
Coded Caching for Broadcast Networks with User Cooperation †


Abstract
:1. Introduction
- How does α affect the system performance?
- What is the (approximately) optimal value of α to minimize the transmission latency?
- How can communication loads be allocated between the server and users to achieve the minimum transmission latency?
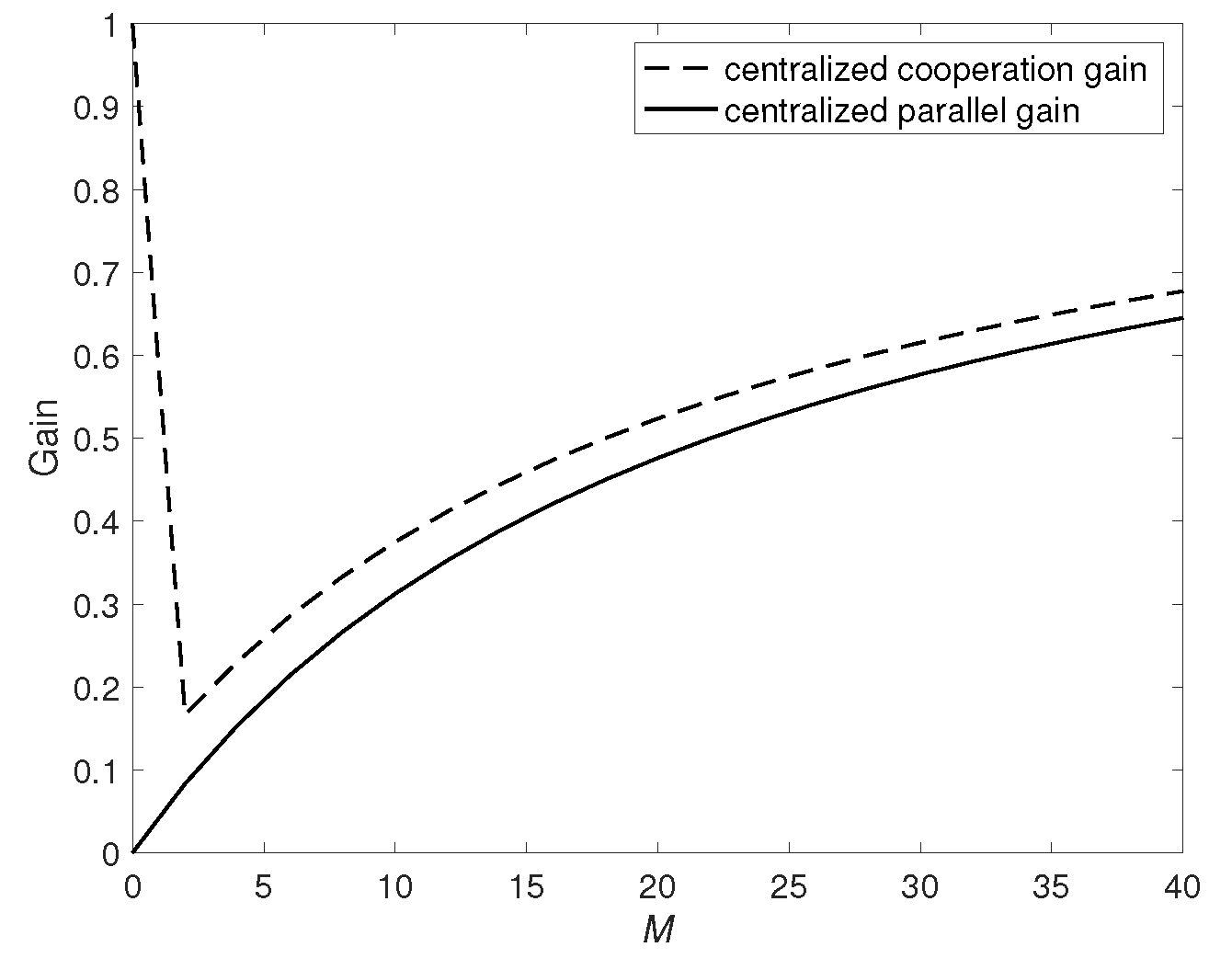
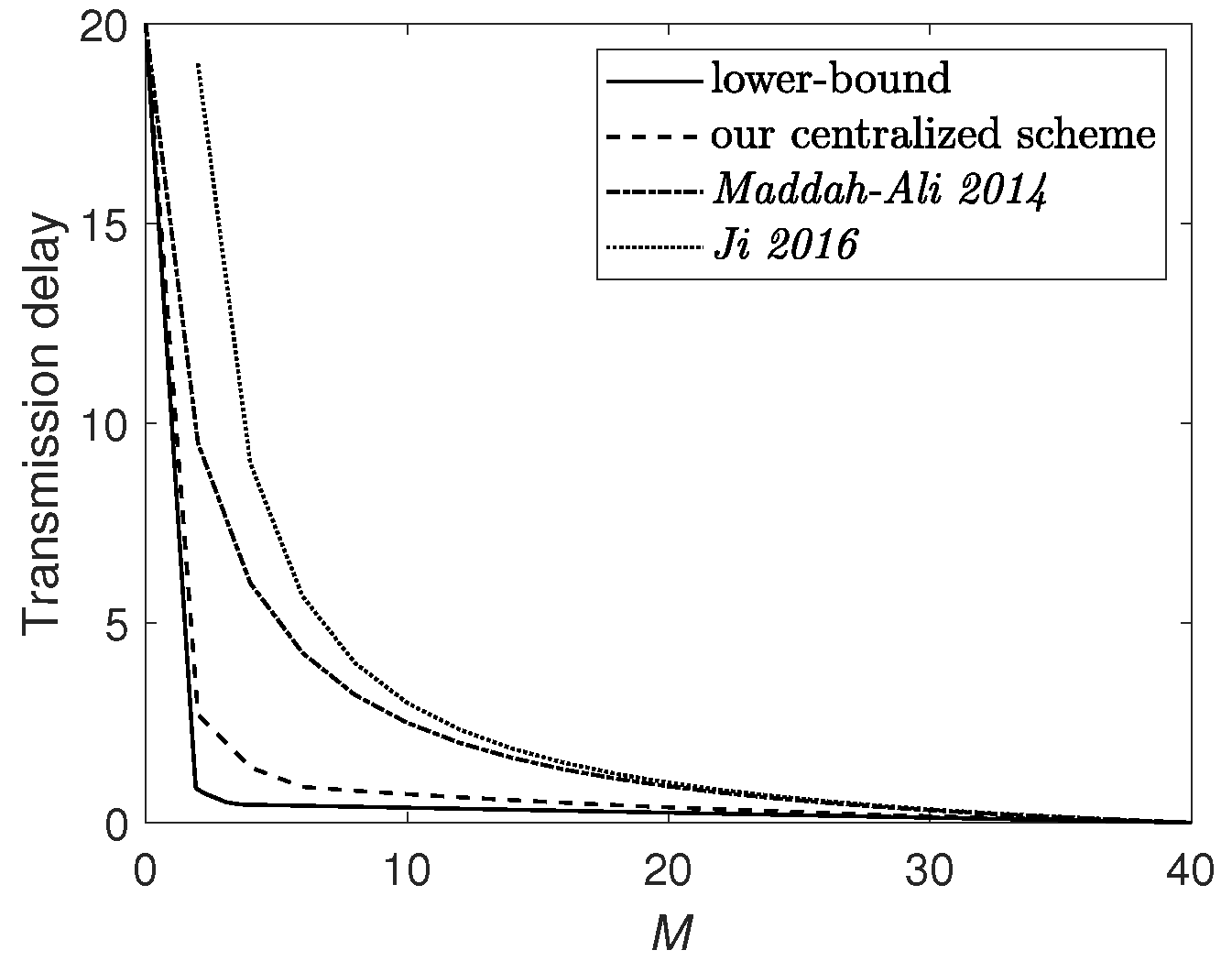
- We propose novel coded caching schemes for this hybrid network under centralized and decentralized data placement. Both schemes efficiently exploit communication opportunities in D2D and broadcast networks, and appropriately allocate communication loads between the server and users. In addition to multicast gain, our schemes achieve much smaller transmission latency than both that of Maddah-Ali and Niesen’s scheme for a broadcast network [1,2] and the D2D coded caching scheme [35]. We characterize a cooperation gain and a parallel gain achieved by our schemes, where the cooperation gain is obtained through cooperation among users in the D2D network, and the parallel gain is obtained through the parallel transmission between the server and users.
