1. Introduction
The full Bayesian significance test (FBST) for precise hypotheses is presented in [
1] as a Bayesian alternative to the traditional significance tests based on
p-values. With the FBST, the authors introduce the
e-value as an evidence index in favor of the null hypothesis (
H). An important practical issue for the implementation of the FBST is to establish how small the evidence must be to decide to reject
H ([
2,
3]). In that sense, the authors of [
4] present loss functions such that the minimization of their posterior expected values characterizes the FBST as a Bayes test under a decision-theoretic approach. This procedure provides a cutoff point for the evidence that depends on the severity of the error for deciding whether to reject or accept
H.
In the frequentist significance-test context, it is known that under certain conditions the
p-value decreases as the sample size increases, in such a way that by setting a single significance level, the comparison of the
p-value with the fixed significance level usually leads to rejection of the null hypothesis ([
5,
6,
7,
8,
9]). In the FBST procedure, the
e-value exhibits similar behavior to the
p-value when the sample size increases, which suggests that the cutoff point to define the rejection of
H should depend on the sample size and (possibly) on other characteristics of the statistical model under consideration. However, in the proposal of [
4], a loss function that explicitly takes into account the sample size is not studied.
In order to solve the problem of testing hypotheses in the usual way, in which changing the sample size influences the probability of rejecting or accepting the null hypothesis, the authors of [
10], motivated by [
11], suggest that the level of significance in hypothesis testing should be a function of sample size. Instead of setting a single level of significance, the authors of [
10] propose fixing the ratio of severity between type-I and type-II error probabilities based on the incurred losses in each case, and thus, given a sample size, defining the level of significance that minimizes the linear combination of the decision error probabilities. The authors of [
10] show that proceeding this way, by increasing the sample size, the probabilities of both kind of errors and their linear combination decrease, while in most cases, setting a single level of significance independent of sample size, only type-II error probability decreases. The tests proposed in [
10] take the same conceptual grounds of the usual tests for simple hypotheses based on the minimization of a linear combination of probabilities of error of decisions as presented in [
12]. Then, the authors of [
10] extend, in a sense, the idea in [
12] to composite and sharp hypotheses, according to the initial work in [
11].
Following the same line of work, the authors of [
13,
14] present a new hypothesis-testing procedure formulated from the ideas developed in previous works ([
11,
15,
16,
17]) and using a mixture of frequentist and Bayesian tools. This procedure introduces the capital-P
P-value as a decision-making evidence measure and also includes an adaptive significance level, i.e., a significance level that is a function of sample size. Such an adaptive significance level is obtained from the minimization of the linear combination of generalized type-I and type-II error probabilities. According to the authors of [
14], the resulting hypothesis tests do not violate the likelihood principle and do not require any constraints on the dimensionalities of the sample space and parameter space. It should be noticed that the new test procedure is precisely the optimal decision rule for the problem of testing the simple hypotheses
against
. For this reason, such a procedure overcomes the drawback of increasing the sample size resulting in the rejection of a null precise hypothesis ([
12]). Another important way of successfully dealing with this question is to take into account meaningful deviations from the parameter value that specifies the null precise hypothesis in the formulation of the hypothesis testing problem ([
18,
19]).
On the other hand, linear models are probably the most used statistical models to establish the influence of a set of covariates on a response variable. In that sense, the proper identification of the relevant variables in the model is an important issue in any scientific investigation and is a more challenging task in the context of Big-Data problems. In addition to high dimensionality, in recent statistical learning problems, it is common to find large datasets with thousands of observations. This fact may cause the hypothesis of nullity of the regression coefficients to be rejected most of the time, due to the large sample size when the significance level is fixed.
The main goal of our work is to determine, in the setting of linear regression models, how small the Bayesian evidence in the FBST should be in order to reject the null hypothesis and prevent a decision-maker from the abovementioned drawbacks. Therefore, taking into account the concepts in [
11,
12] associated with optimal hypothesis tests, as well as the conclusions in [
10] about the relationship between the significance levels and the sample size, and finally, considering the ideas developed recently by the authors of [
13,
14] related to adaptive significance levels, we present a method to find a cutoff point for the
e-value by minimizing a linear combination of the averaged type-I and type-II error probabilities for a given sample size and also for a given dimensionality of the parameter space. For that purpose, the scenario of linear regression models with unknown variance under the Bayesian approach is considered. So, by providing an adaptive level for decision making and controlling the probabilities of both kinds of errors, we intend to avoid the problems associated with the rejection of the hypotheses on the regression coefficients when the sample size is very large. In addition to the
e-value, we calculate the
P-value as well as its corresponding adaptive significance levels in order to compare the decisions that can be made by performing the tests with each of these measures.
