
Forecasting Network Interface Flow Using a Broad Learning System Based on the Sparrow Search Algorithm


Abstract
:1. Introduction
2. Related Work
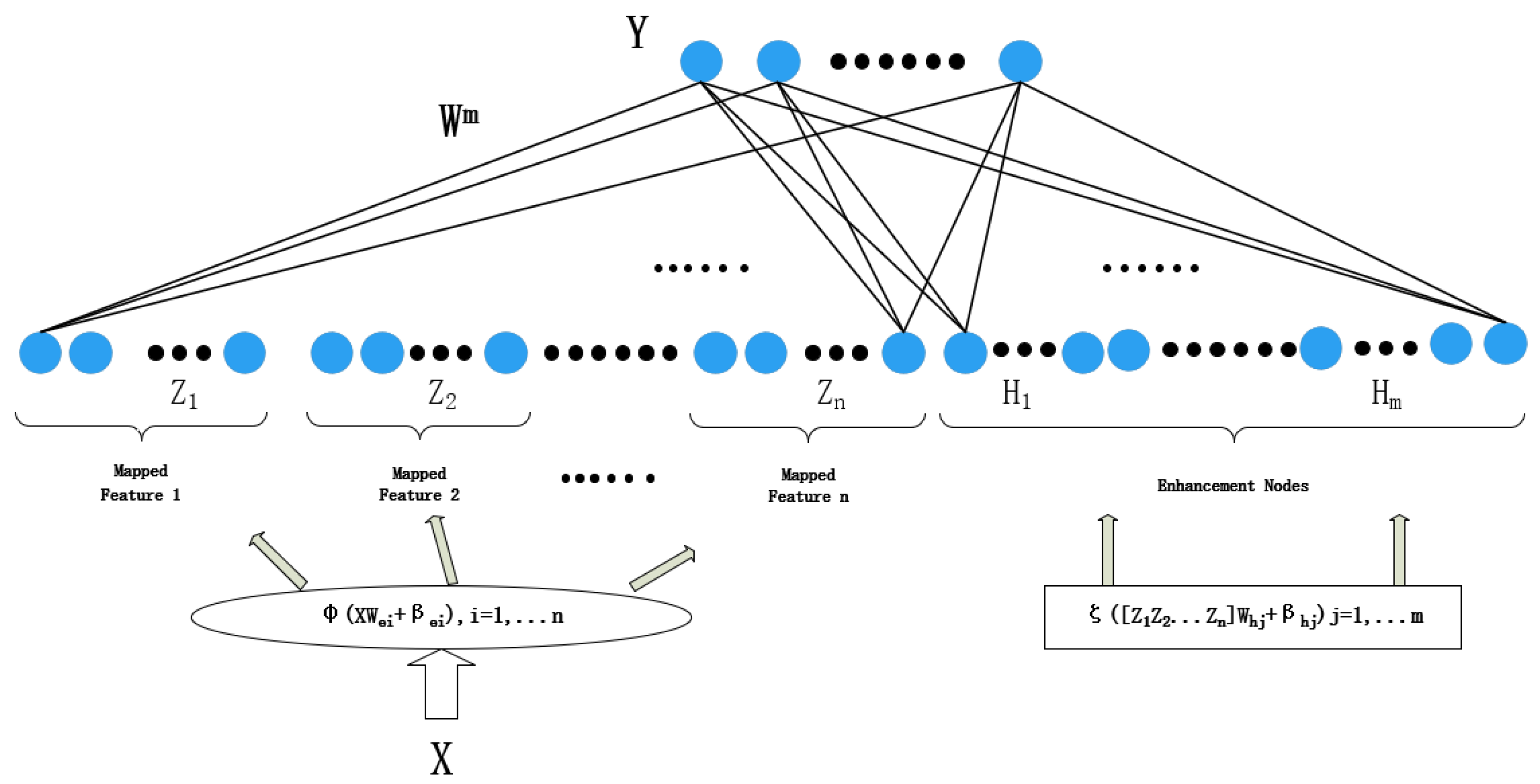
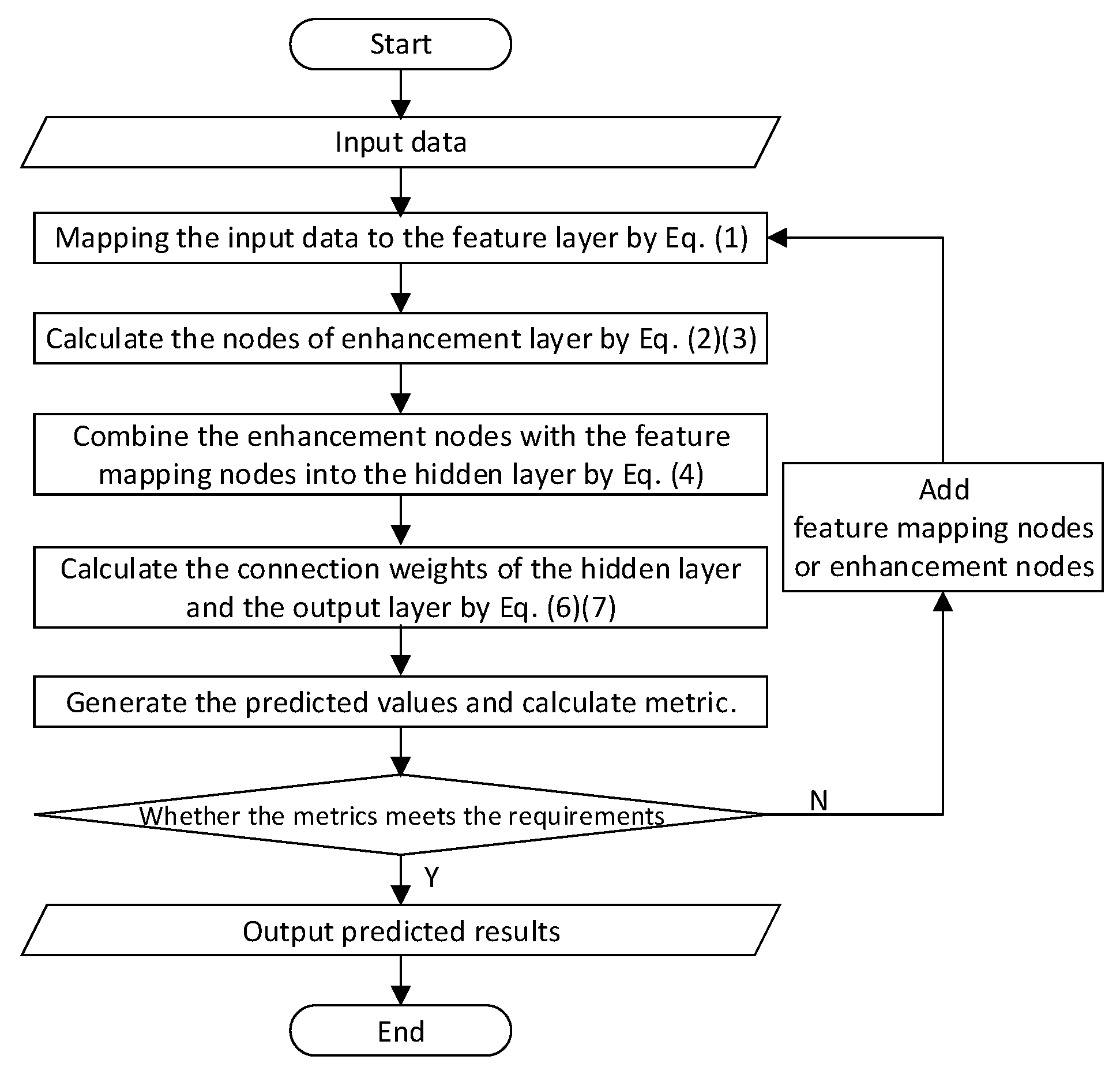
2.1. Broad Learning System (BLS)
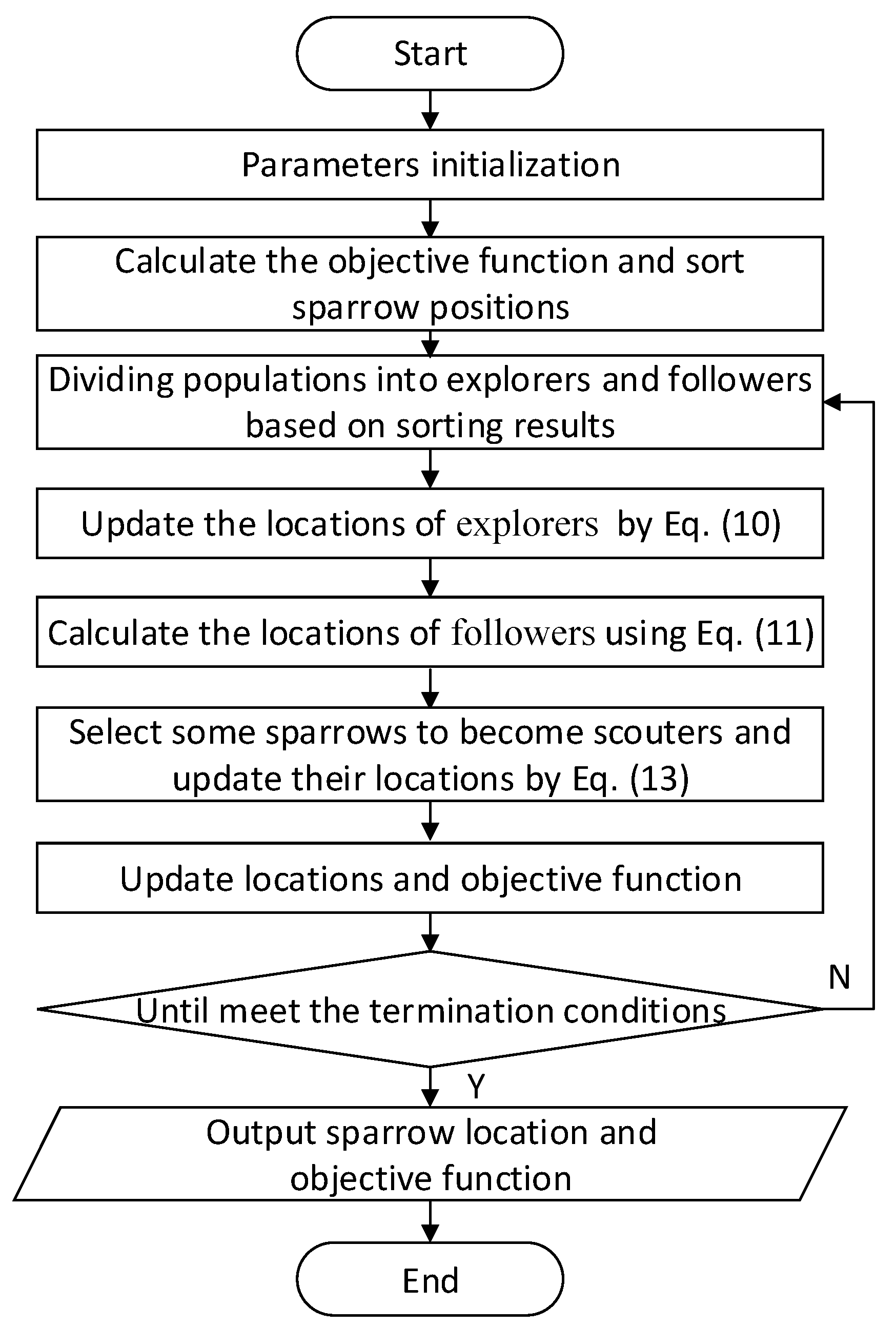
2.2. Sparrow Search Algorithm (SSA)
- (1)
- Similar to the slap swarm algorithm [36], sparrows in the population are divided into explorers and followers according to their fitness. The fitness is the objective function of optimization, which reflects the quality of the sparrow’s position.
- (2)
- Sparrows with good fitness are explorers, and others act as followers. The explorer is responsible for investigating food-rich locations and guiding the followers to foraging locations and directions. The followers were able to search for the explorer with the best feeding position and then foraged around it.
- (3)
- The fitness of a sparrow is dynamic, so the identity of explorers and followers can change with each other, but the proportion of explorers remains the same.
- (4)
- The bad fitness of the followers, the worse their foraging position is indicated. These followers may randomly fly to other places to forage.
- (5)
- A certain percentage of individuals in the sparrow population was selected as scouter, responsible for monitoring the safety of their surroundings. When a predator is detected, the scouter will sound an alarm, and when the alarm value is bigger than the safety value, the explorer will lead the followers to a safer area to forage.