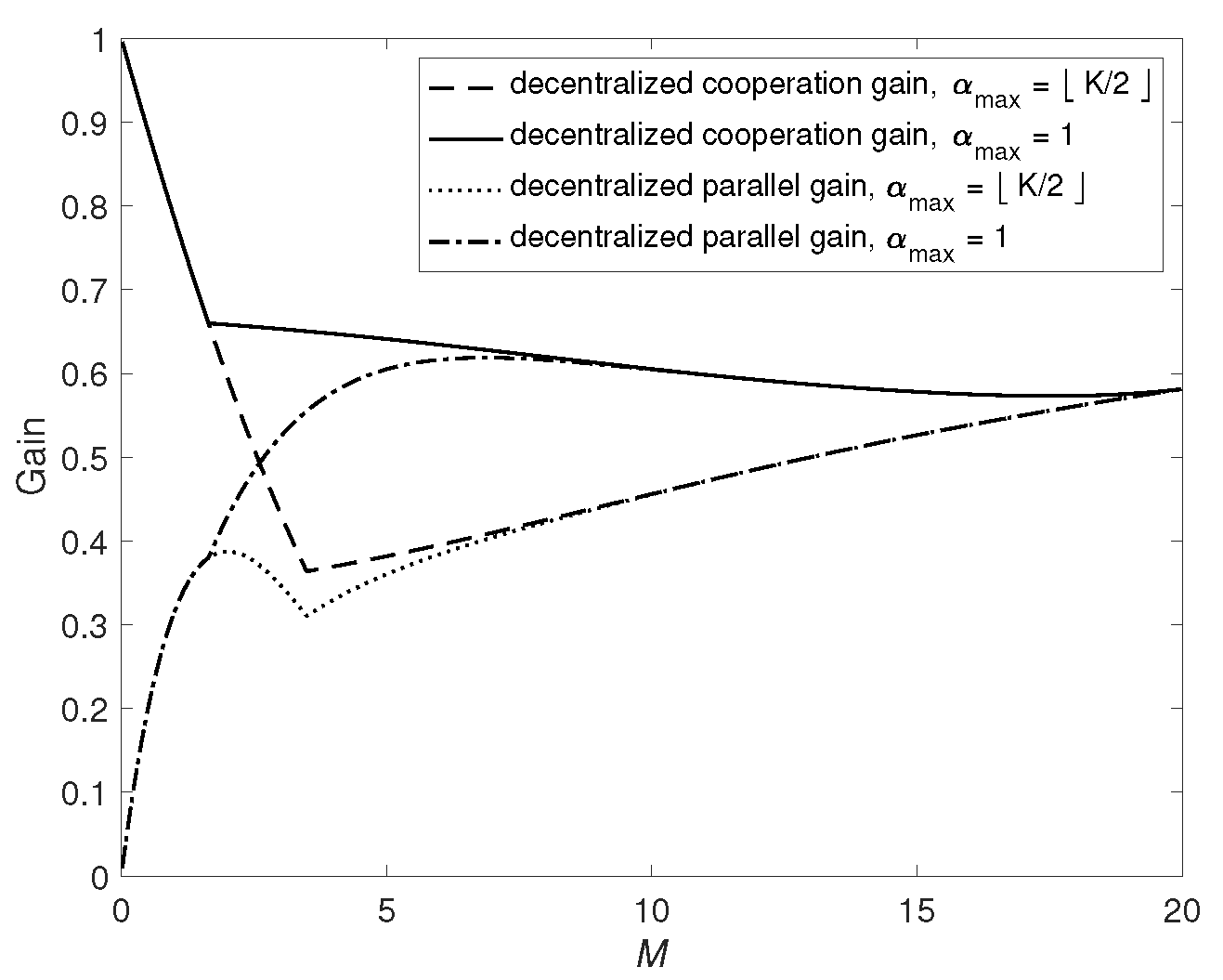
- We prove that the centralized scheme is order-optimal, i.e., achieving the optimal transmission delay within a constant multiplicative gap in all regimes. Moreover, the decentralized scheme is also optimal when the cache size of each user M is larger than the threshold that is approaching zero as .
