
Research on Computer-Aided Diagnosis Method Based on Symptom Filtering and Weighted Network


Abstract
:1. Introduction
2. Hierarchical Reinforcement Model
2.1. Markov Decision Process
2.2. Hierarchical Reinforcement Learning Model
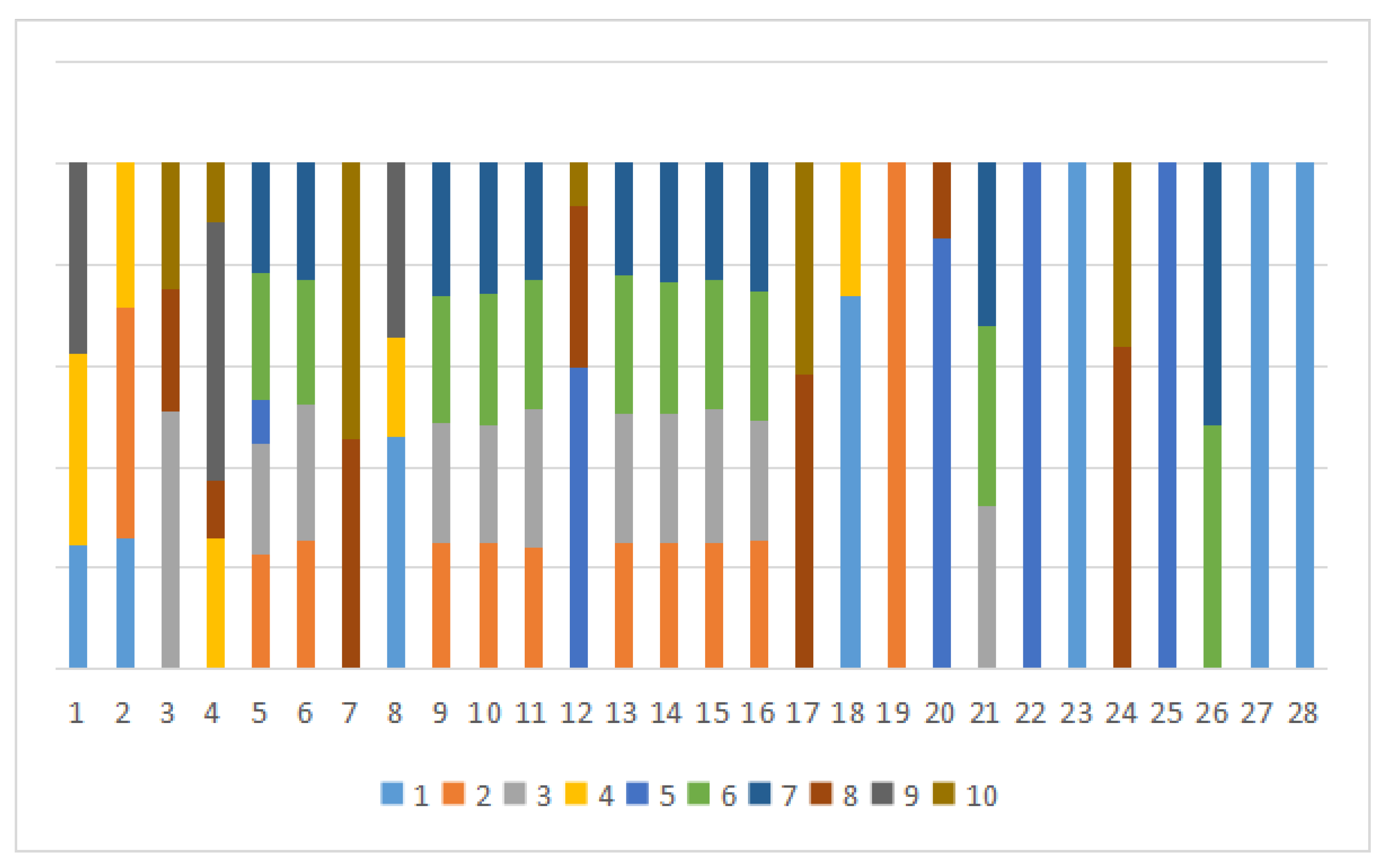
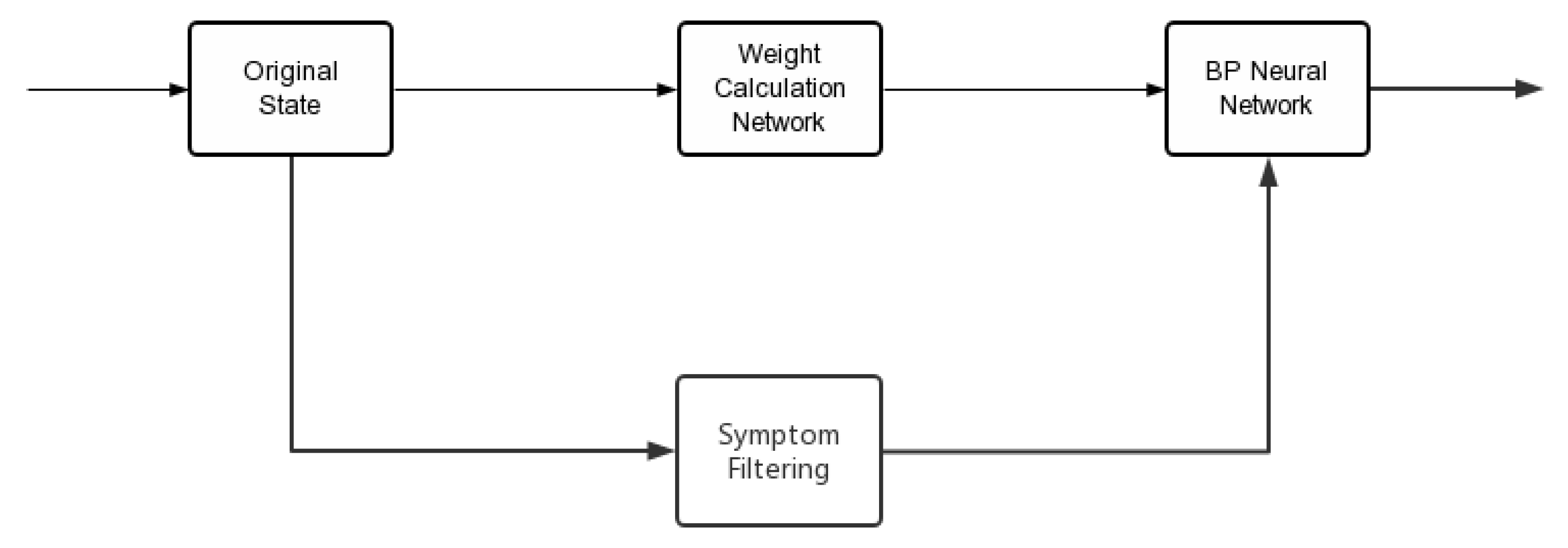
3. Disease Symptom Information Filter
3.1. Sub-Decisions Maker Symptom Filter
3.2. Main-Decision Maker Symptom Filter
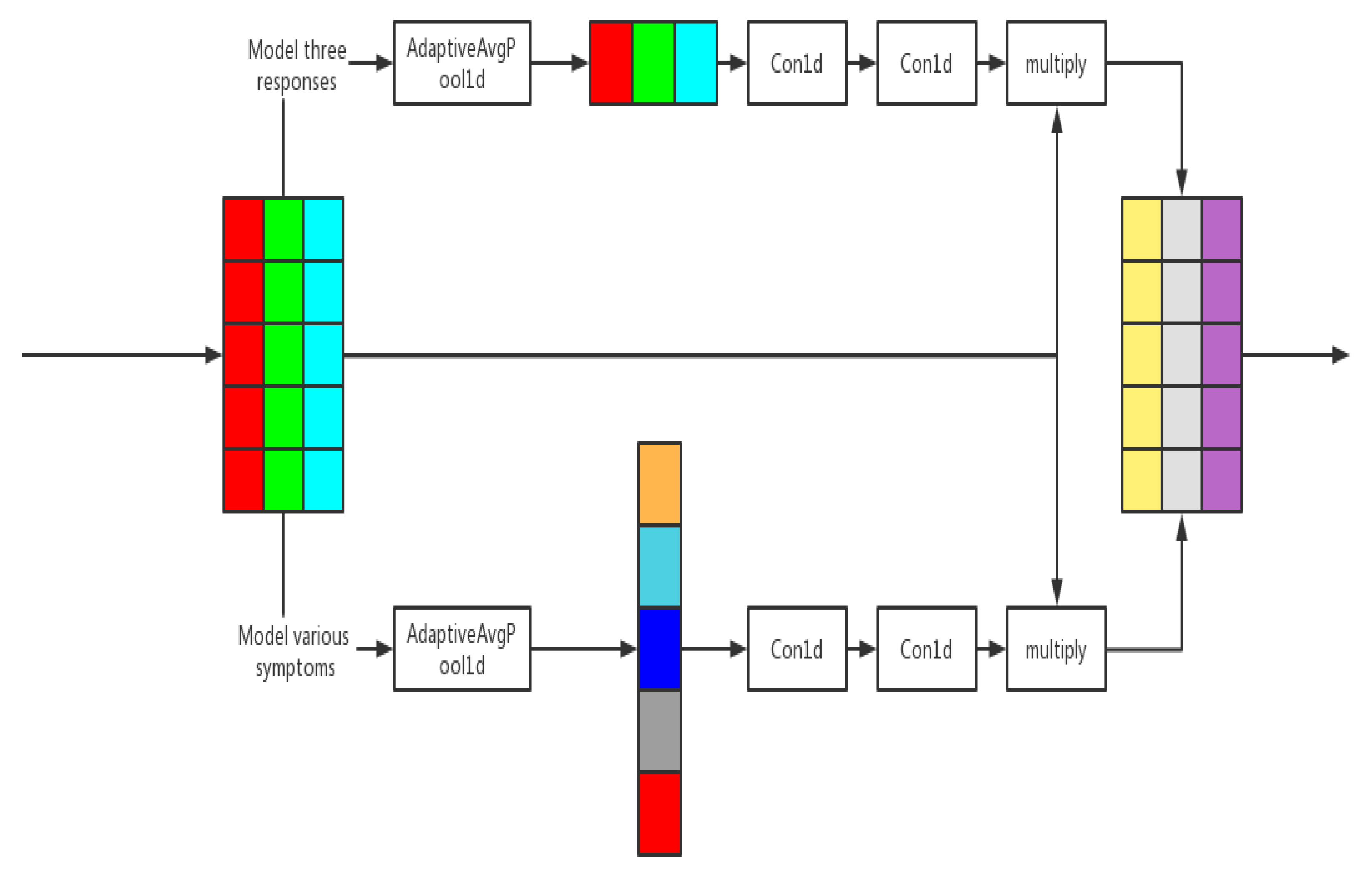
4. Weighted Network
4.1. Weighted Network Module
