
Three-Way Decision Models Based on Ideal Relations in Multi-Attribute Decision-Making

Abstract
:1. Introduction
- (1)
- First of all, traditional MADM methods are generally combined with the two-way decision model, while we combine MADM with TWD. In this paper, we use the basis behind TOPSIS together with TWD in MADM. The main idea of TOPSIS is that the optimal object should have the minimal distance to the best target solution (BTS); at the same time, the larger the distance is from the worst target solution (WTS), the better. However, its limitation is that we cannot determine the order of the objects when they only meet one of the conditions or neither of the two conditions. To solve the problem, some scholars proposed equivalence relations [4], similar relations [5,6,7], dominance relations [8,9] and neighborhood operators [10,11], while we propose a new pair of ideal relations.
- (2)
- Secondly, in most probability rough sets, the values of and are given artificially, and they do not answer why they should be set like this. Moreover, regarding the calculation of conditional probability [12] in decision-theoretic rough set models [1,5,13], scholars have different understanding and calculation methods from different angles and analysis directions; the properties of state sets generally have two types: classic sets [14,15] and fuzzy sets [16]. In classic sets, object membership values are given subjectively, while few studies have calculated state set values. However, different decision-makers have different opinions and preferences, and the given membership values also have great differences. Therefore, in order to reduce the error caused by subjectivity, we propose a new method of objectively calculating the state.
- (3)
- Thirdly, since there are two states and three behaviors for each object, an object has six loss functions, each of which is either a subjective loss function [17,18,19] or an objective loss function [7,16,20]. If multiple attributes of an object are considered separately, there are six loss functions for each attribute, which requires a huge amount of calculation and lots of stored data. In this paper, we use the relative loss function proposed by Jia and Liu, which aggregates the relative loss function values for each object to reduce the amount of calculation. Besides, in order to improve the accuracy and reliability of TWD division, we calculate the threshold of each object and then divide all objects into three territories according to the threshold of each object.
- (1)
- We combine MADM with TWD and use TOPSIS to propose a pair of new ideal relations, namely ideal superiority relations and ideal inferiority relations, which have opposite definition conditions. Based on these two relations, we construct the ideal superiority class on the basis of the ideal superiority relations and the ideal inferiority class on the basis of the ideal inferiority relations. Furthermore, we construct a pair of new models: one is the TWD model based on the ideal superiority class, that is, the TWD ideal superiority model; the other is the TWD model based on the ideal inferiority class, that is, the TWD ideal inferiority model. These two models combined with TWD can be applied to the classification and sorting of objects. Moreover, the models we propose provide a new theoretical basis for research on uncertain decision-making, decision-making model selection, dynamic monitoring and intelligent decision-making technology. Meanwhile, these two models also provide new insights and ideas for decision-makers who are studying TWD.
- (2)
- In the current paper, we provide a new calculation method for the state set of conditional probability. In Wang’s method [21], fixed values of parameters are given subjectively; however, for different decision-makers, the research limits are different, so this method has certain limitations and inflexibility. On the basis of Wang’s method, we set up an adjustable preference parameter k to control the cardinality of the object class, which could help calculate the values of state sets objectively to provide decision-makers with various choices. Our proposed method of calculating state sets provides new insight into the field of decision analysis.
- (3)
- In terms of the loss function, the relative loss function of Jia and Liu is calculated objectively using the evaluation value in the information matrix. In this paper, different from the calculation methods of Jia and Liu, we set the risk-aversion coefficient of each attribute in the relative loss function to the same value instead of subjectively measuring the risk-aversion coefficient of each attribute by the decision maker, and it has been further expanded by computing the threshold of each object. The threshold is used to determine the three territories of TWD. Due to the inconsistency between the nature of attributes and the standards of the criteria for each object, we calculate the threshold of each object instead of using the same threshold standard. Hence, the measurement scale is more in line with human cognition and persuasive, and the research results obtained are more accurate and reasonable.
