1. Introduction
The digital age has dramatically facilitated many aspects of our lives, whereas cybersecurity issues threaten the positive effects of technology. Since unsafe information and illegitimate users blend so well with regular information and users that they can hardly be distinguished, cybersecurity threats [
1] especially online fraud, telecommunications fraud [
2], online social network fraud [
3], credit card fraud [
4], bank fraud [
5], and fraudulent credit applications [
6], have become a knotty governance problem.
Fraud detection [
7] is a kind of anomaly detection and is usually tackled as a classification problem by screening abnormal items out with traditional machine learning methods [
8,
9] or deep learning ones [
10,
11,
12]. Compared with the traditional machine learning model, the deep learning model has the problems of poor interpretability and no direction for parameter adjustment, and its calculation time increases with the complexity index of the model. Traditional machine learning is still widely studied and applied because of its strong interpretability and fast computing speed. The traditional outlier detection methods are mainly based on distribution-based [
13], distance-based [
14], density-based [
15], and clustering-based [
16] perspectives. However, traditional approaches to anomaly detection rely heavily on the relevance of features to the classification task. When the feature space is large, the presence of invalid, irrelevant, redundant, or noisy attributes in the data may inevitably affect the performance of the model. As the saying goes, “Data and features determine the upper limit of machine learning, and models and algorithms only approach this upper limit”. Therefore, in the practical training process of traditional machine learning, model performance is largely affected and hindered by data. It is mainly in the following four aspects. First, the complexity of data, which usually contain multi-dimensional, multi-level, and multi-granularity information, makes the application and processing of data complex and diverse. Second, the heterogeneous data [
17], which often contain non-single mixed information, such as numerical and categorical information, make it challenging to process data effectively. Third, the uncertainty [
18], redundancy [
19], and inconsistency [
20] of the data bring certain difficulties to the classification task. Fourth, the information contained in missing data [
21] is tough to use effectively.
In order to solve the above problems in telecom fraud, achieve fraud mining, and avoid unnecessary economic losses, a large amount of telecom fraud research has emerged. Traditional telecom fraud detection methods typically rely on compiling blacklists of fraudulent numbers to enable fraudulent user discovery and detection. However, fraudulent strategies have evolved, making traditional methods no longer applicable. Therefore, to mine valuable information for fraud detection from multiple network domains of telecommunication data (SMS data, user data, call communication data, app Internet data), behavioral interaction-based [
22], topology-based [
23], and content-based [
24] approaches arise. Meanwhile, considering the rarity and expensive nature of labeled data, unsupervised methods[
25,
26] are utilized to achieve fraud mining. However, the above studies lack the consideration of fraud from the perspective of the uncertainty of the data itself. The incompleteness of data or the relevance of attributes plays a critical role in the effective detection of fraud problems. Information theory and rough set theory as valid means of measuring uncertainty provide new ideas for solving the telecommunication fraud problem.
In recent years, with the intensive study of rough set theory [
27], outlier detection methods based on rough sets and information theory have received extensive attention and research, which provide theoretical support for discovering important information and classifying complex objects. It has strong interpretability and can deal with unlabeled, heterogeneous, redundant, incomplete, or uncertain data. Attribute reduction [
19,
20,
21,
28,
29,
30,
31,
32], or feature selection, is a method to simplify data, reduce data dimension, and improve model classification ability by filtering out irrelevant or redundant features in data, which can effectively avoid overfitting problems. However, vanilla attribute reduction algorithms [
33] of classical rough set theory can only learn the information through strict indistinguishable relation division of the data. This equivalence relation is too tough to handle the incomplete, the ordered, the mixed, and the dynamic data, and these algorithms have poor fault tolerance. To overcome this limitation, variants of rough set theory, for example, the attribute importance based [
19,
20], the positive region based, the tolerance relation based [
28], the maximal consistent block based [
21], the discernibility matrix based [
29], and the incremental based [
30] have proved effective in incomplete information systems [
34], ordered information systems [
35], mixed-valued information systems [
14], and dynamic information systems [
36]. Generally speaking, the discernibility matrix-based is time-consuming and infeasible for large-scale datasets, while the attribute importance-based has low time complexity. Moreover, tolerance relation is the weakened form of indistinguishable relations, which can validly solve incomplete information. Maximal consistent block describes the maximal objects set under the tolerance relationship, meaning that there is neither redundant, irrelevant information nor information loss. In contrast, the maximal consistent block accurately expresses the objects’ information under coverage and has higher accuracy.
After weighing the applicability of these variants, this paper introduces a maximal consistent block to deal with the uncertainty, incompleteness, and redundancy of data in the telecom fraud detection problem for the first time. Guided and inspired by previous research, an anomaly detection method (MCIR-CGAD) based on correlation and the maximal consistent block is proposed in this paper. The main contributions of this paper are summarized as follows:
From the perspective of improving data quality based on the entropy function under rough set theory, we analyze the effect of attribute correlation and independence on the importance of attributes. A max-correlation and max-independence rate attribute reduction algorithm(MCIR) is designed to eliminate redundancy and noise contained in the data.
