
A Multi-Classification Hybrid Quantum Neural Network Using an All-Qubit Multi-Observable Measurement Strategy


Abstract
:1. Introduction
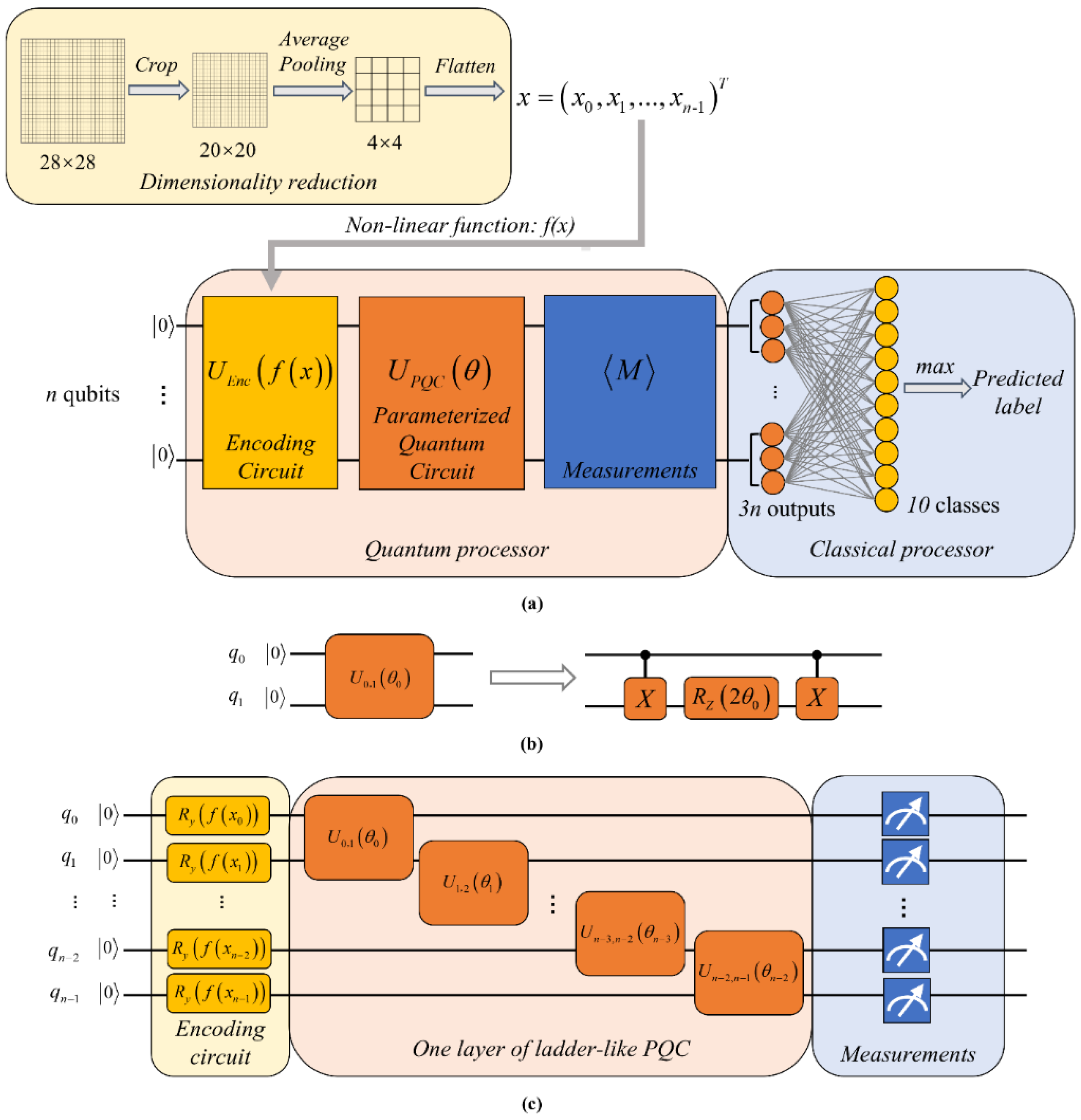
2. Hybrid Quantum Neural Network
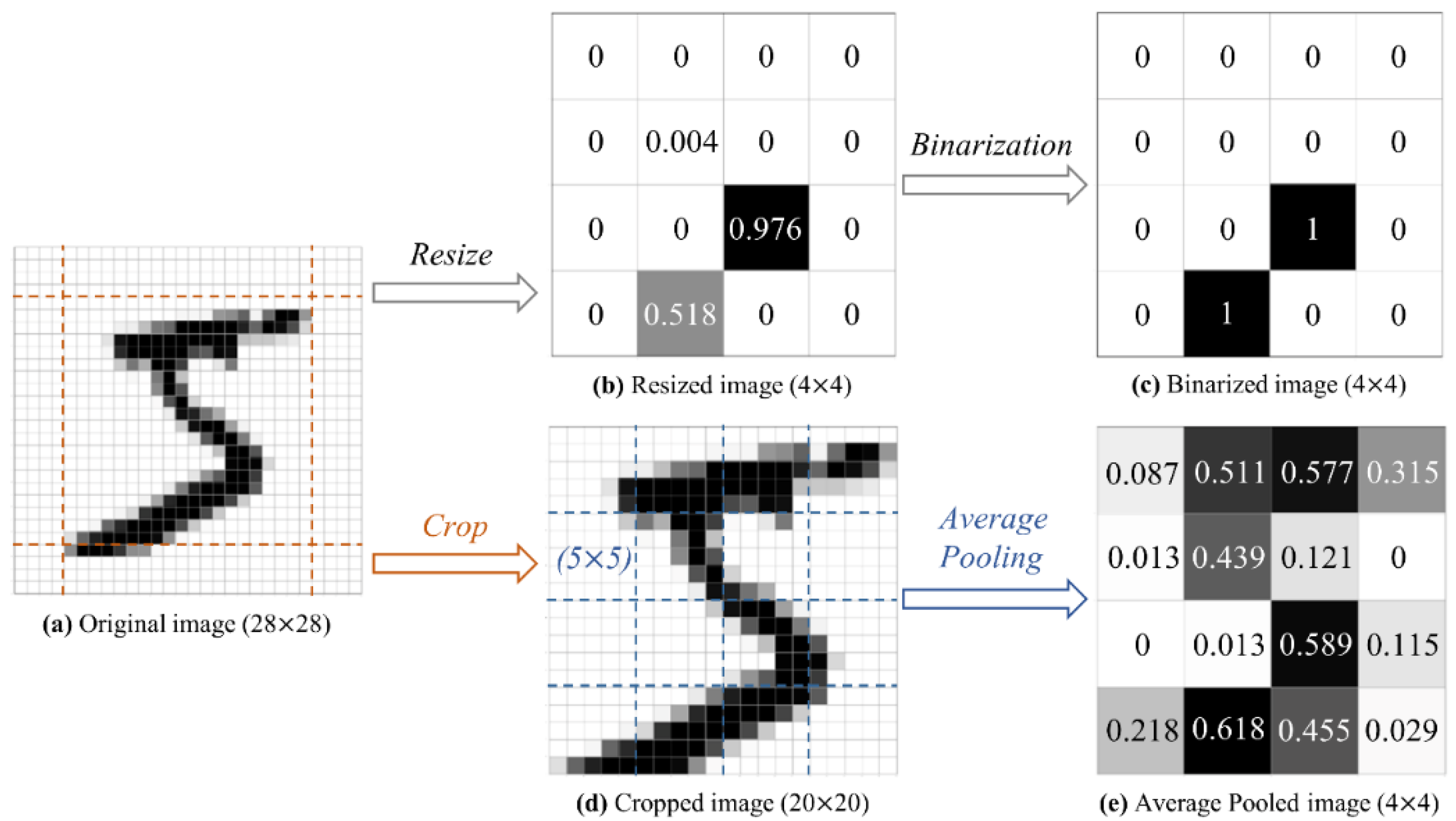
- The average pooling downsampling strategy is adopted to reduce the dimension of real-world data; thus, a vector composed of n-many elements is obtained.
- The data vector is encoded in a quantum state by applying an encoding circuit on an initial state , where is a nonlinear function that maps the data to angle space, and is a rotation operation which guarantees that the amplitude of a single qubit is real.This nonlinear quantum encoding circuit can map the input data into a higher-dimensional space, which will facilitate the subsequent classification process.
- The parameterized quantum circuit performs a series of linear transformations on the input state.
- The final state is measured by calculating the expectation values of a set of observables on all qubits.
- The measurement outcomes are fed into a fully connected layer with the softmax activation function to generate the predicted label.
