1. Introduction
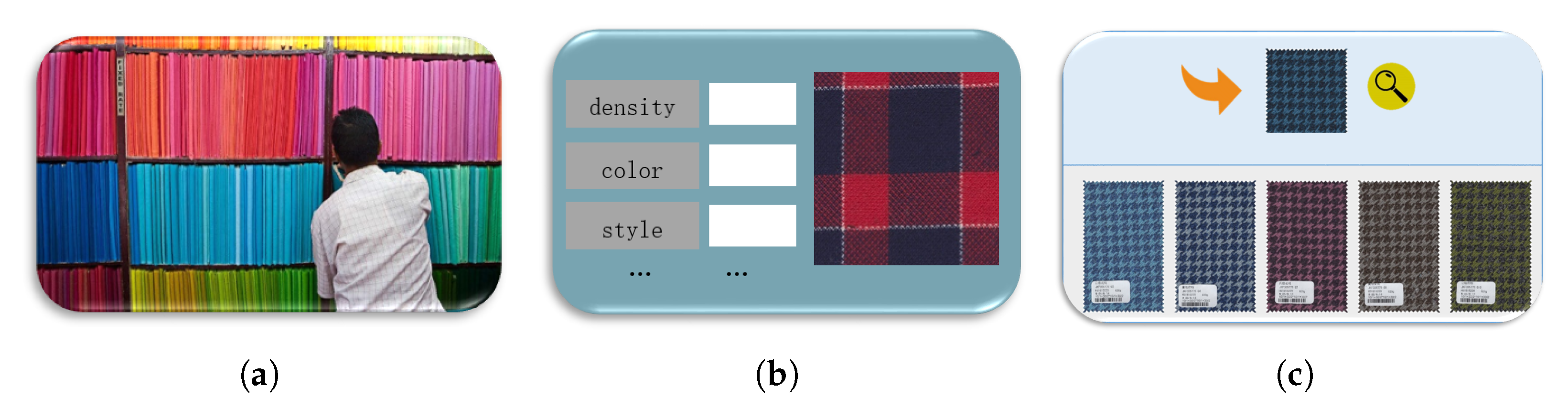
In the context of the major strategy of “carbon compliance and carbon neutrality”, as one of the traditional industries with high energy consumption, the textile industry is faced with the severe challenge of energy conservation and emission reduction. Improving the intelligence, digitization and automation level of textile enterprises are effective measures to help enterprises save energy and reduce emissions. In addition, with “small batch, multi-variety, tight delivery” increasingly becoming the main production mode of textile enterprises, enterprises have accumulated large amounts of historical production data. How to quickly locate target data in a large amount of data and use them to guide production has become an urgent problem for textile enterprises. At present, there are two methods of fabric retrieval commonly used by textile enterprises: real sample search and text-based image retrieval (TBIR). The former method stores the real samples of fabrics, and the retrieval is carried out by manual comparison, as shown in
Figure 1a, which not only takes up storage space, but also has low efficiency and strong subjectivity in manual comparison and retrieval. In addition, textile fabrics will fade with the extension of storage time, which will affect the retrieval results. As shown in
Figure 1b TBIR performs fabric retrieval in a semi-manual manner, using human annotations to index fabric images. Although it overcomes the shortcomings of real sample search to a certain extent, the labeling process still makes the retrieval results subjective, resulting in limited retrieval accuracy, and the retrieval methods that can be provided are relatively simple. Content-based image retrieval (CBIR) uses a specific visual representation method to index image content, as shown in
Figure 1c, which can overcome the shortcomings of the above methods, so it has become a research hotspot in this field. In this paper, we propose a novel CBIR method to achieve accurate fabric image retrieval.
When receiving a query image, the CBIR system is expected to output a list with the same visual content as the query. Technically speaking, there are two phases in the CBIR, namely, image representation and feature matching. Image representation vectorizes the input images (including queries and images in the database), and the second phase ranks the images in the database for similarity and outputs similar images. Currently, the most challenging task in CBIR is to associate pixel-based, low-level features with human-perceived, high-level semantic features. In many previous works [
1,
2,
3], some hand-crafted feature descriptors were used to represent the visual content of fabric images, such as SIFT [
4], LBP [
5] and Color Moment [
6]. Even though these pixel-level methods have achieved some success, they rely too much on feature engineering, which leads to their limitations in robustness. Recently, convolutional neural networks (CNNs) have achieved outstanding performance in many vision tasks, such as image classification, person identification [
7,
8], image segmentation and object detection, which demonstrate its good performance in visual description. Therefore, many researchers adopted CNNs for image retrieval tasks. CBIR has seen a significant breakthrough due to the replacement of earlier low-level feature-based algorithms with an end-to-end framework based on deep learning. Inspired by this trend, we focus on the use of deep CNNs to solve the problem of fabric image retrieval. Krizhevsky et al. [
9] directly used the convolutional layer in a CNN as the index for the image, and its excellent retrieval performance demonstrated the superiority of deep CNN for image retrieval. However, the disadvantage of this method is its high computational cost, which resulted in a long retrieval time.
To improve retrieval efficiency, a lot of feature optimization and encoding methods were proposed, of which the most commonly used approach was the approximate nearest neighbor search (ANN). At present, deep hashing [
10,
11,
12], which is designed to automatically learn the optimal hash function and generate image hash codes, has become the most popular ANN method. The deep-hashing-based method searches nearest neighbors by measuring the similarity in Hamming space between the generated hash codes.
Differently from general natural images, the abstraction of semantic features in fabric images is not high, which mainly include color, texture and higher-order features formed by their interaction. The different feature types in images make it difficult for general image retrieval methods to directly apply fabric image retrieval. To achieve efficient fabric image retrieval, many researches represented the visuals of fabric images by using hand-crafted feature descriptors, and achieved good performance. However, the success of hand-crafted methods is limited to small datasets or specific fabric types. Our previous work [
13,
14] attempted to use classification tasks to guide CNN models to learn fabric image representations. Although the retrieval performance far exceeded those of other low-level feature-based methods, the retrieval accuracy still fell short of the retrieval requirements of textile enterprises. There are two main reasons for this problem: (1) the similarity of fabrics cannot be measured by rough classification; (2) the feature loss is severe in the hashing process. To address the problem, in this paper, we first design a fine-grained similarity to measure the similarity between fabrics, and then introduce the structural network and the variational network in the hashing process to reduce the feature loss. Specifically, to narrow the gap between fabric images and similarities, we design a CNN with a compact structure and cross-shortcut connections, which is regarded as the base network of the hashing model. To overcome the problems of probabilistic missing and difficult training in classical hashing, we introduce a variational network module and structural network module into the hashing model (named DVSH). Then, a fine-grained similarity is defined to measure the similarity between two fabric images. To incorporate the defined fine-grained similarity into hash learning, we employ list-wise learning to complete similarity embeddings in mini-batches.