2. Preliminaries
2.1. MADM
2.2. The TWD Model Based on Decision-Theoretic Rough Set (DTRS)
2.3. The Relative Loss Functions
3. TWD Models Based on the Ideal Relations
3.1. A TWD Model Based on the Ideal Superiority Relation
3.1.1. Construction of the Ideal Superiority Relation and Class
3.1.2. The Three-Way Process Based on the Ideal Superiority Class
3.2. A TWD Model Based on the Ideal Inferiority Relation
3.2.1. The Construction of the Ideal Inferiority Relation and Class
3.2.2. The Three-Way Process Based on the Ideal Inferiority Class
3.3. Description of the above Two Models
4. An Application of the Proposed TWD-MADM Approach
4.1. Introduction of the Problem
4.2. The Decision-Making Algorithms
| Algorithm 1: Decision-making algorithm based on the ideal superiority class |
| Input:I information system, W weight, risk avoidance coefficient. |
| Output: The optimal building shape and the order of all building shapes. |
| Step 1: Choose different normalization formulas to normalize all of the evaluation values based on the nature of the attributes. |
| Step 2: Calculate the BTID and the WTID of each object by using Formula (10). |
| Step 3: Find the ideal superiority class of each object by Formula (12). |
| Step 4: For each object, determine whether it is in the or state by Definition 3. |
| Step 5: Compute the conditional probability of each object by Remark 2. |
| Step 6: Calculate the loss function by using the evaluation value , weight W and risk avoidance coefficient in the information matrix, and then use Formulas (19)–(21) to obtain the three thresholds , and . |
| Step 7: Divide all objects into three regions according to (P6)–(N6), the relationship between thresholds and conditional probabilities. |
