
Attention-Shared Multi-Agent Actor–Critic-Based Deep Reinforcement Learning Approach for Mobile Charging Dynamic Scheduling in Wireless Rechargeable Sensor Networks


Abstract
:1. Introduction
- (1)
- Different from the existing works, we consider both charging sequence and charging ratio optimization simultaneously in this paper. We introduce two heterogeneous agents named charging sequence scheduler and charging ratio controller. These two agents give the charging decisions separately under the dynamic changing environments, which aims to prolong the lifetime of the network and minimize the number of dead sensors.
- (2)
- We design a novel reward function with a penalty coefficient by comprehensively considering the tour length of MC and the number of dead sensors for AMADRL-JSSRC, so as to promote the agents to make better decisions.
- (3)
- We introduce the attention shared mechanism in AMADRL-JSSRC to the problem that charging sequence and charging ratio have different contributions to the reward function.
2. System Model and Problem Formulation
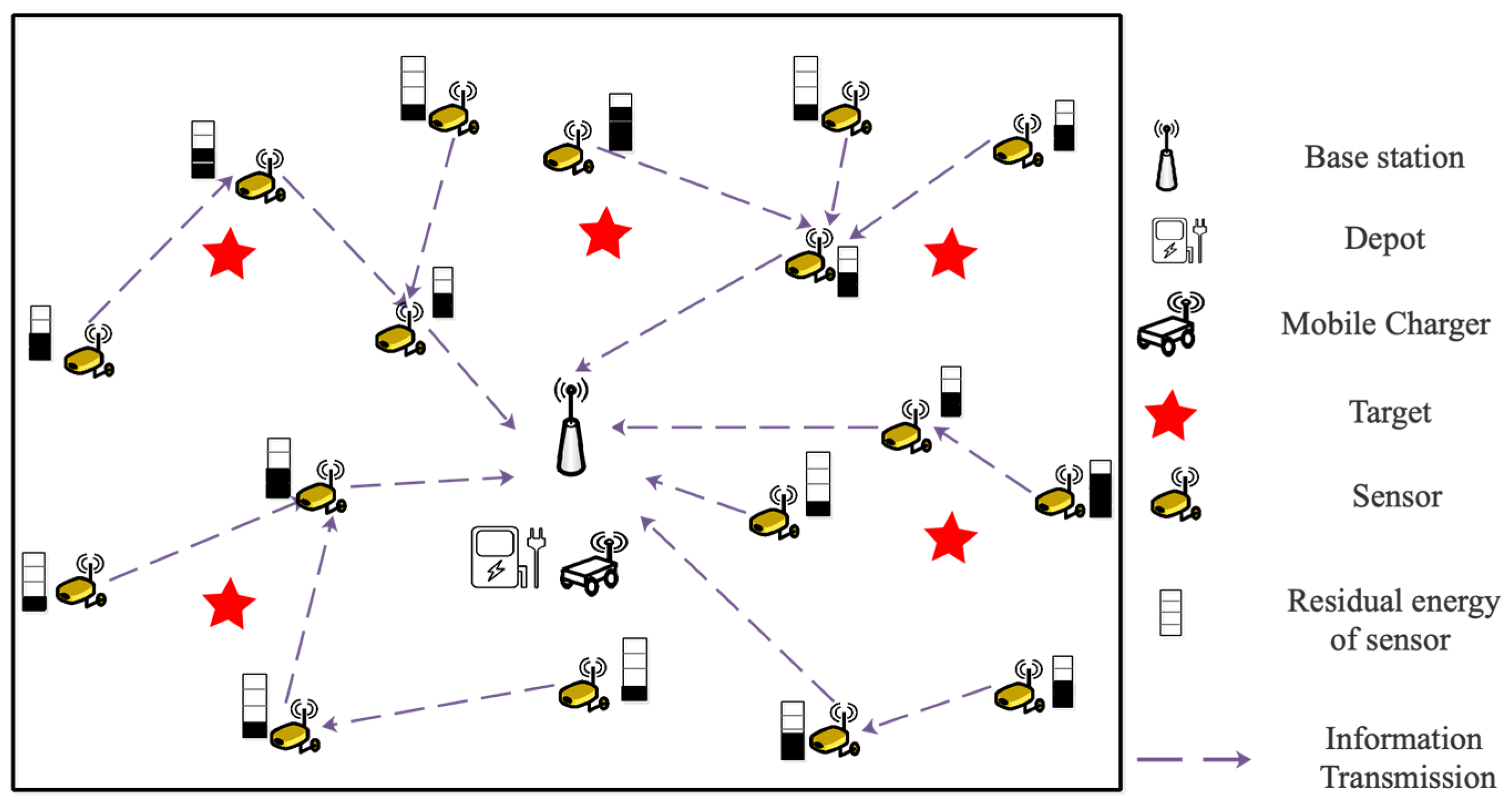
2.1. Network Structure
2.2. Energy Consumption Model of Sensors
2.3. Charging Model of MC
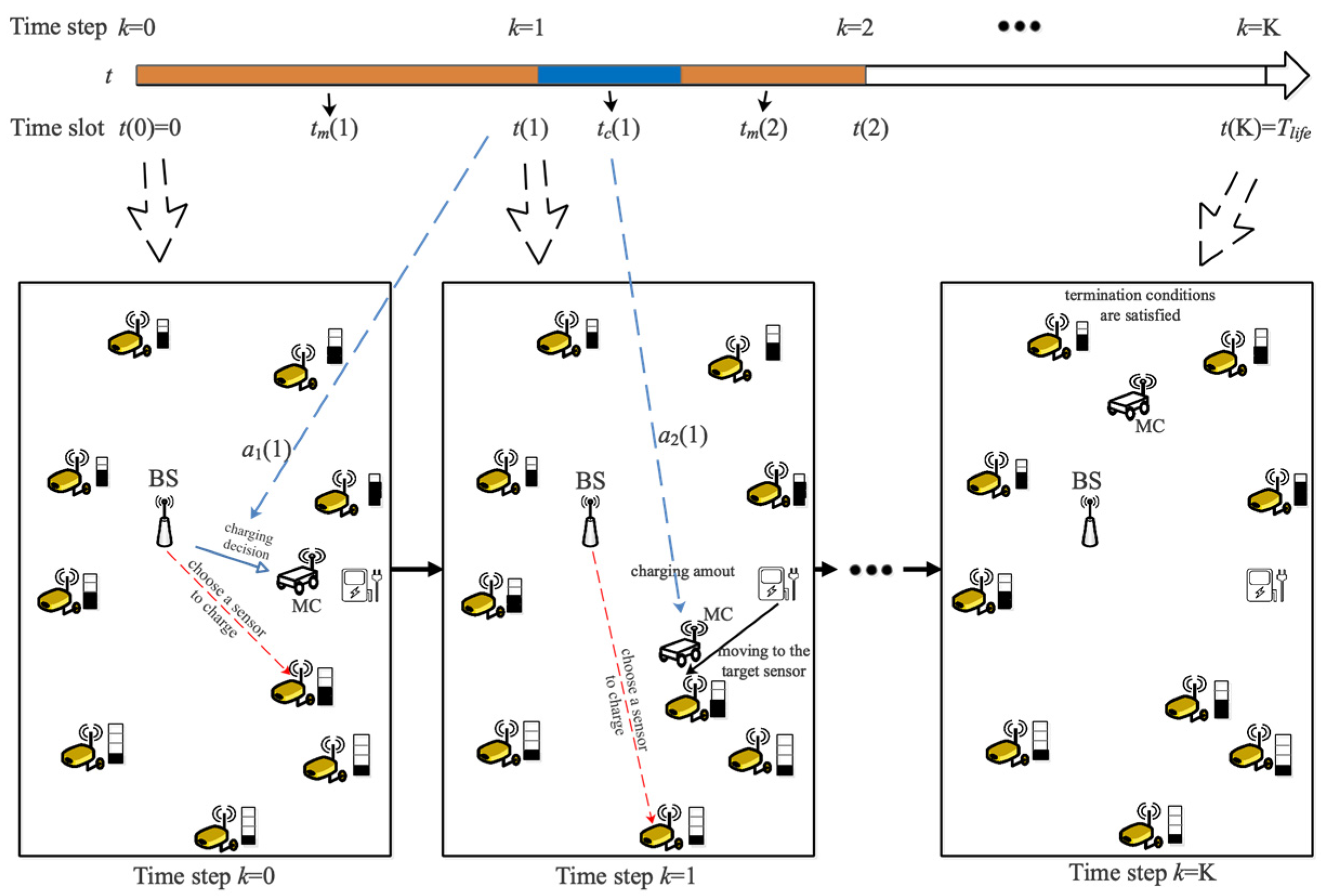
2.4. Problem Formulation
- (1)
- The number of dead sensors reaches % of the total number, .