- For the centralized data placement case, theoretical analysis shows that should decrease with the increase of the user caching size. In particular, when each user’s caching size is sufficiently large, only one user should be allowed to send information, indicating that the D2D network can be just a simple shared link connecting all users. For the decentralized data placement case, should be dynamically changing according to the sizes of subfiles created in the placement phase. In other words, always letting more users parallelly send information can cause a high transmission delay.
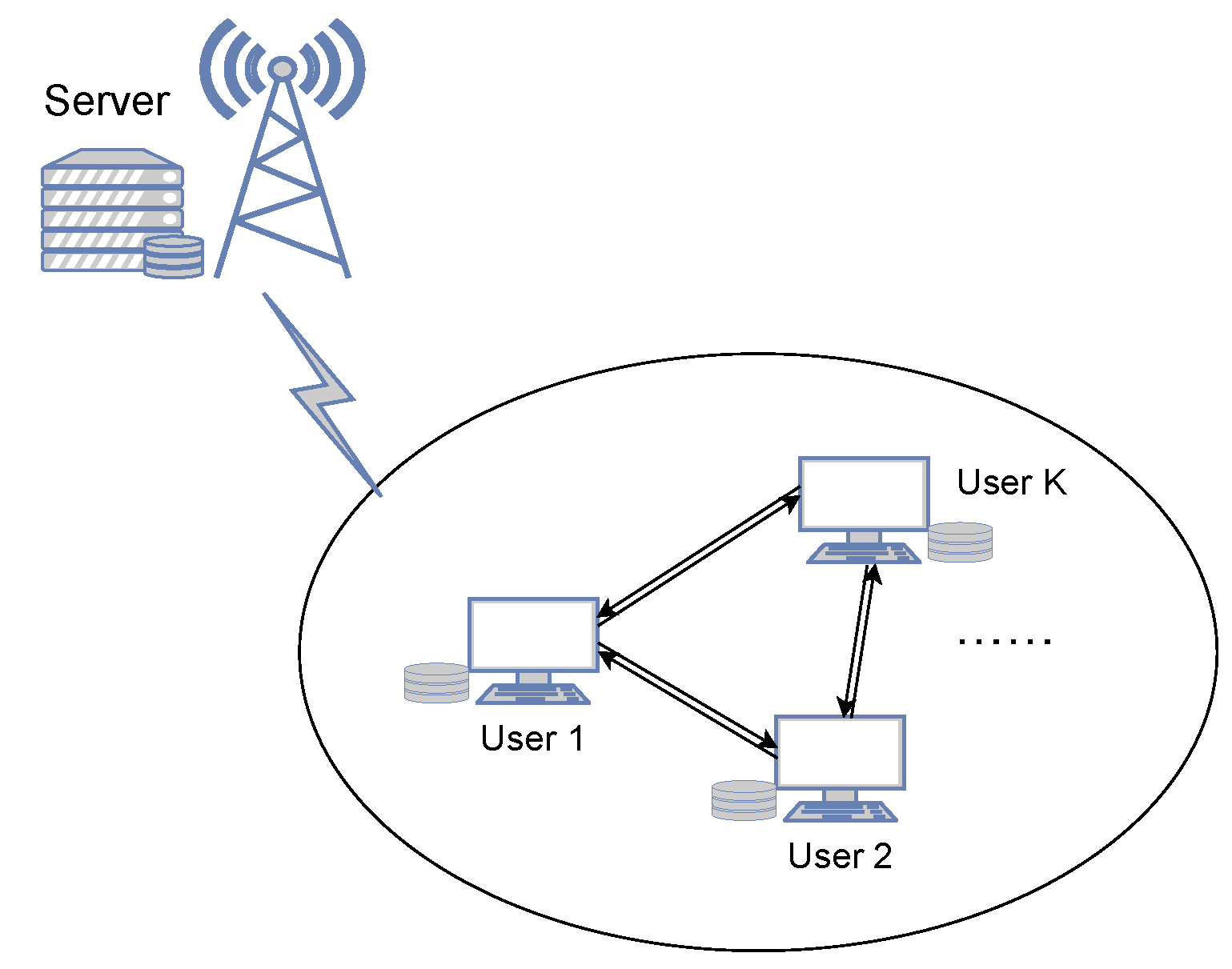
2. System Model and Problem Definition
3. Main Results
3.1. Centralized Coded Caching
3.2. Decentralized Coded Caching
- (a shared link):
- (a flexible network):
- if (shared link), then
- if , then
4. Coding Scheme under Centralized Data Placement
4.1. An Illustrative Example
4.2. The Generalized Centralized Coding Caching Scheme
5. Coding Scheme under Decentralized Data Placement
5.1. An Illustrative Example
5.2. The Generalized Decentralized Coded Caching Scheme
5.2.1. Allocating Communication Loads between the Server and User
5.2.2. Inner-Group Coding
5.2.3. Parallel Delivery among Groups
- Case 1: . In this case, users are allowed to send data simultaneously. Select users from all users and divide them into groups of equal size s. The total number of such kinds of partition isIn each partition, users, selected from groups, respectively, send data in parallel via the D2D network.