- (6)
- When danger is recognized, sparrows located at the edge of the group will quickly move to a safe area to get a better position, while sparrows located in the center will move randomly.
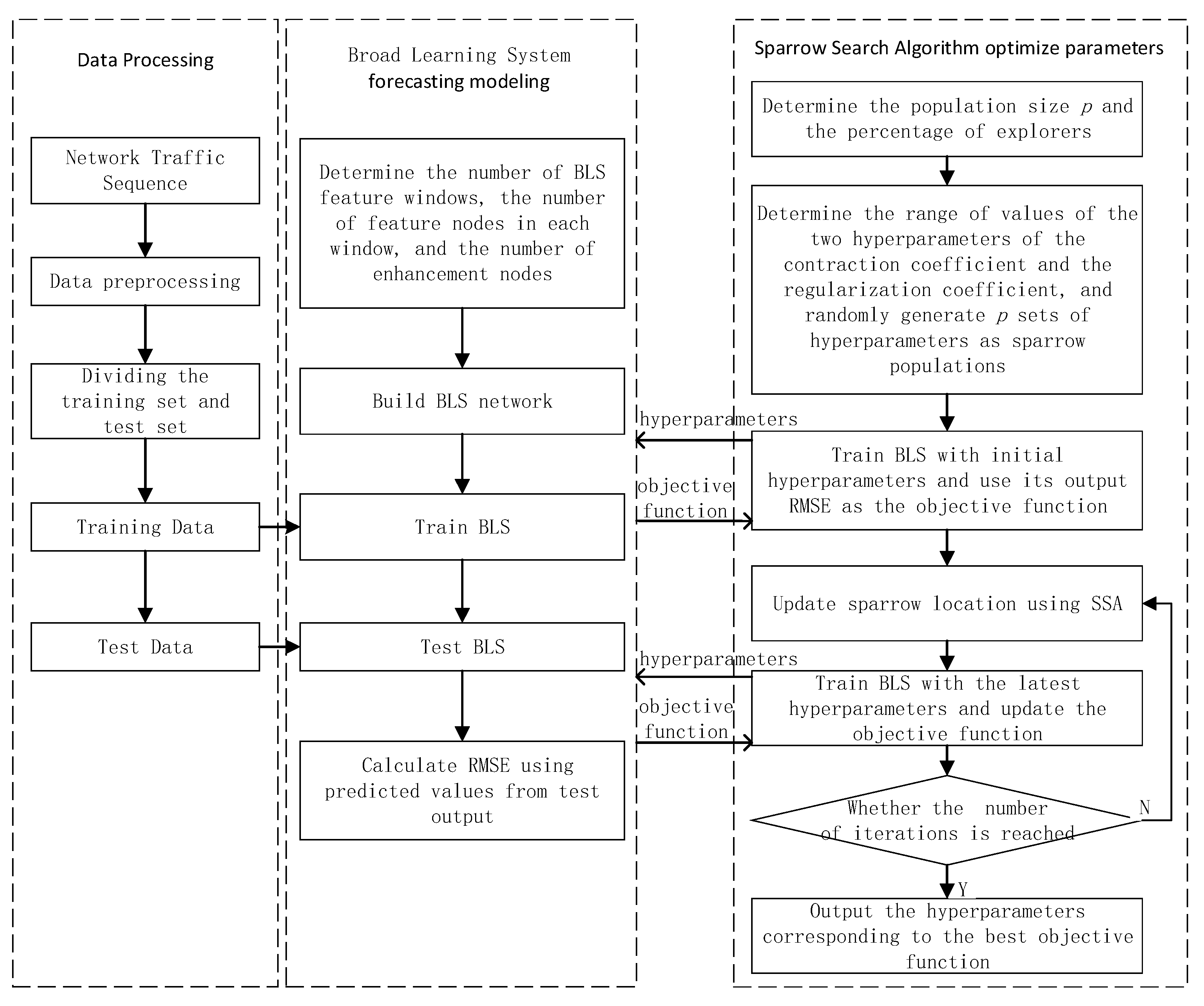
3. Broad Learning System Based on the Sparrow Search Algorithm (SSA-BLS)
4. Experimentation
4.1. Datasets
4.2. Parameters and Evaluation Indicators
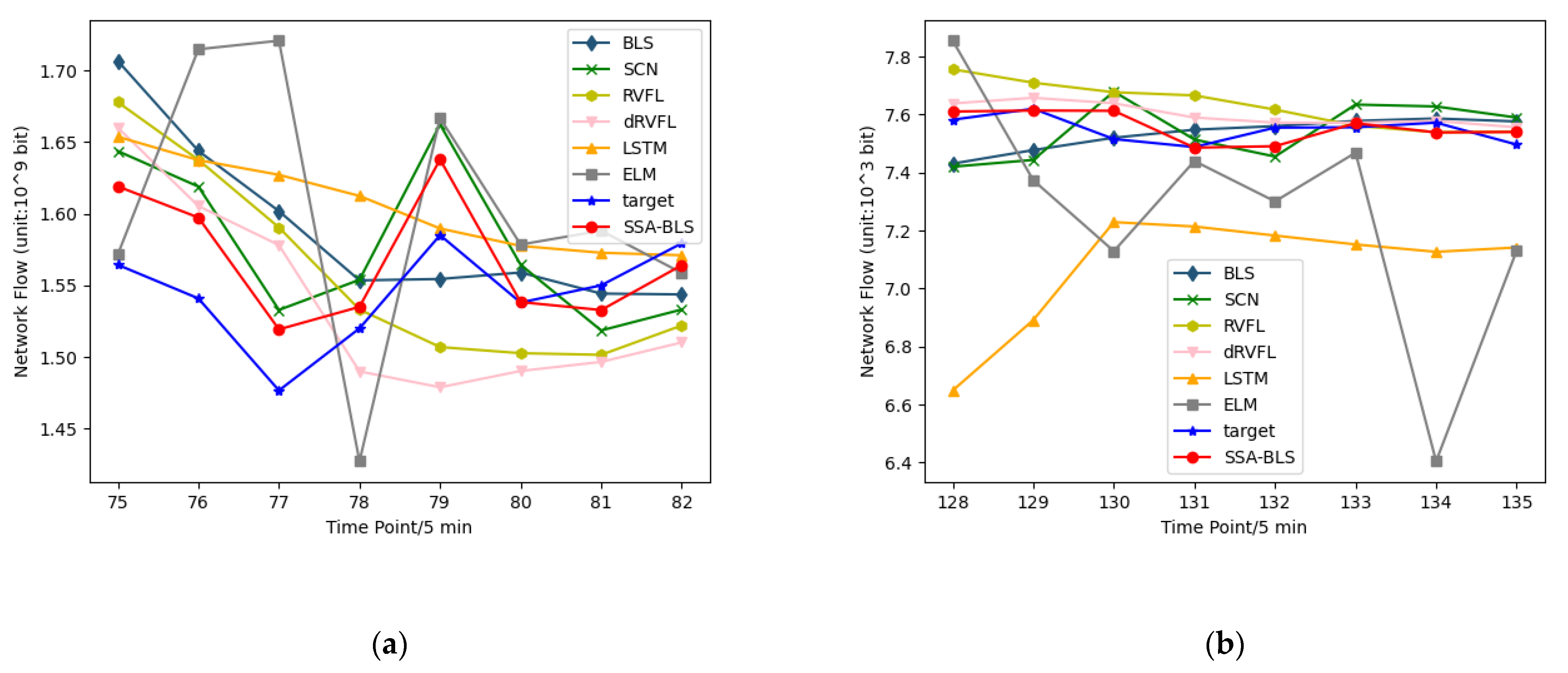
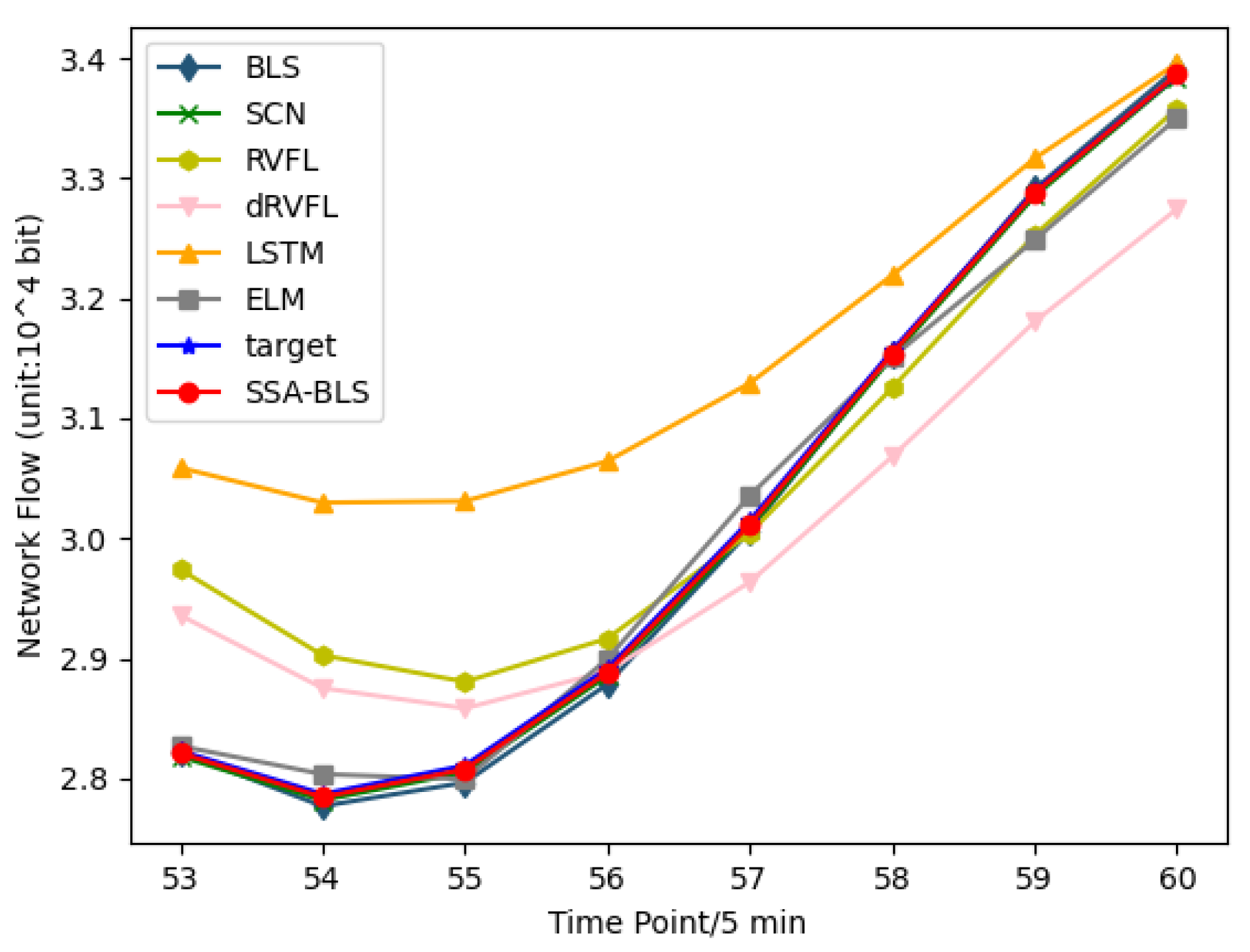
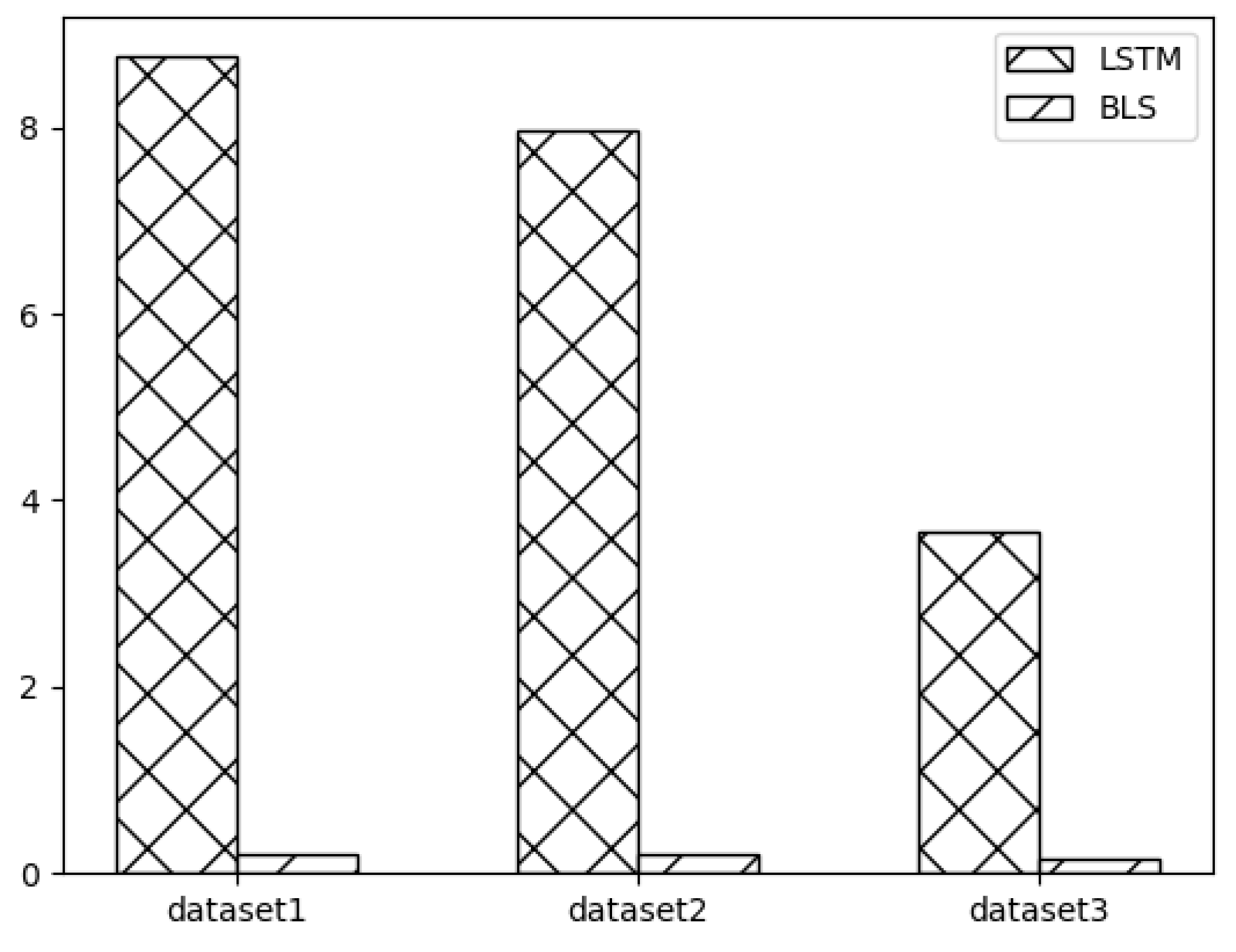
4.3. Results and Discussion
5. Conclusions, Limitations, and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Singh, S.; Chana, I. A Survey on Resource Scheduling in Cloud Computing: Issues and Challenges. J. Grid Comput. 2016, 14, 217–264. [Google Scholar] [CrossRef]
- Katris, C.; Daskalaki, S. Comparing Forecasting Approaches for Internet Traffic. Expert Syst. Appl. 2015, 42, 8172–8183. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, X.; Mao, S.; Rao, C.; Wen, J. Grey Coupled Prediction Model for Traffic Flow with Panel Data Characteristics. Entropy 2016, 18, 454. [Google Scholar] [CrossRef]
- Vo, N.; Ślepaczuk, R. Applying Hybrid ARIMA-SGARCH in Algorithmic Investment Strategies on S&P500 Index. Entropy 2022, 24, 158. [Google Scholar] [CrossRef]
- Zhong-Da, T.; Shu-Jiang, L.; Yan-Hong, W.; Xiang-Dong, W. Network Traffic Prediction Based on ARIMA with Gaussian Process Regression Compensation. J. Beijing Univ. Posts Telecommun. 2017, 40, 65. [Google Scholar]
