1. Introduction
There are 15 tribes in the family Cucurbitaceae [
1]. The tribe Cucurbitae, which has an almost completely American distribution, consists of 11 genera, including the genus
Cucurbita. The genus
Cucurbita (Cucurbitaceae) has five major domesticated species:
Cucurbita moschata,
Curcurbita pepo,
Cucurbita maxima,
Cucurbita argyrosperma, and
Cucurbita ficifolia [
2,
3].
The first three species cited are the most economically important as a popular food resource [
4]. The fruits of the species are incredibly diverse, differing greatly in shape, surface topography, color, size, and color pattern [
5]. Among them,
C. pepo is the genus’ most phenotypically variable species and has eight cultivar groups with edible fruits (groups) [
6]. The second most diversified species in the genus is thought to be
C. moschata [
7].
All Cucurbita species have 20 pairs of chromosomes
, making them all diploid. The theory that Cucurbiteae underwent one whole-genome duplication as a result of their high chromosome number has gained traction [
8,
9]. The tribe Cucurbiteae plant species, including the zucchini (
C. pepo), pumpkin (
C. moschata and
C. maxima), and silver-seed gourd (
C. argyrosperma), all suffered whole-genome duplication events, according to a number of studies [
9,
10,
11].
There are few estimates of genome size in the genus
Cucurbita. However, studies have shown relatively small genome sizes. The genome sizes of
C. maxima and
C. moschata were estimated to be
and
, respectively, [
9], while the genome size in
C. pepo was estimated to be
[
10]. Concerning the number of genes, the estimated values for
C. maxima,
C. moschata, and
C. pepo were
[
9]; and
genes [
10], respectively.
On the other hand, numerous models based on statistical physics consistently attempt to represent statistical features, such as long-range and short-range correlations, in light of the large DNA sequence data. Some approaches used statistical tools in connection with random-walk simulations [
12,
13,
14], wavelet transforms [
15,
16],
Ising models [
17] (see e.g., [
18] and references therein), and Tsallis’ statistics together with Machine Learning [
19]. Many live creatures’ coding and non-coding sequence length distributions have been studied by some models in relation to long- and short-range correlations [
20,
21,
22,
23]. Non-additive entropy-based statistical physics methods have recently been actively advocated for use in complex system research [
24,
25]. In this case, the Kaniadakis entropy yields a power-law distribution rather than an exponential one and depends on a free parameter (the
parameter) [
26,
27,
28]. The
-statistics arose as a useful statistical tool for many systems (see [
29] and references therein). For problems associated with human DNA, see e.g., [
30,
31].
Additionally, the Bayesian inference has been effectively applied as a useful tool to investigate a number of issues in physics [
32] and biophysics [
33]. Which DNA models should be valid from the perspective of Bayesian inference is an intriguing subject. Additionally, the challenge in the context of this work would be to investigate an expansion of a model from Ref. [
31], but this time in the context of other living structures, such as vegetables.
More recently in [
34], statistical models of the Tsallis type provided the distribution of nucleotide chain lengths, successfully capturing the statistical correlations between the parts of the plant (for both coding and non-coding) DNA strands for two species of the Cucurbitaceae family. We expand the paradigm proposed in [
31] in the context of vegetables in this article. We especially evaluate the distribution of nucleotide chain lengths measured in base pairs for
Cucurbita maxima,
Cucurbita moschata, and
Cucurbita pepo utilizing
-deformed statistics in light of the social and economic significance of cucurbits. The most practical model is then chosen using a Bayesian statistical analysis based on the
-distributions. To the best of our knowledge, this is the first time the size distribution of plant DNA has been realized using a
-statistical analysis.
2. Materials and Methods
We use the
-statistics, developed by Kaniadakis [
26,
27,
28], to analyze the correlations between the DNA length distributions of some species of the
Cucurbitaceae family. There are some works in this direction using the Tsallis
q-statistics [
34,
35,
36]. The
-entropy and power-law distribution functions naturally arise from the kinetic foundations of
-statistics. Formally, the
-framework is based on the
-exponential and
-logarithm functions (see Ref. [
26]), defined as
The parameter
is restricted to values belonging to the range
; for
, these expressions reduce to the usual exponential and logarithmic functions. From the optimization of entropy
(see Ref. [
37]),we can obtain the probability distributions (
) associated with the quantities of base pairs
for each of the chromosomes of
Cucurbita maxima,
Cucurbita moschata, and
Cucurbita pepo. Mathematically, the Kaniadakis entropy
is given by
The optimization process is well described in Refs. [
26,
37,
38,
39,
40,
41] and gives us
Rewriting (
4) with the explicit form of
given by (
1), and using constraints as in Ref. [
41], we get
Here, is an adjustable parameter that is related to the mean value of the length distribution, is the model’s free parameter which measures the interaction between the nucleotides in the sample, and l is the chain of nucleotides’ length, expressed in number of base pairs.
We employ the cumulative probability distribution because the probabilities for lengthy lengths l of the nucleotide chain are subject to significant fluctuations.
