1. Introduction
Multi-source information fusion refers to the processing and fusion of data collected from diverse knowledge sources or sensors. It is now used in many fields such as fault diagnosis [
1], life-cycle prediction of engineering parts [
2], recommendation systems [
3], and medical diagnosis [
4], etc. The fusion algorithm for multi-source information must seriously consider the evaluation of different attributes because the impacts of different attributes on the fusion results may be diverse. However, information involved in fusion is often imperfect, mainly in terms of uncertainty, imprecision, incompleteness, ambiguity, multiplicity, conflict, etc. [
5]. How to use multi-source information more efficiently has become a challenge. The techniques commonly applied to address uncertain information modeling and fusion include Bayesian estimation [
6], fuzzy theory [
7], Kalman filter theory [
8], artificial neural network theory [
9], DS evidence theory [
10], etc.
Among the above methods, DS evidence theory enables representing and managing uncertainty without a priori information and expressing “uncertain” and “imprecise” information. By modeling the problem, DS evidence theory is able to process the data more appropriately in the fusion process, which can improve the accuracy of fusion and make the decision results more informative. DS evidence theory is widely applied by researchers in the multi-source information fusion field for classification [
11,
12,
13], decision-making [
14], and so on.
DS evidence theory was first proposed by Dempster [
15] in 1967 to address the multi-valued mapping dilemma using upper and lower probabilities, and Dempster’s combination rule was also proposed in it. The DS evidence theory was further extended and refined by Shafer [
16], who introduced the concept of trust function to form a “mathematical theory of evidence”. Nonetheless, there are shortcomings in DS evidence theory, especially for Dempster’s rule of combination [
17,
18,
19]. For example, the inability to resolve situations of severe or complete conflicts of evidence. Conflict of evidence means that the evidence involved in the calculation supports conflicting results. Many works focus on this issue.
One is to investigate the determination methods of BPAs [
20]. Researchers who study this perspective believe that using different BPA determination methods can make the BPAs obtained from raw data conversion contain more valid information, and it will be easier to obtain the correct fusion results subsequently [
21]. The BPA determination methods are divided into function-based BPA determination and intelligent algorithm-based BPA determination. Among the function-based BPA determination methods, the triangular fuzzy function-based BPA construction method is the most employed owing to its simple construction [
22,
23]. In addition, there are methods to generate BPA using trapezoidal fuzzy functions [
24], Gaussian fuzzy functions [
25], etc. The function-based determination generally has the advantage of being simpler and less time-consuming to compute, but the loss or bias of information is larger. For intelligent algorithms, researchers use methods such as gray correlation function BPA [
26] and kernel density estimation [
27] to establish BPA. Intelligent algorithm-based BPA determination is better, but the complexity is often much greater than the combination rule, where computational cost and rewards are not well balanced.
The next perspective of improvement is the modification of Dempster’s combination rules, especially for the method of conflict evidence fusion. Researchers who have studied this point of view believe that this result arises due to the shortcomings of Dempster’s combination rule itself, which leads to discarding when processing conflicting data [
28,
29,
30]. Yager [
31], for example, eliminated the normalization process of Dempster’s combination rule and proposed a new combination rule that used coercion to assign highly conflicting information to the public, which reduced the impact of evidence conflicts, although this combination rule no longer guaranteed the associative law and the commutative law; Jiang and Zhan [
30] proposed mGCR (modified generalized evidence theory), which made the combination result contain more obvious geometric features and the physical meaning of the original GCR; Smarandache and Dezert [
32] proposed a new DSmT theory based on DS evidence theory, where the representation of evidence was no longer represented by a single BPA but consisted of an independent source of evidence and a related source of evidence, both of which were involved in the computation of the combination of the evidence. The strategy of modifying the rules of Dempster’s combination rules has been shown to be effective in some works. However, modifying the rules means that the new rules may result in the method no longer satisfying the constraints of the DS evidence theory. It is possible that the properties of evidence will change, which may lead to uncontrollable results.
