
Testing for Serial Correlation in Autoregressive Exogenous Models with Possible GARCH Errors


Abstract
:1. Introduction
2. Methodologies and Main Results
- A1. are a strictly stationary sequence with the initial value being a constant vector.
- A2. are Martingale difference sequences to the sigma field .
- A3. almost surely.
- A4. for some almost surely.
- A5. and all roots of are inside the unit circle.
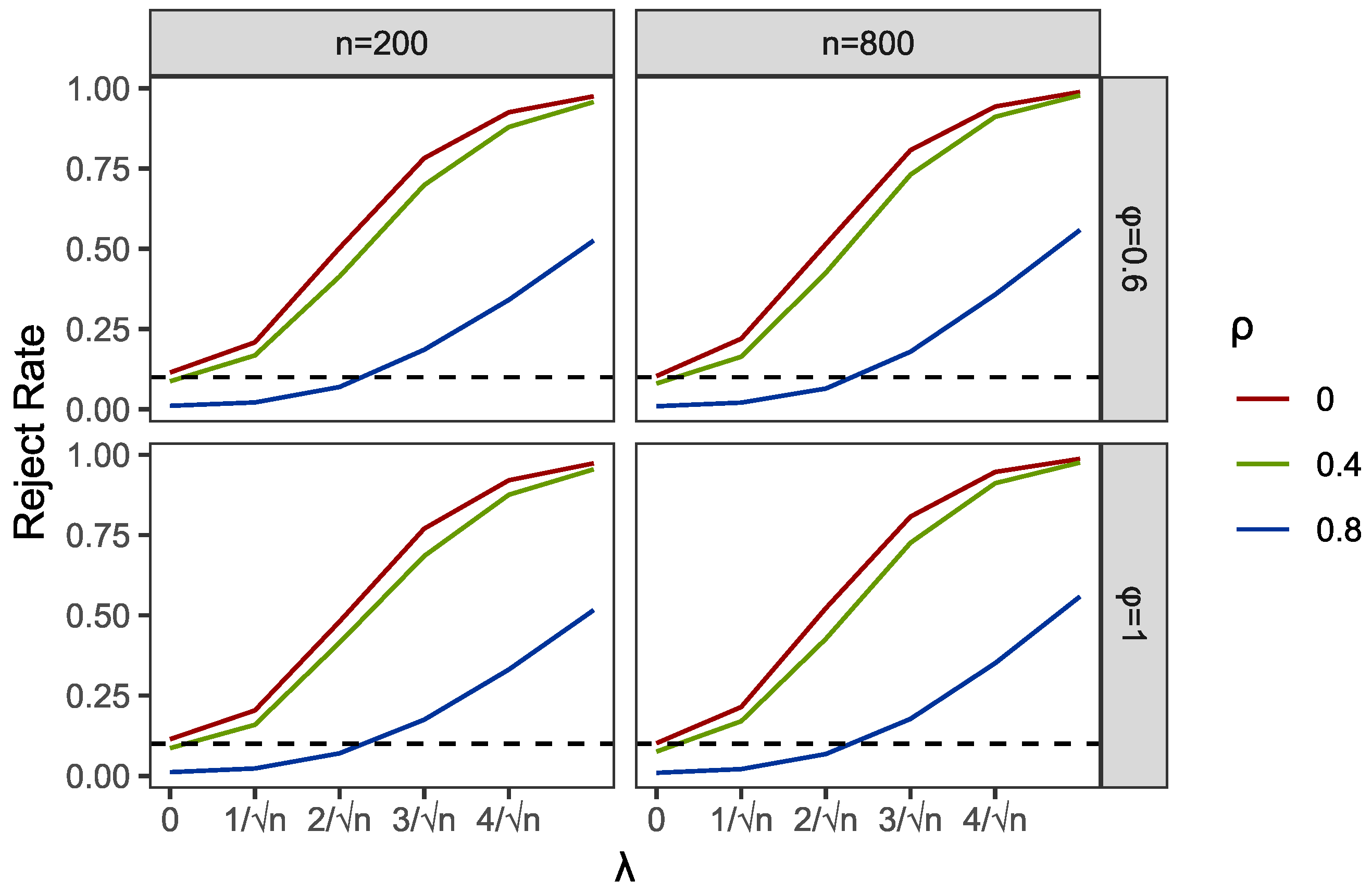
3. Simulation Studies
4. Real Applications
4.1. A Financial Example
4.2. An Environmental Example
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proofs of the Main Results
References
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Yule, G.U. On a method of investigating periodicities in disturbed series with special reference to Wölfer’s sunspot numbers. Philos. Trans. R. Soc. Lond. Ser. A 1927, 226, 267–298. [Google Scholar]
- Stambaugh, R.F. Predictive regressions. J. Financ. Econ. 1999, 54, 375–421. [Google Scholar] [CrossRef]
- Warsono, W.; Russel, E.; Wamiliana, W.; Widiarti, W.; Usman, M. Vector autoregressive with exogenous variable model and its application in modeling and forecasting energy data: Case study of PTBA and HRUM energy. Int. J. Energy Econ. Policy 2019, 9, 390–398. [Google Scholar]
- Astuti, D.; Ruchjana, B.N. Generalized space time autoregressive with exogenous variable model and its application. J. Phys. Conf. Ser. 2017, 893, 012038. [Google Scholar] [CrossRef]
- Bauer, G.; Deistler, M.; Scherrer, W. Time series models for short term forecasting of ozone in the eastern part of Austria. Env. Off. J. Int. Env. Soc. 2001, 12, 117–130. [Google Scholar] [CrossRef]
- Chen, C.W.; Chiu, L.M. Ordinal time series forecasting of the air quality index. Entropy 2021, 23, 1167. [Google Scholar] [CrossRef]
- Dickey, D.A.; Fuller, W.A. Distribution of the estimators for autoregressive time series with a unit root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar]
- Said, S.E.; Dickey, D.A. Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 1984, 71, 599–607. [Google Scholar] [CrossRef]
- Bierens, H.J. Least squares estimation of linear and nonlinear ARMAX models under data heterogeneity. Ann. D’Econom. Stat. 1990, 143–169. [Google Scholar] [CrossRef]
