
Studying Asymmetric Structure in Directed Networks by Overlapping and Non-Overlapping Models


School of Mathematics, China University of Mining and Technology, Xuzhou 221116, China
Entropy 2022, 24(9), 1216; https://doi.org/10.3390/e24091216
Submission received: 4 July 2022
/
Revised: 25 August 2022
/
Accepted: 27 August 2022
/
Published: 30 August 2022
(This article belongs to the Topic Complex Systems and Network Science)
Abstract
:We consider the problem of modeling and estimating communities in directed networks. Models to this problem in the previous literature always assume that the sending clusters and the receiving clusters have non-overlapping property or overlapping property simultaneously. However, previous models cannot model the directed network in which nodes in sending clusters have overlapping property, while nodes in receiving clusters have non-overlapping property, especially for the case when the number of sending clusters is no larger than that of the receiving clusters. This kind of directed network exists in the real world for its randomness, and by the fact that we have little prior knowledge of the community structure for some real-world directed networks. To study the asymmetric structure for such directed networks, we propose a flexible and identifiable Overlapping and Non-overlapping model (ONM). We also provide one model as an extension of ONM to model the directed network, with a variation in node degree. Two spectral clustering algorithms are designed to fit the models. We establish a theoretical guarantee on the estimation consistency for the algorithms under the proposed models. A small scale computer-generated directed networks are designed and conducted to support our theoretical results. Four real-world directed networks are used to illustrate the algorithms, and the results reveal the existence of highly mixed nodes and the asymmetric structure for these networks.
1. Introduction
Community detection is a powerful tool in studying social networks with a latent structure of community [1,2,3,4]. The goal of community detection is to estimate a node’s community information from the network. In the study of social networks, various models have been proposed for community detection to model different networks with different community structures [5]. Due to the extremely intensive studies on community detection, we only focus on identifiable models that are closely relevant to our study in this paper.
The Stochastic Blockmodel (SBM) [6] is a classical and widely used model for an undirected network. SBM assumes that the probability of an edge between two nodes only depends on the clusters they belong to, and this assumption is not realistic because nodes have various degrees in real-world networks. To model real-world un-directed networks in which nodes degrees vary, the Degree-Corrected Stochastic Blockmodel (DCSBM) [7] extends SBM by introducing degree heterogeneities. Under SBM and DCSBM, all nodes are pure, such that each node only belongs to one community. However, in real cases, some nodes may belong to multiple communities, and such nodes have overlapping (also known as mixed membership) property. To model undirected networks in which nodes have an overlapping property, Ref. [8] designs the Mixed Membership Stochastic Blockmodel (MMSB). Ref. [9] introduces the Degree-Corrected Mixed Membership model (DCMM), which extends MMSB by considering degree heterogeneities. Ref. [10] designs the Overlapping Continuous Community Assignment model (OCCAM), which equals DCMM actually. Spectral methods with consistent estimations under the above models are provided in [9,11,12,13,14,15,16,17].
For directed networks in which all nodes have a non-overlapping property, Ref. [18] proposes a model called Stochastic co-Blockmodel, (ScBM) and its extension, the Degree-Corrected Stochastic co-Blockmodel (DCScBM), by considering the degree heterogeneity, where ScBM (DCScBM) is an extension of SBM (DCSBM) from an un-directed network to a directed network. ScBM and DCScBM can model non-overlapping directed networks in which row nodes belong to sending clusters (we also use community to denote cluster occasionally) and column nodes belong to receiving clusters, where row nodes can differ from column nodes, and can differ from . Ref. [19] studies the consistency of some adjacency-based spectral algorithms under ScBM. Ref. [20] studies the consistency of the spectral method D-SCORE under DCScBM when . Ref. [21] designs the Directed Mixed Membership Stochastic Blockmodel (DiMMSB) as an extension of ScBM and MMSB to model directed networks in which all nodes have overlapping property. Meanwhile, DiMMSB can also be seen as an extension of the two-way blockmodels with a Bernoulli distribution of [22]. All of the above models are identifiable under certain conditions. The identifiability of ScBM and DCScBM holds even for the case when . DiMMSB is identifiable only when . Sure, SBM, DCSBM, MMSB, DCMM, and OCCAM are identifiable when , since they model undirected networks. For all the above models, row nodes and column nodes have symmetric structural information such that they always have non-overlapping property or overlapping property simultaneously. As shown by the identifiability of DiMMSB, to model a directed network in which all nodes have overlapping property, the identifiability of the model requires . Naturally, there is a bridge model from ScBM to DiMMSB such that the bride model can model a directed network in which the row nodes and column nodes have asymmetric structural information such that they have different overlapping property. In this paper, we introduce this model and name it the Overlapping and Non-overlapping model.
Our contributions in this paper are as follows. We propose an identifiable model for directed networks, the Overlapping and Non-overlapping model (ONM for short). ONM allows that nodes in a directed network can have different overlapping properties. Without a loss of generality, in a directed network, we let the row nodes have overlapping property while the column nodes do not. The proposed model is identifiable when . Recall that the identifiability of ScBM modeling non-overlapping directed networks holds even for the case , and that DiMMSB modeling overlapping directed networks is identifiable only when , this is the reason for why we call ONM modeling directed networks, in which row nodes have different overlapping properties to column nodes, as a bridge model from ScBM to DiMMSB. We also propose an identifiable model, Overlapping and Degree-Corrected Non-overlapping model (ODCNM), as an extension of ONM, by considering the degree heterogeneity. We construct two spectral algorithms to fit ONM and ODCNM. We show that our methods enjoy consistent estimations under mild conditions. Especially, our theoretical results under ODCNM match those under ONM when ODCNM reduces to ONM. The numerical results of simulated directed networks generated under ONM and ODCNM support our theoretical findings, and the results on four real-world directed networks demonstrate the advantages of our algorithms in studying the asymmetric structure between the sending and receiving clusters.
Notations. We take the following general notations in this paper. For any positive integer m, let , and let denote the identity matrix. For a vector x and fixed , denotes its -norm. For a matrix M, denotes the transpose of the matrix M, denotes the spectral norm, denotes the Frobenius norm, and denotes the maximum -norm of all the rows of M. Let be the i-th largest singular value of matrix M, and let denote the i-th largest eigenvalue of the matrix M ordered by the magnitude. and denote the i-th row and the j-th column of matrix M, respectively. and denote the rows and columns in the index sets and of matrix M, respectively. For any matrix M, we simply use to represent for any . For any matrix , let be the diagonal matrix whose i-th diagonal entry is , and let be M’s rank. is a column vector with all entries being the value 1. is a column vector whose i-th entry is 1, while other entries are zero. In this paper, C is a positive constant which may occasionally be different.
2. The Overlapping and Non-Overlapping Model
Consider a directed network , where is the set of row nodes, is the set of column nodes, and E is the set of edges from the row nodes to the column nodes. Note that since the row nodes can be different from the column nodes, we may have (i.e., there are no common nodes between and ), and may not be equal to (i.e., the row nodes are different from the column nodes), which is a more general case than (i.e., all row nodes are same as column nodes), where ⌀ denotes the null set, and such a directed network is also known as a bipartite graph (or bipartite network) in [18,19]. In this paper, we use the subscript r and c to distinguish the terms for the row nodes and column nodes, where works in [18,19,23,24,25,26] also consider the general bipartite setting, such that the row nodes may differ from the column nodes. Let be the bi-adjacency matrix of directed network , such that if there is a directional edge from row node to column node , and otherwise. For convenience, we call the community that the row nodes belong to as the row community (or sending cluster occasionally), and the community that the column nodes belong to as the column community (or receiving cluster occasionally).
We propose a new blockmodel which we call the Overlapping and Non-overlapping model (ONM for short). ONM can model directed networks whose row nodes belong to overlapping row communities, while the column nodes belong to non-overlapping column communities. For row nodes, let be the membership matrix, such that
Call row node pure if degenerates (i.e., one entry is 1, all others entries are 0), and mixed otherwise. From such a definition, row node has mixed membership and may belong to more than one row communities for .
For column nodes, let ℓ be the vector whose -th entry if column node belongs to the k-th column community, and takes value from for . Let be the membership matrix of column nodes, such that for ,
From such a definition, column node belongs to exactly one of the column communities for . Sure, all of the column nodes are pure nodes.
In this paper, we assume that
Equation (3) is required for the identifiability of ONM. Let be the probability matrix, such that
where controls the network sparsity and is called the sparsity parameter in this paper. For convenience, set , where for , and for model identifiability. For all pairs of with , our model assumes that are independent Bernoulli random variables satisfying
where , and we call it the population adjacency matrix in this paper.
Definition 1.
Remark 1.
Under , for , since , we see that increasing ρ increases the probability to generate an edge from row node to column node , i.e., the sparsity of the network is governed by ρ.
