1. Introduction and Basic Notions
Entropy is an influential quantity that has been explored in a wide range of studies, from applied to physical sciences. In the 19th century, Carnot and Clausius diversified the concept of entropy into three main directions—entropy associated with heat engines (where it behaves similar to a thermal charge), statistical entropy, and (according to Boltzmann and Shannon) entropy in communications channels and information security. Thus, the theory of entropy plays a key role in mathematics, statistics, dynamical systems (where complexity is mostly measured by entropy), information theory [
1], chemistry [
2], and physics [
3] (see also [
4,
5,
6]).
In recent years, other information source entropies have been studied [
7,
8,
9]. Butt et al. in [
10,
11] introduced new bounds for Shannon, relative, and Mandelbrot entropies via interpolating polynomials. Amig and colleagues defined entropy as a random process and the permutation entropy of a source [
1,
12].
Ellerman [
13] was the first to take credit for introducing a detailed introduction to the concept of logical entropy and establishing its relationship with the renowned Shannon entropy. In recent years, many researchers have focused on extending the notion of logical entropy in new directions/perspectives. Markechová et al. [
14] proposed the study of logical entropy and logical mutual information of experiments in the intuitionistic fuzzy case. Ebrahimzadeh [
15] proposed the logical entropy of a quantum dynamical system and investigated its ergodic properties. However, the logical entropy of a fuzzy dynamical system was investigated in [
7] (see also [
16]). Tamir et al. [
17] extended the idea of logical entropy over the quantum domain and expressed it in terms of the density matrix. In [
