1. Introduction and Overview
One of Shannon’s outstanding achievements in source coding is to pointing out the ultimate data compression limit. This result has been widely and successfully applied in stream data compression. However, for image compression, it is still a challenging issue. This paper is an attempt to analyze the ultimate limit theory of image compression.
1.1. Preliminaries
Data compression is one of the basis of digital communications and helps to provide efficient and low-cost communication services. Images are the most important and popular medium in the current information age. Hence, image compression is naturally an indispensable part of data compression [
1]. Moreover, its coding efficiency directly affects the objective quality of the communication network and the subjective experiences of users.
As a compression method with strict requirements, image lossless coding focuses on reducing the required number of bits to represent an image without losing any quality. It guarantees as large a reduction in the occupation of communication and storage resources as possible under certain system or scenario constraints. In the area of big data, image lossless coding may play a more significant role in applications in which errors are not allowed, such as in intelligent medical treatment, digital libraries, semantic communications [
2,
3], and metaverse in the future.
The entropy rate is an important metrics in information theory, which extends the meaning of entropy from a random variable to a random process. It also characterizes the generalized asymptotic equipartition property of a stochastic process. In this paper, we shall employ entropy rate to explain the best achievable data compression. It is well-known that the entropy rate of a stochastic process
is defined as
If the limit exists, then
is the per symbol entropy of the
t random variables, reflecting how the entropy of the sequence increases with
t. Moreover, the entropy rate can also be defined as
is the conditional entropy of the last random variable given all previous random variables. For a stationary stochastic process, the limits in Equations (
1) and (
2) exist and are equal [
4]. That is,
=
. In addition, for a stationary Markov chain, the entropy rate is
The entropy rate is a long-term sequence metric. Even if the initial distribution of the Markov chain is not a stable distribution, it will still tend to converge as in Equations (
3) and (
4). Moreover, for a general ergodic source, the Shannon-McMillan-Breiman theorem points to its asymptotic equipartition property. If
is a finite-valued stationary ergodic process, then
This indicates the convergence relationship between the joint probability density and entropy rate for the general ergodic process. Following a similar idea as that of the analysis of entropy rate, we investigate the asymptotic property of shape-based coding for stationary image ergodic processes.
1.2. Shape Coding
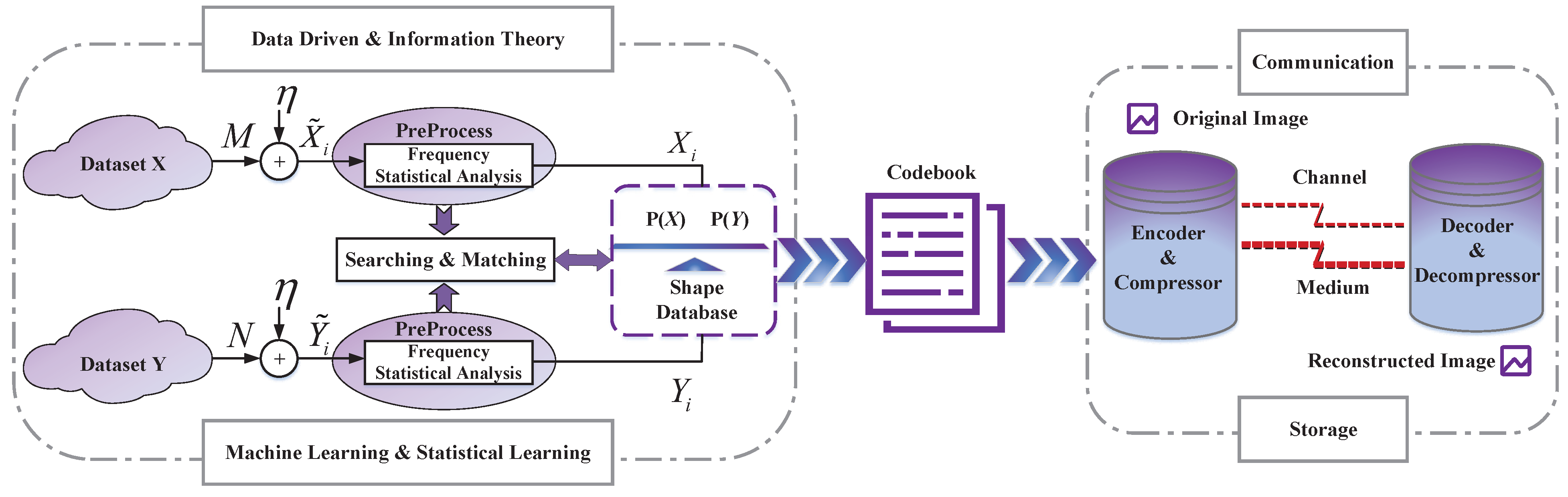
A digital image is composed of lots of pixels arranged in order. This form is fixed and if the size of an image is determined, the number and arrangement mode of the pixels is also determined. Shape coding extends the basic components of images from pixels to shapes, which is a more flexible coding method and may efficiently utilize image embedding structures. Additionally, it will no longer limit the number and position of shapes. Shape coding has three main characteristics: (1) The image is formed by filling shapes; (2) The position arrangement of shapes changes from a fixed mode to a random variable; (3) The shape database and codebook are generated in a data-driven way, which clearly contains more inherent features of image databases.