The third perspective is to modify the evidence sources before fusing them to make them more reasonable logically [
33,
34]. Scholars believe that the problem mentioned arises from the drawback of evidence sources rather than combination rules. Murphy [
35] obtained a preliminary-fused BPA by averaging the BPAs of multiple sources with the same focal element separately to achieve the reduction in conflict degree; Song et al. [
36] composed a support matrix (SDM) between BPAs by means of Euclidean distance to take into account the associations and conflicts between the evidence. This method improves the accuracy and anti-interference ability of the combined results but is computationally complex. Weng et al. [
37] argued that the degree of blurring of BPAs has become larger as the number of focal elements included increased. Therefore, a method of reconstructing the BPA was proposed to reflect the relationship between different focal element BPAs. By reassigning the BPAs, the uncertainty was reduced; Yin [
38] proposed the negation of BPAs so that the uncertain information contained in the BPAs came from both positive and negative aspects to improve the accuracy of fusion. Moreover, Wu et al. [
39] adapted DS evidence theory to tunnel collapse risk analysis. Wu et al. employed a normal cloud model, probabilistic support vector machines (SVM) and a Bayesian network to assign BPAs from statistical data, sensors and expert assessments, respectively. Moreover, the above BPAs were fused and participated in the calculation of Dempster’s combination rule. This approach achieved a high accuracy rate in assessing risk from multiple dimensions. However, its achievement was based on sacrificing a large amount of data collection and processing time, model training time, and computing time.
In this work, the DS evidence theory is modified from two perspectives: the determination of the initial BPAs and the evidence preprocessing. The main motivation is as follows:
Since the initial BPAs have a significant influence on the fusion results, Gaussian functions estimated by the maximum likelihood method are used for determining the initial BPAs. To enhance the generalizability of the method, we assume that the multi-source information involved in the fusion obeys a complex nonlinear joint distribution, and they are distributed normally. This hypothesis has proven to be valid and widely accepted [
40]. Therefore, it is conventional to use Gaussian functions to build the initial BPA determination model. Furthermore, original data will be padded with the mean of the data correspondingly before being estimated by the maximum likelihood method in order to improve generalizability and mitigate overfitting due to the over-dependence on the provided data. The padding strategy was first used in mathematical statistics to supplement missing information or to reduce dimensionality [
41,
42]. Lopez-Martin et al. proved that embedding the features of samples into the mapping space was beneficial for improving the accuracy of detection [
43]. They embedded sample labels in self-supervised learning networks to accomplish network intrusion detection.
To improve the ability to discern the uncertainty of information, a variety of methods are applied to extract more valid information from the original sources. Referring to Weng et al.’s method [
37], the BPA is firstly reconstructed by assigning the original BPAs, and the BPAs’ values with high degrees of uncertainty are partially assigned to the BPA of the subset focal elements. Additionally, referring to Yin’s research [
38] on the negation of BPA, the reconstructed BPA of the subset focal elements is improved by the negation of BPA to enhance the representation of BPA uncertainty information. We denote the result of the calculation after the above process as nrBPA. Such processing can reduce the uncertainty of BPAs while ensuring the uncertainty of BPAs, which makes the final information involved in DS fusion richer and can improve the accuracy of decision-making.
To reduce the impact of conflicting information from each source on the DS evidence fusion and to make the fusion results more robust. First, improved belief entropy is employed to measure the information entropy of information from each source. Then the initial fusion BPAs are calculated by the entropy weighting method based on the improved belief entropy, which will be involved in the subsequent Dempster’s combination rule calculation to obtain the results.
The steps to complete the multi-source information fusion using the proposed method can be divided into four steps. First, the initial BPAs are obtained using the multi-source information data set; secondly, the initial BPAs are reconstructed into nrBPAs through a series of normalization and uncertain information retention methods; in the third step, the improved belief entropy of nrBPAs is served as the information entropy. The inverse normalization results of information entropies are used as weights of mass function to synthesize several known pieces of evidence into preliminary-fused BPAs; finally, Dempster’s combination rule is used for accomplishing data fusion.
The remainder of the article is organized as follows. In the second part, some preparatory knowledge is briefly introduced. In the third part, a multi-source information fusion method based on DS evidence theory with a strategy of nrBPA and padded Gaussian BPA function is proposed. The fourth part numerically demonstrates this fusion method based on the UCI data set. The fifth part discusses the effectiveness of improving the fusion results and compares the performance with other evidence-theoretic-based methods using cross-validation. The sixth part draws conclusions.
3. Proposed Method
We propose a multi-source information fusion method based on the DS evidence theory with padded Gaussian BPA function and nrBPA. The method remedies the traditional DS evidence theory defects, including the inaccuracy of the calculation when the evidence conflicts severely or completely, the inability to recognize the uncertainty degree of BPA and the poor robustness.