18], Ellerman defined logical conditional entropy and logical relative entropy. In fact, logical entropy is a particular case of Tsallis entropy when
. Logical entropy resembles the information measure introduced by Brukner and Zeilinger [
19]. In [
13], Ellerman introduced the concept of logical entropy for a random variable. He studied the logical entropy of the joint distribution
over
as:
The motive of this study was to extend the concept of logical entropy presented in [
13] to information sources. Since estimating entropy from the information source can be difficult [
20], we defined the logical metric permutation entropy of a map and used it to apply for an information source.
In the article,
is a measurable probability space (i.e.,
and
enjoys the structure of
-algebra of subsets of
with
). Further, if
X is a random variable of
possessing discrete finite state space
, then the function
defined by
is a probability function.
denotes the Shannon entropy of
X [
1]. If
is a sequence of the random variables on
, the sequence
is called an information source (also called the stochastic process [
]). Similarly, if
, then we define
by
We know that
for every natural number
m. A finite space
,
can be recalled as a stationary finite space
if
for every
. In an information–theoretical setting, one may assume a stationary
,
as a data source. A finite space
,
is strictly a stationary finite space
if
for every
. The Shannon entropy of order
m of source
is defined by [
1,
12]
The Shannon entropy of source
is defined by
If we assume that the alphabet
A from source
accepts an order ≤, so that
is a totally ordered set, then define another order ≺ on
A by [
1]
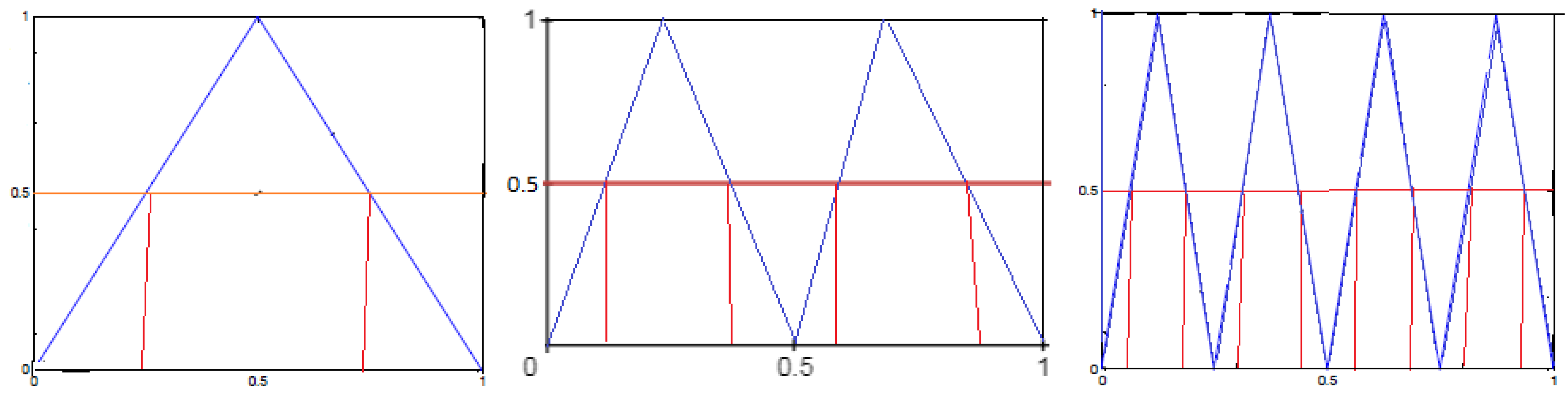
We say that a length-
m sequence
has an order pattern
if,
where
,
and
. To a
,
we associate a probability process
defined by
The sequence
defines a discrete-time process that is non-stationary. The metric permutation entropy of order