- Kim, S. Forecasting Internet Traffic by Using Seasonal GARCH Models. J. Commun. Netw. 2011, 13, 621–624. [Google Scholar] [CrossRef]
- Kim, M. Network Traffic Prediction Based on INGARCH Model. Wirel. Netw. 2020, 26, 6189–6202. [Google Scholar] [CrossRef]
- Alekseeva, D.; Stepanov, N.; Veprev, A.; Sharapova, A.; Lohan, E.S.; Ometov, A. Comparison of Machine Learning Techniques Applied to Traffic Prediction of Real Wireless Network. IEEE Access 2021, 9, 159495–159514. [Google Scholar] [CrossRef]
- Wang, Q.; Fan, A.; Shi, H. Network Traffic Prediction Based on Improved Support Vector Machine. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 1976–1980. [Google Scholar] [CrossRef]
- Nabipour, M.; Nayyeri, P.; Jabani, H.; Mosavi, A.; Salwana, E.; Shahab, S. Deep Learning for Stock Market Prediction. Entropy 2020, 22, 840. [Google Scholar] [CrossRef]
- Liu, F.; Liu, B.; Sun, C.; Liu, M.; Wang, X. Deep Belief Network-Based Approaches for Link Prediction in Signed Social Networks. Entropy 2015, 17, 2140–2169. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Xia, J.; Li, F.; Li, Z.; Li, Q. A Peak Traffic Congestion Prediction Method Based on Bus Driving Time. Entropy 2019, 21, 709. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miguel, M.L.F.; Penna, M.C.; Nievola, J.C.; Pellenz, M.E. New Models for Long-Term Internet Traffic Forecasting Using Artificial Neural Networks and Flow Based Information. In Proceedings of the 2012 IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012; pp. 1082–1088. [Google Scholar] [CrossRef]