| Step 8: Use Formulas (16)–(18) to obtain the expected loss of each object. |
| Step 9: Sort objects in each region according to the expected losses, and then derive the optimal building shape and the order of all shapes based on |
| Algorithm 2: Decision-making algorithm based on the ideal inferiority class |
| Input:I information system, W weight, risk avoidance coefficient. |
| Output: The optimal building shape and the order of all building shapes. |
| Step 1: Choose different normalization formulas to normalize all of the evaluation values based on the nature of the attributes. |
| Step 2: Compute the BTID and the WTID of each object by using Formula (10). |
| Step 3: Find the ideal inferiority class of each object by using Formula (23). |
| Step 4: For each object, determine whether it is in the or state by Definition 6. |
| Step 5: Compute the conditional probability of each object by the conditional probability formula of the ideal inferiority class . |
| Step 6: Calculate the loss function , and then use Formulas (27)–(29) to compute the three thresholds , and . |
| Step 7: Divide all objects into three regions according to (P7)–(N7). |
| Step 8: Obtain the expected loss of each object via Formulas (24)–(26). |
| Step 9: Sort objects in each region according to the expected losses, and then derive the optimal building shape and the order of all shapes based on |
4.3. An Application Example
4.4. Comparison Analysis and Spearman’s Rank Correlation Analysis
4.4.1. Comparison Analysis of Different MADM Approaches
4.4.2. Spearman’s Rank Correlation Analysis
4.4.3. Other Example Analysis
