


An Asymmetric Contrastive Loss for Handling Imbalanced Datasets

Abstract
:1. Introduction
2. Related Work
3. Background on Entropy and Loss Functions
3.1. Entropy, Information, and Divergence
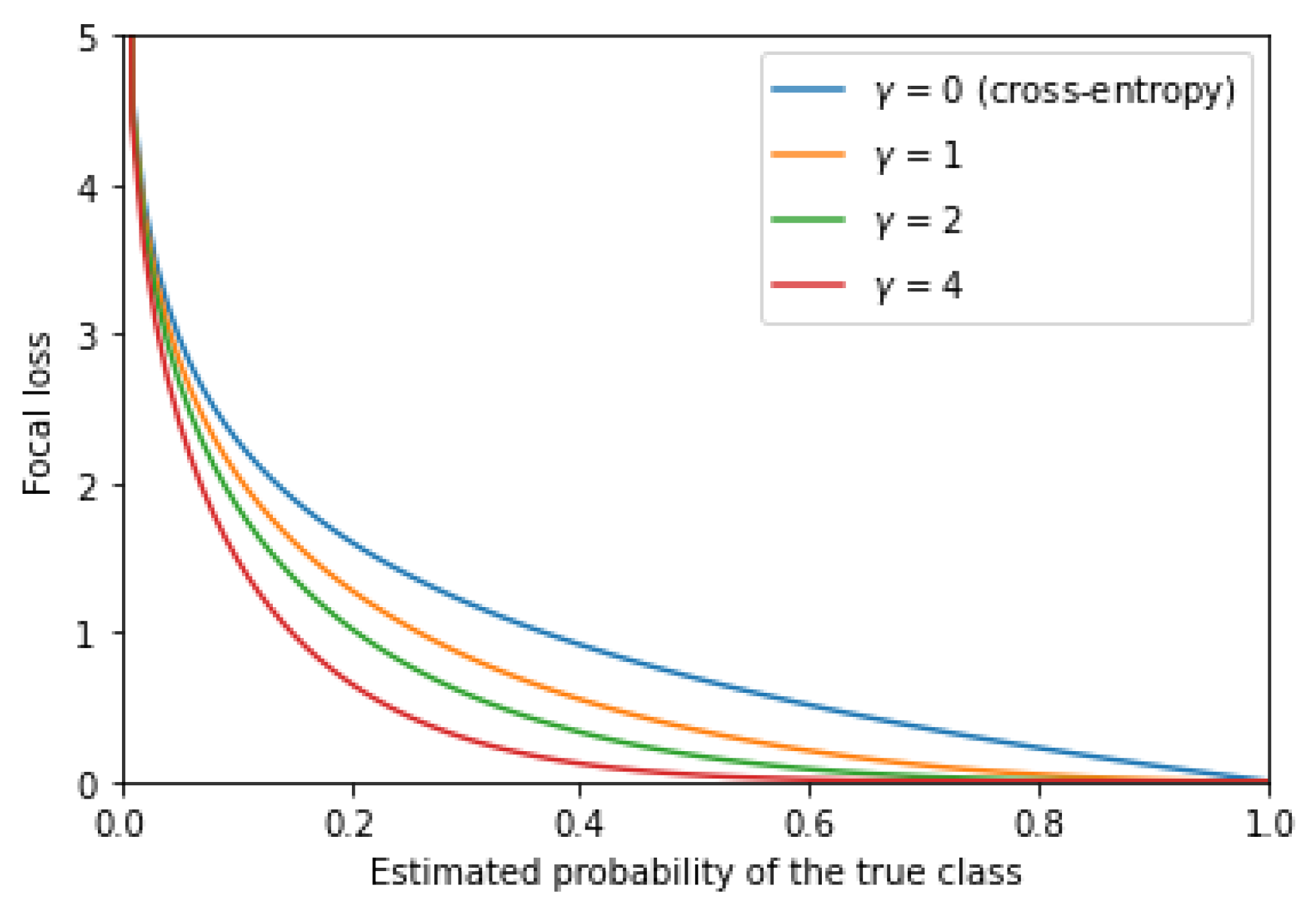
3.2. Cross-Entropy and Focal Loss
3.3. Asymmetric Loss
3.4. Contrastive Loss
4. Proposed Loss Functions and Architecture
4.1. Asymmetric Contrastive Loss
4.2. Asymmetric Focal Contrastive Loss
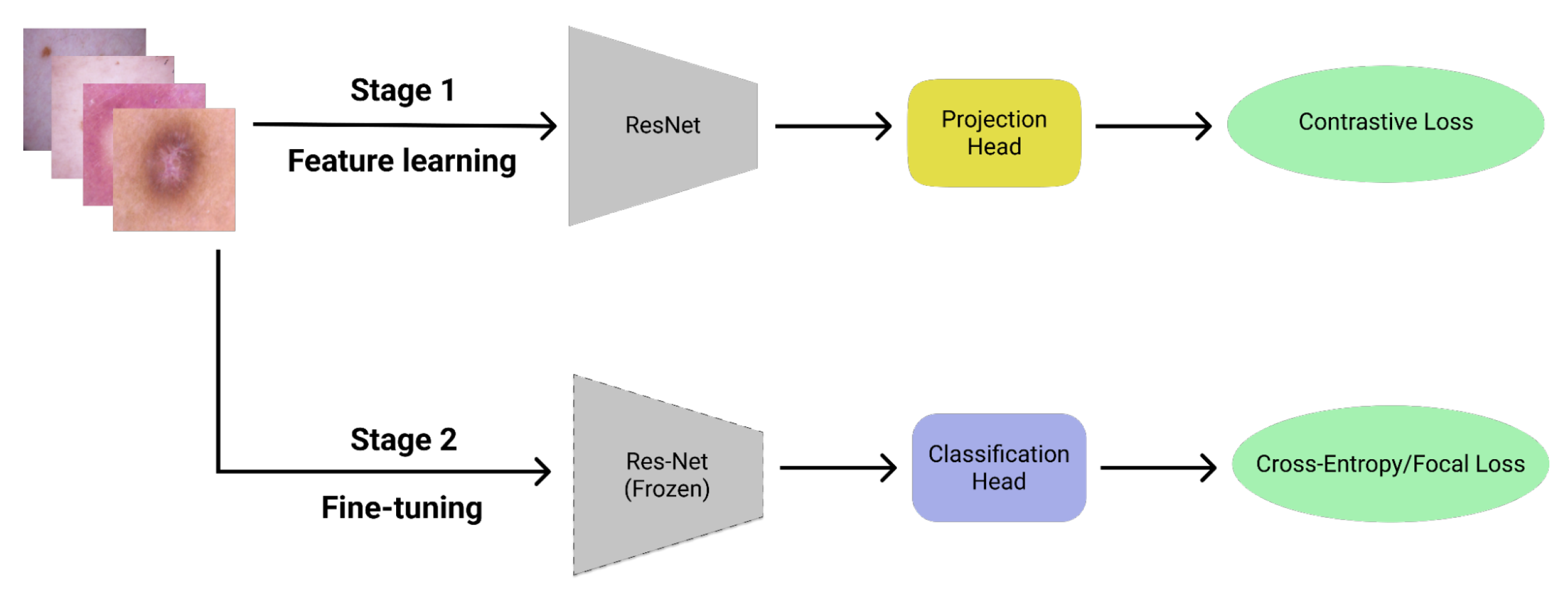
4.3. Model Architecture
5. Experiments
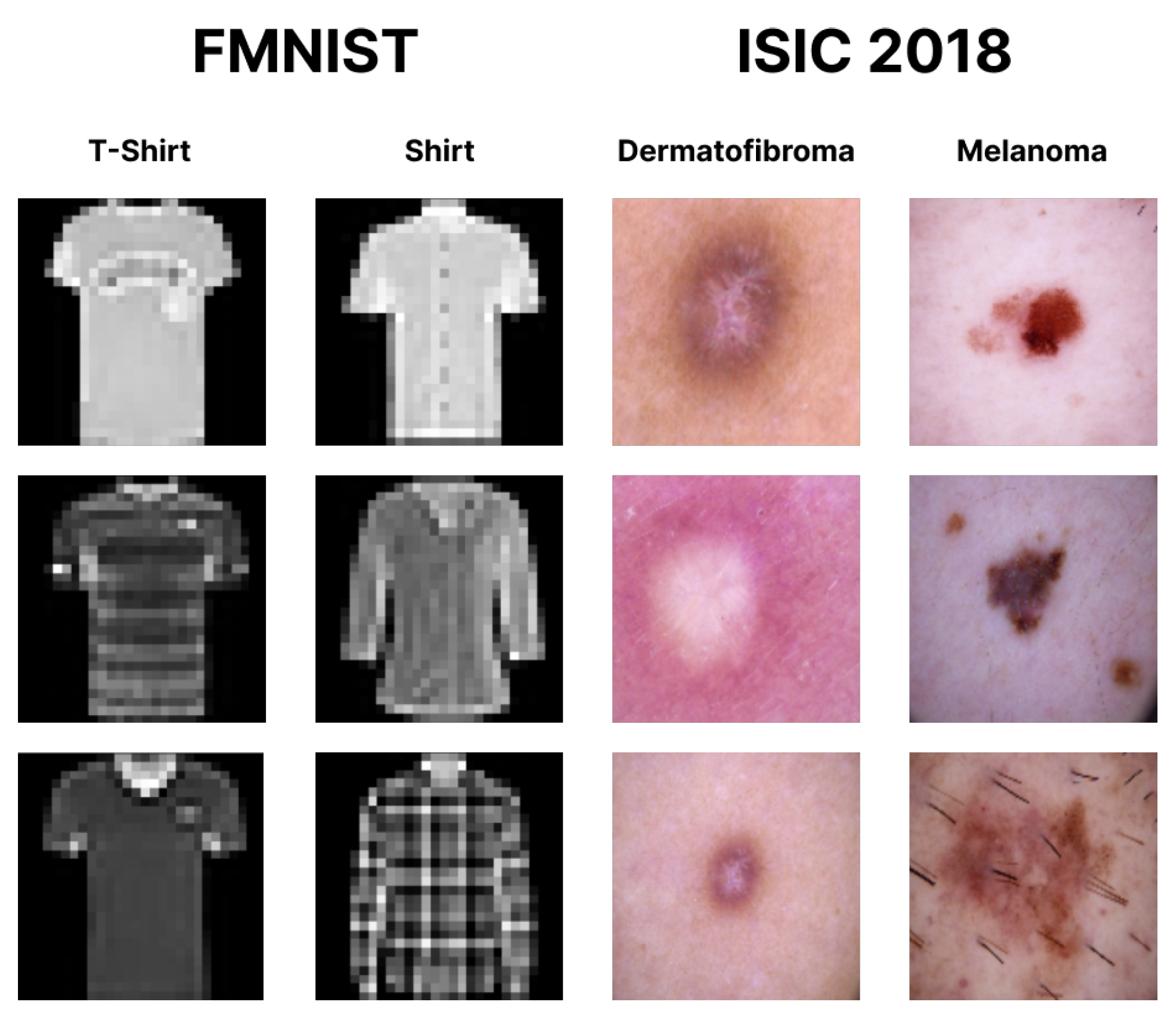
5.1. Datasets
5.2. Experimental Details
5.3. Experiments Using FMNIST
5.4. Experiments Using ISIC 2018
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef] [PubMed]
- Bej, S.; Davtyan, N.; Wolfien, M.; Nassar, M.; Wolkenhauer, O. LoRAS: An oversampling approach for imbalanced datasets. Mach. Learn. 2021, 110, 279–301. [Google Scholar] [CrossRef]
- Fajardo, V.A.; Findlay, D.; Houmanfar, R.; Jaiswal, C.; Liang, J.; Xie, H. Vos: A method for variational oversampling of imbalanced data. arXiv 2018, arXiv:1809.02596. [Google Scholar]
- Karia, V.; Zhang, W.; Naeim, A.; Ramezani, R. Gensample: A genetic algorithm for oversampling in imbalanced datasets. arXiv 2019, arXiv:1910.10806. [Google Scholar]
- Tripathi, A.; Chakraborty, R.; Kopparapu, S.K. A novel adaptive minority oversampling technique for improved classification in data imbalanced scenarios. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10650–10657. [Google Scholar]
- Arefeen, M.A.; Nimi, S.T.; Rahman, M.S. Neural network-based undersampling techniques. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 1111–1120. [Google Scholar] [CrossRef]