We employ the cumulative probability distribution because the probabilities for lengthy lengths l of the nucleotide chain are subject to significant fluctuations, (
5) can be found by solving
, which provides
where
Here,
denotes the probability of finding the sizes of the bases between 0 and
l. In Ref. [
34], it was proposed a comparison between the
q-exponential and a sum of
q-exponentials to explain the DNA length distribution of two species of cucurbits,
Cucumis melo and
Cucumis sativus. Based on this work, we propose an analysis of the same type but using the
-
. We assume that the sum of Kaniadakis-type generalized probabilities (already normalized) is given by
where
,
, and
are adjustable parameters and
l is the length of the nucleotides, respectively. By employing the identical steps as those leading to (
6), the cumulative probability distribution is found to be
where
Initial analyses indicate that, as occurred for the Tsallis’
q-statistics [
34], the
-exponential sum model best fits the DNA length distributions of the species studied here. Therefore, we chose to make a comparison between the sum of
-exponentials (
9) and the
-Maxwellian model (
11) below, proposed in [
31] to explain the length distribution of human DNA.
The best model to describe the length distributions of the nucleotides for three species of the
Cucurbitaceae family is obtained by comparing, via Bayesian analysis, the distributions
and
, which are represented by Equations (
9) and (
11), respectively.
3. Results
We use the public database of the National Center for Biotechnology Information (NCBI) [
42] and the Comparative Genomics (CoGe) [
43]. They are databases that give users access to genetic and biological data. In our analysis, we considered only the coding bases (exons). We define a nucleotide sequence’s length in terms of the
base pairs. All graphical and data modeling was written in R, a free statistical software [
44].
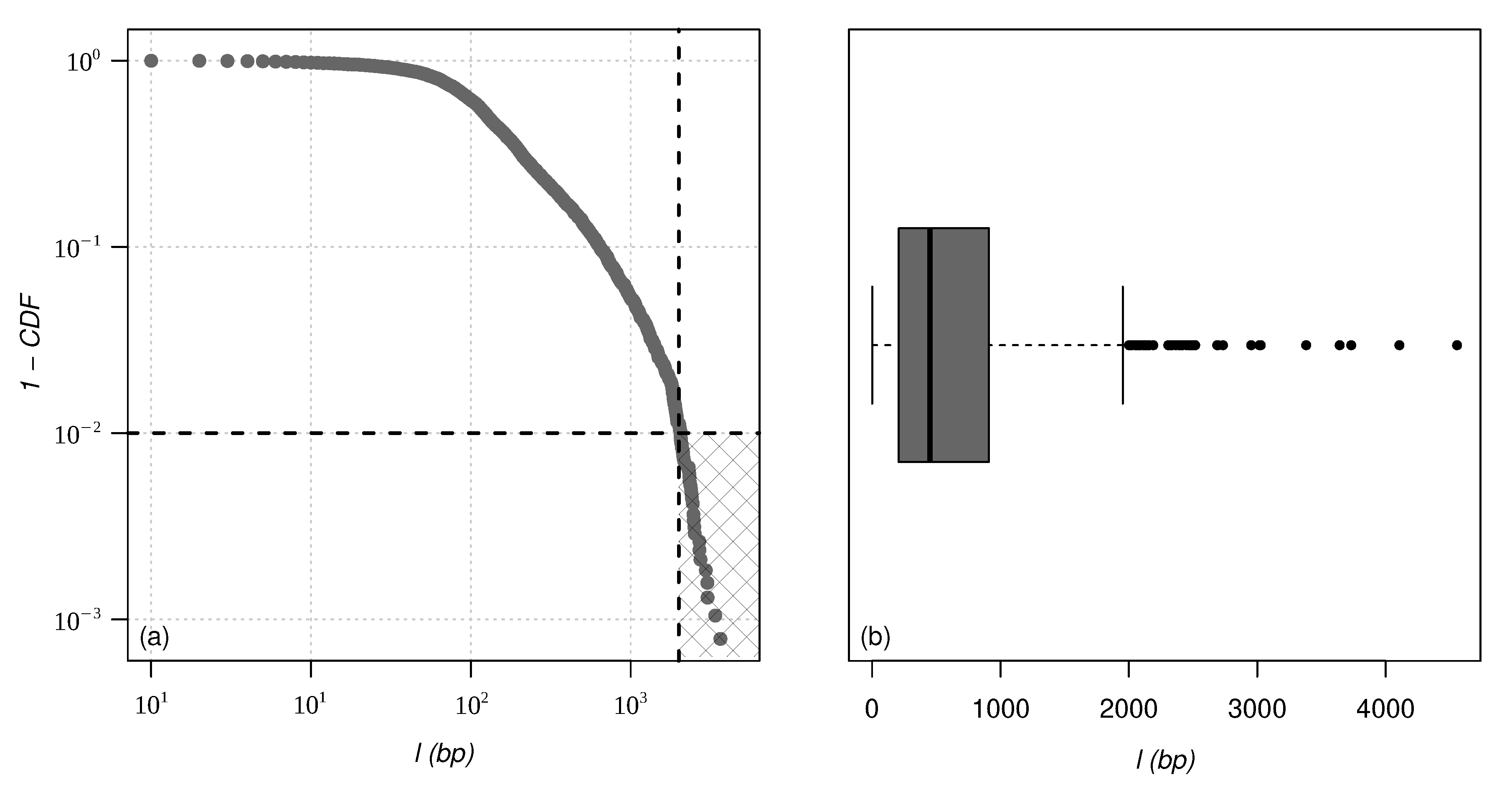
By plotting the cumulative probability distribution function (CDF) and a box plot for chromosome 02 of one of the species studied here (
Figure 1), we can see that some points are very far from the distribution and can be considered outliers. There are various techniques for defining, spotting, and dealing with outliers [
45]. In this work, we decided to use the box plot approach. Outliers in this approach are points that are below the region
and above
, where
,
, and
are first, second, and third quartile, respectively, and
is the interquartile region defined as
. To prevent these points from influencing the behavior of the proposed models, we decided to remove them. The cut was made around 1% of the cumulative distribution, designated by the hatched square in the lower right corner of
Figure 1a. A similar approach has been proposed in [
46] to analyze the length distribution of human DNA.