2. Motivation
The goal of image retrieval is to quickly and accurately retrieve relevant images from the target database. In this paper, we believe that two key issues in this task are: (1) how to define the similarity between two images; (2) How to efficiently retrieve relevant images.
At present, there are generally two ways to define similarity between images, namely, binary pairwise similarity [
15,
16] and soft similarity [
17,
18]. The former has two ways of measuring similarity: (1) two images are considered similar if they share at least one label—otherwise, they are dissimilar; (2) if the labels of the two images are completely identical, they are considered similar—otherwise, dissimilar. Due to the loss of too much information, the two definitions of binary pairwise similarity are not suitable for measuring the similarity between fabric images. Regarding soft similarity, it is calculated by the degree of fit or cosine distance between the label matrices, which needs to be established on the basis that the categories are independent of each other. For fabric images with multi-granularity features, which contain features at multiple levels, the above similarity definition methods are not applicable. This paper argues that an ideal measure of fabric similarity should be designed according to some well-designed rules, and the similarity of each dimension should be considered. Therefore, according to the characteristics of fabric images, we designed a fine-grained similarity.
Generally, the dimensionality of the features extracted by a CNN is high, which leads to a large computational cost in feature matching (called the “curse of dimensionality”). To solve this situation, some researchers proposed to use principal component analysis (PCA) [
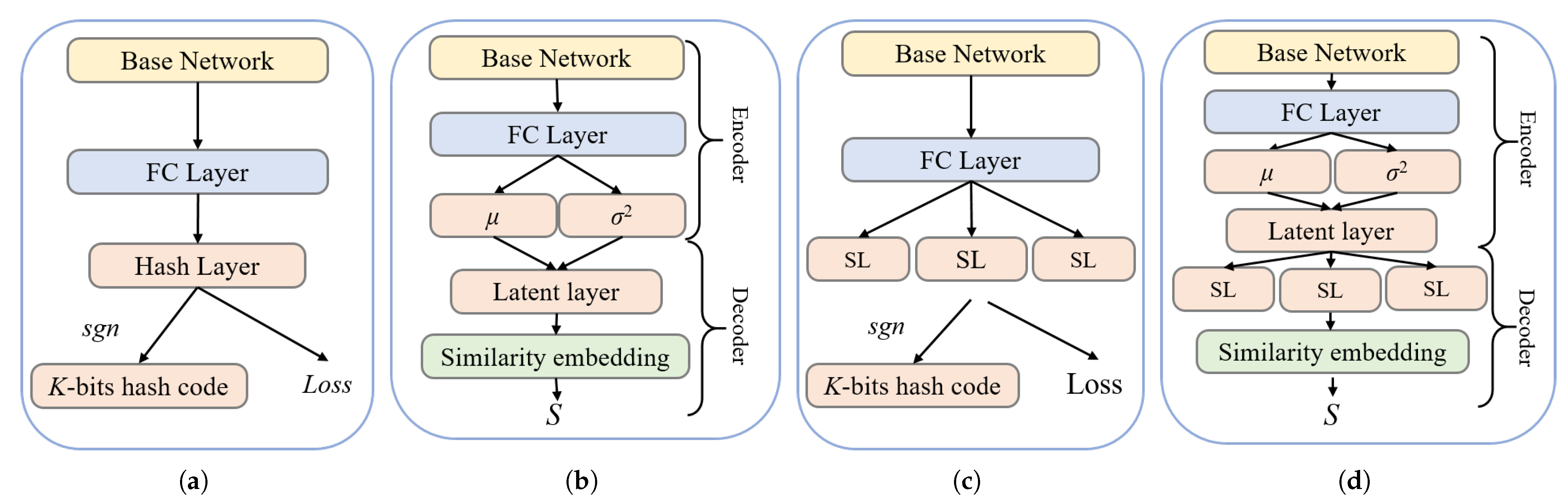
19] for linear dimensionality reduction of high dimensional features. PCA expects that the variance between the information in the projected dimension is the largest, so as to obtain the largest amount of information in fewer data dimensions. The interpretation of the principal components in the features extracted by PCA has a certain ambiguity, and the components with less contributions may be more effective for the representation of the samples, and whether the orthogonal vector space of the eigenvalues is unique remains to be discussed. Approximate nearest neighbor search (ANN) is currently a more efficient method that has made substantial progress in the past decade, especially in visual search applications. Hashing methods are typical in ANN; however, naive hashing methods are difficult to preserve the similarity of input features due to the limitation of code length. With the development of deep learning, deep hashing (DH) methods have achieved rapid development. Deep hashing methods map real vectors in Euclidean space to Hamming space. Efficient searching can be achieved by using the generated binary hash codes, which preserves similarity information. The current commonly used deep hashing network consists of a base network and a hash layer, which is guided by a specific objective function, as shown in
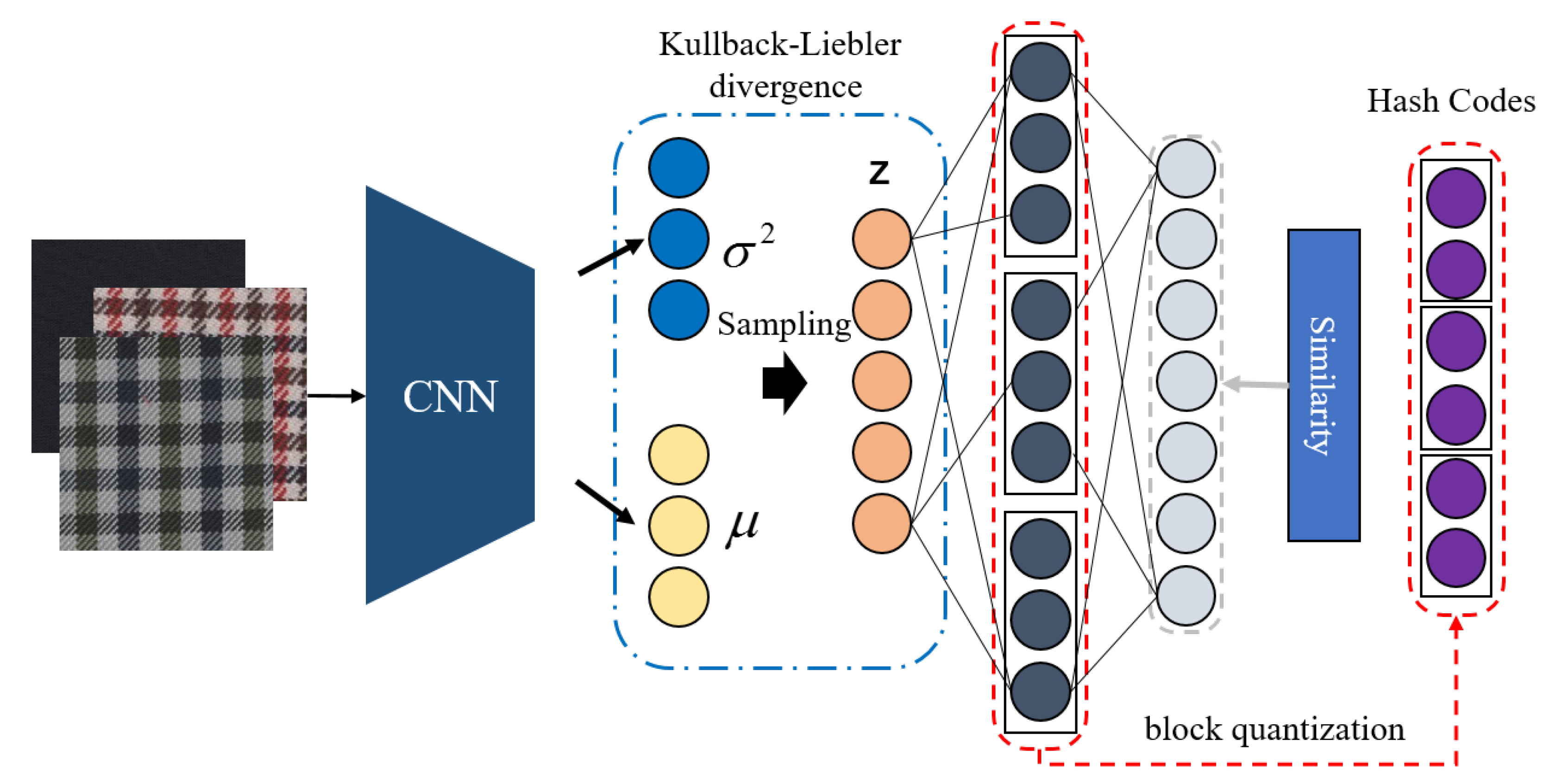
Figure 2a. The adopted base network generally consists of some basic types of layers (e.g., convolutional and pooling layer), which are used for abstraction and optimization of features. The hash layer generates binary hash codes. This architecture has two drawbacks: first, although it can learn nonlinear features, such models are not based on probabilistic modeling, which may limit their ability to learn diverse features; second, the hash layer actually is a bottleneck layer, which is difficult to train using the backpropagation algorithm and has serious information loss.