From the perspective of data incompleteness processing, a rough gain anomaly detection algorithm (RGAD) is constructed based on the maximal consistent blocks and information gain, which can effectively supply missing data and provide an effective solution for incomplete data processing and feature information measurement.
The effectiveness of the MCIR-RGAD algorithm is verified in the UCI dataset and authentic telecom fraud dataset. The results show that compared with the other eight kernel functions, the MCIR-RGAD algorithm can reduce the time complexity and effectively use the information contained in the missing data to improve the model performance.
The remainder of this paper is organized as follows.
Section 2 gives the basic preliminaries of rough set theory. The design of the MCIR-RGAD algorithm is proposed in
Section 3. Furthermore,
Section 4 conducts the experimental analysis, and
Section 5 summarizes the conclusions.
2. Preliminaries
2.1. Rough Set Theory
Rough set theory is an effective way to tackle and utilize incomplete datasets. The information contained in datasets can be represented as an information system.
An information system is a decision information system, where is a nonempty finite set of objects known as a universe. Set is composed of the condition attribute set and the decision attribute set D, where . The information function is a map from the attribute of an object to information value, i.e., . Normally, a decision information system can be abbreviated as .
Definition 1 (Indistinguishable Relation [
37]).
Given an information system , , is an attribute subset. An equivalence relation on the set U is called the indistinguishable relation IND(B), if it satisfies:where is a set of equivalence relations about x. Set family means a partition of U about attribute set B. and . Normally, and can be abbreviated as and , respectively. In an incomplete information system, the indistinguishable relation is unable to effectively divide the incomplete information. Then, the tolerance relation is given as follows.
Definition 2 (Tolerance Relation [
37]).
Given an incomplete information system , . is an attribute subset. The binary relation of incomplete information on is defined aswhere * means the incomplete information. Denote as the family of all equivalence classes of , or simply . Definition 3 (Maximal Consistent Block [
31]).
Given an incomplete information system , , is an attribute subset, and Y is said to be a maximal consistent block of attribute set . If Y satisfies- (i)
, s.t. ,then Y is called a consistent block;
- (ii)
, s.t. .
where is the set of all maximal consistent blocks with , . The set of all MCB of x is denoted by , where .
Example 1.
Consider descriptions of several users of the telecom network in Table 1. It is an incomplete decision information system , , where , with -Duration, -Place, -Platform, and * means the incomplete information. According to the tolerance relation in Definition 2, it follows that , where , , , .
By the concept of the maximal consistent block in Definition 3, the maximal consistent block of attribute set is .
Definition 4 (Information Granularity [
37]).
Given an incomplete information system , , is an attribute subset, and the information granularity of attribute is defined aswhere and mean the number of the indistinguishable relation set and set , respectively. Remark 1.
Given an incomplete information system , , , conditional granularity, mutual information granularity, and joint granularity of attribute set and are defined as [28,38] , , , where means the division of knowledge under attribute and attribute . 2.2. Information Theory
Information entropy is a measure of system uncertainty from the perspective of an information view. The magnitude of entropy reflects the degree of chaos or uncertainty of the system through the distribution of data information.
Definition 5 (Information Entropy [
37]).
Given an incomplete information system , , is an attribute subset, and the information entropy is defined aswhere means the element number of object set . Remark 2.
By [37], the information entropy is called the granulation measure. The equivalent definition of the complete information system in Equation (4) is defined aswhere , , and , . The form of Equation is consistent with the basic definition of information entropy , where , . Therefore, we can understand the change of information entropy from the relationship between sets by a Venn diagram. In the information theory of rough set theory, the finer the partition, the bigger the entropy. Remark 3.
In a complete information system , condition entropy , mutual information , and joint entropy of attribute B and D are defined as [39] , , . Theorem 1 (Entropy Measure).
Given an incomplete information system , , , conditional entropy, mutual information, and joint entropy of attribute and are defined aswhere . Proof of Theorem 1 The specific proof of Theorem 1 can be found in
Appendix A. □
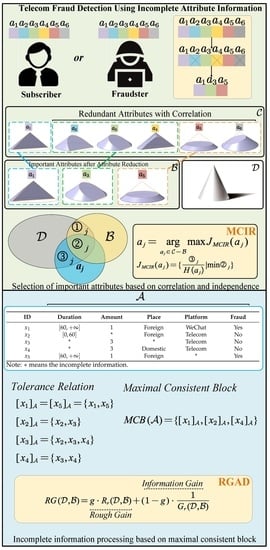
3. Max-Correlation and Max-Independence Rate-Rough GAIN anomaly Detection Algorithm (MCIR-RGAD)
In the information age of Industry 4.0, the amount of data containing a large number of attributes has proliferated. However, not all attributes are relevant to the classification task. In cyberspace, data may be relevant, repetitive, or similar, which does not bring new and valuable information to the anomaly detection task, leading to unnecessary time costs. In addition, attributes that are not relevant to the anomaly detection task may be noisy and not only fail to help model learning, but may even affect detection performance. In addition, data may inevitably be lost during collection, processing, and storage. The lost data itself may contain hidden anomaly information, and a simple subjective assignment or deletion may lead to an invalid use of the lost information. As a result, the attributes in the data are usually not fully functional.