The following conditions are sufficient for the identifiability of ONM:
- (I1) , and .
- (I2) There is at least one pure row node for each of the row communities.
For , let . By condition (I2), is non-empty for all . For , select one row node from to construct the index set ; i.e., is the indices of row nodes corresponding to pure row nodes, one from each row community. Without loss of generality, let (Lemma 2.1 [17] also has a similar setting to design their spectral algorithm under MMSB). is defined similarly for the column nodes, such that . The next proposition guarantees the identifiability of ONM.
Proposition 1.
If conditions (I1) and (I2) hold, ONM is identifiable: For eligible and , if , then , and .
All proofs of propositions, lemmas, and theorems are provided in Appendix B and Appendix C of this paper. Compared to some previous models, ONM models different directed networks.
- When the row nodes are the same as the column nodes, , and all nodes are pure, ONM degenerates to SBM. However, ONM can model directed networks where row nodes enjoy mixed memberships, while SBM only models un-directed networks.
- When all row nodes are pure, our ONM reduces to ScBM with row clusters and column clusters [18]. However, ONM allows for row nodes to have overlapping memberships, while ScBM does not. Meanwhile, for model identifiability, ScBM does not require that ONM requires, and this can be seen as the cost of ONM when modeling the overlapping row nodes.
- Though DiMMSB [21] can model directed networks whose row and column nodes have overlapping memberships, DiMMSB requires for model identifiability. For comparison, our ONM allows at the cost of losing the overlapping property of the column nodes.
2.1. A Spectral Algorithm for Fitting ONM
The primary goal of the proposed algorithm is to estimate the row membership matrix and the column membership matrix from the observed adjacency matrix A with a given and . We now discuss our intuition for the design of our algorithm to fit ONM.
Under conditions (I1) and (I2), by basic algebra, we have . Let be the compact singular value decomposition of , where , , and is a identity matrix. Let be the size of the k-th column community for . Let and . Meanwhile, without causing confusion, let be the -th largest size among all column communities. The following lemma guarantees that enjoys an ideal simplex structure and has distinct rows.
Lemma 1.
Under, there exists a uniquematrixand a uniquematrix, such that
- , where . Meanwhile, when for .
- . Meanwhile,whenfor, i.e.,hasdistinct rows. Furthermore, when, we havefor all.
Lemma 1 says that the rows of form a -simplex in , which we call the Ideal Simplex (IS), with the rows of being the vertices. This IS is also found in [9,17,21]. Meanwhile, Lemma 1 says that has distinct rows, and if two column nodes and are from the same column community, then .
Under ONM, to recover from , since has distinct rows, applying the k-means algorithm on all rows of returns true column communities by Lemma 1. Since has distinct rows, we can set to measure the minimum center separation of . By Lemma 1, when under . However, when , it is a challenge to obtain a positive lower bound of ; see the proof of Lemma 1 for details.
Under ONM, to recover from , since is full rank, if and are known in advance ideally, we can exactly recover by setting via Lemma 1. Set . Since and for , we have
With a given , since it enjoys IS structure , as long as we can obtain the row corner matrix (i.e., ), we can recover exactly. As mentioned in [9,17,21], for such an ideal simplex, the successive projection (SP) algorithm [27] (for details of SP, see Algorithm A1) can be applied to with row communities to find .
Based on the above analysis, we are now ready to give the following algorithm which we call Ideal ONA. Input , and with . Outputs: and ℓ.
- Let be the compact SVD of , such that .
- For the row nodes,
- -
- Run the SP algorithm on all rows of , assuming there are row communities to obtain . Set .
- -
- Set . Recover by setting for .
For the column nodes,- -
- Run k-means on assuming that there are column communities, i.e., find the solution to the following optimization problemwhere denotes the set of matrices with only different rows.
- -
- Use to obtain the labels vector ℓ of the column nodes. Note that since has distinct rows, two different column nodes, , are in the same column community if .
Following a similar proof of Theorem 1 of [21], the Ideal ONA exactly recovers row nodes memberships and column nodes labels, and this also verifies the identifiability of ONM in turn. For convenience, call the two steps for column nodes “run k-means on assuming there are column communities to obtain ℓ”.
We now extend the ideal case to the real case. Set be the top--dimensional SVD of A, such that , and contains the top singular values of A. For the real case, we use given in Algorithm 1 to estimate , respectively. Algorithm 1, called the Overlapping and Non-overlapping algorithm (ONA for short), is a natural extension of the Ideal ONA to the real case. In ONA, we set the negative entries of as 0 by setting , for the reason that the weights for any row node should be non-negative while there may exist some negative entries of . Note that in a directed network, if the column nodes have an overlapping property while row nodes do not, to perform community detection for such a directed network, the transpose of the adjacency matrix should be set as input when applying our algorithm.
| Algorithm 1Overlapping and Non-overlapping Algorithm (ONA) |
|
For column nodes: run k-means on assuming there are column communities to obtain . |
2.2. Main Results for ONA
In this section, we show the consistency of our algorithm for fitting the ONM as the number of row nodes and the number of column nodes increases. Throughout this paper, and are two known integers. First, we assume that:
Assumption 1.
.
Assumption 1 controls the sparsity of the directed network considered for theoretical study. When building an estimation consistency of the spectral clustering methods in community detection, the sparsity assumption is common; see [13,14,17,18,20,21]. Especially, when ONM reduces to SBM, the sparsity requirement in Assumption 1 is consistent with that of Theorem 3.1 in [13], which guarantees the theoretical optimality on the sparsity condition of this paper. To measure the performance of ONA for row nodes memberships, since row nodes have mixed memberships, naturally, we use the norm difference between and . Since the column nodes are all pure nodes, we consider the performance criterion defined in [15] to measure the estimation error of ONA on the column nodes. We introduce this measurement of estimation error below.
Let be the true partition of column nodes obtained from ℓ, such that for . Let be the estimated partition of column nodes obtained from of ONA, such that for . The criterion is defined as
where is the set of all permutations of , and the superscript c denotes the complementary set. As mentioned in [15], measures the maximum proportion of column nodes in the symmetric difference of and .
The next theorem gives the theoretical bounds on the estimations of memberships for both the row and column nodes, which is the main theoretical result for ONA.
Theorem 1.
Under , when Assumption 1 holds, suppose that , with a probability of at least for any ,
- For row nodes, there exists a permutation matrix such thatwhere is the row-wise singular eigenvector error.
- For column nodes, . Especially, when ,
Adding conditions similar to Corollary 3.1 in [17], we have the following corollary.
Corollary 1.
Under , suppose conditions in Theorem 1 hold, and further, suppose that , with a probability of at least ,
- For row nodes, when ,
- For column nodes, . When ,
Especially, when, and,
- For row nodes, when ,
- For column nodes, . When ,
When in Corollary 1, the bounds for the row and column nodes are and , respectively, and we see that ONA yields a stable and consistent community detection for both the row and column nodes, since the error rates go to zero as when is fixed. Especially, for the row nodes with mixed memberships, when the DCMM proposed in [9] reduces to MMSB and , the error bound of the Mixed-SCORE in Theorem 2.2 of [9] is also , which guarantees the theoretical optimality of our analysis for the row nodes. For the column nodes, when every column community enjoys similar sizes and , our bound matches Corollary 3.2 in [13] up to a logarithmic factor, which guarantees the theoretical optimality of our analysis for column nodes. Furthermore, the optimality of our requirement on network sparsity and the theoretical upper bounds of ONA’s error rates is also supported by using the separation condition and sharp threshold criterion developed in [28].
3. The Overlapping and Degree-Corrected Non-Overlapping Model
In this section, we propose an extension of ONM by considering the degree heterogeneity, and we build theoretical guarantees for algorithm fitting our model.
Let be an vector whose -th entry is the degree heterogeneity of column node , for . Let be an diagonal matrix whose -th diagonal element is . For , the extended model for generating A is:
Definition 2.
Note that, under ODCNM, the maximum element of P can be larger than 1, since also controls the sparsity of directed network . The following proposition guarantees that ODCNM is identifiable in terms of , and , and such identifiability is similar to that of DCSBM.
Proposition 2.
If conditions (I1) and (I2) hold, ODCNM is identifiable for the membership matrices: For eligible and , if , then and .
Remark 2.
By setting for , ODCNM reduces to ONM, and this is the reason for why ODCNM can be seen as an extension of ONM. Meanwhile, though DCScBM [18] can model directed networks with degree heterogeneities for both row and column nodes, DCScBM does not allow the overlapping property for row nodes. For comparison, our ODCNM allows row nodes to have an overlapping property at the cost of losing the degree heterogeneities and requiring for model identifiability.
3.1. A Spectral Algorithm for Fitting ODCNM
We now discuss our intuition for the design of our algorithm to fit ODCNM. Without causing confusion, we also use under ODCNM. Let be the row-normalized version of , such that for . Then, clustering the rows of using the k-means algorithm can return perfect clustering for column nodes, and this is guaranteed by the following lemma.
