One of the most fundamental tasks in modern data science and machine learning is to learn and model complex distributions (or structures) of real-world data, such as images or texts, from a set of observed samples. By “to learn and model”, one typically means that we want to establish a (parametric) mapping between the distribution of the real data, say
, and a more compact random variable, say
:
where
has a certain standard structure or distribution (e.g., normal distributions). The so-learned representation or feature
would be much easier to use for either generative (e.g., decoding or replaying) or discriminative (e.g., classification) purposes, or both.
Data embedding versus data transcription.Be aware that the support of the distribution of
(and that of
) is typically
extremely low-dimensional compared to that of the ambient space (for instance, the well-known CIFAR-10 datasets consist of RGB images with a resolution of
. Despite the images being in a space of
, our experiments will show that the intrinsic dimension of each class is less than a dozen, even after they are mapped into a feature space of
) hence the above mapping(s) may not be uniquely defined based on the support in the space
(or
. In addition, the data
may contain multiple components (e.g., modes, classes), and the intrinsic dimensions of these components are not necessarily the same. Hence, without loss of generality, we may assume the data
to be distributed over a union of low-dimensional nonlinear submanifolds
, where each submanifold
is of dimension
. Regardless, we hope the learned mappings
f and
g are (locally dimension-preserving)
embedding maps [
1], when restricted to each of the components
. In general, the dimension of the feature space
d needs to be significantly higher than all of these intrinsic dimensions of the data:
. In fact, it should preferably be higher than the sum of all the intrinsic dimensions:
, since we normally expect that the features of different components/classes can be made fully independent or orthogonal in
. Hence, without any explicit control of the mapping process, the actual features associated with images of the data under the embedding could still lie on some arbitrary nonlinear low-dimensional submanifolds inside the feature space
. The distribution of the learned features remains “latent” or “hidden” in the feature space.
So, for features of the learned mappings (
1) to be truly convenient to use for purposes such as data classification and generation, the goals of learning such mappings should not only simply reduce the dimension of the data
from
D to
d but also determine explicitly and precisely how the mapped feature
is distributed within the feature space
, in terms of both its support and density. Moreover, we want to establish an explicit map
from this distribution of feature
back to the data space such that the distribution of its image
(closely) matches that of
. To differentiate from finding arbitrary feature embeddings (as most existing methods do), we call embeddings of data onto an explicit family of models (structures or distributions) in the feature space as
data transcription.
Paper Outline. This work is to show how such transcription can be achieved for real-world visual data with one important family of models: the linear discriminative representation (LDR) introduced by [
2]. Before we formally introduce our approach in
Section 2, for the remainder of this section, we first discuss two existing approaches, namely autoencoding and GAN, that are closely related to ours. As these approaches are rather popular and known to the readers, we will mainly point out some of their main conceptual and practical limitations that have motivated this work. Although our objective and framework will be mathematically formulated, the main purpose of this work is to verify the effectiveness of this new approach empirically through extensive experimentation, organized and presented in
Section 3 and
Appendix A. Our work presents compelling evidence that the closed-loop data transcription problem and our rate-reduction-based formulation deserve serious attention from the information-theoretical and mathematical communities. This has raised many exciting and open theoretical problems or hypotheses about learning, representing, and generating distributions or manifolds of high-dimensional real-world data. We discuss some open problems in
Section 4 and new directions in
Section 5. Source code can be found at
https://github.com/Delay-Xili/LDR (accessed on 9 February 2022).
1.1. Learning Generative Models via Auto-Encoding or GAN
Auto-Encoding and its variants. In the machine-learning literature, roughly speaking, there have been two representative approaches to such a distribution-learning task. One is the classic “Auto Encoding” (AE) approach [
3,
4] that aims to simultaneously learn an encoding mapping
f from
to
and an (inverse) decoding mapping
g from
back to
:
Here, we use bold capital letters to indicate a matrix of finite samples
of
and their mapped features
, respectively. Typically, one wishes for two properties: firstly, the decoded samples
are “similar” or close to the original
, say in terms of maximum likelihood
; and secondly, the (empirical) distribution of the mapped samples
, denoted as
, is close to certain desired prior distribution
, say some much lower-dimensional multivariate Gaussian (The classical PCA can be viewed as a special case of this task. In fact, the original auto-encoding is precisely cast as
nonlinear PCA [
3], assuming the data lie on only one nonlinear submanifold
).