- The loss function between the predicted label and the true label is computed, and a classical optimizer is employed to update parameters.
2.1. Average Pooling Downsampling
2.2. Ladder-like Parameterized Quantum Circuit
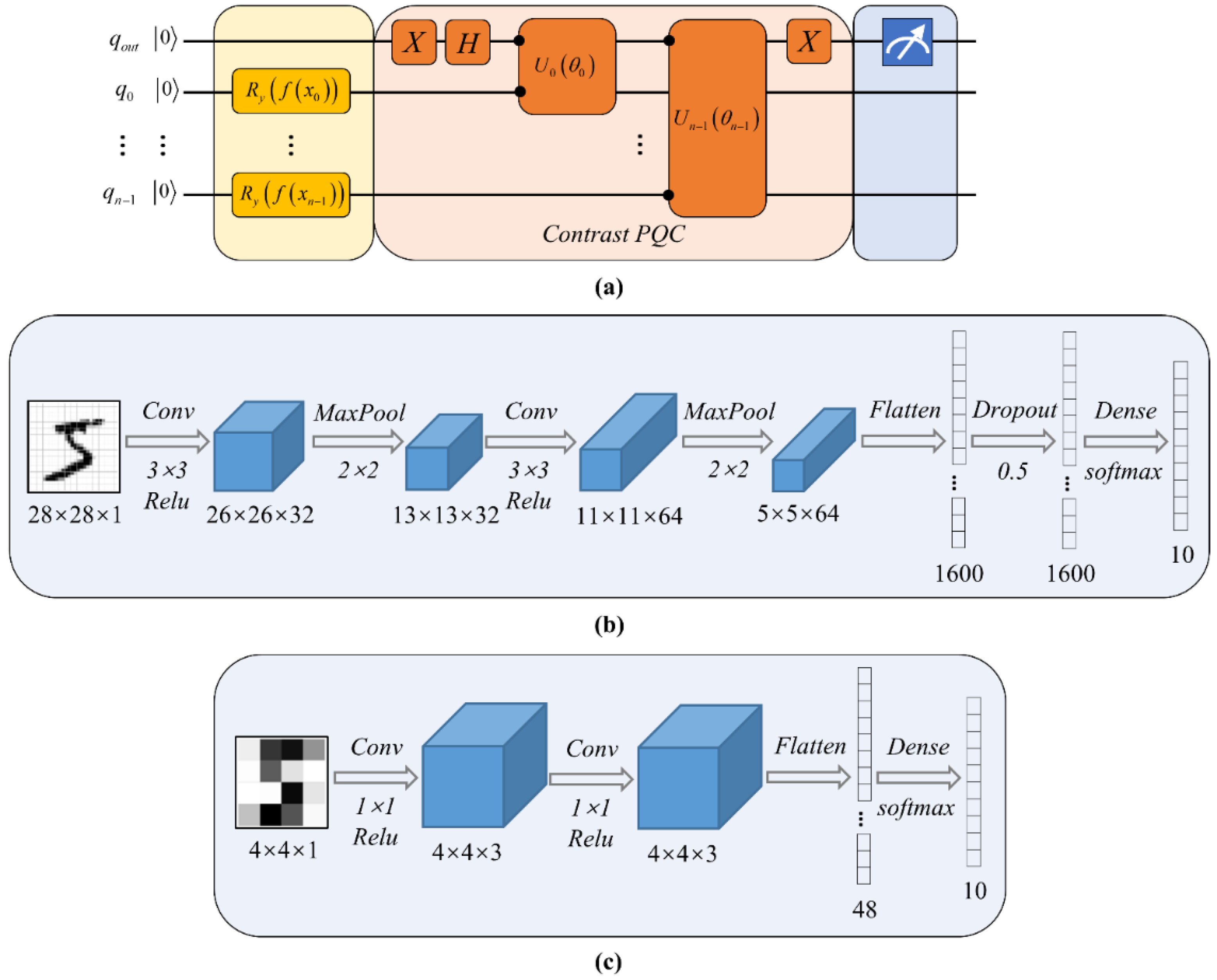
2.3. All-Qubit Multi-Observable Measurement Strategy
3. Experiments and Discussion
3.1. The Superiority of the AMM Strategy
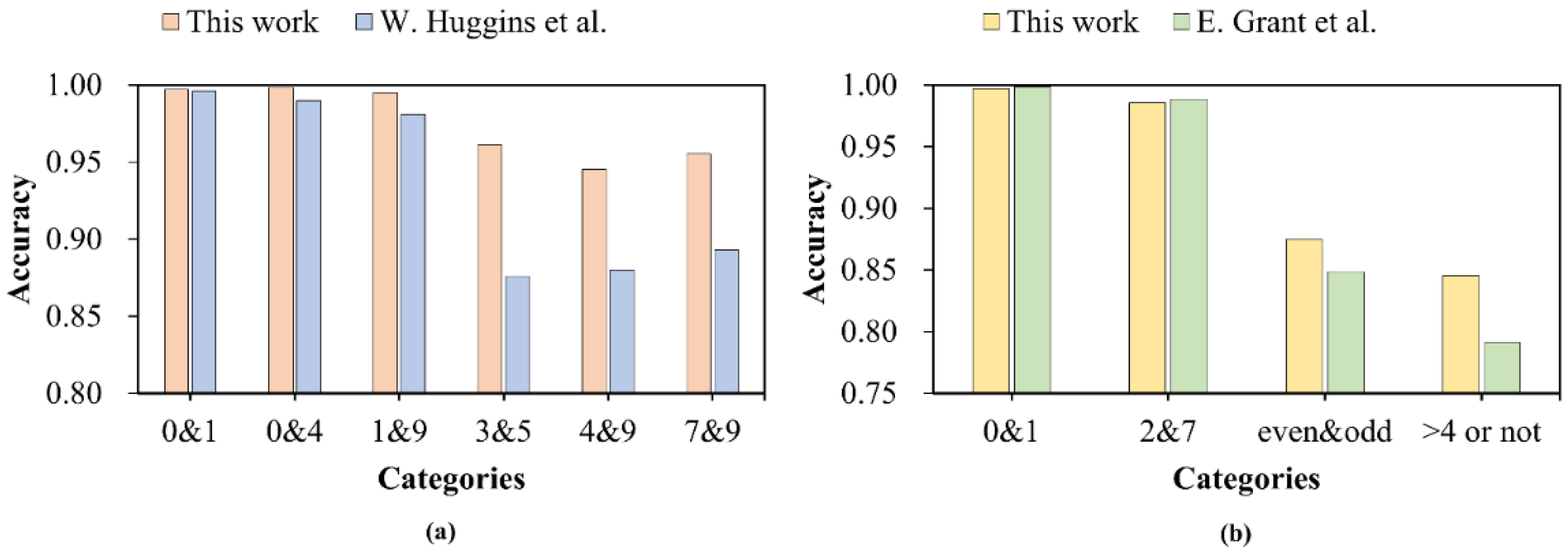
3.2. Binary Classification Based on the HQNN
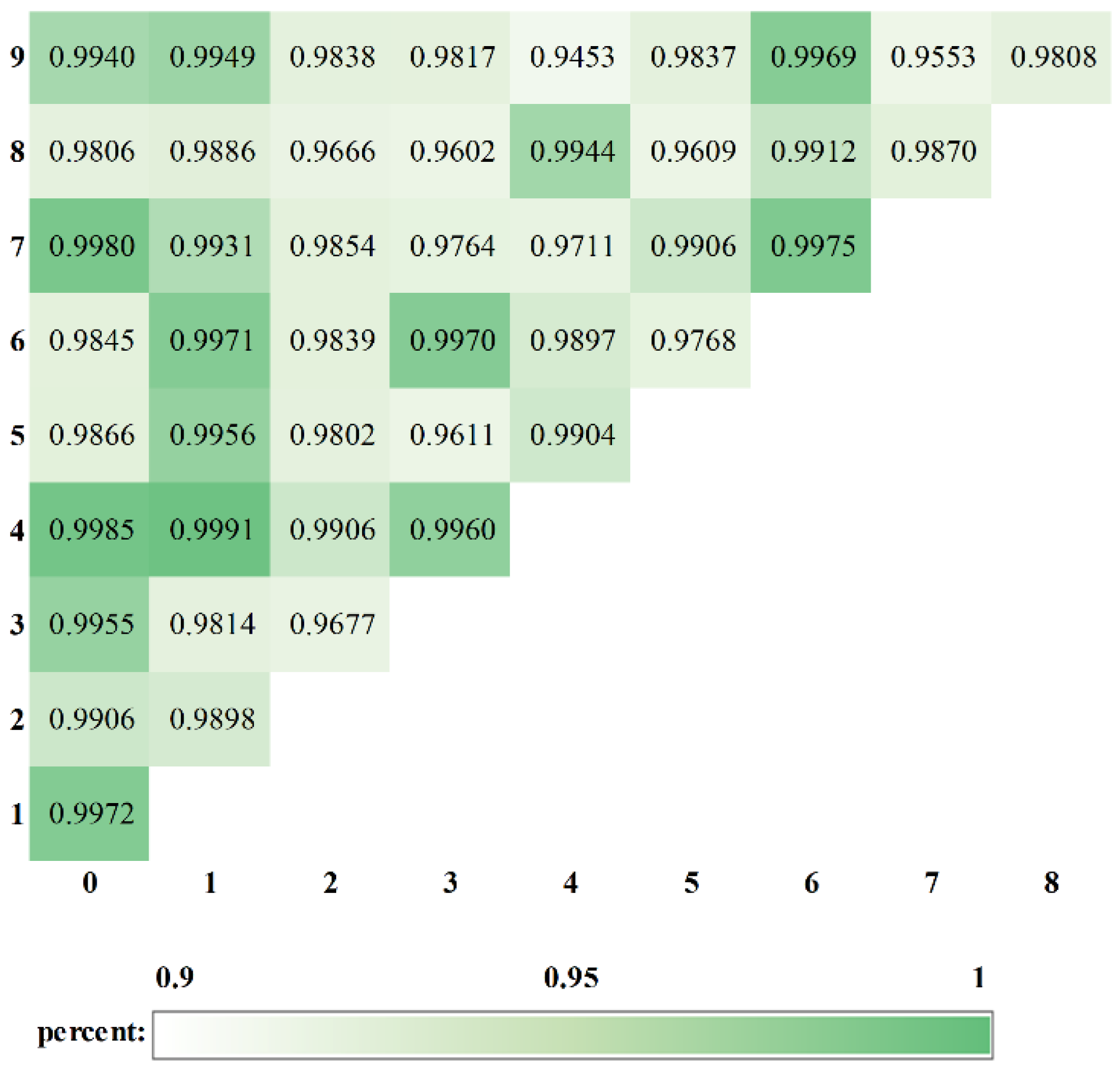
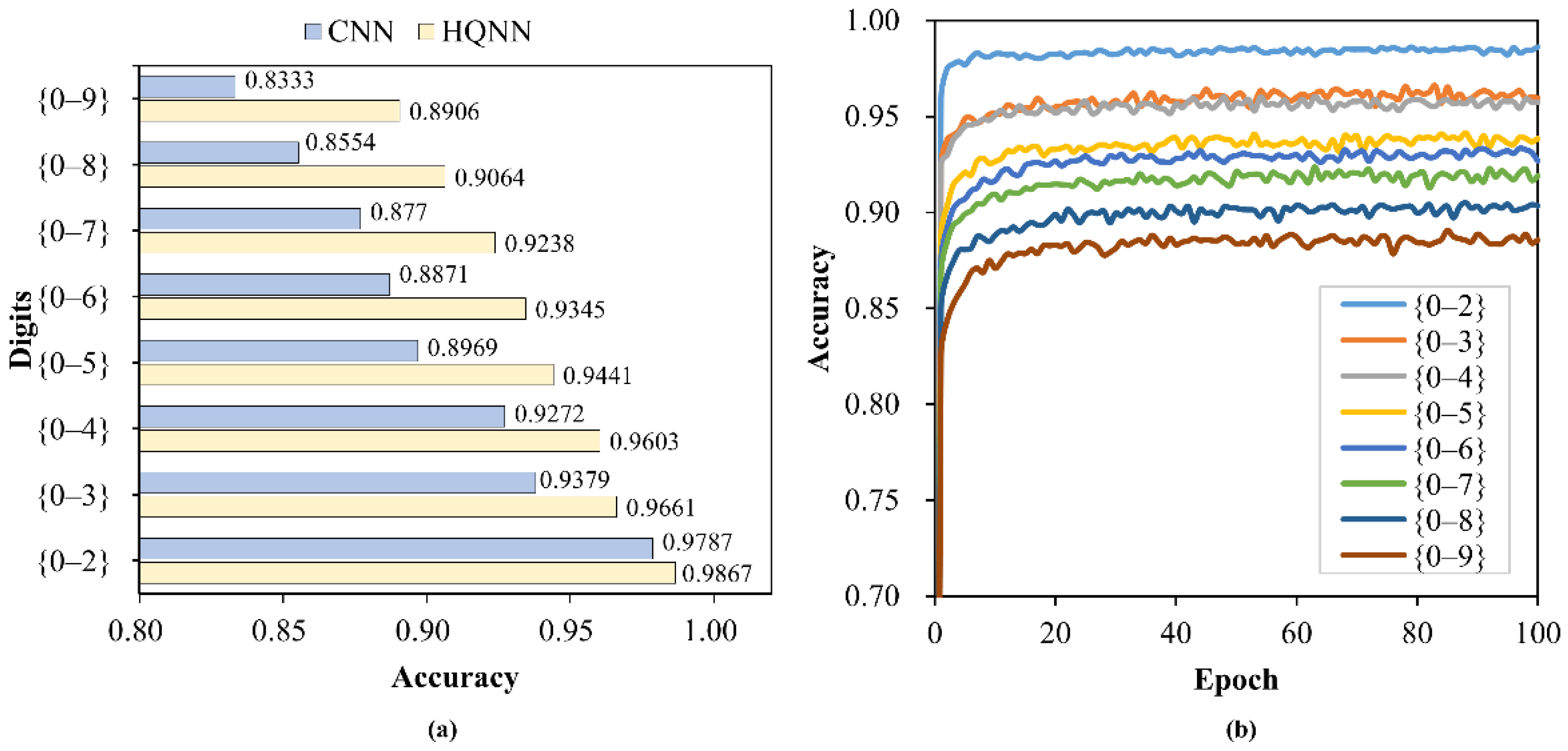
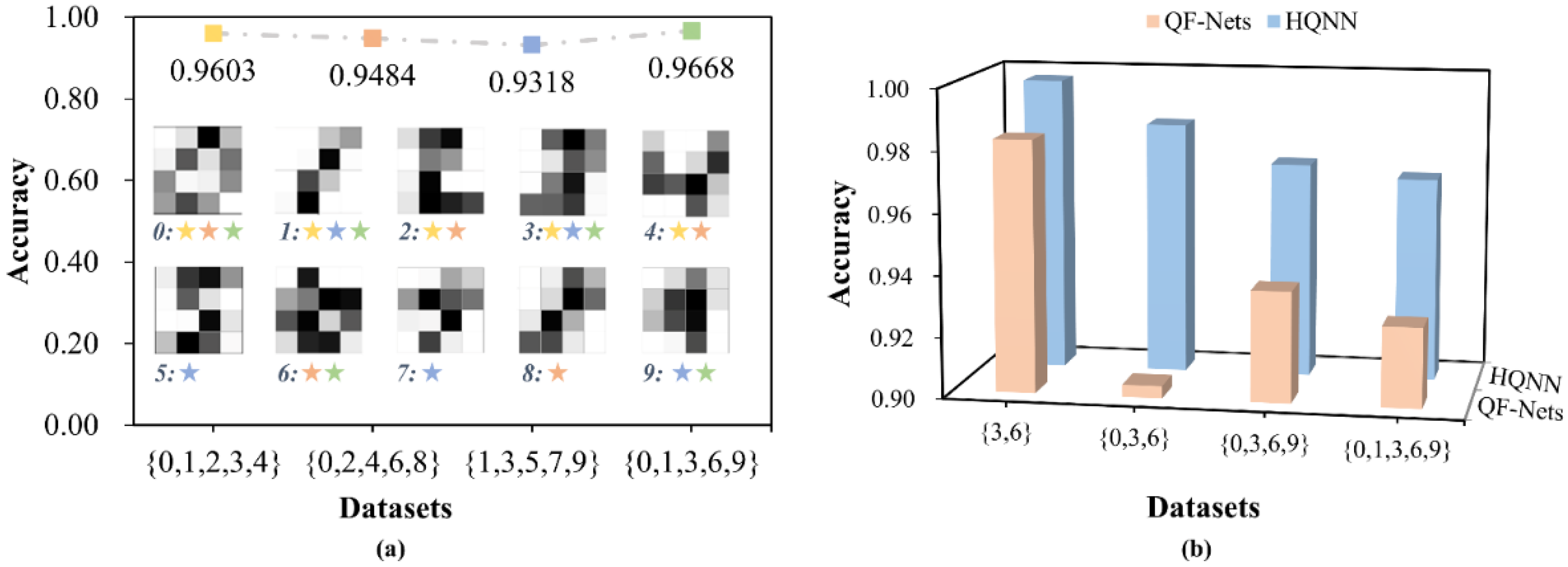
3.3. Multi-Classification Based on the HQNN

3.4. Computational Cost
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feynman, R.P. Simulating physics with computers. Int. J. Theor. Phys. 1982, 21, 467–488. [Google Scholar] [CrossRef]