Consider a binary digital image
Z, whose length and width are
M and
N, respectively, then the total number of pixels is
. Suppose this is divided into
shapes
, where
is the
i-th shape. We used
to denote the shape database and
to represent filling an image with shape
at position
in the
i-th operation. The image with shape coding can be described as [
5]
where
and
represent the bit length of the shape
and its corresponding location at
, respectively. The constraint condition indicates that the binary image
Z can be reconstructed through
filling operations, which is exactly the same as the original image. On this premise, shape coding tries to reduce the cost required to represent an image as much as possible.
The codebook plays an important role in shape coding. It reflects the statistical characteristics and correlation of the data source.
Figure 1 illustrates the structure of shape coding. It consists of two parts, namely the generation and use of the codebook. On the one hand, one searches and matches the shape of images in the dataset through a data-driven method. At the same time, the frequency statistical analysis is carried out to generate a shape database. The codebook can also be used repeatedly in communication and storage tasks to reduce the occupation of resources. The transmitter/compressor encodes the original image with the codebook. After transmission or storage through the channel/storage medium, the receiver/decompressor can decode the compressed file with the same codebook. In this way, one can completely reconstruct the original image in lossless mode.
1.3. Relations to Previous Work
The objective of this work is to present the performance limits from the perspective of information theory, which is related to our previous works in [
5,
6,
7]. An image-encoding method through shapes and data-driven means can provide improvements in image lossless compression. In some known databases,
soft compression outperforms the most popular methods, such as PNG, JPEG2000, and JPEG-LS. However, there is no theoretical support for how shape-based
soft compression methods can reach the ultimate performance limit. That is, the gap between soft compression and its compression limit, namely the entropy rate is not theoretically known. However, the entropy rate associated with the asymptotic equipartition property analysis of images can help us design efficient encoding and decoding algorithms from the perspective of Shannon’s information theory.
The earliest multi-pixel joint coding method can be traced back to symbol-based coding [
8], which transmits or stores only the first instance of each pattern class, and thereafter substitutes this exemplar for every subsequent occurrence of the symbols. This achieved a degree of bandwidth reduction on a scan-digitized printed text. Fractal theory [
9,
10] is also related to block-based coding. Fractal block coding approximates an original image by relying on the assumption that image redundancy can be efficiently exploited through self-transformability on a blockwise basis. However,
soft compression generates the shape database in a data-driven manner, to create the codebook used in the encoder and decoder. Image processing-based data-driven methods such as [
11,
12,
13] can explore the essential features of images and even eliminate semantic redundancy. The use of side information to assist data compression has also been used and analyzed by Kieffer [
14] and Kontoyiannis [
15]. Verdú [
16] provided upper and lower bounds for the optimal guessing moments of a random variable by taking values on a finite set when the side information may be available. Rychtáriková et al. [
17] generalized the point information gain and derived point information gain entropy, which may help analyze the entropy rate of an image.
Another relevent example is the Lempel-Ziv coding schemes [
18]. These proposed the concept of compressibility. For every individual infinite sequence
x, a quantity
is defined. This is shown to be the asymptotically attainable lower bound on the compression ratio that can be achieved for
x be any finite-state encoder. Wyner [
19] derived theorems concerning the entropy of a stationary ergodic information source and used the results to obtain insight into the workings of the Lempel-Ziv data compression algorithm.
The main contribution of this paper is that we will be able to present a sufficient condition, which will allow for us to show that the performance limit of shape-based image coding can be asymptotically achievable in terms of entropy rate.
1.4. Paper Outline
The rest of this paper is organized as follows.
Section 2 contains our main results, providing the asymptotic properties of shape-based image coding in terms of entropy rate. Moreover, we indicates the relationship between the numbers of shapes and coding performance. In
Section 3, we present sample numerical results with concrete examples. In
Section 4, we offer some complementary remarks and conclude this paper.
2. The Asymptotic Properties of Image Sources Composed of Shapes
The encoding method with shapes can take advantage of the characteristics of the data and simultaneously eliminate redundancy in the spatial and coding domains simultaneously. This section theoretically analyzes the performance of image coding with shapes. It will show that when the numbers of shapes and pixels have a reciprocal logarithm relationship, the average code length will asymptotically approach the entropy rate. To the best of our knowledge, this is the first result on image compression in information theory. The framework of this proof is similar to [
4,
19], but there are some important differences.