5. Experiment Analysis
5.1. Analysis of the Preference Parameter and the Risk Aversion Factor in the Ideal Superiority Class Model
5.2. Analysis of the Preference Parameter and the Risk Aversion Factor in the Ideal Inferiority Class Model
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MADM | Multi-attribute decision-making |
| TWD | Three-way decision |
References
- Yao, Y.Y. Decision-theoretic rough set models. In Rough Sets and Knowledge Technology; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–12. [Google Scholar]
- Hwang, C.L.; Yoon, K. Multiple Attribute Decision Making: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Jia, F.; Liu, P.D. A novel three-way decision model under multiple-criteria environment. Inform. Sci. 2019, 471, 29–51. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, P.F.; Li, Z.W. A three-way decision method based on Gaussian kernel in a hybrid information system with images: An application in medical diagnosis. Appl. Soft Comput. 2019, 77, 734–749. [Google Scholar] [CrossRef]
- Lang, G.M.; Miao, D.Q.; Cai, M.J. Three-way decision approaches to conflict analysis using decision-theoretic rough set theory. Inform. Sci. 2017, 406–407, 185–207. [Google Scholar] [CrossRef]
- Li, Z.W.; Zhang, P.F.; Xie, N.X.; Zhang, G.Q.; Wen, C.F. A novel three-way decision method in a hybrid information system with images and its application in medical diagnosis. Eng. Appl. Artif. Intell. 2020, 92, 103651. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, X.S. Three-way decision based on improved aggregation method of interval loss function. Inform. Sci. 2020, 508, 214–233. [Google Scholar] [CrossRef]