- Preskill, J. Quantum Computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Romero, J.; Olson, J.P.; Aspuru-Guzik, A. Quantum autoencoders for efficient compression of quantum data. Quantum Sci. Technol. 2017, 2, 045001. [Google Scholar] [CrossRef] [Green Version]
- Lamata, L.; Alvarez-Rodriguez, U.; Martín-Guerrero, J.D.; Sanz, M.; Solano, E. Quantum autoencoders via quantum adders with genetic algorithms. Quantum Sci. Technol. 2018, 4, 14007. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.; Lamata, L.; Sanz, M.; Chen, X.; Solano, E. Experimental implementation of a quantum autoencoder via quantum adders. Adv. Quantum Technol. 2019, 2, 1800065. [Google Scholar] [CrossRef] [Green Version]
- Kieferová, M.; Wiebe, N. Tomography and generative training with quantum Boltzmann machines. Phys. Rev. A 2017, 96, 062327. [Google Scholar] [CrossRef] [Green Version]
- Jain, S.; Ziauddin, J.; Leonchyk, P.; Yenkanchi, S.; Geraci, J. Quantum and classical machine learning for the classification of non-small-cell lung cancer patients. SN Appl. Sci. 2020, 2, 1–10. [Google Scholar] [CrossRef]
- Dallaire-Demers, P.; Killoran, N. Quantum generative adversarial networks. Phys. Rev. A 2018, 98, 012324. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, S.; Weedbrook, C. Quantum generative adversarial learning. Phys. Rev. Lett. 2018, 121, 040502. [Google Scholar] [CrossRef] [Green Version]