- Cai, Z.; Masry, E. Nonparametric estimation of additive nonlinear ARX time series: Local linear fitting and projections. Econom. Theory 2000, 16, 465–501. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Chan, K.S. Quasi-likelihood estimation of a censored autoregressive model with exogenous variables. J. Am. Stat. Assoc. 2018, 113, 1135–1145. [Google Scholar] [CrossRef]
- Durbin, J.; Watson, G.S. Testing for serial correlation in least squares regression: I. Biometrika 1950, 37, 409–428. [Google Scholar]
- Box, G.E.; Pierce, D.A. Distribution of residual autocorrelations in autoregressive-integrated moving average time series models. J. Am. Stat. Assoc. 1970, 65, 1509–1526. [Google Scholar] [CrossRef]
- Ljung, G.M.; Box, G.E. On a measure of lack of fit in time series models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Maddala, G.S.; Lahiri, K. Introduction to Econometrics; Macmillan: New York, NY, USA, 2009. [Google Scholar]
- Francq, C.; Roy, R.; Zakoïan, J.M. Diagnostic checking in ARMA models with uncorrelated errors. J. Am. Stat. Assoc. 2005, 100, 532–544. [Google Scholar] [CrossRef]
- Zhu, K. Bootstrapping the portmanteau tests in weak auto-regressive moving average models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2016, 78, 463–485. [Google Scholar] [CrossRef] [Green Version]
- Owen, A.B. Empirical likelihood for linear models. Ann. Stat. 1991, 19, 1725–1747. [Google Scholar] [CrossRef]
- Breusch, T.S. Testing for autocorrelation in dynamic linear models. Aust. Econ. Pap. 1978, 17, 334–355. [Google Scholar] [CrossRef]
- Godfrey, L.G. Testing against general autoregressive and moving average error models when the regressors include lagged dependent variables. Econom. J. Econom. Soc. 1978, 46, 1293–1301. [Google Scholar] [CrossRef]
- Mandelbrot, B. New methods in statistical economics. J. Political Econ. 1963, 71, 421–440. [Google Scholar] [CrossRef]
- Cont, R. Volatility clustering in financial markets: Empirical facts and agent-based models. In Long Memory in Economics; Springer: Berlin/Heidelberg, Germany, 2007; pp. 289–309. [Google Scholar]
- Ding, Z.; Granger, C.W. Modeling volatility persistence of speculative returns: A new approach. J. Econom. 1996, 73, 185–215. [Google Scholar] [CrossRef]