- Case 2: and . In this case, choose users from all users and partition them into groups of equal size s. The total number of such kind partition isIn each partition, users selected from groups of equal size s, respectively, together with an extra user selected from the abnormal group of size send data in parallel via the D2D network.
- Case 3: and . In this case, every s users form a group, resulting in groups consisting of users. The remaining users form an abnormal group. The total number of such kind of partition isIn each partition, users selected from groups of equal size s, respectively, together with an extra user selected from the abnormal group of size send data in parallel via the D2D network.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proof of the Converse
Appendix B
- If , from Theorem 1, we havewhere (a) follows from [1] [Theorem 3]. Then we havewhere the last inequality holds by setting .
- If , we havewhere holds by choosing .
- If , setting , we havewhere holds since for any . Please note that for all values of M, the transmission delay
Appendix C
Appendix C.1. Case αmax =
Appendix C.2. Case αmax =1
Appendix D
Appendix D.1. When αmax =
Appendix D.1.1. Case αmax = and p ≥ pth
Appendix D.1.2. Case αmax = and p ≥ pth
Appendix D.2. When αmax = 1
References
- Maddah-Ali, M.A.; Niesen, U. Fundamental limits of caching. IEEE Trans. Inf. Theory 2014, 60, 2856–2867. [Google Scholar] [CrossRef]
- Maddah-Ali, M.A.; Niesen, U. Decentralized coded caching attains order-optimal memory-rate tradeoff. IEEE/ACM Trans. Netw. 2015, 23, 1029–1040. [Google Scholar] [CrossRef]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. Characterizing the Rate-Memory Tradeoff in Cache Networks within a Factor of 2. IEEE Trans. Inf. Theory 2019, 65, 647–663. [Google Scholar] [CrossRef]
- Wan, K.; Tuninetti, D.; Piantanida, P. On the optimality of uncoded cache placement. In Proceedings of the IEEE Information Theory Workshop (ITW), Cambridge, UK, 11–14 September 2016; pp. 161–165. [Google Scholar]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. The exact rate-memory tradeoff for caching with uncoded prefetching. IEEE Trans. Inf. Theory 2018, 64, 1281–1296. [Google Scholar] [CrossRef]
- Yan, Q.; Cheng, M.; Tang, X.; Chen, Q. On the placement delivery array design for centralized coded caching scheme. IEEE Trans. Inf. Theory 2017, 63, 5821–5833. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, N. Coded cache placement for heterogeneous cache sizes. In Proceedings of the IEEE Information Theory Workshop (ITW), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar]
- Wang, S.; Peleato, B. Coded caching with heterogeneous user profiles. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), France, Paris, 7–12 July 2019; pp. 2619–2623. [Google Scholar]
- Zhang, J.; Lin, X.; Wang, C.C. Coded caching for files with distinct file sizes. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; pp. 1686–1690. [Google Scholar]
- Ibrahim, A.M.; Zewail, A.A.; Yener, A. Centralized coded caching with heterogeneous cache sizes. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Ibrahim, A.M.; Zewail, A.A.; Yener, A. Coded caching for heterogeneous systems: An Optimization Perspective. IEEE Trans. Commun. 2019, 67, 5321–5335. [Google Scholar] [CrossRef]