Lemma 2.
Under , there exists a unique matrix and a unique matrix , such that
- , where . Meanwhile, when for .
- . Meanwhile, when for . Furthermore, when , we have for all .
Recall that we set by Lemma 2; when under . However, when , it is a challenge to obtain a positive lower bound of ; see the proof of Lemma 2 for details.
Under ODCNM, to recover from , since has distinct rows, applying the k-means algorithm on all rows of returns true column communities by Lemma 2. To recover from , the same idea as that of under ONM can be followed.
Based on the above analysis, we are now ready to present the following algorithm, which we call Ideal ODCNA. Input with . Output: and ℓ.
- Let be the compact SVD of , such that . Let be the row-normalization of .
- For row nodes, they are the same as that of Ideal ONA.For column nodes: run k-means on assuming there are column communities to obtain ℓ.
We now extend the ideal case to the real case. Let be the row-normalized version of , such that for . The Overlapping and Degree-Corrected Non-overlapping Algorithm (ODCNA for short) is a natural extension of the Ideal ODCNA to the real case, where all steps of ODCNA are the same as ONA except for those for column nodes. ODCNA applies k-means on to obtain .
3.2. Main Results for ODCNA
Set , and . Assume that
Assumption 2.
.
The next theorem is the main theoretical result for ODCNA, where we also use the same measurements as ONA to measure the performances of ODCNA.
Theorem 2.
Under , when Assumption 2 holds, suppose , with a probability at least ,
- For the row nodes,
- For the column nodes,where is a parameter defined in the proof of this theorem, and it is 1 when . Especially, when ,
Adding some conditions on model parameters, we have the following corollary.
Corollary 2.
Under , suppose that conditions in Theorem 2 hold, and further, suppose that , with a probability of at least ,
- For row nodes, when ,
- For column nodes, . When ,
Especially, whenand,
- For row nodes, when ,
- For column nodes,. When ,
If we further set and , we have the below corollary.
Corollary 3.
Under , suppose that the conditions in Theorem 2 hold, and further, suppose that and , with a probability of at least ,
- For row nodes, when ,
- For column nodes, . When ,
Especially, whenand,
- For row nodes, when ,
- For column nodes,. When ,
By setting , ODCNM degenerates to ONM. By comparing Corollaries 1 and 3, we see that theoretical results under ODCNM are consistent with those under ONM when ODCNM degenerates to ONM for the case where .
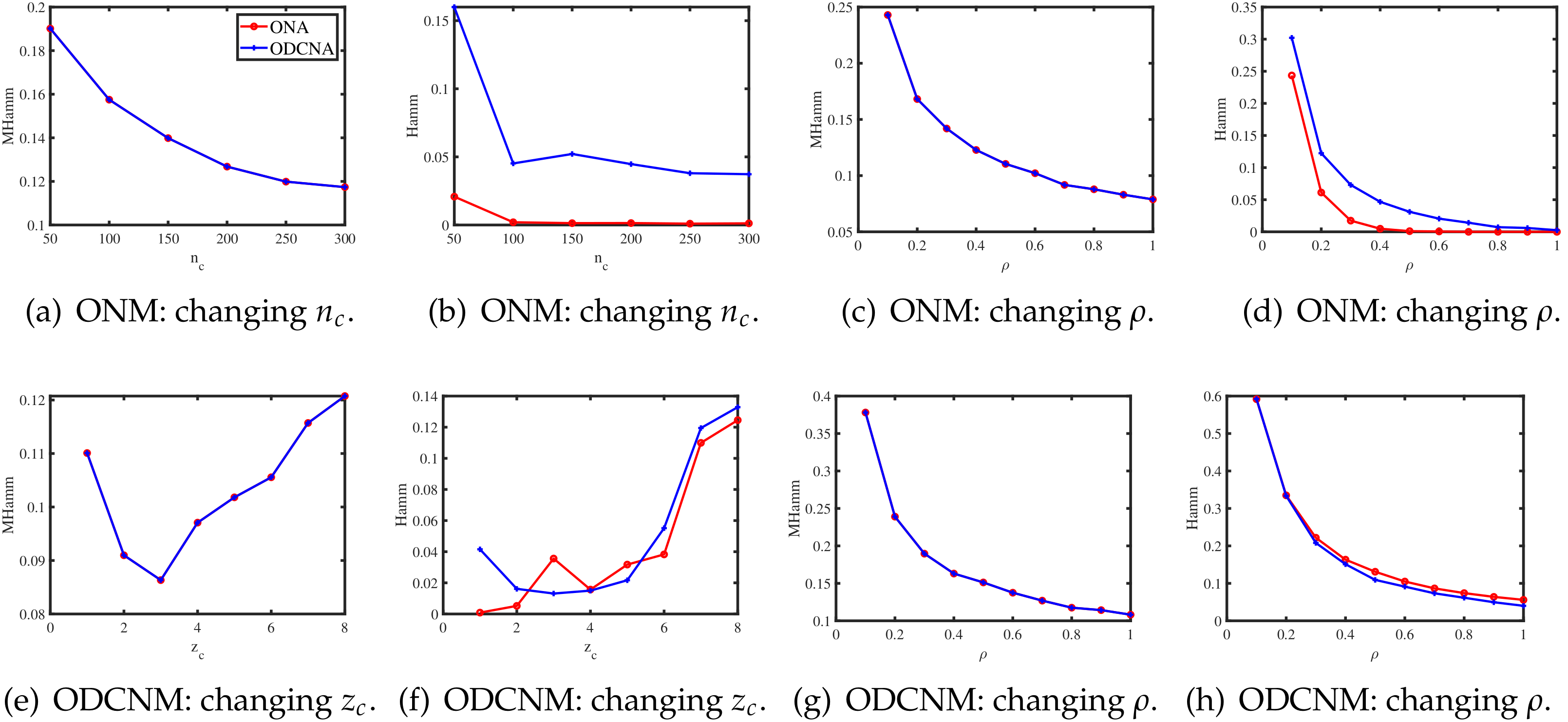
4. Simulations
In this section, we present some simulations to investigate the performances of the two proposed algorithms. We measure their performances using the Mixed-Hamming error rate (MHamm for short) for row nodes, and the Hamming error rate (Hamm for short) for the column nodes defined below
where is the set of all permutations of , is the set of all permutations of ; is defined as if , and 0 otherwise for .
For all simulations in this section, the parameters are set as below. Unless specified, set . For the column nodes, generate by setting each column node belonging to one of the column communities with equal probability. Let each row community have 100 pure nodes, and let all the mixed row nodes have memberships . is set independently under ONM and ODCNM. Under ONM, is 0.5 in Experiment 1, and we study the influence of in Experiment 2. Under ODCNM, for , we generate the degree parameters for the column nodes as below: let , such that for , where denotes the uniform distribution on . We study the influences of and under ODCNM in Experiments 3 and 4, respectively. For all settings, we report the averaged MHamm and the averaged Hamm over 50 repetitions.
Experiment 1: Changing under ONM. Let range over . For this experiment, P is set as
Let for this experiment designed under ONM. The numerical results are shown in panels (a) and (b) of Figure 1. The results show that as increases, ONA and ODCNA perform better. For the row nodes, since both ONA and ODCNA apply the SP algorithm on to estimate , the estimated row membership matrices of ONA and ODCNA are same, and hence, MHamm for ONA is always equal to that of ODCNA.
Experiment 2: Changing under ONM.P is set the same as in Experiment 1, and we let the range of be to study the influence of on the performances of ONA and ODCNA under ONM. The results are displayed in panels (c) and (d) of Figure 1. From the results, we can see that both methods perform better as increases, since a larger gives more edges generated in a directed network.
Experiment 3: Change under ODCNM.P is set to be the same as Experiment 1, and . Let range in . Increasing decreases the edges generated under ODCNM. Panels (e) and (f) in Figure 1 display the simulation results of this experiment. The results show that generally, increasing the variability of the node degrees makes it harder to detect the node memberships for both ONA and ODCNA. Though ODCNA is designed under ODCNM, it holds similar performances as ONA for directed networks in which column nodes have various degrees in this experiment, and this is consistent with our theoretical findings in Corollaries 1 and 2.
Experiment 4: Change under ODCNM. Setting , P is set to be the same as in Experiment 1, and let range in under ODCNM. Panels (g) and (h) in Figure 1 display the simulation results of this experiment. The performances of the two proposed methods are similar as those of Experiment 2.
Remark 3.
For visuality, we plot A generated under ONM. Let , and
For the row nodes, let for , for , and for . For the column nodes, let for , and for . For the above setting, we generate two random adjacency matrices in Figure 2, where we also report the error rates of ONA and ODCNA. Note that, since the adjacency matrices are shown in Figure 2, and as , and are known here, readers can apply ONA and ODCNA to A in Figure 2 to check the effectiveness of ONA and ODCNA.