The deep variational generative model [
20] integrates data distribution priors into the deep model by combining deep neural networks and probability theory, and its effectiveness has been proven in tasks such as image recognition and image segmentation. Therefore, we believe that variational networks have the potential to improve the performances of deep hashing models. As shown in
Figure 2b, the variational network can be viewed as consisting of an encoder and a decoder. The role of the encoder is to sample the output of the fully connected layer. The stochastic layer makes the latent output come from a variational distribution parameterized by a probabilistic model (defined by
and
), which provides the model with strong generalizability. The decoder maps the output of the latent layer into the similarity matrix
S. To learn more information during the training process, this paper introduces the structure layer [
21] in the hash model, as shown in
Figure 2c. The structure layer contains multiple modules, where each module represents multiple binary hash codes, and the structure layer has higher dimensions (the number of nodes) than the hash layer, so more information can be obtained during training. In the testing phase, the output of each node does not correspond to a one-bit hash code, but the outputs of the modules are quantized and spliced together to obtain the final hash code.
Figure 2d shows the hash model that combines the two key technologies.
3. Fine-Grained Similarity of Fabric Images
The goal of fabric image retrieval is to search for the most similar image set to the query image from the fabric image database, and the key is how to judge whether two fabric images are similar. In this study, we propose to describe the similarity between fabric images in four different dimensions, namely, coarse-texture, fine-texture, color and tightness. Both coarse-texture and fine-texture are texture features (only the observation scale is different). Color is represented by the composition and distribution of colors in a fabric image. The tightness is indicated by the tightness index of the fabric. The proposed similarity is measured from these four dimensions. This section describes how the fine-grained similarity is calculated.
3.1. Similarity of Textures
In our previous works [
13,
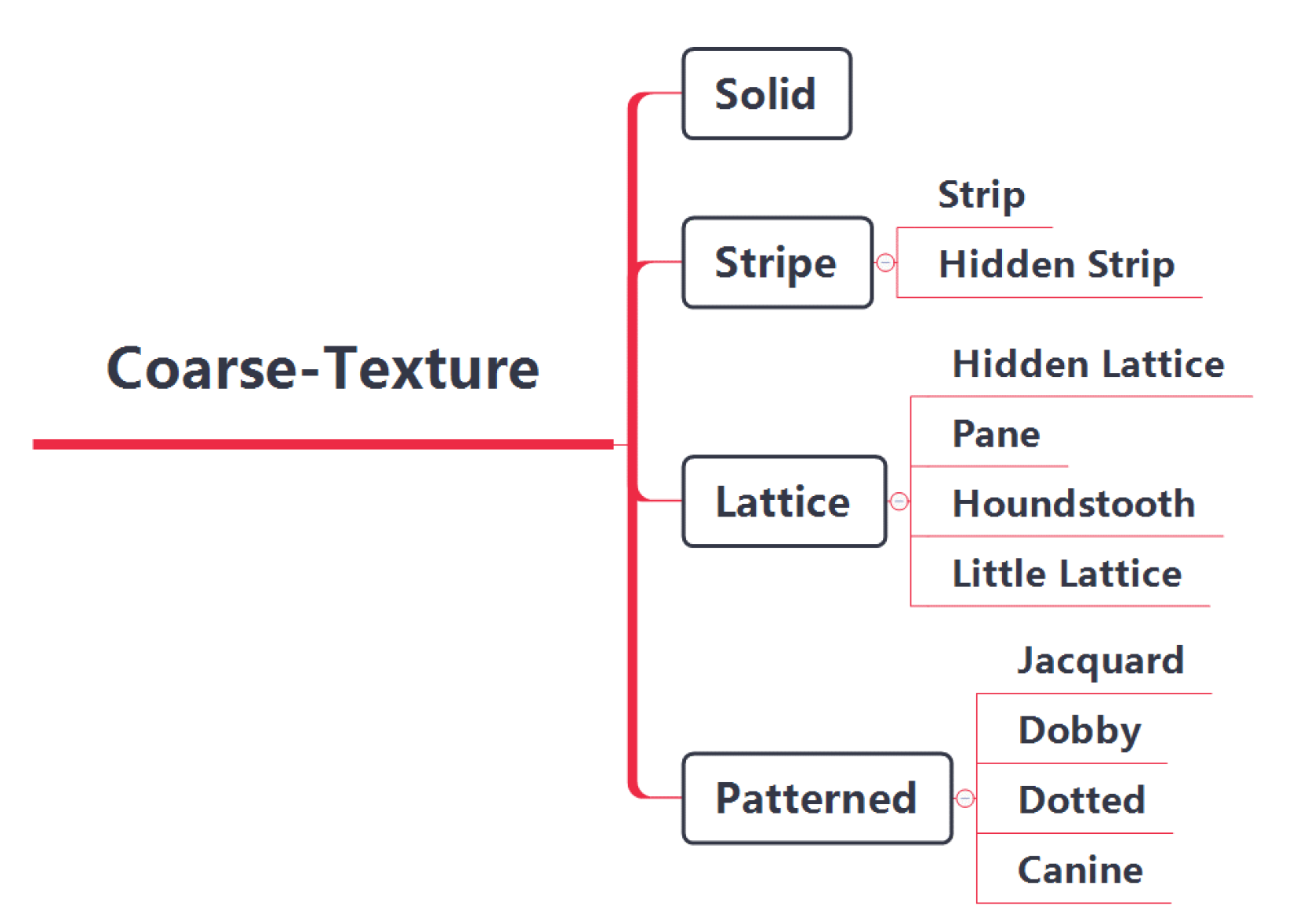
14], we classified fabric images from coarse-texture and fine-texture perspectives, respectively. Here, we classify coarse textures more delicately, as shown in
Figure 3. The coarse texture of the fabric is divided into four major categories: solid color, stripe, plaid and pattern, and each category is subdivided into different numbers of minor categories. Visually, the similarity between fabrics with the same major category but different minor categories is lower than the similarity between fabrics with the same minor category and higher than the similarity between fabrics with different major categories. Therefore, we define three levels for the similarity of coarse textures, namely: similar, approximate and dissimilar. Quantitatively, the similarity between similar fabric images is defined as 1, the similarity between approximate fabric images is 0.5 and the similarity between dissimilar fabrics is 0. The four fabric image samples are shown in
Figure 4, in which both (a) and (b) are small lattices, and their similarity in coarse-texture is 1; (a) and (c) are lattice fabrics, but (c) is a pane with different grid sizes, and their similarity in coarse-texture is 0.5; (a) and (d) belong to different categories, and their similarity is 0. This method avoids the drawbacks of the commonly used non-0 or 1 similarity definition method, and makes the similarity exist in a “middle zone”, which is more in line with human’s cognition of the similarity of things.