m and the metric permutation entropy of source
are, respectively, defined by [
1,
12]
and
2. Main Results
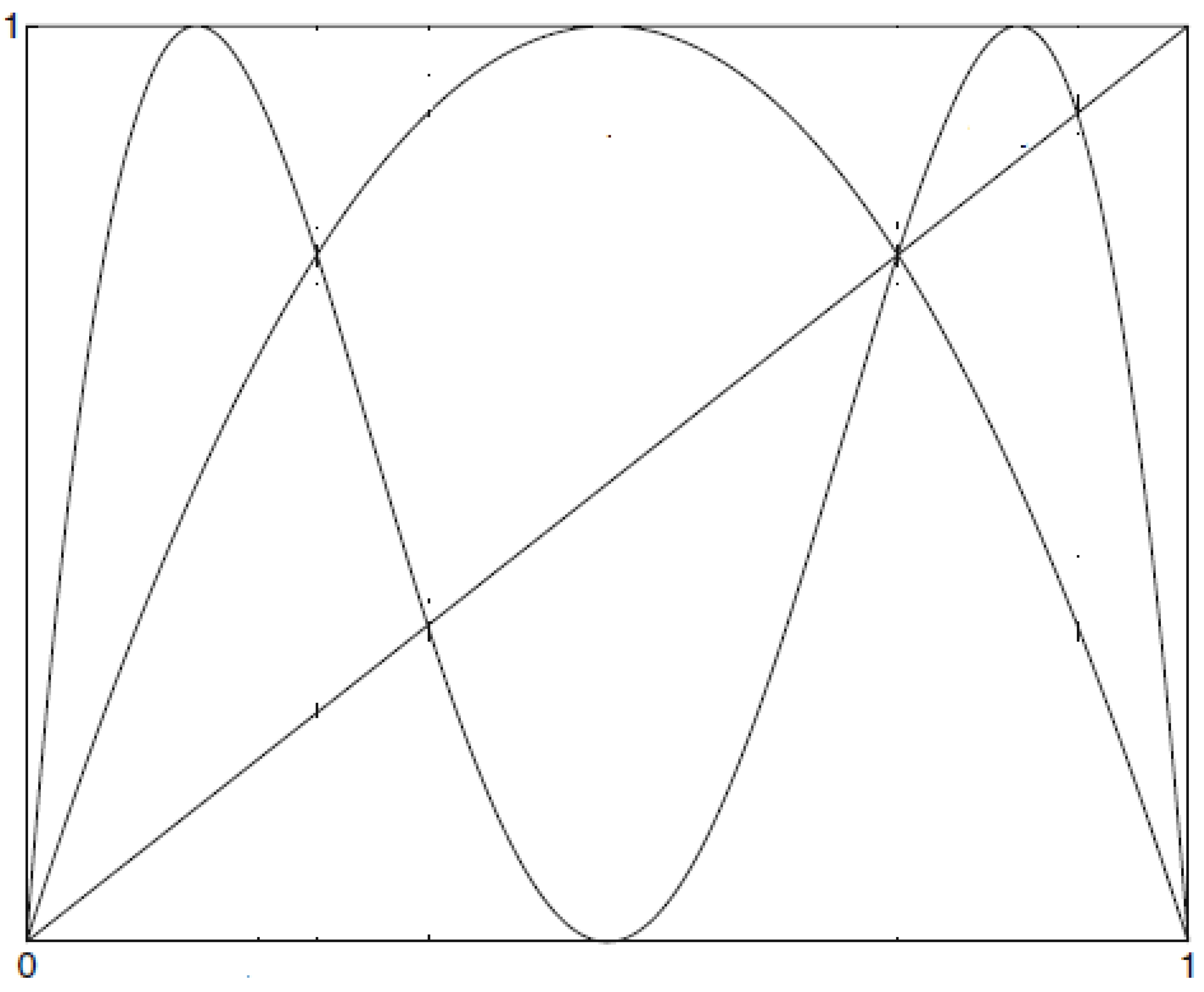
In this section, we use the symbol for to simplify the notation.
Definition 1. Reference [13]. Let X be a random variable on Γ with discrete finite state space . Then,is called the logical Shannon entropy of X. Theorem 1. Reference [21] If f is convex on I and , , then Theorem 2. Suppose that X is a random variable on Γ with a discrete finite state space , and , then Proof. Applying Theorem 1 with
, we obtain
Putting
, it follows that
After some calculations, it turns out that
□
Lemma 1. Let X be a random variable with alphabet . Then, , and equality holds if and only if for every .
Proof. Using Theorem 2, we obtain . Now, let , by the use of Theorem 2, we have and, thus, . Therefore, . Thus, for every . On the other hand, if for every , then , so and by the use of Theorem 2, we obtain . Hence, . □
Definition 2. The logical Shannon entropy of order m of source is defined by It is easy to see that may be but for every two random variables we have .
Definition 3. Let m be a natural number and . We define the sets byand . Moreover,
for every
and for every
. Furthermore, if
, then
for some
. Hence,
for some
and, thus,
. Moreover, if
, then
Define
. Therefore,
Hence,
for some
and, thus,
. So,
and, therefore,
. Hence, we obtain
and
for every
.
We now prove the following Theorem by employing Lemma A1 (see
Appendix A):
Theorem 3. If and are two random variables on Γ, then Proof. Suppose
. For every
, we consider
Moreover,
and
for every
; thus,
for every ordered pair
. For obvious reasons,
for each
and
for each
, and
. So, we have
and for every
,
and
With the use of Lemma A1, we have
Hence,
it follows that
Now, we prove the left-hand inequality. Since
for every
,
. Therefore,
and, thus,
So, .