The average number of bits needed to represent the image
Z with shapes are
. Specifically,
where (a) and (b) follow from the fact that the uniform distribution has maximum entropy. That is,
and
.
is the average cost of encoding
Z, which reflects the coding requirements of bits. In the sequel, we use Equation (
10) instead of (
8) to scale
.
Let
be a strictly stationary ergodic process with finite states and
. Due to the invariance of time,
is an ergodic process, where the
kth-order Markov approximation is used to make an approximation. We will then have
where
is the initial state. In this way, one can use the
k-th order Markov entropy rate to estimate the entropy rate of
. That is,
When
, the entropy rate of the
kth-order Markov approximation converges to the entropy rate of the original random process.
Suppose that is decomposed into shapes . We define as the k bits before , where . Let denote the number of shapes whose size is l and its previous state , .
Lemma 1. For , the joint transition probability and shape size satisfy the following inequalitywhere α is a constant. Proof. Suppose that for fixed
l and
w, the sum of the transition probabilities is less than a constant
, i.e.,
Then,
where (a) follows from Equation (
11) and (b) follows from Jensen’s inequality, thanks to the convexity of
for
. □
Lemma 1 links the conditional probability to , connecting the concepts before and after decomposing . We will continue to explore the quantitative relationship between shapes and pixels.
Lemma 2. For , the number and size of its shapes meet the following relationship Proof. For simplicity, we use
c to represent
. Let
, then
. We define two random variables
U and
V such that
The mean of
U is the average length of each shape, i.e.,
. A random variable with a geometric distribution has maximum entropy when the mean of a discrete random variable is fixed. Thus, we have,
where (a) is the entropy of a random variable with a geometric distribution and (b) follows that the function
is monotonically increasing when
. On the other hand,
. Thus,
which completes the proof. □
Based on these two lemmas, we will further analyze the condition under which the entropy rate can be reached asymptotically.
Theorem 3. When the numbers of shapes and pixels meet the reciprocal relation of the logarithm, then the average encoding length will asymptotically approximate the entropy rate. That is,
Proof. From Lemma 1, one can write
For simplicity, we use
Q to represent
. Thus,
From Lemma 2, it follows that
When
and
, the three terms in the right hand side of Equation (
42) will all tend towards to 0. Combining Equations (
39) and (
42), we obtain
The asymptotic property of the second term in the right hand side of Equation (
10),
This shows that when
and
t meet the condition in Equation (
34), the average coding length of
will asymptotically approximate the entropy rate
. □
Theorem 3 sets up a bridge between the shapes and the entropy rate for image sources with ergodic properties. This theoretically indicates what order of magnitude we should use to obtain the shapes and pixels. When one encodes images with shapes, the average cost will asymptotically tend toward the entropy rate if the numbers of shapes and pixels satisfy the reciprocal relation of the logarithm. Moreover, this provides new insights into the design of image compression algorithms in theory.
3. Numerical Analysis
Section 2 points out the asymptotic property of encoding methods based on shapes. When
, the average encoding length will asymptotically approximate the entropy rate. This indicates the relationship between the shape-pixel number ratio and coding performance. In this section, we present some numerical results to illustrate that for each ergodic process of an image source, if
as
, one can obtain the result of Equation (
35).
Table 1 reveals the numerical results on the MNIST datasets. This includes encoding results
and
in ten categories with the soft compression algorithm [
5]. What can be clearly seen in this table is that
for all classes. This is on the order of
, which is consistent with the assumption in Theorem 3.