Table A1 describes the statistical characteristics of some chromosomes of the three species of
Cucurbitaceae after removing these outliers.
We decided to analyze the impact this action had on the value of
, taking into account the cumulative distribution functions (
9) and (
11). In
Table A2 and
Table A3, we have the number of nucleotides
and the best fit values per
. The subscripts 0 and
f represent the values before and after the outliers are removed, and
represents the relative difference between them. The values of
are smaller than the errors associated with the values of
in
Table A4,
Table A5 and
Table A6. This work deals with a statistical analysis of the distribution of DNA lengths in plants. Possible biological effects caused by removing nucleotides with large amounts of base pairs were not taken into account.
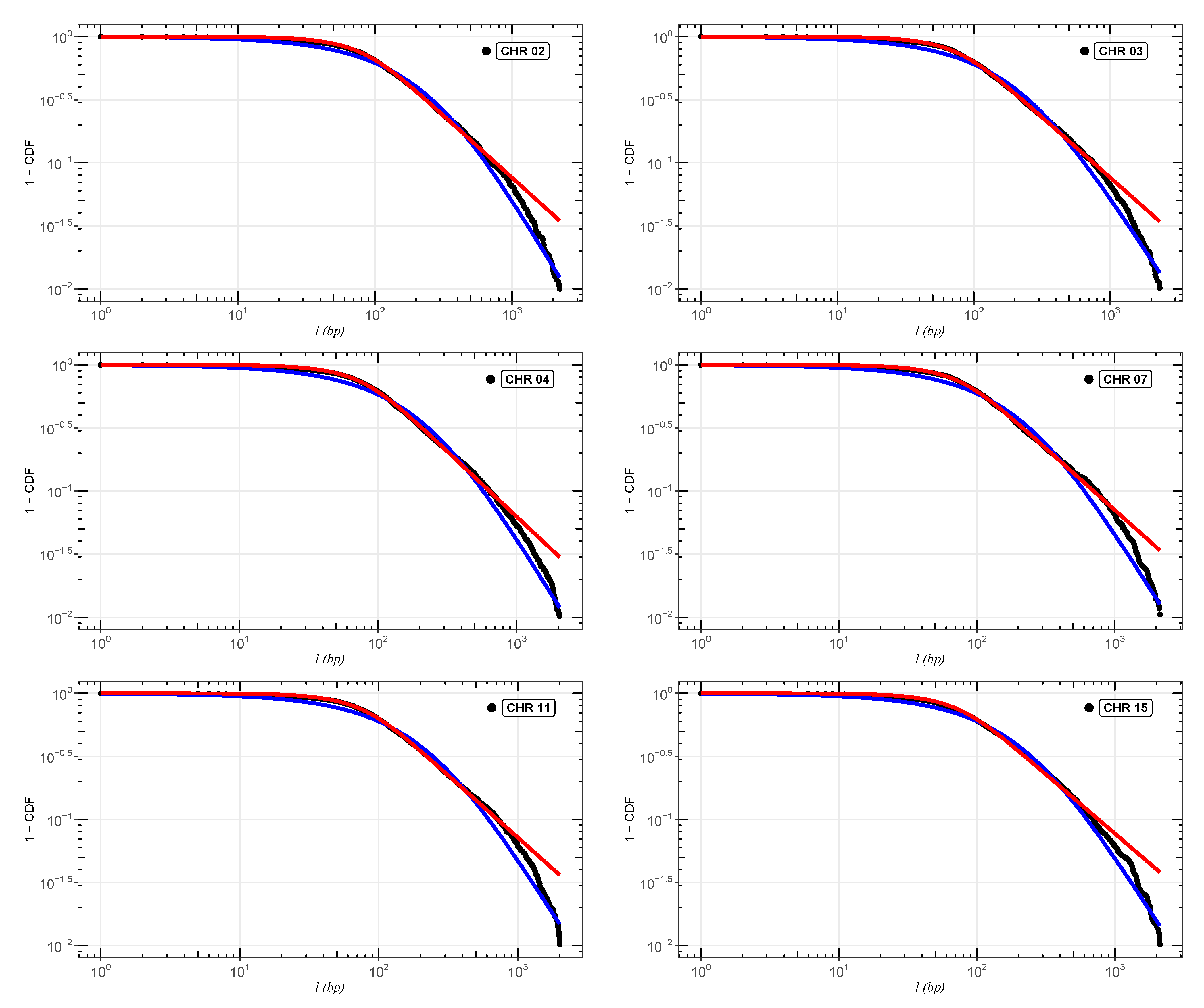
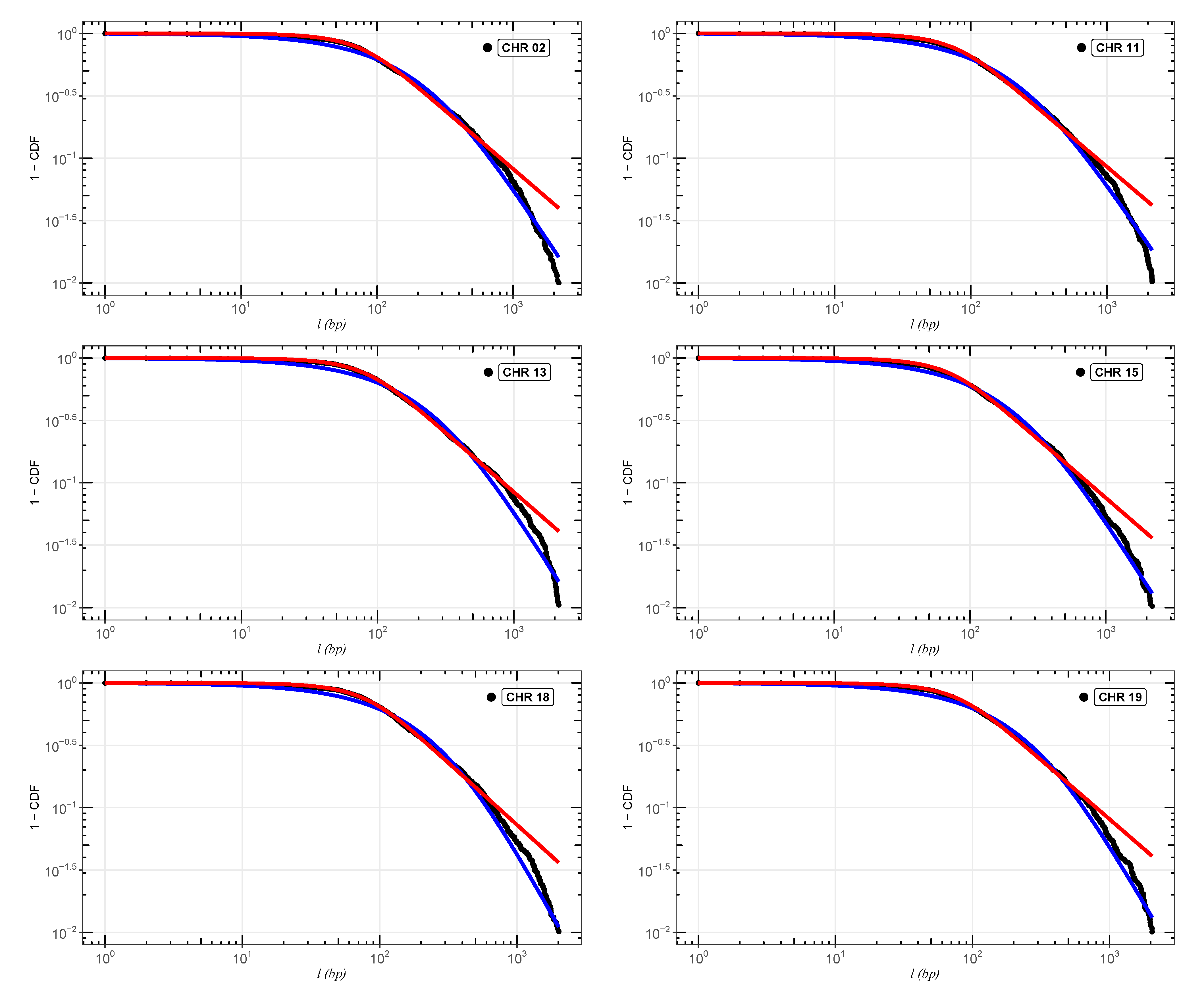
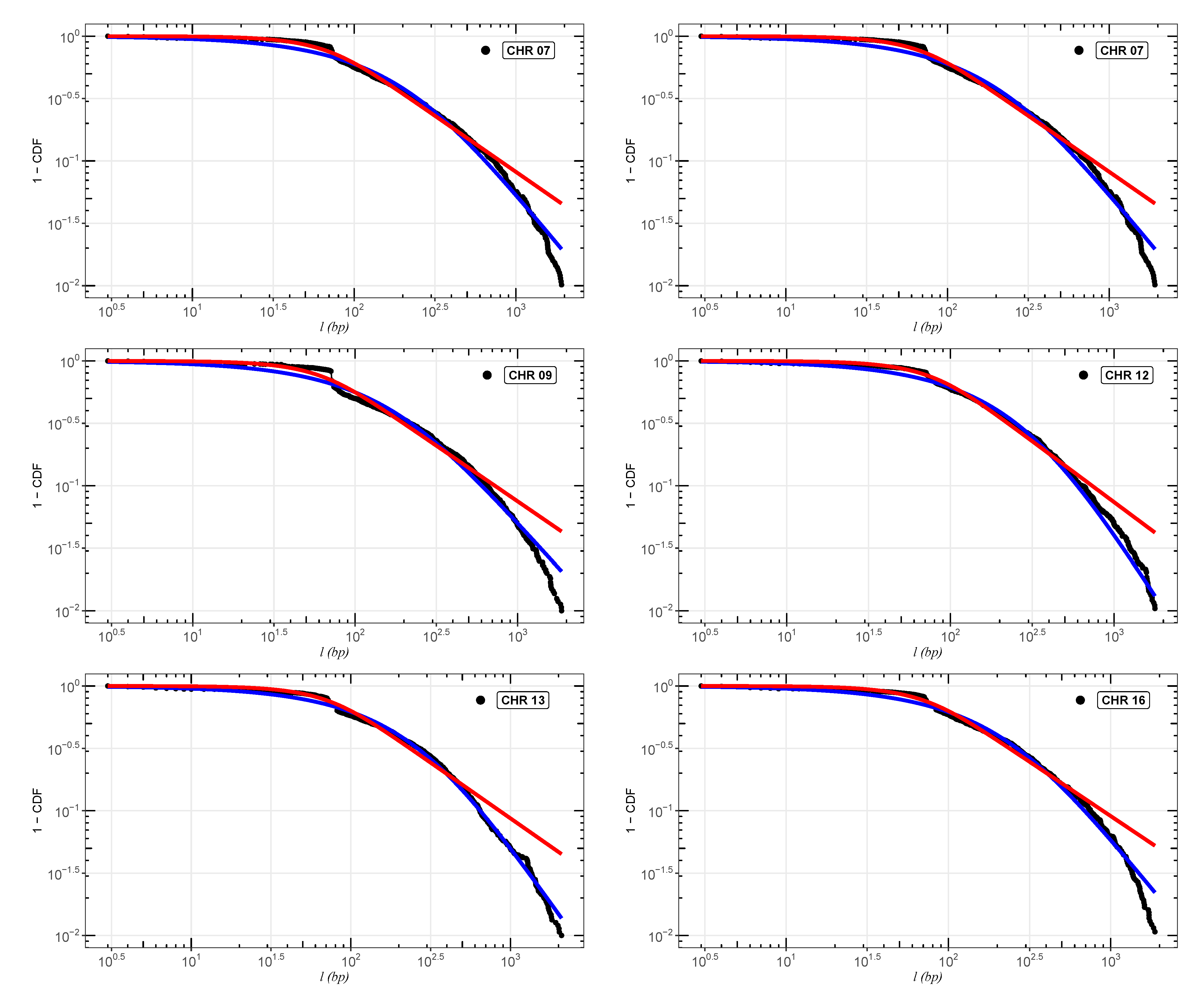
In
Figure 2,
Figure 3 and
Figure 4, we show the cumulative distributions, for exons, for some chromosomes of
Cucubita maxima,
Cucurbita moschata, and
Cucubita pepo, with the other chromosomes behaving similarly. To get the best fit values for
, the distribution functions (
9) and (
11) were fitted to the lengths (
l).
Table A4,
Table A5 and
Table A6 show all numerical results for the parameters
,
and
for distribution (
9) in addition to
and
for distribution (