- Nie, L.; Jiang, D.; Yu, S.; Song, H. Network Traffic Prediction Based on Deep Belief Network in Wireless Mesh Backbone Networks. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–5. [Google Scholar]
- Fang, L.; Cheng, X.; Wang, H.; Yang, L. Mobile Demand Forecasting via Deep Graph-Sequence Spatiotemporal Modeling in Cellular Networks. IEEE Internet Things J. 2018, 5, 3091–3101. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, X.; Li, X.; You, X.; Zhu, Y. Network Traffic Prediction via Deep Graph-Sequence Spatiotemporal Modeling Based on Mobile Virtual Reality Technology. Wirel. Commun. Mob. Comput. 2021, 2021, 2353875. [Google Scholar] [CrossRef]
- Chen, C.P.; Liu, Z. Broad Learning System: An Effective and Efficient Incremental Learning System without the Need for Deep Architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef]
- Pao, Y.-H.; Takefuji, Y. Functional-Link Net Computing: Theory, System Architecture, and Functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Pao, Y.-H.; Park, G.-H.; Sobajic, D.J. Learning and Generalization Characteristics of the Random Vector Functional-Link Net. Neurocomputing 1994, 6, 163–180. [Google Scholar] [CrossRef]
- Igelnik, B.; Pao, Y.-H. Stochastic Choice of Basis Functions in Adaptive Function Approximation and the Functional-Link Net. IEEE Trans. Neural Netw. 1995, 6, 1320–1329. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.P.; Wan, J.Z. A Rapid Learning and Dynamic Stepwise Updating Algorithm for Flat Neural Networks and the Application to Time-Series Prediction. IEEE Trans. Syst. Man Cybern. Part B 1999, 29, 62–72. [Google Scholar] [CrossRef]