- (2)
- The remaining energy of MC is insufficient to return to the depot.
- (3)
- The target lifetime or the base time is reached.where represent the distance from the MC’s current location to the depot, is the running time of the test, and is a given base time. Specifically, when any of the termination conditions in (8) are met, the charging process will end.
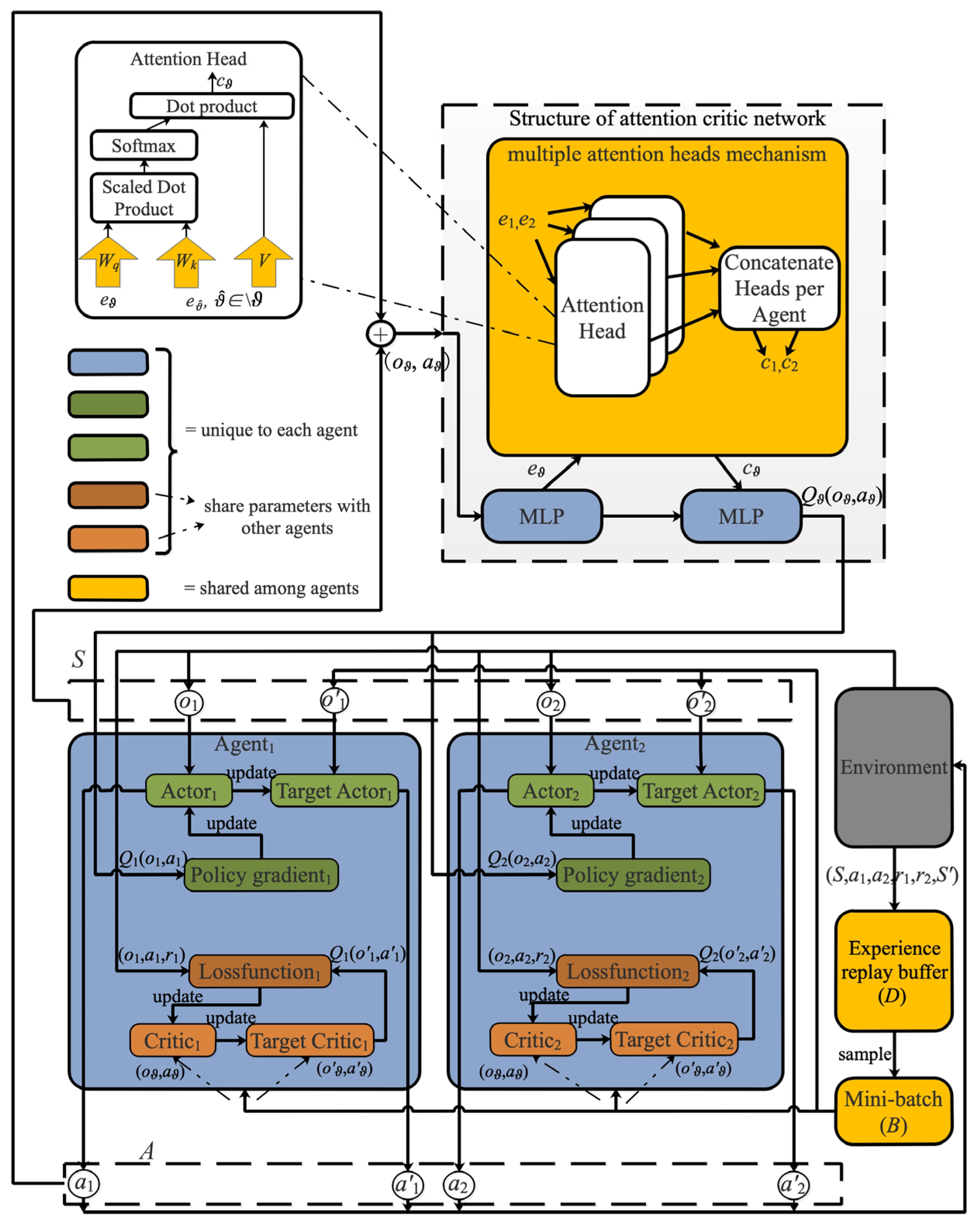
3. Details of the Attention-Shared Multi-Agent Actor-Critic Based Deep Reinforcement Learning Approach for JSSRC (AMADRL-JSSRC)
3.1. Basis of Multi-Agent Reinforcement Learning
3.2. Learning Model Construction for JSSRC
- (1)
- The MC could visit any position in the network as long as its residual energy could satisfy the charging demand of the next selected sensor or is enough to move back to the depot.
- (2)
- All sensors with a charging demand greater than 0 have a certain probability of being selected as the next one to be charged.
- (3)
- The MC does not charge the sensors whose charging demands are zero.
- (4)
- If the residual energy of MC does not satisfy the charging demand of the next selected sensor, but it is enough to return to the depot, the MC is allowed to return to the depot to charge itself, and the charging time of the MC is ignored.
- (5)
- The charging decision of two adjacent time steps cannot be the same sensor or depot.
- (6)
- If the residual energy of the MC does not meet the charging demand for the next sensor, is not enough to return to the depot, or the preset network lifetime is reached, the charging plan will be ended no matter whether the sensors are still alive or not.
3.3. AMADRL-JSSRC Algorithm
3.4. Parameters Update in AMADRL-JSSRC
- (1)
- We must remove from the input of and output a value for every action.
- (2)
- We need add an observation encoder, , to replace the in (24) described above.
- (3)
- We also modify to output the Q-value of all possible actions rather than the single input action.