To begin with, because the determination from the original BPA is the basis for the DS evidence theory, the determination results are closely related to the fusion results. Scholars have attempted in many ways to generate BPA to make it more useful for subsequent calculations, such as the method of fuzzy triangular affiliation function, interval generation, kernel function, etc. In our work, Gaussian functions with padding terms with mean values are utilized as the BPA functions. Complex distributions in reality are often close to Gaussian distributions, and such methods of fitting realistic distributions by means of Gaussian functions have also proven to be effective [
40]. The comparison of the efficiency of our method with other determination methods is shown in
Section 5.1.1. Inspired by the mean interpolation method in statistics, which is widely accepted to fill in defective data [
41,
42], we believe that when the amount of raw data is small, or incomplete, or jitter has a significant impact on the robustness of the method, overfitting is likely to occur. To improve the robustness of our method, the Gaussian functions are padded with mean data under a certain ratio. It makes the confidence level obtained closer to the mean value, so that the interference caused by some outliers is reduced and the overfitting of our method is alleviated. The effectiveness of this strategy will also be discussed in
Section 5.1.2 based on the iris classification task. According to the outcome, we set the padding ratio to 40% as the default padding ratio of the method because this allows the method to guarantee better performance on both small and larger data sets (corresponding in the experiments as the ratio of samples participating in the training of the method) while ensuring that the BPA assignment model is determined by the information of the real data as much as possible. The padding ratio can be adjusted for different sizes of data sets for information fusion tasks in order to achieve better performance.
On the other hand, we believe that the degree of uncertainty and ambiguity of the evidence should be taken into account. The uncertainty of the evidence refers to the focal elements contained in the evidence. The greater the variety of focal elements contained in the evidence, the greater the uncertainty of the evidence, and the more possibilities for fusion results. Consequently, the uncertainty makes it easier to obtain correct fusion results. Therefore, we aim to find a representation that adequately reflects the uncertainty of BPA. Yin et al., proved the modified negation of BPA [
38]. Based on the above viewpoint, we define a BPA representation: negation of reconstructed BPA, which is later abbreviated as nrBPA. First, the initial BPA is reconstructed using the method [
37] by combining the degree of uncertainty of each BPA within the initial BPA, which both enhances the deterministic discriminative information and retains the uncertainty of the original BPA information. The degree of uncertainty of a BPA is defined as the number of focal elements contained in the BPA. The higher the number of focal elements, the vaguer the BPA is, and the lower the number of focal elements, the clearer the BPA is. The method [
38] is then cited to generate the negation of reconstructed BPA. By considering the degree of dispersion of focal elements, more information was collected from both the positive and negative sides of BPA, and BPA becomes more uncertain. Moreover, it is pleasant that when the BPA degenerates to probability, the DS evidence will degenerate to a Bayesian distribution, and the negation of the BPA will also degenerate to the negation of probability. The result obtained from the above two steps is employed as the nrBPA. In addition, the difficulty of having 0 values in BPA using Gaussian BPA functions is discovered. BPAs are likely to obtain the same number of focal elements as all elements in FOD. This can lead to difficulties in measuring the uncertainty before different BPAs. Therefore, before performing Dempster’s combination rule, the improved belief entropy proposed by Yan and Deng [
51] is referred to measure the lateral importance between heterogeneous sources of information. The improved belief entropy considers not only different totals but also variations in entropy values between BPAs with the same total but different elements, which is suitable for evaluating the nrBPAs.
In the proposed method, the first part is to construct a Gaussian BPA function. It is worth noting that besides the training data, each Gaussian function is padded with a certain percentage of data with the mean value of the training data to alleviate the over-fitting when the information in the data set is insufficient. The information to be fused is transformed into the initial BPAs by padded Gaussian BPA functions. After that, the initial BPAs are transformed into the nrBPAs, and the specific implementation process is divided into two steps. In the first step, the initial BPAs are reconstructed by assigning some values of the BPAs with high uncertainty to those with low uncertainty ones associated with them to reduce the uncertainty of the overall evidence. Since not all values of BPAs with high uncertainty are involved in the assignment, the type of focal elements contained in the evidence remains unchanged, and thus.,the uncertainty of the evidence is preserved; in the second step, the reconstructed BPAs are transformed in the way of negation. The negation of BPA caused the BPAs to contain increased uncertainty information from both positive and negative sides. Up to this point, nrBPAs have been generated. Again, the heterogenous nrBPAs are synthesized by the entropy weighting method into the preliminary fused BPAs. Finally, the final fusion results are obtained by Dempster’s combination rule using preliminary fused BPAs. The steps to achieve multi-source fusion using the method we proposed are shown in
Figure 1. For ease of understanding, we show the change process of BPA in
Figure 2. The detailed steps of the method are described as follows.