- Gong, X.; Zhang, T.; Chen, C.P.; Liu, Z. Research Review for Broad Learning System: Algorithms, Theory, and Applications. IEEE Trans. Cybern. 2021, 1–29. [Google Scholar] [CrossRef]
- Jin, J.-W.; Chen, C.P. Regularized Robust Broad Learning System for Uncertain Data Modeling. Neurocomputing 2018, 322, 58–69. [Google Scholar] [CrossRef]
- Chen, C.P. Broad Learning System and Its Structural Variations. In Proceedings of the 2018 IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018; pp. 000011–000012. [Google Scholar]
- Chen, C.P.; Liu, Z.; Feng, S. Universal Approximation Capability of Broad Learning System and Its Structural Variations. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1191–1204. [Google Scholar] [CrossRef] [PubMed]
- Gambardella, M.; Martinoli, M.B.A.; Stützle, R.P.T. Ant Colony Optimization and Swarm Intelligence. In 5th International Workshop; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Figueiredo, E.M.; Ludermir, T.B.; Bastos-Filho, C.J. Many Objective Particle Swarm Optimization. Inf. Sci. 2016, 374, 115–134. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, R.; Wang, Y.; Zhu, Z.; Zhang, J. Color Difference Classification Based on Optimization Support Vector Machine of Improved Grey Wolf Algorithm. Optik 2018, 170, 17–29. [Google Scholar] [CrossRef]