The entropy function of information theory, as a quantitative paradigm for measuring uncertainty, can effectively measure the correlation between attributes in data. In addition, the missing incomplete data has a certain degree of uncertainty, and this uncertainty may also contain valuable information. Therefore, this paper uses the mutual information function in information theory to measure important attributes that are highly relevant and less redundant to the classification task. Further, the maximal consistent blocks of rough set theory are used to process the missing data, and the information useful for the anomaly detection task is mined from the perspective of uncertainty of incomplete data to realize the improvement of the anomaly detection performance.
The main idea of this section can be divided into three parts.
Section 3.1 theoretically discusses the relationship between the attribute correlation and redundancy in the incomplete information system. Then,
Section 3.2 presents an optimization algorithm of attribute reduction(MCIR) with a correlation and independent information. Further, we design a rough gain anomaly detection algorithm(RGAD) based on the maximal consistent block to solve the incompleteness of authentic telecom fraud detection in
Section 3.3.
Figure 1 shows the framework of the proposed methodology.
3.1. Relationship of Correlation and Redundancy
To date, many criteria have been proposed to consider the correlation or redundancy of new classification information, such as criteria JMI, CMIM, CIFE, ICAP, ICI, MCI, etc., which are summarized in [
19]. The criteria are shown as follows.
(① + ② + ③),
②③②,
② + ③②,
① + ③,
② + ③ + (① + ③),
where , ①, ②, and ③.
In
Figure 2a, ①
manifests the relevant information of selected attribute
, ②
means the redundant information between the attributes
,
, and
, and ③
represents the relevant information of candidate attribute.
In the literature, the correlation and redundancy of the criterion function are frequently compared between each candidate attribute
and each attribute
of the selected attribute set
. However, this comparison method has a lot of redundant calculations about information. Therefore, this paper regards the selected attribute reduction set
as a whole and studies the correlation and redundancy between the candidate attribute
and the attribute reduction set
, as shown in
Figure 2b.
For the convenience of formulation, we set ①, ②, and ③ denoted as ①
, ②
, and ③
, respectively. In
Figure 2b, ① manifests the relevant information of selected attribute
, ② means the redundant information between the attributes
,
, and
, and ③ represents the relevant and independent information of candidate attribute
.
Theorem 2 (③ ≜ ① + ② + ③).
Given an incomplete information system , , has been selected, and is a candidate attribute, then the correlation and redundancy relationship between the attribute , , and satisfies Proof of Theorem 2 According to the definition of symbols ①, ②, and ③, we deduce
(① +② + ③) − ③ .
In the decision information system, the attribute set
has been selected, and
is certain, so the division of knowledge is definite. Then,
is a constant. There is a nonnegative constant
, such that
Hence, Equation (
7) holds, i.e., ③ ≜ ① + ② + ③. □
Theorem 2 manifests that the correlation of the newly selected attribute is consistent with the attribute reduction set , and the effect is the same in classification detection.
Theorem 3 (① + ③ ≜ ③ − ②).
Given an incomplete information system , , suppose attribute set has been selected, and is a candidate attribute, then the correlation and redundancy relationship between the attribute , , and satisfies Proof of Theorem 3 According to the definition of symbols ①, ②, and ③, we have that (① + ③) − (③ − ②)∣.
Based on Equation (
8) in Theorem 2, ③
① + ② + ③ holds, hence
=∣(① + ③) − (③ − ②)∣
=∣(① + ③) − [(① + ② + ③ −) − ②]∣
=∣(① + ③) − (① + ③ −)∣ =
Hence, Theorem 3 is proved, i.e., ① + ③ ≜ ③ − ②. □
Theorem 3 shows that only the correlation between the new attribute and the selected attribute set is considered, which is equivalent to considering the correlation and redundancy of new attributes .
3.2. Max-Correlation and Max-Independence Rate Algorithm (MCIR)
In light of the above analysis and inspired by the literature [
19], the max-correlation and max-independence rate algorithm (MCIR) is introduced as follows.
Definition 6 (MCIR).
Given an incomplete information system , , , suppose and , then the max-correlation and max-independence rate function is presented aswhere , i.e.③②}. The principle of the MCIR algorithm is to maximize the correlation and the independence of new classification information and minimize the redundancy between old attributes. The definition of information entropy in rough set theory is from the view of the object attribute information division. The finer the division, the greater the entropy value. Therefore, when the system increases the correlation, it tends to select attributes with more new information.