Remark 4.
For visuality, we also plot a directed network as well as its adjacency matrix generated under ONM. Let , and
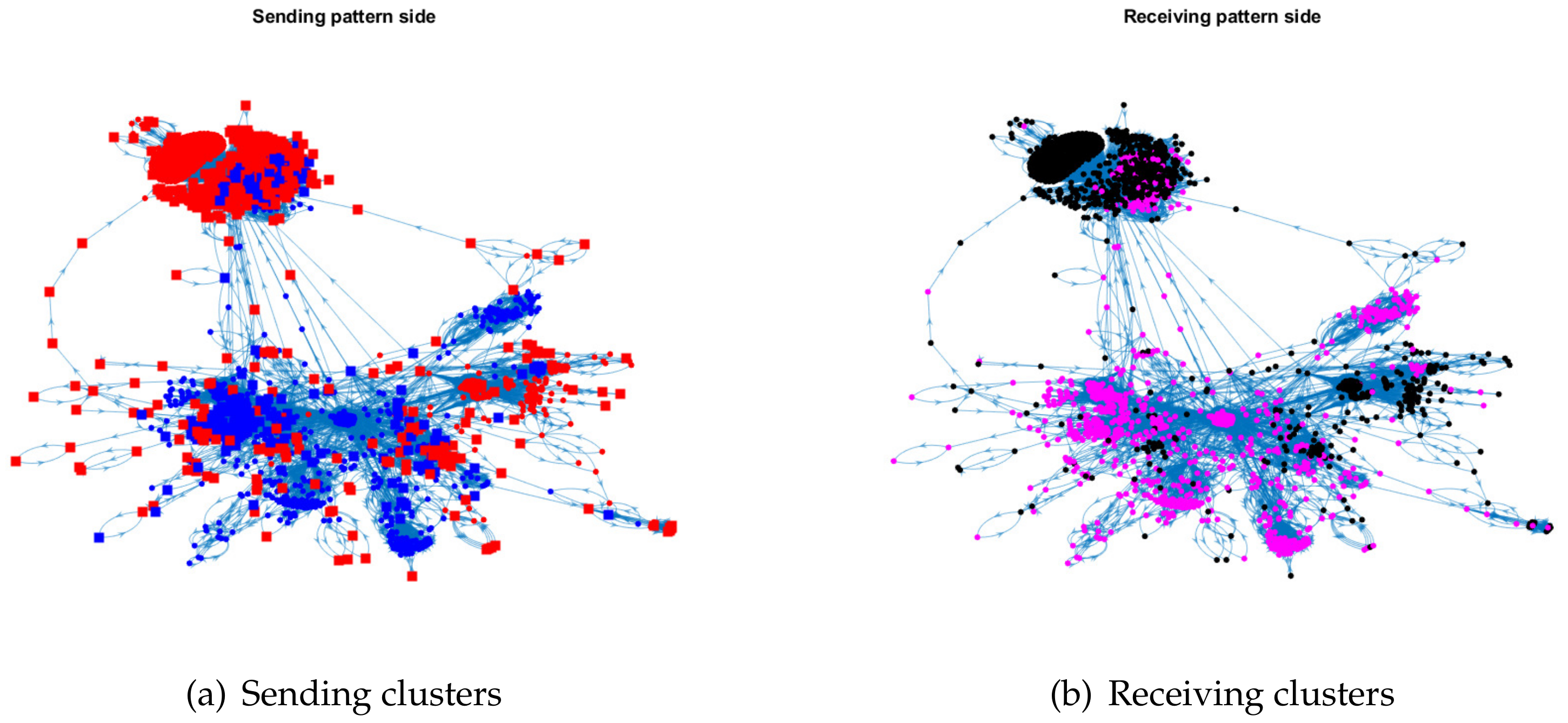
For row nodes, let for , for , and for . For column nodes, let for , for , and for . For the above setting, we generate one adjacency matrix in panel (a) of Figure 3, where we also report the error rates of ONA and ODCNA. Furthermore, panels (b) and (c) of Figure 3 show the sending pattern and receiving pattern sides of this simulated directed network, respectively.
5. Real Data Analysis
For real-world directed networks, since nodes always have various degrees, we only apply ODCNA to deal with real-world datasets in this section. For the real-world directed networks analyzed in this section, the row nodes are always same as the column nodes, so we do not use subscript r and c to distinguish the row and column nodes here, and we let . Meanwhile, the number of row communities is equal to that of the column communities; i.e, for real data, where we always set , as analyzed in [18], since it is a challenge to determine the number of row (column) communities for real-world directed networks without prior knowledge. When the row nodes are the same as the column nodes, means that a directed edge is sent from node i to node j. Thus, for any node, it has two patterns, the sending pattern and the receiving pattern. For the sending (receiving) pattern, we use the sending (receiving) cluster to denote the prior row (column) community, where we use the sending and receiving patterns to distinguish the behaviors of any node having the two patterns, as was performed in [18].
For obtained from ODCNA, we call node i a highly mixed node if , where 0.8 is a threshold. Here, 0.8 is a moderate value to define highly mixed nodes, and we can also choose 0.9, 0.95, or some other values in . However, we choose 0.8 as the threshold, because setting the threshold to be larger (or lesser) than 0.8 may be too restrictive (loose) to define highly mixed nodes. The definition of highly mixed node is important, since it tells us whether a node only belongs to one community or belongs to multiple communities. Let be the proportion of highly mixed row nodes among all nodes, to measure the mixability of a directed network, i.e, . Meanwhile, we let be an vector, such that , where we use to denote the home base sending pattern cluster of node i. Set
where is the set of all permutations of ; is defined as if , and 0 otherwise for . is defined to measure the difference between the sending and receiving pattern clusters. After defining and , we see that a larger indicates a directed network in which a large proposition of nodes are highly mixed nodes with a sending pattern, and a larger indicates that the sending pattern differs a lot with the receiving pattern. For , let denote the total number of edges sent by node i, and let denote the total number of edges that are received by node i. Call and the sending degree and receiving degree of node i, respectively. For real-world directed networks, we find that there are many nodes whose sending degree or receiving degree are zero, and so we need the following pre-processing steps before analyzing the real data:
- (a)
- Set and .
- (b)
- Set .
- (c)
- Update A by removing the nodes in .
- (d)
- Repeat (a)–(c) until is a null set.
- (e)
- After obtaining A through the above four steps, obtain the largest connected component of A.
We now describe the real-world directed networks analyzed in this paper:
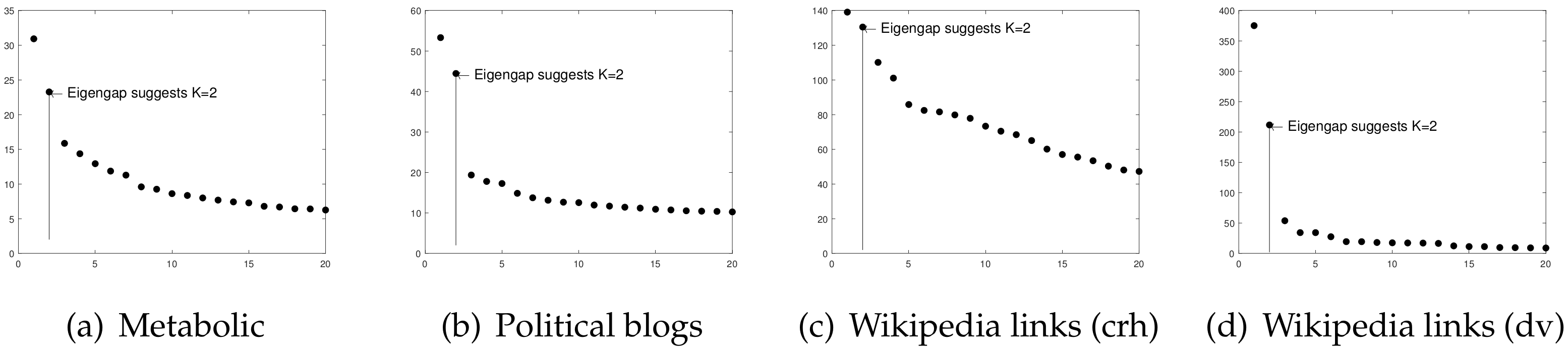
Metabolic: This is a directed network representing the metabolic reactions of E.coli bacteria. In this data, node means metabolite, and a directed edge from node i to node j means that there is a reaction where node i is an input and node j is a product [29]. These data can be downloaded from http://networksciencebook.com/translations/en/resources/data.html. The original dat has 1039 nodes; after preprocessing, . To estimate K, we plot the leading 20 singular values of A, and panel (a) of Figure 4 shows the result that suggests that for these data, where [18] also applies the idea of an eigengap to estimate K for real-world directed networks with an unknown number of communities.