However it is typically very difficult, often computationally intractable to maximize the likelihood function
or to minimize certain “distance”, say the
KL-divergence, between
and
. Except for simple distributions such as Gaussian, the KL divergence usually does not have a closed-form, even for a mixture of Gaussians. The likelihood and the KL-divergence become ill-conditioned when the supports of the distributions are low-dimensional (i.e., degenerate) and not overlapping (which is almost always the case in practice when dealing with distributions of high-dimensional data in high-dimensional spaces). So in practice, one typically chooses to minimize instead certain approximate bounds or surrogates derived with various simplifying assumptions on the distributions involved, as is the case in variational auto-encoding (VAE) [
5,
6]. As a result, even after learning, the precise posterior distribution of
remains unclear or hidden inside the feature space.
In this work, we will show that if we impose specific requirements on the (distribution of) learned feature to be a mixture of subspace-like Gaussians, a natural closed-form distance can be introduced for such distributions based on rate distortion from the information theory. In addition, the optimal solution to the feature representation within this family can be learned directly from the data without specifying any target in advance, which is particularly difficult in practice when the distribution of a mixed dataset is multi-modal and each component may have a different dimension.
GAN and its variants. Compared to measuring distribution distance in the (often controlled) feature space
, a much more challenging issue with the above auto-encoding approach is how to effectively measure the distance between the decoded samples
and the original
in the data space
. For instance, for visual data such as images, their distributions
or generative models
are often not known. Despite extensive studies in the computer vision and image processing literature [
7], it remains elusive to find a good measure for similarity of real images that is both efficient to compute and effective in capturing visual quality and semantic information of the images equally well. Precisely due to such difficulties, it has been suggested early on by [
8] that one may have to take a discriminative approach to learn the distribution or a generative model for visual data. More recently,
Generative Adversarial Nets (GAN) [
9] offers an ingenious idea to alleviate this difficulty by utilizing a powerful discriminator
d, usually modeled and learned by a deep network, to discern differences between the generated samples
and the real ones
:
To a large extent, such a discriminator plays the role of minimizing certain distributional distance, e.g., the
Jensen–Shannon divergence, between the data
and
. Compared to the KL-divergence, the JS-divergence is well-defined even if the supports of the two distributions are non-overlapping. (However, JS-divergence does not have a closed-form expression even between two Gaussians, whereas KL-divergence does). However, as shown in [
10], since the data distributions are low-dimensional, the JS-divergence can be highly ill-conditioned to optimize. (This may explain why many additional heuristics are typically used in many subsequent variants of GAN). So, instead, one may choose to replace JS-divergence with the earth mover’s distance or the Wasserstein distance. However both JS-divergence and W-distance can only be approximately computed between two general distributions. (For instance, the W-distance requires one to compute the maximal difference between expectations of the two distributions over all 1-Lipschitz functions). Furthermore, neither the JS-divergence nor the W-distance have closed-form formulae, even for the Gaussian distributions. (The (
-norm) W-distance can be bounded by the (
-norm) W2-distance which has a closed-form [
11]. However, as is well-known in high-dimensional geometry,
-norm and
norm deviate significantly in terms of their geometric and statistical properties as the dimension becomes high [
12]. The bound can become very loose). However, from a data representation perspective,
subspace-like Gaussians (e.g., PCA) or a mixture of them are the most desirable family of distributions that we wish our features to become. This would make all subsequent tasks (generative or discriminative) much easier. In this work, we will show how to achieve this with a different fundamental metric, known as the rate reduction, introduced by [
13].
