
Chess AI: Competing Paradigms for Machine Intelligence

Abstract
:1. Introduction
Chess is not a game. Chess is a well-defined form of computation. You may not be able to work out the answers, but in theory, there must be a solution, a right procedure in any position—John von Neumann
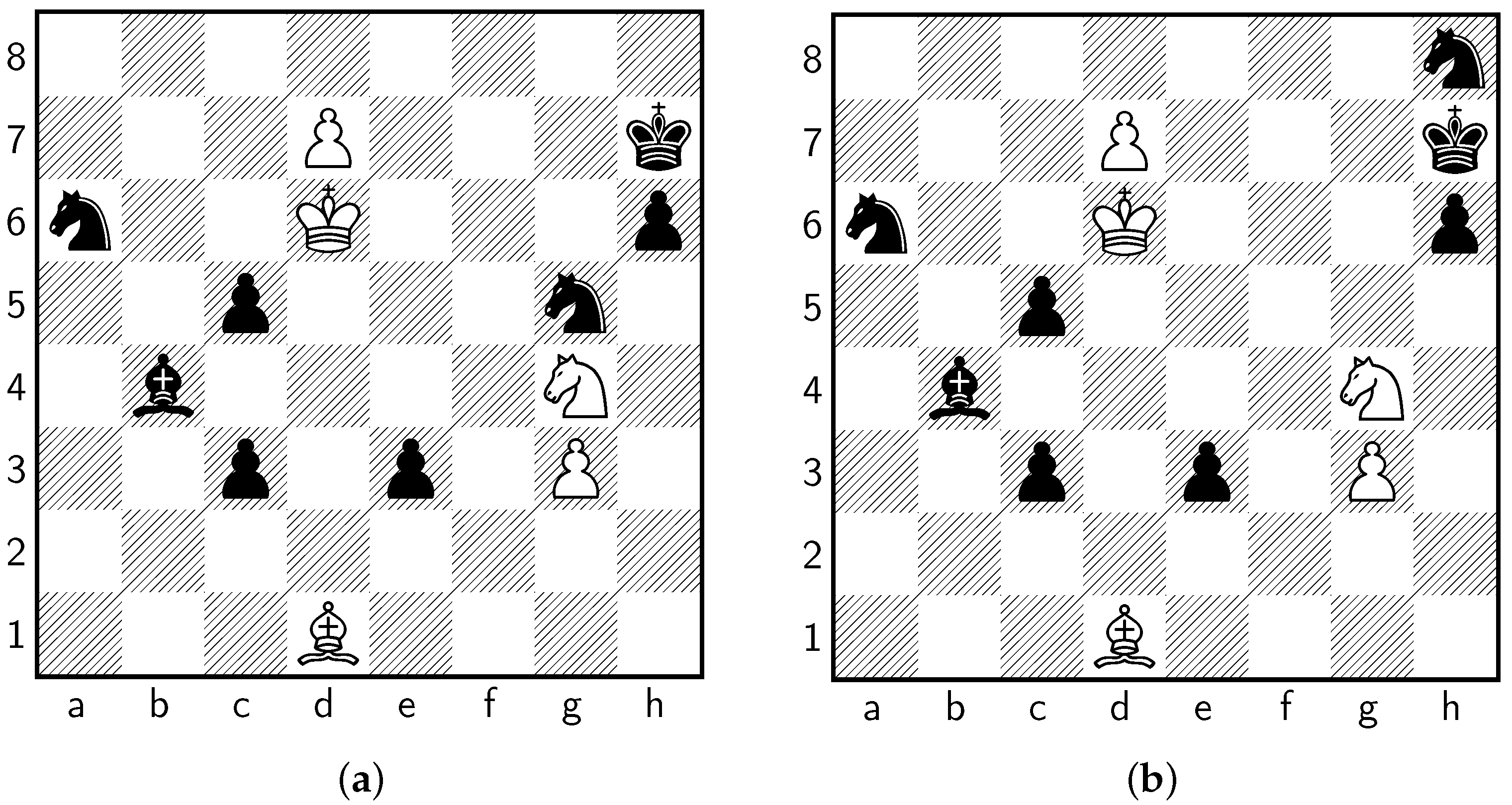
Plaskett’s Study
2. Background: Chess AI
Bellman Principle of Optimality: An optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision.[15]
2.1. Q-Values
2.2. Stockfish 14 Anatomy
2.2.1. Search
2.2.2. Evaluation
2.3. AlphaZero Anatomy
2.3.1. Search
2.3.2. Evaluation
2.4. AlphaZero’s Successor: LCZero
3. Materials and Methods
4. Results
4.1. Stockfish 14 Performance
4.2. LCZero Performance
4.3. Fairness of Engine Comparison
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Romstad, T.; Costalba, M.; Kiiski, J.; Linscott, G.; Nicolet, S.; Geschwentner, S.; VandeVondele, J. Stockfish. Version 14. Available online: https://stockfishchess.org (accessed on 13 April 2022).