- (4)
| Algorithm 1 AMADRL-JSSRC |
| 1: Initialize the number of parallel environments for two agents as , initialize the update time of parallel operation as , initialize the experience replay buffer with D and the minibatch with B, initialize the number of episodes as , the number of steps per episode as the number of critic updates as , the number of policy updates as , and the number of multiple attention head as , initialize the critic network , and actor network with random parameters , , initialize the target network, and , 2: for do 3: Reset environments, and obtain the initial for each agent, 4: for do 5: Randomly select actions for each agent , in each environment () with greedy search strategy 6: Send actions to all parallel environments, then obtain and for all agents 7: Store transitions for all environments in D 8: 9: if then 10: for do 11: Sample B 12: function Update Critic (B): 13: Unpack the mini-batch (B) 14: 15: Calculate for two agents in parallel 16: Calculate and with target policies 17: Calculate for two agents in parallel with the target critic 18: Update critic with shown in (28) and Adam optimizer [44] 19: end function Update Critic 20: end for 21: for do 22: Sample 23: function Update Policies () 24: Calculate 25: Calculate for two agents in parallel 26: Update policies with shown in (33) and Adam optimizer [44] 27: end function Update Policies 28: end for 29: Update target parameters: , 30: 31: end if 32: end for 33: end for 34: Output: The parameters of target actor |
4. Experimental Setup and Results
4.1. Experimental Environment and Details
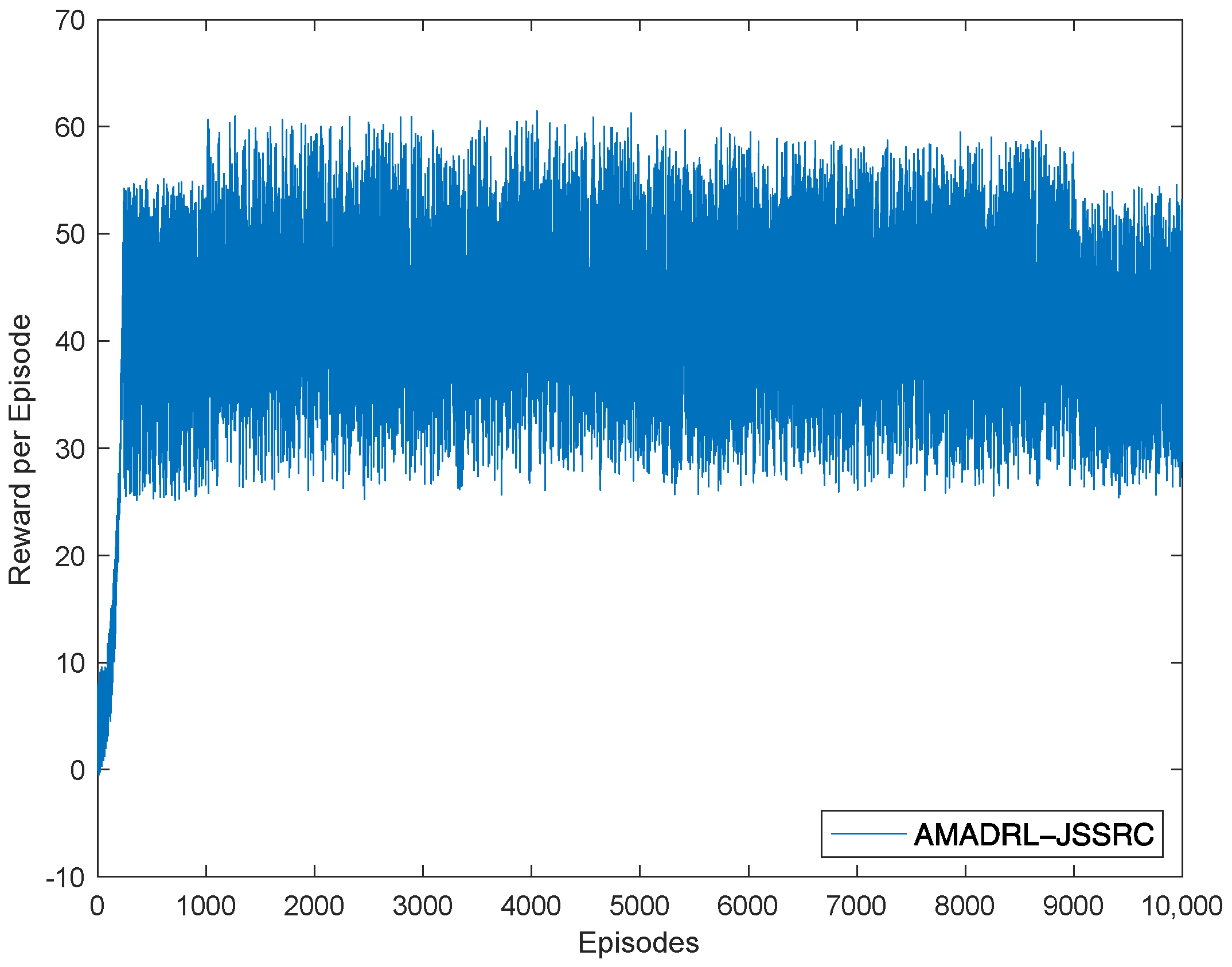
4.2. Comparison Results against the Baselines
5. Discussions
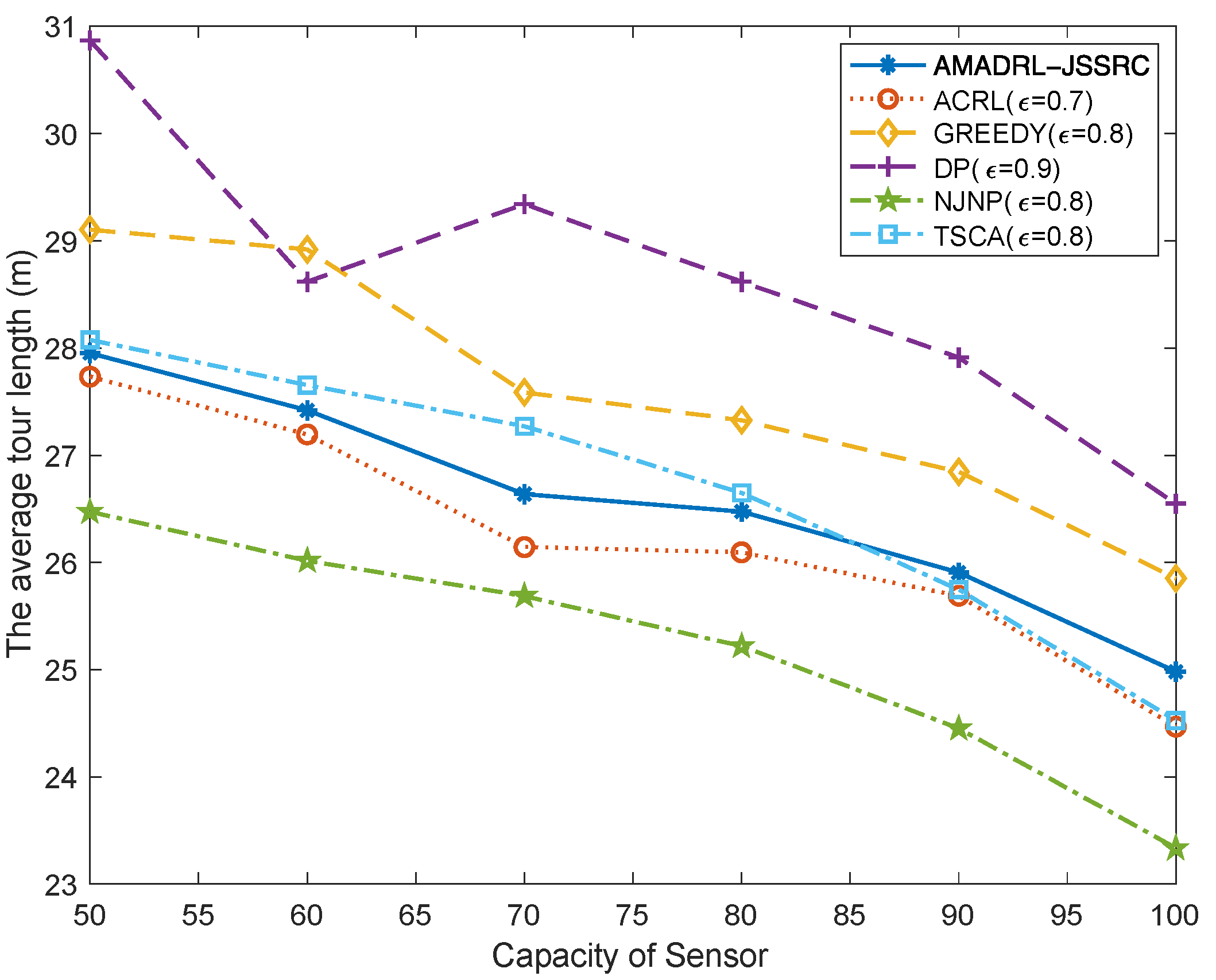
5.1. The Impacts of the Capacity of the Sensor
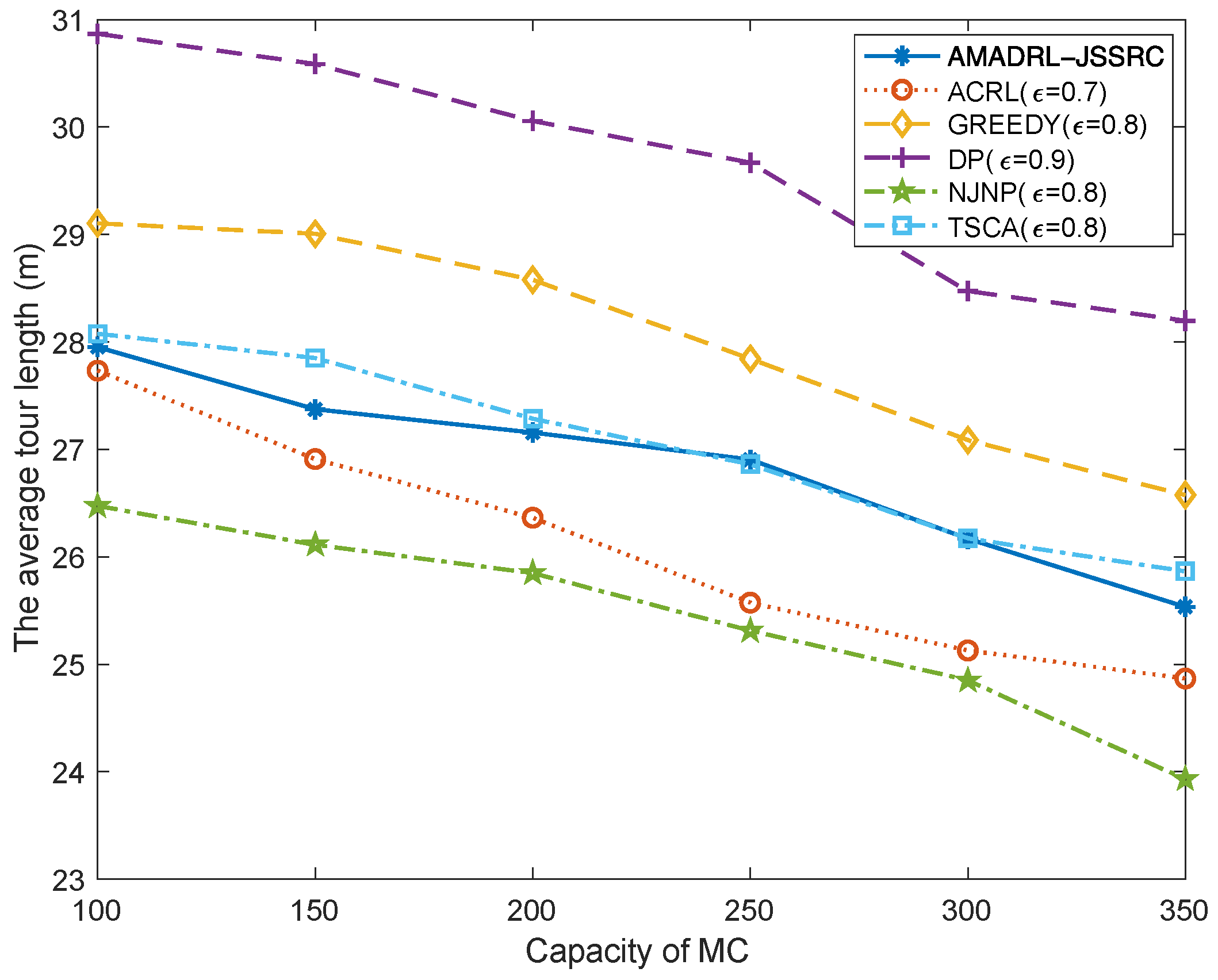
5.2. The Impacts of the Capacity of MC
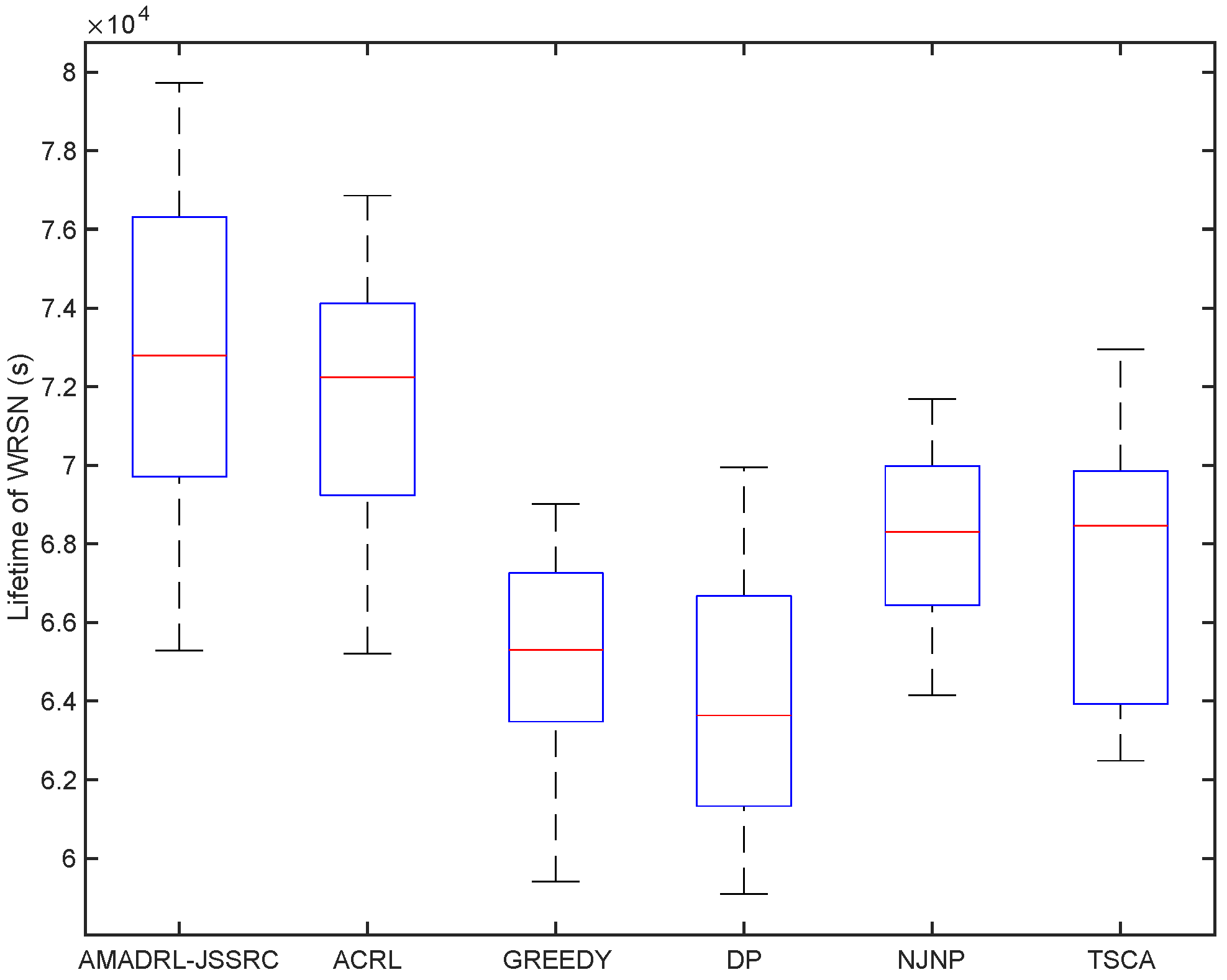
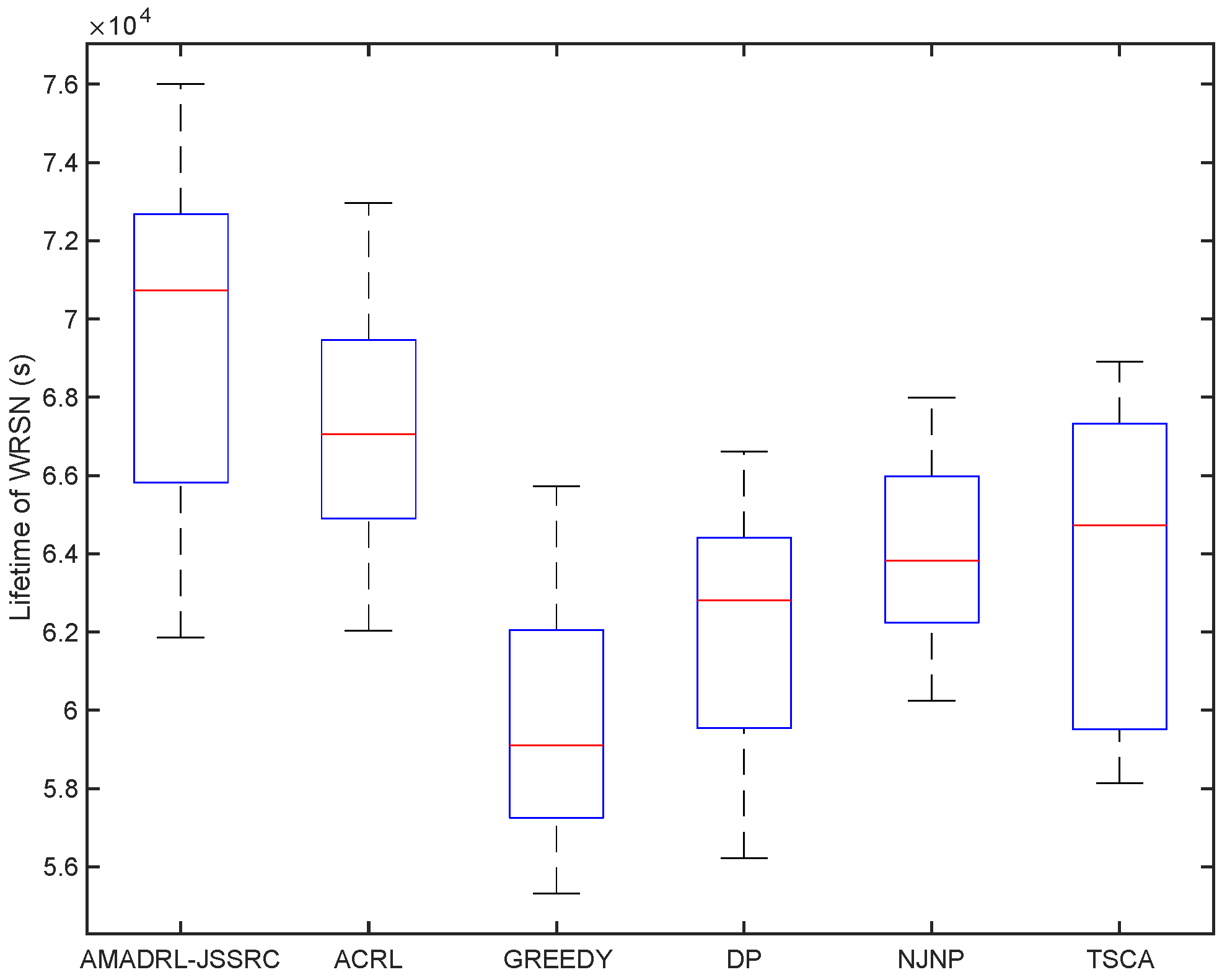
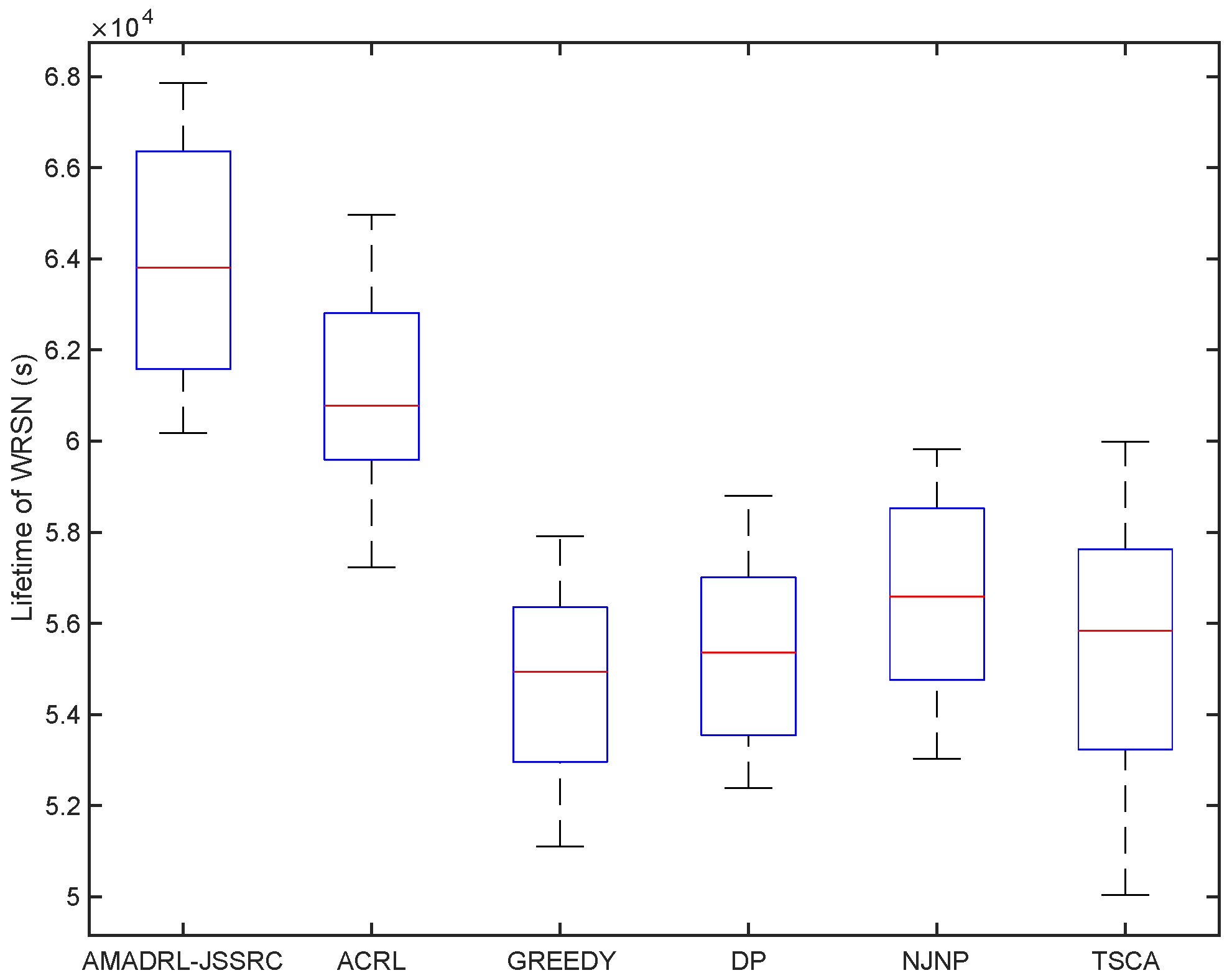
5.3. Performance Comparison in Terms of Lifetime
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, G.; Su, X.; Hong, F.; Zhong, X.; Liang, Z.; Wu, X.; Huang, Z. A Novel Epidemic Model Base on Pulse Charging in Wireless Rechargeable Sensor Networks. Entropy 2022, 24, 302. [Google Scholar] [CrossRef] [PubMed]
- Ayaz, M.; Ammad-Uddin, M.; Baig, I.; Aggoune, M. Wireless Sensor’s Civil Applications, Prototypes, and Future Integration Possibilities: A Review. IEEE Sens. J. 2018, 18, 4–30. [Google Scholar] [CrossRef]