The original GAN aims to directly learn a mapping
, called a generator, from a standard distribution (say, a low-dimensional Gaussian random field) to the real (visual) data distribution in a high-dimensional space. However, distributions of real-world data can be rather sophisticated and often contain
multiple classes and
multiple factors in each class [
14]. This makes learning the mapping
g rather challenging in practice, suffering difficulties such as
mode-collapse [
15]. As a result, many variants of GAN have been subsequently developed in order to improve the stability and performance in learning multiple modes and disentangling different factors in the data distribution, such as
Conditional GAN [
16,
17,
18,
19,
20],
InfoGAN [
21,
22], or
Implicit Maximum Likelihood Estimation (IMLE) [
23,
24]. In particular, to learn a generator for multi-class data, prevalent conditional GAN literature requires label information as conditional inputs [
16,
25,
26,
27]. Recently, [
28,
29] has proposed training a
k-class GAN by generalizing the two-class cross entropy to a
-class cross entropy. In this work,
we will introduce a more refined -class measure for the
k real and
k generated classes. In addition, to avoid features for each class collapsing to a singleton [
30], instead of cross entropy,
we will use the so-called rate-reduction measure that promotes multi-mode and multi-dimension in the learned features [
13]. One may view the rate reduction as a metric distance that has closed-form formulae for a mixture of (subspace-like) Gaussians, whereas neither JS-divergence nor W-distance can be computed in closed form (even between two Gaussians).
Another line of research is about how to stabilize the training of GAN. SN-GAN [
31] has shown that spectral normalization on the discriminator is rather effective, which we will adopt in our work, although our formulation is not so sensitive to such choice designed for GAN (see ablation study in
Appendix A.9). PacGAN [
32] shows that the training stability can be significantly improved by packing a pair of real and generated images together for the discriminator. Inspired by this work,
we show how to generalize such an idea to discriminating an arbitrary number of pairs of real and decoded samples without concatenating the samples. Our results in this work will even suggest that the larger the batch size discriminated, the merrier (see ablation study in
Appendix A.10). In addition, ref. [
29] has shown that optimizing the latent features leads to state-of-the-art visual quality. Their method is based on the deep compressed sensing GAN [
28]. Hence, there are strong reasons to believe that their method essentially utilizes the
compressed sensing principle [
12] to implicitly exploit the low-dimensionality of the feature distribution. Our framework
will explicitly expose and exploit such low-dimensional structures on the learned feature distribution.Combination of AE and GAN. Although AE (VAE) and GAN originated with somewhat different motivations, they have evolved into popular and effective frameworks for learning and modeling complex distributions of many real-world data such as images. (In fact, in some idealistic settings, it can be shown that AE and GAN are actually equivalent: for instance, in the LOG settings, authors in [
33] have shown that GAN coincides with the classic PCA, which is precisely the solution to auto-encoding in the linear case). Many recent efforts tend to combine both auto-encoding and GAN to generate more powerful generative frameworks for more diverse data sets, such as [
15,
34,
35,
36,
37,
38,
39,
40,
41,
42]. As we will see, in our framework, AE and GAN can be naturally interpreted as two different segments of a closed-loop data transcription process. However, unlike GAN or AE (VAE), the “origin” or “target” distribution of the feature
will no longer be specified
a priori, and is instead learned from the data
. In addition,
this intrinsically low-dimensional distribution of (with all of its low-dimensional supports) is explicitly modeled as a mixture of orthogonal subspaces (or independent Gaussians) within the feature space , sometimes known as the principal subspaces.
Universality of Representations. Note that GANs (and most VAEs) are typically designed without explicit modeling assumptions on the distribution of the data nor on the features. Many even believe that it is this “universal” distribution learning capability (assuming minimizing distances between arbitrary distributions in high-dimensional space can be solved efficiently, which unfortunately has many caveats and often is impractical) that is attributed to their empirical success in learning distributions of complicated data such as images. In this work, we will provide empirical evidence that such an “arbitrary distribution learning machine” might not be necessary. (In fact, it may be computationally intractable in general). A
controlled and deformed family of low-dimensional linear subspaces (Gaussians) can be more than powerful, and expressive enough to model real-world visual data. (In fact, a Gaussian mixture model is already a universal approximator of almost arbitrary densities [
43]. Hence, we do not loose any generality at all). As we will also see, once we can place a proper and precise metric on such models, the associated learning problems can become much better conditioned and more amenable to rigorous analysis and performance guarantees in the future.