11). Chromosome numbers are displayed in the first column (CHR), and the number of nucleotide chains is displayed in the second column (N) (exons). The correlations between the values of
l are measured by the values of
[
26,
27,
28,
39]. According to [
36,
47], the coding part of human DNA tends to present short-range correlations. The same behavior for plant DNA can be observed in [
34]. This implies
values close to zero. It is worth remembering that in the limit
, we return to the well-known Boltzmann–Gibbs–Shannon statistics [
26].
The models that fit the length distribution
the best are determined via Bayesian statistics. By taking into account the probability distribution of the hypotheses, conditioned on the evidence, Bayesian inference describes the relationship between the model and the data, and enables a rational and effective selection of one or more hypotheses [
48]. The Bayes’ theorem,
offers us the likelihood that, given the data
D, a posterior model
will be correct. For this, the probability of the prior model
is multiplied by the likelihood function
and divided by the Bayesian evidence
. Here, we assume the pattern
for the likelihood function, where
,
and
are the cumulative probabilities associated with the observed and the theoretical nucleotide lengths, and observed errors, respectively.
The input parameters used in the prior uniform distribution were obtained from the best fit found by the R-code. This approach, which defines the model parameters’ potential range and significantly affects the Bayesian evidence, is a crucial phase in the study. This condition ensures that the parameters will fall inside the previously identified optimal adjustment range.
In
Table A4, we have the parameter ranges for
Cucubita maxima. Considering all chromosomes (CHR),
,
, for cumulative distribution (
11), and
,
and
for cumulative distribution (
9). The process is repeated for the species
Cucubita moschata in
Table A5 and
Cucubita pepo in
Table A6. The MULTINEST algorithm, a Bayesian inference tool that computes the evidence
with an associated error estimate, is thus put into practice for each species and each model. It generates posterior samples from distributions that can contain multiple modes and pronounced degeneracy (curves) in high dimensions. More details can be seen in [
49,
50,
51,
52,
53].
In order to compare the models, we make use of the Bayes factor, which is given by
Here,
is the evidence of the base model, which is used as a reference. In our case, this is the distribution (
9), and
is the evidence of the model we want to compare, given by distribution (
11). We employ the Bayes factor interpretation provided by Jeffrey’s theory [
35,
54,
55,
56] to measure whether a model has favorable evidence in comparison to the base model.
Table A7 contains the findings for each chromosome.