- Raza, M.; Aslam, N.; Le-Minh, H.; Hussain, S.; Cao, Y.; Khan, N.M. A Critical Analysis of Research Potential, Challenges, and Future Directives in Industrial Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2018, 20, 39–95. [Google Scholar] [CrossRef]
- Liu, G.; Peng, Z.; Liang, Z.; Li, J.; Cheng, L. Dynamics Analysis of a Wireless Rechargeable Sensor Network for Virus Mutation Spreading. Entropy 2021, 23, 572. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Huang, Z.; Wu, X.; Liang, Z.; Hong, F.; Su, X. Modelling and Analysis of the Epidemic Model under Pulse Charging in Wireless Rechargeable Sensor Networks. Entropy 2021, 23, 927. [Google Scholar] [CrossRef]
- Liang, H.; Yu, G.; Pan, J.; Zhu, T. On-Demand Charging in Wireless Sensor Networks: Theories and Applications. In Proceedings of the IEEE International Conference on Mobile Ad-Hoc & Sensor Systems, Hangzhou, China, 14–16 October 2013; pp. 28–36. [Google Scholar] [CrossRef]
- Wang, C.; Yang, Y.; Li, J. Stochastic Mobile Energy Replenishment and Adaptive Sensor Activation for Perpetual Wireless Rechargeable Sensor Networks. In Proceedings of the 2013 IEEE Wireless Communications and Networking Conference (WCNC), Shanghai, China, 7–10 April 2013; pp. 974–979. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, N.; Wang, F.; Qian, Q.; Li, X. Starvation Avoidance Mobile Energy Replenishment for Wireless Rechargeable Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Liang, W.; Xu, Z.; Xu, W.; Shi, J.; Mao, G.; Das, S.K. Approximation Algorithms for Charging Reward Maximization in Rechargeable Sensor Networks via a Mobile Charger. IEEE/ACM Trans. Netw. 2017, 25, 3161–3174. [Google Scholar] [CrossRef]
- Peng, Y.; Li, Z.; Zhang, W.; Qiao, D. Prolonging Sensor Network Lifetime through Wireless Charging. In Proceedings of the 2010 31st IEEE Real-Time Systems Symposium, RTSS 2010, San Diego, CA, USA, 30 November—3 December 2010; pp. 129–139. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Peng, Y.; Zhang, W.; Qiao, D. J-RoC: A Joint Routing and Charging Scheme to Prolong Sensor Network Lifetime. In Proceedings of the 2011 19th IEEE International Conference on Network Protocols, Vancouver, BC, Canada, 17–20 October 2011; pp. 373–382. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Zhao, Z.; Min, G.; Wu, Y. A Novel Approach for Path Plan of Mobile Chargers in Wireless Rechargeable Sensor Networks. In Proceedings of the 2016 12th International Conference on Mobile Ad-Hoc and Sensor Networks (MSN), Hefei, China, 16–18 December 2016; pp. 63–68. [Google Scholar] [CrossRef]