Political blogs: this is a directed network of hyperlinks between weblogs on US politics [30], and it can be downloaded from http://www-personal.umich.edu/~mejn/netdata/. Political blogs send and receive hyperlinks to and from blogs for the same political persuasion [18], so node means blog and edge means hyperlink in these data. The original network has 1490 nodes. After removing nodes with zero degrees via pre-processing steps, there are 814 nodes left; i.e., for these data. Since there are two parties, “liberal” and “conservative”, K is 2 for both the sending and receiving pattern communities for these data. [18] applies their DI-SIM algorithm to the Political blogs network, assuming that all nodes have non-overlapping property. In this paper, we apply our ODCNA algorithm on these data to study its asymmetric structure on the overlapping property.
Wikipedia links (crh): This directed network represents the wikilinks of the Wikipedia website in the Crimean Turkish language (crh). Node means article, and the directed edge between two articles is the wikilink [31]. These data can be downloaded from http://konect.cc/networks/wikipedia_link_crh/. The original data have 8286 nodes. After pro-processing, . Panel (c) of Figure 4 suggests for this data.
Wikipedia links (dv): These data represent the wikilinks of the Wikipedia website in the Divehi language (dv), where node means article and the directed edge is a wikilink [31]. These data can be downloaded from http://konect.cc/networks/wikipedia_link_dv/. The original data has 4266 nodes. After removing nodes with zero degrees, . Panel (d) of Figure 4 suggests for these data.
The proportion of highly mixed nodes and for these directed networks are reported in Table 1 when assuming that nodes in sending (receiving) clusters having an overlapping (non-overlapping) property. For the Metabolic network, the results show that the sending pattern differs a lot with the receiving pattern, since is quite large, and there are highly mixed nodes in the sending pattern. For the Political blogs network, there is a slight asymmetric structure between the sending pattern and the receiving pattern, since is small. Meanwhile, for the sending pattern of Political blogs, there are highly mixed nodes. Thus, we may conclude that though there is a slight asymmetric structure in sending and receiving patterns for Political blogs, there are 20 highly mixed nodes in the sending pattern. For the Wikipedia links (crh), they have a slight asymmetric structure between sending and receiving patterns, and there are highly mixed nodes in the sending pattern. For the Wikipedia links (dv) network, it has a large number of highly mixed nodes for its large , and a heavy asymmetric structure in sending and receiving patterns for its large . Generally, Table 1 suggests that if there are a large number of highly mixed nodes in the sending pattern, there is a heavy asymmetric structure between the sending and receiving patterns, and vice versa.
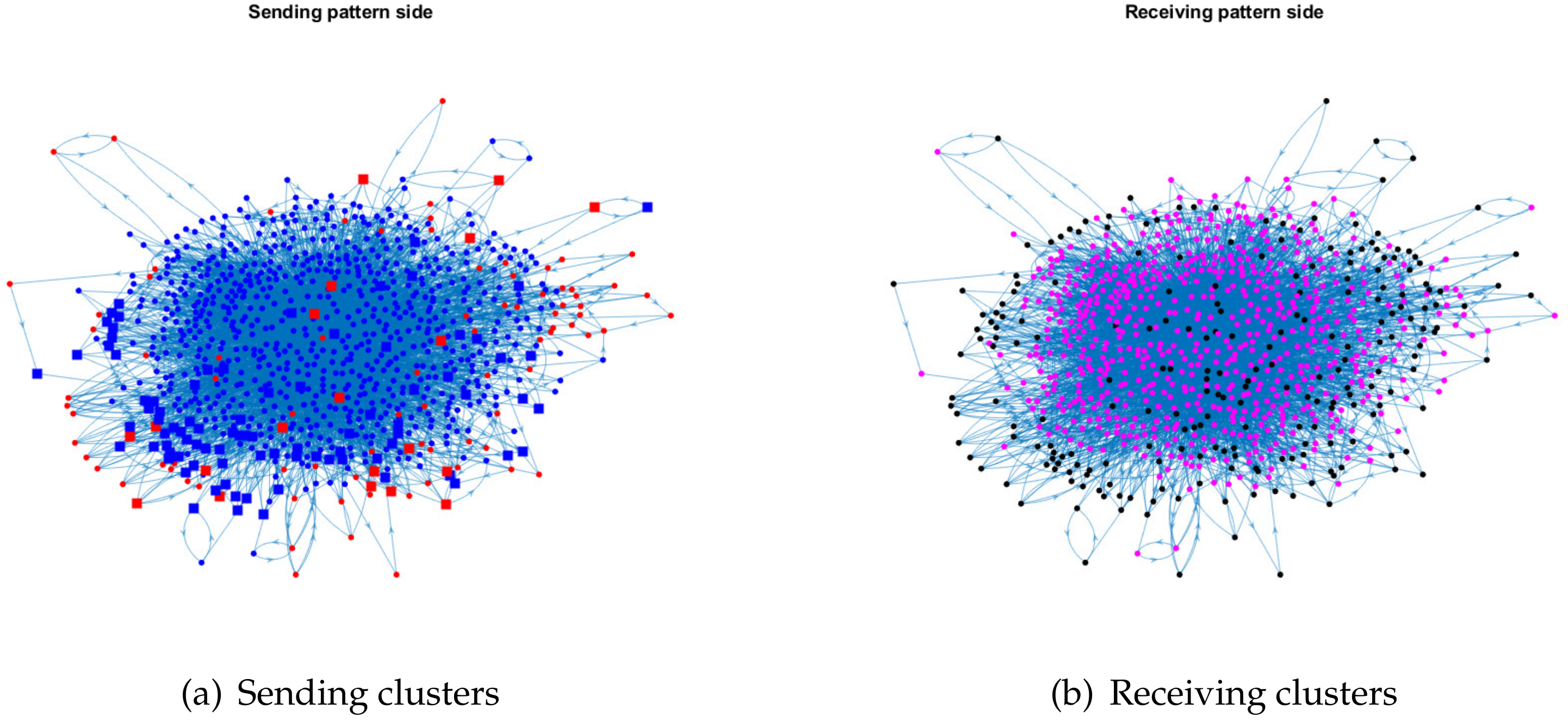
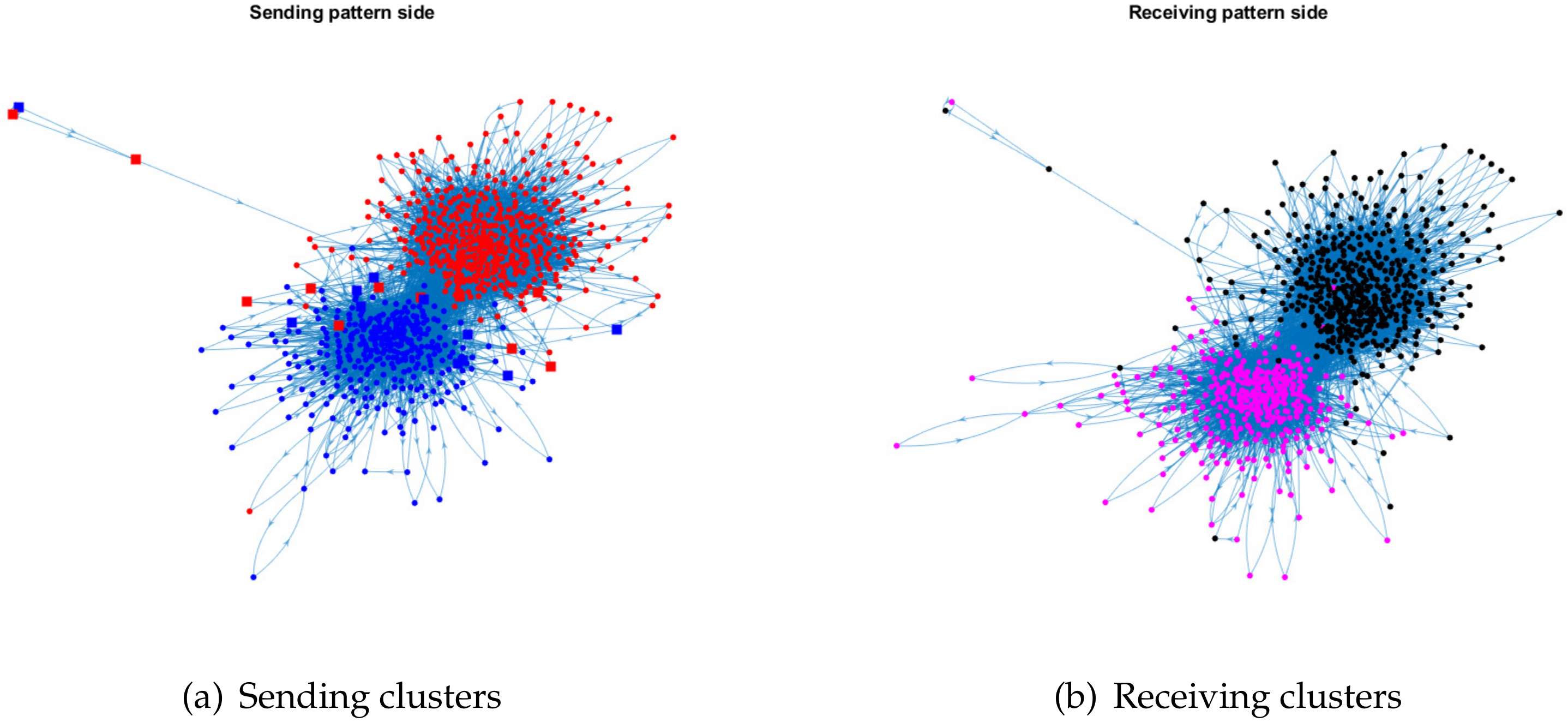
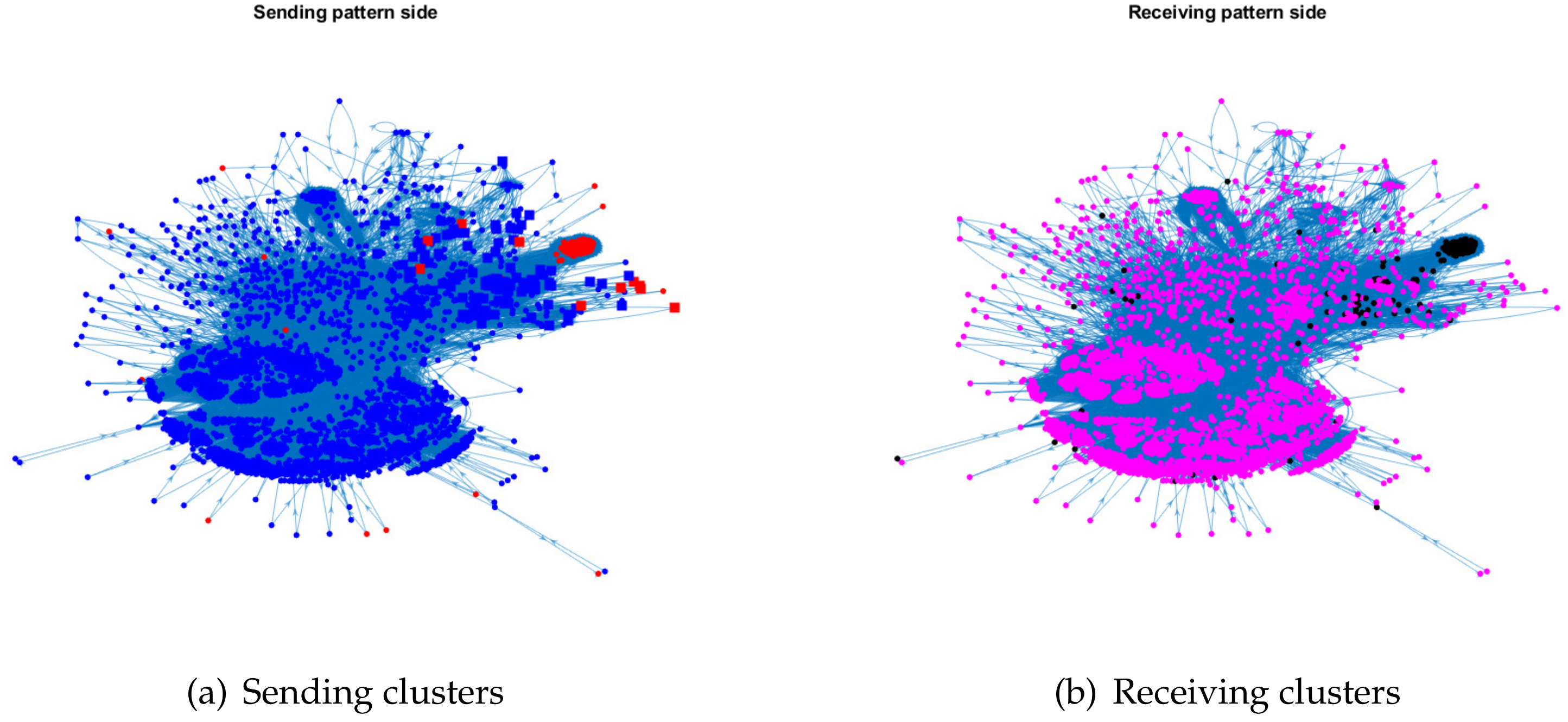
For visualization, we plot the sending clusters and receiving clusters detected by ODCNA for these directed networks when assuming that nodes in the sending (receiving) clusters have an overlapping (non-overlapping) property, i.e., when the input adjacency matrix of the ODCNA approach is A. The results are shown in Figure 5, Figure 6, Figure 7 and Figure 8, where we also show the highly mixed nodes in sending clusters detected by ODCNA. We see that there exists a clear asymmetric structure between the sending and receiving patterns for Metabolic and Wikipedia links (dv), as shown in Figure 5 and Figure 8, while there is a slight asymmetric structure between the sending and receiving patterns for Political blogs and Wikipedia links (crh), as shown in Figure 6 and Figure 7. Furthermore, most nodes are in the same sending (receiving) cluster for Metabolic and Wikipedia links (crh), while the two sending (receiving) clusters for Political blogs and Wikipedia links (crh) have close sizes. The results also show that most highly mixed nodes have many edges, while some highly mixed nodes have only a few edges, where such a phenomenon can be explained easily, since nodes with many edges tend to have an overlapping property, while it is difficult to detect a community for nodes with only a few edges, and ODCNA tends to treat such nodes as highly mixed nodes.
