
Revealing the Dynamics of Neural Information Processing with Multivariate Information Decomposition

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Tracking Information in Neural Circuits
2.1. Defining Key Dimensions
2.2. Tracking Information
3. Information Processing in Neural Circuits
- The future state of Y ();
- The past state of the target Y ();
- The past state of ();
- The past state of ().
4. PID: Partial Information Decomposition
4.1. The Basic Problem and Intuition
The Special Case of Two Parents
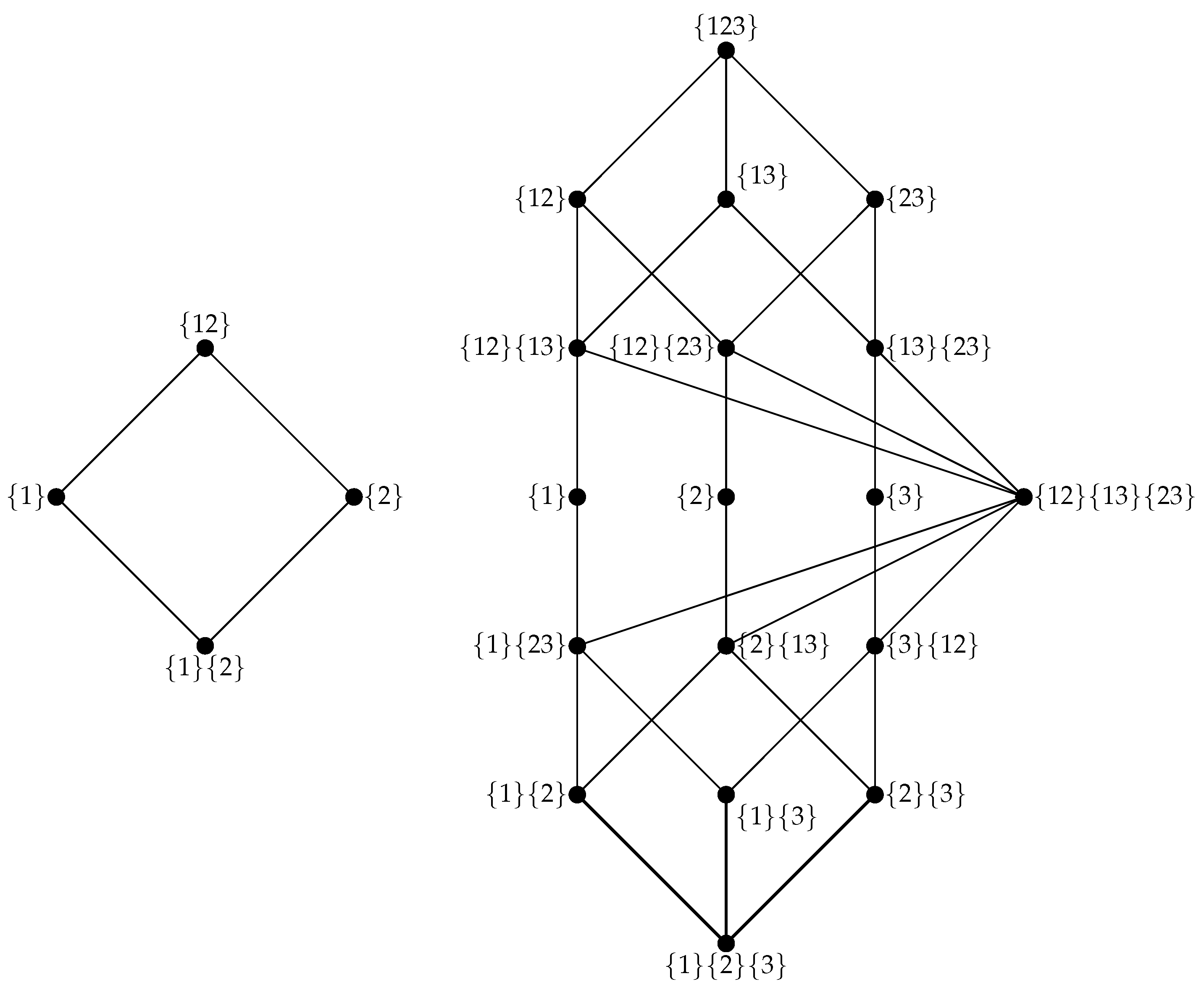
4.2. The Partial Information Lattice
4.3. Choosing a Redundancy Measure
5. PID in Action
5.1. Synergy in Rich Clubs
5.2. The Importance of Feedforward, Feedback, and Recurrent Connections
5.3. Synergy from the Convergence of Correlated Information
5.4. Caveats to Consider
5.5. PID in Behaving Primates
6. Practical Considerations in PID
6.1. Tools for Data Analysis
6.2. Interpreting PID Results as Neural Information Processing
6.3. Practical Limitations of the PID Framework
7. Future Directions
7.1. Local PID
7.2. Multi-Target and Temporal PID
8. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Faber, S.P.; Timme, N.M.; Beggs, J.M.; Newman, E.L. Computation is concentrated in rich clubs of local cortical networks. Netw. Neurosci. 2018, 3, 384–404. [Google Scholar] [CrossRef] [PubMed]
- Sherrill, S.P.; Timme, N.M.; Beggs, J.M.; Newman, E.L. Correlated activity favors synergistic processing in local cortical networks in vitro at synaptically relevant timescales. Netw. Neurosci. 2020, 4, 678–697. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sherrill, S.P.; Timme, N.M.; Beggs, J.M.; Newman, E.L. Partial information decomposition reveals that synergistic neural integration is greater downstream of recurrent information flow in organotypic cortical cultures. PLoS Comput. Biol. 2021, 17, e1009196. [Google Scholar] [CrossRef]
- Varley, T.F.; Sporns, O.; Schaffelhofer, S.; Scherberger, H.; Dann, B. Information processing dynamics in neural networks of macaque cerebral cortex reflect cognitive state and behavior. bioRxiv 2022. [Google Scholar] [CrossRef]
- Mason, A.; Nicoll, A.; Stratford, K. Synaptic transmission between individual pyramidal neurons of the rat visual cortex in vitro. J. Neurosci. Off. J. Soc. Neurosci. 1991, 11, 72–84. [Google Scholar] [CrossRef] [Green Version]
- Swadlow, H.A. Efferent neurons and suspected interneurons in motor cortex of the awake rabbit: Axonal properties, sensory receptive fields, and subthreshold synaptic inputs. J. Neurophysiol. 1994, 71, 437–453. [Google Scholar] [CrossRef]
- Jercog, D.; Roxin, A.; Barthó, P.; Luczak, A.; Compte, A.; Rocha, J.D.L. UP-DOWN cortical dynamics reflect state transitions in a bistable network. eLife 2017, 6, e22425. [Google Scholar] [CrossRef]