- Ping, Z.; Yiwen, Z.; Shuaihua, M.; Xiaoyan, K.; Jianliang, G. RCSS: A Real-Time on-Demand Charging Scheduling Scheme for Wireless Rechargeable Sensor Networks. Sensors 2018, 18, 1601. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Kong, L.; Gu, Y.; Pan, J.; Zhu, T. Evaluating the on-Demand Mobile Charging in Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2015, 14, 1861–1875. [Google Scholar] [CrossRef]
- Lin, C.; Han, D.; Deng, J.; Wu, G. P2S: A Primary and Passer-By Scheduling Algorithm for On-Demand Charging Architecture in Wireless Rechargeable Sensor Networks. IEEE Trans. Veh. Technol. 2017, 66, 8047–8058. [Google Scholar] [CrossRef]
- Chi, L.; Zhou, J.; Guo, C.; Song, H.; Obaidat, M.S. TSCA: A Temporal-Spatial Real-Time Charging Scheduling Algorithm for on-Demand Architecture in Wireless Rechargeable Sensor Networks. IEEE Trans. Mob. Comput. 2018, 17, 211–224. [Google Scholar] [CrossRef]
- Yan, Z.; Goswami, P.; Mukherjee, A.; Yang, L.; Routray, S.; Palai, G. Low-Energy PSO-Based Node Positioning in Optical Wireless Sensor Networks. Opt.-Int. J. Light Electron Opt. 2018, 181, 378–382. [Google Scholar] [CrossRef]
- Shu, Y.; Shin, K.G.; Chen, J.; Sun, Y. Joint Energy Replenishment and Operation Scheduling in Wireless Rechargeable Sensor Networks. IEEE Trans. Ind. Inform. 2017, 13, 125–134. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, W.; Han, G.; Kang, Y.; Wang, J. A Newborn Particle Swarm Optimization Algorithm for Charging-Scheduling Algorithm in Industrial Rechargeable Sensor Networks. IEEE Sens. J. 2020, 20, 11014–11027. [Google Scholar] [CrossRef]
- Chawra, V.K.; Gupta, G.P. Correction to: Hybrid Meta-Heuristic Techniques Based Efficient Charging Scheduling Scheme for Multiple Mobile Wireless Chargers Based Wireless Rechargeable Sensor Networks. Peer-Peer Netw. Appl. 2021, 14, 1316. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, J.; Lu, S. Collaborative Mobile Charging. IEEE Trans. Comput. 2015, 64, 654–667. [Google Scholar] [CrossRef]
- Liang, W.; Xu, W.; Ren, X.; Jia, X.; Lin, X. Maintaining Large-Scale Rechargeable Sensor Networks Perpetually via Multiple Mobile Charging Vehicles. ACM Trans. Sens. Netw. 2016, 12, 1–26. [Google Scholar] [CrossRef]
- Wu, J. Collaborative Mobile Charging and Coverage. J. Comp. Sci. Technol. 2014, 29, 550–561. [Google Scholar] [CrossRef]
- Madhja, A.; Nikoletseas, S.; Raptis, T.P. Hierarchical, Collaborative Wireless Charging in Sensor Networks. In Proceedings of the 2015 IEEE Wireless Communications and Networking Conference (WCNC), New Orleans, LA, USA, 9–12 March 2015; pp. 1285–1290. [Google Scholar] [CrossRef]