- Pascutto, G.C.; Linscott, G.; Lyashuk, A.; Huizinga, F. Leela Chess Zero. Available online: https://lczero.org (accessed on 13 April 2022).
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Segler, M.H.S.; Preuss, M.; Waller, M.P. Towards “AlphaChem”: Chemical Synthesis Planning with Tree Search and Deep Neural Network Policies. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Dalgaard, M.; Motzoi, F.; Sørensen, J.J.; Sherson, J. Global Optimization of Quantum Dynamics with AlphaZero Deep Exploration. NPJ Quantum Inf. 2020, 6, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Edwards, D.J.; Hart, T.P. The Alpha-Beta Heuristic; Technical Report 30; Massachusetts Institute of Technology: Cambridge, MA, USA, 1963. [Google Scholar]
- Wu, M.; Wicker, M.; Ruan, W.; Huang, X.; Kwiatkowska, M. A Game-Based Approximate Verification of Deep Neural Networks with Provable Guarantees. Theor. Comput. Sci. 2020, 807, 298–329. [Google Scholar] [CrossRef]
- Feynman, R. The Pleasure of Finding Things Out; BBC Horizon. Available online: https://www.bbc.co.uk/programmes/p018dvyg (accessed on 13 April 2022).
- Polson, N.; Scott, J. AIQ: How People and Machines Are Smarter Together; St. Martin’s Press, Inc.: New York, NY, USA, 2018. [Google Scholar]
- Friedel, F. Solution to a Truly Remarkable Study. ChessBase. Available online: https://en.chessbase.com/post/solution-to-a-truly-remarkable-study (accessed on 13 April 2022).
- Turing, A. Chess. In Faster than Thought; Bowden, B., Ed.; Pitman: London, UK, 1953. [Google Scholar]
- von Neumann, J. Zur Theorie Der Gesellschaftsspiele. Math. Ann. 1928, 100, 295–320. [Google Scholar] [CrossRef]
- Shannon, C.E. Programming a Computer for Playing Chess. Philos. Mag. 2009, 41, 256–275. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the Game of Go without Human Knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Bellman, R. Dynamic Programming, 1st ed.; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Polson, N.; Sorensen, M. A Simulation-Based Approach to Stochastic Dynamic Programming. Appl. Stoch. Model. Bus. Ind. 2011, 27, 151–163. [Google Scholar] [CrossRef] [Green Version]
- Isenberg, G. Pawn Advantage, Win Percentage, and Elo. Chess Programming Wiki. Available online: https://www.chessprogramming.org/index.php?title=Pawn_Advantage,_Win_Percentage,_and_Elo&oldid=24254 (accessed on 13 April 2022).
- Wiener, N. Information, Language, and Society. In Cybernetics: Or Control and Communication in the Animal and the Machine; MIT Press: Cambridge, MA, USA, 1948; pp. 155–165. [Google Scholar]
- de Groot, A. Thought and Choice in Chess, 2nd ed.; Number 4 in Psychological Studies; Mouton De Gruyter: Berlin, Germany, 1978. [Google Scholar]
- Isenberg, G. Stockfish. Chess Programming Wiki. Available online: https://www.chessprogramming.org/index.php?title=Stockfish&oldid=25665 (accessed on 13 April 2022).
- Schaeffer, J. Experiments in Search and Knowledge. Ph.D. Thesis, University of Waterloo, Waterloo, UK, 1986. [Google Scholar]
- Heinz, E.A. Extended Futility Pruning. ICGA J. 1998, 21, 75–83. [Google Scholar] [CrossRef]
- Levy, D.; Broughton, D.; Taylor, M. The Sex Algorithm in Computer Chess. ICGA J. 1989, 12, 10–21. [Google Scholar] [CrossRef]
- Nasu, Y. Efficiently Updatable Neural-Network-Based Evaluation Functions for Computer Shogi. The 28th World Computer Shogi Championship Appeal Document. 2018. Available online: https://dev.exherbo.org/~alip/doc/nnue_en.pdf (accessed on 13 April 2022).
- Stockfish Team. Introducing NNUE Evaluation; Stockfish Blog. Available online: https://stockfishchess.org/blog/2020/introducing-nnue-evaluation/ (accessed on 13 April 2022).
- Isenberg, G.; Pham, N.H. NNUE. Chess Programming Wiki. Available online: https://www.chessprogramming.org/index.php?title=NNUE&oldid=25719 (accessed on 13 April 2022).