Furthermore, for real-world directed networks, since we have no prior knowledge on whether nodes in the sending pattern side or the receiving pattern side or both sides have overlapping property, simply inputting A with K sending (receiving) pattern communities in our ODCNA algorithm is not enough. To solve this problem, we also apply ODCNA on , and the numerical results are provided in Table 2, where the results show that there also exist highly mixed nodes in the receiving pattern for these directed networks, and there also exists a heavy asymmetric structure between the sending and receiving clusters for the Metabolic and Wikipedia links (dv), while there also exists a slight asymmetric structure between the sending and receiving clusters for the Political blogs and Wikipedia links (crh).
6. Discussion
In this paper, we introduced Overlapping and Non-overlapping models and their extension, by considering the degree heterogeneity. The models can model a directed network with row communities and column communities, in which the row node can belong to multiple sending clusters, while the column node only belongs to one of the receiving clusters. The proposed models are identifiable under the case when , and some other popular constraints on the connectivity matrix and membership matrices. For comparison, modeling a directed network in which the row nodes have overlapping property while column nodes do not, with , is unidentifiable. Meanwhile, since previous works have found that modeling directed networks in which both row and column nodes have an overlapping property with is unidentifiable, our identifiable ONM and ODCNM supply a gap in modeling overlapping directed networks when . These models provide exploratory tools for studying community structure in directed networks with one side overlapping while another side is non-overlapping. Two spectral algorithms are designed to fit ONM and ODCNM. We also showed an estimation consistency under mild conditions for our methods. Especially, when ODCNM reduces to ONM, our theoretical results under ODCNM are consistent with those under ONM. The numerical results for the simulated directed networks generated under ONM and ODCNM support our theoretical results, and the results for real-world directed networks reveal the existence of highly mixed nodes and an asymmetric structure between the sending and receiving clusters.
The models and algorithms introduced in this paper are useful tools for studying the asymmetric structure for directed networks, and we wish that they can be widely applied in network science. However, perhaps the main limitation of the models is that and in the directed network are assumed as givens, and such a limitation also holds for the spectral clustering algorithms developed under the ScBM and DCScBM studied in [18,19,20]. In most community problems, the number of row communities and the number of column communities are unknown; therefore, a complete calculation and theoretical study requires not only the algorithms and their theoretically consistent estimations described in this paper, but also a method for estimating and . A possible solution to this problem may be a combination of algorithms developed in this paper and the modularity for the directed networks developed in [32]. Meanwhile, our idea can be extended in many ways. In this paper, we only consider modeling an un-weighted directed network, and it is possible to extend our work to a weighted directed network. Our algorithms are designed based on the adjacency matrix, and it is possible to design spectral algorithms to fit ONM and ODCNM by applying the regularized Laplace matrix used in [11,12]. When detecting large-scale directed networks, the random projection-based and the random sampling-based spectral clustering ideas in [33] may be applied to accelerate our algorithms. We leave the studies of these problems to our future work.