- Chakhar, S.; Saad, I. Dominance-based rough set approach for groups in multicriteria classification problems. Decis. Support Syst. 2012, 54, 372–380. [Google Scholar] [CrossRef]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough approximation by dominance relations. Int. J. Intell. Syst. 2002, 17, 153–171. [Google Scholar] [CrossRef]
- Li, W.W.; Huang, Z.Q.; Jia, X.Y.; Cai, X.Y. Neighborhood based decision-theoretic rough set models. Int. J. Approx. Reason. 2016, 69, 1–17. [Google Scholar] [CrossRef]
- Ye, J.; Zhan, J.; Xu, Z. A novel decision-making approach based on three-way decisions in fuzzy information systems. Inform. Sci. 2020, 541, 362–390. [Google Scholar] [CrossRef]
- Sun, B.Z.; Ma, W.M.; Zhao, H.Y. Decision-theoretic rough fuzzy set model and application. Inform. Sci. 2014, 283, 180–196. [Google Scholar] [CrossRef]
- Tang, G.L.; Chiclana, F.; Liu, P.D. A decision-theoretic rough set model with q-rung orthopair fuzzy information and its application in stock investment evaluation. Appl. Soft Comput. 2020, 91, 106212. [Google Scholar] [CrossRef]
- Yao, Y.Y. Three-way decisions with probabilistic rough sets. Inform. Sci. 2010, 180, 341–353. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.Y. Three-way decision and granular computing. Int. J. Approx. Reason. 2018, 103, 107–123. [Google Scholar] [CrossRef]
- Zhan, J.M.; Jiang, H.B.; Yao, Y.Y. Three-way multi-attribute decision-making based on outranking relations. IEEE Trans. Fuzzy Syst. 2021, 29, 2844–2858. [Google Scholar] [CrossRef]
- Liu, D.; Liang, D.C.; Wang, C.C. A novel three-way decision model based on incomplete information system. Knowl.-Based Syst. 2016, 91, 32–45. [Google Scholar] [CrossRef]
