1. Introduction
In recent years, micro-expressions (MEs) have gained increasing publicity in both the academic and industrial community. A micro-expression is a stifled facial expression with subtle and spontaneous muscle movements that appears very briefly (i.e., less than 200 ms). It usually appears when people attempt to conceal their true emotional states [
1] and is hard to disguise even for expert actors. Therefore, MEs can be regarded as reliable clues with which to infer human emotions, making them especially helpful in high-stake situations, e.g., in the judicial system, police interrogation [
2] and clinical diagnosis. However, revealing spatial-temporal information is difficult because of the low intensity [
3] and short duration of MEs and it is rather challenging for humans to identify a ME with the naked eye. In order to improve Micro-Expression Recognition (MER) performance, psychological researchers have made contributions so as to train people to use training tools. Despite these tools, the ability of people to recognize MEs achieves a less than 40% accuracy. Moreover, manually recognizing MEs is time consuming, urging people to seek more automatic and accurate methods for MER [
2,
4,
5,
6].
Facial expressions present in a dynamic manner, MEs, can be recorded in online and offline videos. This characteristic facilitates the creation of ME databases, which provide the ability to perform insightful studies on MER. The USF-HD [
7], Polikovsky’s Database [
3] and York Deception Detection Test (York-DDT) [
8] are the earliest databases collecting ME video clips. However, these databases are not widely used because of their limitations. For instance, the MEs in Polikovsky’s Database and USF-HD are collected by asking participants to pose intentionally instead of poses being elicited unconsciously. In addition, the sample size is insufficient in the York-DDT, which limits the more intensive implementation of an ME analysis. Considering the spontaneity of eliciting MEs, state-of-the-art databases collect ME samples induced in the laboratory, e.g., SMIC [
9], CASME [
10], CASME II [
11],
[
12] and SAMM [
13], which is a great improvement compared with the previous databases. Based on these datasets, many approaches have been devised to promote the development of MER systems. In preliminary studies, researchers usually use low-level features, e.g., Local Binary Pattern (LBP) [
14], optical flow [
15], gradient-based features [
3] and their variants to describe ME images. These features provide a form of visual clues to be extracted from the details of the image, such as intensity which changes either temporally or as a gradient. However, most of them lack the explicit semantic interpretation of ME itself and are overdependent on hand gestures. Therefore, recent studies focused on high-level features utilizing deep learning.
A high-level feature is the combination of multiple low-level features. It is semantically interpretable and has a more discriminative ability to represent MEs. Most of the-state-of-the-art high-level representations are extracted from CNN models. In some earlier studies [
16,
17,
18,
19], researchers mainly focused on spatial information, some of which provide clues based on ME frames and the others based on optical flow. Recent works attempted to encode both spatial and temporal information for a more comprehensive representation since facial movement variation is a dynamic process. Many deep-learning-based methods specialize in capturing dependencies in long sequences, e.g., 3D Convolutional Neural Networks (3D CNNs) [
20,
21], and Long Short-Term Memory Networks (LSTMs) [
22], which are employed to capture the motion of MEs. Nevertheless, MEs are reflected in the local area with a low intensity of muscle movements, resulting in the perception of motion variation being complex. To tackle this issue, a technique to magnify these subtle movements can be helpful to improve the performance of MER. The most commonly used magnification techniques, e.g., Eulerian Motion Magnification (EMM) [
23], Global Lagrangian Motion Magnification (GLMM) [
24], and Learning-based Video Motion Magnification (LVMM) [
25], have shown good performance in magnifying subtle movements. Inspired by this effect, many MER works introduced magnification techniques to magnifying ME intensity, and their results proved the effectiveness of ME magnification [
23,
24,
26,
27].
Despite these achievements, the following problem that occurs during magnification is rarely mentioned: the unified-magnification strategy, which is implemented by setting the same amplification factor for all ME samples, is not adaptable, since the intensity variation scope varies in different ME samples. For example, in some ME video clips, the intensity variation is more acute, so a small amplification factor may be adequate to magnify them. Conversely, in other clips, the variation is very subtle and requires larger amplification factors. An improper magnification level may introduce artefacts and even cause severe deformation, as shown in
Figure 1. Therefore, a method to effectively capture powerful motion representation while avoiding the deficiencies of magnification is required. Moreover, existing methods are limited due to imbalanced ME databases. For the minority classes, the model sees much fewer samples and thus tends to underfit these samples during training. This problem can impair the interpretation of unfamiliar ME samples.