- Ding, Z.; Granger, C.W.; Engle, R.F. A long memory property of stock market returns and a new model. J. Empir. Financ. 1993, 1, 83–106. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econom. J. Econom. Soc. 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Qin, J.; Lawless, J. Empirical likelihood and general estimating equations. Ann. Stat. 1994, 22, 300–325. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, J. Adjusted empirical likelihood with high-order precision. Ann. Stat. 2010, 38, 1341–1362. [Google Scholar] [CrossRef] [Green Version]
- Campbell, J.Y.; Yogo, M. Efficient tests of stock return predictability. J. Financ. Econ. 2006, 81, 27–60. [Google Scholar] [CrossRef] [Green Version]
- Davis, J.M.; Eder, B.K.; Bloomfield, P. Modeling Ozone in the Chicago Urban Area. In Case Studies in Environmental Statistics; Springer: New York, NY, USA, 1998. [Google Scholar]
- Liu, Q.; Liu, X. Limit theory for an AR (1) model with intercept and a possible infinite variance. arXiv 2018, arXiv:1802.10299. [Google Scholar]
- Phillips, P.C. Time series regression with a unit root. Econom. J. Econom. Soc. 1987, 55, 277–301. [Google Scholar] [CrossRef]
- Phillips, P.C. Towards a unified asymptotic theory for autoregression. Biometrika 1987, 74, 535–547. [Google Scholar] [CrossRef]
- Hall, P.; Heyde, C.C. Martingale Limit Theory and Its Application; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Owen, A.B. Empirical Likelihood; Chapman and Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PEL | PI | BG | PEL | PI | BG | PEL | PI | BG | PEL | PI | BG | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (0, | 0.6, | 0.6, | 0) | 0.0596 | 0.0348 | 0.0579 | 0.0480 | 0.0311 | 0.0508 | 0.0620 | 0.0371 | 0.0534 | 0.0513 | 0.0316 | 0.0507 |
| (0, | 0.6, | 0.6, | ) | 0.3657 | 0.2867 | 0.3600 | 0.4042 | 0.3191 | 0.4019 | 0.3617 | 0.2775 | 0.3597 | 0.4052 | 0.3137 | 0.3980 |
| (0, | 0.6, | 0.6, | ) | 0.9163 | 0.8760 | 0.9236 | 0.9423 | 0.9092 | 0.9389 | 0.9175 | 0.8782 | 0.9186 | 0.9387 | 0.9003 | 0.9332 |
| (0, | 1, | 0.6, | 0) | 0.0583 | 0.0410 | 0.0538 | 0.0528 | 0.0359 | 0.0486 | 0.0593 | 0.0406 | 0.0545 | 0.0534 | 0.0323 | 0.0494 |
| (0, | 1, | 0.6, | ) | 0.3498 | 0.3056 | 0.3582 | 0.4075 | 0.3460 | 0.4131 | 0.3575 | 0.3045 | 0.3567 | 0.4177 | 0.3483 | 0.4115 |