Visually, the differences between fine-textures are obvious. Therefore, for the similarity of fine-texture, this paper simply adopts the commonly used binary pairwise similarity matrix; that is, the similarity between fabrics in the same category is 1, and the similarity between fabrics in different categories is 0.
3.2. Similarity of Colors
Color is one of the most important characteristics of fabrics. In the image, the color of each pixel is converted into a numerical representation and mapped into the RGB space, and each color can be represented by a three-dimensional vector, so the color is the underlying feature at the pixel level. However, the RGB color model was proposed from a hardware perspective, which has poor uniformity and is difficult to match with the visual features observed by the human eye. Compared with RGB, HSV is closer to the human eye’s perception of color, so this color model is often used for color feature extraction in image processing. The name of HSV consists of the first letters of the three components: H for hue, S for color saturation and V for color brightness. This way of defining colors is more suitable for comparisons between colors. Here, referring to OPENCV, we divide the HSV color space into 10 regions, which are represented by . Except for solid fabrics, other types of fabrics generally contain two or more colors. Before measuring the color similarity of fabric images, the color features need to be quantified first. The quantification process of fabric color is divided into two steps:
- (1)
First, convert the fabric image in RGB space to HSV space, and then gather the colors of all pixel points into 10 divided areas according to the classification criteria in
Table 1;
- (2)
Then, calculate the value of the cluster center of each clustered area and set the pixel point
.
represents the area index where this pixel point is located. Then, the value of the cluster’s center can be represented by the mean of all points in the area class:
In addition to the value of the cluster’s center, the proportion of each color needs to be calculated. Here, we directly discard the color whose percentage is less than 1%. Then, the color information in the fabric image can be quantified by
, where
N is the number of colors.
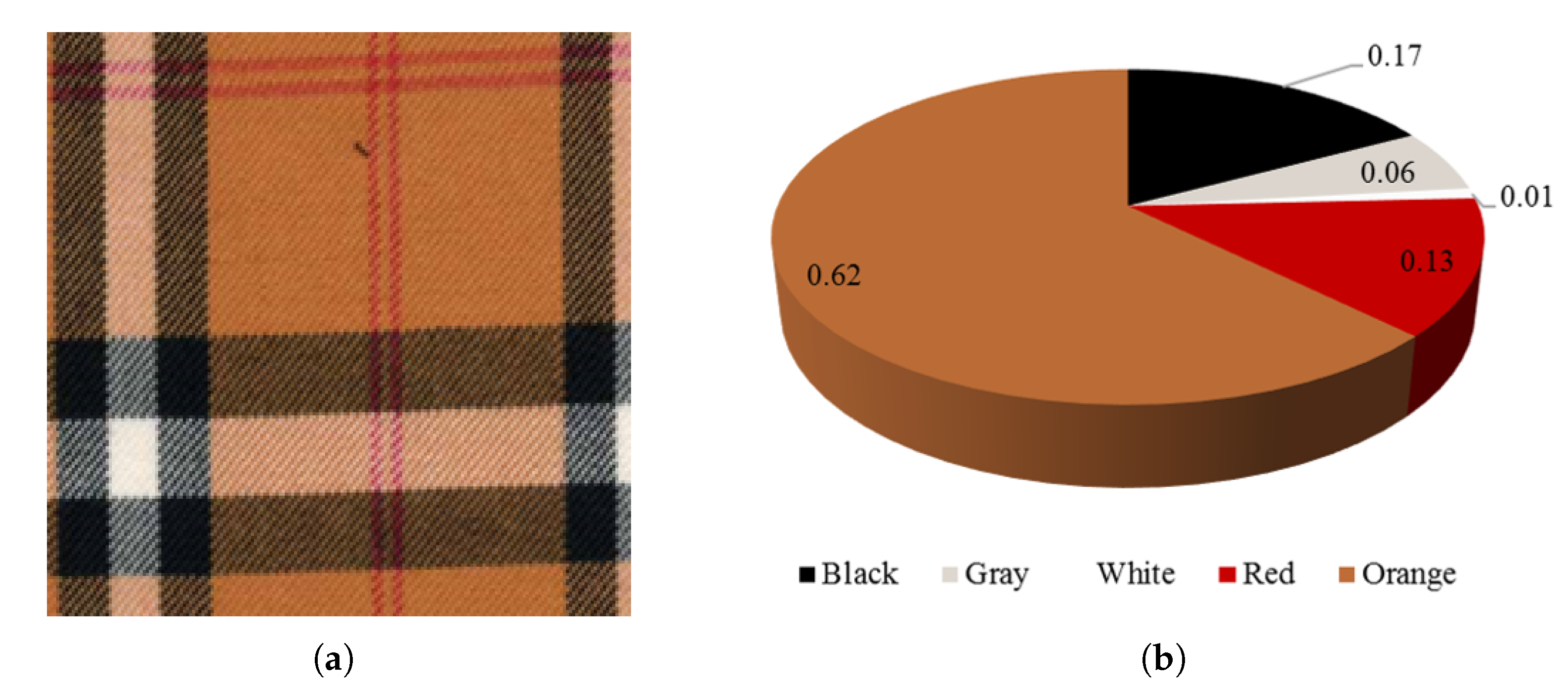
Figure 5 shows an example of fabric image quantization. In the final quantization result, white, which accounts for less than 1%, is discarded. In the final quantization result, the fabric image shown in (a) contains four colors.