- Timme, N.M.; Lapish, C. A Tutorial for Information Theory in Neuroscience. eNeuro 2018, 5, ENEURO.0052-18.2018. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Entropy, Relative Entropy, and Mutual Information. In Elements of Information Theory; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005; pp. 13–55. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Rozell, C.J.; Johnson, D.H. Examining methods for estimating mutual information in spiking neural systems. Neurocomputing 2005, 65, 429–434. [Google Scholar] [CrossRef] [Green Version]
- Friston, K.J. Functional and effective connectivity: A review. Brain Connect. 2011, 1, 13–36. [Google Scholar] [CrossRef] [PubMed]
- Bossomaier, T.; Barnett, L.; Harré, M.; Lizier, J.T. An Introduction to Transfer Entropy: Information Flow in Complex Systems; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Faes, L.; Nollo, G.; Porta, A. Information-based detection of nonlinear Granger causality in multivariate processes via a nonuniform embedding technique. Phys. Rev. E 2011, 83, 051112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ito, S.; Hansen, M.E.; Heiland, R.; Lumsdaine, A.; Litke, A.M.; Beggs, J.M. Extending Transfer Entropy Improves Identification of Effective Connectivity in a Spiking Cortical Network Model. PLoS ONE 2011, 6, e27431. [Google Scholar] [CrossRef]
- Goetze, F.; Lai, P.Y. Reconstructing positive and negative couplings in Ising spin networks by sorted local transfer entropy. Phys. Rev. E 2019, 100, 012121. [Google Scholar] [CrossRef]
- Lizier, J.T.; Flecker, B.; Williams, P.L. Towards a Synergy-based Approach to Measuring Information Modification. arXiv 2013, arXiv:1303.3440. [Google Scholar] [CrossRef] [Green Version]
- Williams, P.L.; Beer, R.D. Generalized Measures of Information Transfer. arXiv 2011, arXiv:1102.1507. [Google Scholar]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef] [Green Version]
- Goodwell, A.E.; Kumar, P. Temporal information partitioning: Characterizing synergy, uniqueness, and redundancy in interacting environmental variables. Water Resour. Res. 2017, 53, 5920–5942. [Google Scholar] [CrossRef]
- Varley, T.F.; Kaminski, P. Intersectional synergies: Untangling irreducible effects of intersecting identities via information decomposition. arXiv 2021, arXiv:2106.10338. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef] [Green Version]
- James, R.G.; Emenheiser, J.; Crutchfield, J.P. Unique Information and Secret Key Agreement. Entropy 2019, 21, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quax, R.; Har-Shemesh, O.; Sloot, P.M.A. Quantifying Synergistic Information Using Intermediate Stochastic Variables. Entropy 2017, 19, 85. [Google Scholar] [CrossRef] [Green Version]
- Rosas, F.E.; Mediano, P.A.M.; Rassouli, B.; Barrett, A.B. An operational information decomposition via synergistic disclosure. J. Phys. Math. Theor. 2020, 53, 485001. [Google Scholar] [CrossRef]
- Timme, N.M.; Ito, S.; Myroshnychenko, M.; Nigam, S.; Shimono, M.; Yeh, F.C.; Hottowy, P.; Litke, A.M.; Beggs, J.M. High-Degree Neurons Feed Cortical Computations. PLoS Comput. Biol. 2016, 12, e1004858. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared Information–New Insights and Problems in Decomposing Information in Complex Systems. arXiv 2013, arXiv:1210.5902. [Google Scholar] [CrossRef] [Green Version]