- Liang, D.C.; Xu, Z.S.; Liu, D.; Wu, Y. Method for three-way decisions using ideal TOPSIS solutions at pythagorean fuzzy information. Inform. Sci. 2018, 435, 282–295. [Google Scholar] [CrossRef]
- Zhang, C.; Li, D.; Liang, J. Multi-granularity three-way decisions with adjustable hesitant fuzzy linguistic multigranulation decision-theoretic rough sets over two universes. Inform. Sci. 2020, 507, 665–683. [Google Scholar] [CrossRef]
- Liu, P.D.; Wang, Y.M.; Jia, F.; Fujita, H. A multiple attribute decision making three-way model for intuitionistic fuzzy numbers. Int. J. Approx. Reason. 2020, 119, 177–203. [Google Scholar] [CrossRef]
- Wang, W.J. Three-way decisions based multi-attribute decision making with probabilistic dominance relations. Inform. Sci. 2021, 559, 75–96. [Google Scholar] [CrossRef]
- Brans, J.P.; Vincke, J.P.; Mareschal, B. How to select and how to rank projects: The PROMETHEE method. Eur. J. Oper. Res. 1986, 24, 228–238. [Google Scholar] [CrossRef]
- Zhang, K.; Dai, J.H.; Zhan, J.M. A new classification and ranking decision method based on three-way decision theory and TOPSIS models. Inform. Sci. 2021, 568, 54–85. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
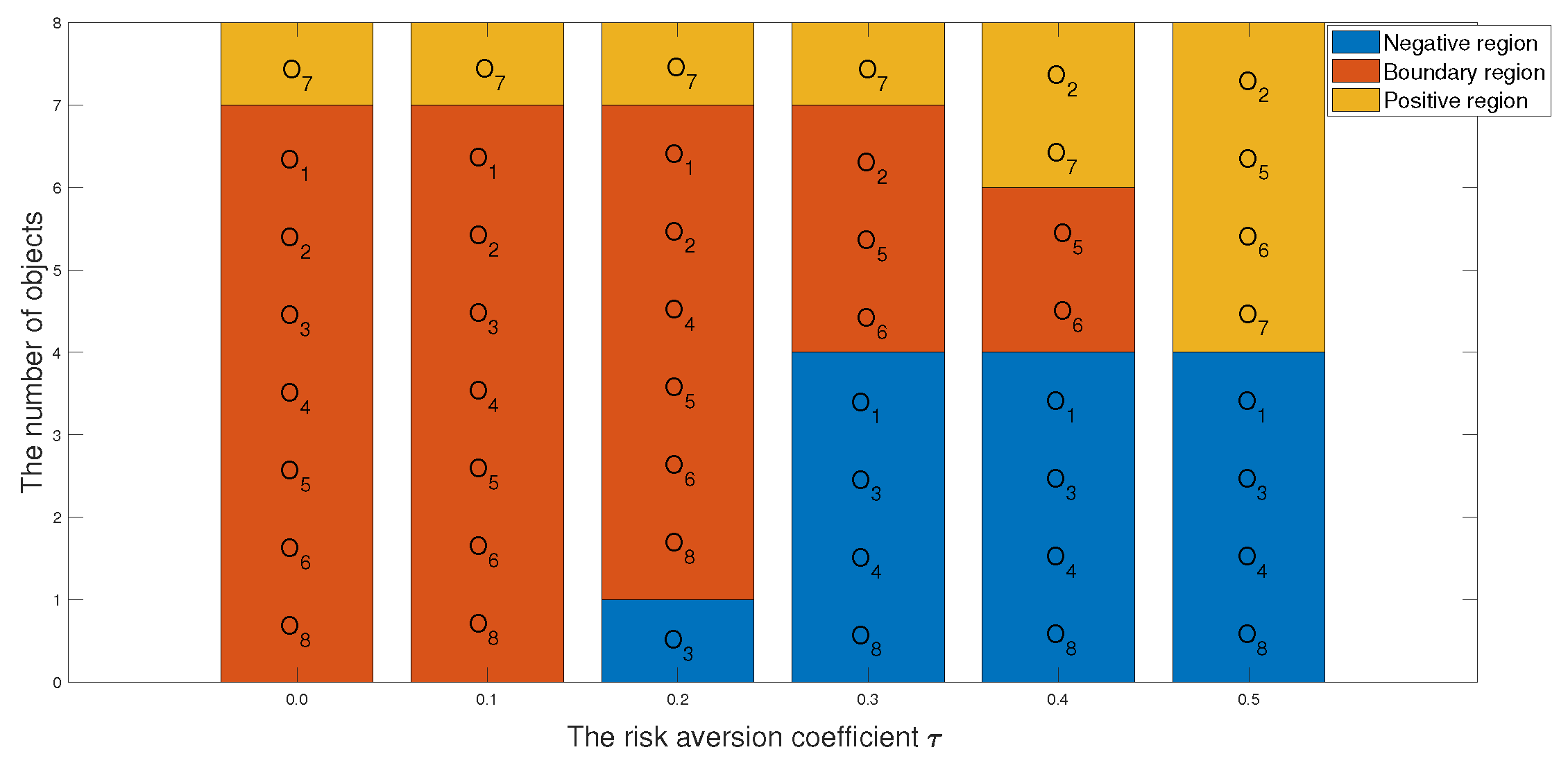{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ⋯ | ||||
|---|---|---|---|---|
| ⋯ | ||||
| ⋯ | ||||
| ⋮ | ⋮ | ⋮ | ⋯ | ⋮ |
| ⋯ |
| ⋯ | ||||
|---|---|---|---|---|
| ⋯ | ||||
| ⋯ | ||||
| ⋮ | ⋮ | ⋮ | ⋯ | ⋮ |
| ⋯ |
| R | ||
|---|---|---|
| 0 | ||
| 0 |
| 0 | ||
| 0 |
| R | ||
|---|---|---|
| 0 | ||
| 0 |
| 0 | ||
| 0 |
| 0 | ||
| 0 |
| Decision rules |
| 588 | 294 | 147 | 2 | ||
| 602 | 118 | 121 | 3 | ||
| 701 | 356 | 145 | 5 | ||