- Xu, X.; Liu, C.; Zhao, Y.; Lv, X. Short-Term Traffic Flow Prediction Based on Whale Optimization Algorithm Optimized BiLSTM_Attention. Concurr. Comput. Pract. Exp. 2022, e6782. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A Novel Swarm Intelligence Optimization Approach: Sparrow Search Algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, S. A Stochastic Configuration Network Based on Chaotic Sparrow Search Algorithm. Knowl.-Based Syst. 2021, 220, 106924. [Google Scholar] [CrossRef]
- Zhang, F.; Sun, W.; Wang, H.; Xu, T. Fault Diagnosis of a Wind Turbine Gearbox Based on Improved Variational Mode Algorithm and Information Entropy. Entropy 2021, 23, 794. [Google Scholar] [CrossRef]
- Tian, Z.; Chen, H. A Novel Decomposition-Ensemble Prediction Model for Ultra-Short-Term Wind Speed. Energy Convers. Manag. 2021, 248, 114775. [Google Scholar] [CrossRef]
- Gai, J.; Zhong, K.; Du, X.; Yan, K.; Shen, J. Detection of Gear Fault Severity Based on Parameter-Optimized Deep Belief Network Using Sparrow Search Algorithm. Measurement 2021, 185, 110079. [Google Scholar] [CrossRef]
- Song, C.; Yao, L.; Hua, C.; Ni, Q. A Water Quality Prediction Model Based on Variational Mode Decomposition and the Least Squares Support Vector Machine Optimized by the Sparrow Search Algorithm (VMD-SSA-LSSVM) of the Yangtze River, China. Environ. Monit. Assess 2021, 193, 363. [Google Scholar] [CrossRef] [PubMed]