- Gutknecht, A.J.; Wibral, M.; Makkeh, A. Bits and pieces: Understanding information decomposition from part-whole relationships and formal logic. Proc. R. Soc. Math. Phys. Eng. Sci. 2021, 477, 20210110. [Google Scholar] [CrossRef]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. Stat. Nonlinear Soft Matter Phys. 2013, 87, 012130. [Google Scholar] [CrossRef] [Green Version]
- Griffith, V.; Chong, E.K.P.; James, R.G.; Ellison, C.J.; Crutchfield, J.P. Intersection Information Based on Common Randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef] [Green Version]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. arXiv 2014, arXiv:1205.4265. [Google Scholar]
- Olbrich, E.; Bertschinger, N.; Rauh, J. Information Decomposition and Synergy. Entropy 2015, 17, 3501–3517. [Google Scholar] [CrossRef] [Green Version]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ince, R.A.A. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef] [Green Version]
- Finn, C.; Lizier, J.T. Pointwise Partial Information Decomposition Using the Specificity and Ambiguity Lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [Green Version]
- Ay, N.; Polani, D.; Virgo, N. Information Decomposition based on Cooperative Game Theory. arXiv 2019, arXiv:1910.05979. [Google Scholar] [CrossRef]
- Kolchinsky, A. A Novel Approach to the Partial Information Decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef]
- Makkeh, A.; Gutknecht, A.J.; Wibral, M. Introducing a differentiable measure of pointwise shared information. Phys. Rev. E 2021, 103, 032149. [Google Scholar] [CrossRef]
- Lizier, J.T. Measuring the Dynamics of Information Processing on a Local Scale in Time and Space. In Directed Information Measures in Neuroscience; Wibral, M., Vicente, R., Lizier, J.T., Eds.; Series Title: Understanding Complex Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 161–193. [Google Scholar] [CrossRef]
- Kay, J.W.; Ince, R.A.A.; Dering, B.; Phillips, W.A. Partial and Entropic Information Decompositions of a Neuronal Modulatory Interaction. Entropy 2017, 19, 560. [Google Scholar] [CrossRef] [Green Version]
- Nigam, S.; Pojoga, S.; Dragoi, V. Synergistic Coding of Visual Information in Columnar Networks. Neuron 2019. [Google Scholar] [CrossRef]
- Luppi, A.I.; Mediano, P.A.M.; Rosas, F.E.; Allanson, J.; Pickard, J.D.; Carhart-Harris, R.L.; Williams, G.B.; Craig, M.M.; Finoia, P.; Owen, A.M.; et al. A Synergistic Workspace for Human Consciousness Revealed by Integrated Information Decomposition. bioRxiv 2020, 2020.11.25.398081. [Google Scholar] [CrossRef]
- Varley, T.F. Decomposing past and future: Integrated information decomposition based on shared probability mass exclusions. arXiv 2022, arXiv:2202.12992. [Google Scholar]
- Luppi, A.I.; Mediano, P.A.M.; Rosas, F.E.; Holland, N.; Fryer, T.D.; O’Brien, J.T.; Rowe, J.B.; Menon, D.K.; Bor, D.; Stamatakis, E.A. A synergistic core for human brain evolution and cognition. Nat. Neurosci. 2022, 25, 771–782. [Google Scholar] [CrossRef]