4.2. Channel Modeling and Weighted Network
5. Experiments and Results
5.1. Data Set
5.2. Main Parameters Settings
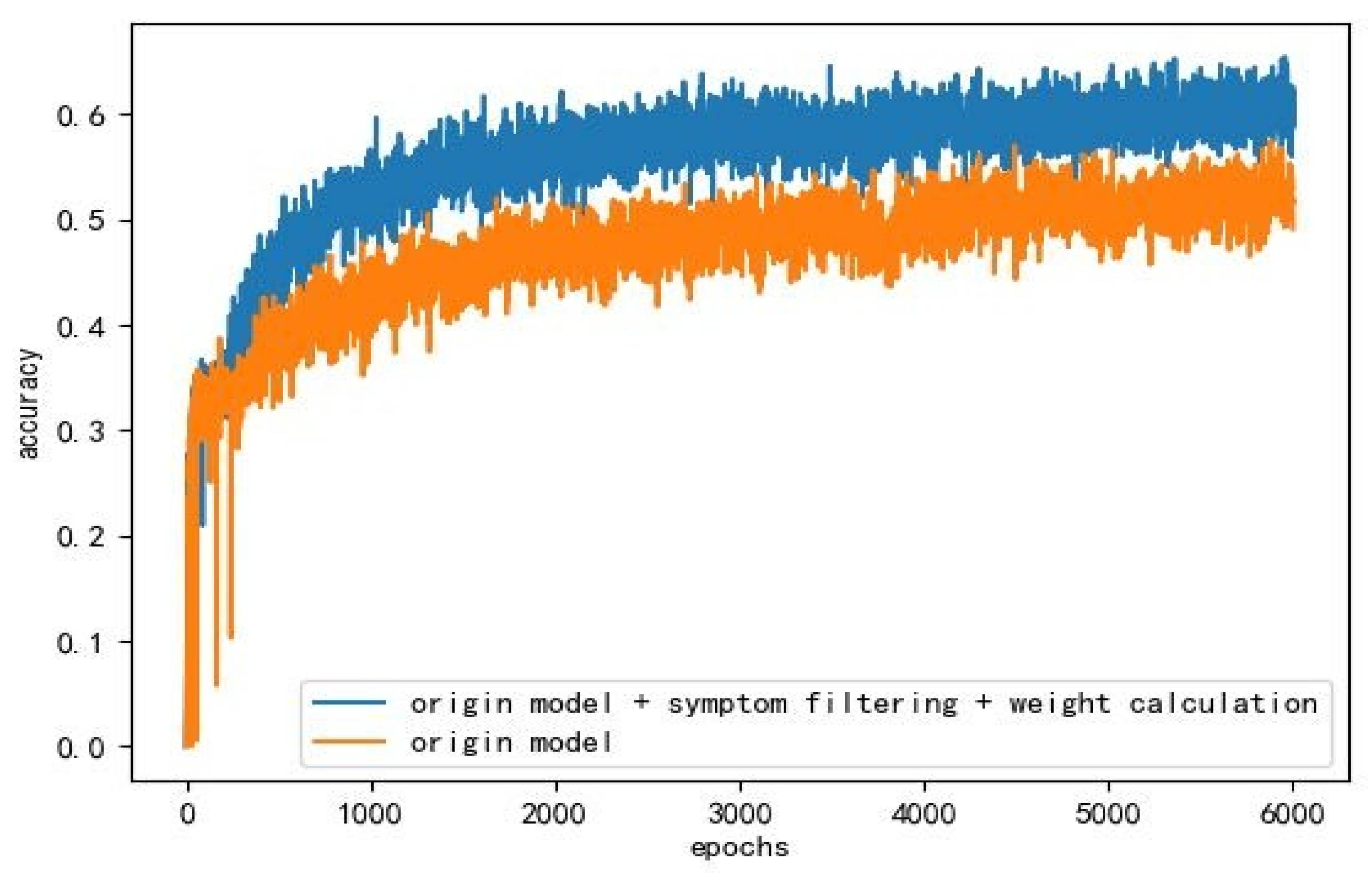
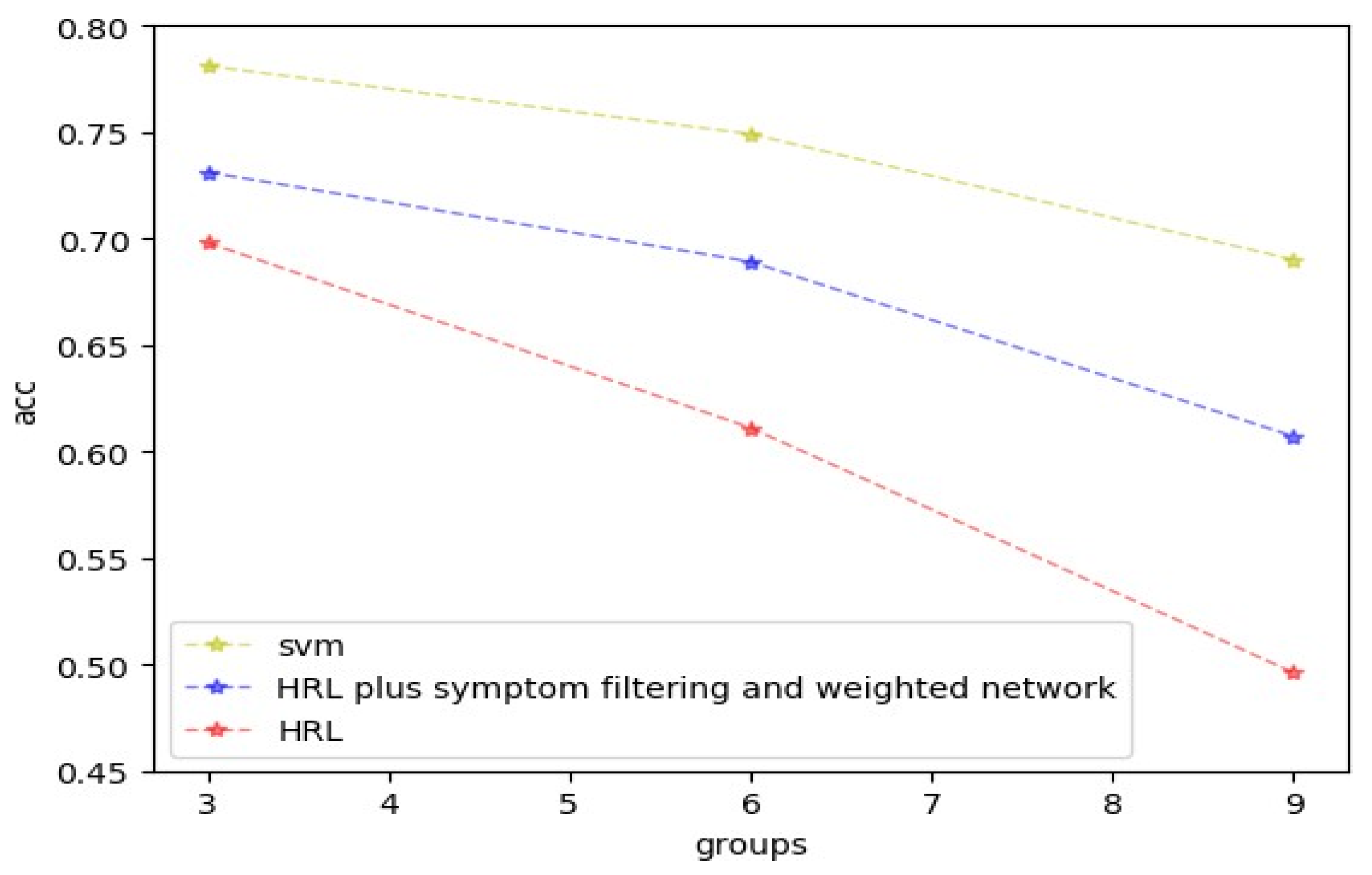
5.3. Experimental Results and Comparison
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Du, C. From informed consent to concerted efforts of doctors and patients. Med. Philos. 2019, 40, 1–7. [Google Scholar]
- Li, L.; Cheng, W.Y.; Glicksberg, B.S.; Gottesman, O.; Tamler, R.; Chen, R.; Dudley, J.T. Identification of type 2 diabetes subgroups