smaller lattice.
We list the number of samples needed for 1-bit leakage. “uSVP” stands for solving HNP by BKZ algorithm and “Sieving” stands for using Algorithm 2. We have solved 1-bit leakage with modulus up to 116-bit, and list the expected requirements for a larger modulus. We point out that the main constraint for larger parameters is the memory consumption, for example, when solving HNP with 1-bit leakage and a 116-bit modulus, the peak memory reached is 960 GB, which is unacceptable for larger parameters.
We solved all the instances listed in
Table 2, except for 2-bit leakage with a 256-bit modulus. We need to construct a lattice of dimension 132. The memory cost becomes to the main obstacle with the dimension going up.
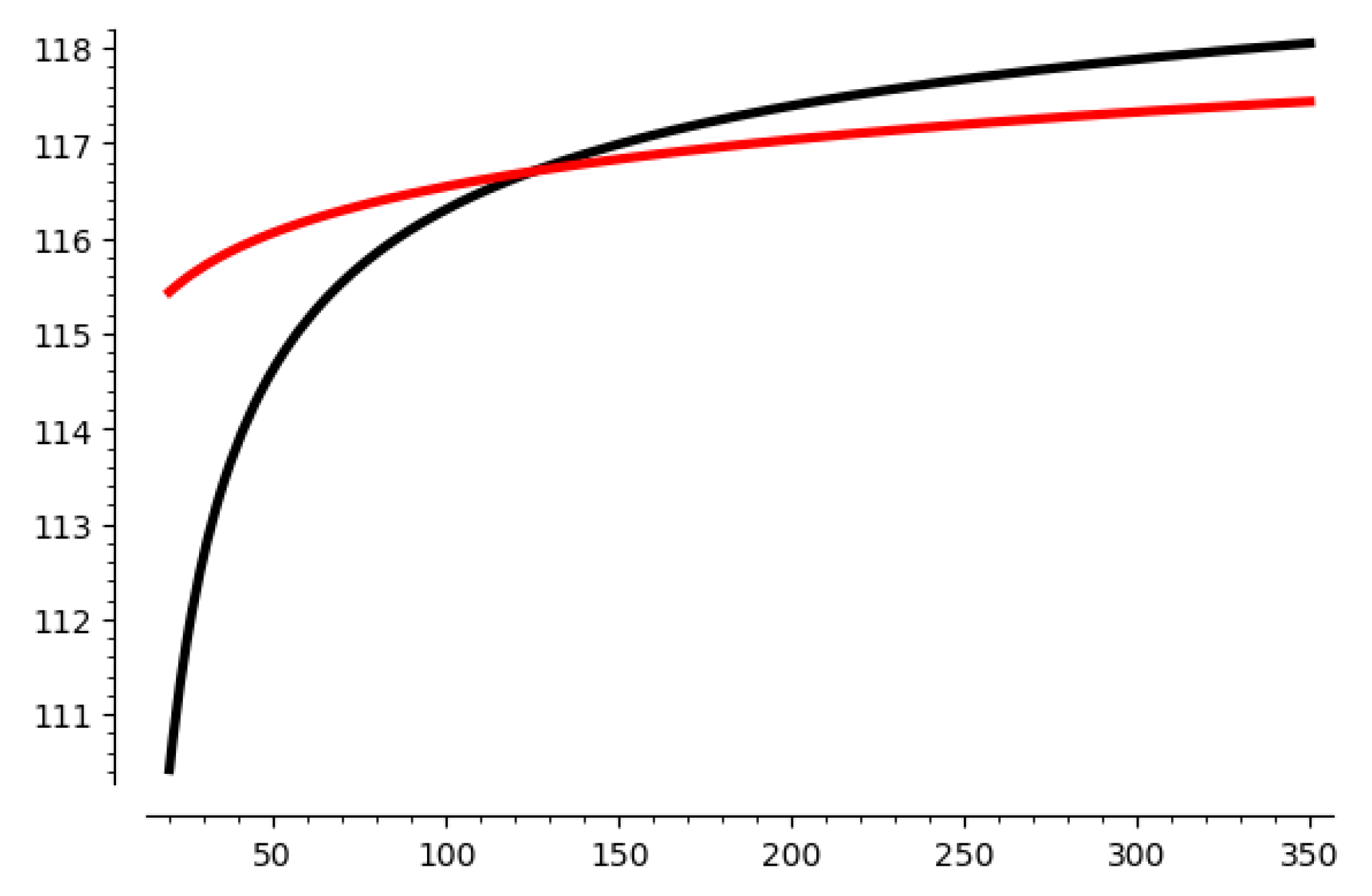
Let us take 116-1 HNP as an example. We show how the number of samples
affects
and
in
Figure 1. The x-axis stands for the number of samples
used for sieving. The y-axis stands for the value of
and
, since they are functions of
. The red line is
and the black line is
. The crossing point is the value of
we choose to solve HNP. When
, which means that the red line it lower than the black line, the HNP is believed to be solvable, and the corresponding minimum
is the samples we use for sieving.