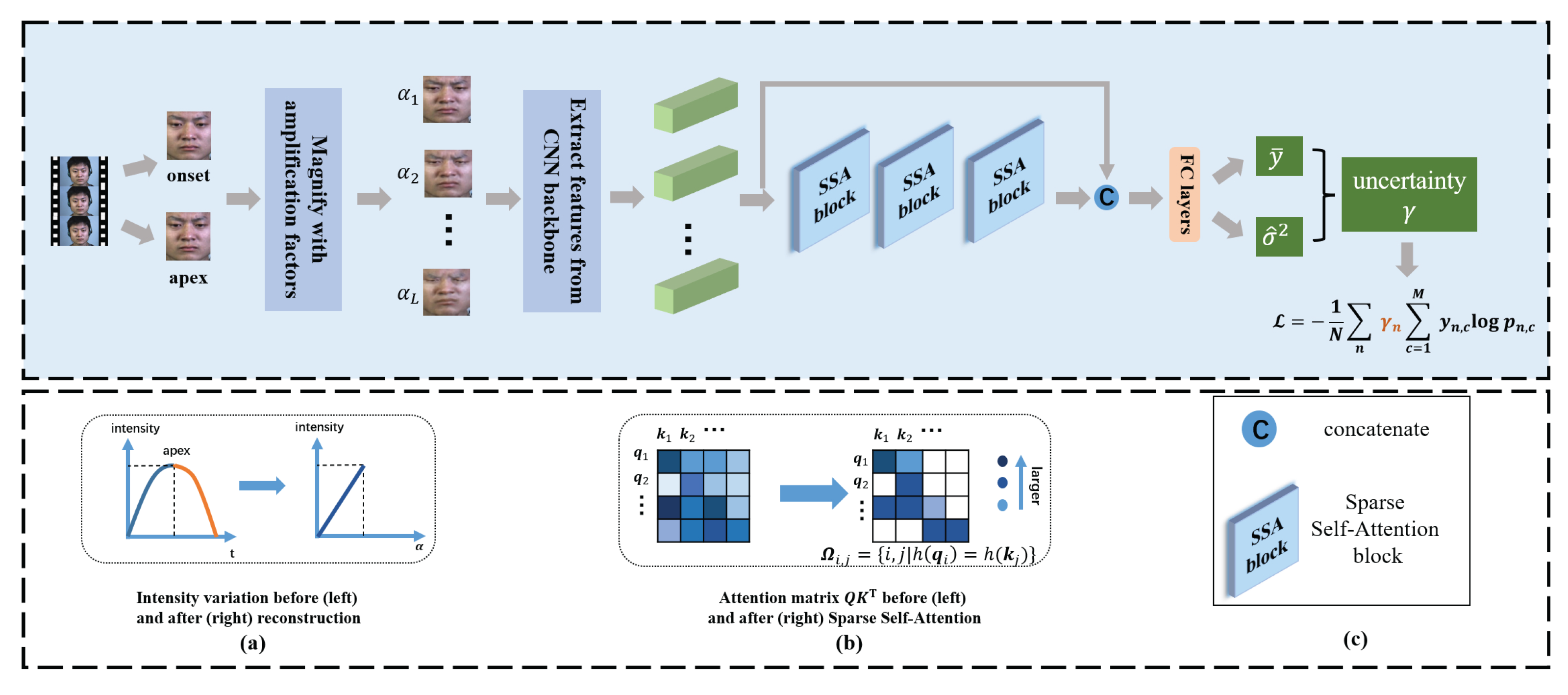
In this paper, we proposed a novel framework, namely an Uncertainty-Aware Magnification-Robust Network (UAMRN), to address the aforementioned problems. Specifically, in order to make the network perceive ME movements more easily, we used magnification techniques to rebuild a sequence with a more discriminative representation for motion. Afterwards, we imposed sparsity constraints via Locality Sensitive Hashing (LSH) into a self-attention block, adaptively reserving highly-correlated ME features and discarding the uncorrelated ones. The resultant sparsity of the self-attention feature retains the global modeling ability of the standard self-attention feature while mitigating magnification artefacts. On the other hand, to manage the imbalanced dataset issue, we utilized sample uncertainty information based on the Bayesian uncertainty measure to learn more generalizable features for rare classes.
This work is an extended version of our conference paper (part of this work is presented in ICPR2022). In addition, a more robust model with higher MER performance, enhanced by using uncertainty estimation to guide the training, is provided. The experiments were reimplemented to test the model, and the results are provided. The main contributions are summarized as follows:
A sequence more able to reflect ME movements was rebuilt via magnification techniques.
To preserve as many of the ME-related features as possible and suppress magnification noise, we proposed a sparse self-attention (SSA) block by enforcing sparsity in attention terms using Locality Sensitive Hashing (LSH).