2. The Linear Regression Model with Unknown Variance
The identification of the relevant variables in linear models can be done through hypothesis-testing procedures involving the respective regression coefficients. In the conjugate Bayesian analysis of the normal linear regression model with unknown variance, it is possible to obtain expressions for the posterior distributions of the parameters and their respective marginals. Therefore, in this setting, the FBST can be used for testing if one or more of the regression coefficients is null, which is the basis of one possible model-selection procedure. We first review the normal linear regression model
where
is an
vector of
observations,
is an
matrix of covariates, also called the design matrix, with
,
is a
vector of parameters (regression coefficients), and
an
vector of random errors. The model shows simply that the conditional distribution of
given parameters
is the multivariate normal distribution
. Therefore, the likelihood becomes
The natural conjugate prior distribution of
is a
p-variate normal-inverse gamma distribution with hyperparameters
,
,
, and
, denoted by
. Combining it with the likelihood (
2) gives the posterior distribution ([
20,
21,
22]):
where
If
is non-singular, we can write
where
is the classical maximum likelihood or least squares estimator of
. Therefore, the posterior distribution of
is
See
Appendix A for further explanation of the priors, posteriors, and conditional distributions for the linear regression models with unknown variance.
3. Adaptive Significance Levels in Linear Regression Coefficient Hypothesis Testing
In this section, we present the methodology to find a cutoff value for the evidence in the FBST as an adaptive significance level and we also develop the procedure to calculate the P-value with its corresponding adaptive significance level, all this in the context of linear regression coefficient hypothesis testing in models with unknown variance under the Bayesian point of view. For that purpose, first of all, it is necessary to show how the Bayesian prior predictive densities under the null and alternative hypotheses are defined.
3.1. Prior Predictive Densities in Regression-Coefficient Hypothesis Testing
Let
, with
and
, having
s elements and
r elements. Let
, then,
where
. We are interested in testing the hypotheses
Let
and
be the partition of the parameter space defined by the competing hypotheses
H and
A. Consider the prior density
) defined over the entire parameter space
and let
and
be the Bayesian prior predictive densities under the respective hypotheses. Both are probability density functions over the sample space
, as follows:
where
.
Additionally,
where
and
are the prior probability measure of
restricted to the sets
and
respectively (more details can be seen in
Appendix B).
3.2. Evidence Index: e-Value
The
full Bayesian significance test (FBST) was proposed in [
1] for precise or “sharp” hypotheses (subsets of the parameter space with smaller dimension than the dimension of the whole parameter space, and, therefore, with null Lebesgue measure) based on the evidence in favor of the null hypothesis, calculated as the posterior probability of the complement of the highest posterior density (HPD) region (here we consider the usual HPD region with respect to the Lebesgue measure, even though it could be built by choosing any other dominating measure instead) tangent to the set that defines the null hypothesis. Considering the concepts in [
10,
11], and the recent works [
13,
14] related to adaptive significance levels, we propose to establish a cutoff value
for the
-value (
) in the FBST as a function of the sample size
n and the dimensionality of the parameter space
d, i.e.,
with
, such that
minimizes the linear combination of the averaged type-I and type-II error probabilities,
. To describe the procedure in the context of the coefficient hypothesis testing of the linear regression model we are addressing, consider the tangential set to the null hypothesis which is defined as
This is the posterior distribution of
given
a
s-variate normal-inverse gamma, that is
where the point under
H for which the posterior attains its maximum value can be calculated as follows
Thus, we get the tangential set
The evidence in favor
is calculated as the posterior probability of the complement of
. That is,
The evidence index,
e-value, in favor of a precise hypothesis, considers all points of the parameter space which are less “probable" than some point in
. A large value of
means that the subset
lies in a high-probability region of
, and, therefore, the data support the null hypothesis; on the other hand, a small value of
means that
is in a low-probability region of
and the data would make us discredit the null hypothesis ([
23]).