through topologcical analysis of patient similarity. Sci. Transl. Med. 2015, 7, 311ral174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, E.; Schuetz, A.; Stewart, W.F.; Sun, J. Using recurrent neural network models for early detection of heart failure onset. J. Am. Med. Inform. Assoc. 2016, 24, 361–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y. Application of data mining technology in medical diagnosis—Perceptron model for heart disease diagnosis. Pract. Electron. 2019, 4, 8–10. [Google Scholar]
- Chen, Q.; Ping, W.; Zheng, L. Carabao disease diagnosis system based on back propagation artificial neural network. Comput. Eng. Des. 2008, 29, 1485–1488. [Google Scholar]
- Lin, S.; Zhou, P.; Liang, X.; Tang, J.; Zhao, R.; Chen, Z.; Lin, L. Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Conference, 2–9 February 2021; Volume 35, pp. 13362–13370. [Google Scholar]
- Xu, L.; Zhou, Q.; Gong, K.; Liang, X.; Tang, J.; Lin, L. End-to-end knowledge-routed relational dialogue system for automatic diagnosis. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33. [Google Scholar]
- Wei, Z.; Liu, Q.; Peng, B.; Tou, H.; Chen, T.; Huang, X.J.; Dai, X. Task-oriented Dialogue System for Automatic Diagnosis. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2. [Google Scholar]
- Tang, K.F.; Kao, H.C.; Chou, C.N.; Chang, E.Y. Inquire and Diagnose: Neural Symptom Checking Ensemble Using Deep Reinforcement Learning. NIPS Workshop on Deep Reinforcement Learning. 2017. Available online: https://sites.google.com/view/deeprl-symposium-nips2017/home (accessed on 15 January 2016).