For the fabric color information obtained by the above quantization algorithm, it is difficult to use the general color distance calculation method. Assuming that
and
represent the color quantization results of two fabric images, respectively, their similarity is calculated by the following equations:
where
is the Euclidean distance between the two cluster centers in three color components (HSV). The larger the value of
, the more similar the two colors are, and vice versa.
3.3. Similarity of Tightness
For coarse and fine texture, the categories are discrete, whereas the fabric tightness is actually continuous. It is generally believed that the more similar the tightness between the fabrics, the higher the similarity. Here, we use the original fabric tightness information to measure the similarity of tightness. For two fabrics with tightness values
and
, their similarity is defined as follows:
The similarity is evaluated according to the difference between the fabric tightness, represents the distance between adjacent levels and represents the number of levels. If , it means that there is a big difference between them. In that case, the similarity of the tightness between the two fabrics is regarded as 0. If the difference between and is small, the value of is close to 1, indicating that they are very similar. In this paper, and are configured so that the similarity between fabrics is continuous. This definition of fabric tightness similarity is more refined than the binary pairwise similarity matrix, and is more suitable for describing the similarity between such sequence features.
This section defines the similarity measure of fabrics from four granularities, in which tightness (
) and texture (
and
) are at the semantic level, and color (
) is at the underlying pixel level. Finally, the overall similarity between the two fabric images is expressed as:
4. Deep Variational and Structural Hashing
Assume
is the training set used to train the hash model, where
I represents the fabric image,
d denotes the channel of the images and
n represents the number of images in the training set. The goal of hash learning is to learn a hash code generator that can convert input image into binary hash codes while embedding similarity information
S into the generated
K-dimensional binary hash codes
B. The hashing process can be expressed as:
where
g denotes the hash function and
K represents the length of generated hash codes. The framework of the proposed hashing model, which consists of base network module, variational network module and structural network module, is shown in
Figure 6 (called DVSH).
4.1. Base Network Module
Most of the features in the fabric image are some global low-level features, such as color and texture, and the middle and high-level features produced by their combinations. Studies [
22,
23,
24] have shown that the last layer of the deep convolutional neural network contains the highest-order features that can be extracted from this model. The output of this layer is the deep features learned after several convolution operations. The visual content is highly abstract and contains rich semantic information, such as the location, size, and category of the target. These features are the abstraction of the output of the previous layer, so the output of the previous layer has a lower degree of abstraction. Therefore, the features extracted by deeper convolutional layers are more abstract. Generally, the output of the first and second layers often contains rich color and texture features. In our previous study [
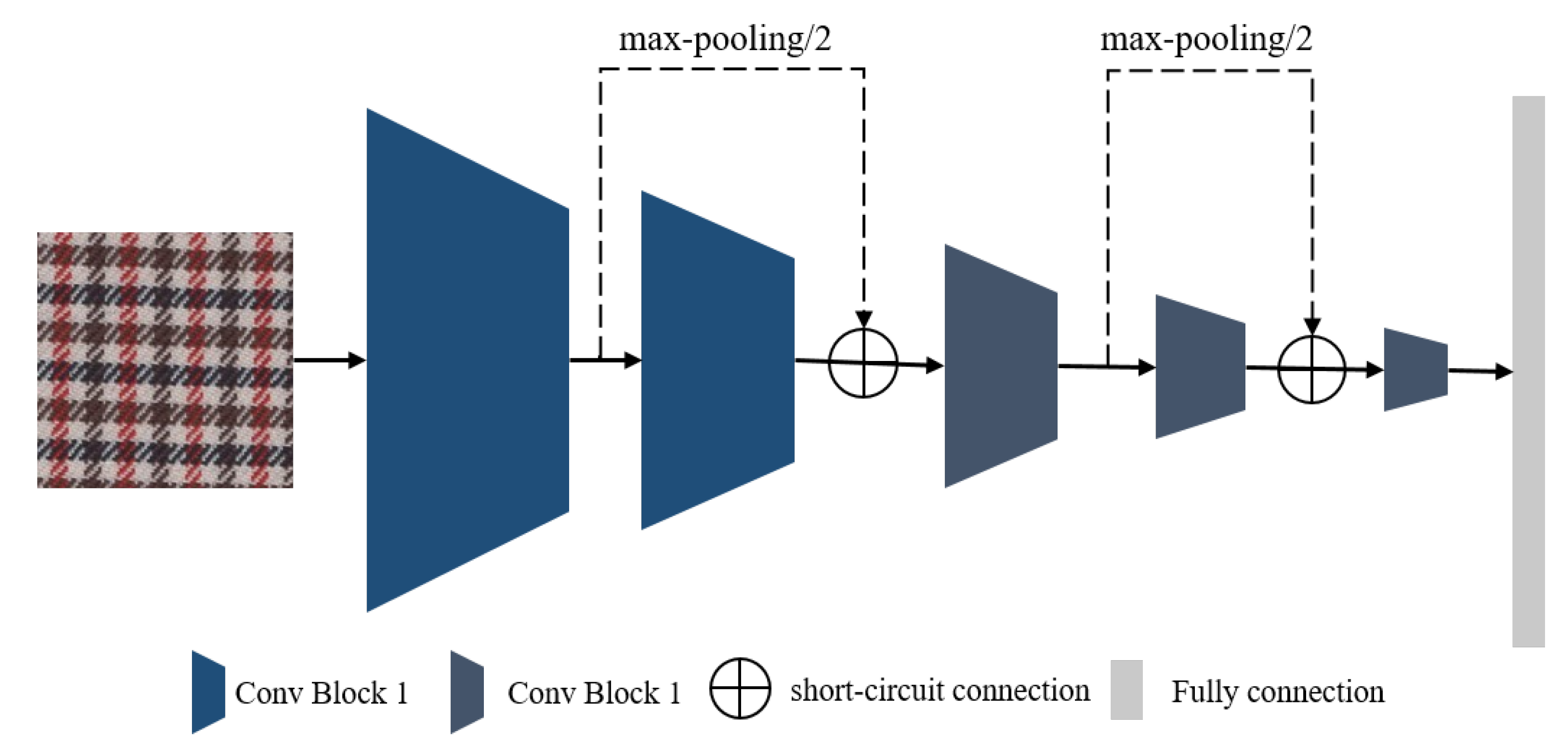
25], we designed a deep convolutional neural network with a compact structure and cross-circuit connections to bridge the “semantic gap.” The architecture of the proposed CNN is shown in
Figure 7, which contains five convolutional blocks, two short-circuit connections and one full connection. Comparative experiments demonstrated the effectiveness and superiority of this CNN for fabric image representation. Therefore, this study directly applied the CNN shown in
Figure 7 as the base network, whose details can be found in reference [
25]. The parameters in the base network are denoted as
; then the features extracted by the base network can be represented by
.