The evidence in (
8) can be approximately determined via Monte Carlo simulation. Then, generating
M samples from the posterior distribution of
, such that
, we estimate the evidence by Monte Carlo simulation through the expression
Now, consider the test such that
The averaged error probabilities, expressed in terms of the predictive densities, can be estimated by Monte Carlo simulation through the expressions
where
is the set
So, the adaptive cutoff value for will be the k that minimizes . The a and b values represent the relative seriousness of errors of the two types or, equivalently, relative prior preferences for the competing hypotheses. For example, if , it is said that and are equally severe, whereas if , then undergoes a more intense minimization than , which means that type-I error is considered more serious than type-II error and also indicates a prior preference for H.
3.3. Significance Index: P-Value
The authors of [
13,
14] present a new hypothesis-testing procedure using a mixture of frequentist and Bayesian tools. On the one hand, the procedure resembles a frequentist test as it is based on the comparison of the
P-value as a decision-making evidence measure with an adaptive significance level. On the other hand, such an adaptive significance level is obtained from the minimization of a linear combination of generalized type-I and type-II error probabilities under a Bayesian perspective. As a result, it generally depends on both the null and alternative hypotheses and on the sample size
n, as opposed to standard fixed significance levels. The new proposal may also be seen as a test for simple hypotheses characterized by the predictive distributions
and
in
Section 3.1 that minimizes a specific linear combination of probabilities of errors of decision. It is then formally characterized by a cutoff for the Bayes Factor (which takes the place of the likelihood ratio here) and therefore may prevent a decision-maker from rejecting the null hypothesis when the data seem to be clear evidence in its favor ([
12]). It should be stressed that under the new proposal, a cutoff value for the Bayes factor (for the “likelihood ratio” here) is chosen in advance and consequently no constraint is imposed exclusively on the probability of the error of the first kind. In this sense, the test in [
13,
14] completely departs from regular frequentist tests. From another angle, the Bayes factor may be seen as the ratio between the posterior odds in favor of the null hypothesis and its prior odds ([
24]). Note that the quantity defined here is a capital-P “
P-value” to distinguish it from the small-p “
p-value”. In the scenario of the linear regression model with unknown variance, the ratio between the two prior predictive densities (
4) and (
5), will be the Bayes factor,
For any other test
,
minimizes a linear combination of the type-I and type-II error probabilities,
. Here again, the
a and
b values represent the relative seriousness of errors of the two types. To obtain the
P-value at the point
, define the set
of sample points
for which the Bayes factors are smaller than or equal to the Bayes factor of the observed sample point
, that is
Then, the
P-value is the integral of the predictive density over
H,
, in
Defining the set
of sample points
with Bayes factors smaller than or equal to
, i.e.,
the optimal averaged error probabilities from the generalized Neyman–Pearson Lemma, which will depend on the sample size, are given by
In order to make a decision, the P-value is compared to the optimal adaptive significance level . Then, when is observed, the hypothesis H will be rejected if the .
4. Simulation Study
We developed a simulation study considering two models. The first model was
where
and
. The hypotheses to be tested were
The second model studied was
where
is an
matrix of covariates with
and
is the
vector of coefficients. In this case, the hypotheses of interest were
The averaged error probabilities, and , were calculated using the Monte Carlo method with values generated from the following distributions:
Then, is a random sample of the conditional distribution of , .
In a first stage, we considered model (
11) where
and model (
12) with
. Note that the dimensionality of the parameter space, denoted by
d, is different in the two models: for model (
11), the dimensionality is
and for model (
12), the dimensionality is
. Samples of size
were generated for each model under the respective hypotheses and also for different sample sizes between
and
. In model (
12), the covariate
,
, was generated from a standard normal distribution. Finally, to obtain the adaptive values
and
, the two types of errors were considered as equally severe, that is,
.
Figure 1 shows the averaged error probabilities for the FBST as functions of
k for a sample size
. This was replicated for all sample sizes in order to numerically find the corresponding
value that minimizes
.