| (0, | 1, | 0.6, | ) | 0.8400 | 0.8919 | 0.9132 | 0.8354 | 0.9195 | 0.9417 | 0.9214 | 0.8910 | 0.9151 | 0.9212 | 0.9261 | 0.9411 |
| (0, | 1, | 1, | 0) | 0.0626 | 0.0391 | 0.0536 | 0.0497 | 0.0359 | 0.0505 | 0.0672 | 0.0421 | 0.0562 | 0.0529 | 0.0345 | 0.0560 |
| (0, | 1, | 1, | ) | 0.3741 | 0.3097 | 0.3521 | 0.4169 | 0.3601 | 0.4120 | 0.3815 | 0.3050 | 0.3450 | 0.4207 | 0.3619 | 0.4170 |
| (0, | 1, | 1, | ) | 0.8943 | 0.8928 | 0.9174 | 0.9267 | 0.9284 | 0.9476 | 0.8876 | 0.8964 | 0.9222 | 0.9238 | 0.9278 | 0.9436 |
| (0.4, | 0.6, | 0.6, | 0) | 0.0571 | 0.0333 | 0.0577 | 0.0496 | 0.0304 | 0.0507 | 0.0573 | 0.0369 | 0.0545 | 0.0510 | 0.0330 | 0.0497 |
| (0.4, | 0.6, | 0.6, | ) | 0.3660 | 0.3002 | 0.3632 | 0.4081 | 0.3361 | 0.4062 | 0.3732 | 0.3052 | 0.3627 | 0.4041 | 0.3423 | 0.4011 |
| (0.4, | 0.6, | 0.6, | ) | 0.9112 | 0.8807 | 0.9155 | 0.9355 | 0.9082 | 0.9374 | 0.9070 | 0.8764 | 0.9141 | 0.9393 | 0.9086 | 0.9392 |
| (0.4, | 1, | 0.6, | 0) | 0.0594 | 0.0421 | 0.0499 | 0.0511 | 0.0389 | 0.0531 | 0.0583 | 0.0437 | 0.0514 | 0.0513 | 0.0363 | 0.0496 |
| (0.4, | 1, | 0.6, | ) | 0.3661 | 0.3273 | 0.3715 | 0.4209 | 0.3747 | 0.4243 | 0.3580 | 0.3309 | 0.3735 | 0.4215 | 0.3734 | 0.4178 |
| (0.4, | 1, | 0.6, | ) | 0.8368 | 0.8986 | 0.9182 | 0.9233 | 0.9333 | 0.9485 | 0.8303 | 0.8974 | 0.9150 | 0.9250 | 0.9298 | 0.9443 |
| (0.4, | 1, | 1, | 0) | 0.0678 | 0.0567 | 0.0520 | 0.0494 | 0.0535 | 0.0486 | 0.0657 | 0.0596 | 0.0513 | 0.0530 | 0.0511 | 0.0514 |
| (0.4, | 1, | 1, | ) | 0.4387 | 0.4227 | 0.4246 | 0.4790 | 0.4782 | 0.4682 | 0.4390 | 0.4275 | 0.4127 | 0.4753 | 0.4727 | 0.4665 |
| (0.4, | 1, | 1, | ) | 0.9156 | 0.9596 | 0.9607 | 0.9497 | 0.9720 | 0.9701 | 0.9181 | 0.9555 | 0.9574 | 0.9454 | 0.9738 | 0.9728 |
| (0.8, | 0.6, | 0.6, | 0) | 0.0532 | 0.0089 | 0.0567 | 0.0538 | 0.0057 | 0.0495 | 0.0544 | 0.0074 | 0.0516 | 0.0502 | 0.0059 | 0.0531 |
| (0.8, | 0.6, | 0.6, | ) | 0.2378 | 0.0703 | 0.2359 | 0.2577 | 0.0787 | 0.2535 | 0.2376 | 0.0677 | 0.2253 | 0.2560 | 0.075 | 0.2717 |
| (0.8, | 0.6, | 0.6, | ) | 0.6951 | 0.4030 | 0.6907 | 0.7485 | 0.4426 | 0.7544 | 0.6938 | 0.3900 | 0.6909 | 0.7519 | 0.4463 | 0.7538 |
| (0.8, | 1, | 0.6, | 0) | 0.0569 | 0.0088 | 0.0516 | 0.0525 | 0.0076 | 0.0487 | 0.0521 | 0.0102 | 0.0539 | 0.0498 | 0.0073 | 0.0512 |