4.2. Variational Network Module
Inspired by the success of variational encoders, we employed a probabilistic interpretation to the hashing network. The output of base network is regarded as the latent representation
, which is assumed to be represented by its posterior distribution
. Under this assumption, the posterior probability approximately follows a normal distribution:
By doing a re-parameterization trick, we can sample
as:
where
means the
lth sample of noise and ⊙ denotes element-wise multiplication;
and
would be the output of the nonlinear projection from the hashing network. Then, the proposal distribution should follow a prior distribution over the latent variable defined as a multivariate Gaussian:
We can enforce this assumption by using Kullback–Liebler divergence (KLD) derived as:
where
j is the
jth element of
and
. The KLD would act as a regularizer of the proposed distribution.
4.3. Structural Network Module
From the latent variable, we impose structure in the succeeding fc layer by splitting it into
M blocks such that
is parameterized by
. Each block would project the latent sample into a distinct semantic representation. Each block vector is represented as:
where
represents the nonlinear projections made on
for the
mth block. Assume
is a struct block with the length of
A. Then, the shared struct layer output would be:
where
. Softmax is adopted for each block output to help maximize the potential of one element on each block, which would prevent approximation loss during encoding.
4.4. Hashing Learning
In fact, the process of converting from continuous variables to binary hash codes is a process of information loss, which can be regarded as the conversion of continuous variables to Hamming distances through lossy information channels. Channel capacity determines the amount of information that can be transferred from continuous variables. Through theoretical derivation, Li et al. [
26] proved that when the input continuous variables obey the bi-half distribution, the channel capacity is the largest and the information loss in the hashing process is the smallest. Following its conclusion, we design the loss function in the hashing process:
To incorporate the defined fine-grained similarity into hash learning, we use list-wise learning as the learning method. During the training, the model receives a set of n fabric images,
.
is regarded as an anchor, and then the similarity matrix
can be obtained by using Equation (
6). Based on the similarity matrix, we can obtain the true permutation of the input fabric images, which is represented by
. Then probability of permutation
is expressed by:
where
denotes the distance of image at position
j of permutation
. Here, we set
. During training, the true permutation of the input images is known. Then, according to the idea of maximum likelihood estimation, by maximizing the log-likelihood corresponding to the true permutation (or equivalently minimizing the negative log-likelihood), the parameters of the model then can be optimized, and the loss function can be written as:
In summary, the total loss function of the model can be expressed as:
where
is the total loss,
is the list-wise loss of feature
U and
is the quantitative loss.
and
are three weighting parameters to balance the effects of different loss functions. Each sub-item in the objective function is differentiable, so this optimization problem can be regarded as a convex optimization problem. Like other deep learning models, the stochastic gradient descent (SGD) algorithm and the backpropagation (BP) algorithm are used to optimize the parameters in the proposed model.
5. Experiments
5.1. Experimental Detail
As we all know, the CBIR method based on deep learning learns the image representation ability from a certain amount of training data. Therefore, data are the basis for model learning. In our previous studies [
13,
14], a dataset named WFID has been established for studying fabric image retrieval. WFID consists of 82,073 fabric images, all of which are annotated from four perspectives: coarse texture, fine texture, fabric style and the pattern forming method. In this study, we still used this dataset to demonstrate the effectiveness and superiority of the proposed method for fabric image retrieval. The difference is that only two versions of annotations were used in this study: coarse texture and fine texture. For fair comparison, the proposed method and compared learning-based methods were all trained on the training set with 33,645 fabric images; the performances of all methods were evaluated on the validation set. The validation set consists of 1029 sets of samples, each of which is an image.
The proposed DVSH was implemented by using the Pytorch toolkit. The hardware environment is as follows: CPU = E5 2623V4@2.60GHz, RAM = DDR4 32G, GPU = GeForce RTX 3090(24G) × 2. All compared deep learning-based methods were implemented using the Pytorch toolkit and based on the backbone of VGG-16. Additionally, the other methods, which are based on hand-crafted descriptors, were implemented by using MATLAB 2018b. During the training, the hyper-parameter configuration was as follows: batch_size = 32, weight_decay = , optimizer = ADAM and learning_rate = .
Generally, CBIR methods are evaluated based on precision, recall or the precision–recall curve. In addition, we also adopted
and
to more comprehensively evaluate the performance of each method. We computed each evaluation metric by referring to reference [
25].
5.2. Parameter Analysis
There are three parameters, , and , to balance different objective functions. is the main driver to guide the learning of the model, so its corresponding weight parameter was directly set to 1. and were, respectively, used to adjust the gradients of the corresponding parameters of the objective functions and during training. In this experiment, the influences of different weight parameter configurations on the final retrieval effect of the model were compared to optimize the optimal parameter configuration. We used the control variable method for analysis and comparison—that is, fixing one of the parameters to analyze and discussing the influence of another parameter on the performance of the model.
The retrieval performance comparison results of the models under different parameter configurations are shown in
Table 2.
- (1)
When the parameter is fixed, the performance of the model under each evaluation index shows a similar law; that is, with the increase in , the performance of the model shows a trend of first increasing and then decreasing. When its value is close to 1, the guiding effect of the corresponding objective function will be stronger than in other tasks; when its value is lower than , the guiding effect of the corresponding objective function is too low and is covered by other tasks. Both cases will affect the feature selection ability of the variational network module, which will lead to the degradation of retrieval performance.
- (2)
When
is fixed, and the value of
is 1 and
, each retrieval evaluation index of the model is very low, and the retrieval effect varies greatly in each coding length. This phenomenon shows that the guiding effect of this objective function completely covers other objective functions under this condition, which leads to the instability of the model performance. In particular, the retrieval performance of the model is the worst in
Table 2, and it can be considered that the similarity of the fabric images is not embedded in the generated hash code. When the value of
is in the range of [
,
], the retrieval performance of the model is not very different, and all of them can achieve good performance. When
, the model performance has a certain decline. When the parameters take values in the interval [
,
], the sensitivity of the model performance is low, and the performance is relatively stable.
In contrast, the DVSH model is more sensitive to , because the quantization loss directly affects the quality of the generated hash code. The experimental results show that when and , the model achieves the best performance, so this configuration was used in subsequent experiments.
5.3. Ablation Study
To gain insight into DVSH, we performed an ablation study. DVSH contains a variational network module, a structural network module and a similarity embedding module. Undoubtedly, the similarity embedding module is an indispensable part of the model, so this module was not analyzed in the ablation study. The other two modules of DVSH are very flexible and can be added or removed. Under the condition that the similarity embedding module is preserved, DVSH produces three variants: DVSH1a (removing the variational network module), DVSH1b (removing the structural network module) and DVSH2a (removing both modules). The comparative experimental results of DVSH and its three variants are shown in
Table 3. It is clearly observed that removing any one of the modules in DVSH leads to a decrease in model performance. The performance of DVSH2a with both modules removed is significantly reduced. The experimental results demonstrate that the structural network module and the variational network module can jointly promote hash learning, so that the generated hash codes retain more useful information.