Similarly,
. Consequently,
□
Corollary 1. If is an information source, then Proof. This follows from Theorem 3. □
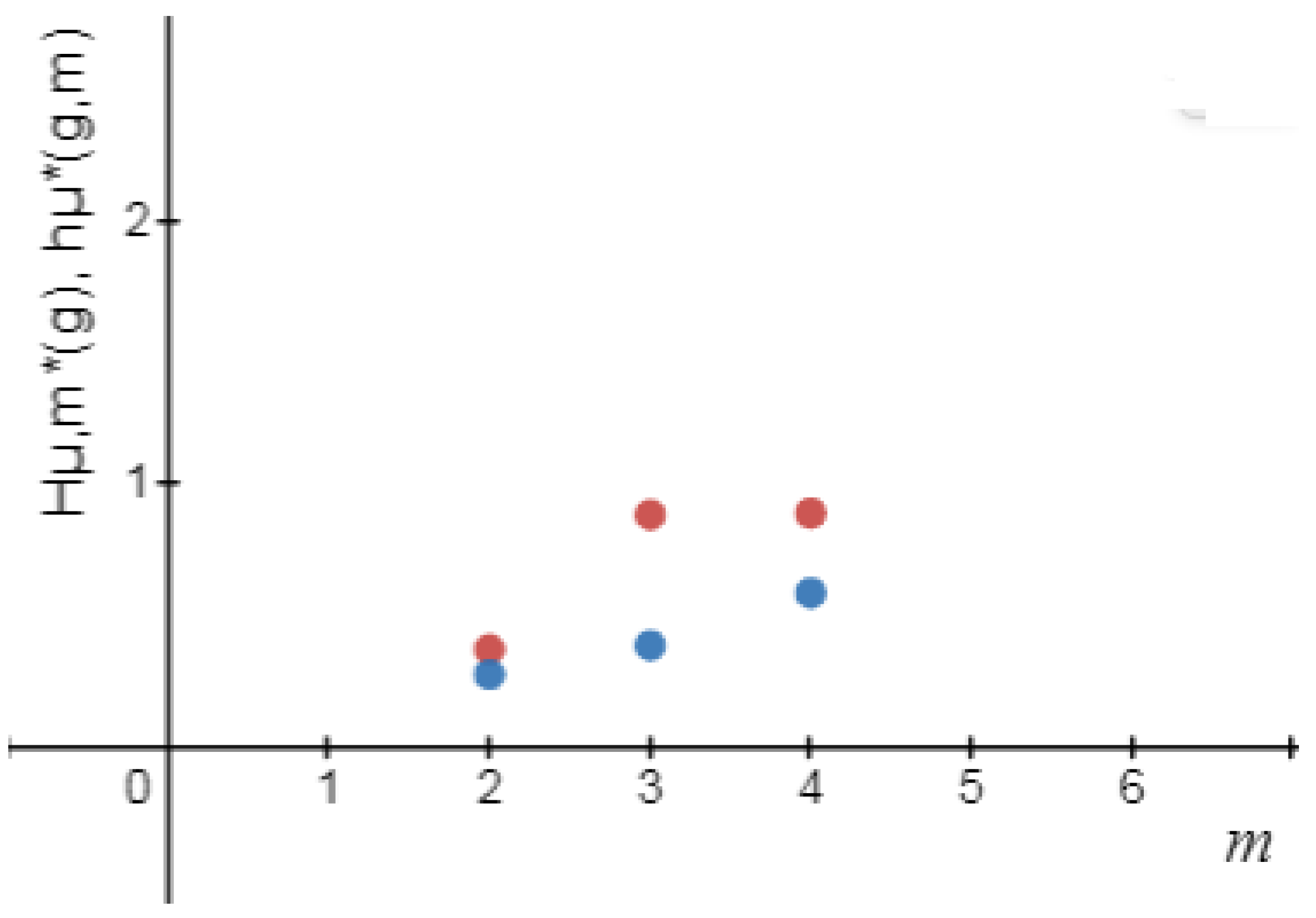
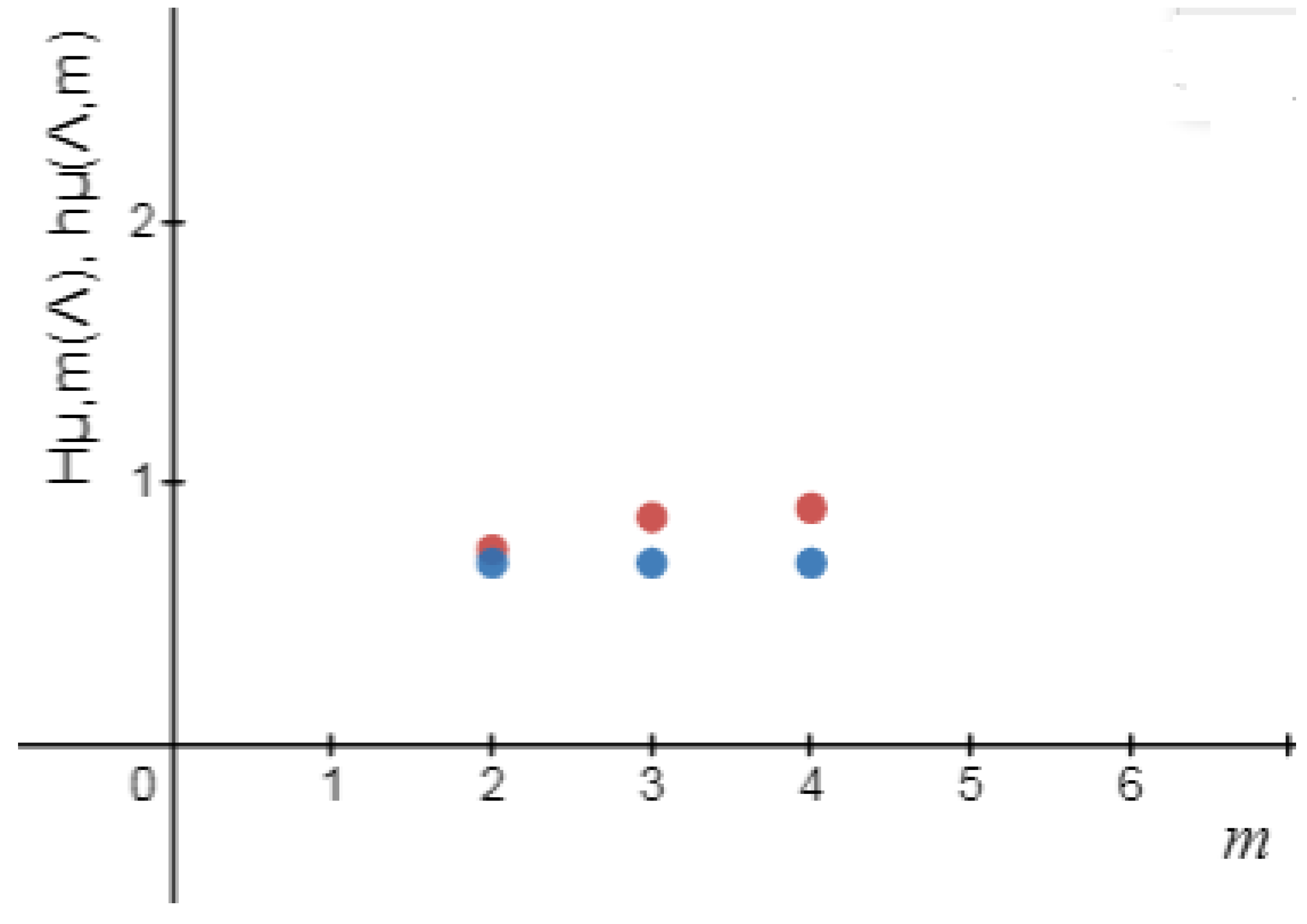
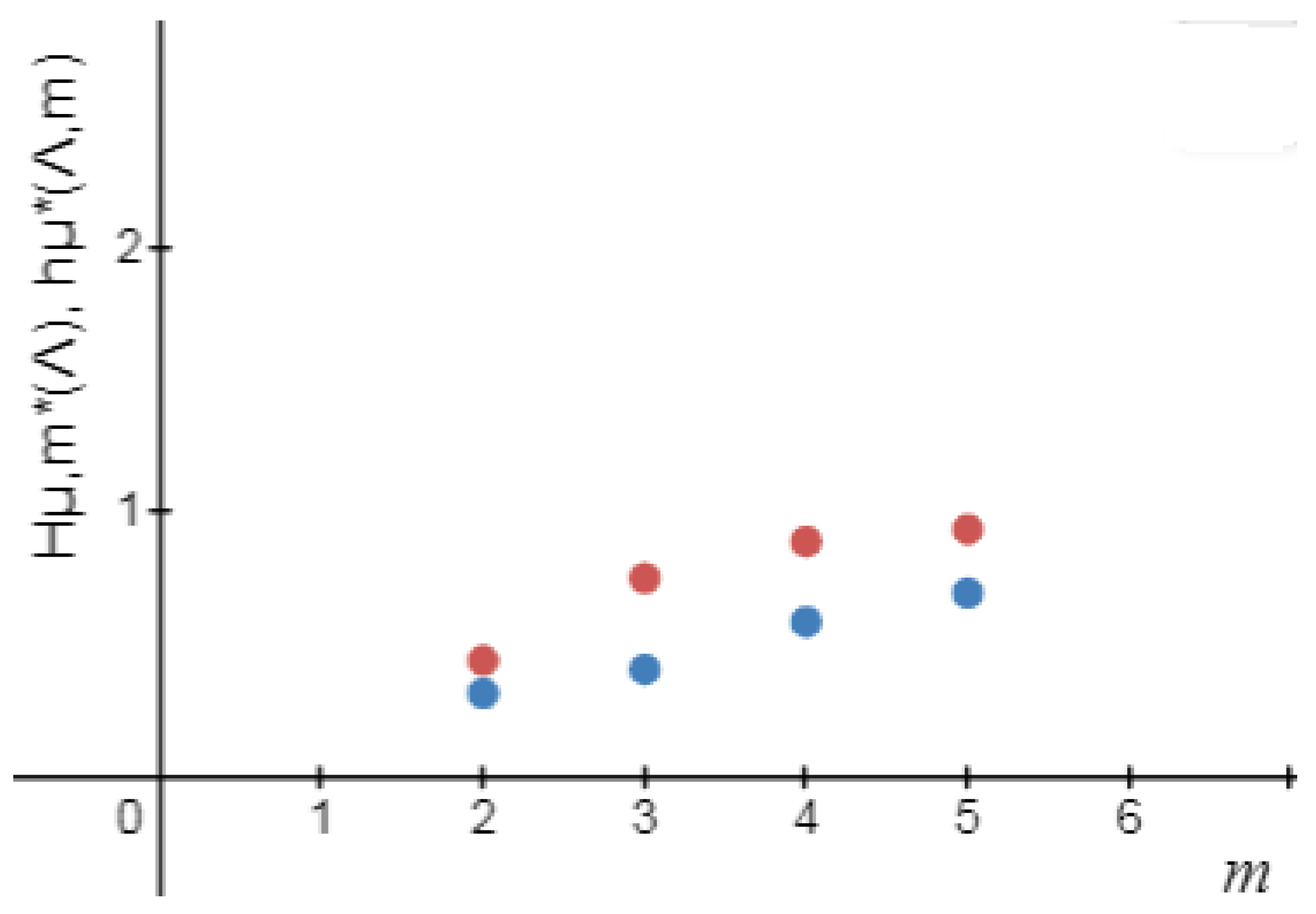
Definition 4. The logical metric permutation entropy of order m of source defined by Lemma 2. For a , , the sequence of increases. Thus, exists.
Proof. According to (
1),
for every
. Therefore,
and
□
Definition 5. The logical Shannon entropy of source is defined by Definition 6. The logical metric permutation entropy of source is defined by Remark 1. Let m be a positive integer number. Then and .
Lemma 3. Let be an information source. Then the following holds:
- 1.
for every.
- 2.
.
Proof. If
, then
□
Theorem 4. Suppose that represents an information source on Γ with the discrete finite state space .
- 1.