- Rosin, C.D. Multi-Armed Bandits with Episode Context. Ann. Math. Artif. Intell. 2011, 61, 203–230. [Google Scholar] [CrossRef] [Green Version]
- Thrun, S. Learning to Play the Game of Chess. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1995; Volume 7. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Halevy, A.; Norvig, P.; Pereira, F. The Unreasonable Effectiveness of Data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Jordan, B. Calculation versus Intuition: Stockfish versus Leela, 1st ed.; Self-published; 2020. [Google Scholar]
- Botvinnik, M. Computers, Chess and Long-Range Planning; Springer: Berlin, Germany, 1970. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef] [PubMed]
- Searle, J.R. Minds, Brains, and Programs. Behav. Brain Sci. 1980, 3, 417–424. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- LCZero Team. Announcing Ceres; LCZero Blog. Available online: https://lczero.org/blog/2021/01/announcing-ceres/ (accessed on 13 April 2022).
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Toshniwal, S.; Wiseman, S.; Livescu, K.; Gimpel, K. Learning Chess Blindfolded: Evaluating Language Models on State Tracking. arXiv 2021, arXiv:2102.13249. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model Compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 20–23 August 2006; p. 535. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Optimal Brain Damage. In Advances in Neural Information Processing Systems; Touretzky, D., Ed.; Morgan-Kaufmann: Burlington, MA, USA, 1989; Volume 2. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning Both Weights and Connections for Efficient Neural Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 18–20 June 2018; pp. 2704–2713. [Google Scholar]
- Campbell, J. Richard Feynman Computer Heuristics Lecture; YouTube. Available online: https://www.youtube.com/watch?v=EKWGGDXe5MA (accessed on 13 April 2022).
- Mahadevan, S. Imagination Machines: A New Challenge for Artificial Intelligence. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2018. [Google Scholar]
- Lindley, D.V. Understanding Uncertainty; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar] [CrossRef] [Green Version]