- Feng, Y.; Guo, L.; Fu, X.; Liu, N. Efficient Mobile Energy Replenishment Scheme Based on Hybrid Mode for Wireless Rechargeable Sensor Networks. IEEE Sens. J. 2019, 19, 10131–10143. [Google Scholar] [CrossRef]
- Kaswan, A.; Tomar, A.; Jana, P.K. An Efficient Scheduling Scheme for Mobile Charger in on-Demand Wireless Rechargeable Sensor Networks. J. Netw. Comput. Appl. 2018, 114, 123–134. [Google Scholar] [CrossRef]
- Tomar, A.; Muduli, L.; Jana, P.K. A Fuzzy Logic-Based On-Demand Charging Algorithm for Wireless Rechargeable Sensor Networks with Multiple Chargers. IEEE Trans. Mob. Comput. 2021, 20, 2715–2727. [Google Scholar] [CrossRef]
- Cao, X.; Xu, W.; Liu, X.; Peng, J.; Liu, T. A Deep Reinforcement Learning-Based on-Demand Charging Algorithm for Wireless Rechargeable Sensor Networks. Ad Hoc Netw. 2021, 110, 102278. [Google Scholar] [CrossRef]
- Wei, Z.; Liu, F.; Lyu, Z.; Ding, X.; Shi, L.; Xia, C. Reinforcement Learning for a Novel Mobile Charging Strategy in Wireless Rechargeable Sensor Networks. In Wireless Algorithms, Systems, and Applications; Chellappan, S., Cheng, W., Li, W., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 485–496. [Google Scholar] [CrossRef]
- Soni, S.; Shrivastava, M. Novel Wireless Charging Algorithms to Charge Mobile Wireless Sensor Network by Using Reinforcement Learning. SN Appl. Sci. 2019, 1, 1052. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Liu, N.; Zuo, L.; Feng, Y.; Liu, M.; Gong, H.; Liu, M. Dynamic Charging Scheme Problem with Actor-Critic Reinforcement Learning. IEEE Internet Things J. 2021, 8, 370–380. [Google Scholar] [CrossRef]
- Xie, L.; Shi, Y.; Hou, Y.T.; Sherali, H.D. Making Sensor Networks Immortal: An Energy-Renewal Approach with Wireless energy transmission. IEEE/ACM Trans. Netw. 2012, 20, 1748–1761. [Google Scholar] [CrossRef]
- Hou, Y.T.; Shi, Y.; Sherali, H.D. Rate Allocation and Network Lifetime Problems for Wireless Sensor Networks. IEEE/ACM Trans. Netw. 2008, 16, 321–334. [Google Scholar] [CrossRef]
- Shu, Y.; Yousefi, H.; Cheng, P.; Chen, J.; Gu, Y.J.; He, T.; Shin, K.G. Near-Optimal Velocity Control for Mobile Charging in Wireless Rechargeable Sensor Networks. IEEE Trans. Mob. Comput. 2016, 15, 1699–1713. [Google Scholar] [CrossRef] [Green Version]
- Littman, M.L. Markov Games as a Framework for Multi-Agent Reinforcement Learning. In Machine Learning Proceeding 1994; Cohen, W.W., Hirsh, H., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1994; pp. 157–163. [Google Scholar] [CrossRef] [Green Version]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. Available online: https://doi.org/10.48550/arXiv.1706.02275 (accessed on 7 June 2017).