5.4. Time Complexity Analysis
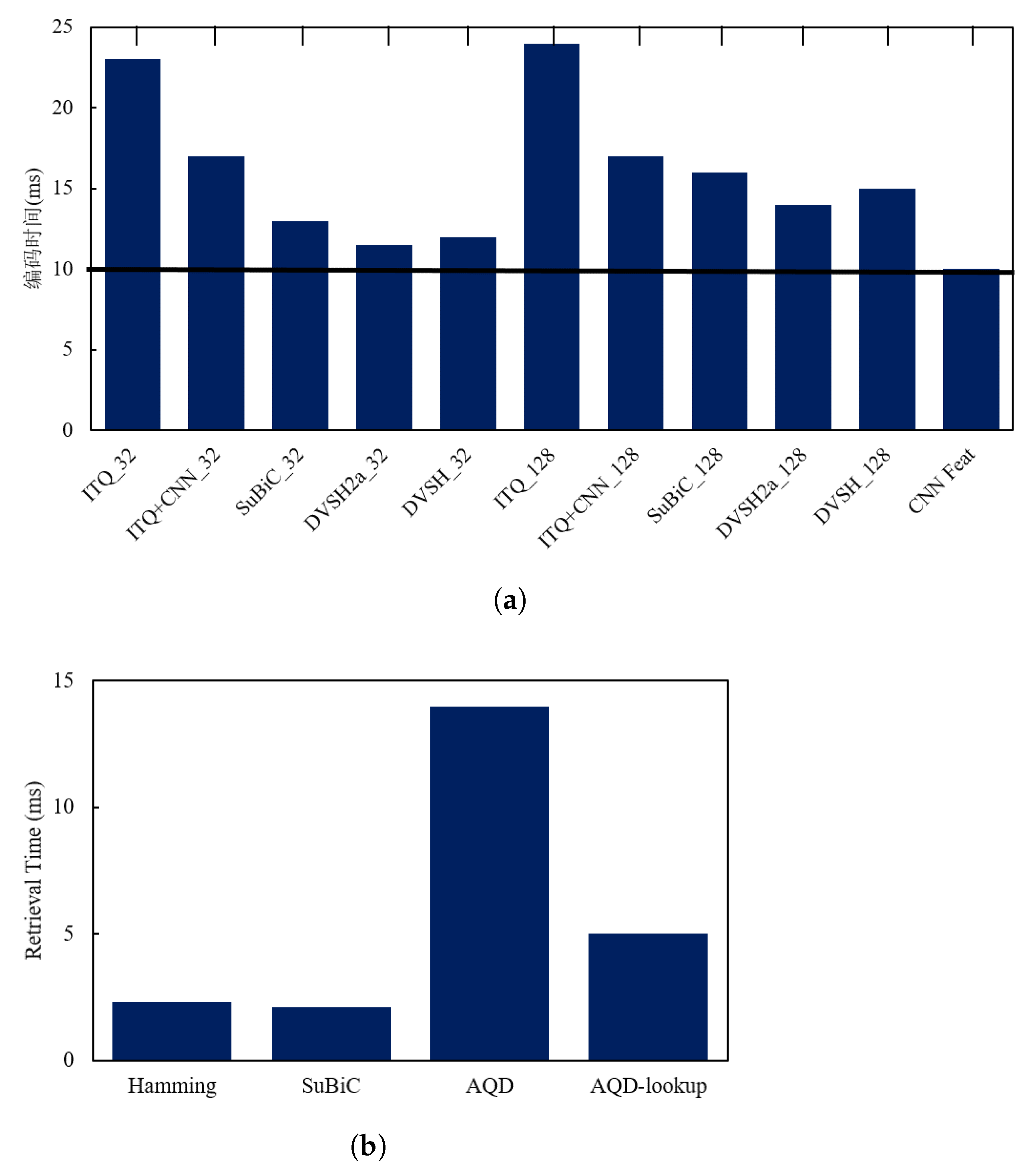
An efficient retrieval system not only needs to output accurate retrieval results, but also must respond quickly to retrieval needs; that is, it must also have high timeliness. To demonstrate the efficiency of DVSH, we first compare the single image encoding times of different methods when the encoding length is 32 or 128 bits, including iterative quantization (ITQ) [
27], ITQ+CNN [
27], SuBiC [
28] and DVSH2a (mentioned in the section of ablation study). Among them, ITQ and ITQ+CNN are two quantization-based dimensionality reduction methods, SuBic is a structured hashing method and DVSH2a is a variant of DVSH. The comparison results of the encoding time of the above methods are shown in
Figure 8a, where “CNN Feat” represents the time when the convolutional neural network (Base Network) extracts features. As can be seen in the figure, the hash-based methods, SuBic and DVSH, consumed more time than CNN Feat because the encoding process takes a certain amount of time. Since more nodes will take more quantization time, the DVSH_128 encoding process takes more time than DVSH_32. However, the time consumption of high-dimensional feature extraction accounted for more than 70% of the total time-consuming, and the DVSH encoding time only accounted for less than 30%. DVSH is less than 10% more time-consuming than DVSH2a, indicating that the structural network module and the variational network module do not add too much computation.
Similarity measurement is another time-consuming link in CBIR. The hash method maps the similarity measure to the Hamming space, and then uses a simple and efficient XOR operation to calculate the similarity between binary codes. Quantization-based methods such as DVSQ [
29] employ AQD [
30] to compute the inner product between features to measure their similarity. SuBiC [
28] computes asymmetric distances between features directly using the network output, thereby quickly computing similarities. In the experiment, the parameters of SuBiC and AQD were configured according to reference [
28] and reference [
29], respectively. The experimental results are shown in
Figure 8b, which show that the query speed of AQD was seven times that of Hamming and SuBiC, and the time consumption of Hamming and and that of SuBiC were not very different. In retrieval, SuBiC only needs to perform a certain number of addition operations and use real-valued query codes. Although the time consumption is slightly lower than that of the Hamming, its calculation process takes up a lot of memory. AQD-lookup adopts the AQD of the code table, which uses the pre-calculated M × K code table, and directly uses the code table to query the distance between the two subspaces, which greatly shortens the time for quantizing the product. However, AQD-lookup needs to allocate memory on the code table of each query, increasing memory consumption, and the retrieval speed is lower than Hamming. In conclusion, the overall retrieval efficiency of DVSH is more suitable for efficient fabric image retrieval.