| (0.8, | 1, | 0.6, | ) | 0.2359 | 0.0747 | 0.2316 | 0.2676 | 0.0880 | 0.2744 | 0.2422 | 0.0787 | 0.2436 | 0.2745 | 0.0839 | 0.2684 |
| (0.8, | 1, | 0.6, | ) | 0.6691 | 0.4528 | 0.7067 | 0.7700 | 0.4867 | 0.7752 | 0.6730 | 0.4425 | 0.7066 | 0.7623 | 0.4950 | 0.7653 |
| (0.8, | 1, | 1, | 0) | 0.0616 | 0.0245 | 0.0550 | 0.0516 | 0.0201 | 0.0507 | 0.0604 | 0.0211 | 0.0587 | 0.0513 | 0.0193 | 0.0519 |
| (0.8, | 1, | 1, | ) | 0.3501 | 0.2263 | 0.3254 | 0.3708 | 0.2424 | 0.3566 | 0.3445 | 0.2251 | 0.3293 | 0.3688 | 0.2348 | 0.3648 |
| (0.8, | 1, | 1, | ) | 0.8719 | 0.8202 | 0.8896 | 0.8999 | 0.8254 | 0.9021 | 0.8679 | 0.8205 | 0.8917 | 0.8968 | 0.8266 | 0.9056 |
| PEL | PI | BG | PEL | PI | BG | PEL | PI | BG | PEL | PI | BG | ||||
| (0, | 0.6, | 0.6, | 0) | 0.0653 | 0.0647 | 0.1416 | 0.0560 | 0.0556 | 0.1632 | 0.0658 | 0.0622 | 0.1419 | 0.0542 | 0.0544 | 0.1622 |
| (0, | 0.6, | 0.6, | ) | 0.3660 | 0.3813 | 0.5544 | 0.3794 | 0.3929 | 0.6183 | 0.3707 | 0.3796 | 0.5599 | 0.3734 | 0.4039 | 0.6146 |
| (0, | 0.6, | 0.6, | ) | 0.7632 | 0.8689 | 0.9621 | 0.7591 | 0.8986 | 0.9759 | 0.7583 | 0.8702 | 0.9626 | 0.7594 | 0.9056 | 0.9754 |
| (0, | 1, | 0.6, | 0) | 0.0658 | 0.0612 | 0.1508 | 0.0598 | 0.0526 | 0.1537 | 0.0656 | 0.0620 | 0.1386 | 0.0575 | 0.0520 | 0.1607 |
| (0, | 1, | 0.6, | ) | 0.3486 | 0.3651 | 0.5393 | 0.3756 | 0.3983 | 0.6106 | 0.3391 | 0.3622 | 0.5406 | 0.3785 | 0.3811 | 0.6046 |
| (0, | 1, | 0.6, | ) | 0.6795 | 0.8602 | 0.9516 | 0.7192 | 0.9018 | 0.9745 | 0.6867 | 0.8672 | 0.9595 | 0.7205 | 0.9079 | 0.9760 |
| (0, | 1, | 1, | 0) | 0.0735 | 0.0625 | 0.1473 | 0.0593 | 0.0557 | 0.1631 | 0.074 | 0.0644 | 0.1462 | 0.0565 | 0.0547 | 0.1628 |
| (0, | 1, | 1, | ) | 0.3847 | 0.3627 | 0.5322 | 0.3795 | 0.3876 | 0.6067 | 0.3943 | 0.3628 | 0.5384 | 0.3931 | 0.3917 | 0.6019 |
| (0, | 1, | 1, | ) | 0.8440 | 0.8639 | 0.9536 | 0.7583 | 0.9049 | 0.9770 | 0.8441 | 0.8553 | 0.9570 | 0.7547 | 0.8957 | 0.9767 |
| (0.4, | 0.6, | 0.6, | 0) | 0.0701 | 0.0436 | 0.1410 | 0.0531 | 0.0364 | 0.1524 | 0.0654 | 0.0428 | 0.1395 | 0.0525 | 0.038 | 0.1570 |
| (0.4, | 0.6, | 0.6, | ) | 0.3449 | 0.2963 | 0.5106 | 0.3707 | 0.3024 | 0.5733 | 0.3458 | 0.2924 | 0.5083 | 0.3626 | 0.3064 | 0.5684 |
| (0.4, | 0.6, | 0.6, | ) | 0.7459 | 0.7970 | 0.9408 | 0.7363 | 0.8424 | 0.9654 | 0.7414 | 0.8002 | 0.9412 | 0.7420 | 0.8442 | 0.9633 |