- Dai, Q.; Liu, J.w.; Liu, Y. Multi-granularity relabeled under-sampling algorithm for imbalanced data. Appl. Soft Comput. 2022, 124, 109083. [Google Scholar] [CrossRef]
- Koziarski, M. Radial-based undersampling for imbalanced data classification. Pattern Recognit. 2020, 102, 107262. [Google Scholar] [CrossRef]
- Rayhan, F.; Ahmed, S.; Mahbub, A.; Jani, R.; Shatabda, S.; Farid, D.M. Cusboost: Cluster-based under-sampling with boosting for imbalanced classification. In Proceedings of the 2017 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS), Bengaluru, India, 21–23 December 2017; pp. 1–5. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Marrakchi, Y.; Makansi, O.; Brox, T. Fighting class imbalance with contrastive learning. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 466–476. [Google Scholar]
- Chen, K.; Zhuang, D.; Chang, J.M. SuperCon: Supervised contrastive learning for imbalanced skin lesion classification. arXiv 2022, arXiv:2202.05685. [Google Scholar]
- Wang, Z.; Peng, C.; Zhang, Y.; Wang, N.; Luo, L. Fully convolutional siamese networks based change detection for optical aerial images with focal contrastive loss. Neurocomputing 2021, 457, 155–167. [Google Scholar] [CrossRef]
- Alenezi, F.; Öztürk, Ş.; Armghan, A.; Polat, K. An Effective Hashing Method using W-Shaped Contrastive Loss for Imbalanced Datasets. Expert Syst. Appl. 2022, 204, 117612. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Henaff, O. Data-efficient image recognition with contrastive predictive coding. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 4182–4192. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 776–794. [Google Scholar]