We take 116-bit modulus with 1-bit leakage as an example and illustrate it in
Figure 2. This figure shows how the number of samples affect the gap between
and the expectation of the hidden vector. With an increasing number of samples, the value of
decreases, and it becomes solvable when
Regarding the number of samples required for Algorithm 2, the point of intersection is the number of samples that we use. However, we find that the limitation of is not a necessary condition. For example, 2-bit leakage with a modulus of 160-bit is expected to be solvable with more samples than 84 but can be solved with only 77 samples with a success probability of nearly 1.
6. Comparison of BDD with Predicate
In this section, we compare our asymmetric lattice sieving algorithm with previous lattice methods. To the best of our knowledge, there are two algorithms that achieve the same result: the BDD with the predicate method [
16] and the bit guessing method [
18]. Experimentally, the BDD with the predicate method is faster and gives a thorough analysis of its algorithm in various parameters. So, we compare our algorithm with the algorithm mentioned in Ref. [
16], which is the state-of-the-art algorithm for solving HNP. There are four algorithms mentioned in Ref. [
16] for the different parameters: “BKZ-enum”, “BKZ-sieve”, “enum-pred”, and “sieve-pred”. For the parameters considered in this paper, we mainly use the “sieve-pred” algorithm to solve the problems, since “sieve-pred” is the fastest algorithm for these parameters. Therefore, we compare our algorithm with the “sieve-pred” algorithm in Ref. [
16].
In this table, “Ours” stands for our asymmetric two-step sieving and “sieve-pred” stands for the “sieve with predicate” algorithm mentioned in Ref. [
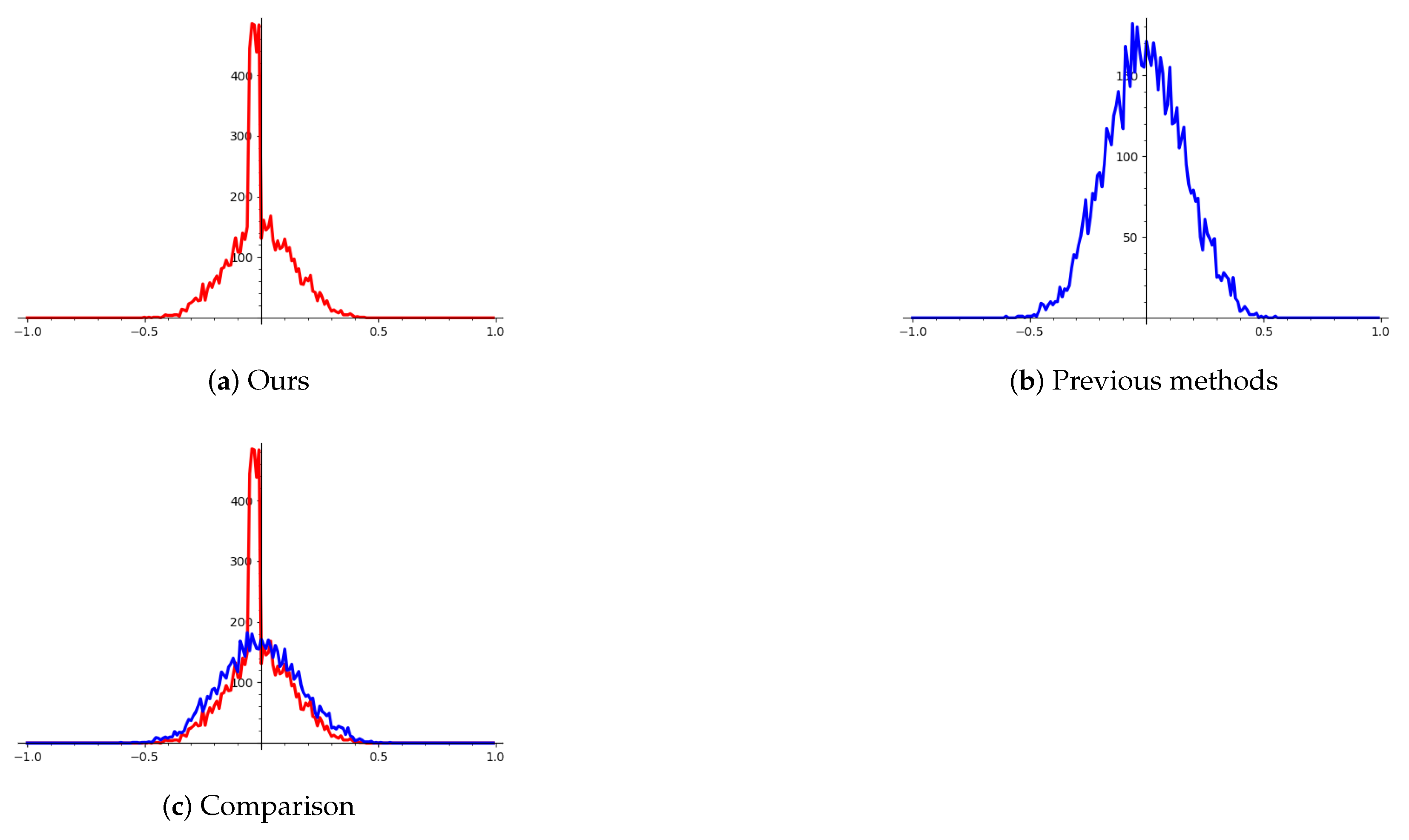
16]. The time is walltime and all these experiments are performed on the same machine. In the same dimension, our algorithm obtains a better basis in the aspect of orthogonality, since we use more samples to restrict the reduction process. Let us take 2-bit leakage with a modulus of 224-bit as an example. The following figure shows that the basis obtained by our algorithm is more orthogonal. Note that the range of y-axis in “Ours” and “Previous methods” is different.