- Romero, J.; Guzik, A.A. Variational quantum generators: Generative adversarial quantum machine learning for continuous distributions. Adv. Quantum Technol. 2021, 4, 2000003. [Google Scholar] [CrossRef]
- Zeng, J.; Wu, Y.; Liu, J.; Wang, L.; Hu, J. Learning and inference on generative adversarial quantum circuits. Phys. Rev. A 2019, 99, 052306. [Google Scholar] [CrossRef] [Green Version]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef]
- Havlicek, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [Green Version]
- Mengoni, R.; di Pierro, A. Kernel methods in quantum machine learning. Quantum Mach. Intell. 2019, 1, 65–71. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Broughton, M.; Mohseni, M.; Babbush, R.; Boixo, S.; Neven, H.; McClean, J.R. Power of data in quantum machine learning. Nat. Commun. 2021, 12, 3043. [Google Scholar] [CrossRef]
- Chen, H.; Wossnig, L.; Severini, S.; Neven, H.; Mohseni, M. Universal discriminative quantum neural networks. Quantum Mach. Intell. 2021, 3, 1–11. [Google Scholar] [CrossRef]
- Grant, E.; Benedetti, M.; Cao, S.; Hallam, A.; Lockhart, J.; Stojevic, V.; Green, A.G.; Severini, S. Hierarchical quantum classifiers. NPJ Quantum Inf. 2018, 4, 65. [Google Scholar] [CrossRef] [Green Version]
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/datasets/Iris (accessed on 11 March 2022).
- LeCun, Y.; Cortes, C.; Burges, C.J.C. MINIST Handwritten Digit Database. ATT Labs. Volume 2. 2010. Available online: http://yann.lecun.com/exdb/mnist (accessed on 7 February 2022).