The attribute reduction algorithm based on max-correlation and max-independence rate is shown in Algorithm 1.
| Algorithm 1:Max-Correlation and Max-Independence Rate (MCIR) |
Input: Information system . Output: An attribute reduction set . - 1:
compute - 2:
, - 3:
- 4:
, - 5:
whiledo - 6:
for do - 7:
if then - 8:
- 9:
else[] - 10:
- 11:
- 12:
- 13:
- 14:
end if - 15:
end for - 16:
end while
|
With the data obtained in the different scenarios, the importance of the correlation and redundancy between attributes exists in diversity. In other words, in the incomplete information system, when the effect of correlation is far biggerer than the redundancy, it is more effective to add new information related to the decision attribute. When similar, redundant, and repetitive information causes noise to affect the detection and classification, it is necessary to increase the correlation and reduce the redundancy.
From the relationship of relevance and independence of the MCIR algorithm in Definition 6,
Figure 2c satisfies ③
③
③
, ②
②
. It shows that the order of attribute importance is
, i.e., attribute
is better than attribute
, and attribute
is better than attribute
, which can be sorted correctly by the MCIR algorithm.
3.3. Rough Gain Anomaly Detection Algorithm with Max-Correlation and Max-Independence Rate (MCIR-RGAD)
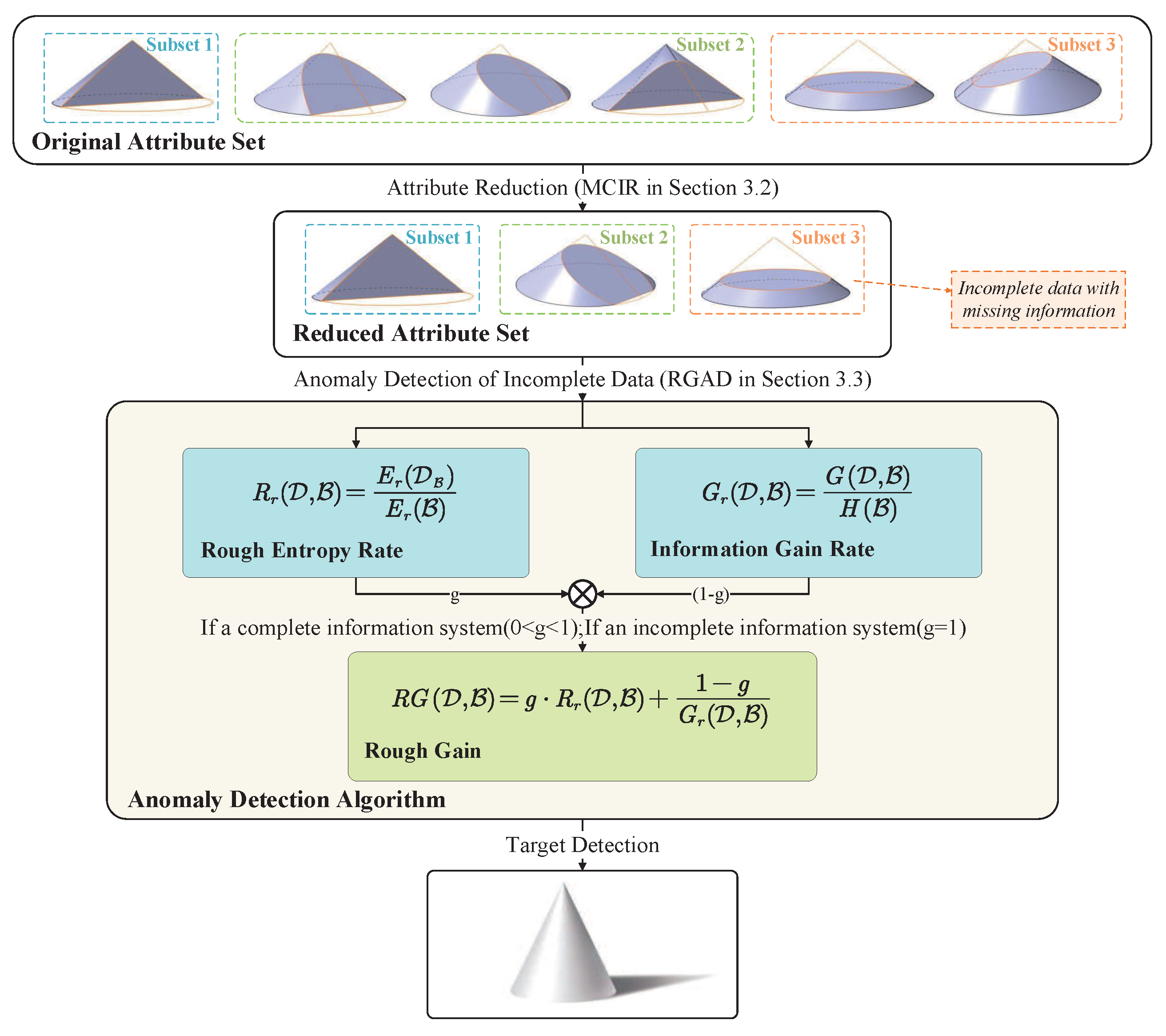
An anomaly detection algorithm (MCIR-RGAD) is designed based on the maximal consistent block horizontally supplementing reduced data. Then, anomaly detection is carried out for the new complemented data. Inspired by the design of information gain in the decision tree, the main idea of the MCIR-RGAD algorithm is to construct a correlation function to measure the ability of attribute classification.