| 637 | 343 | 165 | 2 | ||
| 588 | 294 | 118 | 3 | ||
| 634 | 348 | 163 | 3 |
| 0 | ||
| 0 |
| 0 | ||
| 0 |
| Decision rules |
| 2 | 0 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 2 | 1 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 4 | 2 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 3 | 3 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 3 | 4 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 5 | 4 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 5 | 1 | |||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 2 | 3 |
| 3 | |||||
| 5 | |||||
| 3 | |||||
| 3 | |||||
| 4 | |||||
| 4 | |||||
| 5 | |||||
| 2 |
| O | ||||||||
|---|---|---|---|---|---|---|---|---|
| O | ||||||||
|---|---|---|---|---|---|---|---|---|
| Decision rules |
| Domains | Rankings |
|---|---|
| Overall ranking |
| O | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 |
| O | ||||||||
|---|---|---|---|---|---|---|---|---|
| Decision rules |
| Domains | Rankings |
|---|---|
| Overall ranking |
| Method | Ranking Results | Optimal Object |
|---|---|---|
| IS | ||
| IF | ||
| TOPSIS | ||
| PROMETHEE | ||
| Ye’s | ||
| Zhang’s | ||
| Jia’s |
| Method | IS | IF | TOPSIS | PROMETHEE | Ye’s | Zhang’s | Jia’s |
|---|---|---|---|---|---|---|---|
| IS | |||||||
| IF | |||||||
| TOPSIS | |||||||
| PROMETHEE | |||||||
| Ye’s | |||||||
| Zhang’s | |||||||
| Jia’s |
| Method | Ranking Results | Optimal Object |
|---|---|---|
| IS | ||
| IF | ||
| TOPSIS | ||
| PROMETHEE | ||
| Ye’s | ||
| Zhang’s | ||
| Jia’s |
| Method | IS | IF | TOPSIS | PROMETHEE | Ye’s | Zhang’s | Jia’s |
|---|---|---|---|---|---|---|---|
| IS | |||||||
| IF | |||||||