- Amiri, M.M.; Yang, Q.; Gündüz, D. Decentralized caching and coded delivery with distinct cache capacities. IEEE Trans. Commun. 2017, 65, 4657–4669. [Google Scholar] [CrossRef]
- Cao, D.; Zhang, D.; Chen, P.; Liu, N.; Kang, W.; Gündüz, D. Coded caching with asymmetric cache sizes and link qualities: The two-user case. IEEE Trans. Commun. 2019, 67, 6112–6126. [Google Scholar] [CrossRef]
- Niesen, U.; Maddah-Ali, M.A. Coded caching with nonuniform demands. IEEE Trans. Inf. Theory 2017, 63, 1146–1158. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Wang, X. Coded caching under arbitrary popularity distributions. IEEE Trans. Inf. Theory 2018, 64, 349–366. [Google Scholar] [CrossRef]
- Pedarsani, R.; Maddah-Ali, M.A.; Niesen, U. Online coded caching. IEEE/ACM Trans. Netw. 2016, 24, 836–845. [Google Scholar] [CrossRef]
- Daniel, A.M.; Yu, W. Optimization of heterogeneous coded caching. IEEE Trans. Inf. Theory 2020, 66, 1893–1919. [Google Scholar] [CrossRef]
- Shariatpanahi, S.P.; Motahari, S.A.; Khalaj, B.H. Multi-server coded caching. IEEE Trans. Inf. Theory 2016, 62, 7253–7271. [Google Scholar] [CrossRef]
- Zhang, J.; Elia, P. Fundamental limits of cache-aided wireless BC: Interplay of coded-caching and CSIT feedback. IEEE Trans. Inf. Theory 2017, 63, 3142–3160. [Google Scholar] [CrossRef]
- Bidokhti, S.S.; Wigger, M.; Timo, R. Noisy broadcast networks with receiver caching. IEEE Trans. Inf. Theory 2018, 64, 6996–7016. [Google Scholar] [CrossRef]
- Sengupta, A.; Tandon, R.; Simeone, O. Cache aided wireless networks: Tradeoffs between storage and latency. In Proceedings of the 2016 Annual Conference on Information Science and Systems (CISS), Princeton, NJ, USA, 15–18 March 2016; pp. 320–325. [Google Scholar]
- Tandon, R.; Simeone, O. Cloud-aided wireless networks with edge caching: Fundamental latency trade-offs in fog radio access networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2029–2033. [Google Scholar]
- Karamchandani, N.; Niesen, U.; Maddah-Ali, M.A.; Diggavi, S.N. Hierarchical coded caching. IEEE Trans. Inf. Theory 2016, 62, 3212–3229. [Google Scholar] [CrossRef]
- Wang, K.; Wu, Y.; Chen, J.; Yin, H. Reduce transmission delay for caching-aided two-layer networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), France, Paris, 7–12 July 2019; pp. 2019–2023. [Google Scholar]
- Wan, K.; Ji, M.; Piantanida, P.; Tuninetti, D. Caching in combination networks: Novel multicast message generation and delivery by leveraging the network topology. In Proceedings of the IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Naderializadeh, N.; Maddah-Ali, M.A.; Avestimehr, A.S. Fundamental limits of cache-aided interference management. IEEE Trans. Inf. Theory 2017, 63, 3092–3107. [Google Scholar] [CrossRef]
- Xu, F.; Tao, M.; Liu, K. Fundamental tradeoff between storage and latency in cache-aided wireless interference Networks. IEEE Trans. Inf. Theory 2017, 63, 7464–7491. [Google Scholar] [CrossRef]
- Ji, M.; Tulino, A.M.; Llorca, J.; Caire, G. Order-optimal rate of caching and coded multicasting with random demands. IEEE Trans. Inf. Theory 2017, 63, 3923–3949. [Google Scholar] [CrossRef]