5.5. Comparisons
This section verifies the rationality and superiority of the proposed hashing model through horizontal comparison experiments. Some SOTA (state-of-the-art) deep hashing methods are compared, including: three hashing methods based on triplet loss supervised learning (DRSCH [
31], DSRH [
32], DNNH [
33]), four supervised methods based on pairwise similarity loss (CNNH+ [
34], DSH [
35], DHN [
11], IDHN [
36]) and seven methods based on custom similarity guidance (CSQ [
37], ISDH [
38], DSHSD [
39], SuBiC [
28], MVL [
40], UDHNR [
41] and VTDH [
42]. SuBiC is similar to DVSH, but it uses a sigmoid and threshold to binarize the output features to generate hash codes.
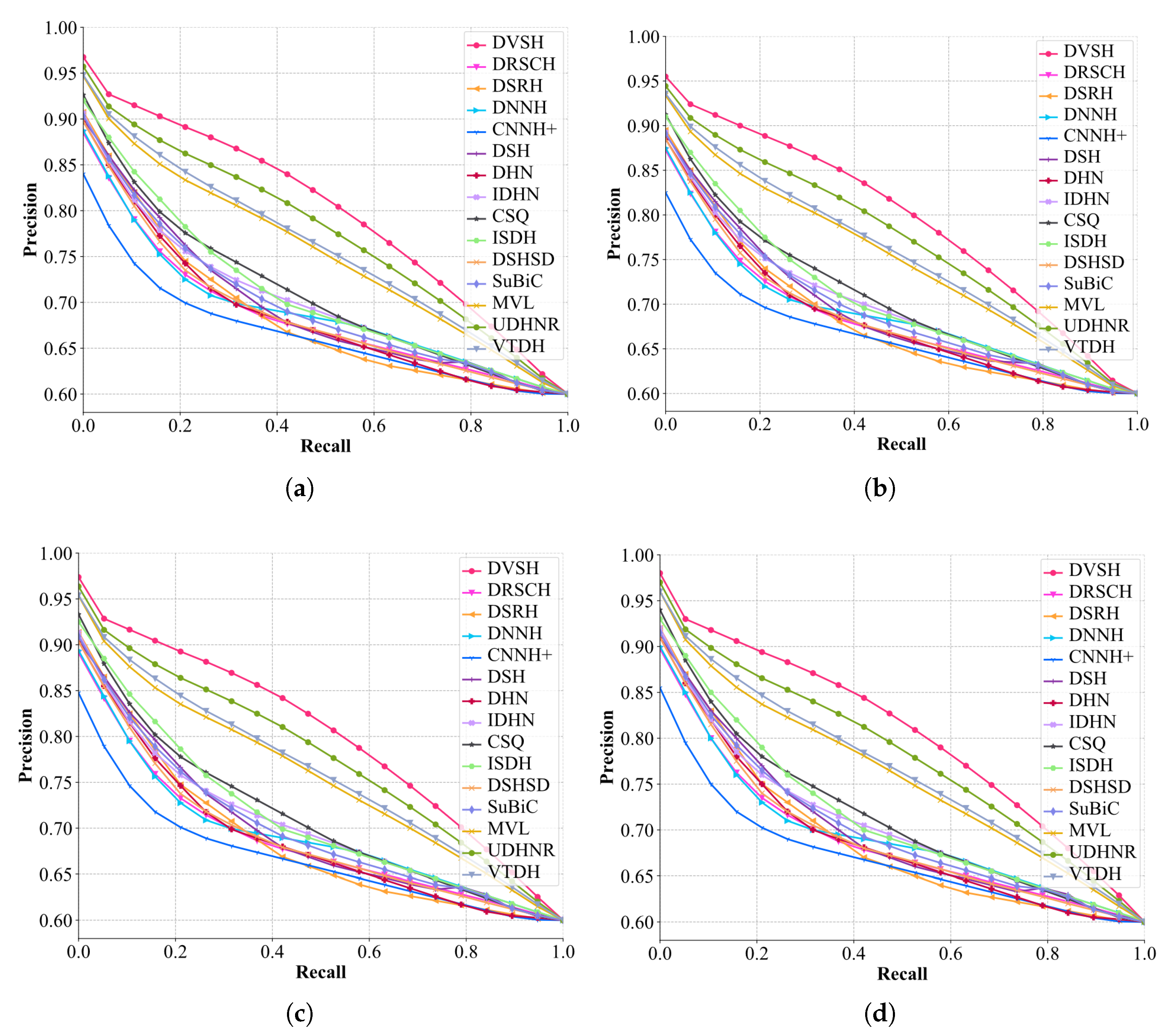
The comparison results of
and
of different hashing methods are shown in
Table 4. It can be observed from the results that methods based on triplet loss are generally more stable than methods based on pairwise similarity loss, proving that methods based on triplet loss learn more similarity information. However, the DVSH proposed in this paper not only utilizes the discriminative classification of fabrics to guide hash learning, but also uses list-wise learning to embed more similarity information in the generated hash codes. List-wise learning is guided by the similarity of a batch of fabric images, and its learning objective is more stringent than pairwise and triplet losses. The variational network module and the structural network module are used in the DVSH model to reduce the learning difficulty, and the content of the model’s learning is closer to the ideal fabric similarity arrangement. DVSH far outperformed other methods in
, indicating that the hash code generated by DVSH contained more fabric fine-grain similarity information, and thus achieved a higher ranking score. As shown in
Figure 9, the trends of PR curves for different code length models show consistency, illustrating the robust performance of the contrasting methods for fabric retrieval. The area under the PR curve corresponding to DVSH is higher than those of other methods at all encoding lengths, which verifies the superiority of the proposed method. In addition, all experimental results show that the longer the code length, the more fabric similarity information can be inherited, and thus the better the retrieval performance that can be obtained. It is worth noting that methods using soft similarity, such as IDHN and CSQ, achieved better retrieval results than other methods, indicating that more fine-grained similarity measurement methods can improve the retrieval performance of fabric images. Compared with the soft similarity, a more fine-grained measurement method was adopted, and more superior performance was obtained. The experimental results once again proved the validity of the fabric fine-grained similarity defined in this paper. Some retrieval samples are shown in
Figure 10. The precise retrieval results show that DVSH has excellent performance for fabric image retrieval.
6. Conclusions
In this paper, a novel method for fabric image retrieval based on variational and structural hashing was proposed. To narrow the gap between fabric images and similarities, we designed a CNN with a compact structure and cross-shortcut connections, which is regarded as the base network of the hashing model. To overcome the problems of probabilistic missing and difficult training in classical hashing, we introduced a variational network module and structural network module into the hashing model (named DVSH). Then, a fine-grained similarity was defined to measure the similarity between two fabric images. To incorporate the defined fine-grained similarity into hash learning, we employed list-wise learning to complete similarity embeddings in mini-batches. The results of ablation experiments showed that the absence of any module will cause the performance of the model to decline, which verified the necessity and effectiveness of each module in DVSH. Through time complexity analysis, the single image encoding time of DVSH was only 16 milliseconds, which verified the real-time performance of the method. The retrieval performances of different hashing methods were compared, and DVSH achieved the best performance in different coding lengths, which verified the superiority of the method for fabric image retrieval. The method proposed in this paper has been successfully applied in cooperative enterprises.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}