To improve the recognition accuracy of rare classes, we estimated the uncertainty for each sample, where the samples from rare classes can be trained more carefully.
Extensive experiments conducted on three widely used databases demonstrate that our approach yields competitive results compared with state-of-the-art MER methods.
4. Experiments
4.1. Databases
We conducted experiments on three public ME datasets, i.e., CASME II [
11], SAMM [
13], and SMIC-HS [
9]. More details concerning these datasets are provided below.
CASME II contains 246 ME video clips elicited from 26 participants, recorded by a high-speed camera at 200 fps. The following five ME categories were selected for experimentation: happiness (32), disgust (63), repression (27), surprise (25) and other (99), where the number in the brackets denotes the number of samples in this class.
SAMM includes 159 ME samples from 32 participants of 13 ethnicities. The recording rate of the camera is 200 fps. We also selected five categories from this database, i.e., anger (57), happiness (26), contempt (12), surprise (15) and other (26).
SMIC-HS is the HS version of SMIC where the videos are recorded by a 100 fps high-speed camera. It collects 164 spontaneous MEs which are divided into the following classes: positive (51), negative (70), and surprise (43). We use all the samples in this dataset.
When we rebuild the new sequence using magnification, we need to know the indices of the apex and onset frame. The CASME II and SAMM provide the annotation of key frames while the SMIC-HS does not. Considering that our model does not require the accurate location of key frames as we can produce high intensity variation by applying a large amplification factor, we selected the middle frame as the apex.
4.2. Protocols
To evaluate the efficacy of the proposed method, we used the leave-one-subject-out (LOSO) cross-validation protocol, implemented by treating all samples from one subject as the test set while the remaining samples comprised the training set. The final recognition result is obtained by averaging all the subjects. The metrics of evaluation are the accuracy and F1-score, given as below:
where the accuracy assesses the overall recognition performance, with
T denoting the total number of correct predictions. F1-score evaluates the ability when managing the unbalanced database problem, where
and
are the precision and recall of the
c-th micro-expression, respectively.
4.3. Implementation Details
In each ME video clip, we first used [
39] to compute 68 facial landmarks of the onset, and then cropped the face area by these coordinates. The apex was cropped using the coordinates of the onset, aiming to ensure the two frames had no displacements caused by irrelevant factors. We resized all the images to
as the input.
Considering that a small ME dataset may result in overfitting, we used the first few layers of the pre-trained Resnet-18 [
40], pre-trained on the FER+ [
41] dataset, to extract shallow features of the magnified frames. These features were set as the input of the proposed framework. To encode position clues before SSA blocks, we adopted sine and cosine functions of different frequencies as follows:
,
, where
is the position in the sequence and
d is the specific dimension of
.
We trained the UAMRN at 40 epochs. For learning parameters, the decay rates for the 1st and 2nd moment estimates were 0.9 and 0.999, respectively, in the ADAM optimizer. The learning rate was set to
and reduced by
after every 10 epoch. Other detailed hyper-parameters are listed in
Table 1.
4.4. Experimental Results
In
Table 2,
Table 3 and
Table 4, we compare the performance of the UAMRN against other relelated MER works. The comparison is provided from two perspectives, i.e., a comparison against the methods using hand-crafted or learning based ME features, and against those methods with the aid of magnification techniques.
4.4.1. Comparison with Methods Using Hand-Crafted Features and Deep Models
It can be observed that when compared with other traditional and deep features, our method obtained the best overall performance. To be specific, UAMRN exceeded early hand-crafted works, e.g., LBP-SIP [
48], LBP-TOP + AdaBoost [
42], and STRBP [
43], by a large margin, which proves that deep models have more advantages in extracting ME features. Moreover, compared with most state-of-the-art learning based methods, e.g., TSCNN [
44], 3D-CNNs [
21], MERSiamC3D [
20], UAMRN also achieves better results. TSCNN surpasses our method in terms of F1-score by 4.68% and of accuracy by 0.4%, respectively, on the CASME II. According to the ablation experiments reported, in its model, the dynamic-temporal and static-spatial modules are two major parts contributing to recognizing MEs. Our method also focused on temporal and spatial clues, where the temporal clue was enhanced by magnifying intensity. Therefore, the performance of our model on the other two databases is much higher.
4.4.2. Comparison with Methods Magnifying ME Intensity
The proposed UAMRN obtained increases of 9.72% and 13.36% in the accuracy on the CASME II, compared with ME-Booster [
23] and HIGO + Mag [
26] which adopt Eulerian Motion Magnification (EMM) for magnification. Compared with the approaches using the same magnification techniques as ours, i.e., Graph-tcn [
25], and AU-GCN [
29], UAMRN also performs better. We speculate that its superiority lies in the innovative exertion of magnification, implemented by applying multiple AFs for the same subject instead of applying just one AF, which adds adaptability to the framework. In addition, it can be noticed that UAMRN exceeds most MER methods substantially in terms of the F1-score, indicating that our method has a better ability to manage the imbalanced dataset problem.