- Gähwiler, B.; Capogna, M.; Debanne, D.; McKinney, R.; Thompson, S. Organotypic slice cultures: A technique has come of age. Trends Neurosci. 1997, 20, 471–477. [Google Scholar] [CrossRef]
- Zhou, S.; Mondragon, R. The rich-club phenomenon in the Internet topology. IEEE Commun. Lett. 2004, 8, 180–182. [Google Scholar] [CrossRef] [Green Version]
- Nigam, S.; Shimono, M.; Ito, S.; Yeh, F.C.; Timme, N.; Myroshnychenko, M.; Lapish, C.C.; Tosi, Z.; Hottowy, P.; Smith, W.C.; et al. Rich-Club Organization in Effective Connectivity among Cortical Neurons. J. Neurosci. 2016, 36, 670–684. [Google Scholar] [CrossRef] [Green Version]
- Hafizi, H.; Nigam, S.; Barnathan, J.; Ren, N.; Stevenson, I.H.; Masmanidis, S.C.; Newman, E.L.; Sporns, O.; Beggs, J.M. Inhibition-Dominated Rich-Club Shapes Dynamics in Cortical Microcircuits in Awake Behaving Mice. bioRxiv 2021. [Google Scholar] [CrossRef]
- Novelli, L.; Lizier, J.T. Inferring network properties from time series using transfer entropy and mutual information: Validation of multivariate versus bivariate approaches. Netw. Neurosci. 2021, 5, 373–404. [Google Scholar] [CrossRef]
- Dann, B.; Michaels, J.A.; Schaffelhofer, S.; Scherberger, H. Uniting functional network topology and oscillations in the fronto-parietal single unit network of behaving primates. eLife 2016, 5, e15719. [Google Scholar] [CrossRef] [Green Version]
- Novelli, L.; Wollstadt, P.; Mediano, P.; Wibral, M.; Lizier, J.T. Large-scale directed network inference with multivariate transfer entropy and hierarchical statistical testing. Netw. Neurosci. 2019, 3, 827–847. [Google Scholar] [CrossRef]
- Wollstadt, P.; Lizier, J.T.; Vicente, R.; Finn, C.; Martinez-Zarzuela, M.; Mediano, P.; Novelli, L.; Wibral, M. IDTxl: The Information Dynamics Toolkit xl: A Python package for the efficient analysis of multivariate information dynamics in networks. J. Open Source Softw. 2019, 4, 1081. [Google Scholar] [CrossRef]
- Schick-Poland, K.; Makkeh, A.; Gutknecht, A.J.; Wollstadt, P.; Sturm, A.; Wibral, M. A partial information decomposition for discrete and continuous variables. arXiv 2021, arXiv:2106.12393. [Google Scholar]
- Milzman, J.; Lyzinski, V. Signed and Unsigned Partial Information Decompositions of Continuous Network Interactions. arXiv 2021, arXiv:2112.12316. [Google Scholar]
- Pakman, A.; Nejatbakhsh, A.; Gilboa, D.; Makkeh, A.; Mazzucato, L.; Wibral, M.; Schneidman, E. Estimating the Unique Information of Continuous Variables. arXiv 2021, arXiv:2102.00218. [Google Scholar] [CrossRef]
- Kay, J.W.; Ince, R.A.A. Exact Partial Information Decompositions for Gaussian Systems Based on Dependency Constraints. Entropy 2018, 20, 240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Verdú, S. Empirical Estimation of Information Measures: A Literature Guide. Entropy 2019, 21, 720. [Google Scholar] [CrossRef] [Green Version]
- Panzeri, S.; Senatore, R.; Montemurro, M.A.; Petersen, R.S. Correcting for the Sampling Bias Problem in Spike Train Information Measures. J. Neurophysiol. 2007, 98, 1064–1072. [Google Scholar] [CrossRef] [Green Version]