Table 1 and
Table 2 and
Figure 2 and
Figure 3 present the
and
values as function of
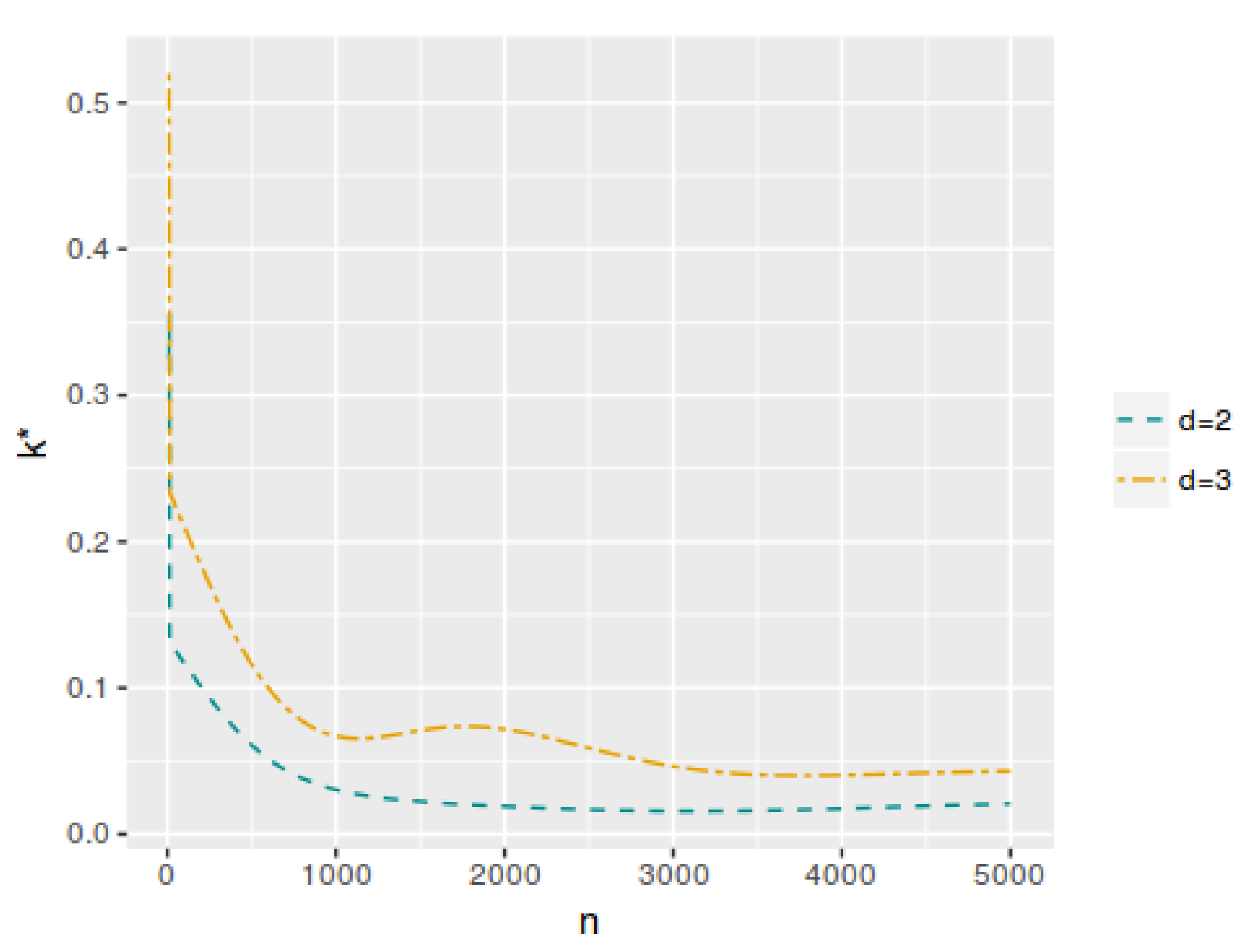
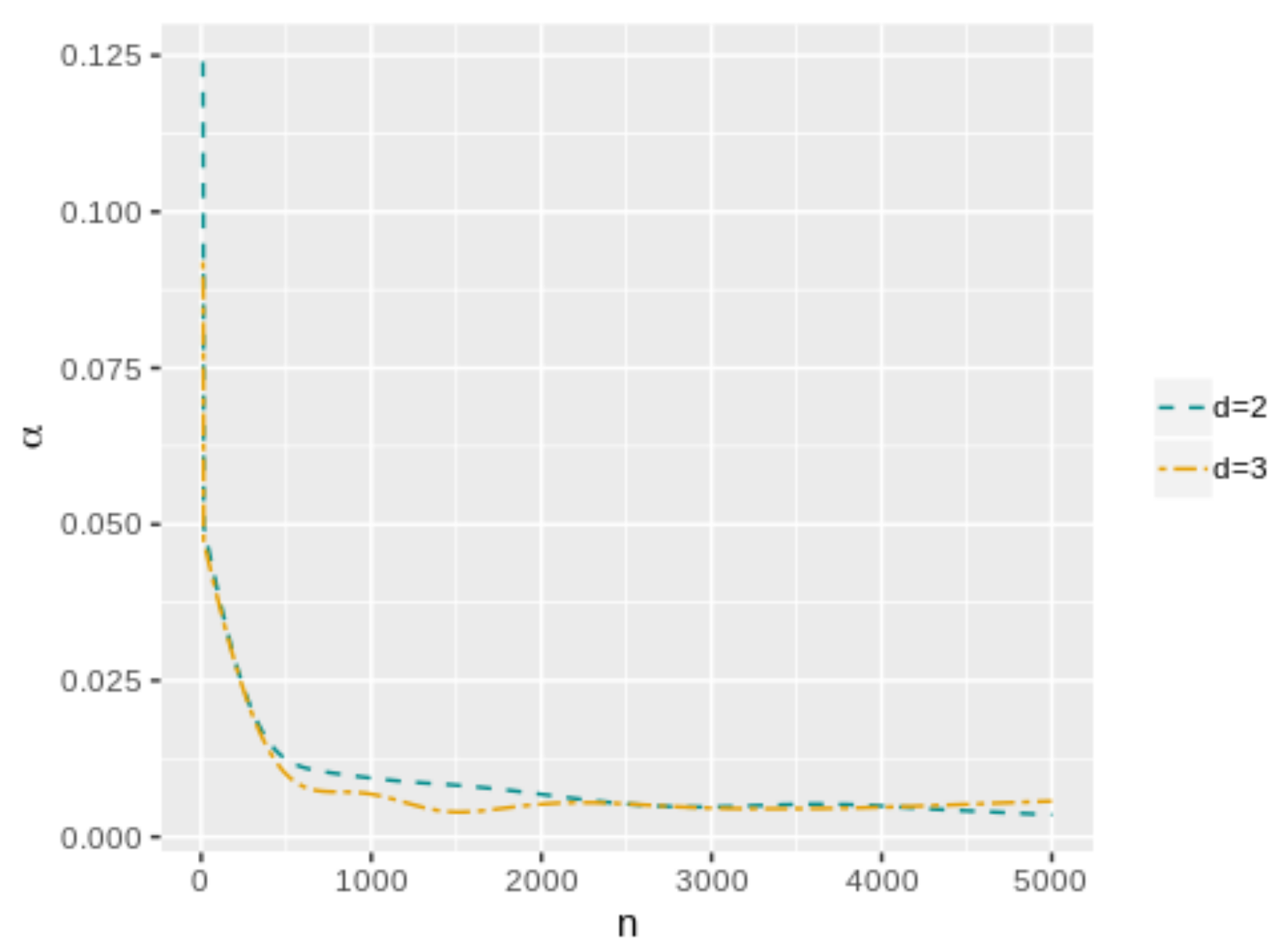
n for each model. As can be seen, both values have a decreasing trend when the sample size increases. In the case of the cutoff value for the evidence, it is possible to notice the differences in the results when the dimensionality of the parameter space change. Then, the
value depends not only on the sample size but also on the dimensionality of the parameter space, more specifically, it is greater when
d is higher. However, this does not occur with
, which maintains almost the same values even if