- Diaconis, P. Theories of Data Analysis: From Magical Thinking through Classical Statistics. In Exploring Data Tables, Trends, and Shapes; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2006; pp. 1–36. [Google Scholar] [CrossRef]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2020, arXiv:1910.10683. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial Landmark Detection by Deep Multi-task Learning. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Berlin, Germany, 2014; pp. 94–108. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| ♘xe3 | d8♖ | d8♕ | ♗c2+ | ♔d5 | |
|---|---|---|---|---|---|
| Q-value | −3.62 (0.06) | −4.26 (0.69) | −4.28 (0.60) | −4.76 (0.21) | −5.12 (0.08) |
| Win Prob. | 11.1% (0.4%) | 8.3% (2.8%) | 8.1% (2.2%) | 6.1% (0.7%) | 5.0% (0.2%) |
| ♘f6+ | ♘xe3 | d8♕ | d8♖ | ♗c2+ | |
|---|---|---|---|---|---|
| Q-value | +5.44 (1.86) | −3.98 (0.06) | −4.49 (0.51) | −4.50 (0.53) | −5.27 (0.05) |
| Win Prob. | 93.8% (6.4%) | 9.2% (0.3%) | 7.2% (1.8%) | 7.2% (2.0%) | 4.6% (0.1%) |
| ♘f6+ | ♘xe3 | d8♖ | d8♕ | ♔e6 | |
|---|---|---|---|---|---|
| Q-value | ∞ (0) | −3.31 (0.07) | −4.28 (0.30) | −4.31 (0.27) | −4.92 (0.09) |
| Win Prob. | 100% (0%) | 13.0% (0.4%) | 7.9% (1.3%) | 7.8% (1.1%) | 5.6% (0.3%) |
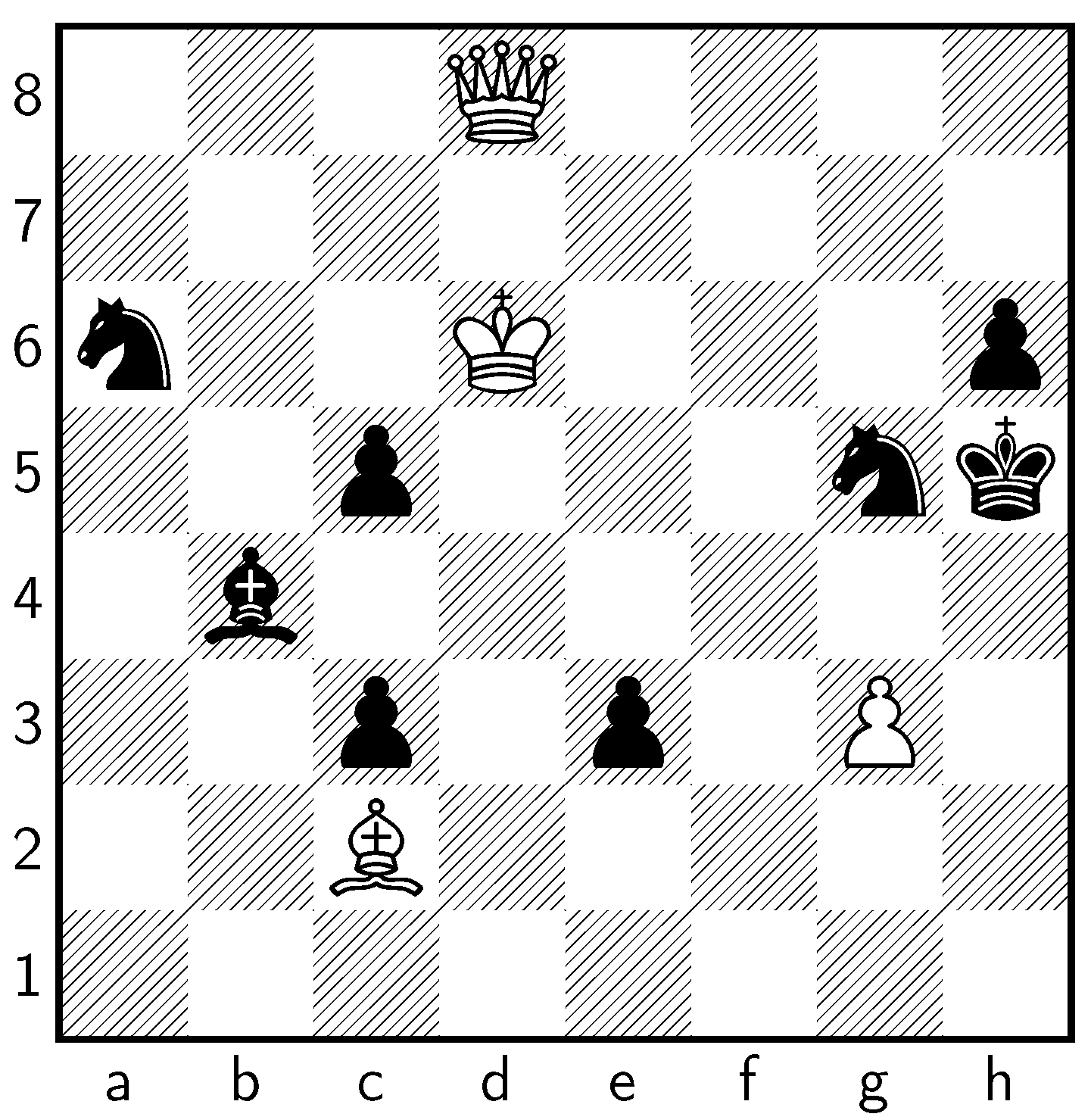
| d8♖ | ♔c6 | d8♕ | ♘f6+ | ♗c2+ | ♘xe3 | |
|---|---|---|---|---|---|---|
| Q-value | −4.67 (0.01) | −5.02 (0.01) | −5.44 (0.09) | −5.61 (0.00) | −6.46 (0.10) | −8.88 (0.00) |
| Win Prob. | 5.86% (0.01%) | 5.44% (0.01%) | 5.02% (0.08%) | 4.86% (0.00%) | 4.2% (0.07%) | 3.01% (0.00%) |
| Policy | 3.11% | 7.23% | 13.33% | 7.40% | 9.22% | 15.75% |
| Visits | 0.53% (0.00%) | 2.39% (0.04%) | 1.27% (0.01%) | 0.36% (0.00%) | 1.07% (0.03%) | 92.35% (0.05%) |
| Moves left | 73.6 (0.1) | 79.3 (0.1) | 73.8 (0.1) | 63.7 (0.0) | 80.5 (0.6) | 95.9 (0.0) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maharaj, S.; Polson, N.; Turk, A. Chess AI: Competing Paradigms for Machine Intelligence. Entropy 2022, 24, 550. https://doi.org/10.3390/e24040550
Maharaj S, Polson N, Turk A. Chess AI: Competing Paradigms for Machine Intelligence. Entropy. 2022; 24(4):550. https://doi.org/10.3390/e24040550
Chicago/Turabian StyleMaharaj, Shiva, Nick Polson, and Alex Turk. 2022. "Chess AI: Competing Paradigms for Machine Intelligence" Entropy 24, no. 4: 550. https://doi.org/10.3390/e24040550