The decision tree, one of the basic classification methods of machine learning, achieves classification tasks by the characteristics of data information. It has fast classification speed, strong interpretability, and readability. Generally, the decision tree learning process consists of feature selection, decision tree generation, and decision tree pruning. In the decision tree, to improve the learning efficiency of the decision tree, the kernel functions, such as information gain, information gain rate, or Gini coefficient, are used to select important features, and then, the decision tree is constructed recursively based on the kernel function. To avoid the occurrence of classification overfitting, we prune the decision tree to balance the model complexity while ensuring the fitting accuracy of the training data.
Both attribute reduction and decision tree work by finding significant features that can classify decision features in information systems. Attribute reduction algorithms can effectively find relevant classification features and achieve effective feature selection. In addition, since there may be intersections in the equivalence class of the object set divided by the maximally consistent block in the incomplete information system, the completeness is not satisfied, i.e., , and there is a negative value when using the information gain for decision learning. Therefore, this paper designs an improved algorithm(MCIR-RGAD) to solve the anomaly detection problem in incomplete systems. Moreover, similar, redundant, repeated, or invalid features are filtered out by reducing. Therefore, this paper does not consider decision pruning.
Frequently, missing data is handled simply by deleting the missing row, filling in zero, filling in one, or filling in the previous data information. However, the explicit deletion or subjective filling of the acquired information will destroy the original data information, so that the missing information cannot be effectively utilized and processed. In an incomplete information system, knowledge can be divided according to the compatibility between available and missing information. This division method not only does not lose the existing data information, but also is more objective. The definition of the kernel function, rough gain , is given below.
Definition 7 ([
40] Rough Entropy).
Given an incomplete information system , , , rough entropy is defined aswhere rough entropy satisfies . Inspired by the literature [
40], this paper presents a generalized form of the definition of rough entropy for decision making in information division as shown in Definition 8.
Definition 8 (Decision Rough Entropy).
Given an incomplete information system , , , the maximal consistent block of attributes and are , , then the decision rough entropy is defined as Definition 9 (Rough Gain).
Given an incomplete information system , , , the maximal consistent block of attributes and are , , then the rough gain are defined aswhere is a positive constant, is the rough entropy rate, is decision rough entropy, is rough entropy of attribute , is the information gain rate, is the information gain, , and . Therefore, this paper selects features based on the MCIR algorithm, then combines the advantage of the information gain with rough entropy to deal with missing data information. We design an anomaly detection algorithm, MCIR-RGAD algorithm, to achieve the task of anomaly detection. The specific algorithm is shown in Algorithm 2.
Essentially, the MCIR-RGAD algorithm replaces the information gain function of the decision tree with the rough gain function in Definition 9. Contrary to the information gain, a smaller rough gain indicates a better attribute, and the other parts are consistent with the decision tree. Therefore, consistent with the decision tree model, the time complexity of this model is
.
| Algorithm 2:MCIR-RGAD algorithm |
Input: Information system , an attribute reduction set , threshold . Output: A decision tree T - 1:
compute - 2:
compute , . - 3:
if is incomplete then - 4:
, (Equation ( 14)) - 5:
else - 6:
, (Equation ( 14)) - 7:
end if - 8:
fordo - 9:
- 10:
- 11:
if then - 12:
- 13:
else - 14:
- 15:
for do - 16:
- 17:
if then - 18:
- 19:
- 20:
else - 21:
return Step 8 - 22:
end if - 23:
end for - 24:
end if - 25:
end for - 26:
return T
|
4. Experimental Analysis
The Sichuan telecom fraud phone dataset consists of four datasets, namely call data (VOC), short message service data (SMS), user information data (USER), and Internet behavior data (APP). The Union data is an integrated dataset combined based on user phone numbers and contains the attribute of four datasets: Voc dataset, APP dataset, SMS dataset, and User dataset. The details of the datasets are described in
Table 2.