Funding
This research was funded by the scientific research start-up fund of China University of Mining and Technology, NO. 102520253, and the high-level personal project of Jiangsu Province, NO. JSSCBS20211218.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available within the article.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SBM | Stochastic Blockmodel |
| DCSBM | Degree-Corrected Stochastic Blockmodel |
| MMSB | Mixed Membership Stochastic Blockmodel |
| DCMM | Degree-Corrected Mixed Membership model |
| OCCAM | Overlapping Continuous Community Assignment model |
| ScBM | Stochastic co-Blockmodel |
| DCScBM | Degree-Corrected Stochastic co-Blockmodel |
| DiMMSB | Directed Mixed Membership Stochastic Blockmodel |
| ONM | Overlapping and Non-overlapping model |
| ODCNM | Overlapping and Degree-Corrected Non-overlapping model |
| SP | successive projection algorithm |
| ONA | Overlapping and Non-overlapping algorithm |
| ODCNA | Overlapping and Degree-Corrected Non-overlapping Algorithm |
Appendix A. Successive Projection Algorithm
Algorithm A1 is the Successive Projection algorithm.
| Algorithm A1 Successive Projection (SP) [27] |
Require: Near-separable matrix , where should satisfy Assumption 1 [27], the number r of columns to be extracted. Ensure: Set of indices such that (up to permutation)
|
Appendix B. Proofs under ONM
Appendix B.1. Proof of Proposition 1
Proof.
By Lemma 1, let be the compact SVD of , such that ; since , we have , which gives . By Lemma 1, since , we have where we have used the fact that the inverse of exists. Since , we have . By Lemma 7 of [21], we have , i.e., , where we set . Let be the vector of column nodes labels obtained from . For , from , we have , which means that we must have for all , i.e., and . Note that for the special case , can be obtained easily: since and is assumed to be full rank, we have . Thus, the proposition holds. □
Appendix B.2. Proof of Lemma 1
Proof.
For , since and , we have . Recall that ; we have , where we set . Since , we have . For , , so we have when .
For , following a similar analysis as for , we have , where . Note that . Sure, when for .
Now, we focus on the case where . For this case, since , is full rank when . Since , we have . Since , we have . When , we have for any and . Then, we have , and the lemma follows.
Note that when , since is not full rank now, we cannot obtain from . Therefore, when , the equality does not hold for any . Additionally, we can only know that has distinct rows when , but have no knowledge about the minimum distance between any two distinct rows of . □
Appendix B.3. Proof of Theorem 1
Proof.
First, by Lemma 4 of [21], we have the below lemma.
Lemma A1.
(Row-wise singular eigenvector error) Under , when Assumption 1 holds, suppose , with a probability of at least ,
For the row nodes, when conditions in Lemma A1 hold, by Theorem 2 of [21], with a probability of at least for any , there exists a permutation matrix such that, for , we have
Next, we focus on the column nodes. By the Proof of Lemma 3 in [19], there exists an orthogonal matrix such that
Under , by Lemma 10 of [21], we have
Since all column nodes are pure, . By Lemma 3 of [21], when Assumption 1 holds with a probability at least , we have
Let be a small quantity; by Lemma 2 in [15], if
then the clustering error . Recall that we set to measure the minimum center separation of . Setting makes Equation (A5) hold for all . Then, we have . By Equation (A4), we have
Especially, when , under by Lemma 1. When , we have
□
Appendix B.4. Proof of Corollary 1
Proof.
For the row nodes, under the conditions of Corollary 1, we have
Under the conditions of Corollary 1, and for some by the proof of Corollary 1 [21]. Then, by Lemma A1, we have
which gives that
Note that, when , we cannot draw a conclusion that . This is because, when , the inverse of does not exist, since . Therefore, Lemma 8 of [21] does not hold, and we cannot obtain the upper bound of , causing the impossibility of obtaining the upper bound of , and this is the reason for why we only consider the case for when , for the row nodes here.
For the column nodes, under the conditions of Corollary 1, we have
For the special case , since when , we have
When , and , the corollary follows immediately by basic algebra. □
Appendix C. Proofs under ODCNM
Appendix C.1. Proof of Proposition 2
Proof.
Since , we have by Lemma 2, which gives that . Since by Lemma 2, we have . □
Appendix C.2. Proof of Lemma 2
Proof.
- For : since and , we have . Recall that under ODCNM; we have , where . Sure, holds when for .
- For : let be a diagonal matrix, such that for . Let be an matrix, such that for . For such and , we have and , i.e., .Since and , we have . Since , we have , where we set. Note that since , we have . Now, for , we havewhich gives thatThen, we haveSure, we have when for . Let , such that for . Equation (A6) gives , which guarantees the existence of .Now, we consider the case for when . Since and , we have and . Since , we have when . Then, we haveSince , we have by Equation (A6), andwhen for , i.e., for .Note that, when , since and , the inverse of does not exist, which causes that the last equality in Equation (A7) does not hold and for all .
□
Appendix C.3. Proof of Theorem 2
Proof.
First, by the proof of Lemma 4.3 of [25], we have the below lemma.
Lemma A2.
(Row-wise singular eigenvector error) Under , when Assumption 2 holds, suppose that , with a probability at least ,
For the row nodes, when the conditions in Lemma A2 hold, by Theorem 2 of [21], we have
Next, we focus on the column nodes. By the proof of Lemma 3 in [19], there is an orthogonal matrix , such that
Under , by Lemma 4 of [25], we have
By Lemma 4.2 of [25], when Assumption 2 holds, with a probability at least , we have
For , by basic algebra, we have
Setting , we have
Next, we provide the lower bounds of . By the proof of Lemma 2, we have
where we set . Note that when , by the Proof of Lemma 2, we know that , which gives that for ; i.e., when . However, when , it is challenge to obtain a positive lower bound of . Hence, we have . Then, by Equation (A11), we have
Let be a small quantity; by Lemma 2 in [15], if
then the clustering error . Setting makes Equation (A12) hold for all . Then, we have . By Equation (A11), we have
Especially, when , under by Lemma 2, and . When , we have
□
Appendix C.4. Proof of Corollary 2
Proof.
For the row nodes, under the conditions of Corollary 2, we have
Under the conditions of Corollary 2, and for some by Lemma 2 of [25]. Then, by Lemma A2, we have
which gives that
The reason for why we do not consider the case when for row nodes is similar as that of Corollary 1, and we omit it here.