- Zhang, Y.; Hooi, B.; Hu, D.; Liang, J.; Feng, J. Unleashing the power of contrastive self-supervised visual models via contrast-regularized fine-tuning. Adv. Neural Inf. Process. Syst. 2021, 34, 29848–29860. [Google Scholar]
- Ben-Baruch, E.; Ridnik, T.; Zamir, N.; Noy, A.; Friedman, I.; Protter, M.; Zelnik-Manor, L. Asymmetric loss for multi-label classification. arXiv 2020, arXiv:2009.14119. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Ajjanagadde, G.; Makur, A.; Klusowski, J.; Xu, S. Lecture Notes on Information Theory; Laboratory for Information and Decision Systems, Massachusetts Institute of Technology: Cambridge, MA, USA, 2017. [Google Scholar]
- Gowers, W. Topics in Combinatorics. 2020. Available online: https://drive.google.com/file/d/1V778zHQTx4XE8FxDgznt2jTshZzxAFot/view (accessed on 13 May 2022).
- Khinchin, A.Y. Mathematical Foundations of Information Theory; Dover Publications: Mignola, NY, USA, 1957. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Boudiaf, M.; Rony, J.; Ziko, I.M.; Granger, E.; Pedersoli, M.; Piantanida, P.; Ayed, I.B. A unifying mutual information view of metric learning: Cross-entropy vs. pairwise losses. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 548–564. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Fahad, M.S.; Ranjan, A.; Yadav, J.; Deepak, A. A survey of speech emotion recognition in natural environment. Digit. Signal Process. 2021, 110, 102951. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Metric | ||||||
|---|---|---|---|---|---|---|---|
| 0 | 60 | 120 | 180 | 240 | 300 | ||
| 50:50 | Accuracy | 78.92 | 77.83 | 79.75 | 71.08 | 77.17 | 78.83 |