- Devarapalli, R.; Sinha, N.K.; Rao, B.V.; Knypinski, L.; Lakshmi, N.J.N.; Márquez, F.P.G. Allocation of Real Power Generation Based on Computing over All Generation Cost: An Approach of Salp Swarm Algorithm. Arch. Electr. Eng. 2021, 70, 337–349. [Google Scholar]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Wang, D.; Li, M. Stochastic Configuration Networks: Fundamentals and Algorithms. IEEE Trans. Cybern. 2017, 47, 3466–3479. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Katuwal, R.; Suganthan, P.N.; Tanveer, M. Random Vector Functional Link Neural Network Based Ensemble Deep Learning. Pattern Recognit. 2021, 117, 107978. [Google Scholar] [CrossRef]
- Zhuo, Q.; Li, Q.; Yan, H.; Qi, Y. Long Short-Term Memory Neural Network for Network Traffic Prediction. In Proceedings of the 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–6. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MSE | RMSE | MAE | MAPE | MA | |
|---|---|---|---|---|---|
| SSA-BLS | 0.0159047 | 0.1261069 | 0.0937315 | 0.0294284 | 97.057155% |
| BLS | 0.0781227 | 0.2551322 | 0.1878021 | 0.0571019 | 94.289801% |
| SCN | 0.0154907 | 0.1244372 | 0.0934485 | 0.0295662 | 97.043378% |
| RVFL | 0.0254023 | 0.1593589 | 0.1208186 | 0.0388347 | 96.116525% |
| dRVFL | 0.0227553 | 0.1507691 | 0.1135728 | 0.0367191 | 96.328085% |
| ELM | 0.1394488 | 0.3686439 | 0.2710739 | 0.0780252 | 92.197470% |
| LSTM | 0.0781441 | 0.2502372 | 0.1884968 | 0.0517535 | 94.824642% |
| MSE | RMSE | MAE | MAPE | MA | |
|---|---|---|---|---|---|
| SSA-BLS | 0.0071345 | 0.0844570 | 0.0618339 | 0.0136258 | 98.637411% |
| BLS | 0.0913392 | 0.2639297 | 0.1873060 | 0.0440354 | 95.596458% |
| SCN | 0.0097822 | 0.0982373 | 0.0668127 | 0.0143890 | 98.561099% |