Step 1
Establishing the initial Gaussian BPA determination model. In order to transform the data into the initial BPAs, a Gaussian model was chosen, and the steps to build it are shown below.
Step 1.1. Obtaining the feature data set of known fusion results. The set of known fusion results
, which correspond to the identification framework
in DS evidence theory, and
are the fusion results, which correspond to the elements in DS evidence theory. The data set is represented as:
Step 1.2. Let
N be the total number of data, the original data structure of each sample to be fused is assumed as:
where
is each feature value, the last bit
is the fusion result,
, and
M is the number of feature dimensions.
Step 1.3. The individual features of the training data are involved in estimating parameters of the Gaussian function by the maximum likelihood method. Notably, in order to avoid overfitting of the generated Gaussian model, each feature is supplemented with a certain proportion of data with the value of the mean when calculating the variance. For example, if the original training data volume is , where N is the total, is the training proportion. For a feature, suppose the mean value of a certain event is , and the filling proportion is p, where . Then, samples with the value of will be filled, and the size of the padded data set is .
Using the padded data set, the combination of the mean and variance of each feature on each category
is calculated with reference to Equation (
13). It is easy to obtain combinations of size
, constructed as
.
G is the set of Gaussian probability density functions.
,
, is the set of Gaussian distributed probability density functions for each fusion result under the specified features.
Each
is shown in Equation (
14), which is obtained by substituting the corresponding combination of mean and variance into the Gaussian probability distribution function.
Step 2
Determining the initial BPAs. The given data for each of the objects to be fused are input according to the structure
. The obtained input data
are substituted into the corresponding functions in the set of Gaussian probability density functions composed of Step 1.1, Step 1.2, and the initial BPAs can be obtained. Let the elements
be sorted from smallest to largest by the values obtained after bringing in the corresponding probability density functions.
are the values of the Gaussian functions of the feature values substituted into each fusion result, respectively, the corresponding BPAs are calculated as below.
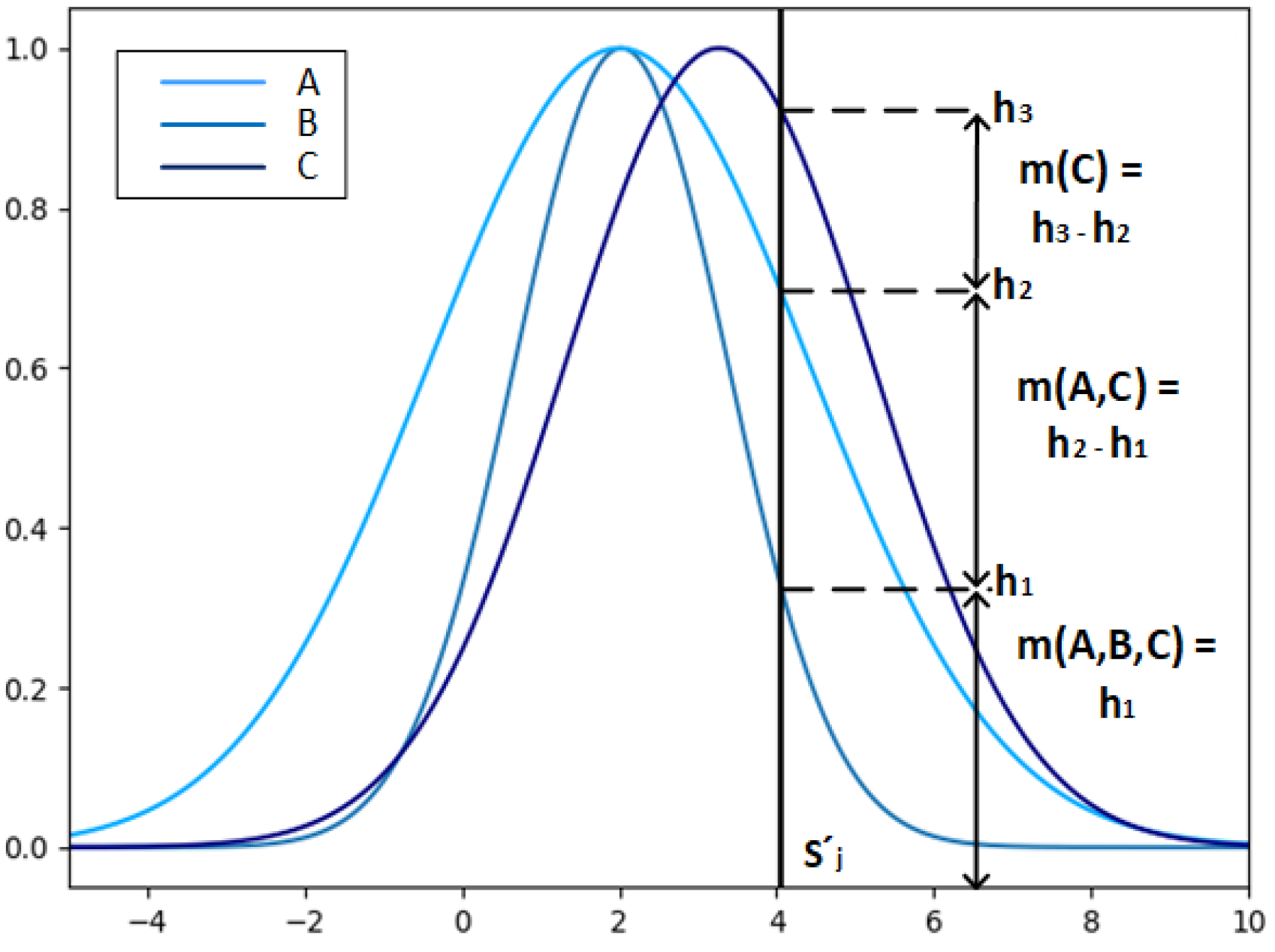
Let
, and the schematic diagram of the BPA calculation is shown in
Figure 3. The horizontal coordinate value of the thick black line represents the feature value
, and the intersection points
are the intersection points of the feature value
and the Gaussian function of the fusion results B, A and C under the feature
, respectively, which determines the BPA about the feature value: values of