| UWA | 79.00 | 78.28 | 80.32 | 72.53 | 77.87 | 79.42 | |
| 55:45 | Accuracy | 79.50 | 79.50 | 79.33 | 77.83 | 77.67 | 77.75 |
| UWA | 78.70 | 79.34 | 79.15 | 77.17 | 78.21 | 76.50 | |
| 60:40 | Accuracy | 84.50 | 82.92 | 82.42 | 81.33 | 82.08 | 83.17 |
| UWA | 83.09 | 81.82 | 81.27 | 79.71 | 81.74 | 81.66 | |
| 65:35 | Accuracy | 81.50 | 83.42 | 83.25 | 81.59 | 82.58 | 79.25 |
| UWA | 79.19 | 80.91 | 80.73 | 77.92 | 79.43 | 75.42 | |
| 70:30 | Accuracy | 82.50 | 84.33 | 85.08 | 82.08 | 83.42 | 83.00 |
| UWA | 78.41 | 78.26 | 80.91 | 77.78 | 79.14 | 75.11 | |
| 75:25 | Accuracy | 86.75 | 85.17 | 85.58 | 85.17 | 86.92 | 86.58 |
| UWA | 77.87 | 76.48 | 77.74 | 77.03 | 78.63 | 77.57 | |
| 80:20 | Accuracy | 86.00 | 87.25 | 87.33 | 87.92 | 87.00 | 88.25 |
| UWA | 76.16 | 74.65 | 76.94 | 76.28 | 77.49 | 76.97 | |
| 85:15 | Accuracy | 87.33 | 87.08 | 86.75 | 87.42 | 87.33 | 87.67 |
| UWA | 70.08 | 66.34 | 55.77 | 68.33 | 69.83 | 62.83 | |
| 90:10 | Accuracy | 90.83 | 91.00 | 90.83 | 90.67 | 89.50 | 91.67 |
| UWA | 64.91 | 68.61 | 66.11 | 64.02 | 61.77 | 72.58 | |
| 95:5 | Accuracy | 94.42 | 93.33 | 93.42 | 94.00 | 92.83 | 93.25 |
| UWA | 54.77 | 60.70 | 54.24 | 50.00 | 49.38 | 54.80 | |
| 98:2 | Accuracy | 97.42 | 97.83 | 98.08 | 98.08 | 98.33 | 98.08 |
| UWA | 52.45 | 52.66 | 55.87 | 55.87 | 49.83 | 52.79 | |
| Scenario | Metric | ||||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 4 | 7 | 10 | ||
| 50:50 | Accuracy | 78.08 | 74.83 | 77.08 | 77.58 | 76.58 | 77.50 |
| UWA | 77.70 | 74.84 | 76.77 | 77.55 | 76.55 | 77.25 | |
| 55:45 | Accuracy | 80.17 | 81.25 | 80.75 | 80.00 | 81.75 | 76.83 |
| UWA | 80.14 | 81.19 | 80.69 | 79.96 | 81.70 | 76.82 | |