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Wu, Y. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games. Available online: https://arxiv.org/abs/2103.01955 (accessed on 2 March 2021).
- Graves, A.; Wayne, G.; Danihelka, I. Neural Turing Machines. Available online: https://arxiv.org/abs/1410.5401v1 (accessed on 20 October 2014).
- Oh, J.; Chockalingam, V.; Singh, S.; Lee, H. Control of Memory, Active Perception, and Action in Minecraft. Available online: https://arxiv.org/abs/1605.09128 (accessed on 30 May 2016).
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. Available online: https://arxiv.org/abs/1705.08926 (accessed on 24 May 2017).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Available online: https://arxiv.org/abs/1706.03762. (accessed on 12 June 2017).
- Iqbal, S.; Sha, F. Actor-Attention-Critic for Multi-Agent Reinforcement Learning. Available online: https://arxiv.org/abs/1810.02912 (accessed on 5 October 2018).
- Wei, E.; Wicke, D.; Freelan, D.; Luke, S. Multiagent Soft Q-Learning. Available online: https://arxiv.org/abs/1804.09817 (accessed on 25 April 2018).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/abs/1412.6980 (accessed on 22 December 2014).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
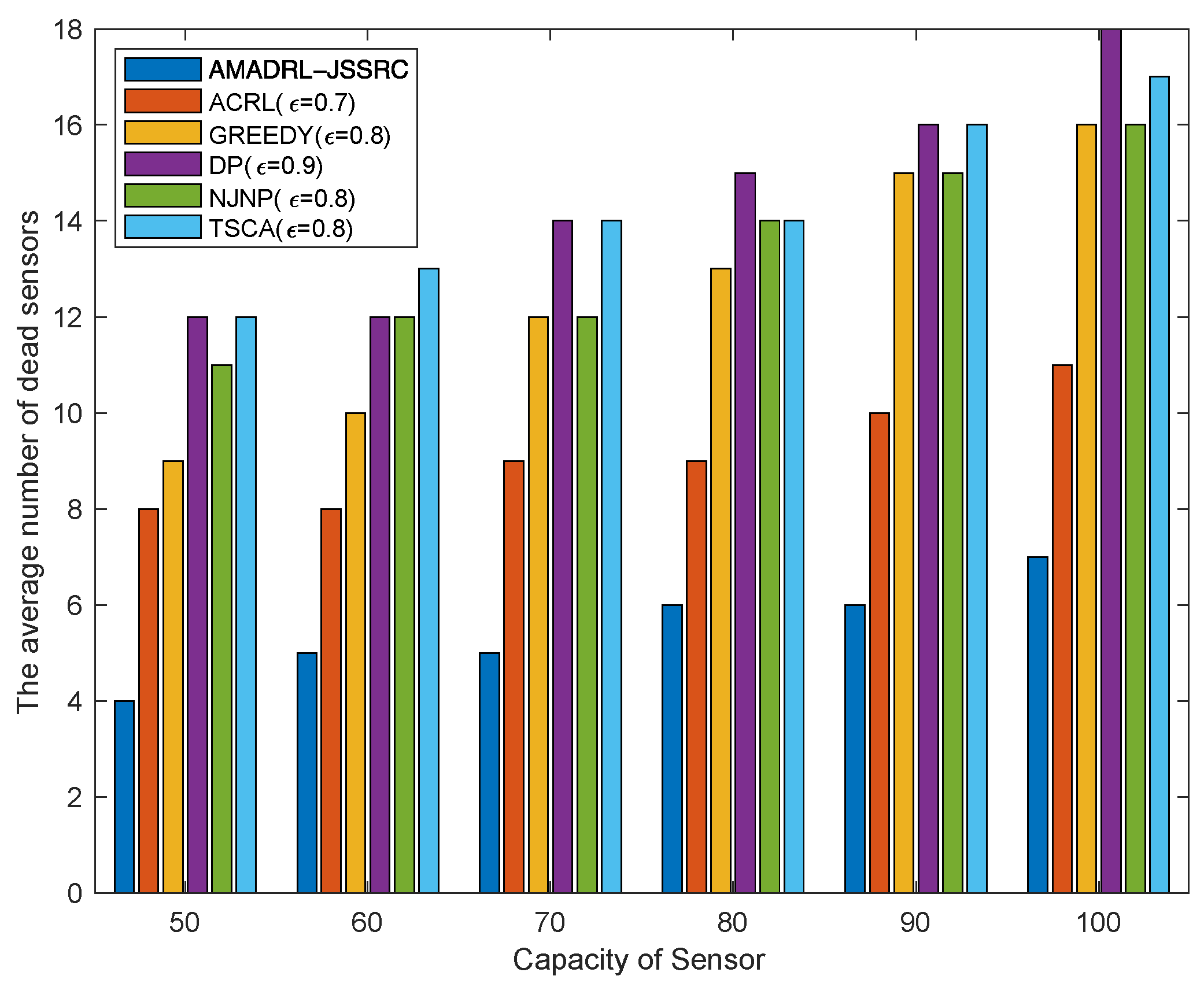{kind=link}
{kind=link}
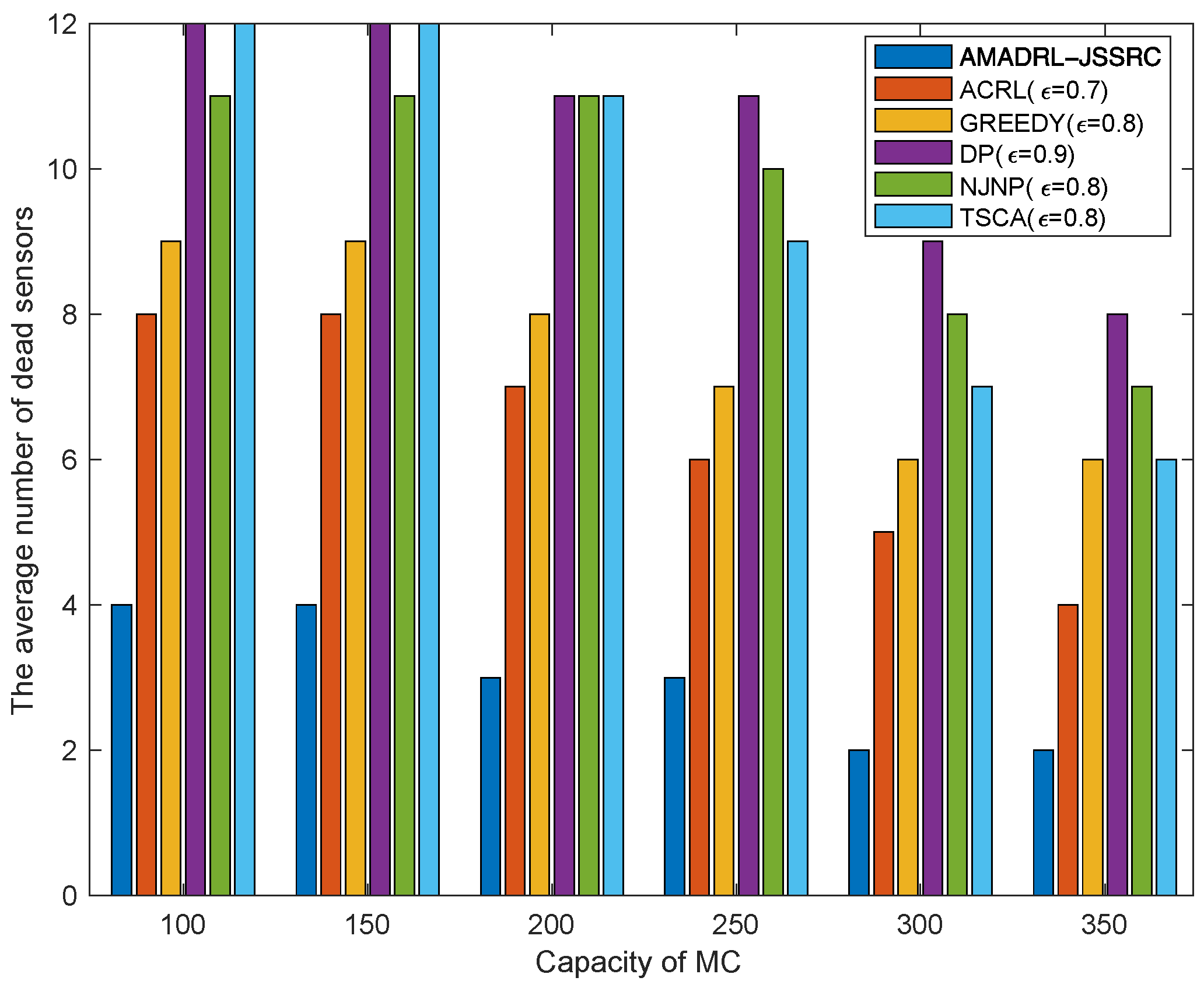{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Dynamic Change of the Sensor Energy Consumption | Charging Sequence Scheduling | Charging Ratio Control | Charging Sequence Scheduling and Charging Ratio Control Simultaneously | |
|---|---|---|---|---|---|
| Off-line | [17] | No | Yes | No | No |
| [18] | No | Yes | No | No | |
| [19] | No | Yes | No | No | |
| [20] | No | Yes | No | No | |
| [21] | No | Yes | No | No | |
| On-line | [16] | Yes | Yes | No | No |
| [25] | Yes | Yes | No | No | |
| [26] | Yes | Yes | No | No | |
| [27] | Yes | Yes | Yes | No | |
| RL | [28] | No | Yes | No | No |
| [29] | No | Yes | No | No | |
| [30] | No | Yes | No | No | |
| [31] | Yes | Yes | No | No | |
| Ours | Yes | Yes | Yes | Yes |
| Abbreviation | Description |
|---|---|
| WRSN | Wireless rechargeable sensor network |
| MC | Mobile charger |
| BS | Base station |
| Dis | Total moving distance of MC during the charging tour |
| JSSRC | Joint mobile charging sequence scheduling and charging ratio control problem |
| AMADRL | Attention-shared multi-agent actor–critic-based deep reinforcement learning |
| Smc | State information of MC |
| Snet | State information of network |
| ACRL | Actor–critic reinforcement learning |
| DP | Dynamic programming |
| NJNP | Nearest-job-next with preemption |
| TSCA | Temporal–spatial real-time charging scheduling algorithm |
| Time Step | Observation | Agent 1 | Agent 2 | Immediate Rewards | ||
|---|---|---|---|---|---|---|
| Individual Reward | ||||||
| 1 | ||||||
| … | … | … | … | … | … | … |
| k | ||||||
| … | … | … | … | … | … | … |
| K | ||||||
| Parameter | Description | Value |
|---|---|---|
| Network size | ||
| Number of sensors | 50–200 | |
| MC initial energy | 100 J | |
| Moving speed of MC | 0.1 m/s | |
| The speed of energy consumed on moving of MC | 0.1 J/m | |
| Charging speed of MC | 1 J/s | |
| Charging ratio | ||
| Energy capacity of sensor | 50 J | |
| The threshold of the number of dead sensors | 0.5 | |
| The set of initial residual energy | 10~20 J |
| Parameter | Description | Value |