- James, R.; Ellison, C.; Crutchfield, J. dit: A Python package for discrete information theory. J. Open Source Softw. 2018, 3, 738. [Google Scholar] [CrossRef]
- Watanabe, S. Information Theoretical Analysis of Multivariate Correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar] [CrossRef]
- Tononi, G.; Sporns, O.; Edelman, G.M. A measure for brain complexity: Relating functional segregation and integration in the nervous system. Proc. Natl. Acad. Sci. USA 1994, 91, 5033–5037. [Google Scholar] [CrossRef] [Green Version]
- Lizier, J.T. JIDT: An Information-Theoretic Toolkit for Studying the Dynamics of Complex Systems. Front. Robot. AI 2014, 1, 11. [Google Scholar] [CrossRef] [Green Version]
- Rosas, F.; Mediano, P.A.M.; Gastpar, M.; Jensen, H.J. Quantifying High-order Interdependencies via Multivariate Extensions of the Mutual Information. Phys. Rev. E 2019, 100, 032305. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stramaglia, S.; Scagliarini, T.; Daniels, B.C.; Marinazzo, D. Quantifying Dynamical High-Order Interdependencies from the O-Information: An Application to Neural Spiking Dynamics. Front. Physiol. 2021, 11, 595736. [Google Scholar] [CrossRef] [PubMed]
- Varley, T.F.; Pope, M.; Faskowitz, J.; Sporns, O. Multivariate Information Theory Uncovers Synergistic Subsystems of the Human Cerebral Cortex. arXiv 2022, arXiv:2206.06477. [Google Scholar] [CrossRef]
- Miller, G. Note on the bias of information estimates. In Information Theory in Psychology: Problems and Methods; Free Press: Glencoe, IL, USA, 1955. [Google Scholar]
- Mediano, P.A.M.; Rosas, F.; Carhart-Harris, R.L.; Seth, A.K.; Barrett, A.B. Beyond integrated information: A taxonomy of information dynamics phenomena. arXiv 2019, arXiv:1909.02297. [Google Scholar]
- Mediano, P.A.M.; Rosas, F.E.; Luppi, A.I.; Carhart-Harris, R.L.; Bor, D.; Seth, A.K.; Barrett, A.B. Towards an extended taxonomy of information dynamics via Integrated Information Decomposition. arXiv 2021, arXiv:2109.13186. [Google Scholar]
- Luppi, A.I.; Mediano, P.A.M.; Rosas, F.E.; Harrison, D.J.; Carhart-Harris, R.L.; Bor, D.; Stamatakis, E.A. What it is like to be a bit: An integrated information decomposition account of emergent mental phenomena. Neurosci. Conscious. 2021, 2021, niab027. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Newman, E.L.; Varley, T.F.; Parakkattu, V.K.; Sherrill, S.P.; Beggs, J.M. Revealing the Dynamics of Neural Information Processing with Multivariate Information Decomposition. Entropy 2022, 24, 930. https://doi.org/10.3390/e24070930
Newman EL, Varley TF, Parakkattu VK, Sherrill SP, Beggs JM. Revealing the Dynamics of Neural Information Processing with Multivariate Information Decomposition. Entropy. 2022; 24(7):930. https://doi.org/10.3390/e24070930
Chicago/Turabian StyleNewman, Ehren L., Thomas F. Varley, Vibin K. Parakkattu, Samantha P. Sherrill, and John M. Beggs. 2022. "Revealing the Dynamics of Neural Information Processing with Multivariate Information Decomposition" Entropy 24, no. 7: 930. https://doi.org/10.3390/e24070930