The Bayesian analysis is performed from each model’s range of definite parameters. Therefore, the better we understand the behavior of the parameters, the more accurate our analysis will be, and we can guarantee that the evidence found will represent the curve with the best fit [
48]. In
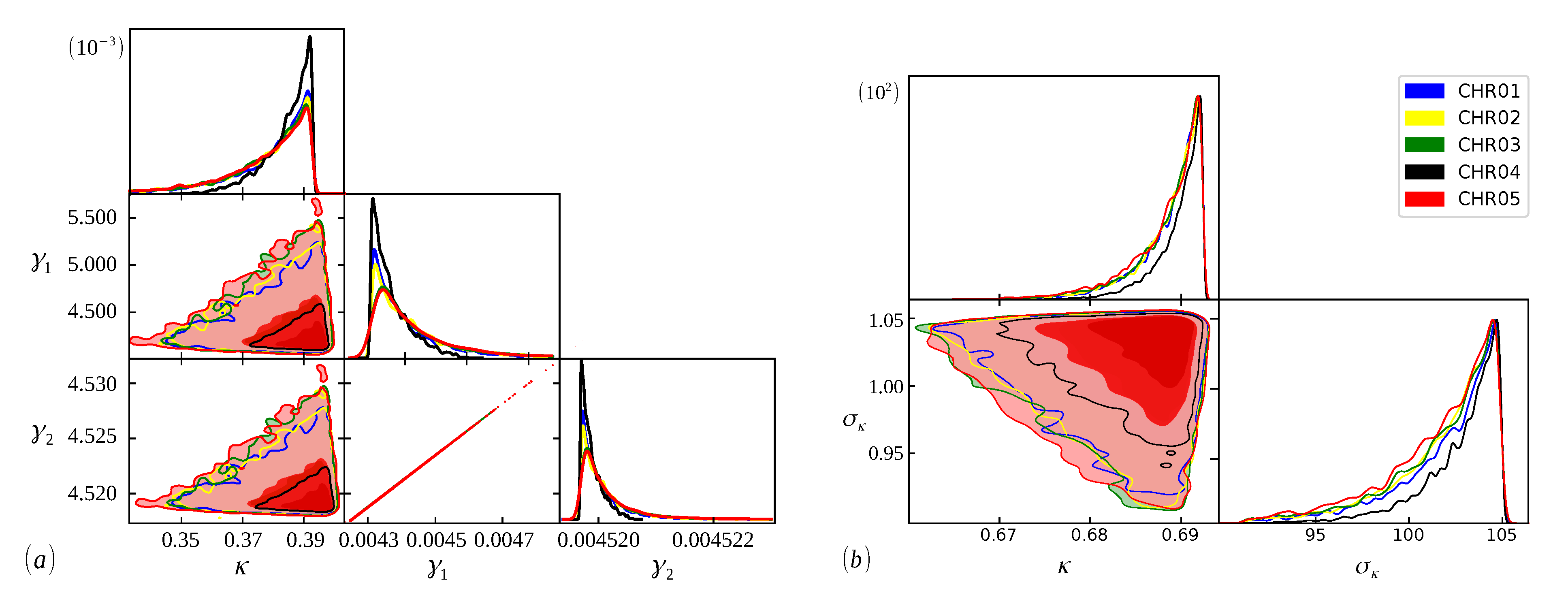
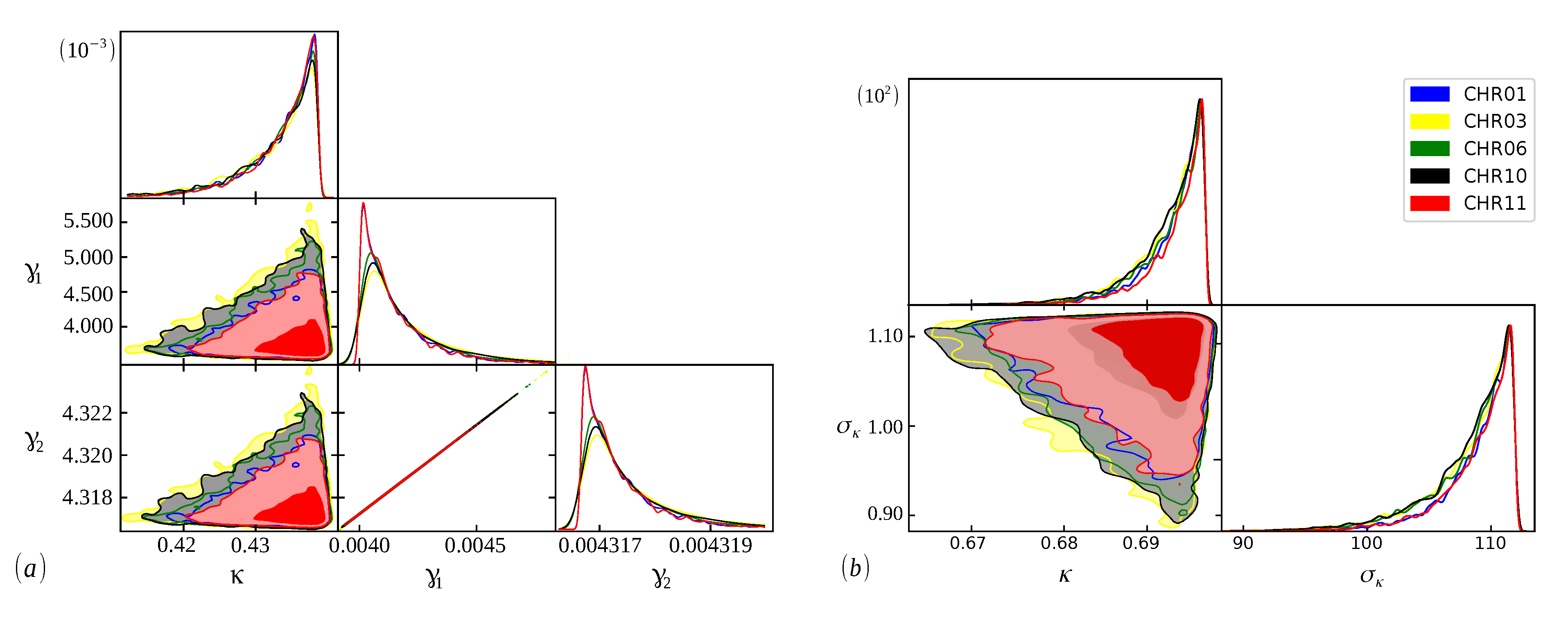
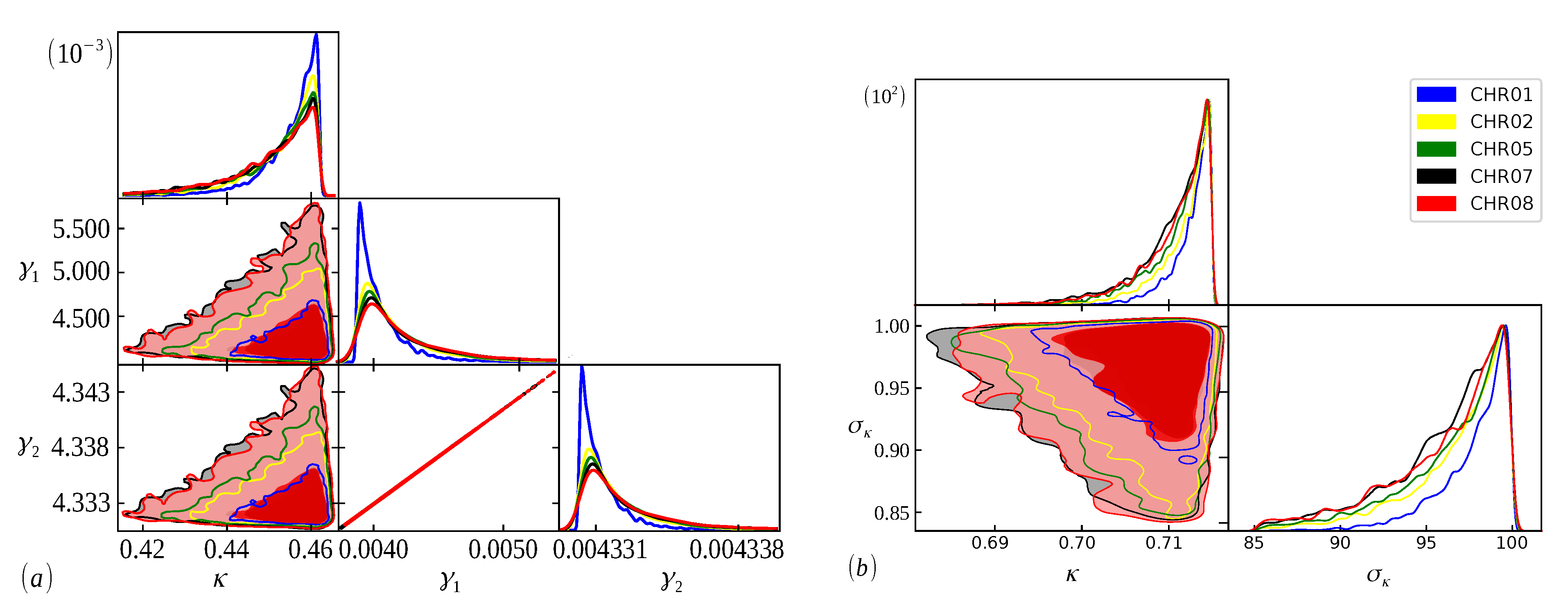
Figure 5,
Figure 6 and
Figure 7, we have scatter plots for the parameters of the models (
9) (a) and (
11) (b). For all chromosomes of all species analyzed here, we found strong correlations between the parameters
and
present in the distribution (
9). This was expected, as this model appears as a variation of the model (
6), as carried out in [
34]. These two adjustable constants together (
and
) have an inverse role to what
has in the distribution (
6), and when
, we obtain the model (
6) again. This implies that these parameters are related to the
parameter in the same way, resulting in similar images for scattering but with different ranges. This behavior was repeated for all chromosomes.