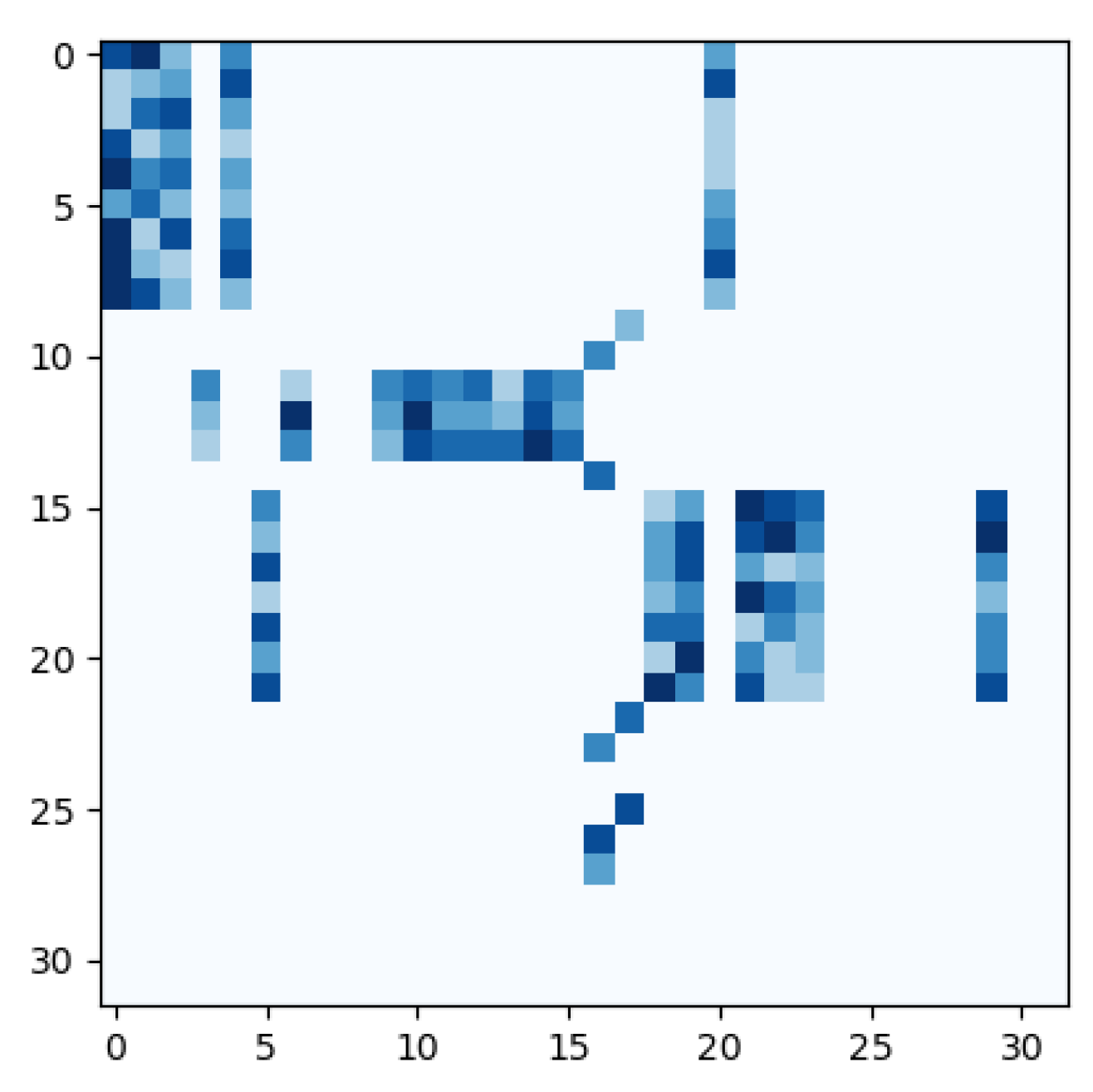
4.5. The Effectiveness of Locality Sensitive Hashing
In order to validate that the magnified images with excessive artefacts can be discarded through SSA blocks, we retrieved the feature vectors
and
and plotted the result
. Afterwards, we verified them with the frames from the rebuilt sequence. Large indexes of
and
denote features from magnified frames with large AFs, as shown in
Figure 4.