- Ji, M.; Tulino, A.M.; Llorca, J.; Caire, G. Caching in combination networks. In Proceedings of the 2015 49th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015. [Google Scholar]
- Ravindrakumar, V.; Panda, P.; Karamchandani, N.; Prabhakaran, V. Fundamental limits of secretive coded caching. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 425–429. [Google Scholar]
- Tang, L.; Ramamoorthy, A. Coded caching schemes with reduced subpacketization from linear block codes. IEEE Trans. Inf. Theory 2018, 64, 3099–3120. [Google Scholar] [CrossRef]
- Cheng, M.; Li, J.; Tang, X.; Wei, R. Linear coded caching scheme for centralized networks. IEEE Trans. Inf. Theory 2021, 67, 1732–1742. [Google Scholar] [CrossRef]
- Wan, K.; Caire, G. On coded caching with private demands. IEEE Trans. Inf. Theory 2021, 67, 358–372. [Google Scholar] [CrossRef]
- Hassanzadeh, P.; Tulino, A.M.; Llorca, J.; Erkip, E. Rate-memory trade-off for caching and delivery of correlated sources. IEEE Trans. Inf. Theory 2020, 66, 2219–2251. [Google Scholar] [CrossRef]
- Ji, M.; Caire, G.; Molisch, A.F. Fundamental limits of caching in wireless D2D networks. IEEE Trans. Inf. Theory 2016, 62, 849–869. [Google Scholar] [CrossRef]
- Tebbi, A.; Sung, C.W. Coded caching in partially cooperative D2D communication networks. In Proceedings of the 9th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Munich, Germany, 6–8 November 2017; pp. 148–153. [Google Scholar]
- Wang, J.; Cheng, M.; Yan, Q.; Tang, X. Placement delivery array design for coded caching scheme in D2D Networks. IEEE Trans. Commun. 2019, 67, 3388–3395. [Google Scholar] [CrossRef]
- Malak, D.; Al-Shalash, M.; Andrews, J.G. Spatially correlated content caching for device-to-device communications. IEEE Trans. Wirel. Commun. 2018, 17, 56–70. [Google Scholar] [CrossRef]
- Ibrahim, A.M.; Zewail, A.A.; Yener, A. Device-to-Device coded caching with distinct cache sizes. arXiv 2019, arXiv:1903.08142. [Google Scholar] [CrossRef]
- Pedersen, J.; Amat, A.G.; Andriyanova, I.; Brännström, F. Optimizing MDS coded caching in wireless networks with device-to-device communication. IEEE Trans. Wirel. Commun. 2019, 18, 286–295. [Google Scholar] [CrossRef]
- Chiang, M.; Zhang, T. Fog and IoT: An overview of research opportunities. IEEE Internet Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| user 2: | user 5: |
| user 2: | user 5: |
| user 1: | user 4: |
| user 3: | user 6: |
| user 2: | user 5: |
| user 6: | user 3: |
| user 1: | user 4: |
| user 3: | user 4: |
| user 3: | user 4: |
| user 2: | user 5: |
| user 1: | user 6: |
| user 1: | user 6: |
| ⊕⊕ | ⊕ |
| ⊕⊕ | ⊕ |
| ⊕⊕ | ⊕ |
| ⊕⊕ | |
| ⊕⊕ | ⊕ |
| ⊕⊕ | ⊕ |
| ⊕⊕ | ⊕ |
| ⊕⊕ | |
| ⊕⊕ | ⊕ |
| ⊕⊕ | ⊕ |
| ⊕⊕ | ⊕ |
| ⊕⊕ | |
| ⋯ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Chen, J.; You, X.; Ma, S.; Wu, Y. Coded Caching for Broadcast Networks with User Cooperation. Entropy 2022, 24, 1034. https://doi.org/10.3390/e24081034
Huang Z, Chen J, You X, Ma S, Wu Y. Coded Caching for Broadcast Networks with User Cooperation. Entropy. 2022; 24(8):1034. https://doi.org/10.3390/e24081034
Chicago/Turabian StyleHuang, Zhenhao, Jiahui Chen, Xiaowen You, Shuai Ma, and Youlong Wu. 2022. "Coded Caching for Broadcast Networks with User Cooperation" Entropy 24, no. 8: 1034. https://doi.org/10.3390/e24081034