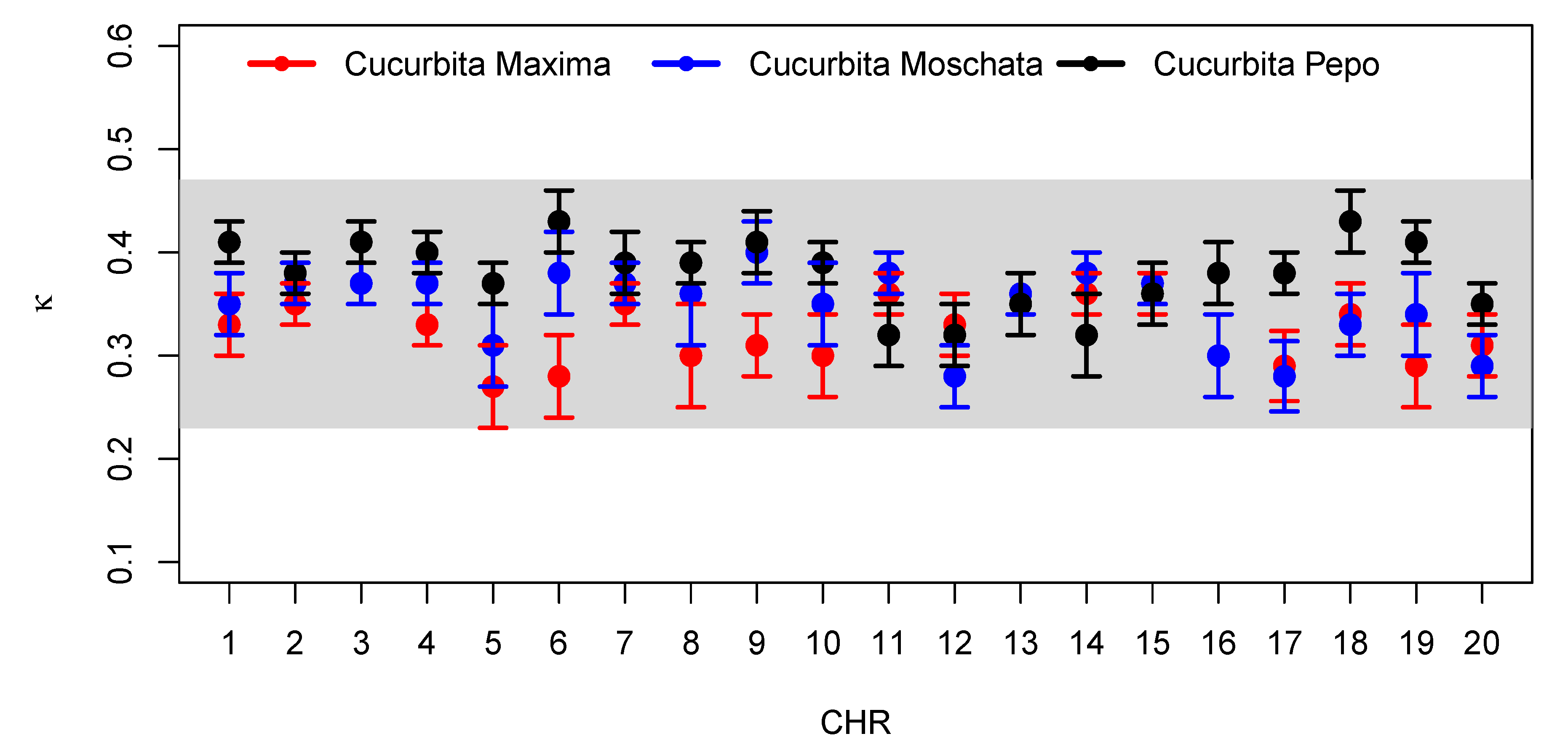
The
parameter (that is, the
value that provides the best fit, when using the sum of
-exponentials, Equation (
9)) in
Table A4,
Table A5 and
Table A6, measures the correlation between lengths
l, and belongs to the range
in the case of
Cucubita maxima,
for
Cucubita moschata, and
for
Cucubita pepo. It can be seen in
Figure 8 that the values of
, for different species, seem to specify a universal behavior. Therefore, all of these findings lead us to the conclusion that for all the species under study, the model (
9) (sum of
-exponentials) is strongly preferred over the distribution model (
11) (
-Maxwellian).
4. Conclusions
A statistical model based on non-additive statistics was developed to describe the size distribution of nucleotide chains in the DNA of species belonging to the
Cucurbitaceae family, namely
Cucurbita maxima,
Cucurbita moschata, and
Cucurbita pepo [
26,
27,
28,
31]. Specifically, the proposed distribution, Equation (
9), expands on a distribution studied in [
41] through the sum of the
-exponentials, which added the parameters
and
to capture the statistical correlations between the DNA strands. Another model investigated was the
-Maxwellian distribution, Equation (
11), proposed in [
31] for human DNA. We tested the statistical feasibility of models, as well as methods based on Bayesian statistical analysis using the NCBI project database. The cumulative distribution function (
9) best fitted the nucleotide base for all chromosomes, of the three species, with the parameter
belonging to the range
for
Cucurbita maxima,
for
Cucurbita moschata, and
in the case of
Cucurbita pepo. It can be seen in
Figure 8 that the values of
for different species of the coding parts (exons) of the DNA appear to be within a common and relatively narrow range.
Regarding the Bayesian analysis, we compared the
-exponential-sum distribution with the
-Maxwellian model. We demonstrated that the first has solid and favorable evidence compared to the
-Maxwellian distribution. This was reasonably expected given that the distribution (
9) has a free parameter for potential future adjustments. A general task should be to expand the model presented in this study to include additional species, determining whether they fall within the same range of
for exons
discovered for the species investigated here.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