The goal of this paper is to detect fraudulent users among regular users according to the important attribute efficiently selected by the correlation and independence from the perspective of data uncertainty and incompleteness. Next, we discuss the effectiveness of the method proposed in this paper from three aspects: incompleteness of data (Definition 3), MCIR attribute reduction algorithm (
Section 3.2), and MCIR-RGAD anomaly detection classifier (
Section 3.3).
4.1. Incompleteness of Data
Loss of data during recording, storage, or transmission is a very likely problem. Normally, the way to deal with incomplete information is to delete it directly, fill it with zeero, one or mean value; however, this simple way of dealing with it will cause the loss of information. As can be seen from
Figure 3, in the Sichuan Telecom fraud dataset, most of the users with null values (red parts) are abnormal, and if they are directly deleted or simply assigned, the abnormal information will not be effectively used. Therefore, from the perspective of improving data quality, this paper uses the idea of maximal consistent blocks in rough set theory to deal with incomplete data to achieve effective information mining.
Then,
Table 3 and
Figure 4 further illustrate the effectiveness of the maximal consistent block in handling incomplete data.
Table 3 and
Figure 4 are the performance comparisons of tackling null values under authentic incomplete telecom fraud data and random deletion of artificially constructed incomplete data (5%, 10%,
…, 50%, 10 types of data missing ratios). From the perspective of the accuracy (
Figure 4a), recall (
Figure 4b), F1 (
Figure 4c), and the number of correct predictions, the maximal consistent block (MCB) can effectively utilize incomplete information and avoid unnecessary information loss.
4.2. Attribute Reduction under MCIR Algorithm
This paper proposes an attribute reduction algorithm of MCIR which uses the entropy function to measure the correlation and independence of attributes from the perspective of rough set theory. The calculation time of the algorithm is reduced while ensuring the accuracy of the telecom fraud detection problem. The main idea is to reduce the computation time by filtering out partial attributes that are most relevant to fraudulent users and have the greatest independence (least redundancy).
Experiments on UCI and telecom fraud data show that the computation time of the data can be significantly reduced by filtering out important attributes.
Figure 5 and
Figure 6 further illustrate that the MCIR algorithm not only effectively reduces the computation time, but also eliminates the adverse effects of noise on information, improves data quality, and maintains or even improves the accuracy of model detection.
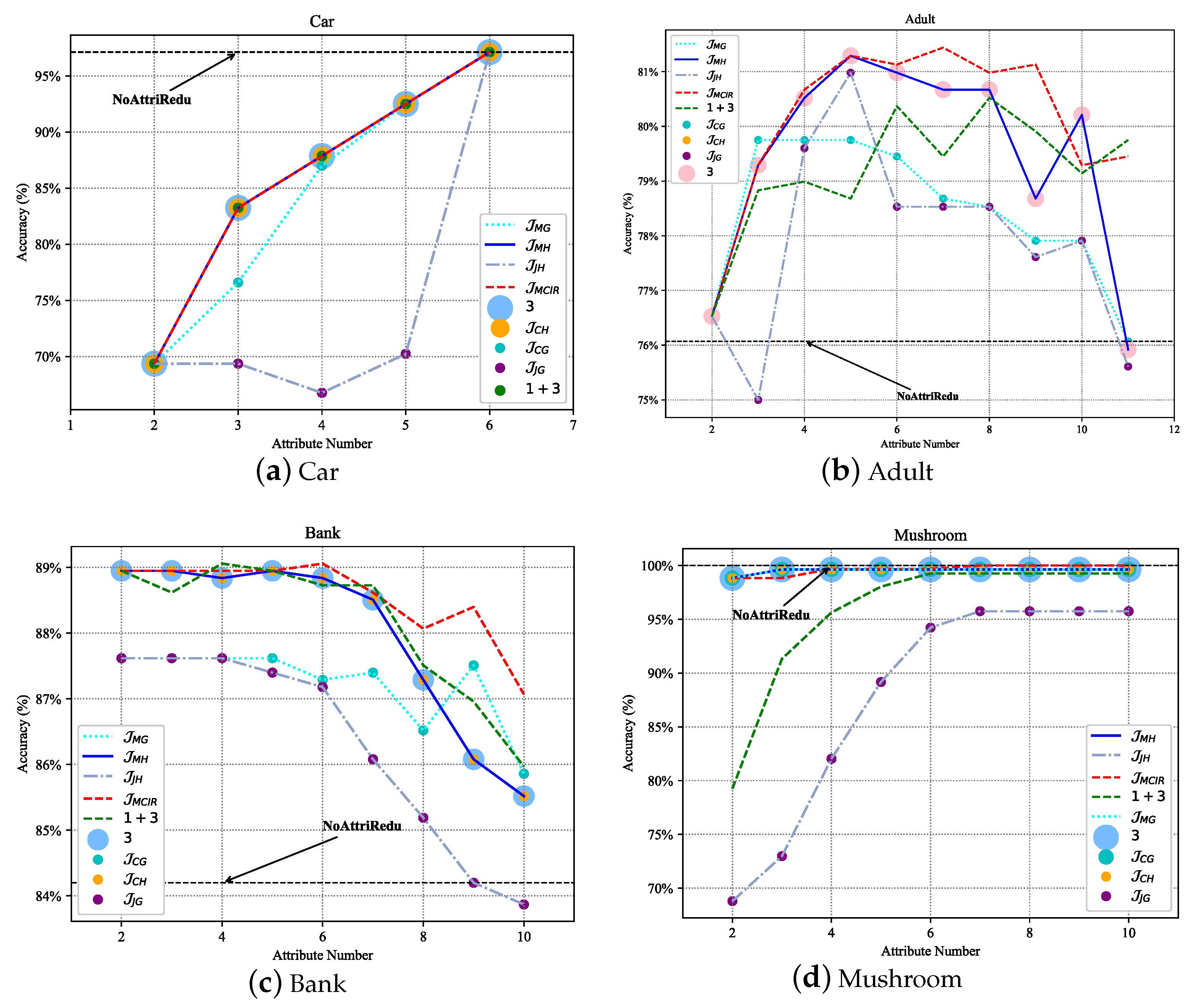
Generally, datasets can be roughly divided into four types, namely: non-redundant and noise-free dataset (
Figure 7a Car, approximated as a strictly monotonically increasing function), non-redundant and noisy dataset (
Figure 7b Adult, approximately concave function), redundant and noisy dataset (
Figure 7c Bank, approximately non-increasing function), and redundant and non-noise dataset (
Figure 7d Mushroom, approximately non-decreasing function). Redundancy shows the approximation, repetition, and correlation of attributes in the data with each other; noise refers to the interference and misleading effects of certain attributes in the data on the classification task. Specifically, for a non-redundant and noise-free dataset, there is no need to perform attribute reduction, and each dimension of features is important information. For other types of data, it is necessary to remove redundant and noisy attributes. In addition, it can be seen from