| (0.4, | 1, | 0.6, | 0) | 0.0705 | 0.0437 | 0.1379 | 0.0629 | 0.0338 | 0.1526 | 0.0619 | 0.0456 | 0.1404 | 0.0634 | 0.0398 | 0.1631 |
| (0.4, | 1, | 0.6, | ) | 0.3239 | 0.2936 | 0.4983 | 0.3598 | 0.3038 | 0.5659 | 0.3175 | 0.2895 | 0.4991 | 0.3626 | 0.3042 | 0.5616 |
| (0.4, | 1, | 0.6, | ) | 0.6694 | 0.7881 | 0.9342 | 0.7100 | 0.8444 | 0.9620 | 0.6619 | 0.7910 | 0.9348 | 0.7104 | 0.8379 | 0.9608 |
| (0.4, | 1, | 1, | 0) | 0.0792 | 0.0495 | 0.1408 | 0.0621 | 0.0426 | 0.1637 | 0.0769 | 0.0500 | 0.1389 | 0.0598 | 0.0401 | 0.1524 |
| (0.4, | 1, | 1, | ) | 0.3608 | 0.2868 | 0.4990 | 0.3765 | 0.3153 | 0.5691 | 0.3714 | 0.2909 | 0.4915 | 0.3715 | 0.3173 | 0.5611 |
| (0.4, | 1, | 1, | ) | 0.8265 | 0.7967 | 0.9373 | 0.7412 | 0.8532 | 0.9609 | 0.8196 | 0.7959 | 0.9344 | 0.7477 | 0.8532 | 0.9620 |
| (0.8, | 0.6, | 0.6, | 0) | 0.0644 | 0.0028 | 0.1120 | 0.0513 | 0.0019 | 0.1370 | 0.0632 | 0.0020 | 0.1131 | 0.0584 | 0.0018 | 0.1364 |
| (0.8, | 0.6, | 0.6, | ) | 0.2097 | 0.0266 | 0.3061 | 0.2104 | 0.0226 | 0.3634 | 0.2217 | 0.0269 | 0.2982 | 0.2116 | 0.0251 | 0.3609 |
| (0.8, | 0.6, | 0.6, | ) | 0.5523 | 0.1972 | 0.6954 | 0.5658 | 0.1944 | 0.7821 | 0.5376 | 0.1961 | 0.6979 | 0.5608 | 0.1956 | 0.7789 |
| (0.8, | 1, | 0.6, | 0) | 0.0654 | 0.0035 | 0.1147 | 0.0677 | 0.0029 | 0.1340 | 0.0670 | 0.0031 | 0.1174 | 0.0696 | 0.0021 | 0.1413 |
| (0.8, | 1, | 0.6, | ) | 0.2050 | 0.0285 | 0.2935 | 0.2282 | 0.0235 | 0.3548 | 0.2089 | 0.0311 | 0.2983 | 0.2281 | 0.0227 | 0.3572 |
| (0.8, | 1, | 0.6, | ) | 0.5008 | 0.1909 | 0.6842 | 0.5693 | 0.1922 | 0.7783 | 0.4951 | 0.1909 | 0.6875 | 0.5831 | 0.1941 | 0.7781 |
| (0.8, | 1, | 1, | 0) | 0.0886 | 0.0030 | 0.1205 | 0.0701 | 0.0033 | 0.1344 | 0.0804 | 0.0034 | 0.1253 | 0.0717 | 0.0024 | 0.1379 |
| (0.8, | 1, | 1, | ) | 0.2579 | 0.0333 | 0.2998 | 0.2469 | 0.0311 | 0.3683 | 0.2527 | 0.0316 | 0.2950 | 0.2440 | 0.0281 | 0.3679 |
| (0.8, | 1, | 1, | ) | 0.6173 | 0.2238 | 0.7013 | 0.6097 | 0.2353 | 0.7940 | 0.6122 | 0.2156 | 0.7030 | 0.6139 | 0.2279 | 0.7993 |
| Period | Obs. | Exo. Var. | Results for the Following Values of q | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | |||
| 1927–2002 | 912 | ldp | 0.2727 | 0.1017 | ||||||
| lep | 0.2692 | |||||||||
| 1927–1994 | 804 | ldp | 0.2145 | |||||||
| lep | 0.2317 | |||||||||