| TOPSIS | |||||||
| PROMETHEE | |||||||
| Ye’s | |||||||
| Zhang’s | |||||||
| Jia’s |
| Method | Ranking Results | Optimal Object |
|---|---|---|
| IS | ||
| IF | ||
| TOPSIS | ||
| PROMETHEE | ||
| Zhang’s |
| Method | IS | IF | TOPSIS | PROMETHEE | Zhang’s |
|---|---|---|---|---|---|
| IS | |||||
| IF | |||||
| TOPSIS | |||||
| PROMETHEE | |||||
| Zhang’s |
| Preference Parameter | Ranking Results |
|---|---|
| = 0.05 | |
| = 0.10 | |
| = 0.15 | |
| = 0.20 | |
| = 0.25 | |
| = 0.30 | |
| = 0.35 | |
| = 0.40 | |
| = 0.45 | |
| = 0.50 |
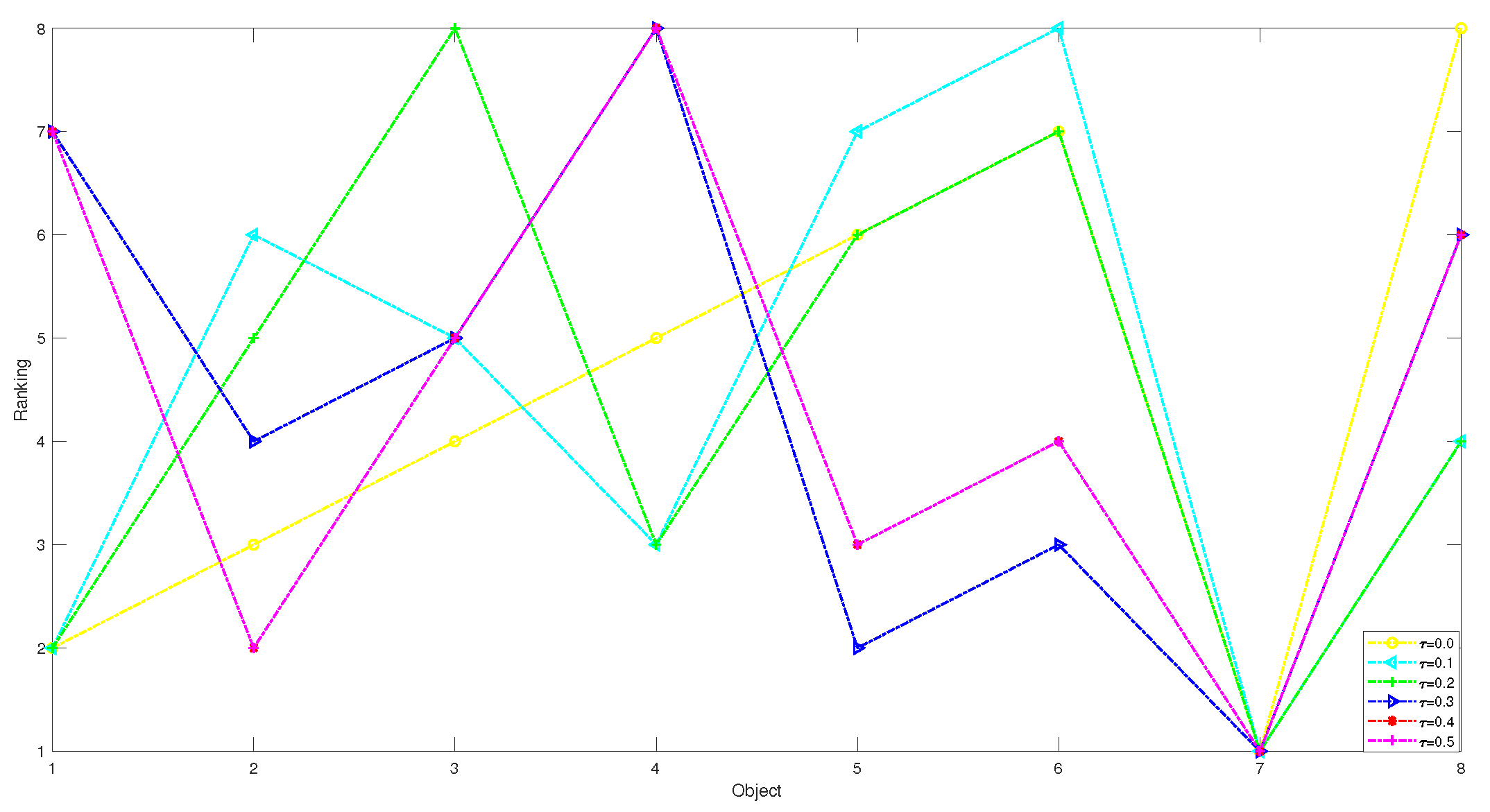
| The Risk Aversion Coefficient | Ranking Results |
|---|---|
| = 0.0 | |
| = 0.1 | |
| = 0.2 | |
| = 0.3 | |
| = 0.4 | |
| = 0.5 |
| Preference Parameter | Ranking Results |
|---|---|
| = 0.50 | |
| = 0.55 | |
| = 0.60 | |
| = 0.65 | |
| = 0.70 | |
| = 0.75 | |
| = 0.80 | |
| = 0.85 | |
| = 0.90 | |
| = 0.95 | |
| = 0.10 |
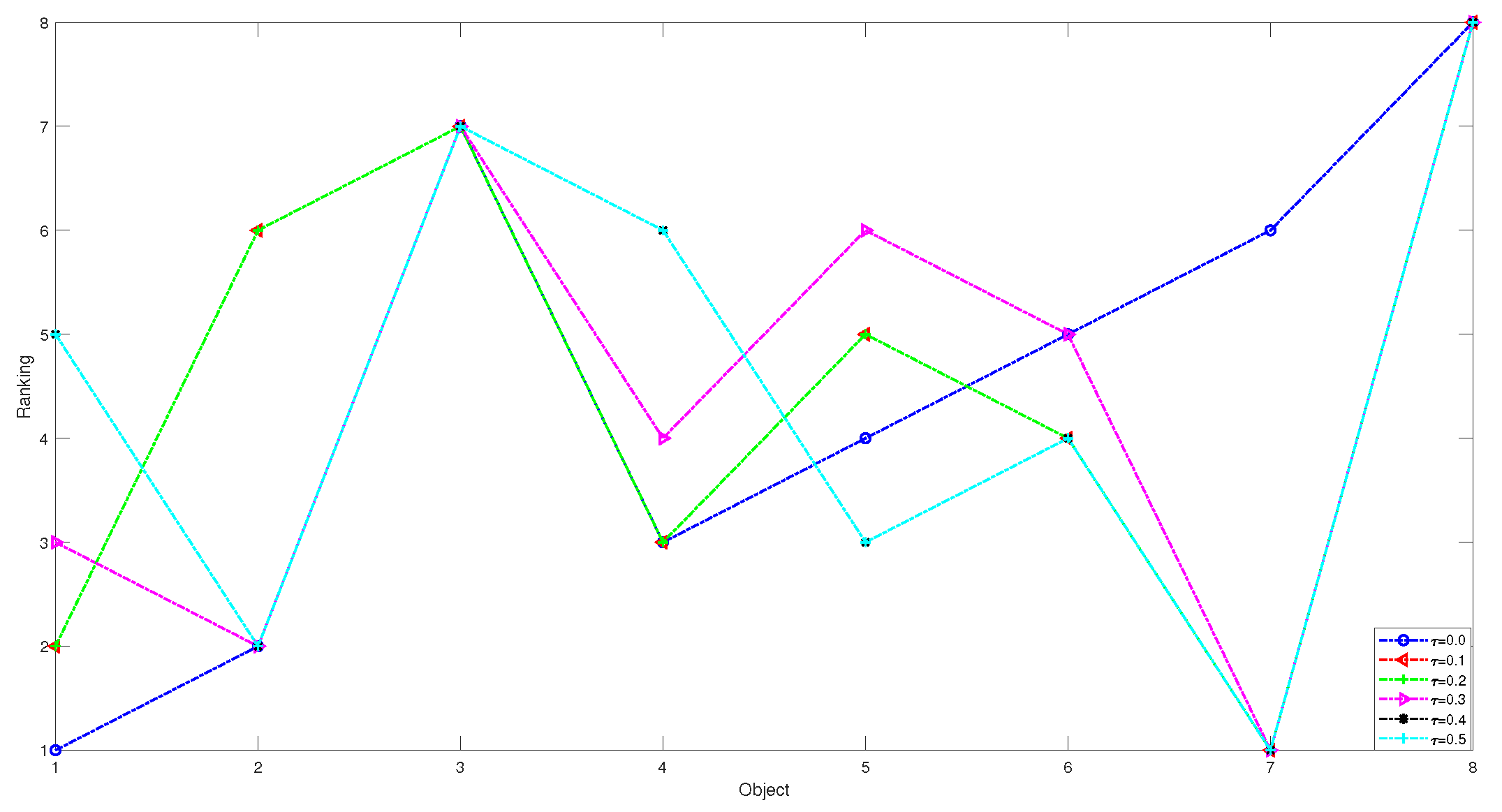
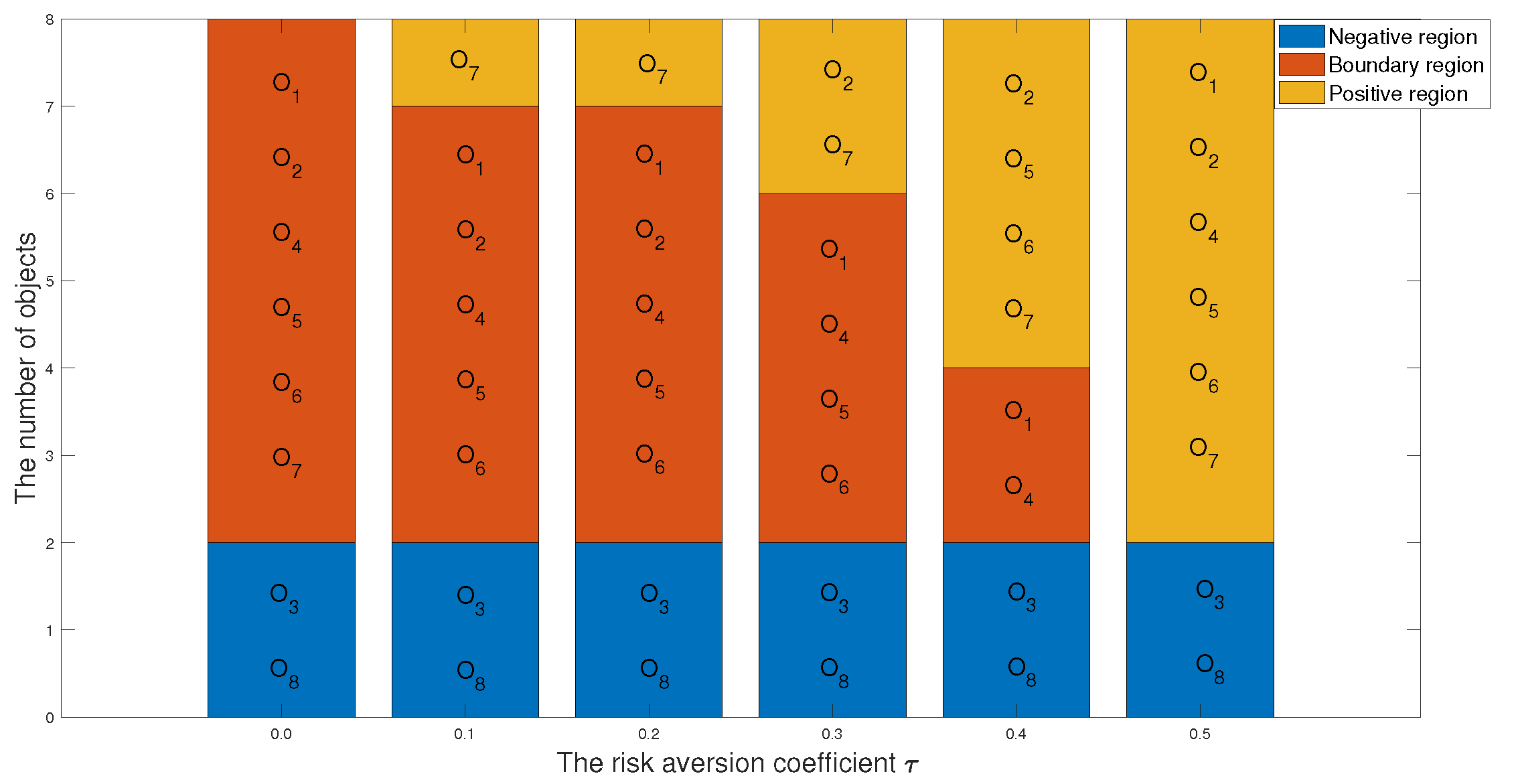
| Risk Aversion Coefficient | Ranking Results |
|---|---|
| = 0.0 | |
| = 0.1 | |
| = 0.2 | |
| = 0.3 | |
| = 0.4 | |
| = 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Zou, L. Three-Way Decision Models Based on Ideal Relations in Multi-Attribute Decision-Making. Entropy 2022, 24, 986. https://doi.org/10.3390/e24070986
Chen X, Zou L. Three-Way Decision Models Based on Ideal Relations in Multi-Attribute Decision-Making. Entropy. 2022; 24(7):986. https://doi.org/10.3390/e24070986
Chicago/Turabian StyleChen, Xiaozhi, and Ligeng Zou. 2022. "Three-Way Decision Models Based on Ideal Relations in Multi-Attribute Decision-Making" Entropy 24, no. 7: 986. https://doi.org/10.3390/e24070986