Figure 7 that compared with other different attribute reduction algorithms (
[
41],
[
42],
,
[
43],
,
, ③, ① + ② + ③ [
44], ① + ③ [
19], ③–② [
45]), the MCIR algorithm (red dotted line) designed in this paper achieves better accuracy with fewer attributes. Since the MCIR model removes as many redundant or noisy attributes from the data as possible and achieves data optimization through data dimensionality reduction, making the reduced data better for anomaly detection tasks, the model can maintain or even improve the accuracy of performance detection while reducing the time complexity.
Therefore, in the process of data processing, the MCIR algorithm can use partial important attribute information to shorten the computation time and effectively improve the detection accuracy of the model (
Figure 7, the black dotted line).
Next, the feature selection of the telecom fraud dataset under the MCIR algorithm is discussed.
Figure 8 shows correlations within attributes via a heatmap. Among them,
Figure 8a,b are the correlations before and after attribute reduction, respectively. As shown in
Figure 8, when attribute reduction is not performed, the data contain a lot of redundant information (dark patches). This paper constructs the MCIR attribute reduction algorithm from the perspective of attribute uncertainty and correlation, which can reduce the information redundancy degree of data while reducing data weight.
Further, the boxplot and probability distribution plot in
Figure 9 show the difference in statistical distribution between normal and abnormal users. The important attributes selected based on the MCIR-RGAD algorithm can effectively highlight the difference between abnormal users and normal users, and fraudulent users can be filtered out by the selected important attributes. Compared with the original Union dataset of 84 attributes with 85.84% detection performance (
Table 4), the detection performance of 10 attributes after MCIR simplification is improved to 89.96%, indicating that the MCIR model involved in this paper effectively achieves the selection of important attributes. To further visualize how the selected attributes distinguish between normal and fraudulent users,
Figure 9 depicts the box line plot and statistical distribution of the 10 important attributes in the telecom fraud dataset filtered by the MCIR method. From
Figure 9, it can be seen that the distributions of normal users and fraudulent users under the 10 attributes have large differences, mainly in the form of (a, f, e) with large difference in mean and variance, (b, d, j, g, h) with large difference in variances with similar means, and (c, i) with large difference in means with similar variances. The larger the difference between the mean and variance distributions of normal and fraudulent users for the selected attributes, the more effective it the method is in distinguishing fraudulent users.
4.3. Anomaly Detection under MCIR-RGAD Algorithm
Redundancy and noise attributes are removed from the original data to improve the data quality of the MCIR algorithm. Then, to perform effective anomaly detection on incomplete data containing missing content, this paper designs the MCIR-RGAD algorithm based on maximal consistent blocks. It provides an effective solution for the processing and utilization of incomplete data.
In the anomaly detection of the decision tree, six types of kernel function classification algorithms, namely Information Gain
, Information Gain Rate
, Gini Coefficient, Rough Entropy
, Rough Entropy Rate
, and Rough Gain
, are compared in this paper. As shown in
Figure 10, the rough gain anomaly detection algorithm (RGAD) integrates rough entropy and information gain as the kernel function has better performance.