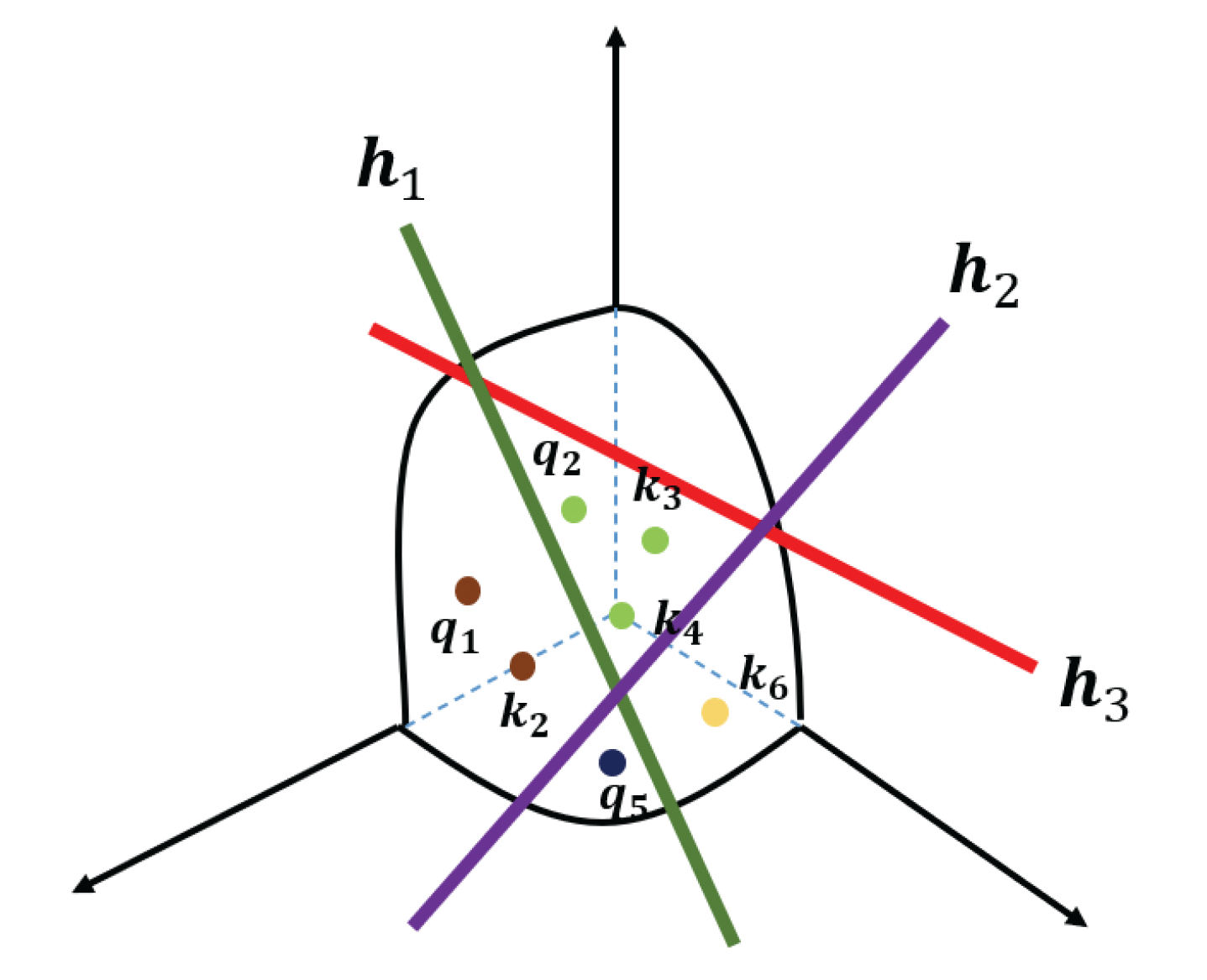
It can be observed that generally, non-zero elements are centred near the diagonal of the matrix, suggesting that adjacent frames tend to have a higher correlation than distant frames. Additionally, the majority of the lower right corner of the matrix, where the indexes of and are larger (corresponding to images with large AF), is filled with zero values, which validates the efficacy of LSH for removing distorted images. It can also be noted that some vectors sharing adjacent indexes were placed into different buckets, e.g., . We speculate the reason is that some vectors, even if they are close to one another, may fall into different buckets due to the randomness of the way that hyper-planes are partitioned. The impact of this problem can be counteracted by employing attention with multi-heads to extract multiple levels of information.










{kind=link}
{kind=link}
{kind=link}
{kind=link}