For column nodes, under conditions of Corollary 2, we have
For the case , we have
When and , the corollary follows immediately by basic algebra. □
References
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E. The structure and function of complex networks. Siam Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Goldenberg, A.; Zheng, A.X.; Fienberg, S.E.; Airoldi, E.M. A survey of statistical network models. Found. Trends Mach. Learn. 2010, 2, 129–233. [Google Scholar] [CrossRef]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Karrer, B.; Newman, M.E.J. Stochastic blockmodels and community structure in networks. Phys. Rev. 2011, 83, 16107. [Google Scholar] [CrossRef]
- Airoldi, E.M.; Blei, D.M.; Fienberg, S.E.; Xing, E.P. Mixed Membership Stochastic Blockmodels. J. Mach. Learn. Res. 2008, 9, 1981–2014. [Google Scholar]
- Jin, J.; Ke, Z.T.; Luo, S. Estimating network memberships by simplex vertex hunting. arXiv 2017, arXiv:1708.07852. [Google Scholar]
- Zhang, Y.; Levina, E.; Zhu, J. Detecting Overlapping Communities in Networks Using Spectral Methods. Siam J. Math. Data Sci. 2020, 2, 265–283. [Google Scholar] [CrossRef]
- Rohe, K.; Chatterjee, S.; Yu, B. Spectral clustering and the high-dimensional stochastic blockmodel. Ann. Stat. 2011, 39, 1878–1915. [Google Scholar] [CrossRef]
- Qin, T.; Rohe, K. Regularized spectral clustering under the degree-corrected stochastic blockmodel. Adv. Neural Inf. Process. Syst. 2013, 26, 3120–3128. [Google Scholar]
- Lei, J.; Rinaldo, A. Consistency of spectral clustering in stochastic block models. Ann. Stat. 2015, 43, 215–237. [Google Scholar] [CrossRef]
- Jin, J. Fast community detection by SCORE. Ann. Stat. 2015, 43, 57–89. [Google Scholar] [CrossRef]
- Joseph, A.; Yu, B. Impact of regularization on spectral clustering. Ann. Stat. 2016, 44, 1765–1791. [Google Scholar] [CrossRef]
- Mao, X.; Sarkar, P.; Chakrabarti, D. Overlapping Clustering Models, and One (class) SVM to Bind Them All. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31, pp. 2126–2136. [Google Scholar]
- Mao, X.; Sarkar, P.; Chakrabarti, D. Estimating mixed memberships with sharp eigenvector deviations. J. Am. Stat. Assoc. 2020, 116, 1–13. [Google Scholar] [CrossRef]
- Rohe, K.; Qin, T.; Yu, B. Co-clustering directed graphs to discover asymmetries and directional communities. Proc. Natl. Acad. Sci. USA 2016, 113, 12679–12684. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Amini, A.A. Analysis of spectral clustering algorithms for community detection: The general bipartite setting. J. Mach. Learn. Res. 2019, 20, 1–47. [Google Scholar]
- Wang, Z.; Liang, Y.; Ji, P. Spectral algorithms for community detection in directed networks. J. Mach. Learn. Res. 2020, 21, 1–45. [Google Scholar]
- Qing, H.; Wang, J. Directed mixed membership stochastic blockmodel. arXiv 2021, arXiv:2101.02307v2. [Google Scholar]
- Airoldi, E.M.; Wang, X.; Lin, X. Multi-way blockmodels for analyzing coordinated high-dimensional responses. Ann. Appl. Stat. 2013, 7, 2431–2457. [Google Scholar] [CrossRef]
- Razaee, Z.S.; Amini, A.A.; Li, J.J. Matched bipartite block model with covariates. J. Mach. Learn. Res. 2019, 20, 1174–1217. [Google Scholar]
- Zhou, Z.; Amini, A.A. Optimal bipartite network clustering. J. Mach. Learn. Res. 2020, 21, 1–68. [Google Scholar]
- Qing, H. Directed degree corrected mixed membership model and estimating community memberships in directed networks. arXiv 2021, arXiv:2109.07826. [Google Scholar]
- Ndaoud, M.; Sigalla, S.; Tsybakov, A.B. Improved clustering algorithms for the bipartite stochastic block model. IEEE Trans. Inf. Theory 2021, 68, 1960–1975. [Google Scholar] [CrossRef]
- Gillis, N.; Vavasis, S.A. Semidefinite programming based preconditioning for more robust near-separable nonnegative matrix factorization. Siam J. Optim. 2015, 25, 677–698. [Google Scholar] [CrossRef]
- Qing, H. A useful criterion on studying consistent estimation in community detection. Entropy 2022, 24, 1098. [Google Scholar] [CrossRef]
- Schellenberger, J.; Park, J.O.; Conrad, T.M.; Palsson, B.Ø. BiGG: A Biochemical Genetic and Genomic knowledgebase of large scale metabolic reconstructions. BMC Bioinform. 2010, 11, 1–10. [Google Scholar] [CrossRef]
- Adamic, L.A.; Glance, N. The political blogosphere and the 2004 US election: Divided they blog. In Proceedings of the 3rd International Workshop on Link Discovery, Chicago, IL, USA, 21–25 August 2005; pp. 36–43. [Google Scholar]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Leicht, E.A.; Newman, M.E. Community structure in directed networks. Phys. Rev. Lett. 2008, 100, 118703. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Guo, X.; Chang, X. Randomized spectral clustering in large-scale stochastic block models. J. Comput. Graph. Stat. 2022, 1–20. [Google Scholar] [CrossRef]
Figure 1.
Estimation errors of ONA and ODCNA.

Figure 2.
For adjacency matrix in panel (a), and for ONA are 0.0544 and 0, respectively. For adjacency matrix in panel (b), and for ONA are 0.1004 and 0, respectively. ODCNA enjoys same error rates as ONA. x-axis: row nodes; y-axis: column nodes.
Figure 2.
For adjacency matrix in panel (a), and for ONA are 0.0544 and 0, respectively. For adjacency matrix in panel (b), and for ONA are 0.1004 and 0, respectively. ODCNA enjoys same error rates as ONA. x-axis: row nodes; y-axis: column nodes.

Figure 3.
Illustration of a simulated directed network generated under ONM. Panels (a–c) show the adjacency matrix, the sending clusters, and the receiving clusters of this simulated directed network, respectively. For this directed network, and for ONA (and ODCNA) are 0.0615 (0.0615) and 0 (0.2333), respectively. In panels (b,c), the dots in the same color are pure nodes in the same sending (receiving) clusters, and the square indicates the mixed nodes with weight 0.7 belonging to red sending clusters, and weight 0.3 belonging to blue sending clusters, where the sending and receiving clusters are obtained by and ℓ provided in Remark 4.
Figure 3.
Illustration of a simulated directed network generated under ONM. Panels (a–c) show the adjacency matrix, the sending clusters, and the receiving clusters of this simulated directed network, respectively. For this directed network, and for ONA (and ODCNA) are 0.0615 (0.0615) and 0 (0.2333), respectively. In panels (b,c), the dots in the same color are pure nodes in the same sending (receiving) clusters, and the square indicates the mixed nodes with weight 0.7 belonging to red sending clusters, and weight 0.3 belonging to blue sending clusters, where the sending and receiving clusters are obtained by and ℓ provided in Remark 4.

Figure 4.
Leading 20 singular values of adjacency matrices for real-world directed networks used in this paper.
Figure 4.
Leading 20 singular values of adjacency matrices for real-world directed networks used in this paper.

Figure 5.
Sending and receiving clusters detected by ODCNA for Metabolic network when assuming that nodes in a sending (receiving) pattern have an overlapping (non-overlapping) property. Colors indicate clusters detected using ODCNA, and squares indicate highly mixed nodes, where sending clusters are obtained using , the home base sending pattern community, and receiving clusters are obtained by from ODCNA.
Figure 5.
Sending and receiving clusters detected by ODCNA for Metabolic network when assuming that nodes in a sending (receiving) pattern have an overlapping (non-overlapping) property. Colors indicate clusters detected using ODCNA, and squares indicate highly mixed nodes, where sending clusters are obtained using , the home base sending pattern community, and receiving clusters are obtained by from ODCNA.

Figure 6.
Sending and receiving clusters detected by ODCNA for Political blogs network. Colors indicate clusters and square indicates highly mixed nodes.
Figure 6.
Sending and receiving clusters detected by ODCNA for Political blogs network. Colors indicate clusters and square indicates highly mixed nodes.

Figure 7.
Sending and receiving clusters detected by ODCNA for Wikipedia links (crh) network. Colors indicate clusters and square indicates highly mixed nodes.
Figure 7.
Sending and receiving clusters detected by ODCNA for Wikipedia links (crh) network. Colors indicate clusters and square indicates highly mixed nodes.

Figure 8.
Sending and receiving clusters detected by ODCNA for Wikipedia links (dv) network. Colors indicate clusters and square indicates highly mixed nodes.
Figure 8.
Sending and receiving clusters detected by ODCNA for Wikipedia links (dv) network. Colors indicate clusters and square indicates highly mixed nodes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The proportion of highly mixed nodes and the asymmetric structure measured by for real-world directed networks considered in this paper when ODCNA’s input adjacency matrix is A; i.e., the case when assuming that nodes in a sending (receiving) pattern have overlapping (non-overlapping) property.
Table 1.
The proportion of highly mixed nodes and the asymmetric structure measured by for real-world directed networks considered in this paper when ODCNA’s input adjacency matrix is A; i.e., the case when assuming that nodes in a sending (receiving) pattern have overlapping (non-overlapping) property.
| Data | ||
|---|---|---|
| Metabolic | 0.1209 | 0.2497 |
| Political blogs | 0.0246 | 0.0443 |
| Wikipedia links (crh) | 0.0444 | 0.0307 |
| Wikipedia links (dv) | 0.4089 | 0.1466 |
Table 2.
The proportion of highly mixed nodes and the asymmetric structure measured by for real-world directed networks considered in this paper when ODCNA’s input adjacency matrix is , i.e., the case when assuming that nodes in sending (receiving) pattern have non-overlapping (overlapping) property.
Table 2.
The proportion of highly mixed nodes and the asymmetric structure measured by for real-world directed networks considered in this paper when ODCNA’s input adjacency matrix is , i.e., the case when assuming that nodes in sending (receiving) pattern have non-overlapping (overlapping) property.
| Data | ||
|---|---|---|
| Metabolic | 0.0594 | 0.2945 |
| Political blogs | 0.1365 | 0.0443 |
| Wikipedia links (crh) | 0.1308 | 0.0543 |
| Wikipedia links (dv) | 0.3492 | 0.2059 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Qing, H. Studying Asymmetric Structure in Directed Networks by Overlapping and Non-Overlapping Models. Entropy 2022, 24, 1216. https://doi.org/10.3390/e24091216
AMA Style
Qing H. Studying Asymmetric Structure in Directed Networks by Overlapping and Non-Overlapping Models. Entropy. 2022; 24(9):1216. https://doi.org/10.3390/e24091216
Chicago/Turabian StyleQing, Huan. 2022. "Studying Asymmetric Structure in Directed Networks by Overlapping and Non-Overlapping Models" Entropy 24, no. 9: 1216. https://doi.org/10.3390/e24091216
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.