- Huggins, W.A.; Patil, P.A.; Mitchell, B.A.; Whaley, K.A.B.; Stoudenmire, E.B.M. Towards quantum machine learning with tensor networks. Quantum Sci. Technol. 2019, 4, 024001. [Google Scholar] [CrossRef] [Green Version]
- Farhi, E.; Neven, H. Classification with quantum neural networks on near term processors. arXiv 2018, arXiv:1802.06002. [Google Scholar]
- Skolik, A.; McClean, J.R.; Mohseni, M.; van der Smagt, P.; Leib, M. Layerwise learning for quantum neural networks. Quantum Mach. Intell. 2021, 1, 5. [Google Scholar] [CrossRef]
- Wilson, C.M.; Otterbach, J.S.; Tezak, N.; Smith, R.S.; Polloreno, A.M.; Karalekas, P.J.; Heidel, S.; Alam, M.S.; Crooks, G.E.; da Silva, M.P. Quantum kitchen sinks: An algorithm for machine learning on near-term quantum computers. arXiv 2018, arXiv:1806.08321. [Google Scholar]
- Yang, Z.; Zhang, X. Entanglement-based quantum deep learning. New J. Phys. 2020, 22, 033041. [Google Scholar] [CrossRef]
- Li, R.Y.; Albash, T.; Lidar, D.A. Limitations of error corrected quantum annealing in improving the performance of Boltzmann machines. Quantum Sci. Technol. 2020, 5, 45010. [Google Scholar] [CrossRef]
- Wu, R.; Cao, X.; Xie, P.; Liu, Y. End-to-end quantum machine learning implemented with controlled quantum dynamics. arXiv 2020, arXiv:2003.13658. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, R.; Xu, R.; Luo, J.; Hu, W. A quantum deep convolutional neural network for image recognition. Quantum Sci. Technol. 2020, 5, 44003. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/datasets/Wine (accessed on 7 February 2022).
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the 29th AAAI Conference on Artificial Intelligence 2015, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. arXiv 2016, arXiv:1605.08695. [Google Scholar]
- Jiang, W.; Xiong, J.; Shi, Y. A co-design framework of neural networks and quantum circuits towards quantum advantage. Nat. Commun. 2021, 12, 579. [Google Scholar] [CrossRef]
- Schuld, M.; Bocharov, A.; Svore, K.M.; Wiebe, N. Circuit-centric quantum classifiers. Phys. Rev. A 2020, 101, 032308. [Google Scholar] [CrossRef] [Green Version]
- Mitarai, K.; Negoro, M.; Kitagawa, M.; Fujii, K. Quantum Circuit Learning. Phys. Rev. A 2018, 98, 032309. [Google Scholar] [CrossRef] [Green Version]
- Broughton, M.; Verdon, G.; McCourt, T.; Martinez, A.J.; Yoo, J.H.; Isakov, S.V.; Massey, P.; Halavati, R.; Niu, M.Y.; Zlokapa, A.; et al. TensorFlow Quantum: A Software Framework for Quantum Machine Learning. arXiv 2020, arXiv:2003.02989. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learn, Represent, (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Chollet and Francois. Keras. Available online: https://keras.io (accessed on 7 February 2022).
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Forina, M.; Leardi, R.; Armanino, C.; Lanteri, S. PARVUS: An Extendible Package for Data Exploration, Classification and Correlation; Elsevier: Amsterdam, The Netherlands, 1990. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dimensions | Classes | Samples | Cost | Accuracy | ||
|---|---|---|---|---|---|---|---|
| Train | Test | Qubits | Gates | ||||
| IRIS | 4 | 3 | 112 | 38 | 4 | 9 | 100% |
| WINE | 13 | 3 | 133 | 45 | 13 | 36 | 100% |
| SEMEION | 256→16 | 10 | 1194 | 399 | 16 | 45 | 90.98% |
| MNIST | 784→16 | 10 | 60,000 | 10,000 | 16 | 45 | 89.06% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Y.; Wang, H.; He, J.; Huang, Q.; Chang, S. A Multi-Classification Hybrid Quantum Neural Network Using an All-Qubit Multi-Observable Measurement Strategy. Entropy 2022, 24, 394. https://doi.org/10.3390/e24030394
Zeng Y, Wang H, He J, Huang Q, Chang S. A Multi-Classification Hybrid Quantum Neural Network Using an All-Qubit Multi-Observable Measurement Strategy. Entropy. 2022; 24(3):394. https://doi.org/10.3390/e24030394
Chicago/Turabian StyleZeng, Yi, Hao Wang, Jin He, Qijun Huang, and Sheng Chang. 2022. "A Multi-Classification Hybrid Quantum Neural Network Using an All-Qubit Multi-Observable Measurement Strategy" Entropy 24, no. 3: 394. https://doi.org/10.3390/e24030394