We experimentally verified the orthogonality of the lattice basis obtained by our BKZ pre-processing step, and find that it is more orthogonal to each other and thus we obtain a better lattice basis.
We demonstrate the conclusion by computing the cosine value between each basis. That is, we first generate two lattice basis: one is obtained by our BKZ-pre-processing step, denoted as
, and the other is obtained by the previous method, denoted as
. We then calculate the cosine values and compare them. The cosine values are calculated as follows:
We can draw the results based on
Figure 3. The x-axis stands for the cosine values and the y-axis stands for the number of the cosine values of the basis. So, these figures show the distribution of the cosine of lattice basis, It can be seen that the basis obtained by our algorithm is more orthogonal since its cosine value is more centered at zero, which means the angle is closer to
. We combine the figure “Ours” and “Previous methods” together to get the figure “Comparison”. In “Comparison”, the red curve stands for the cosine distribution of lattice basis obtained by our algorithm and the blue curve stands for previous methods. It can be seen that the cosine distribution is more centered at zero, which means that the basis is more orthogonal to each other.
However, there are still two problems unsolved: how to choose the pre-processing step parameter m and how the angle between the lattice basis affects the sieving step. As for the first question, we usually choose for simplicity. That is because for the parameters considered in this paper, performing a BKZ- reduction on a lattice of dimension is acceptable. If we use a large m, the pre-processing step will be too expensive. As for the second question, a better basis can make it easier to find “good combinations”, which will give a shorter vector in lattice. However, how the angle distribution affects the sieving step needs more rigorous analysis.
7. Conclusions
In this paper, we proposed an asymmetric lattice algorithm for HNP. We call it “asymmetric” since the algorithm uses a different number of samples for the two steps.
Compared with the BKZ algorithms, we use sieving to solve HNP since sieving can reduce the dimension of the lattice significantly, as can be seen in
Table 1, parameter
. The main reason why sieving can reduce the dimension is that sieving can produce exponentially many short vectors while BKZ algorithms cannot. For the parameters considered in this paper, this reduction in dimension is usually over 20, which results in a significant speedup in time. Compared with sieving only, we apply a BKZ pre-processing step with more samples to make use of the information that each sample sufficiently gives. We thus expect to obtain a better lattice basis, namely, a basis that is more orthogonal.
We experimentally verified the efficiency of our algorithm, and applied it to solve HNP with 1-bit leakage with a modulus up to 116-bit. To verify the effect of the pre-processing step, we studied the “cosine distribution” of the lattice basis obtained by our algorithm and other methods, and conclude that the angle of our basis tends more to
, which means that it is more orthogonal. To verify the overall efficiency of our algorithm, we compared it with the state-of-the-art algorithm mentioned in Ref. [
16]. We performed the algorithms on the same machine and compared the runtime. The results can be seen in
Table 1 and
Table 2.
An analysis of the parameters used in this algorithm is also given. We take 1-bit leakage and a 116-bit modulus as an example, and we illustrate the effect of
in
Figure 1 and
Figure 2. For the other parameters, we list it in
Appendix A. However, for the parameter
m used for the pre-processing step, we simply choose
. This is because performing a BKZ reduction in a lattice of
dimension is acceptable and has a good result on the basis. For smaller
m, the effect of pre-processing step will be reduced. More rigorous analysis and experimental verification will be done in future work.







{kind=link}
{kind=link}
{kind=link}
{kind=link}