m(
C),
m(
A,
C),
m(
A,
B,
C).
Step 3
Converting the initial BPAs to nrBPAs. The transformation of the original BPA to nrBPA is achieved using approaches from reference [
37] and the method of reference [
38]. The specific implementation steps are as follows.
Step 3.1. For a BPA, the more elements pointed to, the greater the uncertainty of that BPA and the more ambiguous the information contained. Weng et al.’s method [
37] is proved to measure the uncertainty of BPA and reduce the information uncertainty. For all BPAs according to Equation (
15).
where
are the focal elements of
is a modulo operation on
, which is also equal to the number of elements contained in
represents the number of possible outcomes in
, which is a measure of uncertainty, and n is the number of focal elements contained in
. With this operation, not only does each BPA’s data come from itself but from its upper sets, measuring the degree of association between individual BPAs. When the focal element of a BPA is
, its only source of data is itself.
Step 3.2. The reconstructed BPAs are normalized according to Equation (
16) in order to comply with the construction criterion of the BPA and to facilitate the subsequent operations.
Step 3.3. The reconstructed BPAs are transformed into nrBPAs,
. By exploring both positive and negative information of the evidence through Yin et al.’s method [
38], the inverse of the BPAs is obtained through Equation (
6).
Step 4
The fusion results of heterogenous information are weighted using the entropy weighting method. The entropy weighting method has the ability to take the importance of heterogeneous sources of information into account. The specific steps are as follows.
Step 4.1. The uncertainties of BPAs are measured by improved belief entropy [
51]. Equation (
8) is applied to obtain the information entropy of each BPA, denoted as
.
Step 4.2. Equation (
9) is referenced to convert the information entropy into weights to obtain
.
Step 4.3. The final BPAs of each focal element are obtained by multiplying the obtained BPAs with their corresponding weight value obtained by the entropy weight method and then multiplying the BPAs of different BPAs but the same focal element to obtain the final BPA of each focal element. Take the focal element
belonging to
as an example,
M is the total number of features, and the final BPA A
is calculated as Equation (
17).
Step 5
Further fusion through Dempster’s combination rule. The final BPA is combined M-1 times using the DS evidence theory combination algorithm,
M is the total number of feature types, ⨁ denotes the calculation of Equation (
5), and the fusion equation is as Equation (
18).
Step 6
The fusion conclusion is obtained by comparing the combined results. Considering that the BPA was flipped by using negation, the smallest value is chosen as the highest confidence fusion conclusion.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}