1.2. Learning Linear Discriminative Representation via Rate Reduction
Recently, the authors in [
2] proposed a new objective for deep learning that aims to learn a
linear discriminative representation (LDR) for multi-class data. The basic idea is to map distributions of real data, potentially on
multiple nonlinear submanifolds
(in classical statistical settings, such nonlinear structures of the data were also referred to as principal curves or surfaces [
44,
45]. There has been a long quest of trying to extend PCA to handle potential nonlinear low-dimensional structures in data distribution (see [
46] for a thorough survey) to a family of canonical models consisting of multiple independent (or orthogonal) linear subspaces, denoted as
. To some extent, this generalizes the classic nonlinear PCA [
3] to more general/realistic settings where we simultaneously apply
multiple nonlinear PCAs to data on multiple nonlinear submanifolds. Or equivalently, the problem can also be viewed as a nonlinear extension to the classic
Generalized PCA (GPCA) [
46]. (Conventionally, “generalized PCA” refers to generalizing the setting of PCA to multiple
linear subspaces. Here, we need to further generalize multiple
nonlinear submanifolds. Unlike conventional discriminative methods that only aim to predict class labels as one-hot vectors, the LDR aims to learn the likely multi-dimensional distribution of the data, hence it is suitable for both discriminative and generative purposes. It has been shown that this can be achieved via maximizing the so-called “rate reduction” objective based on the rate distortion of subspace-like Gaussians [
47].
LDR via MCR. More precisely, consider a set of data samples
from
k different classes. That is, we have
with each subset of samples
belonging to one of the low-dimensional submanifolds:
. Following the notation in [
2], we use a matrix
to denote the membership of sample
i belonging to class
j (and
otherwise). One seeks a continuous mapping
from
to an optimal representation
:
which maximizes the following coding rate-reduction objective, known as
the MCR principle [
13]:
where
,
,