The performance and computation time of nine types of attribute reduction algorithms are shown in
Table 5 and
Table 6. Compared with other algorithms, the MCIR-RGAD algorithm proposed in this paper can effectively achieve classification detection in a shorter time.
To effectively measure the trade-off between detection performance and computation time cost of an algorithm, this paper designs a robustness metric in Definition 10. In the robustness metric, since computation time and performance level have different importance in different application scenarios, a linear parameter k is designed to trade off the importance of time and performance. The telecom fraud problem in this paper pays more attention to the accuracy of the model; hence, the hyperparameter weight in the robustness metric is set as .
Definition 10 (Performance Robustness).
where is the degree of performance retention, is the degree of time optimization, , , , and are the performance and time before and after attribute reduction, respectively, and is a weight parameter of time, which means the importance of time cost. Then,
Table 4 shows the number of attributes after attribute reduction for different datasets and shows the changes in performance and computation time of the MCIR-RGAD algorithm before and after attribute reduction. Note that this paper compares the performance and computation time of different algorithms in the same number of attribute reduction sets
.
The performance robustness metric with less computation time and high performance indicates that the designed classifier algorithm is better. The accuracies and computation time in
Table 4 and
Table 5 and
Figure 11 show the robustness under the different attribute reduction algorithms. Compared with other algorithms, the MCIR-RGAD algorithm has strong robustness. That is, when the number of attributes in the attribute set is reduced to the same number, the anomaly detection algorithm MCIR-RGAD can effectively ensure the accuracy of classification detection while shortening the calculation time.
4.4. Statistical Test Analysis
Two nonparametric statistical test analyses of the Friedman test and the Nemenyi post hoc test are introduced to further verify the validity of the comparison method and the proposed method. We compare the performance differences at a significance level of .
4.4.1. Friedman Test
The Friedman test can effectively determine whether there is a significant difference in algorithm performance. Suppose we compare
K algorithms on
N datasets. In the Friedman test, the null hypothesis assumes that there is no significant difference between the models. First, the models were ranked on different datasets using the performance accuracy cases in
Table 5. Then, we acquire the average of overall ranking for each model,
. The performance ranking of the nine algorithms on the nine datasets is given in
Table 7. When the performance of the algorithms is equal, the ordinal values are averaged. For example, if the performance of the 7 algorithms (
,
,
,
, ③, ①+③,
) under the Car dataset in
Table 5 is equal, then their rank values are
.
The Friedman statistic is distributed according to -distribution with degrees of freedom, when K and N are large enough. Owing to the overly conservative nature of the original Friedman test, the variable is commonly used today, which is distributed according to F-distribution with and degrees of freedom, i.e., .
This paper compares nine algorithms using nine datasets. In the Friedman test, if the p-value is less than the significance level or the value is greater than the critical value determined by the F-distribution table, the null hypothesis can be rejected, and at least two algorithms are considered to have significant differences. By checking the table and calculating, we have and . Therefore, the null hypothesis can be rejected with 95% confidence level, indicating that there is a significant difference between the algorithms in the model. Then, a pairwise comparison of the benchmark algorithms was performed using the Nemenyi post hoc test.
4.4.2. Nemenyi Post Hoc Test
In the Nemenyi post hoc test, the performance of two models is considered to be significantly different if the average rank value
of the two models is greater than or equal to the criterion distance
, where the critical value
obeys the Tukey distribution. By checking the table and calculating,
under the confidence level
, then
. It can be seen from
Figure 12 that the MCIR-RGAD model is optimal and significantly different from
and
. In addition,
,
, and 3 are equivalent, and
is equivalent to
. Namely, the model performance can be ordered as
③
①+③
.
5. Conclusions
It is crucial and time-consuming to obtain anomaly classification information in big data with uncertainty, redundancy, and incompleteness. In this paper, a new attribute reduction algorithm (MCIR) is proposed based on the correlation and independence of the data. Furthermore, considering the consistency of attribute reduction and decision tree in selecting features, this paper combines their advantages and constructs an anomaly detection algorithm called RGAD to tackle incomplete data based on the maximal consistent blocks. The proposed algorithm (MCIR-RGAD) can significantly reduce the computation time and effectively maintain or improve the accuracy. Therefore, facing the problem of anomaly detection, this paper provides an effective solution for the optimization of data quality and the processing of incomplete data.
In the future, we plan to extend this work in the context of unsupervised learning from the perspective of structural information among objects, using the concept of neighborhood information systems in rough set theory. The extended work will optimize the data quality and reduce the time complexity through attribute reduction methods, improve the detection performance of classification tasks through structural information, and maximize valuable information through incomplete mixed data (both categorical and numerical data). This will provide an effective solution to the research of information theory and rough set theory on anomaly detection problems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}