- Zhang, J.; Hao, B.; Chen, B.; Li, C.; Chen, H.; Sun, J. Hierarchical reinforcement learning for course recommendation in MOOCs. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 435–442. [Google Scholar]
- Feng, J.; Huang, M.; Zhang, Y.; Yang, Y.; Zhu, X. Relation Mention Extraction from Noisy Data with Hierarchical Reinforcement Learning. arXiv 2018, arXiv:1811.01237. [Google Scholar]
- Zhang, J.; Zhao, T.; Yu, Z. Multimodal Hierarchical Reinforcement Learning Policy for Task-Oriented Visual Dialog. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, Melbourne, Australia, 12–14 July 2018; pp. 140–150. [Google Scholar]
- Liao, K.; Liu, Q.; Wei, Z.; Peng, B.; Chen, Q.; Sun, W.; Huang, X. Task-oriented Dialogue System for Automatic Diagnosis via Hierarchical Reinforcement Learning. arXiv 2020, arXiv:2004.14254. [Google Scholar]
- Yang, J. Analysis of cloud network information data mining algorithm based on artificial intelligence decision. Chin. Foreign Commun. 2018, 50, 22–33. [Google Scholar]
- Qu, D. Extracting the Digital Differential Signal Based FIR and IIR Fliters. Comput. Simul. 2002, 19, 4–6. [Google Scholar]
- Yu, L.; Du, Q.; Yue, B. Survey of Reinforcement Learning Based Recommender System. Comput. Sci. 2021, 48, 1–18. [Google Scholar]
- Liang, X.; Feng, Y.; Ma, Y. Deep Muti-Agent Reinforcement Learning. Acta Autom. Sin. 2020, 46, 2537–2557. [Google Scholar]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement learning in healthcare: A survey. ACM Comput. Surv. 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Liu, R.; Zhang, H.; Xiao, Y. Research on multiple unmanned aerial vehicles cooperative path planning based on improved Markov decision processes model. J. Nanjing Univ. Sci. Technol. 2021, 45, 84–91. [Google Scholar]
- Guan, R.; Ding, J.; Jia, L. A Diversity Document Ranking Algorithm based on Reinforcement Learning. Comput. Eng. Sci. 2020, 42, 1697–1703. [Google Scholar]
- Lai, J.; Wei, J.; Chen, X. Overview of Hierarchical Reinforcement Learning. Comput. Eng. Appl. 2021, 57, 72–79. [Google Scholar]
- Zhao, K.; Wu, S.; Li, T. A study on method of rolling bearing fault diagnosis based on Inception-BLSTM. J. Vib. Shock 2021, 40, 290–297. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks; IEEE: Piscataway, NJ, USA, 2016; pp. 2874–2883. [Google Scholar]
- Hu, J.; Li, S.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Jiang, K.; Bai, W.; Zhang, L.; Chen, J.; Pan, Z.; Guo, S. Malicious code detection based on multi-channel image deep learning. J. Comput. Appl. 2021, 41, 1142–1147. [Google Scholar]
- Chen, M.; Zhu, Y.; Lu, B. Classification of Application Type of Encrypted Traffic Based on Attention-CNN. Comput. Sci. 2021, 48, 325–332. [Google Scholar]
- Xia, Y.; Zhou, J.; Shi, Z.; Lu, C.; Huang, H. Generative Adversarial Regularized Mutual Information Policy Gradient Framework for Automatic Diagnosis. AAAI Conf. Artif. Intell. 2020, 34, 7346–7353. [Google Scholar] [CrossRef]
- Chen, Y.; Xin, M.; Chen, Q. Ontology-based Knowledge Base of Disease of Design. China Digit. Med. 2010, 10, 29–31. [Google Scholar]
- Yin, C.; Yang, R.; Zhu, W. A survey on multi-agent hierarchical reinforcement learning. CAAI Trans. Intell. Syst. 2020, 15, 646–655. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Award | Average Epochs |
|---|---|---|---|
| HRL | 49.5% | 0.473 | 16.2 |
| HRL plus Symptom filtering | 52.9% | 0.61 | 19.76 |
| HRL plus Weighted network | 53.4% | 0.76 | 20.18 |
| Our model | 60.5% | 2.13 | 19.23 |
| SVM | 69.8% | / | / |
| Method | Accuracy | Award | Average Epochs |
|---|---|---|---|
| Flat-DQN | 68.2% | 0.513 | 2.712 |
| HRL-pretrained | 69.9% | 0.563 | 2.815 |
| DQN+relation branch | 70.1% | 0.595 | 2.651 |
| Our model | 71.0% | 0.613 | 2.893 |
| Model | Accuracy | Award | Average Epochs |
|---|---|---|---|
| Flat-DQN | 68.5% | 0.522 | 2.720 |
| HRL-pretrained | 69.7% | 0.559 | 2.800 |
| DQN+relation branch | 70.1% | 0.578 | 2.649 |
| Our model | 71.9% | 0.580 | 2.805 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Wang, H. Research on Computer-Aided Diagnosis Method Based on Symptom Filtering and Weighted Network. Entropy 2022, 24, 931. https://doi.org/10.3390/e24070931
Huang X, Wang H. Research on Computer-Aided Diagnosis Method Based on Symptom Filtering and Weighted Network. Entropy. 2022; 24(7):931. https://doi.org/10.3390/e24070931
Chicago/Turabian StyleHuang, Xiaoxi, and Haoxin Wang. 2022. "Research on Computer-Aided Diagnosis Method Based on Symptom Filtering and Weighted Network" Entropy 24, no. 7: 931. https://doi.org/10.3390/e24070931