|---|---|---|
| Distance-free energy consumption index | ||
| Distance-related energy consumption index | ||
| Energy consumption for receiving or transmitting | ||
| Number of bits | ||
| Signal attenuation coefficient | 4 | |
| Per second packet generation probability | 0.2~0.5 |
| Parameter | Description | Value |
|---|---|---|
| D | Size of experience replay buffer | |
| B | Size of mini-batch | 1024 |
| Actor learning rate | 5 × 10−4 (JSSRC50,100) 5 × 10−5 (JSSRC200) | |
| Critic learning rate | 5 × 10−4 (JSSRC50,100) 5 × 10−5 (JSSRC200) | |
| Number of parallel environments | 4 | |
| Number of episodes | ||
| Number of steps per episode | 100 | |
| Number of critic updates | 4 | |
| Number of policy updates | 4 | |
| Number of multiple attention heads | 4 | |
| Number of target updates | ||
| Adam | Optimizer method | |
| Reward discount | 0.9 | |
| Reward coefficient | 0.5 | |
| Penalty coefficient. | 10 | |
| Update rate of target parameters | 0.005 | |
| Temperature parameter | 0.01 |
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
|---|---|---|---|---|---|
| Reward | −60.72 | −18.05 | 0.19 | 20.89 | 52.45 |
| Number of dead sensors | 25 | 18 | 13 | 8 | 5 |
| Moving distance (m) | 11.37 | 13.15 | 14.85 | 15.55 | 16.77 |
| 0 | 1 | 5 | 8 | 10 | |
|---|---|---|---|---|---|
| Reward | 60.33 | 38.29 | 37.64 | 40.12 | 52.45 |
| Number of dead sensors | 20 | 15 | 11 | 7 | 5 |
| Moving distance (m) | 14.54 | 15.09 | 15.88 | 16.23 | 16.77 |
| Environment | Algorithm | Mean Length | Std | Base Time | Extra Time | |
|---|---|---|---|---|---|---|
| JSSRC50 | AMADRL-JSSRC | 13.918 | 0.802 | 3 | 100 | 0.905 |
| ACRL | 13.878 | 0.798 | 4 | 100 | 0.788 | |
| GREEDY | 13.902 | 0.834 | 2 | 100 | 0.647 | |
| DP | 14.068 | 0.856 | 6 | 100 | 0.743 | |
| NJNP | 13.834 | 0.815 | 5 | 100 | 0.516 | |
| TSCA | 14.028 | 0.755 | 4 | 100 | 0.498 | |
| JSSRC100 | AMADRL-JSSRC | 17.454 | 1.228 | 5 | 200 | 1.463 |
| ACRL | 16.768 | 1.266 | 8 | 200 | 1.32 | |
| GREEDY | 18.233 | 1.445 | 13 | 200 | 1.38 | |
| DP | 18.088 | 1.328 | 13 | 200 | 1.12 | |
| NJNP | 16.891 | 1.306 | 12 | 200 | 0.995 | |
| TSCA | 17.718 | 1.205 | 11 | 200 | 0.936 | |
| JSSRC200 | AMADRL-JSSRC | 36.769 | 1.813 | 8 | 300 | 1.828 |
| ACRL | 36.126 | 1.998 | 12 | 300 | 1.482 | |
| GREEDY | 37.856 | 3.162 | 19 | 300 | 1.635 | |
| DP | 37.532 | 2.376 | 18 | 300 | 1.864 | |
| NJNP | 35.513 | 2.265 | 17 | 300 | 1.465 | |
| TSCA | 35.921 | 2.169 | 16 | 300 | 1.416 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, C.; Wang, Z.; Chen, S.; Li, J.; Wang, H.; Xiang, J.; Xiao, W. Attention-Shared Multi-Agent Actor–Critic-Based Deep Reinforcement Learning Approach for Mobile Charging Dynamic Scheduling in Wireless Rechargeable Sensor Networks. Entropy 2022, 24, 965. https://doi.org/10.3390/e24070965
Jiang C, Wang Z, Chen S, Li J, Wang H, Xiang J, Xiao W. Attention-Shared Multi-Agent Actor–Critic-Based Deep Reinforcement Learning Approach for Mobile Charging Dynamic Scheduling in Wireless Rechargeable Sensor Networks. Entropy. 2022; 24(7):965. https://doi.org/10.3390/e24070965
Chicago/Turabian StyleJiang, Chengpeng, Ziyang Wang, Shuai Chen, Jinglin Li, Haoran Wang, Jinwei Xiang, and Wendong Xiao. 2022. "Attention-Shared Multi-Agent Actor–Critic-Based Deep Reinforcement Learning Approach for Mobile Charging Dynamic Scheduling in Wireless Rechargeable Sensor Networks" Entropy 24, no. 7: 965. https://doi.org/10.3390/e24070965