d increases. On the other hand,
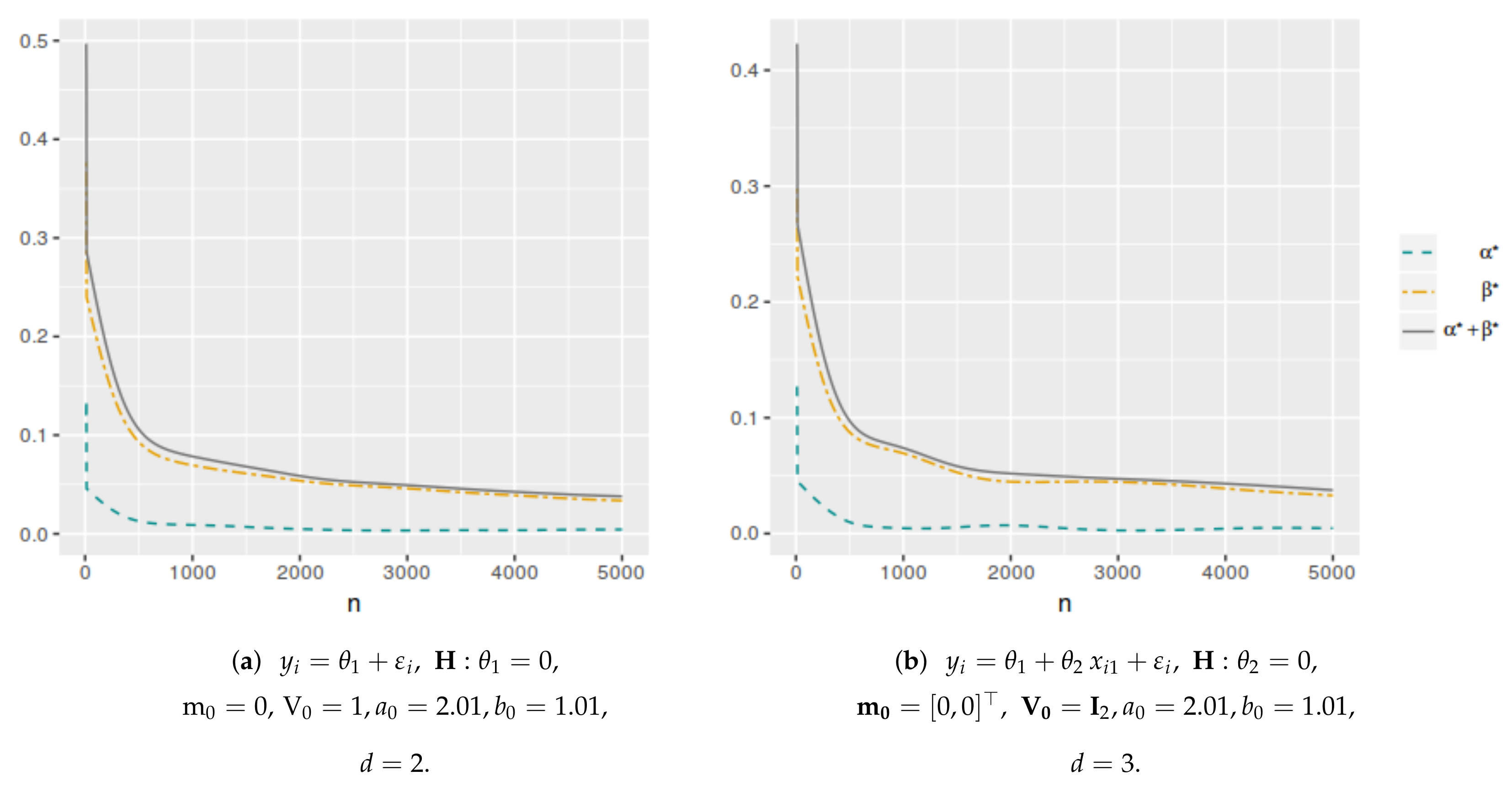
Figure 4 and
Figure 5 illustrate that in all these models, the optimal averaged error probabilities and their linear combination also decrease with increasing sample size.
We choose a single random sample
to calculate the
e-value and
P-value for the models.
Table 3 displays the results: the cases where
is rejected being represented by the cells in
boldface. It can be observed that the decision remains the same regardless of the index used.
As the second stage in our simulation study, we set two sample sizes
and
to perform the tests for model (
12), increasing the dimensionality of the parameter space. In that scenario, the vector of coefficients was such that
and the hypotheses to be tested were
So, by varying the dimension of vector
, the different models considered for each test were obtained.
Table 4 and
Table 5 and
Figure 6 and
Figure 7 show the
and
values as functions of
d. For
, the values correspond to model (
11). We can say that, for a fixed hypothesis, the larger the dimensionality of the parameter space, the greater the value of
. In the case of the
value, it does not change significantly when the dimensionality of the parameter space increases, except when the number of parameters is very large in relation to the sample size.