for
. In this paper, for simplicity we denote
as
assuming
are known and fixed. The first term
, or
for short, is the coding rate of the whole feature set
(coded as a Gaussian source) with a prescribed precision
; the second term
, or simply
, is the average coding rate of the
k subsets of features
(each coded as a Gaussian).
As has been shown by [
13], maximizing the difference between the two terms will expand the whole feature set while compressing and linearizing features of each of the
k classes. If the mapping
f maximizes the rate reduction, it maps the features of different classes into independent (orthogonal) subspaces in
.
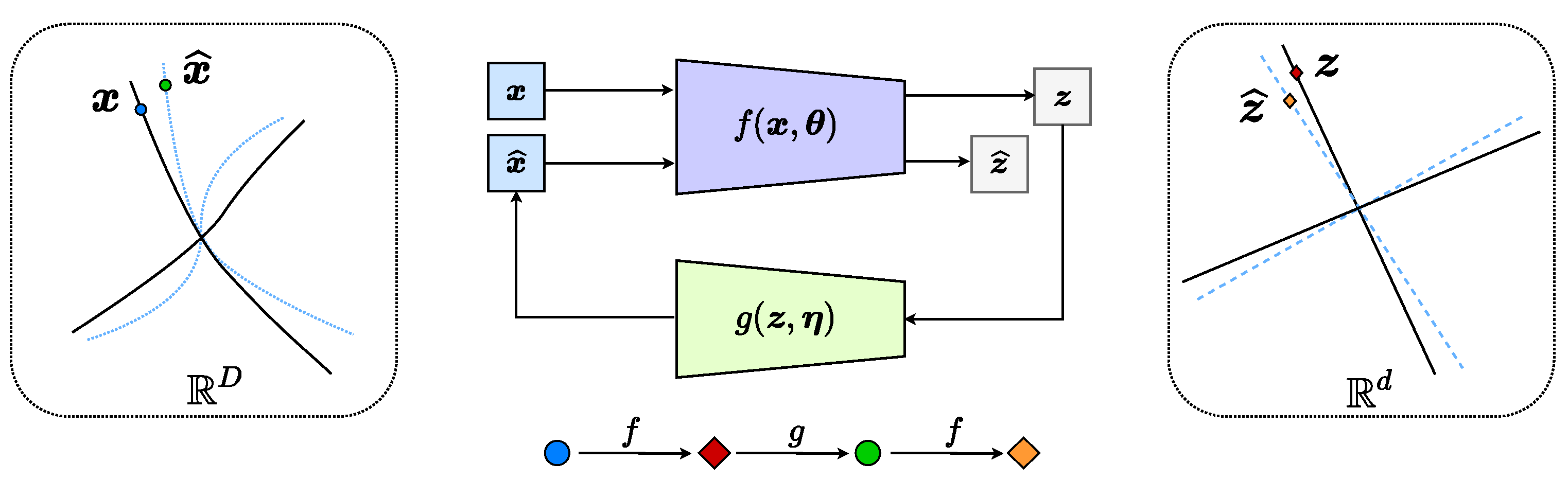
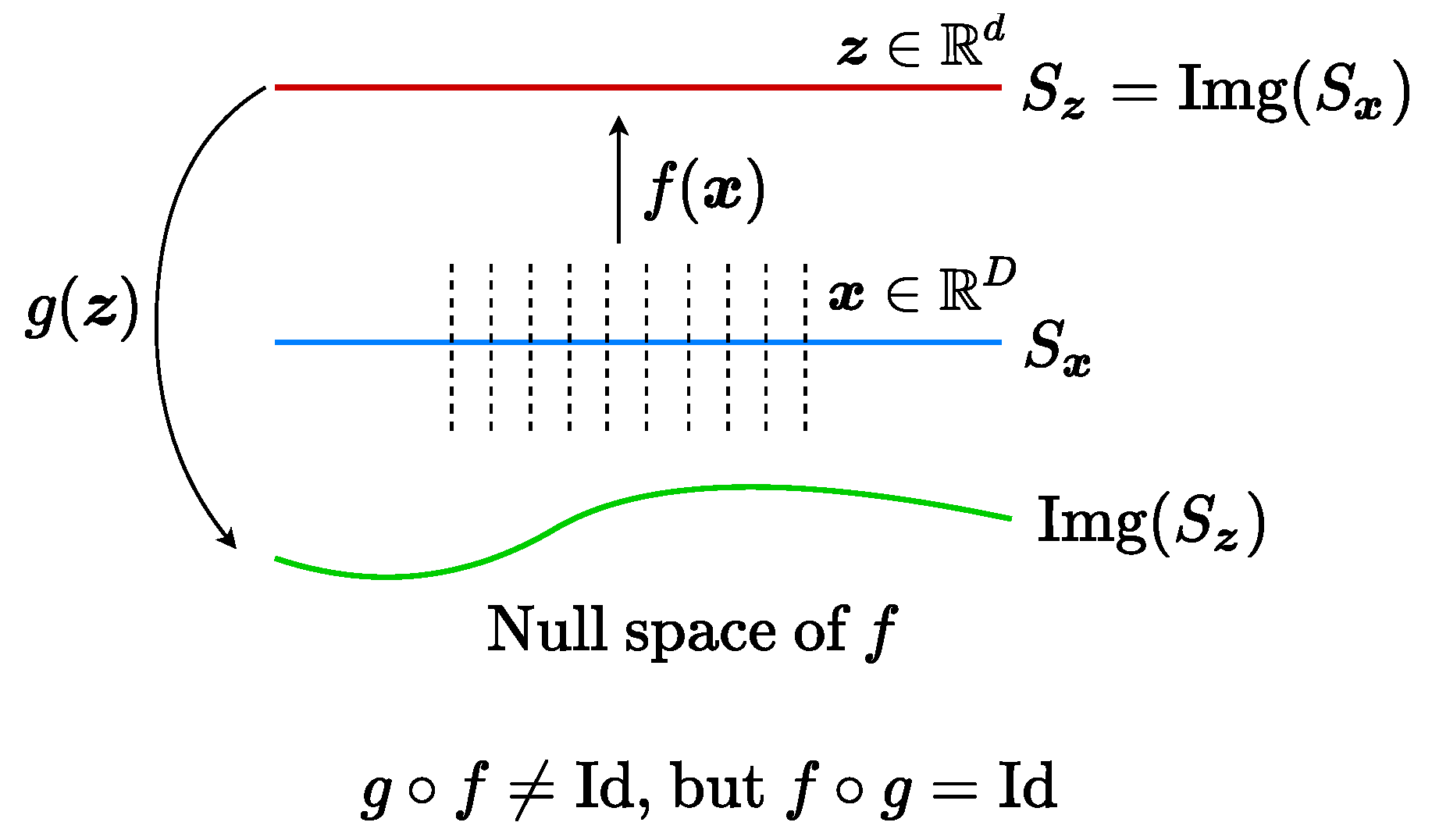