| 60:40 | Accuracy | 79.42 | 78.50 | 77.92 | 80.17 | 80.67 | 80.08 |
| UWA | 84.42 | 83.42 | 80.00 | 83.00 | 82.42 | 82.92 | |
| 65:35 | Accuracy | 84.42 | 83.42 | 80.00 | 83.00 | 82.42 | 82.92 |
| UWA | 81.98 | 81.22 | 77.87 | 80.39 | 80.68 | 80.16 | |
| 70:30 | Accuracy | 83.75 | 83.83 | 82.17 | 82.58 | 84.83 | 82.25 |
| UWA | 79.64 | 79.18 | 77.82 | 77.51 | 79.67 | 78.71 | |
| 75:25 | Accuracy | 85.42 | 86.17 | 84.42 | 84.83 | 85.75 | 86.00 |
| UWA | 76.27 | 79.85 | 77.08 | 76.41 | 77.34 | 78.47 | |
| 80:20 | Accuracy | 89.33 | 89.58 | 87.67 | 89.42 | 87.33 | 88.00 |
| UWA | 77.59 | 78.67 | 78.43 | 79.31 | 78.97 | 70.12 | |
| 85:15 | Accuracy | 87.42 | 89.00 | 88.17 | 88.33 | 89.08 | 90.08 |
| UWA | 64.97 | 72.08 | 71.99 | 71.47 | 71.95 | 77.04 | |
| 90:10 | Accuracy | 92.42 | 92.33 | 93.42 | 93.25 | 92.58 | 91.25 |
| UWA | 64.00 | 67.94 | 66.04 | 74.42 | 80.54 | 68.35 | |
| 95:5 | Accuracy | 94.17 | 93.17 | 95.33 | 95.00 | 94.00 | 95.09 |
| UWA | 62.13 | 53.11 | 57.64 | 59.17 | 55.22 | 55.82 | |
| 98:2 | Accuracy | 96.92 | 96.92 | 95.00 | 96.00 | 96.92 | 96.67 |
| UWA | 56.59 | 51.56 | 55.61 | 52.63 | 53.10 | 52.98 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vito, V.; Stefanus, L.Y. An Asymmetric Contrastive Loss for Handling Imbalanced Datasets. Entropy 2022, 24, 1303. https://doi.org/10.3390/e24091303
Vito V, Stefanus LY. An Asymmetric Contrastive Loss for Handling Imbalanced Datasets. Entropy. 2022; 24(9):1303. https://doi.org/10.3390/e24091303
Chicago/Turabian StyleVito, Valentino, and Lim Yohanes Stefanus. 2022. "An Asymmetric Contrastive Loss for Handling Imbalanced Datasets" Entropy 24, no. 9: 1303. https://doi.org/10.3390/e24091303