If and , then - 2.
Lemma 4. Let represent an information source on Γ with the discrete finite state space , then , and equality holds if and only if for every .
Proof. By Theorem 4, . If , then by the use of Theorem 4 we obtain . Hence . Therefore . Thus for every . On the other hand if for every , then . Therefore and by Theorem 4 has and thus . □
Definition 7. Let , the conditional probability function defined by . In general, for , the conditional probability function is defined by .
Lemma 5. Let be a word. Thenwhere and . Proof. We prove the lemma by induction. If
, have
. Thus, the statement is true for
. Now suppose the statement is true for
, we give reasons for
.
which completes the proof. □
Definition 8. Let and be two random variables on Γ. We define the conditional logical entropy of given byNote: if , define . Definition 9. Suppose are m random variables on Γ. Define the conditional logical entropy of given by Lemma 6. Suppose are m random variables on Γ, then Proof. According to Definition 9, we obtain
□
Lemma 7. Let be a stationary finite space , then Proof. Since
is stationary,
which yields (
5). □
Theorem 5. Let be a stationary finite space , with discrete finite state space . Then the sequence of conditional logical entropies decreases.
Proof. Under the notation of Definition 3, define
and
where
. Furthermore, assume that
where
and
. It is easy to see that
for every
, and
for every ordered pair
. Therefore,
for every
. For obvious reasons,
for each
,
for every
and
. Consequently,
and
and
for every
.
Using Theorem A1 and Lemma 7, we deduce that
With the use of Theorem A1, we obtain
this means that the sequence of conditional logical entropies
is decreasing, so
□
Corollary 2. Let be a source. Then the limit exists.
Lemma 8. Let be a stationary finite space . Then Proof. Since
is stationary,
which completes the proof. □
Theorem 6. Let be a stationary finite space . Then Proof. According to Lemma 7,
Theorem 6 is thus proved. □
Theorem 7. Let and be two random variables on Γ. Then the following hold:
- 1.
- 2.
.
Proof. Using the definition of condition logical entropy, we deduce
which completes the proof.
From the previous part, and since
, we have
□
Theorem 8. Let be an information source. Thenwhere . Proof. According to Lemma 6, we obtain
hence the theorem is proven. □
Theorem 9. Let be an information source. Then Proof. By the use of Theorem 8, we obtain
which completes the proof. □
Definition 10. An independent information source, , is a source with the following propertyfor all . Theorem 10. Let be an independent information source. Thenfor every . Proof. Since
is an independent random variables, we have
The result follows from (
6). □
Theorem 11. Suppose that is an independent information source and . Then .
Proof. In view of Theorem 10 and Lemma A2, we conclude that
Since
,
. Hence,
□
Theorem 12. Let be an independent information source. Thenfor every . Proof. Since
is an independent source,
which is the desired result. □
Theorem 13. If is an independent information source, then
- 1.
- 2.
If there exists , such that , then .
Proof. Hence, . □
Definition 11. Let and be two random variables on Γ. Define the logical mutual information of and by Lemma 9. Let and be two random variables on Γ. Then the following hold:
- 1.
.
- 2.
.
- 3.
.
- 4.
.
- 5.
If and are independent random variables, then
Proof. - 1–3.
follows from Definition 11 and Theorem 7.
- 4.
According to Lemma 3,
. Therefore,
- 5.
It follows from Lemma 12 that
Hence, the result follows from 2. □
Definition 12. Let be an information source. Define the logical mutual information of ,…, by Lemma 10. Let and be two random variables on Γ. Then Proof. It follows from Theorem 8 that
and from Theorem 3 that
. Hence,
This means that □
Theorem 14. Let and be two random variables on Γ. Then the following holds: Proof. From Lemma 9, it follows that
Furthermore, Theorem 3 yields
. Hence,
Similarly,
; therefore,
On the other hand, (
2) yields
Therefore,
and, thus,
□









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}