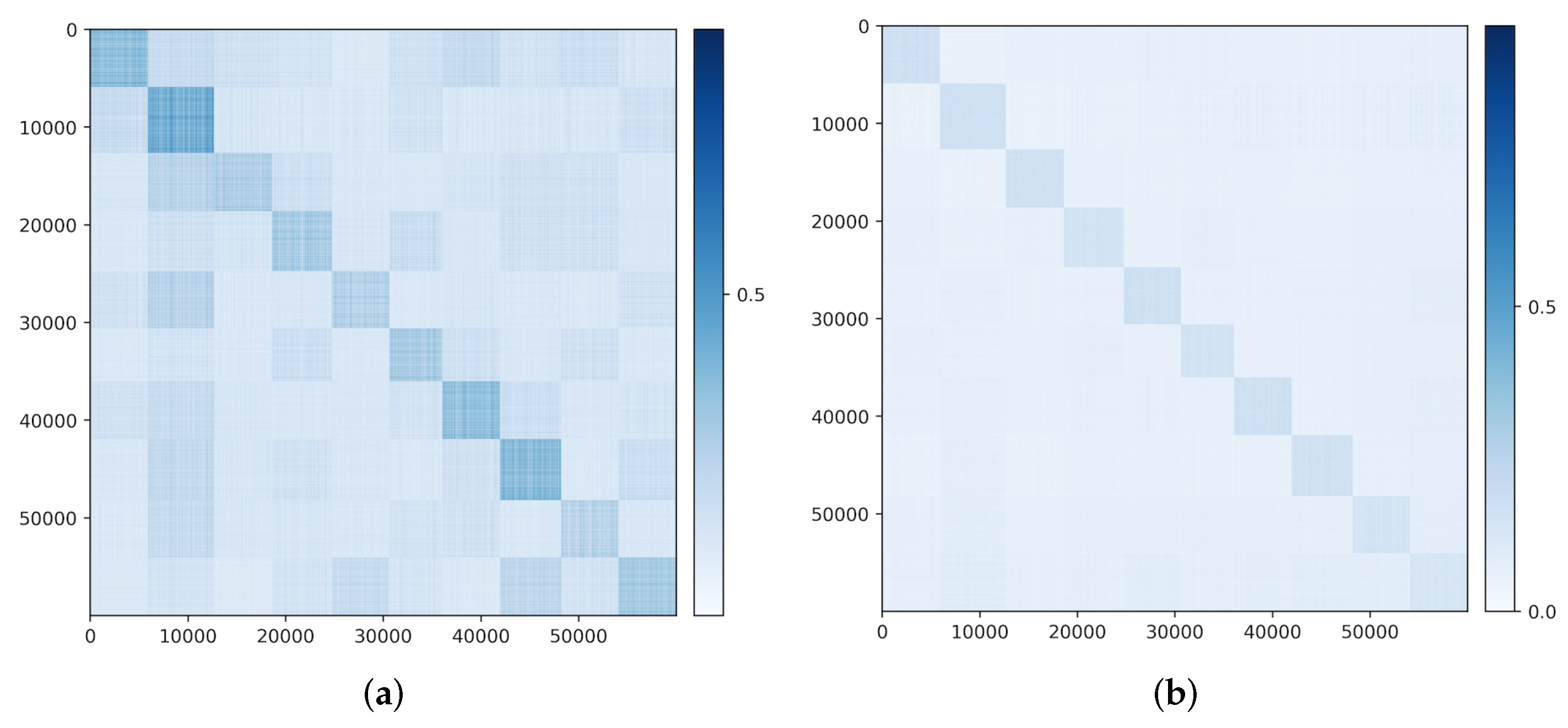
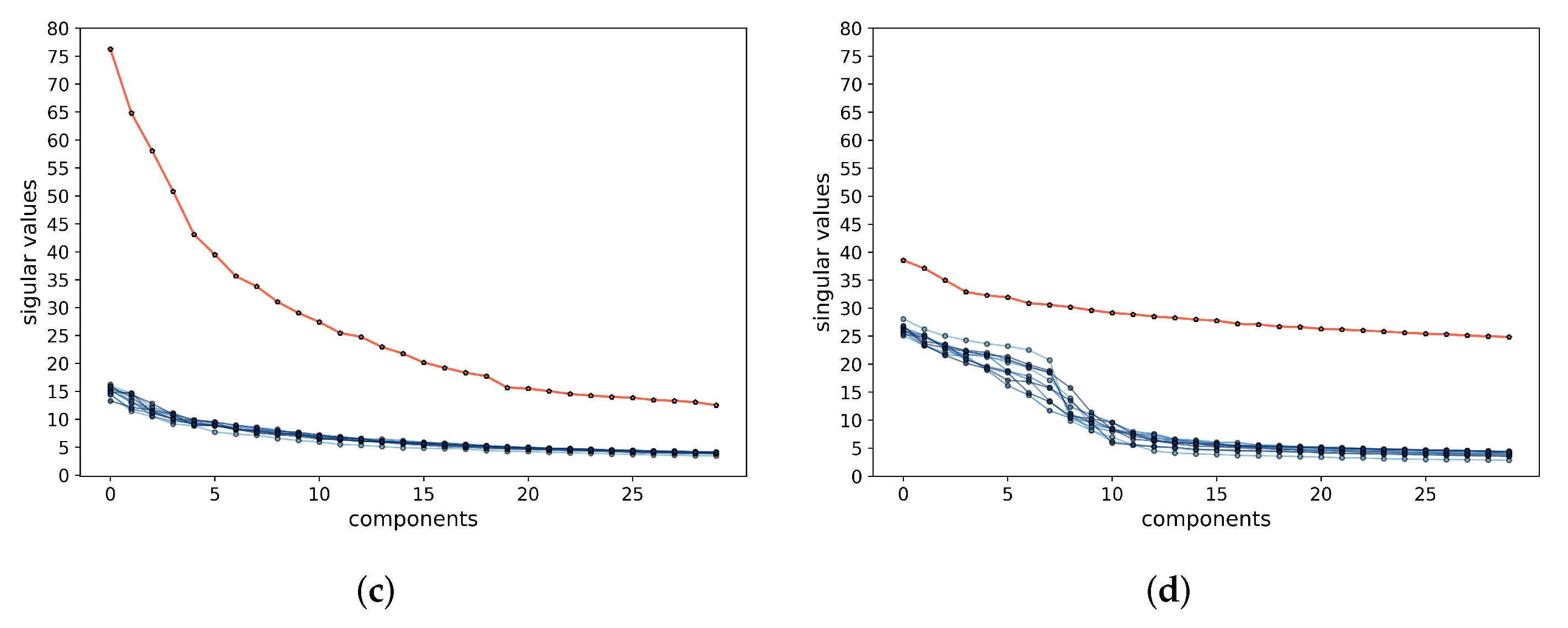
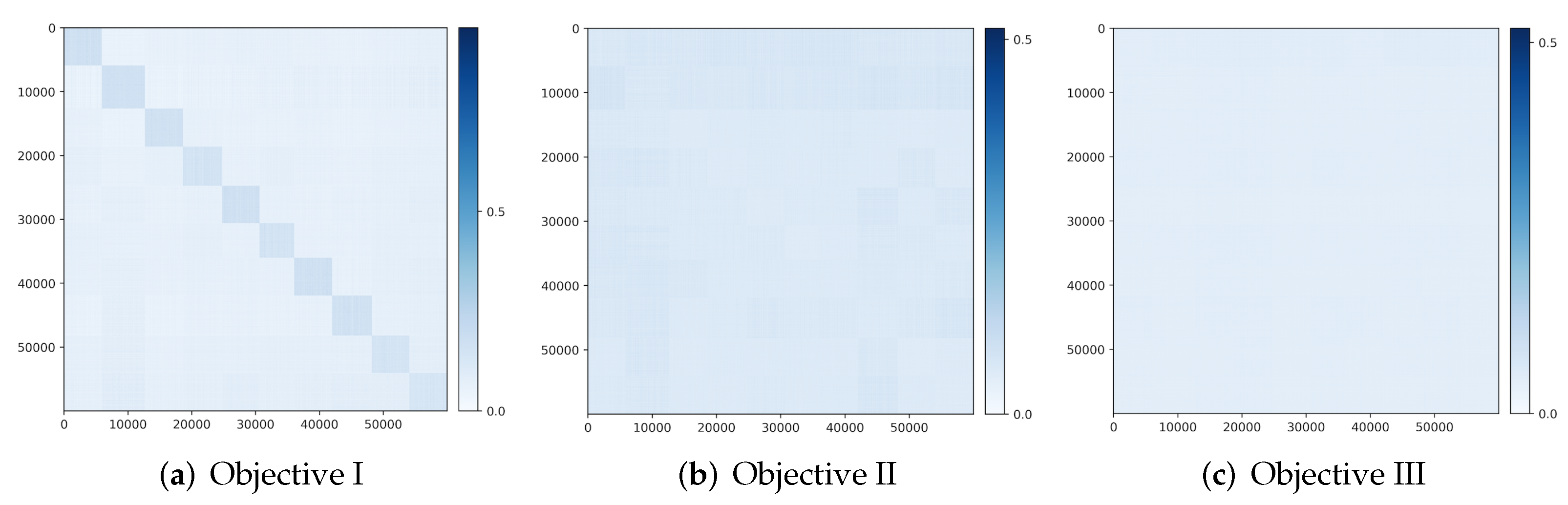
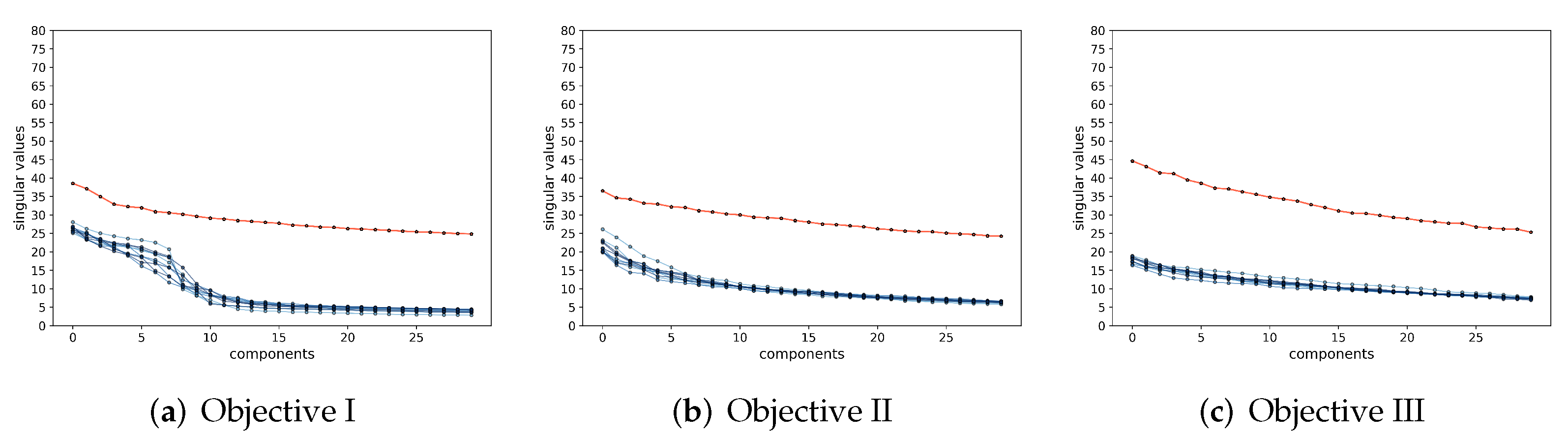
Figure 1 illustrates a simple example of data with
classes (on two submanifolds) mapped to two incoherent subspaces (solid black lines). Notice that, compared to AE (
2) and GAN (
3), the above mapping (
4) is only one-sided: from the data
to the feature
. In this work, we will see how to use the rate-reduction metric to establish inverse mapping from the feature
back to the data
, while still preserving the subspace structures in the feature space.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





