Table 6 presents the
e-value and
P-value calculated for a single random sample
. Here, with the
e-value the null hypothesis is less easily rejected. This may be related to two things: it may be due to approximation error as a result of the simulation process or due to the fact that the evidence apparently converges to 1 as the dimensionality of the parameter space increases, in which case a more detailed study is required.
5. Numerical Examples
In this section, we present two applications with real datasets. We choose and as parameters of the inverse gamma prior distribution for . Additionally, in the normal prior for given , and are taken as parameters. The Monte Carlo approximations were made generating samples of size M =10,000.
5.1. Budget Shares of British Households Dataset
We select a dataset that draws 1519 observations from the 1980–1982 British Family Expenditure Surveys (FES) ([
25]). In our application, we want to fit the model
We consider as explanatory variables, respectively, the total net household income (rounded to the nearest 10 UK pounds sterling) (), the budget share for alcohol expenditure (), the budget share for fuel expenditure, and the age of household head (). We take the budget share for food expenditure as the dependent variable (). All the expenditures and income are measured in pounds sterling per week.
Table 7 summarizes the results for the hypotheses
,
, by performing the test with the
p-value at
significance level and also the
e-value and the
P-value with their respective adaptive significance levels. The cases where
is rejected are represented by the cells in
boldface.
and
are, respectively, the classical maximum likelihood estimator and the Bayes estimator of
. It can be seen that unlike the
p-value, the
e-value and the
P-value do not reject the hypothesis of nullity of the coefficient associated with the age of household head variable.
Table 8 exposes the optimal averaged error probabilities using the
e-value and the
P-value. It can be noted that the values are very similar with both methodologies.
5.2. Boston Housing Dataset
We also take a dataset that contains information about housing values obtained from census tracts in the Boston Standard Metropolitan Statistical Area (SMSA) in 1970 ([
26]). These data are composed of 506 samples and 14 variables. The regression model we use is
We choose the following explanatory variables to fit our model: per capita crime rate by town (), the proportion of residential land zoned for lots over sq. ft (), the proportion of non-retail business acres per town (), the proportion of non-retail business acres per town (), the average number of rooms per dwelling (), the proportion of owner-occupied units built prior to 1940 (), the weighted mean of distances to five Boston employment centers (), the full-value property tax rate per (), the pupil–teacher ratio by town, and , where is the proportion of black people by town (). The dependent variable is the median value of the owner-occupied homes (in 1000 s) in the census tract ().
The results for the hypotheses
,
by performing the test with the
p-value, the
e-value and the
P-value, are summarized in
Table 9. In this case, with the
e-value the null hypotheses are less rejected. The
e-value does not reject the hypotheses of nullity of the coefficients associated with the proportion of residential land zoned for lots over
sq. ft and proportion of non-retail business acres per town variables, while the
p-value does. On the other hand, the
P-value, unlike the
p-value, does not reject the hypothesis for the proportion of residential land zoned for lots over
sq. ft variable, but it does for the Intercept. As can be observed in
Table 10, for these data, the optimal averaged error probabilities values are also very close.
6. Conclusions
In this work, we present a method to find a cutoff value
for the Bayesian evidence in the FBST by minimizing the linear combination of the averaged type-I and type-II error probabilities for a given sample size
n and also for a given dimensionality
d of the parameter space in the context of linear regression models with unknown variance under the Bayesian perspective. In that sense, we provide a solution to the existing problem in the usual approach of hypothesis-testing procedures based on fixed cutoffs for measures of evidence: the increase of the sample size leads to the rejection of the null hypothesis. Furthermore, we compare our results with those obtained by using the test proposed by the authors of [
13,
14]. With our suggestion of cutoff value for the evidence in the FBST and also with the procedure proposed by the authors of [
13,
14], increasing the sample size implies that the probabilities of both kinds of optimal averaged errors and their linear combination decrease, unlike most cases, where, by setting a single level of significance independent of sample size, only type-II error probability decreases.
A detailed study is still needed for more complex models, so the methodology we propose to determine the adaptive cutoff value for evidence in the FBST could be extended to models with different prior specifications, which would involve, among other things, using approximate methods to find the prior predictive densities under the null and alternative hypotheses.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}