| RVFL | 0.0289572 | 0.1701013 | 0.1179645 | 0.0264767 | 97.352324% |
| dRVFL | 0.0234114 | 0.1527494 | 0.1058797 | 0.0232484 | 97.675151% |
| ELM | 0.1051171 | 0.3157292 | 0.2166875 | 0.0426738 | 95.732612% |
| LSTM | 0.3192739 | 0.3290859 | 0.2518907 | 0.0595686 | 94.043138% |
| MSE | RMSE | MAE | MAPE | MA | |
|---|---|---|---|---|---|
| SSA-BLS | 0.0000734 | 0.0082991 | 0.0063628 | 0.0021407 | 99.785924% |
| BLS | 0.0103714 | 0.0811761 | 0.0563080 | 0.0176119 | 98.238804% |
| SCN | 0.0001742 | 0.0130396 | 0.0067544 | 0.0021857 | 99.781427% |
| RVFL | 0.0361230 | 0.1899801 | 0.1288009 | 0.0400804 | 95.991952% |
| dRVFL | 0.0327578 | 0.1807739 | 0.1277397 | 0.0403579 | 95.964208% |
| ELM | 0.0579519 | 0.2382928 | 0.1327614 | 0.0400340 | 95.996599% |
| LSTM | 0.0283041 | 0.1057008 | 0.0759722 | 0.0238097 | 97.619024% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Li, S.; Zhou, P.; Chen, G. Forecasting Network Interface Flow Using a Broad Learning System Based on the Sparrow Search Algorithm. Entropy 2022, 24, 478. https://doi.org/10.3390/e24040478
Li X, Li S, Zhou P, Chen G. Forecasting Network Interface Flow Using a Broad Learning System Based on the Sparrow Search Algorithm. Entropy. 2022; 24(4):478. https://doi.org/10.3390/e24040478
Chicago/Turabian StyleLi, Xiaoyu, Shaobo Li, Peng Zhou, and Guanglin Chen. 2022. "Forecasting Network Interface Flow Using a Broad Learning System Based on the Sparrow Search Algorithm" Entropy 24, no. 4: 478. https://doi.org/10.3390/e24040478