| 1952–2002 | 612 | ldp | 0.7848 | 0.8508 | 0.1528 | 0.2762 | 0.4311 | 0.4346 | 0.3533 | 0.4101 |
| lep | 0.7850 | 0.8475 | 0.1466 | 0.2639 | 0.4222 | 0.4401 | 0.3397 | 0.3929 | ||
| tbl | 0.7518 | 0.8740 | 0.1786 | 0.2986 | 0.4620 | 0.4849 | 0.4171 | 0.4522 | ||
| lty | 0.7788 | 0.8742 | 0.1774 | 0.2948 | 0.4628 | 0.4989 | 0.4006 | 0.4401 | ||
| Period | Obs. | Exo. Var. | Test | Results for the Following Values of q | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | ||||
| 1927–2002 | 912 | ldp, lep | PEL | 0.5270 | 0.2376 | 0.1018 | 0.1383 | 0.1858 | |||
| PI | 0.9720 | 0.2891 | 0.1148 | 0.1034 | 0.1287 | 0.1722 | 0.1086 | ||||
| BG | |||||||||||
| 1927–1994 | 804 | ldp, lep | PEL | 0.4398 | 0.1600 | 0.1359 | 0.1984 | ||||
| PI | 0.9958 | 0.2077 | 0.1310 | 0.1957 | |||||||
| BG | |||||||||||
| 1952–2002 | 612 | ldp, lep, tbl, lty | PEL | 0.2836 | 0.4779 | 0.1453 | 0.2582 | 0.2342 | 0.2476 | 0.2862 | |
| PI | 0.6568 | 0.8131 | 0.1910 | 0.3092 | 0.4592 | 0.4027 | 0.3940 | 0.4427 | |||
| BG | 0.2187 | 0.4371 | 0.1084 | 0.2206 | 0.3437 | 0.3155 | 0.2825 | 0.3883 | |||
| Period | Obs. | Test | Results for the Following Values of q | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | |||
| 1 January–26 June | 178 | PEL | 0.2817 | |||||||
| PI | 0.6555 | 0.1883 | 0.2412 | 0.3223 | 0.4602 | 0.3379 | 0.2664 | 0.1787 | ||
| BG | 0.2939 | 0.1029 | 0.1773 | 0.2124 | 0.2545 | 0.3236 | 0.3637 | 0.3682 | ||
| 11 July–31 December | 173 | PEL | ||||||||
| PI | 0.7063 | 0.9547 | 0.8998 | 0.8022 | 0.6021 | 0.5958 | 0.4126 | 0.2402 | ||
| BG | 0.0352 | 0.1856 | 0.2614 | 0.2499 | 0.3011 | 0.2450 | 0.2852 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Liu, X.; Chen, Y.; Fan, Y. Testing for Serial Correlation in Autoregressive Exogenous Models with Possible GARCH Errors. Entropy 2022, 24, 1076. https://doi.org/10.3390/e24081076
Li H, Liu X, Chen Y, Fan Y. Testing for Serial Correlation in Autoregressive Exogenous Models with Possible GARCH Errors. Entropy. 2022; 24(8):1076. https://doi.org/10.3390/e24081076
Chicago/Turabian StyleLi, Hanqing, Xiaohui Liu, Yuting Chen, and Yawen Fan. 2022. "Testing for Serial Correlation in Autoregressive Exogenous Models with Possible GARCH Errors" Entropy 24, no. 8: 1076. https://doi.org/10.3390/e24081076