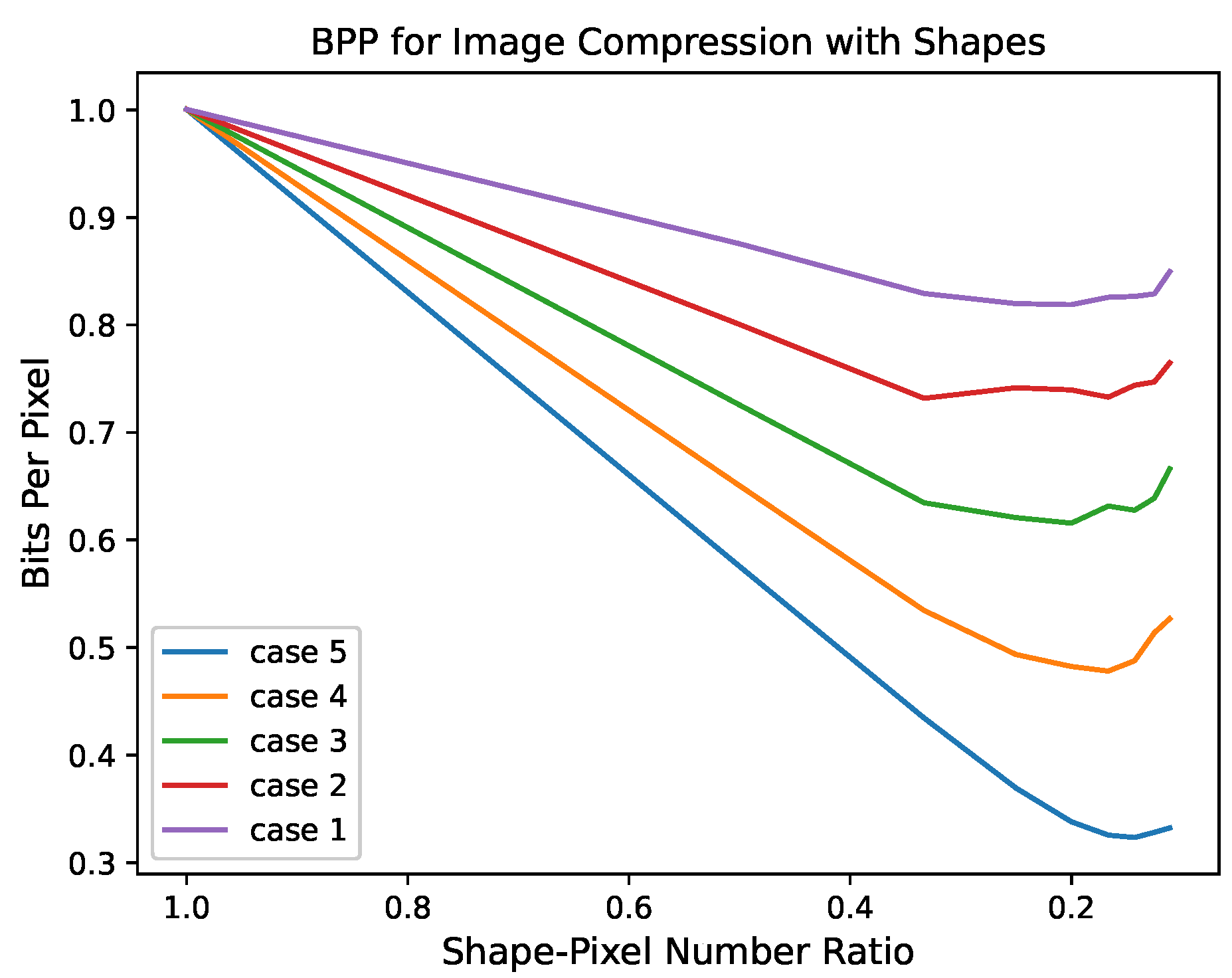
We focused on simulated images as an alternative analysis. We used the birth and death processes of two states to simulate a stationary ergodic process. For each case, 5000 with were generated, respectively. We encoded with fixed size shapes and observed the effect of on coding performance.
Figure 2 illustrates the shape coding working mechanism of the image source. This indicates the performance of the encoding method with shapes, in bits per pixel (bpp). Cases 1–5 represent different parameters of the infinitesimal generator matrix of the birth-death process, illustrating the relationship between coding performance and
. In different cases, the change trend of these curves is the same. The bpp decreases with the increase in shape size (i.e., the shape-pixel number ratio decreases), which reflects the gain brought by shape. Moreover, as the shape-pixel number ratio continues to decrease, bpp enters the smoothing region. This also shows that the reduction in the number ratio will not always improve the encoding performance. This is due to the fineness of the model itself, which does not take advantage of the additional statistical information of larger shapes. Note that, the numerical difference between the curves is essentially the difference of the entropy rate.
4. Concluding Remarks
In this paper, we investigated the performance limit of shape-based image compression. Our works answered the open problem regarding the relationship between image decomposition and lossless compression, which reflects the performance variation in general. Specifically, when the numbers of shapes and pixels have a reciprocal relation to the logarithm relation, the average code length will asymptotically approach the entropy rate.
For image coding algorithms, one should pay full attention to the superiority of shapes in image processing. Likewise, it is necessary to take advantage of the characteristics of the image dataset. Through shapes and data-driven means, one can use the high-dimensional information of images to help with coding. Moreover, the asymptotic analysis of the entropy rate can also be extended to gray images and multi-component images, with some adjustments.
Finally, it is noted that this paper focuses on the source part, without considering the natural robustness of images in the communication process. In a future work, we will explore the theory of joint source-channel image coding in the finite block length regime. It is noted that image lossless compression, especially, soft compression, may become an important block for semantic information communications, and even play some roles in the new developments of metaverse-type services in the future.





{kind=link}
{kind=link}